融合单词贡献度与Word2Vec 词向量的文档表示
2021-04-29彭俊利耿小航
彭俊利,谷 雨,张 震,耿小航
(杭州电子科技大学通信信息传输与融合技术国防重点学科实验室,杭州 310000)
0 概述
随着深度学习技术的快速发展,文档表示方法已由基于词频信息的词袋模型(Bag-of-Word,BOW)[1-2]逐渐转向基于词嵌入(Word Embedding)的表示法。词袋模型将文档视为多个词的集合,其不考虑词的顺序和语义等信息,使用与词集合相同维度的向量来表示文档,向量中每一维所包含的数值即为该位置所表示词的权重[3-4]。虽然词袋模型在支持向量机(Support Vector Machine,SVM)、贝叶斯分类器和逻辑回归分类器中可得到较好效果,但仍存在一些问题[5-6]。当数据集较大时,采用词袋模型获得的文档向量维度会很高,从而导致维度灾难,而且文档中出现的词语数量较多,但在表示为高维向量时只有极少数的维度存在有效权重[7-8]。例如,文档中出现1 000个词,词向量维度为10万,但其中仅有1 000 个维度存在有效权重。此外,词袋模型仅考虑了词语的频次信息,没有在词语与上下文之间建立联系,导致词语的语义信息不足,从而无法区分一词多义或多词一义的情况。
以词嵌入为代表的基于深度学习的词向量表示法在词语与上下文之间建立联系,把维数为所有词语数量的高维空间嵌入到一个维数较低的连续向量空间中,每个词语都被映射为实数域上的向量,弥补了词频统计法存在的不足[9-10]。MIKOLOV 等人于2013 年构建Word2Vec 词嵌入模型[11],其利用词语与上下文的关系将词语转化为一个低维实数向量,从而有效地区分了一词多义或多词一义的情况。此后,EMLO、BERT 等词嵌入模型相继出现。虽然这些模型在多项自然语言处理任务中均获得了性能提升,但由于Word2Vec 能够简单、高效地获取词语的语义向量,因此其依然被广泛应用于分类任务、推荐系统和中文分词等方面。
文档由大量词语构成,但其中只有少数词语能代表文档,而大部分为噪声词语,如何去除噪声词语,充分利用具有表征性词语的语义信息构建文档向量是一个难题。现有研究多将词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法[12]和Word2Vec 相结合构建文档向量。文献[3]通过考虑词语的重要性,提出一种融合Word2Vec词向量与TF-IDF权重的文档表示法,并在搜狗中文文本语料库上验证了方法的有效性。文献[13]采用Word2Vec对微博文本进行扩展后以TF-IDF方法表示句向量,将句子中每个词的词向量相加形成句向量。文献[14]将词性引入TF-IDF算法,结合Word2Vec生成文本向量,并在复旦大学中文文本分类数据集上验证方法的有效性。文献[15]通过融合Word2Vec模型与改进TF-IDF算法获取文本向量,利用卷积神经网络进行分类,并在THUCNews数据集上验证方法的有效性。
上述方法结合了词语的TF-IDF 权重与Word2Vec词向量,但均未考虑文档中只有少数词语具有表征性的事实,影响了分类性能。针对该问题,本文提出一种新的文档表示方法。设计改进的单词贡献度(Term Contribution,TC)算法筛选具有表征性的词语集合,将其中所有词语的单词贡献度与Word2Vec 词向量相结合构建文档向量。为验证该方法的有效性,在搜狗中文文本语料库、复旦大学中文文本分类语料库和IMDB英文语料库上进行实验,并与相关方法进行对比。
1 相关工作
1.1 词的量化表示
1.1.1 TF-IDF 算法
TF-IDF 算法以概率统计为基础,计算一个词语在数据集中的重要程度。当一个词语在某篇文档中出现的频率越高而在数据集其他文档中出现的频率越低,则该词语的表征性越强,其TF-IDF 值越大。在TF-IDF 算法中,TF 指词频,即词语在文档中出现的频率,IDF 指逆文档频率。TF 和IDF 的计算公式分别如式(1)和式(2)所示:

其中,|wi|表示词语wi在文档dj中出现的次数,|dj|表示文档dj中所有词语的总数,|D|表示数据集中的文档总数,nw表示包含词语wi的文档数目。由此可以得出词语wi在文档dj中归一化后的TF-IDF 权重计算公式,如式(3)所示:

然而,TF-IDF 权重只考虑了词语在数据集中的频次信息,无法表达词语的语义信息。例如,“番茄”和“西红柿”表示的意义相同,若在数据集中出现的频次不同,则其TF-IDF 权重可能会相差很大。
1.1.2 Word2Vec 模型
受文献[16]提出的NNLM 模型启发,MIKOLOV等人[11]提出了Word2Vec 模型。Word2Vec 与NNLM 的区别在于:NNLM 是一个语言模型,词向量只是“副产品”,而Word2Vec是一种用于获取词向量的词嵌入模型。
Word2Vec 主要包括CBOW 和Skip-gram 两种模型[17]:CBOW 模型利用词wt的前后各c个词来预测当前词,如图1(a)所示;Skip-gram 模型利用wt预测其前后各c个词,如图1(b)所示。

图1 Word2Vec 模型示意图Fig.1 Schematic diagram of Word2Vec model
CBOW模型的输入层是词wt的前后2c个one-hot词向量,投影层将这2c个词向量累加求和,输出层是一棵以训练数据中所有的词作为叶子节点,以各词在数据中出现的次数作为权重的Huffman 树[3],此模型应用随机梯度上升法预测投影层的结果作为输出。Skip-gram模型与之类似。当获得所有词的词向量后,可发现类似如下规律:“king”−“man”+“woman”=“queen”[18],可见词向量能够有效表达词语的语义信息。
1.2 单词贡献度
单词贡献度[19]用于计算数据集中特征词t 对于文本相似性的贡献程度,计算公式如式(4)所示:
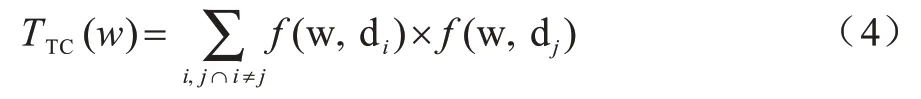
其中,f(w,d)表示单词w 在文档d 中的TF-IDF 权重。
词语的文档频数越高其IDF 值越低,当所有文档都包含该特征词时,其IDF 值为0。而那些在大部分文本中出现的特征词因为IDF 值非常小,所以TC值也会较小。当特征词只出现在一个文本或所有文本中,其TC 值为0。在文档频数适中的情况下,TF-IDF 权重较大的特征词具有较大的TC 值。
1.3 文档的量化表示
文档的量化表示就是将非结构化的文本信息转化为计算机可处理的数字信息[20],本文主要介绍以下两种表示方法。
1.3.1 基于词频信息的表示方法
经典的文档量化方法是BOW 模型,主要原理是词one-hot 编码的叠加[3],如数据集中共9 个词语,其中,“番茄”的one-hot 编码是[0,0,0,1,0,0,0,0,0],“西红柿”的one-hot 编码是[0,1,0,0,0,0,0,0,0],若一篇文档仅包含“番茄”和“西红柿”,则文档向量表示为[0,1,0,1,0,0,0,0,0]。BOW 模型中仅体现了词语是否出现在文档中,可以看出很难利用该向量计算出与实际相符的文档相似度。因此,研究者提出了许多改进方法。应用词的TF-IDF 权重代替BOW 模型中的非“0”值是最常用的一种方法,它能够有效计算文本间的相似度,但这种基于词频统计的方法容易导致向量的高维性和稀疏性。
1.3.2 基于Word2Vec 的表示方法
基于Word2Vec 的文档表示方法解决了传统词向量高维性和稀疏性的问题,并引入了语义信息,因此其被广泛应用。此类方法的基本流程是先获取文档中所有词的词向量,再通过聚类或取平均值的方法进行文档向量表示[3]。很多研究者考虑到单词的重要性,将TF-IDF 权重与Word2Vec 相结合,这样虽然可以使性能得到提升,但很多无区分度的词语依然会影响文档向量的表征性。
2 融合改进TC 算法与Word2Vec 的文档表示
考虑到文档中无区分度词语对文档向量表征性的影响以及词语在文档中的重要性,本文对传统单词贡献度算法进行改进,在Word2Vec 词向量的基础上,结合改进算法提出一种新的文档向量表示方法。
2.1 改进的单词贡献度算法
由式(4)可知,传统的单词贡献度算法是将不同文本中相同单词的TF-IDF 值两两相乘再相加,这样会严重弱化IDF 值所包含的语义信息,即弱化单词在整个数据集中的重要程度。为解决这一问题,本文提出一种新的计算方法:先将每篇文档中相同单词的TF 值进行两两相乘再相加的操作,得到根据TF 值计算出的单词权值,再将该值与IDF 相乘。这样得到的单词贡献度不仅保留了由TF 值计算得到的权值,同时也保留了IDF 值包含的完整语义信息,提高了特征词与噪声词的区分度。单词贡献度的计算公式如式(5)所示:

其中,tfii和tfij表示单词wi在第i篇文档和第j篇文档中的文档频率TF 值,idfi表示wi的逆文档频率IDF 值。
2.2 Word2Vec 词向量与改进单词贡献度的融合
设数据集D中包含M个文档,首先将M个文档中的内容采用分词工具进行分词,利用Word2Vec 模型进行训练,获取每个词语对应的n维词向量V=(v1,v2,…,vn),同时应用改进的单词贡献度算法计算每个单词的贡献度。对所有单词按贡献度大小进行降序排列,设置贡献度阈值x,选出贡献度大于x的前W个单词构建单词集合T。
对于文档dj(j=1,2,…,M),找出集合T中存在的单词,文档向量可表示为:

其中,Vwi表示词语wi的词向量,TCwi表示词语wi的单词贡献度。通过改进TC 与Word2Vec 的融合,能够将单词对文档的重要性权值融入包含语义信息的词向量,使词向量更具表征性。本文方法流程如图2 所示。

图2 本文方法流程Fig.2 Procedure of the proposed method
3 实验
3.1 分类性能评价指标
本文采用的是分类任务最常用的评价指标准确率、召回率和F1值。
准确率是指分类结果中某类被正确分类的文档数目与所有被分入该类文档总数的比值,计算公式如式(7)所示:

召回率是指某类被正确分类的文档数与该类实际文档数的比值,计算公式如式(8)所示:

F1值是综合准确率与召回率的评价指标,计算公式如式(9)所示:

在上述评价指标中,TP 表示分入A 类实际也为A 类的文档数,FN 表示未分入A 类而实际为A 类的文档数,FP 表示分入A 类而实际不为A 类的文档数。
3.2 实验结果与分析
选用搜狗实验室整理的中文文本分类语料库作为实验数据集,语料库内文本被分为9类,分别为财经(C1)、互联网(C2)、健康(C3)、教育(C4)、军事(C5)、旅游(C6)、体育(C7)、文化(C8)和招聘(C9),每类包含1 990 篇文档。
分别采用TF-IDF、均值Word2Vec、TF-IDF 加权Word2Vec、TC 加权Word2Vec 模型构建的文档向量与本文模型构建的文档向量进行分类结果对比。经过多次试验,在计算单词贡献度时将贡献度阈值设置为效果最佳的0.009,本文模型提取19 082 个具有表征性的词语。选用lib-svm 作为分类器,所有实验采用五折交叉验证。各模型的分类性能对比如表1~表5 所示。
由表1、表2和表5可以看出,本文模型的分类性能优于TF-IDF模型和均值Word2Vec模型,表明TF-IDF与Word2Vec融合后生成的词向量包含更丰富的语义信息,能够更准确地进行分类。由表3、表4和表5可以看出,本文模型在SVM 分类器上平均准确率、召回率和F1值较TF-IDF 加权Word2Vec 模型分别提升2.27%、2.24%和2.26%,较TC加权Word2Vec模型分别提升1.32%、1.29%和1.25%。通过比较5种模型分类性能评价的平均值可以看出,本文模型在准确率、召回率、F1值指标上均获得了最佳的效果,验证了本文方法在中文文档表示方面的有效性。

表1 TF-IDF 模型分类性能Table 1 Classification performance of TF-IDF model %

表2 均值Word2Vec 模型分类性能Table 2 Classification performance of average Word2Vec model %
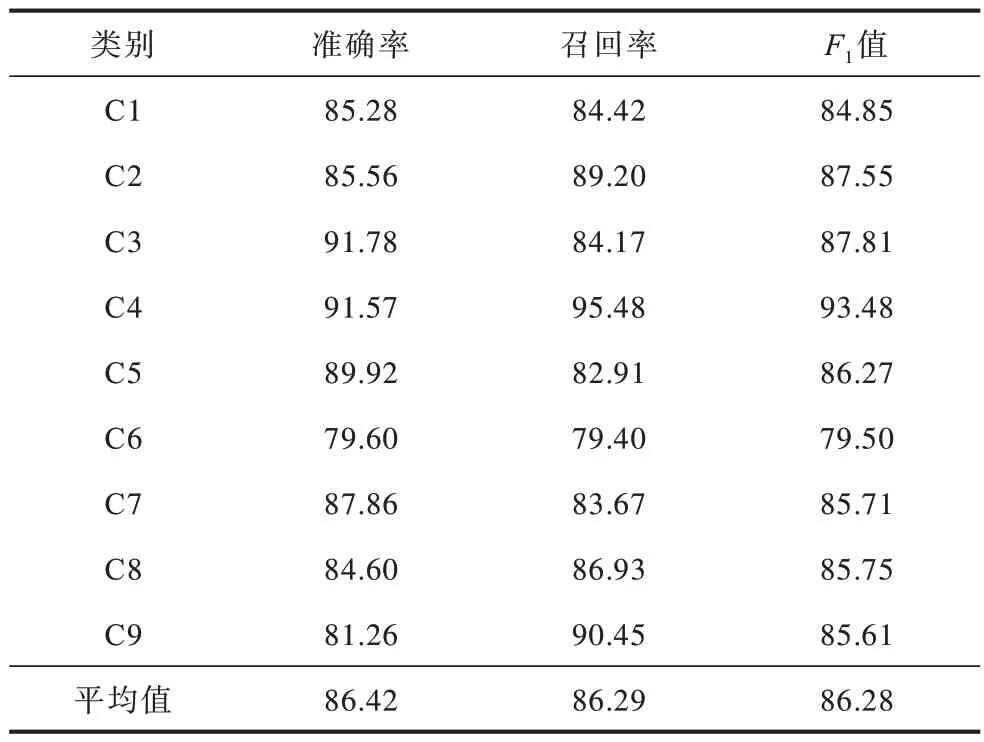
表3 TF-IDF 加权Word2Vec 模型分类性能Table 3 Classification performance of TF-IDF weighted Word2Vec model %
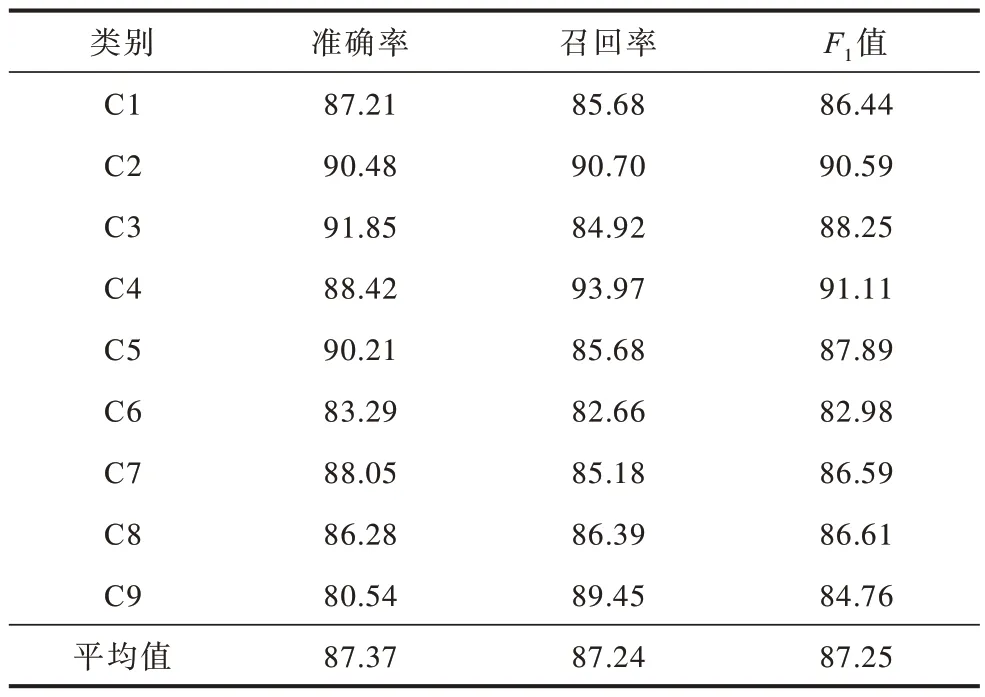
表4 TC 加权Word2Vec 模型分类性能Table 4 Classification performance of TC weighted Word2Vec model %

表5 本文模型分类性能Table 5 Classification performance of the proposed model %
此外,采用复旦大学中文文本分类语料库中文档数目较多的Art类、Agriculture类、Economy类和Politics类数据集进行实验,将本文模型与文献[13]提出的PTF-IDF 加权Word2Vec 模型进行对比,如图3 所示。可以看出,本文模型在准确率、召回率和F1值上均具有优势,进一步验证了本文方法的有效性

图3 本文模型与文献[13]模型的分类性能对比Fig.3 Classification performance comparison of the proposed model and the model in literature[13]
上述实验均采用了中文语料,仅验证了本文方法在中文文本表示方面的有效性。为验证其对英文文本表示的有效性,选取IMDB 文本情感分类语料库作为英文实验数据集,其中包括积极和消极两类数据,从每类中选取2 500 篇英文数据,采用五折交叉验证。结果表明,本文模型的分类准确率为76.26%,验证了其在英文文本表示方面的有效性。但由结果可知,英文文本分类准确率低于中文文本分类,这可能有两点原因:1)由于英文数据集较少,本文仅用3 万多篇英文文本训练Word2Vec 模型,训练语料的不足导致模型无法学习到单词较为准确的语义信息;2)由于英文存在各类语态的表达方法,单词在不同语态下需要添加不同后缀,使得多词一义的情况进一步加重,Word2Vec 模型可能会将加了不同后缀的单词理解为不同的单词,单词贡献度的计算也因此受到影响。
4 结束语
针对当前文档向量表示方法存在的不足,本文综合考虑单词的重要程度和语义信息,将计算出的贡献度权值与Word2Vec 词向量进行融合,提出一种新的文档表示方法。实验结果表明,应用于中文文本分类任务时,本文模型较基于TF-IDF 模型、均值Word2Vec 模型、TF-IDF加权Word2Vec模型和传统TC加权Word2Vec模型效果更好,并且其对英文文本也可实现有效分类。后续将从降低单词贡献度算法的时间复杂度出发,进一步优化本文方法。
