基于机器学习的污染土壤修复变量分类与评价
2021-04-29曹书苗柯希彪汤引生李军富
郭 琳,曹书苗,柯希彪,刘 俊,汤引生,李军富
(1.商洛学院 电子信息与电气工程学院,陕西 商洛 726000;2.西安建筑科技大学 陕西省环境工程重点实验室,陕西 西安 710055;3.商洛学院 化学工程与现代材料学院,陕西 商洛 726000)
0 引言
污染土壤修复研究具有保障耕地安全、修复生态环境和土地资源再利用等方面的重要意义,是当前技术研究和应用的热点。通常,检验一种修复方法的优劣主要看是否达到土壤环境质量、肥力质量和健康质量等目标参数[1],内容涉及污染物降低程度、生态功能恢复程度和农产品安全性等方面。但是对于尾矿库、垃圾填埋场等污染程度高、修复难度大的复杂污染场地[2],不仅需要成熟的技术,还要考虑修复周期、成本投入和资源综合利用等因素。传统的土壤修复效率评估采用权重法,累计每个变量指标所占百分比,再结合土壤重金属消解率计算修复效率。但固定的变量指标及权重无法适应动态修复过程,容易导致结果出现较大误差。随着人工智能技术的发展应用,研究者开始关注效率高、成本低的智能精细修复技术,利用算法或者模型来完成修复变量特征的表征[3],再通过规则构造评价权重集,最后用匹配模型实现结果评价和分析。郑燊燊等[4]模拟电动修复Cd 污染土壤,利用不同位置下pH 值与Cd 浓度关系为基础,首次建立DBLM 模型预测修复效果;金晶炜等[5]提出以生菜砷吸收量等为指标,利用灰色关联和聚类分析法定量聚类评价修复贡献值;郝安峰等[6]在PLC 控制的工控机上安装修复软件,模拟测控污染土壤修复过程,实时确定土壤物理参数和控制参数;王兵等[7]采用层次分析与优劣解距离法建立评价体系,解决指标权重和排序问题,并实施了室内试验校核;马科峰等[8]和魏树和等[9]几乎同时总结了电动-植物修复重金属污染土壤的最新研究数据,为定量评价奠定了基础。以上研究是基于实验室盆栽富集植物,开展强化修复重金属污染土壤,解决单一或主要因素下电动修复与富集植物吸收的自适应问题,而通用型的定量评价与主动干预方法有待继续研究。本文提出一种融合策略,利用随机森林算法中的集成学习策略和灰色关联度法中相似行为映射结果的客观科学性,充分发挥快速主动干预优势,建立土壤修复变量分类评价模型,并通过重金属污染土壤修复测试加以验证。
1 修复变量分类方法
1.1 分类与评价整体流程
尾矿库或矿场矿渣主要包含金属氧化物的残渣态和结合态,土壤在修复过程中由于电流密度增大、土壤湿度下降,使得渗流作用减弱、金属离子迁移困难[10],所以需要采用综合的强化修复技术提高重金属去除效率。在研究“电动法+植物萃取”修复法机理的基础上,对快速智能修复中固有或潜在的影响因素进行分析,从而制定出变量分类与评价指标体系和应用模型,其流程见图1。由图1可以看出,先采集修复样本数据,对数据进行预处理,通过评价指标体系得到文本变量特征;训练样本由软件变量抽样后送到随机森林RF 分类器,通过决策树进行性能评估得到分类结果和评价错误率;同时,把分类结果送到GRA 灰色关联算法模块中计算分类评价结果。
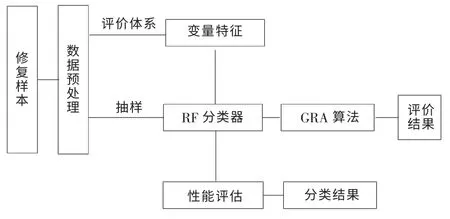
图1 分类与评价流程
1.2 修复变量的分类评价指标体系
提出的修复变量分类评价指标体系是建立在电动修复重金属污染土壤的基础上,进行定量评价土壤修复质量。此方法既考虑了农田土壤的一般性,也考虑了污染场地的特殊性,兼顾土壤复耕标准和二次开发利用的社会、经济价值。比如使用闭库之后的重金属尾矿库,综合修复治理难度和费用很大,但具有生态环保、安全监控和资源再利用等方面的重大意义,需要研究者系统考虑修复方案。重金属尾矿库的污染体存量大、坝体结构复杂,适用于原位修复和治理,其中添加试剂法易造成下游水体二次污染,而“电动法+植物萃取” 技术在尾矿库土壤修复及资源再利用等方面具有显著优势。本文以尾矿库土壤修复为例,通过对尾矿库实地调研和重金属成分检测,分析污染物的组成和迁移规律,同时研究了库区富集植物的优势度和转运系数,设计影响土壤修复质量的变量评价指标体系见表1。由表1可以看出,修复变量包括土壤因素变量群、电极因素变量群、电场因素变量群和辅助因素变量群4 类一级指标,以及它们所属的20 个二级变量指标。通过分析污染土壤自身影响变量,土壤因素包括土壤原始pH值、动态pH 值、湿度、温度、紧实度、电导率和重金属质量浓度等变量;电极因素包括电极布置方式、材料、间距和正负极交替周期等变量;电场因素包括通电时间、电场强度、电流大小、交流/直流交替周期等变量;辅助因素包括添加剂的种类、浓度、富集植物种类等变量。
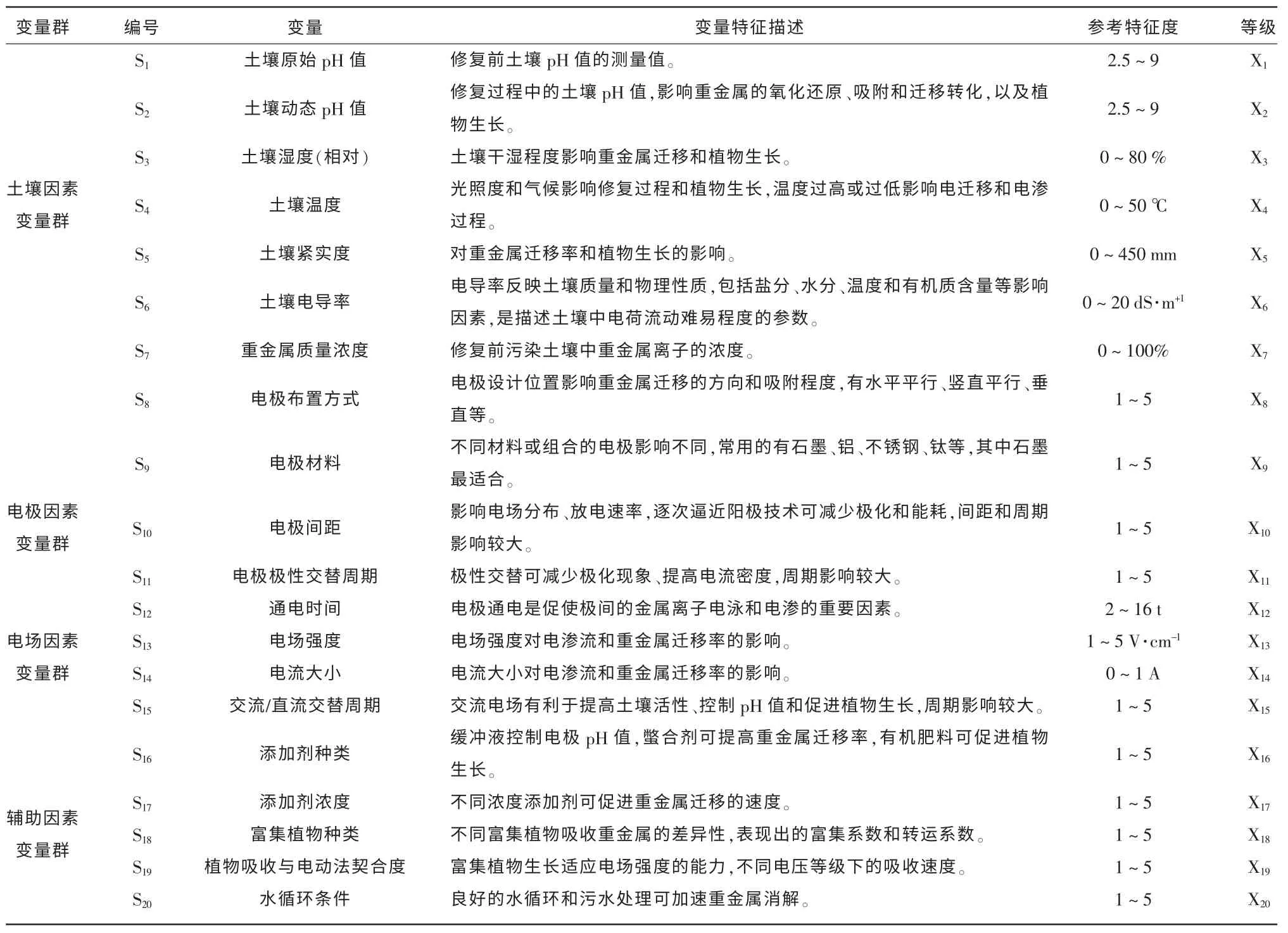
表1 土壤修复变量分类评价指标体系
1.3 变量特征度的提取
土壤修复变量分类评价指标体系建立之后,用于过滤提取修复样本变量,机器系统一般用特征来识别或区分变量,这里采用向量空间模型VSM[11]定义的)S1,x1;S2,x2;…;Sj,xj)来描述特征,其中Sj为特征项,xj为特征项对应的等级赋值,用以描述变量特征项的变化程度。为提高特征度获取精度,研究利用Doc2Vec 方法[12](一种随机文本获得固定长度特征的无监督算法工具,具备计数、平均、加权、百分率、最大值及最小值等功能),对变量特征项进行预处理,获得特征度的编码和等级赋值。实验样本数据较多时,为获得更好区分效果,可利用类似短时傅里叶分析工具[13],再次处理变量特征,通过公式(1)得到j 变量处第i 个节点的特征度方均根值Xj,i(S),xj,n为变量j 处的第n 个等级赋值;N 为j 变量全部赋值个数。
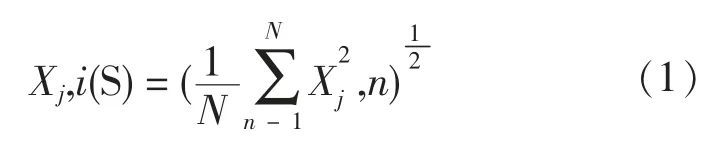
2 修复变量分类评价模型
2.1 随机森林分类算法
随机森林算法是一种基于集成学习Bagging 的算法,建立包含多个决策树的随机分类器,准确度高、处理能力强,适合于分类和变数评估等问题[14-15]。原始Original-RF 森林算法,是一种基于Boosting 算法的依赖串行生成序列化方法,首先初始训练得到基学习器,然后调整样本训练下一个基训练器,如此重复达到基训练器预期数目,最后将所有基训练器加权结合得到分类结果;随机抽样Random-RF 森林算法是基于Bagging 算法的改进版,产生相对独立和差异化的基训练器集合,通过Bootstrap 自助采样,随机森林分类算法示意见图2。由图2可以看出,引入决策树结构,从根节点开始将数据样本根据特征进行分类,每个类别决策树通过Bootstrap 抽样产生一个训练集,重复随机抽取m 次的M 个样本数据。决策树数量根据所选取的变量数目及组合确定,随后在生长过程中以指数最小原则选出符合评价指标体系中若干特征变量的最优集合,通过构建的M个决策树形成随机森林。将土壤修复样本集输入到随机森林,由最大投票数结果作为分类结果。
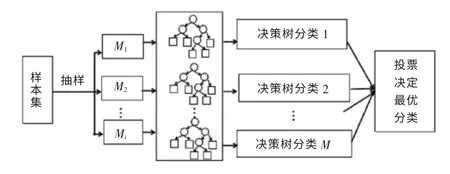
图2 随机森林分类算法示意
2.2 GRA 评价算法
GRA 灰色关联度算法[16]是一种无监督学习模型。随机森林法将半定性、半定量问题转化为定量问题,对模型训练的依赖性强,而灰色关联度算法是根据序列几何形状的相似性来确定序列重要关系,强调行为结果的客观性,所以需要兼顾二者的优点。通过随机森林分类算法得出的分类结果和变量权重值,用于构建评价指标重要性判断矩阵φ,先确定比较集列和最优指标集,再对指标进行离散性的规范量化,再通过公式(2)计算修复评价指标的关联系数,经过加权求和,得到土壤修复变量的加权关联度值。式(2)中λ 为修复分辨系数,本文取0.4(一般取0~0.5);λj为修复质量关联系数。然后通过公式(3)得到灰色关联系数矩阵R,再结合判断矩阵φ,由公式(4)计算出灰色关联度值θj,S 为修复变量特征。

根据灰色关联度值对土壤变量分类修复效率进行分级评价,当样本的修复评价效率为0.8~1 时为修复水平优秀,0.7~0.8 时为优良,0.5~0.7 时为一般,0~0.5 时为修复水平较差。
2.3 分类与评价模型RF-GRA
通过比较融合随机森林算法和GRA 算法的功能,建立RF-GRA 土壤修复变量分类评价模型见图3。由图3可以看出,由随机森林算法得到分类结果和分类错误率,再由GRA 算法得到修复变量分类准确度的评价值。土壤修复实验的训练样本通过工具包预处理后,得到的变量特征数据S1~S20,通过Bootstrap 再从对应训练集中抽取M 个样本构成M个决策树,不剪枝完全自然生长得到随机森林分类器,通过多数投票表决得到分类结果和分类错误率;最后将测试样本输入到模型GRA 评价算法中,经过分层加权关联度计算,得到修复变量分类评价值。
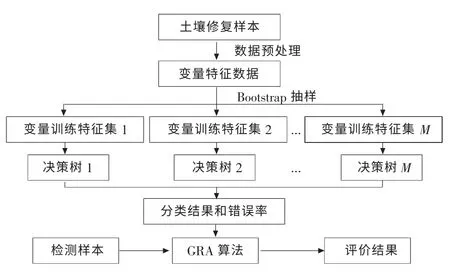
图3 RF-GRA 土壤修复变量分类评价模型
通过Bootstrap 从表1中20 个二级变量中抽取20 组变量特征度数据,带入RF 随机森林算法中得到20 个变量分类结果见图4。
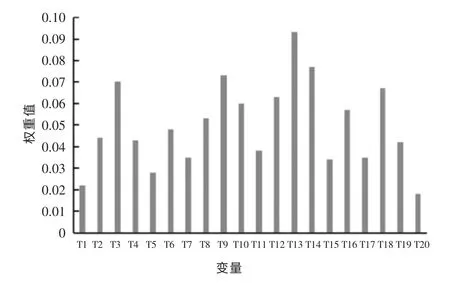
图4 RF 随机森林变量分类结果
由图4可以看出,修复变量的权重值,其中最重要的修复变量是电压梯度(0.093),第2 层次是电流大小(0.077)、电极材料(0.073)和土壤湿度(0.070),第3 层次是富集植物种类(0.067)、通电时间(0.063)和电极间距(0.06),第4 层次是添加剂种类(0.057)和电极布置方式(0.053),之后的变量指标权重均小于平均值,说明以上变量是影响土壤修复水平的重要指标;其中最后层次是土壤紧实度(0.028)、土壤原始pH 值(0.022)和水循环条件(0.018),此类变量在修复评价体系中的影响最小。
3 实验与结果分析
本文以地处秦岭山区的一个闭库6 a 的金矿的尾矿库为例,采集地表下20~50 cm 处的土壤作为实验测试样本,利用自制的电动修复箱开展修复实验,测试土壤中Cd,Cu,Zn 的消解效率。在室内修复实验时,土壤原始pH 值、土壤温度、电极间距、自然水循环条件等11 项变量设定不变,选择上述分类结果中的前9 项变量,分别设计A 类变量实验环境(电压梯度为1 V/cm、电流为200 mA、电极高纯石墨、土壤湿度为60%、富集植物:A1 东南景天/A2 黑麦草/A3 东南景天、通电时间为6 h/d、电极间距为10 cm、添加剂EDTA 二钠盐、阳极/阴极上下垂直布置)和B 类变量实验环境(电压梯度为1.5 V/cm、电流为500 mA、电极为不锈钢网、土壤湿度为70%、富集植物:B1 东南景天/B2 黑麦草/B3 白茅、通电时间为12 h/d、电极间距为20 cm、添加剂为柠檬酸+氯化钙、阳极/阴极为上下平行布置),分别将土壤测试样本A1(Cd),A2(Cu),A3(Zn)和样本B1(Cd),B2(Cu),B3(Zn)6 个修复样本加入电动修复箱进行实验;同时,测试样本通过RF-GRA 模型进行分级评价,得到20×M 个灰色关联度,再分级评价得到离散化数据文本,通过计算得到样本的修复评价效率。6 个修复样本的实验与仿真结果见图5。由图5可以看出,仿真评价效率高于实验效率,A1~A3 的相对误差分别为3.35%,4.12%和6.54%,B1~B3 的相对误差分别为11.19%,9.48%和8.66%,实验环境A 的相对误差低于环境B,分类评价模型真实反映了实际修复过程,误差在可接受范围内。实验环境A1 和A2中Cd 和Cu 的修复效果优于B1 和B2,但是环境A3中Zn 的修复效果低于B3。
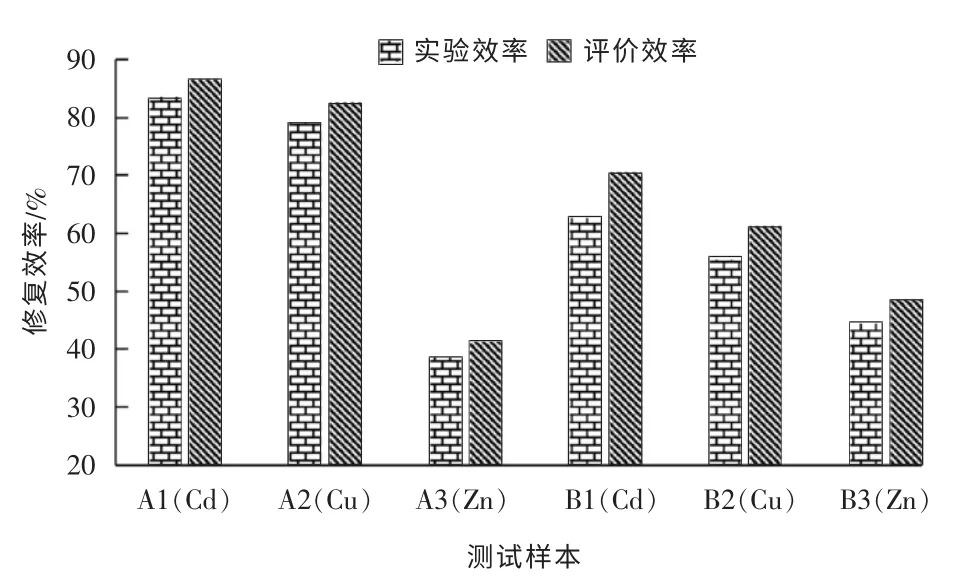
图5 修复样本的实验效率与评价效率
智能分类评价过程与人工修复实验类似,需要对修复变量进行编码、组合和优化,对众多变量特征进行融合和训练找到最佳变量组合。在模型计算过程中,树节点变量数目和决策树数目非常关键,决定了分类评价模型的错误率。不同测试样本或者不同的决策树初始抽样值,模型变量分类的误判率均值不同,选择误判率均值最低时的变量及数目作为最佳修复变量集,当错误率趋于稳定时决策树数目设定不变,分类训练过程结束。通过随机抽样森林RFRandom 算法和RF-GRA 算法,分别计算输出分类结果性能指标的错误率,RF-Random 算法的错误率见图6。RF-GRA 算法的错误率见图7。
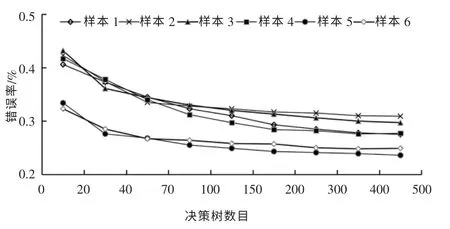
图6 RF-Random 算法的错误率

图7 RF-GRA 算法的错误率
对比分析图6、图7,随着决策树数目增加,分类错误率明显下降,并且当决策树数目从20 增至约300 时,分类错误率趋于稳定,所以针对选取的6 个测试样本,确定300 为最优分类决策树数量。在相同决策树数量均为300 条件下修复样本的2 种算法分类错误率对比见图8。由图8可以看出,RF-GRA 算法的分类错误率低于RF-Random 算法,说明文本提出的修复变量分类评价方法是可行的。

图8 不同随机森林算法的错误率对比
4 结论
在土壤电动强化修复技术的基础上,建立修复变量的分类评价指标体系和模型,根据修复实验样本数据进行分类效果评价,得到如下结论。
(1)融合随机森林算法和灰色关联法建立RFGRA 模型,输入分类评价指标完成修复变量分类,为修复方案的质量评价和改进奠定了基础。变量分类排名结果前9 的依次是电压梯度、电流大小、电极材料、土壤湿度、富集植物种类、通电时间、电极间距、添加剂种类和电极布置方式,处于最低层的依次是土壤紧实度、土壤原始pH 值和水循环条件。
(2)6 个测试样本的模型评价效率均高于实验效率,分类评价结果真实反映了实验修复过程。实验环境A 的相对误差低于环境B,实验环境A1 和A2 中Cd 和Cu 的修复效果优于B1 和B2,但是环境A3中Zn 的修复效果低于B3。如果相对误差超过可接受范围,可通过改变修复变量的特征度等级,重新分类和评价。
(3)RF-GRA 算法的分类效果优于RF-Random,并且当决策树数目由0 增至300 时,测试样本的分类错误率下降趋于平衡状态。
