基于深度学习CaffeNet模型的综合交通设施场景分类与识别研究
2021-04-28肖和平赵宇恒米素娟
肖和平, 赵宇恒, 米素娟
(1.湖南省交通运输厅科技信息中心, 湖南 长沙 410015;2.中国地质大学(武汉)地理与信息工程学院, 湖北 武汉 430074; 3.中国交通通信信息中心, 北京 100011)
0 引言
当前,遥感信息技术在交通网络建设与监管中的应用日益广泛,如何从海量遥感影像数据中对桥梁、港口、机场、车站等重要交通设施场景进行计算机自动图像特征提取,并将提取的设施场景图像特征输入分类算法模型,实现目标设施的准确分类与识别、及时获取各类交通设施状况,是智能化交通建设监管的难点问题,也是实现交通网络数字化、智能化,建立交通网络模型的重要技术之一,对综合交通网络布局、智慧交通建设等方面都具有重要的理论意义和实践应用价值[1-3]。近年来,国内外学者基于图像纹理、形状、颜色等低层特征和知识、语义等高层特征的提取,以及特征学习的方法,针对桥梁、机场、港口等某种交通目标的识别与检测进行了一定研究,如Huertas等[4]对航拍图像的纹理特征进行提取,实现机场综合体跑道的自动检测;毛玲等[5]提出了一种复合线索视觉注意模型,利用高分辨率光学遥感图像的港口多尺度低层特征和知识线索高层特征,实现了港口检测;Lu等[6]基于高空间分辨率遥感HSR(High Spatial Resolution)影像提取机场目标。韩晓青等[7]提取地物边缘轮廓,并结合SURF(Speed Up Robust Features)检测到图像中的机场目标;常永雷等[8]分析高分辨率遥感SAR影像的统计特征和桥梁特征,提出了一种新的桥梁自动识别方法;秦伟锋[9]基于层次化处理方法进行了机场跑道及停机坪轮廓自动提取,并综合运用Hough变换、数学形态学等多种图像处理算法,完成了对机场目标的识别;张志龙等[10]提出一种基于内港岸线特征谱的方法识别港口。上述研究取得了较好的进展,但基于低层特征进行目标识别与分类有一定的应用限制,其识别精度也较低,且特征提取过程中由于图像质量、背景复杂程度及提取算法等都会影响识别精度,存在较大的不确定性[11]。
20世纪80年代,Rumelhart等[12]首次提出反向传播算法,为机器学习的发展奠定了良好基础。随后,基于支持向量机(Support Vector Machine, SVM)、Boosting等浅层学习算法的应用取得较好的效果,如Bhattacharya等[13]基于改进的BP神经网络完成道路目标的检测;马洪超等[14]以机场为研究对象,采用改进的BP神经网络作为算法工具识别机场;Lv等[15]提出一种用模糊支持向量机对图像进行分类,再对所有分类的区块构建距离空间,通过在距离空间中设定阈值来定位桥梁。而支持向量机、仅含一层隐层的神经网等一些浅层学习结构的机器学习方法,在有限的样本数量和计算单元对复杂函数的表示存在明显不足,在复杂的分类问题上更难以有效地表现性能和泛化能力[16],且基于反向传播算法的BP神经网络在训练过程中容易出现梯度消失现象,并在增加网络层数后会出现过拟合问题[17]。
近年来,与浅层结构相对应的深度学习进入快速发展阶段,Hinton等[18]提出深层网络训练中梯度消失的解决方案;Yosinski等[19]提出迁移学习方法,结合目前最大的图像识别数据库ImageNet构建深度学习模型框架,有效解决小样本数据训练模型易产生的过拟合问题,且大大缩减模型训练时间;Zhang等[20]基于耦合卷积神经网络的弱监督学习检测机场目标;Cheng等[21]采用高空间分辨率遥感影像VHR(Very High Resolution),结合自动编码器的方法提取出了机场、道路等交通目标;杨淼等[22]基于卷积神经网络对港口进行识别;牛新等[23]采用迁移学习方法在有标签样本稀缺的情况下有效构建深度网络,并利用目标先验知识对潜在目标进行高效提取,可在秒级时间对机场进行识别。大量研究表明基于深度学习在交通设施目标的检测应用中精度较高,检测效果良好,基于深度学习的交通设施目标检测成为研究热点。
从上述研究现状分析中可以看出,目前针对特定交通目标检测与识别的研究取得了一定进展,但如何对机场、桥梁、港口、火车站、停车场等综合交通设施场景进行识别与分类还有待深入研究。在综合交通设施场景中,相同交通设施目标在场景上往往存在较大的差异,同时一些交通设施目标与非交通设施在场景上又存在极大的相似性,且有些不同的交通设施目标在场景上也会出现一定的相似性,这无疑给综合交通设施目标场景的识别与分类带来了较大难度。而综合交通设施场景自动分类与识别对于交通网络的规划与布局、城市的结构优化与发展等具有重要的价值。
鉴于深度学习方法在图像分类识别领域的潜在优势和广泛应用前景,本文采用Caffe框架中的CaffeNet模型进行综合交通设施的分类与识别。CaffeNet模型具有模块化设置,便于扩展新的任务,能高效处理海量数据,同时又具有极高的识别精度等优势。数据集使用遥感图像场景分类的AID(Aerial Image Data)数据集[24],并根据迁移学习的思想,基于ImageNet图像库预训练出的CaffeNet模型进行特征提取,然后将特征输入到SVM分类器进行分类识别。研究结果证明:相较于基于VGG-16、GoogleNet这2种深度学习模型以及典型的基于颜色直方图特征提取、局部二值化特征提取和尺度不变特征提取等方法,基于CaffeNet模型的方法在机场、桥梁、港口、停车场及火车站等目标的分类与识别中,性能最稳定,具有最高的分类精度,对各类交通设施目标的识别率均达到了90%以上,可以有效实现对综合交通设施场景的高精度分类与识别。
1 深度学习CaffeNet模型
深度学习CaffeNet模型是一种卷积神经网络(Convolutional Neural Network)方法,卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的主要方法之一[25]。CaffeNet为卷积神经网络的一个开源框架,具有速度快、模块化、开放性等优点。图像输入CaffeNet模型后经过卷积层、池化层、激活函数、全连接层的处理,获得特征向量,并将结果输出到分类器中进行分类。其中卷积层是对图像的滤波计算过程,卷积运算如公式(1)所示。
g(x,y)=f(x,y)*w(i,j)=

(1)
式中:f(x,y)为图像中x行y列的灰度值;w为卷积核即滤波器。
卷积层是卷积神经网络的重要组成之一,用于提取图像特征。卷积层采用一系列可训练的卷积核对上一层输出数据进行卷积运算,并用一个非线性函数将卷积结果变换到某一个限定范围内,从而使模型具有非线性特征。卷积层计算如式(2)所示。
(2)

通过卷积层获取的特征维数一般较大,易出现过拟合,故使用池化层对输入图像进行降采样处理。池化层对输入特征图像的相邻像素之间进行取平均或求最大值,以降低特征图的分辨率。池化层的计算如式(3)所示。
(3)

CaffeNet模型采用ReLU(Rectified Linear Units)激活函数,能够有效缓解梯度弥散问题,从而直接以监督的方式训练深度神经网络[26]。ReLU的具体形式如式(4)所示。
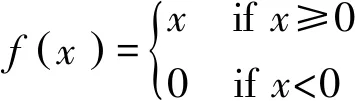
(4)
全连接层一般出现在网络的末端,但并不是必须的,可以是没有或多个。全连接层的每一个神经元都与前一层的所有神经元相连接,它的主要作用是将二维特征图转换成一维向量,便于输出层进行分类。输出层是卷积神经网络最后一层,它的作用是对输入的一维向量进行分类。输出层相当于一个分类器,本文采用SVM分类器。输出层与前一层也是采用全连接形式,输出也是一个一维向量,维数等于分类数目。
2 实验结果分析
实验数据采用AID数据集中的机场、桥梁、停车场、港口、火车站等5类交通设施场景图像,其中机场场景图像360幅,桥梁场景图像360幅、停车场场景图像390幅,港口场景图像380幅,火车站场景图像260幅;同时选取非交通设施场景图像800幅。图像的空间分辨率为0.5~8 m/像元。实验中,采用随机抽样方法,从每类场景图像中选取50%的图像作为训练数据集,另外50%的图像作为测试数据集,图1为图像实验数据示例。
采用的分类方法由CaffeNet深度学习模型与支持向量机(SVM)分类器构成,为解决基于CaffeNet模型用于综合交通设施场景分类识别时需要大量带标签预训练样本的问题,根据迁移学习的思路,采用基于ImageNet图像库预训练的CaffeNet模型,进行综合交通设施场景图像的特征提取,避免了小样本数据训练模型可能产生的过拟合问题,同时缩减了模型训练时间。在CaffeNet模型中,图像经过卷积、池化、局部归一化操作后,以特征图的形式输入全连接层中,然后将全连接后得到的一维特征向量输入至SVM分类器中进行分类。采用的CaffeNet模型结构如图2所示,图中Ci为卷积层,Si为池化层,Relu为激活函数,fc1为全连接层,共5个卷积层,3个池化层,1个全连接层。输入场景图像大小为227像元×227像元,通过上述卷积、池化等操作后,最后全连接为一维4 096单元的特征向量,并将该向量输入SVM分类器中。

图1 综合交通设施场景图像实验数据示例

图2 基于深度学习CafeNet模型方法的特征提取与分类流程图
实验过程中,首先基于CaffeNet模型针对所有综合交通设施场景图像及非交通设施场景图像数据集进行抽象特征提取;并将其中训练数据集的抽象特征输入SVM分类器,对SVM分类器进行训练;然后将测试样本集的抽象特征数据输入训练后的SVM分类器,进行分类。
为验证方法的可重复性和有效性,在分类识别实验中进行反复测试,共完成4 800次实验,每次实验均将样本库中每一类交通设施场景图像的训练样本与测试样本进行随机分配,各占50%。图3为基于CaffeNet深度学习模型针对综合交通设施目标的4 800次实验分类精度折线图。通过4 800次实验,可以看出该算法分类精度稳定在一定范围内,并呈现出围绕某一具体值(图中黑线所指示的值)上下波动的趋势,该中心值的分类精度为93.8%,即为采用CaffeNet网络进行综合交通设施目标分类的平均精度。图4为基于CaffeNet网络深度学习分类算法针对不同类别交通设施场景的识别精度。其中,针对停车场的识别精度最高,为98.5%;机场的识别精度相对最低,为90.6%。通过对分类结果图例进行分析,由于非交通设施中存在许多与机场场景特征近似的图像,导致部分非交通设施场景图像被误判为机场场景。

图3 基于深度学习CaffeNet模型方法的分类精度随实验次数变化曲线

图4 基于深度学习CaffeNet模型方法的综合交通设施场景分类实验结果
同时,在实验中将基于CaffeNet模型的分类方法与基于VGG-16和GoogleNet这2种深度学习模型以及基于颜色直方图特征提取算法(Color Histogram, CH)、局部二值化特征提取算法(Local Binary Patterns, LBP)和尺度不变特征提取算法(Scale-invariant Feature Transform,SIFT)进行了对比研究。其中VGG-16和GoogleNet都是基于卷积神经网络原理的深度学习模型,均由卷积层、池化层、全连接层组成,本研究选用的VGG-16模型包括12个卷积层以及8个全连接层,其基本原理是通过增加网络的层数优化特征提取效果;GoogleNet模型是一种全新的深度学习模型,该模型不仅增加网络层数,还增加了网络中神经元数,从宽度与深度2个方面对网络的尺寸进行提升,进而提升模型的特征提取能力。而SIFT、CH以及LBP这3种特征提取算法基于图像中待识别场景的颜色、纹理、结构等低层特征,是目前常用的典型特征提取算法。本文采用上述方法对图像场景目标进行特征提取,再利用SVM分类器对测试集图像进行分类,并与CaffeNet模型进行对比分析,分类比较结果如表1所示。
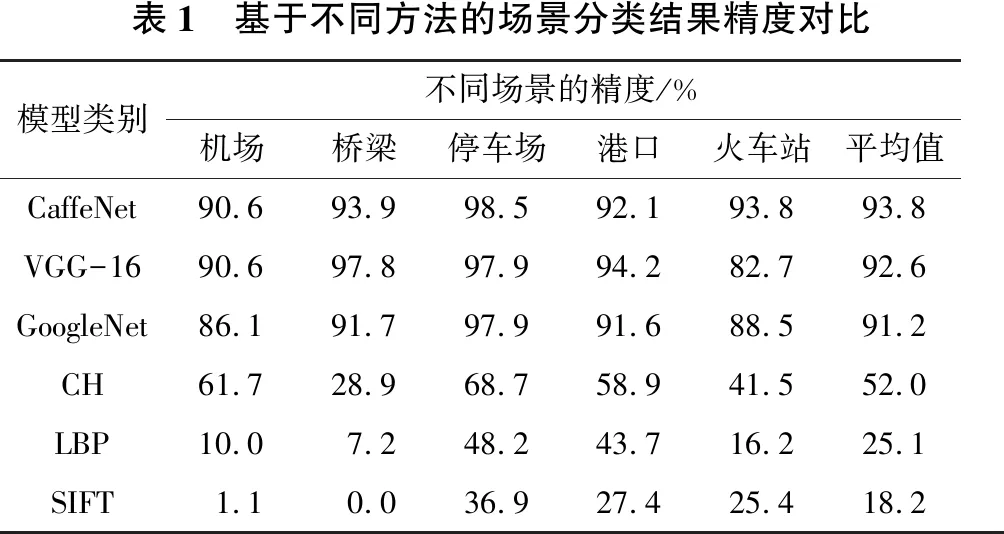
表1 基于不同方法的场景分类结果精度对比模型类别不同场景的精度/%机场桥梁停车场港口火车站平均值CaffeNet90.693.998.592.193.893.8VGG-1690.697.897.994.282.792.6GoogleNet86.191.797.991.688.591.2CH61.728.968.758.941.552.0LBP10.07.248.243.716.225.1SIFT1.10.036.927.425.418.2
由表1可以看出,基于深度学习模型的场景分类具有精度高、结果稳定的优点: 其中VGG-16模型方法的平均分类精度值为92.6%,GoogleNet模型的平均分类精度值为91.2%,CaffeNet模型的分类方法在3类方法中最优,其平均分类精度达到了93.8%,而且针对机场、桥梁、停车场、港口、火车站等交通设施相对都较稳定,识别精度均在90%以上。基于低层特征的CH、LBP、SIFT这3种方法相对于深度学习的方法而言,准确率低且分类精度不稳定。其中,基于CH特征提取的方法相对较好,平均识别精度达到52%,而基于LBP和SIFT特征提取方法的平均分类精度仅为25.1%和18.2%,且SIFT算法基本无法识别机场与桥梁等交通场景设施。
3 结论
利用CaffeNet深度学习模型与支持向量机(SVM)分类器,实现了对综合交通设施场景目标的识别与分类。基于CaffeNet模型,采用AID数据集作为实验数据,通过多层卷积、池化、全连接等过程提取机场、桥梁、停车场、港口、火车站等交通设施场景图像的特征向量,并将提取的特征向量输入SVM分类器实现综合交通设施场景的分类,对上述5类综合交通设施场景的平均分类精度为93.8%,所有交通设施的场景分类结果均在90%以上,其中针对停车场的分类精度最高,达到了98.5%。同时,选取VGG-16与GoogleNet两种深度学习模型以及SIFT、LBP、CH这3种基于低层特征的特征提取算法与基于CaffeNet模型的方法进行对比实验,结果显示基于CaffeNet模型的方法识别精度最高,算法的稳定性最强。基于深度学习CaffeNet模型的综合交通设施场景分类,能够实现机场、桥梁、停车场、港口、火车站等场景图像的较高精度识别,为未来城市规划、交通网络布局以及智慧城市发展提供了一定技术支撑。
