基于弱监督学习面向主题的图文识别方法*
2021-04-26朱命冬刘小杰王鲜芳张建霞
朱命冬,刘小杰,王鲜芳,张建霞
(1.河南工学院 计算机科学与技术学院,河南 新乡 453003;2.新乡市智能工业大数据应用工程技术研究中心,河南 新乡 453003; 3.河南工学院 智能工程学院,河南 新乡 453003)
0 引言
图文识别具有广泛的应用场景,如图像检索、图像标注、实体识别、语义理解、跨模态查询等。面向主题的图文识别可以自动识别图片中针对某一主题的关键信息,例如图书封面中的书名信息、商品图片上的品牌信息和旅游图片中的景点信息等。
面向主题的图文识别与传统的自然场景下文字识别有一定的相似性,都是从图片中识别文本,但它们存在本质上的区别:一方面自然场景下文字识别是识别图片中所有的文字,不考虑文字和主题之间的关系,容易识别出很多与当前主题不相关的文本信息;另一方面,自然场景下文字识别只识别场景中的文本片段,而不考虑这些文本片段之间的关系,很难给出一个具有完整语义的文本表述。由此可见,面向主题的图文识别具有更强的实用性。
实现准确地面向主题的图文识别主要面临两个挑战:首先,针对某一特定的主题,往往缺乏大规模的训练数据集,人工修正的成本较高,训练数据集中容易包含脏数据;其次,只识别出文字片段,不具备独立完整的语义,难以被理解和应用,因此需要识别出文字片段与主题之间的相关性,以及各个文字片段之间的语义语序关系,才能构建具有完整语义的文本。基于上述挑战,本文提出了一种高效的面向主题的图文识别方法 (Subject-oriented Text Recognition based on Weakly supervised learning,STRW),该方法结合区域卷积神经网络(Region Convolutional Neural Network, RCNN)和基于注意力机制的长短记忆模型(Long Short Term Memory,LSTM),通过弱监督学习方法和基于位置信息的全局连接层,实现准确完整地识别图片中的主题文本信息。首先,本文提出一个基于弱监督学习面向主题的图文识别框架,该框架可以有效处理面向特定主题的复杂数据集;其次,该框架整合了基于位置信息的全局连接层,可以有效识别出与主题相关的文本,并对连贯的文本进行连接,生成完整语义;最后,实验环节从网络上采集图书封面数据,并整理出训练集和测试集,通过与现有方法进行对比,验证了所提方法的有效性。
1 相关工作
图文识别从技术角度可以分成文字检测和文字识别两个阶段。传统图文识别方法中两个阶段的模型往往独立构建,但随着深度学习等技术的发展以及可用数据集规模越来越大,端到端同步构建方法被广泛采用[1,2]。端到端同步构建方法可以有效捕捉两个模型之间的内部联系,提高识别的准确率。根据图片中文本的排版方式,相关研究工作可以分为规则化图文识别和非规则化图文识别两类。
规则化图文识别方法主要针对图片中需要识别的文本大小一致并且排版单一的情况。Li等人[3]提出了第一种基于深度学习的端到端规则化图文识别方法,该方法通过两阶段框架和兴趣区(Region of Interest,ROI)池结构来联合检测和识别特征[4]。文献[5]和[6]采用无锚机制以提高训练和推理速度,分别采用文本对齐和ROI旋转作为采样策略,从四边形检测结果中提取文本特征。
非规则化图文识别方法主要针对图片中需要识别的文本排版不统一的情况,如横竖混排和字体大小不一等。为了检测不规则形状的图形文本,文献[7]提出了一个掩文本识别方法,基于掩码区域卷积神经网络并使用字符级监督同时检测和识别字符和实例掩码。该方法显著提高了检测不规则形状文本的性能。文献[8]提出了使用ROI遮罩将注意力集中在不规则形状的文本区域上,但该方法容易受到异常像素的影响,另外,拟合多边形过程还会带来额外的计算代价。可见,图文识别相关研究是当前的研究热点并取得了一定的研究成果,但对训练数据规模存在较高的依赖,同时主要集中于文字形式上的识别而忽略了文本的语义信息。
2 基于弱监督学习面向主题的图文识别方法
图1是STRW的框架图。该方法主要由四个模块组成,分别是区域生成网络(Region Proposal Networks,RPN)模块、ROI对齐模块、卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)文本识别模块和基于位置的序列生成模块。下面分别对各个模块进行详细介绍。

图1 STRW方法架构图
RPN模块主要用于生成候选文本区域。该模块采用基于ResNet50[9]的特征金字塔网络, 该网络采用自上而下的网络结构构建单张图片不同尺寸的具有高级语义信息的特征图,可以有效提高识别准确率。RPN模块采用锚点的方法。为了有效处理不同大小和不同长宽的词条,分别设置区域分辨率为162、322、 642、1282、和2562, 并且每个阶段都使用了0.2、0.5、1、2和4五个长宽比。
ROI对齐模块可抽取出文本建议框的区域特征。传统的兴趣区池方法也可以完成这个操作,但是由于其计算过程取整,易造成特征粗糙,故对小目标的检测效果不好。为解决避免这种情况,本框架采用ROI对齐方法。ROI对齐模块除了需要使用ROI对齐进行文本建议区域筛选以外,还需要使用快速区域卷积神经网络进行区域文本分类和区域位置回归。
CRNN文本识别模块主要识别文本区域中的文本内容。采用CRNN模型[10],主要包括三层结构:(1)卷积层,作用是从输入图像中提取特征向量;(2)循环层,作用是预测从卷积层获取的特征序列的标签分布;(3)转录层,作用是把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果;基于联接时间分类代价[10]计算损失函数,如公式(1)所示:
L(S)=-lnΠ(x,z)sp(z|x)=-Σ(x,z)sln(ΣπF-1(z)p(π|x)
(1)
式中,S为训练集,x为输入,z为输出,F代表一种多对一的映射,将输出路径映射到标签序列l,p(π|x)代表给定输入为x、输出路径为π的概率。
基于位置的序列生成模块的主要功能是筛选出符合主题的文本内容并对文本内容进行整合,形成完整表达。该模块通过位置信息和文本框内容特征进行序列生成训练,该模块是STRW方法的核心模块。
图文识别如果只能识别出图片中各个区域的文字,这些文字无法组织成一个完整的语义,识别结果的可用性就会受到严重影响。而基于位置的序列生成模块可以对各个文本框的内容进行整合排序,形成一个面向主题的具有完整语义的文本。如图2所示,该模块主要由三层结构组成,第一层是融合位置信息的文本嵌入表示层,第二层是双层的LSTM结构,第三层是序列分类预测层。

图2 基于位置的序列生成模块结构
融合位置信息的文本嵌入表示主要包含两部分内容,一部分是识别文本的嵌入表示,记为ET,ET可以通过语义嵌入方法获得。另一部分是位置嵌入表示,记为EP。EP={Hs,Ws,He,We},Hs=onehot(|H1|*H,H),Ws=onehot(|W1|*W,W) ,He=onehot(|H2|*H,H),We=onehot(|W2|*W,W),其中onehot(x,X)表示维度为X的向量,该向量对应索引位置的值为1,其他为0。H和W分别为定义的对应高和宽的维度常量。H1、W1、H2、W2为对应文本框的归一化后的左上角和右下角的坐标位置。EP中同时包含了位置和大小两种信息。通过连接操作生成对应文本框i的嵌入表示Xi如公式2所示:
Xi=Concat(ETi,EPi),
(2)
式中,i表示第i个文本框。
双层的LSTM结构可以结合整体文本内容的语义进行当前文本框的序列预测。如图2所示,双层LSTM结构由两排逆序的LSTM单元连接组成。LSTM单元的计算方法如公式(3)—(6)所示:
(3)
ct=ft⊙ct-1+itgt
(4)
ht=ot⊙tanh(ct)
(5)
yt=softmax(ht)
(6)
式中,it、ft、ot、gt、ct和ht分别是LSTM单元t的输入状态、遗忘状态、输出状态、中间状态、记忆和隐含状态,yt是序列预测输出。
序列分类预测层根据LSTM单元的输出ht计算出对应文本框的序列,预测整数区间是[0,L],L是设定的最长序列,0表示该文本内容和主题不相关。最后,通过多项逻辑斯特回归函数进行分类计算得出该文本的序列。
3 实验
为了验证所提方法的有效性,本节将STRW与当前主流方法TextSpotter[9]和PP-OCR[11]进行对比。数据集是从电商平台网站上采集的图书封面数据集,主题是图书名称。数据集的规模是23,000张图片,具体包括生物类图书封面4000张,文学类图书封面2000张,经济类图书封面4000张,语言类图书封面3000张,数学类图书封面4000张,哲学类图书封面2000张,程序类图书封面4000张。图片的分辨率是200*200。模型实现主要分两个阶段:第一个阶段为初始化阶段,模型初始化采用预训练模型的参数;第二个阶段是微调训练阶段。训练集、验证集和测试集规模采样比例是3:1:1。
实验环境采用基于TitanXP显卡的工作站,CPU i5-10400, 内存64GB,硬盘512GB SSD, 操作系统是Ubuntu16.04。
3.1 准确度
首先验证方法的准确度,不同类别的图书封面展示书名的特点不一样,图3给出了STRW方法处理不同类别图书的识别准确度,可以看出综合准确度达到80%。不同类的准确度有一定的差别,这一方面和该类别的数据量有关系,往往训练数据越大参数相对就越准确;另一方面和该类别的数据质量有关,例如语言类和数学类中考试辅导用图书较多,采集图片中营销广告信息对准确识别造成了一定的干扰。图4给出了三种方法综合准确度的比较,可以看出, STRW方法综合准确度最高。

图3 分类准确度

图4 综合准确度对比
3.2 系统性能
系统性能实验主要验证STRW方法的训练收敛性和识别推测的效率。图5是STRW方法在迭代训练过程中模型准确度变化图,可以看出,由于采用了预训练模型和迁移方法,210次迭代后基本实现收敛,为了防止过拟合我们采用准确度80%时的训练参数。图6是STRW方法在推测时间方面和其他方法的对比,可以看出STRW方法平均用时最少,具有较好的推测效率。
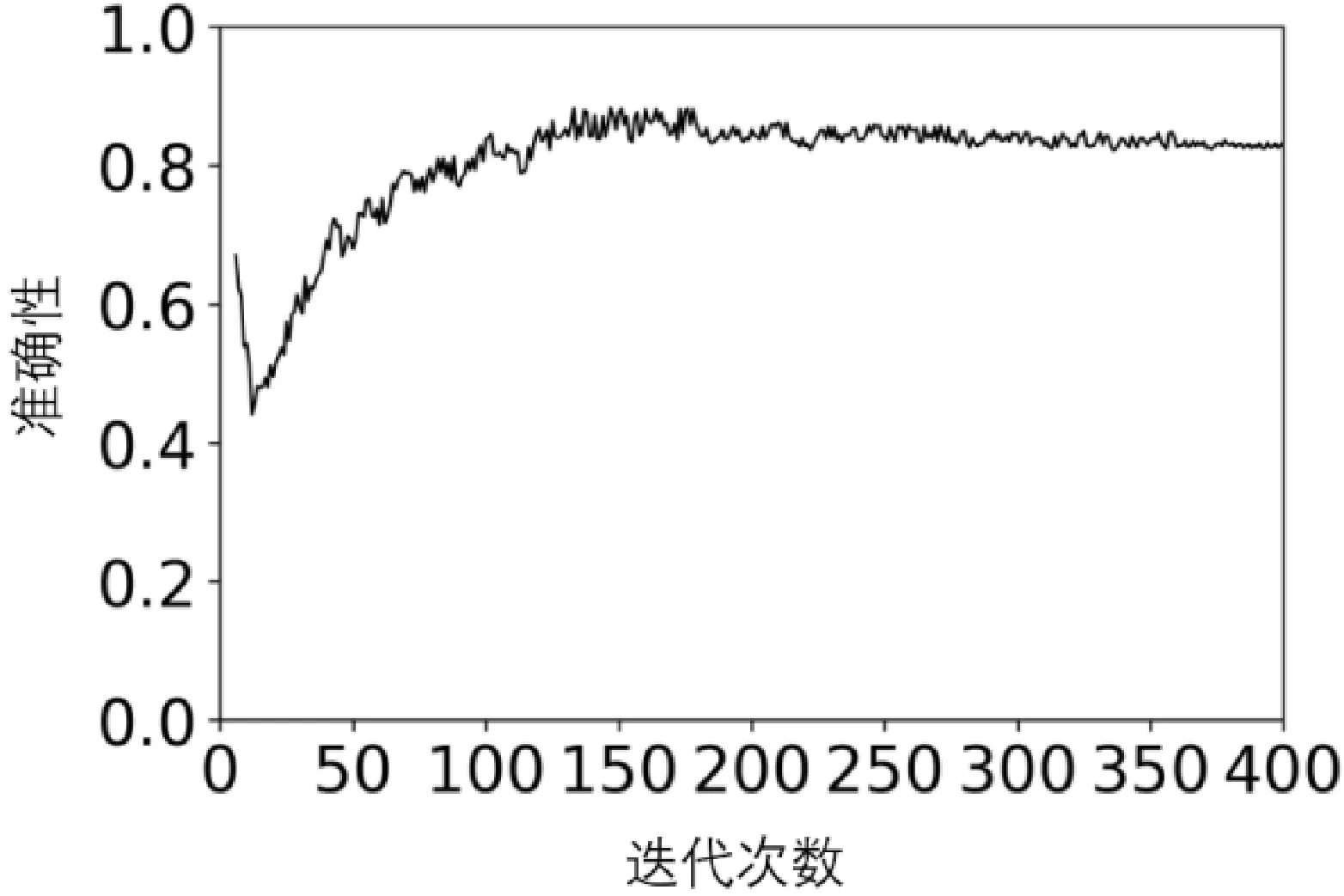
图5 STRW方法训练收敛性

图6 识别推测的时间对比
图7给出了STRW方法的部分识别样例,图书名称被识别成多个文本块的连接,文本块前的序号是该文本块在整个题目中的序列。图片中方框标注出了文本块的位置。

图7 部分图书名识别样例
4 结论
现有的面向主题图文识别方法在面对数据集较少且易含有噪音数据时,准确度无法保证,针对这个问题,提出了一种基于弱监督学习面向主题的图文识别方法——STRW,该方法结合RCNN和基于注意力机制的LSTM,通过弱监督学习方法和基于位置信息的全局连接层,能够准确识别图片中的主题文本信息。实验结果表明,所提方法可以有效解决面向主题的图文识别问题。
