面向类不平衡网络流量的特征选择算法
2021-04-25姚立霜王云锋裴作飞
唐 宏 刘 丹* 姚立霜 王云锋 裴作飞
①(重庆邮电大学通信与信息工程学院 重庆 400065)
②(移动通信技术重庆市重点实验室 重庆 400065)
1 引言
网络流量分类技术广泛应用于网络管理和网络安全领域[1]。基于端口号的流量分类方法[2,3]在开放端口、伪装端口号等技术出现之后,分类准确率大大降低。基于特征字段的流量分类方法摆脱了对端口号的依赖,可以取得较高的分类准确率,但该方法只能对明文传输的数据包进行解析,难以适用于加密流量的分类[4-6]。基于传输层主机行为的流量分类方法不依赖于端口号,也不需要解析报文,但该方法对外界环境异常敏感,多变的网络环境可能导致分类效果不够稳定。因此,基于机器学习的网络流量分类方法得到了研究人员的青睐[1,7]。
数据预处理是基于机器学习的网络流量分类过程中的重要步骤,该过程通常采用特征选择算法对特征进行降维。Moore等人[8]使用快速相关滤波器去除冗余和无关的特征。Dai等人[9]利用卡方和C4.5算法进行特征选择。Xu等人[10]将二进制萤火虫算法与反向学习相结合进行特征选择。张震等人[11]通过定义基于信息熵的“用户行为模式”来分析各个行为子簇背后表现出的业务特征,能有效降低算法的计算复杂度。Shafiq等人[12]提出了一种基于机器学习的混合特征选择算法,该算法利用了加权互信息度量和受试者工作特征曲线(Receiver Operating Characteristic, ROC)下面积两个指标,使用该算法选择出的特征能够表现出很好的性能。Shi等人[13]提出了一种新的基于深度学习和特征选择技术的特征优化方法,为流量分类提供具有强区分能力的特征。Wang等人[14]提出一种基于多重过滤权重和多重特征权重的混合特征选择方法,能有效提高分类精度。王勇等人[15]在特征提取过程中引入卷积神经网络,可以在避免复杂显式特征提取的同时达到提高分类精度的效果。Ren等人[16]使用深层神经网络挑选数据的固有特征,利用树结构的递归神经网络处理大规模流量分类问题,可以在更少的训练时间内获得更高的性能。
现有的特征选择算法多数情况下选择出来的特征在多数类(大类)上表现良好,分类器对少数类(小类)的预测精度却很低,这就是类不平衡导致的问题。然而,在现实生活中,人们通常更关注小类的分类效果,错误地识别小类所带来的后果往往很严重。如在入侵检测中[17-19],攻击类相对于正常流量就属于小类,错分攻击类可能会引起网络的瘫痪。
为了减轻类不平衡问题带来的不良影响,本文提出一种基于加权对称不确定性(Weighted Symmetric Uncertainty, WSU)和近似马尔科夫毯(Approximate Markov Blanket, AMB)的网络流量特征选择算法。该算法首先根据类别分布信息定义偏向于小类别的度量,使得识别小类别的特征更容易被选择出来,并基于加权信息熵计算特征与类别间的加权对称不确定性,利用特征排序算法删除不相关特征;然后,充分考虑特征与类别间、特征与特征间的相关性,利用近似马尔科夫毯条件删除冗余特征;最后,根据特征评估准则函数和序列搜索算法从候选特征集合中选出满足合适维数的特征子集。
2 特征选择
特征选择的流程图如图1所示,它主要包含4个基本环节:生成特征子集(搜索策略),评价准则,停止准则和结果验证[20]。在原始特征集上运用搜索策略得到生成子集,利用评价准则对第1步选择出来的子集进行评估,最后根据停止准则结束搜索,并选择出来的最优特征子集进行检验,判断所选特征子集是否满足标准。
3 基于WSU_AMB的特征选择算法
基于加权对称不确定性和近似马尔科夫毯(WSU_AMB)的网络流量特征选择算法主要包含两个步骤。第1步,根据类别分布信息定义偏向于小类别的权值,基于加权信息熵计算出特征与类别间的加权对称不确定性,利用特征排序算法删除不相关特征,这一步可以过滤掉大多数特征;计算特征与特征之间的加权对称不确定性,利用近似马尔科夫毯删除冗余特征,确定候选特征集合。第2步,计算特征准则评估函数值,利用序列搜索算法选择出满足合适维度的特征子集。WSU_AMB算法的总体框架如图2所示。
3.1 加权对称不确定性
加权对称不确定性可以用来衡量特征与类别以及特征与特征之间的相关性,它是在加权信息熵的基础上计算出来的[21]。加权对称不确定性可由式(1)进行计算

其中

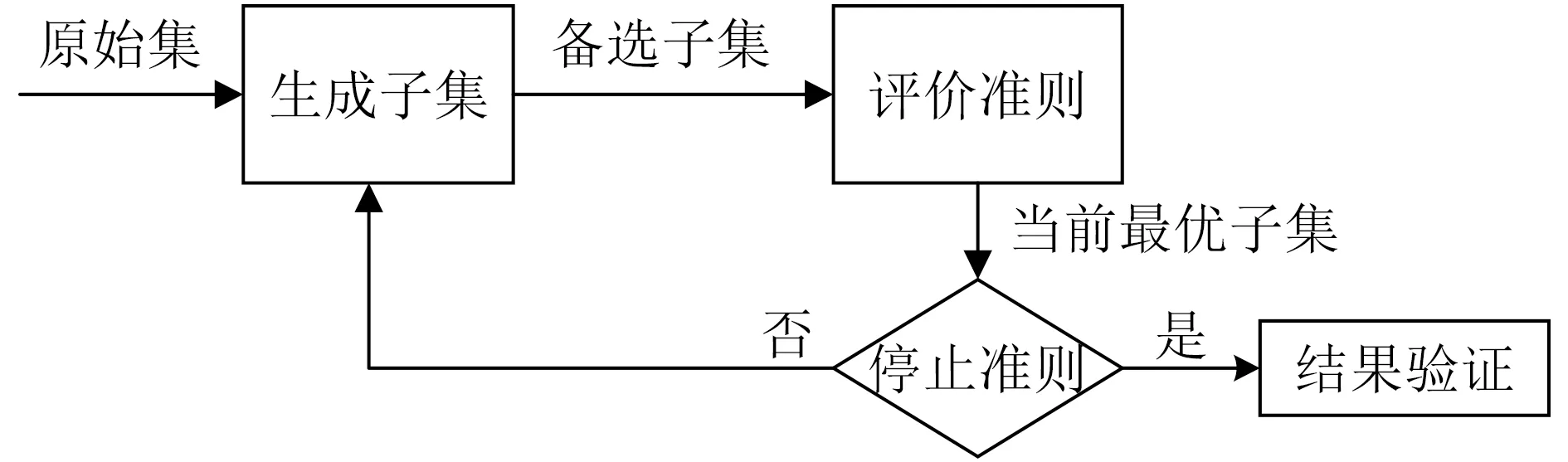
图1 特征选择流程图

图2 WSU_AMB特征选择算法的总体框架

wi表 示权值,p (ci,fj)表示类别C与特征F的联合概率, p(ci) 表示类别C的先验概率,p (fj)表示特征F的先验概率, p (ci|fj)表示F发生的条件下C的后验概率, ni表示属于类别ci的样本数,N表示样本总量。
通过加权对称不确定性,可对相关特征进行定义,具体表述为:计算每个特征与类别之间的加权对称不确定性W SU(fi,C),对该值进行降序排列,排在最前面、值越大所对应的特征与类别的相关性越 强。
3.2 近似马尔科夫毯
通常对特征与特征之间的相关性进行分析来判定某一特征是否冗余。根据马尔科夫毯思想可以形式化地给出冗余特征的定义,但是马尔科夫毯的条件过于严格,现实数据难以达到要求,需要对该条件进行近似假设[22],基于此,本节提出了近似马尔科夫毯来删除冗余特征。
所谓马尔科夫毯,需满足以下条件。假设属性类别为C,特征集合为F,对于给定的特征fi⊂F和特征子集M ⊂F(fi∈/M),若有

则称能满足上述条件的特征子集M为fi的马尔科夫毯。其中,符号“⊥”表示独立,“|M”表示在给定M的条件下。
假设属性类别为C,特征集合为F,特征 fi为冗余特征的充要条件为当且仅当存在特征子集M为fi的马尔科夫毯,其中,fi⊂F , M ⊂F(fi∈/M)。在特征集合F中,由于在特征 fi的马尔科夫毯M条件下,fi与其他非马尔科夫毯变量独立,因此,对于特征 fi而言,所有非马尔科夫毯变量都是冗余的。
特征 fi是特征fj的 近似马尔科夫毯( i/=j),需要满足式(8)的条件
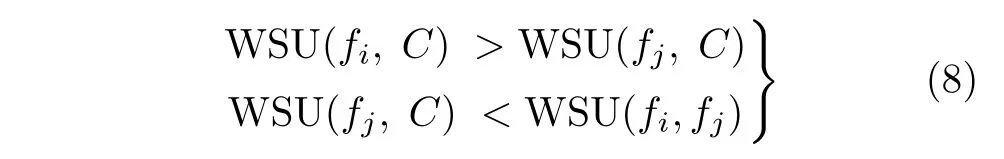
特征与类别之间的WSU可由式(5)得到,特征与特征之间的WSU的计算方法略有差别,此时需要 将其中一个特征看成类别属性。
3.3 相关性特征度量
在充分考虑特征的相关性的前提下,有效减少特征维数,提出一种特征准则评估函数


3.4 算法流程描述
WSU_AMB算法的实现过程如表1所示。第1阶段((1)~(9)行)利用加权对称不确定性和近似马尔科夫毯条件删除不相关特征和冗余特征,得到候选特征集合;第2阶段((10)~(20)行)利用特征评估准则函数和序列搜索算法找到最优特征子集。
4 实验验证
4.1 实验数据集
本实验使用Moore数据集[23]来验证算法的性能,表2展示了该数据集的统计信息。
4.2 性能评价指标
本实验采用整体精确率(accuracy),小类别的准确率(precision)、召回率(recall)和F1值作为算法的性能评价指标。整体精确率可以反映多分类模型的综合预测能力,准确率、召回率和F1值可以反映分类模型对单个应用的预测能力。
4.3 实验方案
利用Moore数据集的10个数据子集(DataSet1,DataSet2, ···, DataSet10)进行训练和预测,每个子集中训练集的比例为70%。选用C4.5决策树作为分类器进行所提算法的最优参数选择。
在对网络流量进行分类时,一般4~8个特征就能得到较好的分类效果。本文对10个数据子集进行实验,可以发现相似的变化趋势,只选取2个数据子集进行展示,如图3,经验证,选取特征数L=6。
阈值δ的设置对算法的性能有重要影响。因为δ值越高,筛选特征的速度越快,但会遗漏某些重要特征,降低分类系统的性能;δ值越低,会把训练样本自身的某些特点当成共性来学习,会导致分类器泛化性能下降,出现“过拟合”的现象。同样地,利用10个数据子集进行阈值选择实验,分类器的整体精确率变化趋势相似,如图4所示,本文选取了2个数据子集进行实验展示。通过实验验证,选取阈值δ=0.55。

表1 基于WSU_AMB的特征选择算法
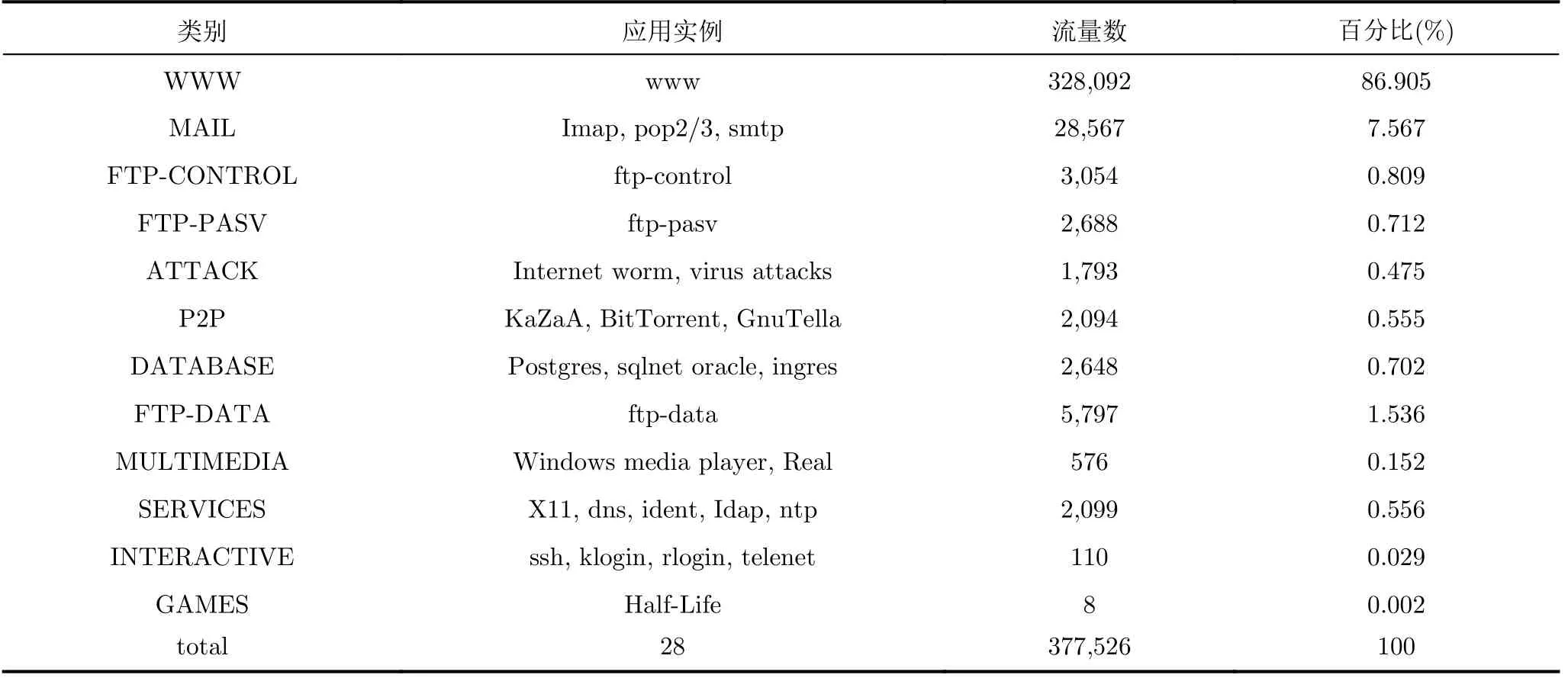
表2 Moore数据集的统计信息

图3 特征子集数目L对算法的影响

图4 阈值δ对算法的影响
在实验过程中,利用4种分类器:朴素贝叶斯(Naive Bayes, NB)、逻辑斯蒂回归模型(Logistic Regression, LR)、K近邻算法(K-Nearest Neighbour,KNN)和C4.5决策树(Decision Tree, DT),将未进行特征选择的数据集(fullset)、基于相关的快速过滤器(Fast Correlation-Based Filter, FCBF)[8]、卡方决策树算法(Chi-Square and Decision Tree,CSDT)[9]、高效的特征优化方法(Efficient Feature Optimization Approach, EFOA)[13]以及基于多重过滤权重和多重特征权重的混合特征选择方法(Hybrid Feature Selection based on Multi-Filter weights and Multi-Feature weights, MFHFS)[14]与所提算法(WSU_AMB)进行对比。
4.4 实验结果与分析
4.4.1 所选特征集合
选用C4.5决策树作为分类器,在不同的数据子集下,FCBF, CSDT, EFOA, MFHFS和WSU_AMB算法选择出来的特征数目如表3所示。选出的特征子集规模显示,总体上WSU_AMB算法所选特征数较少,CSDT算法所选的特征数较多,其他3种算法的降维能力相当。WSU_AMB算法的停止准则是基于搜索策略设定的,一旦所选特征达到指定个数即停止搜索,所以在不同的数据子集上,WSU_AMB算法选择的特征个数都相同。而其他4种算法的停止准则是基于评价准则设定的,需要在评价价值达到最高时才停止搜索,故每个数据子集所选特征个数会有所不同。
4.4.2 算法复杂度对比
表4对各算法的时间复杂度进行了定性分析,其中,N为特征总数,M为数据集的实例数目,L为候选特征集合中的特征数量,D为隐层数,t为当前所在的层,Nt为 该层的特征数,Ct为该层的类别数,K为选择的特征数。

表3 不同特征选择方法所选特征数目

表4 不同特征选择方法的时间复杂度分析
为了进一步对算法的复杂度进行定量分析,利用Moore数据集的10个特征子集对各算法的特征选择时间进行统计,如图5所示。从图5中可看出算法运行时间与算法复杂度的定性分析基本保持一致,WSU_AMB算法的特征选择时间少于EFOA算法,MFHFS算法的特征选择时间最短;因DataSet7~DataSet10的数据量较大,是前6个数据子集的2倍多,故EFOA算法的特征选择时间出现了明显的增长。
同时,选用C4.5决策树作为分类器,对各算法的分类时间进行了测试,如表5所示。很明显,使用基于CSDT算法和EFOA算法选择出来的特征进行C4.5分类器的训练,分类时间较长,而C4.5使用WSU_AMB算法选择出来的特征进行分类时,分类速度优于FCBF算法和MFHFS算法。虽然WSU_AMB算法在特征选择阶段的运行时间较长,但经过特征选择之后所选特征的特征值数目较小、数量较少,减少了分类过程中的计算开销,缩短了系统在分类阶段的耗时,提升了系统的分类效率。
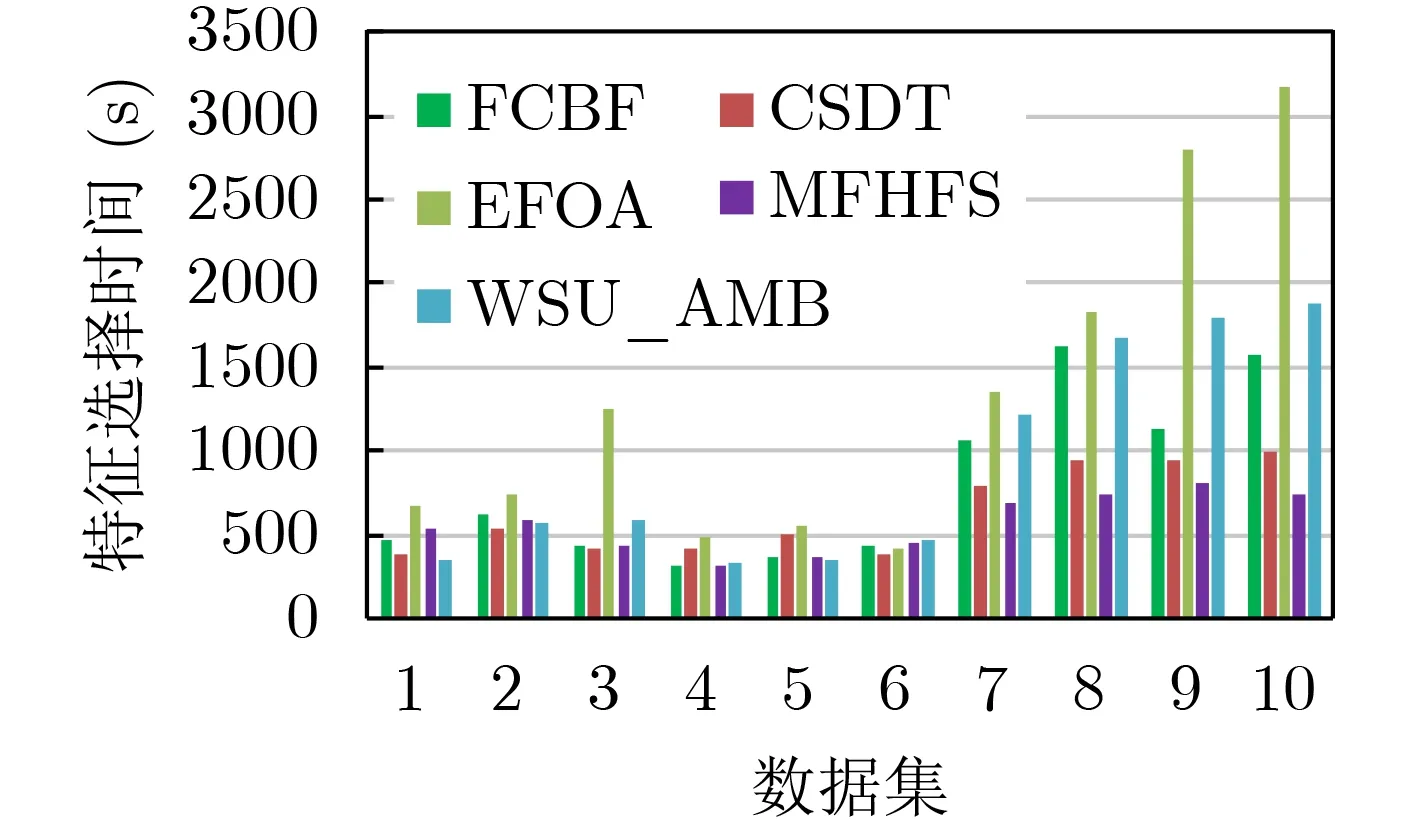
图5 不同算法在各数据集上的特征选择时间对比
4.4.3 分类性能对比
(1) 整体分类精确率。按照4.3节的实验方案进行实验,可以得到各特征选择算法在不同数据子集上的整体精确率。如图6所示,当NB, LR, 6NN和DT作为分类器时,WSU_AMB算法的平均整体精确率均高于对比算法。使用6NN作为分类器时,各特征选择算法的分类性能更加稳定,当使用DT分类器时,5种特征选择算法均能取得较高的整体分类准确率。

表5 分类时间的比较(ms)
(2) 小类准确率。选择ATTACK类和FTPPASV类对5种特征选择方法在小类别上的性能进行分析。图7为基于不同数据子集,5种特征选择算法在DT分类器上的小类准确率对比。相比FTPPASV类,ATTACK类在各个数据子集上的波动比较大。因为ATTACK类属于攻击类型,它通常会模仿其他流量的特征来躲避网络监测系统,故ATTACK类的分类结果呈现不稳定的特性。相比于其他4种对比算法,WSU_AMB算法对ATTACK类和FTP-PASV类的准确率提升明显,MFHFS算法的小类准确率性能仅次于WSU_AMB算法。

图6 不同数据子集下各特征选择算法在4种分类器上的整体精确率对比
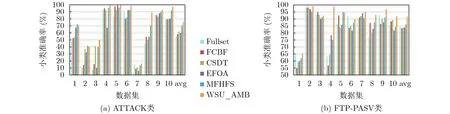
图7 各特征选择算法的小类准确率对比
(3) 小类召回率。由于网络流量中的WWW类占绝大多数,所以在训练分类器时,往往对WWW类有利,容易把其他类别错分为WWW类,降低小类别的分类性能。而WSU_AMB算法为小类别选择出强相关性的特征,能够有效减少小类别被错分为WWW类的数量,提高小类别的召回率。图8为使用DT分类器,5种算法在各个子集上的小类召回率,可以看出,WSU_AMB算法的小类召回率好于对比算法。
(4) 小类F1值。图9为基于不同数据子集,5种特征选择算法在DT分类器上的小类F1值对比。WSU_AMB算法在对每个特征进行度量时,识别小类别的特征权重更大;在对特征进行选择时,保证所选的特征具有较强的区分能力,即特征与类别之间高度相关,特征之间彼此不相关。因此,WSU_AMB算法的小类平均F1值能够高于其他4种方法。

图8 各特征选择算法的小类召回率对比
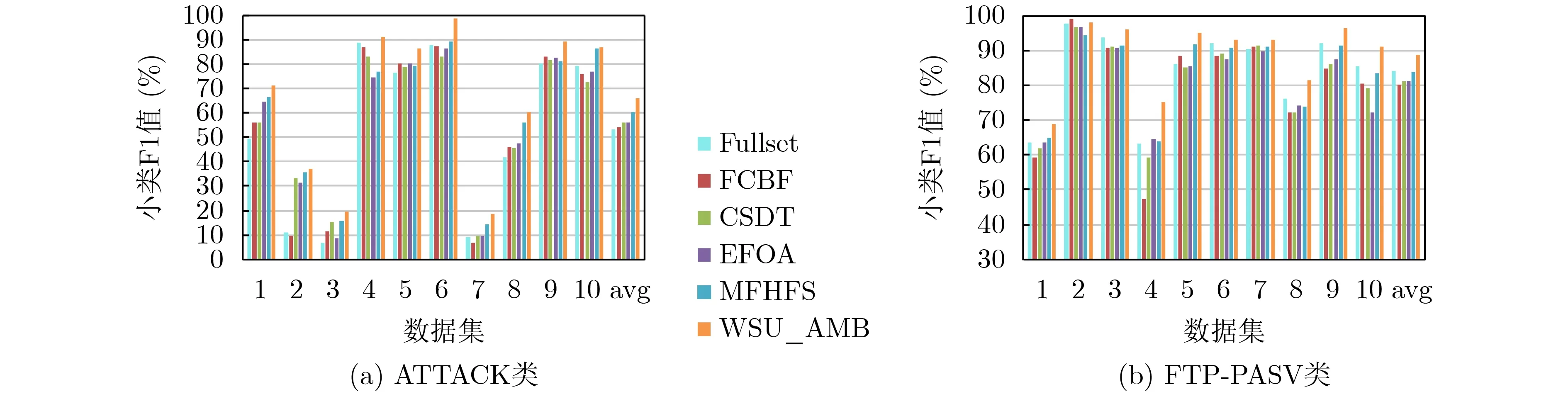
图9 各特征选择算法的小类F1值对比
5 结束语
针对网络流量分类技术存在的类不平衡问题,本文提出一种基于加权对称不确性和近似马尔科夫毯的特征选择算法。充分考虑特征的相关性,利用偏向于小类别的加权对称不确性和特征排序算法来滤除不相关特征,通过近似马尔科夫毯条件删除冗余特征;再根据特征评估准则函数和序列搜索算法进一步降低特征维数。实验表明,服务器的端口号和初始窗口中发送的字节总数是识别网络流量的两个重要特征,所提算法能够在不牺牲分类器整体精确率的前提下,有效提高小类别的准确率、召回率和F1值。进一步研究工作主要在以下几个方面:(1)减小数据漂移现象的影响;(2)有效降低算法在搜索最优特征子集时的时间消耗;(3)新应用的识别与分类。
