基于MIV的NRDBA-BP参考作物腾发量预测
2021-04-25任亚飞邵馨叶邵建龙
任亚飞, 田 帅, 邵馨叶,2, 邵建龙*
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.云南电网有限责任公司 信息中心,云南 昆明 650200)
参考作物腾发量(ET0)是计算蒸散量和估算作物实际需水量的重要参数,在灌溉制度的选择、作物种植结构优化、田间水分平衡理论等方面有着广泛的应用。ET0的计算受到多个气象参数的影响,包括温度、相对湿度、风速、日照时长、气压和太阳辐射量等,因此很难建立一个简单的方程来获得不同气候条件下的准确估计值[1-3]。目前基于气候变量估算ET0的方法大致可以分为三类:辐射法、温度法和合成法[4]。但是上述方法无法完全体现出ET0计算过程中非线性、动态性和高度复杂性的特点,导致其计算结果在不同区域存在截然不同的精度,适用性较差。1998年由联合国粮农组织提出的经典Peman-Monteith公式被普遍认为是目前计算ET0的唯一精确方法[5]。然而,PM模型需要大量的气象数据作为输入,计算过程涉及到这些因素之间复杂的非线性计算。因此,为了使其更加方便的应用于农业生产指导中,有必要需要寻找一个更加简单、精确的模型来计算ET0。
近年来,随着神经网络理论的迅速发展,基于此的BP神经网络模型在ET0预测中得到了广泛的应用。柳烨等[6]建立了基于温湿度的ET0估算模型,通过对陕西省6个站点的数据进行分析,证明该模型不仅能得到较为精确的预测结果且具有更强的鲁棒性;余江斌等[7]利用天气预报的可测因子建立了BP-ET0预测模型,发现其预测值与PM公式的计算值相接近,且操作简单。这些都证明了BP神经网络在灌溉量预测上的应用是可行和有效的[7]。但BP神经网络也存在一些缺点,如网络结构难以确定、易陷入局部极小值、收敛速度慢等[8]。针对这些局限性问题,已有学者提出了一些改进措施以改善BP神经网络的不足,如人工蜂群算法(ABC)、遗传算法(GA)、混合PSO-BP等群智能优化算法被用于优化BP神经网络以提高其性能[9-11]。但是这些算法仍无法克服局部极小值的问题。为此,本文提出了一种新的结合平均影响值算法(MIV)和改进的非线性随机递减蝙蝠算法(Nonlinear Random Decreasing Bat Algorithm,NRDBA)的反向传播算法(NRDBA-BP),首先采用MIV算法和SPSS软件对输入变量进行筛选,以优化BP神经网络的结构,降低计算量。同时利用改进的蝙蝠算法对BP神经网络的初始阈值和权值进行优化,以提高BP神经网络的收敛速度和预测精度。
1 NRDBA-BP混合算法
1.1 BP神经网络原理
BP神经网络是采用误差反向传播算法训练的多层前馈网络。该方法的训练速度快,非线性拟合能力强,是目前最流行和应用最为广泛的一种方法。大量研究表明,单隐含层的BP神经网络模型即可逼近任意精度的连续函数。BP神经网络的经典结构如图1所示,由3层组成:输入层、隐含层和输出层。在BP神经网络模型中,信号的前向传播和误差的反向传播交替执行,通过梯度下降算法来使误差函数逐渐减小[12]。一旦确立了目标误差和训练参数,网络模型就可以通过连续校正各层之间的权重和阈值来逼近任意精度的非线性连续函数。误差函数为
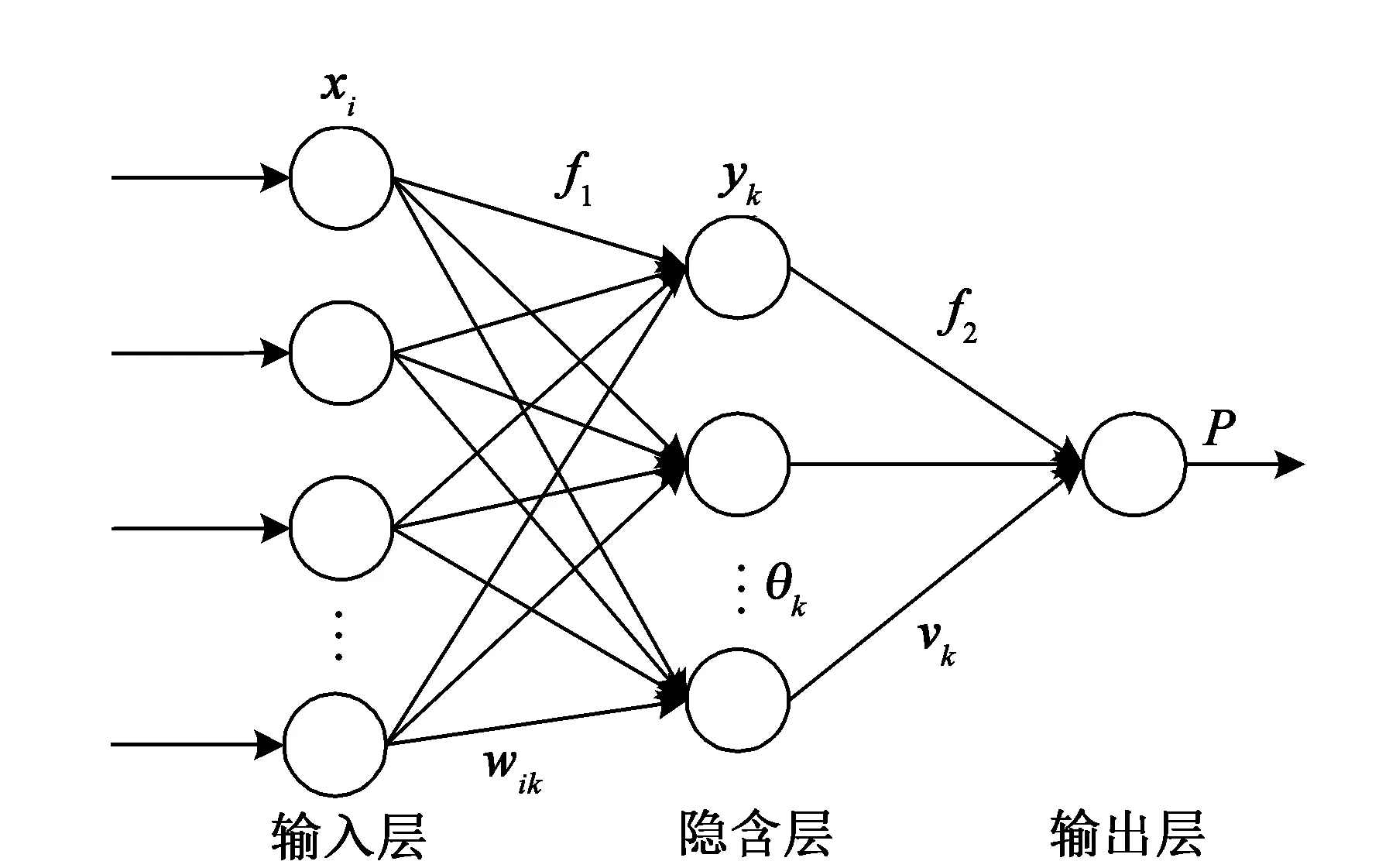
图1 神经网络经典结构模型
(1)
其中Pn是该神经网络模型的计算输出,On是期望的输出,N是训练数据集的个数。
1.2 蝙蝠算法
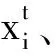
fi=fmin+(fmax-fmin)·β,
(2)
(3)
(4)
式中β是随机数且β∈[0,1],x*是全局最佳位置,fmax、fmin是频率的最大、最小值,t为迭代次数。
此外蝙蝠还采用另一种随机移动策略以更好地对搜索空间进行探索。算法每次迭代的过程中随机生成一个数λ,若λ>ri,则根据式(5)更新位置,否则随机产生一个新的位置[14]:
(5)
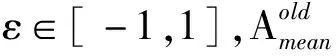
(6)
(7)
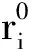
1.3 改进的蝙蝠算法(NRDBA)
文献[13]已经证明BA算法优于其他基于进化的群智能算法,如粒子群算法(PSO)、遗传算法(GA)等。本文为了进一步提高该算法的全局搜索和局部搜索能力,提出了一种新的改进算法,将粒子群算法中惯性权重的思想引入到速度更新公式中。
通过对蝙蝠算法基本原理的分析,发现算法中蝙蝠的位置受到蝙蝠移动速度的影响,同时蝙蝠当前速度又受上一代移动速度的影响。根据蝙蝠算法的基本公式可知,上一代蝙蝠的移动速度前的系数始终为1,这将不利于算法前期对搜索空间的快速搜索和算法后期的局部精细搜索[15]。为此,本文借鉴粒子群算法的思想,将非惯性权重引入到速度更新公式中,同时为了避免算法后期陷入局部极值,在非线性递减的基础上引入随机因子,使得每一代蝙蝠的个体速度具有一定的随机性,在算法前期使种群快速地分布在整个搜索空间,在后期陷入局部极值时,随机的速度增加了其跳出局部极值的机会。具体表达式如下:
w=wmax-(0.7+0.3·rand())·(wmax-wmin)·
(8)
式中wmax=0.9和wmin=0.4为惯性权重w的最大和最小值,rand()为在[0,1]上服从均匀分布的随机数,t和tmax分别为算法的当前运行次数和最大运行次数,betarnd()为服从beta分布的随机数[16],k∈[0.1,0.9]为惯性偏离因子,本文取0.8。
此时,惯性权重w在算法的前期数值较大,蝙蝠的飞行速度也大,此时蝙蝠具有出色的全局探测能力,可以快速地找到局部最优解;相反当后期w较小时,蝙蝠的局部搜索能力大大增强,可以在局部最优解的附近进行精细搜索[17]。同时,随机因子的引入使得算法后期w也可能得到一个相对大的值,从而增加算法跳出局部最小值的概率,而且使得蝙蝠种群的速度在每代和每一代的个体之间都具有随机性,增加了种群的多样性,可以加快蝙蝠算法的收敛速度,进一步避免算法后期陷入局部极值[18]。此时,速度更新公式为
(9)
1.4 NRDBA-BP神经网络模型
为了得到更加精确的ET0预测值,本文采用NRDBA算法对BP神经网络的初始参数进行优化,整个模型的算法实现流程如图2所示。具体实现步骤如下:
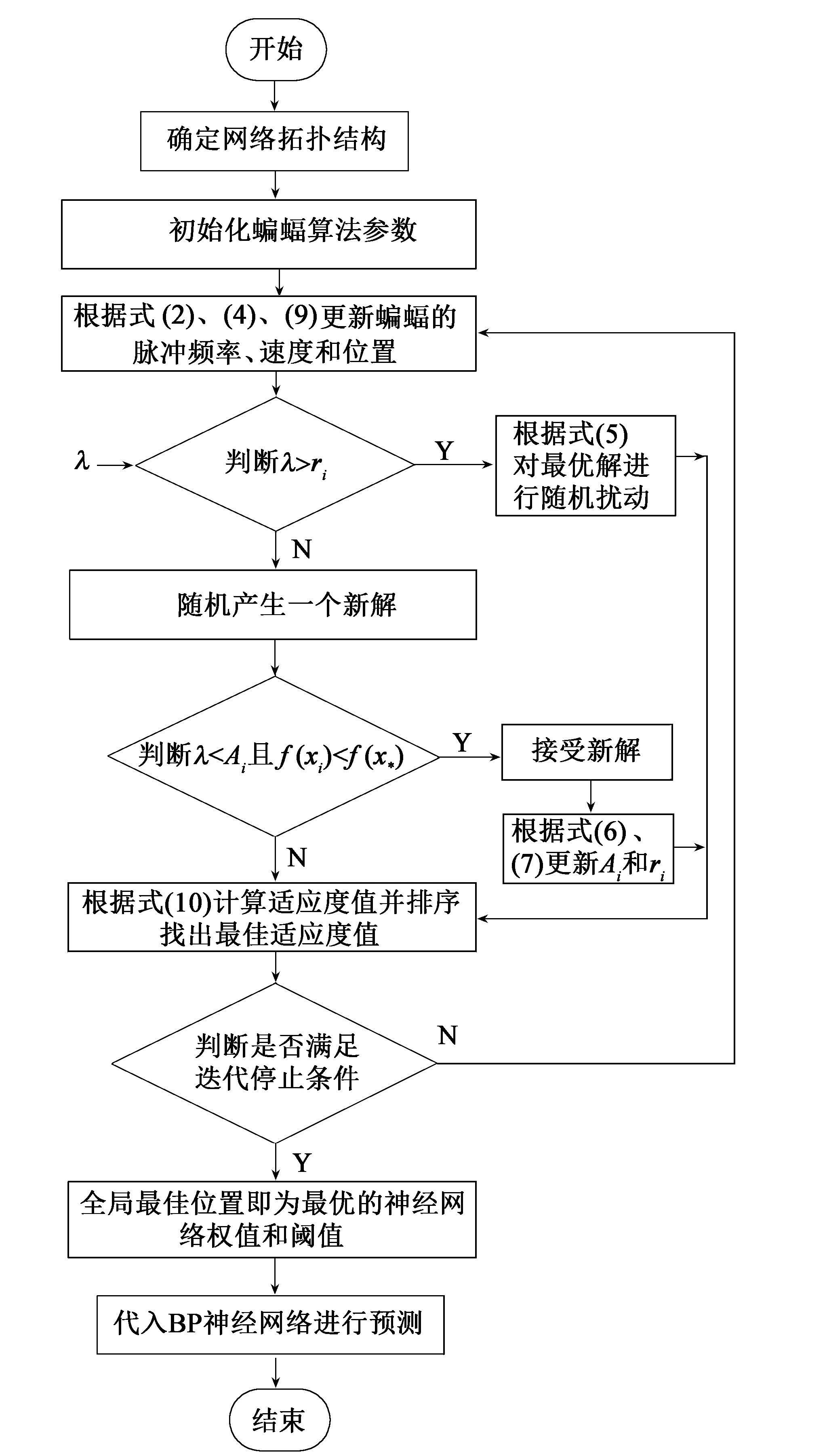
图2 NRDBA-BP算法流程图
(1)确定BP神经网络结构,若模型具有m个输入层和n个隐含层,则模型的结构为m-n-1,蝙蝠算法的搜索空间维数为[19]D=(m+1)·n+(n+1);
(2)初始化蝙蝠算法的参数,对蝙蝠种群的数量N、个体位置x、速度v、脉冲频率f、脉冲响度A和速率r随机进行初始化;
(3)确定适应度函数:
(10)
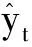
(4)更新蝙蝠搜索脉冲、位置和速度,获得局部最佳位置和全局最佳位置;
(5)生成随机数λ,若λ>ri则根据式(5)对当前的最优解进行随机扰动,否则通过随机飞行产生一个新解;
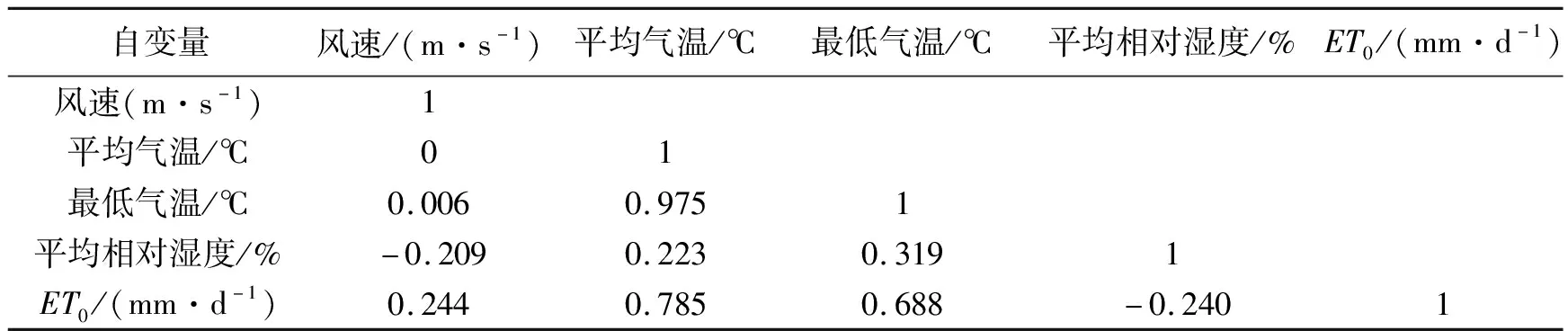
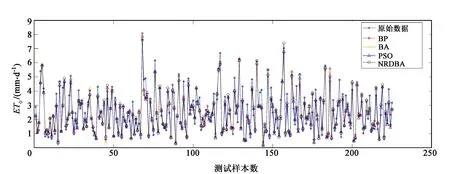
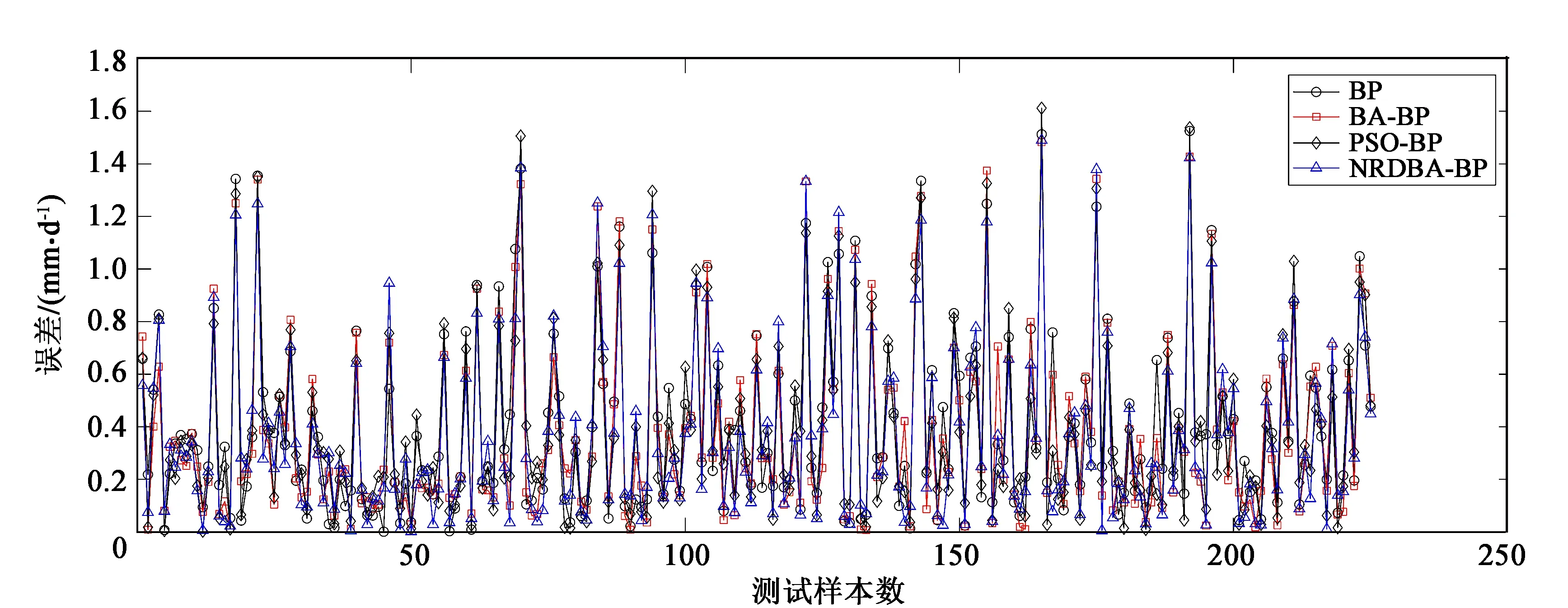
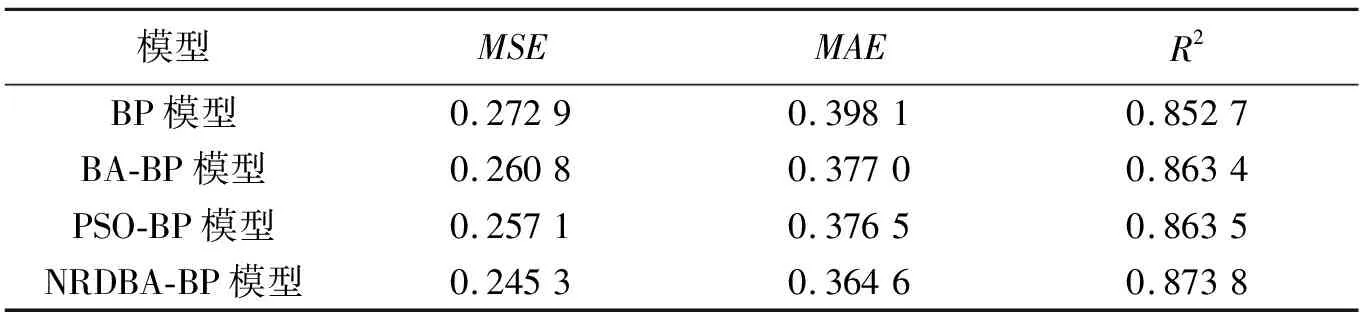
(6)若[λ (7)根据式(10)计算所有蝙蝠的适应度值并对其排序,得到全局最佳位置的适应度值fg,若fg达到网络训练精度(ε)或当前迭代次数达到最大值,则算法结束,否则转到步骤4继续更新蝙蝠的速度和位置; (8)蝙蝠算法求出fg对应的的全局最佳位置即是BP神经网络最佳的权值和阈值。 本研究使用的数据来源于中国气象数据网提供的中国地面气候资料日值数据集(V3.0)中商丘站2014-01-01至2016-06-17共900天的逐日风速、日照时长、平均气温、最高气温、最低气温和平均相对湿度6个气象资料,并以此作为原始数据,采用修正后的Peman-Monteith公式计算ET0,具体数据见表1。 表1 2014-01-01至2016-06-17商丘地区逐日气象数据与ET0 本文中ET0参考值采用修正后的Peman-Monteith公式计算,公式为 (11) 其中ET0为参考作物腾发量(mm/d),Rn是作物表面的净辐射量(MJ/(m2·d)),G是地面热通量(MJ/(m2·d)),T是2 m高度处的日平均气温(℃),u2为2 m高度处的风速(m/s),es为饱和蒸汽压(kPa),ea为实际蒸汽压力(kPa),Δ为饱和水汽压与温度曲线的斜率(kPa/℃),γ是湿度常数(kPa/℃)。 由表1数据可看出,利用PM公式计算ET0时涉及到的气象因素较多,若将其直接用于BP神经网络建模,不仅会增加网络结构设计难度和算法的运行时间,而且会对其精确度产生影响。因此选择尽可能少的影响ET0的主要气象因素用来建模是用BP神经网络预测ET0时另一迫切需要解决的问题。 在从所有因素中选择关键决定因素时主成分分析和因子分析被认为是有效的。但是使用这些分析时,需保证主成分之间相互独立且各因素之间无相互作用。然而,本研究中各气象因子之间具有明显的相关性[20],这与前提条件相冲突。而简单的相关分析没有考虑变量之间的相互作用,很可能导致错误的结果。MIV算法被认为是评估变量在神经网络中对结果影响的最佳指标之一[21]。故本文将平均影响值(MIV)与BP神经网络相结合,筛选出对ET0影响较大的参数进行建模,同时利用SPSS软件进行进一步的相关性分析,避免出现具有强相互作用的变量参与建模。 MIV的主要原理是在网络模型中训练自变量,通过观察不同变量对结果的影响值来确定参数对预测结果的影响。其具体计算过程是:首先利用训练集训练BP神经网络,然后将训练集中每个变量分别增加10%和减少10%,得到两个新的样本集A1和A2。最后将A1和A2分别使用已经训练好的神经网络进行预测得出两组预测值B1和B2,其差值即为影响变化值(IV)并对其求平均,其值即为平均影响值(MIV)。值得一提的是,MIV的绝对值大小代表各类参数对因变量产生的实际影响大小,正负值则代表相关的方向。此时可将MIV绝对值较大的参数挑选出来进行建模,从而实现对自变量的筛选[22]。 求出各自变量的MIV值后,计算第i个自变量对因变量的相对贡献率: (12) 对上文中提到的影响ET0的6个气象因素进行MIV变量筛选,其结果如表2所示。 表2 各影响因素MIV特征值 根据MIV绝对值数值越大时其相对于网络输出结果所产生的影响也越大的原理,由表2可知,排名前4的因素为风速、平均气温、最低气温和平均相对湿度。根据以往资料可知输入变量的独立性也会影响BP神经网络的拟合精度,因此本文利用SPSS 25软件对其进行进一步的独立性分析。各自变量之间的皮尔逊相关系数如表3所示[24]。 表3 各气象因素与ET0相关系数 由表3可以看出风速、平均气温、平均相对湿度之间彼此独立,而最低气温和平均气温之间具有强相关性,且平均气温对ET0的影响程度大,故本文选择风速、平均气温和平均相对湿度作为输入变量,ET0为输出变量,且输入变量三者的CCR为86.27%,满足BP神经网络的建模条件。 由于BP神经网络参与建模的各因素之间的数量级不同,若不对其进行归一化处理,将会导致较大的误差。因此在BP神经网络的训练之前,将训练和预测的所有影响因素标准化到0~1的区间内,即[25] (13) 其中xnorm、x0、xmin、xmax分别是归一化值、原始数据、最小值和最大值。 由上一节可知BP神经网络的输入和输出变量分别为3和1,然而,至今尚未有一个明确的公式可以用来确定隐含层节点数。根据式(13)可以确定隐含层节点数的范围,然后用试错法确定最优的节点数[26]。 通常情况下,实验者会先基于经验公式划分粗略的范围,然后将其代入神经网络进行逐一的验证,从中选择预测误差最小的隐含层节点数[27]: (14) 式中m为输入层节点数,n为输出层节点数,a∈[0,10]。 由式(14)可以确定隐含层节点数l的范围为[2,12],取该区间的整数值依次进行实验,其结果如图3所示。 图3 不同隐含层节点数的预测误差对比 由图3可知,使BP神经网络误差最小的隐含层节点数为6,故BP神经网络的结构为3-6-1。 根据以上分析,本文分别建立BP模型、BA-BP模型、NRDBA-BP模型和PSO-BP模型对ET0进行预测。其中BA-BP和NRDBA-BP算法使用相同的参数设置:N=50,x∈[-2,2],v∈[-5,5],f∈[0,2],A0=0.5ones(N,1),α=0.95,r0=0.9ones(N,1),γ=0.95。PSO-BP算法的参数为:学习因子c1=c2=2,惯性权重wmax=0.7,wmin=0.4,迭代次数tmax=100,粒子种群个数N=20。 本研究共收集了900组数据,使用其中的675组数据作为训练集,其余225组数据作为测试集。图4为4种模型的预测结果与实际结果的对比图,图5为4种模型的预测误差对比图。同时为了更加明显的说明4种模型的预测效果,本文选取以下统计指标作为评价模型的依据,其计算公式如下: (1)均方误差: (15) (2)平均绝对误差: (16) (3)决定系数: (17) 从图4中可以看出NRDBA-BP的预测结果与BP模型、BA-BP模型、PSO-BP模型相比更加接近真实值,说明NRDBA-BP模型比BP、BA-BP、PSO-BP模型具有更好的预测性能。图5中不同模型预测的误差对比进一步说明了这个情况,从中可以看出在4种预测模型中,从整体上看NRDBA-BP模型的误差与其他3种模型相比较小,表明其预测精度最高,与真实值最接近。 图4 不同模型预测曲线比较 图5 不同模型预测误差对比 为了定量地确定最优预测模型,采用上述3种统计指标对模型进行评价和比较。表4记录了BP、BA-BP、PSO-BP和NRDBA-BP 4种模型预测ET0时的相关指标。其中NRDBA-BP模型的MSE、MAE与BP模型相比降低了10.11%和8.41%,与BA-BP模型相比降低了5.9%和3.2%,与BA-BP模型相比降低了4.58%和3.16%,且4种预测模型中NRDBA-BP的R2最大,这表明NRDBA-BP模型在ET0预测方面优于BP、BA-BP和PSO-BP算法。因此综合分析,本文所提出的NRDBA-BP预测模型具有良好的预测性能和可信赖性,其预测值更加接近真实的ET0,说明NRDBA-BP模型在ET0预测方面具有很大的应用潜力。 表4 模型指标对比 本文提出了一种基于非线性随机递减权重改进的NRDBA算法,并将其应用于BP神经网络预测ET0中以优化其初始阈值和权值。该方法能够有效解决传统BP神经网络由于初始阈值和权值随机选取所带来训练速度慢、易陷于局部极值的问题。同时本文的另一个意义在于为ET0神经网络建模筛选关键因素提供了一种新的思路,通过MIV算法和SPSS软件实现对变量的筛选,从而将互不相干的关键因素挑选出来参与建模。在此基础上构建了基于风速、平均气温和平均相对湿度的三因素NRDBA-BP预测模型。实验结果表明,所提出的模型显示出了较高的精度,对发展节能高效的新型灌溉技术具有一定的指导作用,同时所建立的模型对于减少工作量和利用较少气象因素下建立预测模型具有重要意义。2 实验数据分析
2.1 实验数据来源

2.2 MIV特征值筛选变量
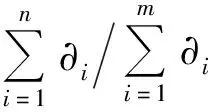

2.3 输入数据预处理
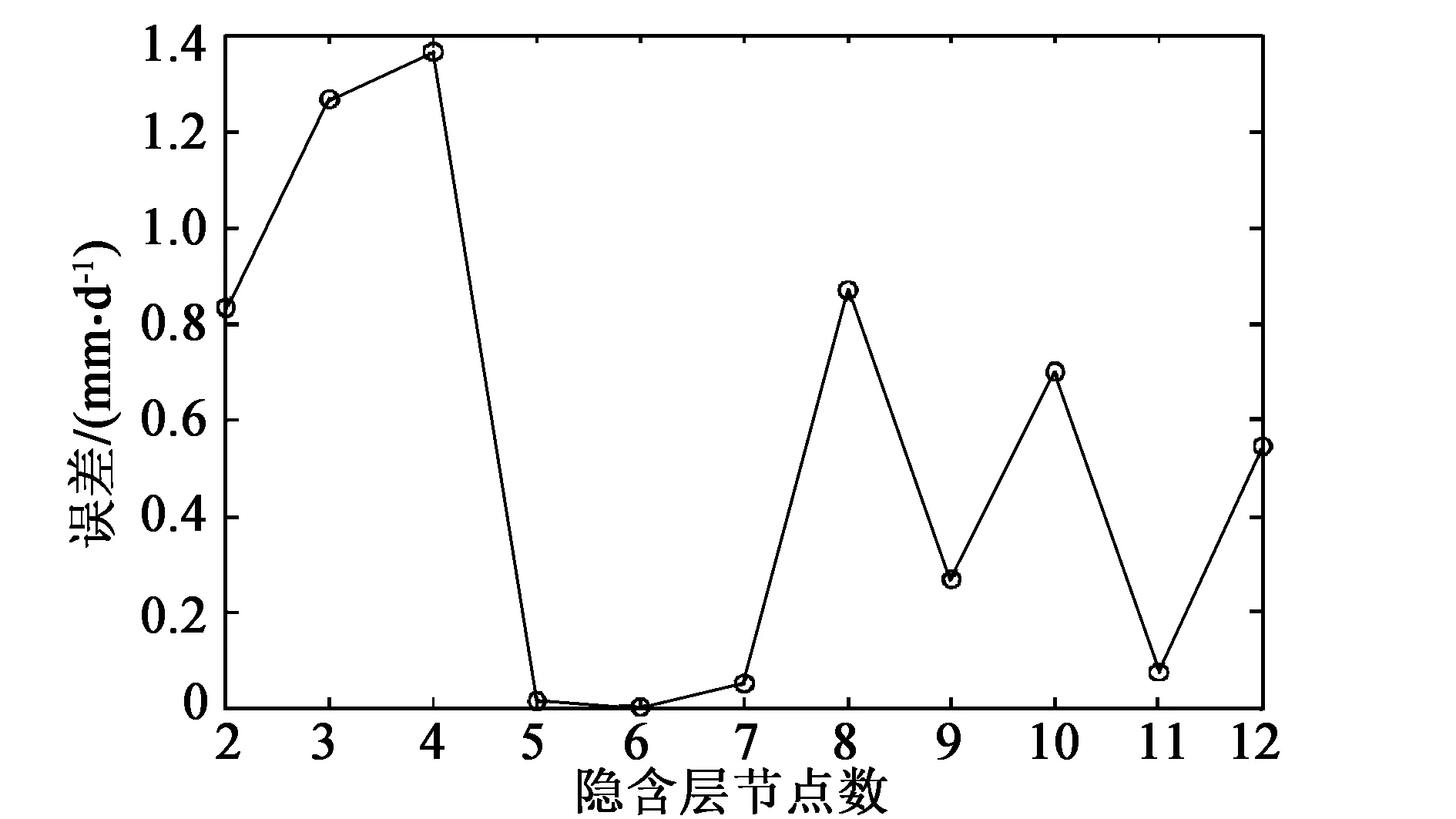
2.4 确定BP神经网络的结构
3 基于NRDBA-BP的ET0预测模型
4 结语
