面向低资源场景的论辩挖掘方法
2021-04-23叶锴魏晶晶魏冬春王强廖祥文
叶锴, 魏晶晶, 魏冬春, 王强, 廖祥文
(1. 福州大学数学与计算机科学学院, 福建 福州 350108; 2. 福建江夏学院电子信息科学学院, 福建 福州 350108)
0 引言
主观性文本能反映人们对现实事物的看法, 具有巨大的研究价值. 论辩挖掘[1]的目标是自动学习文本的论辩结构, 进而识别论点和提取相关论点间的逻辑关系, 从而帮助人们在如政府决策等事务中做出决策, 提供便利.
传统的论辩挖掘方法主要采用机器学习模型, 如朴素贝叶斯[2]等, 并取得不错的性能. 但传统方法依赖于特征工程的设计, 难以应用于低资源场景. 现有工作大多采用神经网络进行端到端的特征表示学习[3],但论辩挖掘单一领域的现有标注数据难以满足神经网络的训练. 因此, 有研究者对多个领域数据集进行联合训练[4-5], 利用任务间的关联信息改进模型性能. 但这些方法没有利用文本的层级结构信息, 难以检测跨段落的论点部件边界.
针对上述问题, 本研究提出一种面向低资源场景的多任务学习论辩挖掘方法, 该方法采用多任务学习策略, 学习文本的字符级共享表示, 同时在序列编码中融入文本的结构信息进行求解. 该模型共享任务的字符级特征, 有效利用领域间的信息以解决低资源场景训练数据不足的问题; 此外, 学习到的结构信息能有效捕获长依赖关系, 帮助模型更好识别长论点部件. 采用了文献[4]中所使用的六个数据集进行实验, 实验结果表明, 与当前最好的方法相比, 本研究提出的方法在宏观F1值上有1%~2%的提升, 较好地验证了该方法的有效性.
1 相关工作
1.1 论辩挖掘
论辩挖掘是自然语言处理中的新兴领域. 文献[2]首先在法律文本上通过朴素贝叶斯模型完成论点分类任务. 这些方法严重依赖手工特征, 成本高昂. 文献[3]首次提出基于神经网络端到端的论辩挖掘模型, 并证明论辩挖掘任务更适合视作序列标注进行求解. 文献[6]发现论辩挖掘领域标签的概念化差异一定程度上阻碍了论辩挖掘任务的跨域训练. 文献[7-8]的研究工作表明由于论辩挖掘领域概念化不同, 大多数据集缺乏规范的论辩架构且存在噪音, 因而难以在网络文本中开展. 文献[9]首次采用监督学习检索文本中与给定主题相同立场的论证内容. 文献[4]首次将多任务学习应用在论辩挖掘并提升了性能, 证明了多任务学习也能处理论辩挖掘这一复杂任务. 文献[5]通过对多个数据集进行联合训练, 利用多任务之间的关联信息一定程度上改进了论点部件检测和识别的性能.
1.2 多任务学习
多任务学习目的是在学习主任务时, 同时学习其它任务以获取额外信息改进主任务. 文献[10]首次提出多任务学习, 认为将复杂问题分解为更小且合理的独立子问题分别求解再组合, 能够解决初始的复杂问题. 文献[11]在此基础上增加了“窃听”机制, 所有任务共享模型的编码层. 文献[12]的工作表明多任务学习对于数据稀少的任务更加有效. 文献[13]通过同时借鉴同任务高资源语言数据和相关的任务数据学到的知识, 解决低资源语言训练数据缺乏, 即低资源问题. 文献[14]提出一种新的参数共享机制——稀疏共享, 为每个任务从基网络中抽取出一个对应的子网络来处理该任务, 在任务相关性弱的场景下, 稀疏共享提升较大.
2 问题描述
论辩挖掘任务的目标是学习文本的论辩结构以识别论点, 本质是序列标注任务. 因此, 对于论辩挖掘问题, 其形式化定义描述如下, 在给定的某个含n个单词的主观性文本x={x1,x2, …,xn}和对应的标签y={y1,y2, …,yn}, 其中yi定义如下:yi={(b,c)|b∈(B, I, O),c∈(P, C, MC)},b代表论点边界检测的标签, B代表起始单元, I代表中间单元, O则表示非论辩单元,c表示论点部件的类型. 这里以学生论文数据集作为示例, P表示前提, C代表主张, M则表示文本中唯一的主要主张. 具体的标注示例如表1.

表1 学生论文数据集标注样例
3 模型建立

图1 论辩挖掘多任务学习模型
本研究引入多任务学习解决多个不同领域数据集的论辩挖掘任务, 所提出的框架CNN-Highway-On-LSTM-CRF如图1所示. 该模型主要包括以下模块: 1)基于CNN的字符表示; 2)基于高速神经网络的特征过滤层; 3)基于ON-LSTM模型的词级标注方法; 4)输出层. 本研究将以自下而上方式详细介绍所提出的模型框架.
3.1 基于CNN的字符级表示
本研究拓展了文献[15]提出的CNN模型. 具体如下:
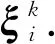
3.2 基于高速神经网络的特征过滤
为进一步提高实验效果, 引入高速神经网络进行特征过滤. 其主要通过转换门和进位门控制不同层信息衰减的比例, 具体实现如下:at=z⊗σ(Wat-1+b)+(1-z)⊗at-1. 这里,σ为非线性函数,z=σ(Wat-1+b)为转换门, (1-z)成为进位门, 这里W表示转关门的权重矩阵.
3.3 基于ON-LSTM模型的词级标注方法
文本的每个句子可以被表示为层级结构, 在低资源场景下, 这些结构特征能改善模型性能. 因此, 引入有序神经元长短时记忆网络(ON-LSTM)[16]作为词级序列标注模型.
在ON-LSTM通过对内部的神经元进行排序将层级结构信息集成到LSTM中, 通过控制神经元的更新频率来表示不同尺度的依赖关系, 与标准的LSTM架构相比, 其引入了新的更新规则, 定义如下:
这里,xt是当前输入,ht-1为前一时间步的隐藏状态.
3.4 模型求解
标签依赖是解决序列标注任务的关键. 例如BIO标注方法中, 标记I不能出现在B之前. 因此, 联合解码标签链可以确保得到的标签是有意义的. 条件随机场(CRF)已被证明能够捕捉标签依赖信息. 因此, 采用CRF作为模型的最终预测层.
本研究整个模型的输入为一段论辩挖掘文本序列, 最终输出为该文本序列预测的标签序列Y.
4 数据集描述
采用文献[4]所使用的数据集, 数据集具体情况如表2所示. 其中Domain表示数据集所属的领域, Len为数据集的最大句子长度, Token为每个数据集每篇文章的平均单词数量, Class 为每个数据集论点部件的类型, 每个数据集的类型都不相同.

表2 数据集详情
5 实验结果与分析
本节将从实验的对比模型、 参数设置以及评价指标进行介绍, 同时对不同场景的实验结果进行简要的分析.
5.1 实验对比模型
为了验证本研究模型的有效性, 选取以下模型作为基准实验.
1) STL[4]. 单任务学习模型, 该模型仅针对单一数据集进行训练和预测.
2) MTL-Bi-LSTM-CRF[4]. 多任务学习模型, 采用Bi-LSTM进行特征提取, 用CRF进行序列标注, 记为MTL.
3) CharLSTM+Bi-LSTM-CRF[17]. 该模型在2)的基础上引入字符级的LSTM进行字符特征提取, 记为LBLC.
4) CharCNN+Bi-LSTM-CRF[17]. 与3)不同的是字符级的LSTM换成了字符级的CNN, 记为CBLC.
5) CNNs-Highway+Bi-LSTM-CRF[5]. 与4)不同的是字符级的CNN换为TextCNN-Highway, 记为CHBLC.
5.2 评价指标
5.3 实验结果及分析
在现实场景中, 由于标注代价高昂, 论辩挖掘仍十分缺乏标注数据, 因此, 本研究模拟了低资源场景, 比较模型在各种场景中的性能. 为模拟低资源场景, 按照21 k, 12 k, 6 k, 1 k的单词规模对数据集进行随机抽取, 其规模指的是训练样本数目.
5.3.1多任务学习的任务数量和任务差异对实验的影响
为探究任务数量对实验的影响, 以Hotel为主任务, 逐次增加辅助任务的数量. 如图2~3所示, 在迭代次数相同的情况下, 随着任务的增加, 模型的训练时间随之增长, 模型性能也逐步提高. 与模型复杂度增加改善的性能提高相比, 其带来的训练时间增加仍在可接受的范围.
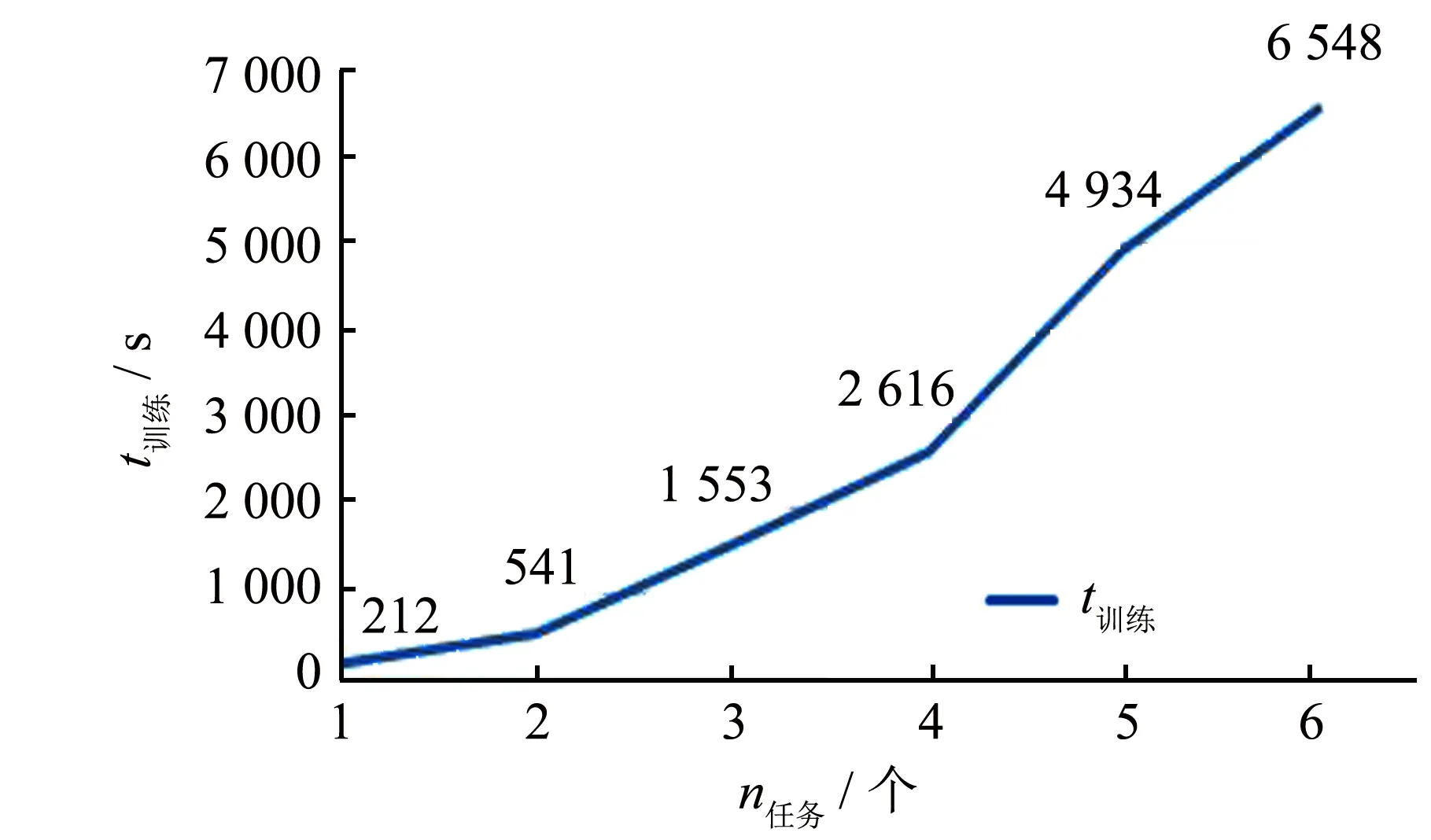
图2 任务数量对模型训练时间的影响

图3 任务数量对模型性能的影响
为了探究多任务学习方法中任务间差异对实验的影响, 分别以Essays等五个数据集作为Hotel辅助任务进行对比实验, 实验结果如图4~5所示.从图4可以看出, 每个任务的引入都对模型性能有一定的提升, 而任务间差异的大小影响性能的提升幅度. 由图5可以发现, 差异较大的News作为辅助任务时模型收敛时间较长, 而几个差异相近的辅助任务: Var, Wiki, Web等, 其收敛时间相近. 从实验结果综合来看, 模型的差异性对模型收敛时间有一定的影响, 但影响有限.
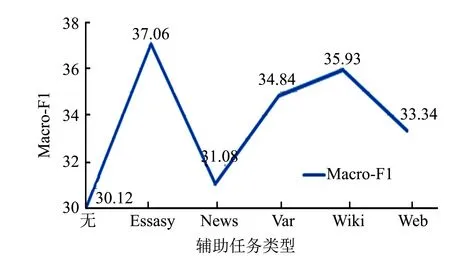
图4 任务差异对模型性能的影响
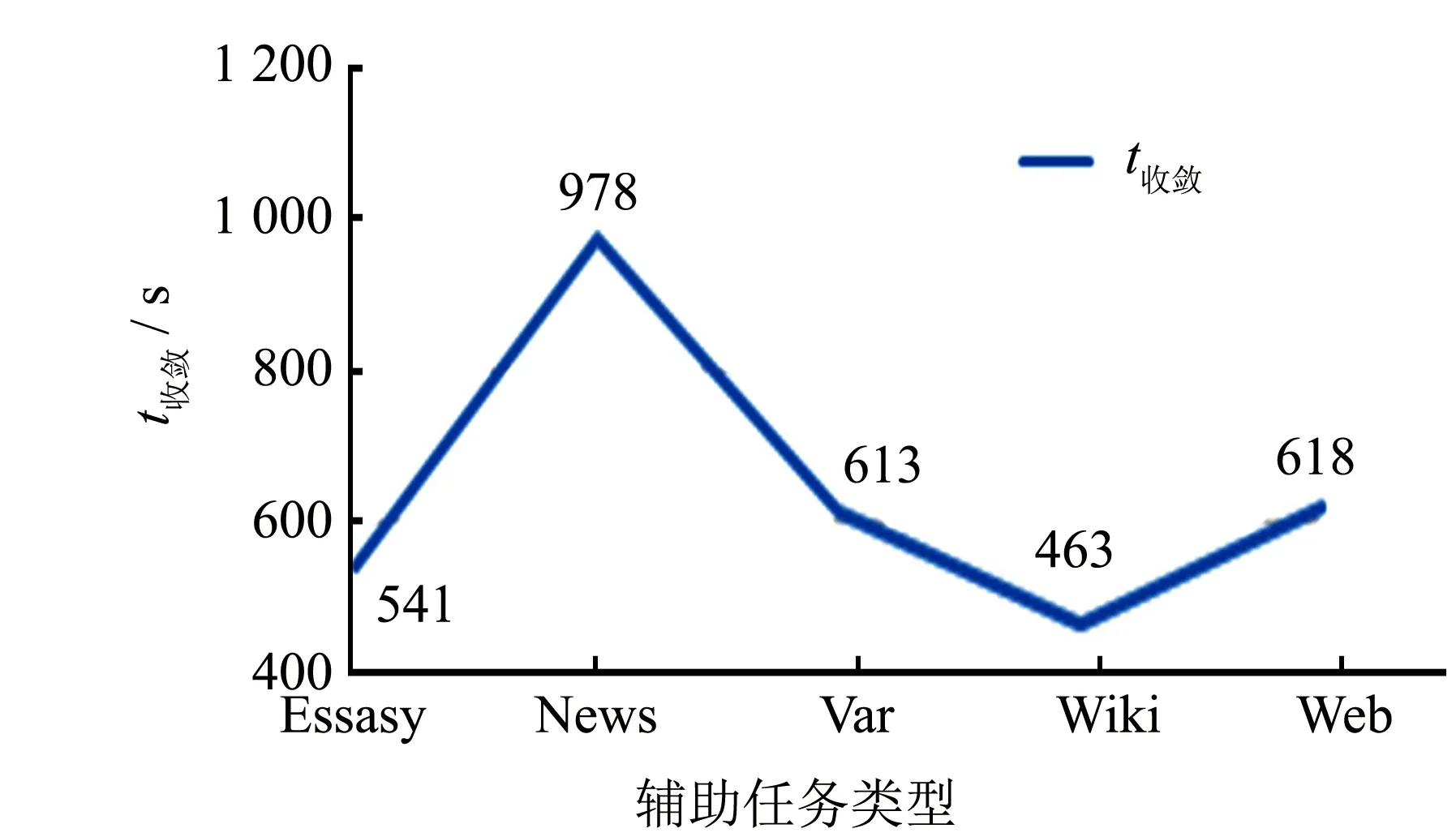
图5 任务差异对模型收敛时间的影响
5.3.2数据稀疏情况下对比各个模型性能
在不同低资源场景下的模型Macro-F1值如表3所示, 其中, 提升最高且稳定的是Hotel数据集, 在四种低资源场景下均获得了1%~4%的提升. 在1 k, 6 k, 12 k的单词场景中, 大部分数据集都取得了1%~5%的提升, 在21 k的单词场景中, 虽然没有取得显著的提升, 但也达到了与当前最优方法模型相近的性能. 从表4中可以看到, 在绝大部分场景中, 本研究模型性能高于所有基准模型, 在数据规模越小的场景中, 性能提升越大.
观察实验结果发现, MTL等多任务模型较单任务模型在各个任务上都获得了一定的提高, 特别是Wiki数据集, 在21 k的单词场景提升了8.9%. 这可能是因为Wiki数据集是社交媒体上随机采集的文本, 存在大量非论辩成分, 影响其他论点部件类型的判断, 而多任务机制的引入降低了过拟合的风险, 提升了对论辩类型的预测准确率. 例如在News数据集中Premise因为存在大量的O而被单任务模型预测为O, 而多任务减少了这种情况.
结合实验预测标签情况对结果进一步分析, 发现本研究所提出的模型捕获了层级结构信息, 利用这些信息能够较好地判断论点边界, 进而提升模型的性能. 如Hotel数据集中, 在1 k的单词规模下提升了8.8%, 其他规模也提升了2%左右. 这是因为论点部件长度过长, 存在跨段部件时, 基准模型难以捕捉这一长依赖信息, 使得预测的论点边界过小而发生错误, 而本研究模型利用层级结构信息, 能够捕获长依赖信息, 提升边界的预测准确度, 进而提升了模型性能.
综上所述, 与单任务学习模型和其他的基准模型相比, 本研究的模型方法在大部分低资源的场景下都能取得一定的提升, 由此证明本研究方法在面向低资源场景下是有效的.

表3 不同低资源场景下各个模型的Macro-F1值
5.3.3在完整数据集场景下比较各个模型性能
虽然论辩挖掘任务目前仍缺少标注数据, 但随着研究的进行, 数据资源将不断丰富. 因而, 所提方法还需考虑有足够训练数据的场景. 因此, 将在完整数据集场景中比较各个模型性能, 以验证所提方法的有效性(表4). 从表4的实验结果可以看出, 本研究所提出的模型在完整数据的场景中较前面的基准模型获得了一定的提升. 其中Hotel较其他模型提升较为明显, 这可能是因为Hotel论点部件长度普遍较长且标签多达7种, 其他模型难以解决这种长依赖多标签问题, 而本研究模型通过学习隐藏的层次信息, 可以较好地解决这类长依赖问题.
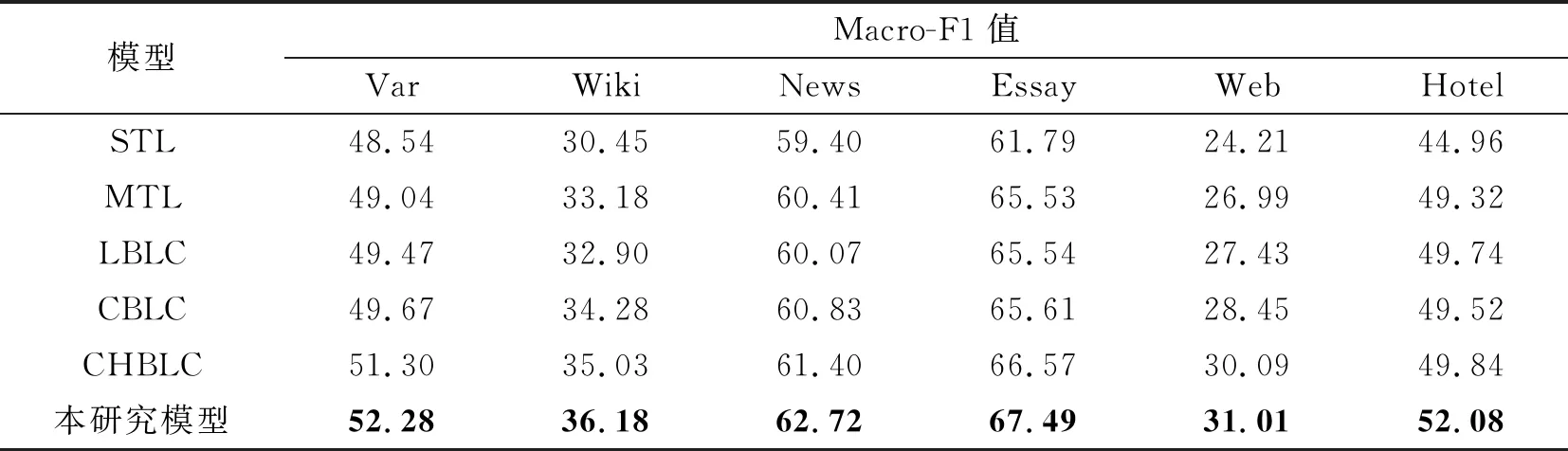
表4 完整数据集下各个模型的Macro-F1值
从对比实验中, 可以发现MTL模型所代表的多任务架构较单任务性能有较大改善. 其在Essays数据集上提升最为显著, 提升了3.74%, 而提升最少的Var和News也提升0.5%~1.0%, 说明多任务方法是解决多个数据集论辩挖掘任务的有效方法.
综上所述, 与单任务学习模型相比, 多任务学习模型能获得较好的效果, 利用字符级信息模型也能进一步提升性能. 而本研究方法较其他模型更加优秀, 说明本方法在完整数据集上也有不错的效果.
6 结语
本研究提出一种面向低资源场景的多任务学习论辩挖掘方法. 该方法应用多任务学习策略获取多任务间的共享信息表示, 并引入ON-LSTM, 最后通过条件随机场进行标注. 通过与现有方法的实验结果对比, 证明所提方法利用多任务可有效解决论辩挖掘任务缺乏数据的问题, 同时解决跨段论点部件难以检测的问题. 接下来的研究中, 将继续探索如何更加有效地利用资源以提升模型性能, 促进论辩挖掘在新兴领域中的应用.
