非参数贝叶斯分类字典学习的MRI重建方法
2021-04-22曹赛男刘媛媛李康康
朱 路,曹赛男,刘 松,刘媛媛,李康康
(华东交通大学 信息工程学院,江西 南昌 330013)
0 引 言
为减少磁共振成像(magnetic resonance imaging,MRI)的数据采集时间,相关研究者提出了许多图像重构方法。其中,基于数据或图像本身学习出的字典训练方法在MRI重构中得到广泛应用[1-5]。文献[3]中基于自适应学习稀疏变换的DLMRI算法,通过数据本身学习获得字典,使信号具有更稀疏的表示。文献[4]提到的GradDLRec算法采用K-SVD训练字典,需要预先设定好字典的大小、信号的稀疏度、噪声方差等参数。Zonoobi等[5]利用图像块之间的相似性进行图像块聚类,对动态MR图像进行分类字典学习,提高了字典的结构表示能力。然而,该方法采用K-means执行图像块分组,需凭经验预设聚类个数,缺乏自适应性。Zhou等[6]提出基于BPFA(beta process factor analysis)的字典学习算法,解决了字典学习中的参数选择问题。由于Zhou等通过贝塔-伯努利先验来构造稀疏,未利用图像的稀疏先验和非局部信息,所以重构质量仍可进一步提升。
本文利用梯度域稀疏和非局部相似性,提出基于非参数贝叶斯分类字典学习的MRI重构方法。通过在梯度域中进行字典学习,使字典的稀疏表示能力更强。采用无限高斯混合模型,为图像块自动确定聚类个数。引入基于BPFA的非参数字典学习方法,分别为每一类图像块训练字典,降低对参数选择的依赖性,提高图像的结构化表达。
1 基于梯度域和分类字典的MRI重构模型
1.1 压缩感知与字典学习
压缩感知理论指出,若信号在特定域上具有稀疏性或可压缩性,则通过少量测量即可重建整个原始信号。压缩感知理论主要包括信号的稀疏性、测量矩阵和非线性重建方法3个方面。MR图像本身不具有稀疏性,但可利用小波、差分、字典等变换方式来表示MR图像的稀疏性。其中,通过构造自适应字典的变换方法得到了广泛应用[5-7]。对于一幅MR图像,可通过构造一个字典D和相应的稀疏表示系数矩阵来近似表示。字典D∈Rn×K, 由K列dj向量构成,每一列dj称为一个原子。其目标函数为
(1)
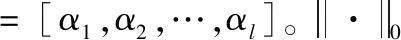
1.2 梯度域MR图像的非局部相似先验信息
MR图像具有变换域稀疏、局部平滑、非局部相关等多种特性,充分利用MR图像的不同先验信息受到研究者的广泛重视。近年来的研究结果表明[8,9],数据越稀疏,自适应学习字典的稀疏表示能力越强。因此,可考虑先进行图像的稀疏变换,在稀疏的变换域中再进行自适应字典学习。同时,图像的非局部相似性在图像去噪、重建领域中得到了极为广泛地应用[5,10,11]。在一幅MR图像中取一小块,则可以在该图像的其它多处区域找到与此块相似的小块,这种相似特性即为非局部相似性。由于差分变换是线性的,因此在梯度域中同样具有这种相似性。图1显示了MR脑图像的非局部相似性,将原始像素做差分后,在横向差分域和纵向差分域中依然具有非局部相似特性。

图1 MR原始图像和梯度域图像中的非局部相似性
1.3 梯度域和分类字典的MRI重构模型
基于上述两种先验,本文提出基于梯度域和分类字典学习的MRI重构模型,如图2所示。

图2 基于梯度域和分类字典学习的MRI重构框架
首先将原始图像转换到梯度域,使图像的表示更稀疏;同时利用图像的非局部相似性将图像块聚类,分别为每一类图像块进行字典训练,具有保持图像局部结构和边缘纹理的优点。该重构模型的数学表述为
(2)

2 基于非参数贝叶斯分类字典学习的MRI重构方法
2.1 非局部相似块聚类
在式(2)中,字典Dj根据每一类图像块的结构特点训练而来。在对图像块聚类时,有别于Zonoobi等直接对图像块做非局部相似性处理和利用K-means方法确定聚类个数,本文对梯度域图像块做均值削减并利用无限高斯混合模型自动聚类。本文对梯度域图像块的分类过程[12]如下:
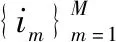

(3)
第n个PG变化向量的条件分布为
(4)
当混合系数向量π服从狄利克雷分布时,式(4)则为无限高斯混合模型。所有变量的联合概率分布为

(5)
此联合概率的后验参数,可由EM(expectation maximization)算法[13]估计。推断出所有的后验参数后,从而获得所有PG变化向量的聚类个数Ng。
2.2 非参数贝叶斯字典学习与优化方法


(6)
(7)
这里采用交替迭代方法(alternating direction method,ADM)[15]对式(6)进行变量分离,得到P1、P2、P3这3个子问题,并对3个子问题分别求解


(8)
(2)P2求解:对差分图像变量ω进行更新,同样采用最小二乘法进行求解,并令β=P, 结果为
(9)
(3)P3求解:更新每一组图像块的字典Dj和对应的稀疏表示系数矩阵Γj。大部分字典学习方法需要预先设置字典大小、稀疏度、噪声方差等参数,当参数设置与图像实际偏离较大时,这些字典学习方法的重构性能将大大下降。因此,本文提出基于BPFA的非参数分类字典学习方法,该模型表示如下

(10)
其中,dk表示第j组字典矩阵D的第k个原子,εl表示噪声。Ip表示p×p大小的单位矩阵。稀疏系数αl被分解成两个向量的哈达玛乘积,sl表示图像块稀疏表示的权重向量;zl表示图像块稀疏表示的二值向量;⊙为哈达玛向量乘积,表示逐个元素对应相乘。字典中各个原子的使用情况由zlk∈{0,1}决定,表示此原子是否参与对信号的表示。每个zlk均服从参数为πk的Bernoulli分布,参数πk又由Beta分布生成。这种概率分布设置,使得当K为一个足够大的值时,有相当数量的原子都未参与对信号的表示。由于该算法的稀疏先验用Truncated Bernoulli-Beta的先验假设来代替,因此不需要预先设置稀疏度、字典大小等参数,是一种非参数字典学习的方法。
为求解后验概率,将BPFA模型与优化方法相结合[16,17],通过吉布斯采样(Gibbs sampling)更新BPFA的后验参数,其更新方程为

(11)
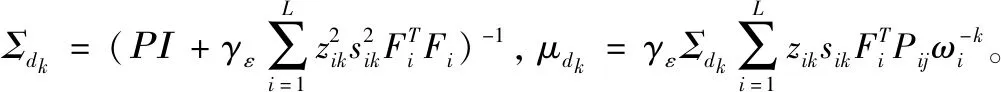
算法1:基于BPFA的分类字典学习算法
输入:梯度域图像块Plωk,超参数a,b,c,d,e,f。
输出:更新的梯度域图像块Plωk+1。
从N个梯度图像块Plωk中提取N个PG,计算其均值μi和PG变化向量。通过贝叶斯变分推断估计无限高斯混合模型中的参数,对每一类PG变化向量执行以下操作:
(1)构造字典矩阵Dj=[dj1,…,djK],djk~N(0,P-1Ip);
(3)权重向量和噪声向量的精度值采样γs~Gamma(c,d),γε~Gamma(e,f);
(4)对第j组第i个图像块进行以下操作:
构造稀疏系数:αi=zi⊙si;
根据P1、P2和P3子问题的求解过程,本文重构方法的具体步骤归纳为算法2。
算法2:基于非参数贝叶斯分类字典学习的MRI重构算法
输入:下采样K空间数据v,循环次数K,k=1。
输出:重构图像Ik+1。

重复以下步骤直到终止条件:
(1)根据式(8),更新图像I;
(2)根据式(9),更新差分图像变量ω;
(3)根据式(10),通过Gibbs采样更新D和αl;
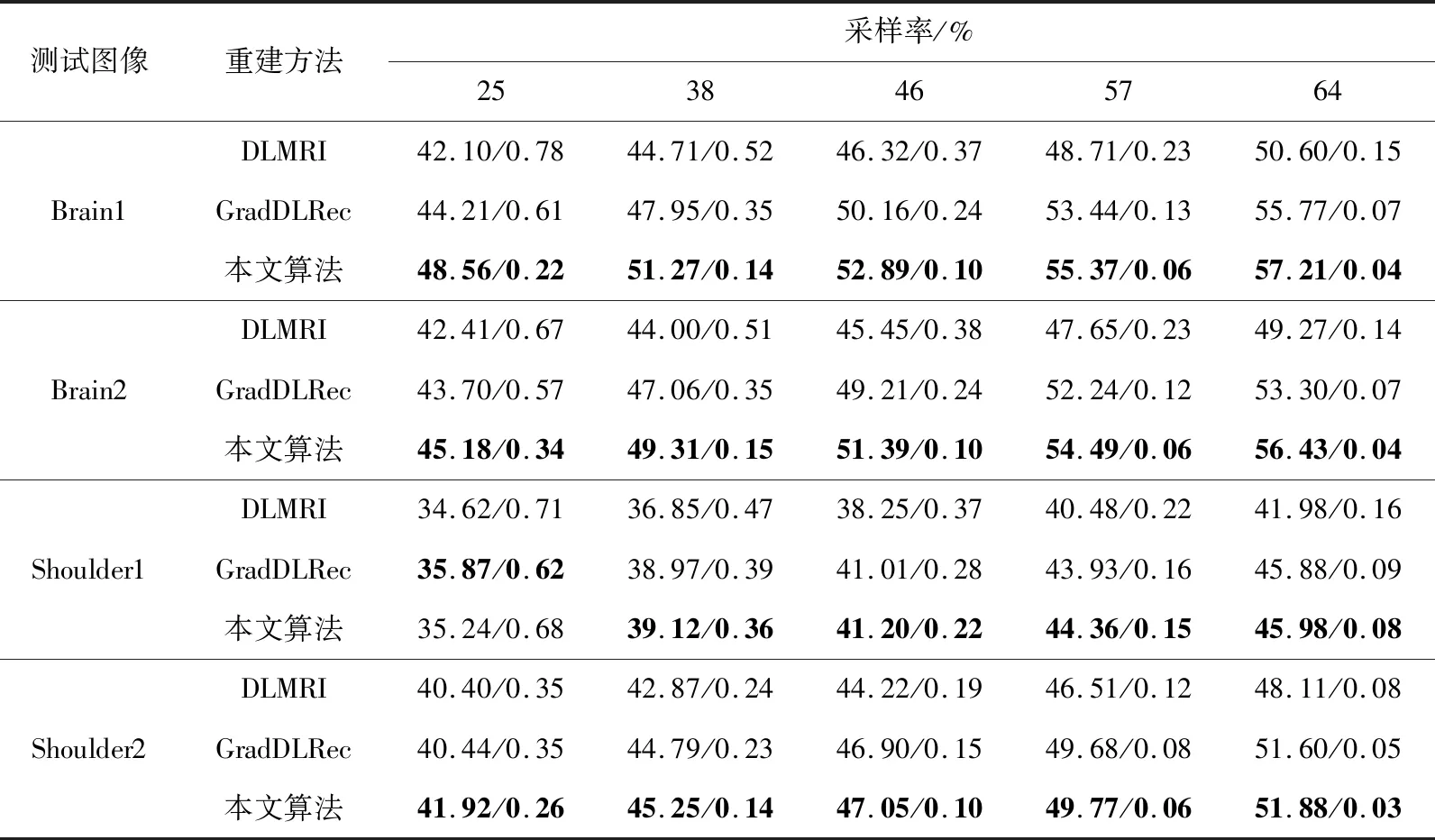
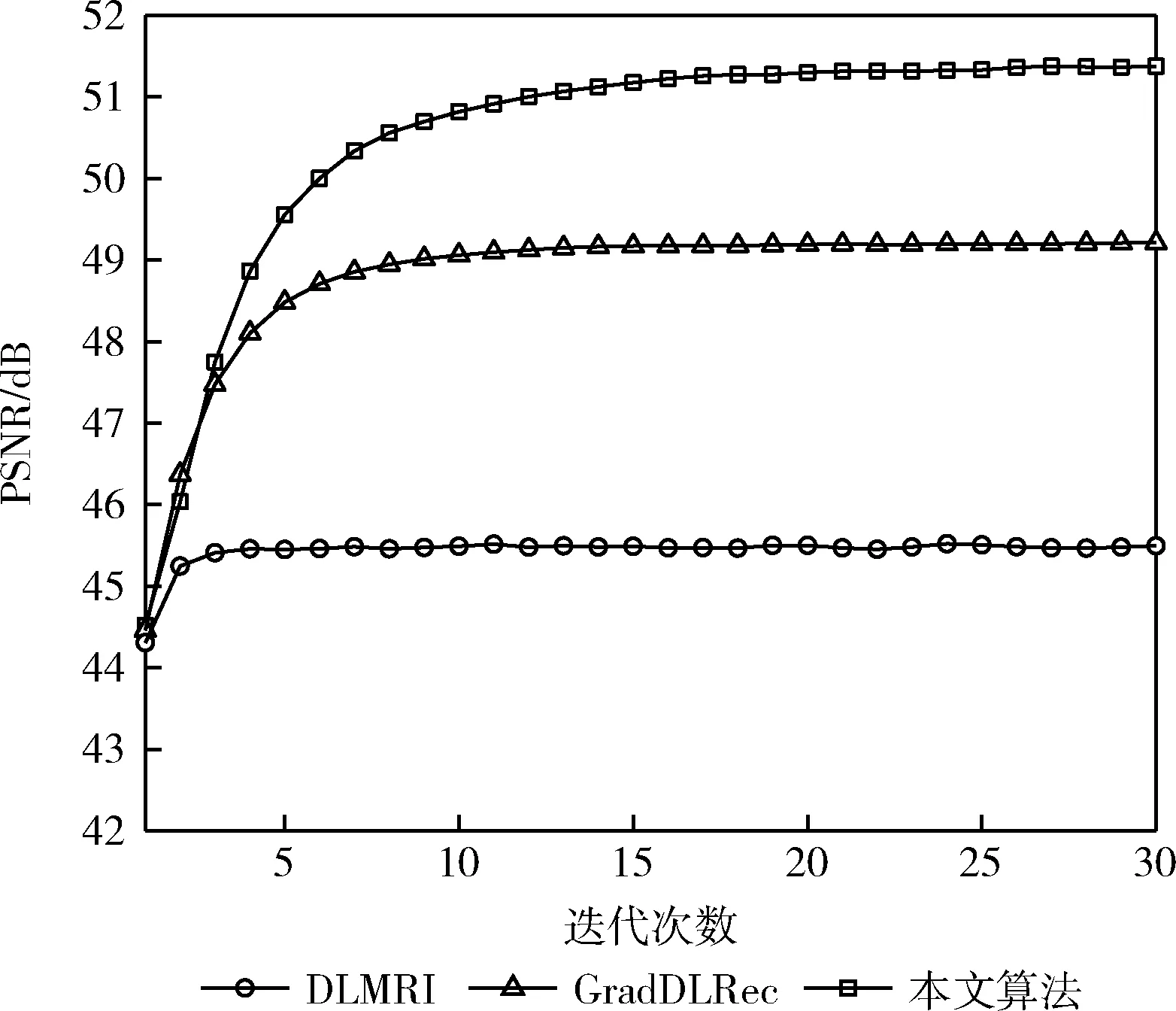
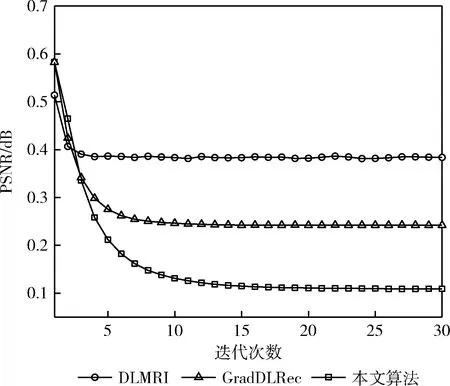
(5)令k=k+1, 若k 为验证本文提出方法的重建性能,仿真实验选用4张典型的MR测试图像,如图3所示。选用当前两种经典的MRI重建算法进行性能比较,分别为DLMRI算法和GradDLRec算法。 图3 测试图像 在所有的实验中,均采用二维随机压缩采样方式,并设置25%、38%、46%、57%、64%这5种从低到高不等间隔的采样率。采用峰值信噪比(PSNR)和高频误差范数(HFEN)评价算法的重建质量。其中,PSNR从像素之间的灰度差别整体进行评价,HFEN利用高频信息从图像的边缘和细节特征进行评价。PSNR值越高且HFEN值越低,说明重建质量越好。 首先对MR图像在无噪声干扰情况下的重建性能进行测试。然后,对MR图像在噪声标准方差为15、20、25、30、35情况下的重建性能进行测试,用于比较3种重建算法的鲁棒性能。实验仿真软件为MATLAB,实现平台是1.70 GHz Intel®64 GB RAM的计算机。 在测试实验中,本文所提算法的参数设置如下:抽取的图像块大小为P1/2=8,图像块的重叠抽取步长为r=1。非局部相似块的搜索窗口大小为w×w=31×31。图像块的个数N为MR图像的大小。N个PG变化的初始聚类个数为Ng=32。当某类PG变化的个数大于104时,字典的原子大小设为K=512,反之,字典的原子大小设为K=256;基于BPFA的分类字典学习算法采用10次循环迭代。将超参数a,b,c,d,e,f经验性地设置为a=b=1,c=d=e=f=10-6。对比算法DLMRI算法和GradDLRec算法的代码均取自原作者主页。其中,DLMRI算法的参数设置如其论文中所建议的:字典大小K=36,图像块大小P1/2=6,图像块的重叠抽取步长为r=1,β=36,λ=140,图像块的个数为200×P,稀疏阈值T0=5;GradDLRec算法除增加参数λ1=60,v2=3外,其它设置均与DLMRI算法保持一致。 首先对无噪声情况下的4幅MR图像进行测试。图4是Brain1图像在采样率为25%时的重建图像(第一行)及重建残差图像(第二行)。可以观察,DLMRI算法和GradDLRec算法的重构残差图中的外部边缘和内部纹理仍有部分保留,左侧和右侧的居中位置处均呈现出白色短线条。其中,DLMRI算法呈现的短线条更明显,且外部边缘的上侧也出现了白色短线条。而在本文算法的重构残差图中,外部边缘的任意位置都未出现边缘短线。这说明,使用DLMRI算法和GradDLRec算法重建出的图像丢失了Brain1图像的部分边缘和纹理信息;而使用本文算法重构的图像误差最小,边缘结构和局部纹理均保持得很好。这是因为本文算法利用了图像的稀疏性和非局部相似性两种先验信息,增加了图像的结构性表达,故获得了细节上更加丰富的图像。 图4 Brain1图像在3种算法下的重建效果 表1详细列出了4幅测试图像在不同重建算法下的重构结果。表中加粗的地方表示3种重建算法的重构结果中最大的PSNR值和最小的HFEN值。由表1可以看出,在各幅图像中和各个采样率下,DLMRI算法的PSNR值最低、HFEN值最高;GradDLRec算法的PSNR值、HFEN值优于DLMRI算法;本文算法的PSNR值、HFEN值均优于前两种算法。相比GradDLRec算法,平均每幅图像、每个采样率,本文所提算法的PSNR值平均提高了2.9 dB,HFEN值平均降低了0.45。由此可知,本文所提算法与DLMRI算法和GradDLRec算法相比,重构质量有显著提高。 表1 不同算法重建图像的PSNR/HFEN值 为测试在有噪声情况下的稀疏采样性能,在K空间加入不同量级的高斯白噪声。图5是在不同的噪声标准方差下,3种算法在采样率为25%时对Shoulder1图像的重建性能曲线。从图中可以看出,无论在何种噪声量级中,本文算法的PSNR值都高于GradDLRec算法和DLMRI算法,特别是在高噪声情况下,PSNR值有显著提高。 图5 Shoulder1图像在不同量级噪声情况下的重建性能比较 图6给出了当噪声标准方差为20、采样率为25%时,3种方法对Shoulder1图像的重建效果。可以看出,由本文算法重构的图像更加清晰,对Shoulder1图像中的线条和纹理结构保持的最好。 图6 Shoulder1图像在3种算法下的重建图像 例如,在图中的白色方框位置,由DLMRI算法和GradDLRec算法重构出的图像由于受到噪声的干扰,出现了一些龟裂线条。而由本文算法重构出的图像,方框位置内的线条和细小结构均保持得很好。这是因为GradDLRec算法和DLMRI算法都采用KSVD训练字典,这种方法需要经验性地设置字典大小、稀疏度等参数。而在实际应用中,预先设置的参数往往会因具体每幅MR图像的差异而偏离真实值。基于BPFA模型的分类字典学习方法直接跳过这些设置环节,根据每幅MR图像数据自动推断参数,所以学习出的字典具有更强的表示能力。 为测试3种重建算法的收敛性能,观察3种重建算法在每次迭代时的PSNR值和HFEN值。图7是Brain2图像在采样率为46%时的PSNR值随迭代次数变化的曲线。从中可以看出,3种算法都具有良好的收敛性能。其中,DLMRI算法的收敛速度最快,但达到收敛时的PSNR值最低,为45.45 dB;GradDLRec算法的收敛速度相对较慢,达到收敛时的PSNR值相对较高,为49.21 dB;本文算法的收敛速度相对较慢一些,但达到收敛时的PSNR值最高,为51.39 dB,相对提高了5.84 dB和2.17 dB。 图7 3种算法的PSNR值与迭代次数的关系曲线 图8是Brain2图像在采样率为46%时的HFEN值随迭代次数变化的曲线,可以看出,3种算法都有良好的收敛性能。这是因为3种重建算法都是在字典学习和稀疏表示之间交替迭代求解,使其非负的目标函数单调递减。本文算法由于在梯度域中执行图像块的无限高混合聚类和利用BPFA进行字典学习,导致收敛速度有所降低,但重构效果最好。 图8 3种算法的HFEN值与迭代次数的关系曲线 假设图像块个数为N,图像块大小为P,字典大小为K,则稀疏阈值为T0=0.15P。在每次迭代中,DLMRI算法在稀疏表示和图像重构两个阶段的计算复杂度分别为O(PKNT0) 和O(Nlog(N)); GradDLRec算法在梯度变换、稀疏表示和图像重构3个阶段的计算复杂度分别为O(Nlog(N))、 O(PKNT0)、 O(Nlog(N))。 在本文算法中,假设每一类图像块的个数为Nj,则在稀疏表示阶段的计算复杂度为O(P(N1+N2+…+Ng))。 本文算法由于利用了非局部相似性,故又增加非局部相似块的搜索计算时间。虽然本文算法的计算复杂度有所增加,但能获得质量更好的MR图像。在获得相同质量的MR图像时,可以采用更低的采样率,这对医学成像而言具有重要意义。见表1,当要求Brain1重构图像的PSNR值达到47 dB以上时,GradDLRec算法和DLMRI算法分别需要38%和46%以上的采样率,而本文算法只需要使用低于25%的采样率即可满足要求。 本文利用差分变换稀疏和非局部相似性这两种先验信息,提出基于非参数贝叶斯分类字典学习的MR图像重建模型。实验结果相比经典的MRI重建方法而言,本文所提算法在相同的采样率下的重建质量更优,尤其在含有噪声情况下图像质量有显著提高,验证了该重构方法的有效性。由于采用了分类训练字典的策略以及对非局部相似块的搜索计算,本文算法运行时间较长,后续工作将在分类字典学习和非局部相似块搜索方面做进一步优化。3 实验及分析

3.1 参数设置
3.2 稀疏采样性能比较

3.3 有噪声稀疏采样性能比较


3.4 收敛性分析
3.5 计算复杂度分析
4 结束语
