基于BRAM的NVMe控制器原型仿真平台设计
2021-04-22冯志华王华卓安东博王红艳
冯志华,王华卓,安东博,罗 重,王红艳
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
近年来,面向PCIe接口的非易失性存储协议,简称NVMe协议,为固态硬盘(solid state disk,SSD)提供了高带宽、高吞吐量和低延迟的性能提升。在固态硬盘存储系统中,存储设备的容量、带宽、延迟、每秒进行读写操作的次数(input/output operations per second,IOPS)、可靠性和功耗等指标直接决定了存储服务质量,乃至整个系统的计算性能。其中基于闪存的存储设备在存储器技术领域引领了新的技术方向,填补了动态随机存储器与机械硬盘之间的性能差距,同时拥有较好的性价比指标。
在固态硬盘开发过程中,根据NVMe控制器搭建原型仿真平台,对各部分功能进行验证,以确保所开发固态硬盘的可用性。通过优化工程的结构复杂程度,可以有效降低功能验证过程中的时间成本。不但可以快速完成各部分功能的验证工作,加快开发迭代周期,还能帮助开发人员进一步评估设计改动对整体设计的影响,基于验证得到的结果改进后续设计方案。
为进一步降低工程的结构复杂程度,加速开发迭代周期,本文提出通过块随机存储器(block random access memory,BRAM)代替闪存作为存储介质,既而从工程中省略闪存控制器模块,优化工程结构,加速完成各部分功能的验证工作,能够适用于NVMe控制器的开发过程。
1 NVMe技术简介
1.1 NVMe协议
NVMe协议是针对IO到内存,特别是到非易失性闪存进行优化的一种基于命令的应用层协议,规定主机端和存储设备之间的通信方式,针对固态硬盘定义了存储器接口、指令集和功能集。相比于传统固态硬盘优化了数据传输路径和传输方式,提高数据传输效率,降低数据访问延迟,释放闪存存储介质的性能优势。
1.2 系统架构
NVMe协议驱动位于NVMe存储系统的主机端,是通用IO块层(block IO、BIO层)和NVMe控制器之间的软件层,负责将来自BIO层的I/O请求合成NVMe命令,通过PCIe Root Complex(以下简称RC)下发到主机端内存中的NVMe命令提交队列中,等待NVMe控制器来获取命令;RC是高速串行计算机扩展总线标准体系结构(peri-pheral component interconnect express,PCIe)的一个重要组成部件,RC并非本设计关注重点,而且RC的相关细节也被包含在操作系统的PCIe基础驱动中[1],因此对于RC的形式和分担的功能不做深入解释。
NVMe控制器位于NVMe存储系统的设备端[2],NVMe控制器通过RC从主机端内存中获得主机下发的命令后,将获取的数据包进行拆解获取命令的相关信息,将其发送到软核处理器MicroBlaze进行命令处理;当NVMe控制器处理完成命令后,通过中断响应机制通知主机端命令执行已完成[3]。主机端接收到命令处理完成的中断响应后,会暂停其它任务,优先处理保存在主机内存中的NVMe命令完成队列中的完成信息,之后根据完成信息对设备端下发的命令完成指令,同时释放内存资源[4]。
NVMe原型仿真主要是根据NVMe标准协议对NVMe控制器进行设计与验证,因此本设计没有采用传统NVMe存储系统使用NAND闪存(NAND flash memory,NAND Flash)作为存储介质的方案[5],而是使用BRAM替代NAND Flash作为存储介质,继而省略掉Nand控制器模块,以及软件部分中闪存转换层部分(flash translation la-yer,FTL),包括磨损均衡、垃圾回收等复杂算法。存取数据时通过片内总线直接从BRAM中读取或写入。克服现有仿真控制器的速度慢、结构复杂的缺点,能够实现快速、方便的仿真,适用于高性能NVMe控制器的开发验证,如图1所示。

图1 存储系统整体架构
1.3 初始化与命令处理
主机在对NVMe设备初始化过程中需要了解NVMe设备的容量、逻辑块大小等信息,这些信息均由identify命令获取[6]。对NVMe控制器的初始化流程包括:
(1)基于系统配置,设置PCIe寄存器。当IO队列数量确定之后,配置中断方式;
(2)等待控制器RDY信号为‘0’,表明控制器已复位;
(3)配置管理队列相关信息,包含AQA (admin queue attributes),ASQ(admin submission queue base address),ACQ(admin completion queue base address)等寄存器;
(4)配置控制器配置(controller configuration,CC)寄存器,包括在CC.MPS中初始化内存页大小、在CC.AMS中选择命令仲裁机制以及在CC.CSS对IO Command进行配置;
(5)配置控制器配置使能,即配置CC.EN为‘1’;
(6)等待控制器表明已经准备好处理命令,不断向控制器发送读控制器状态(controller status,CSTS)寄存器的信号,直到控制器CSTS.RDY为‘1’时停止;
(7)向NVMe控制器发送Identify命令,获取Controller data structure和Namespace data structure;
(8)通过Set Feature命令决定IO提交队列和IO完成队列的数量,然后再配置中断寄存器;
(9)根据系统配置需求和控制器的数量需求,使用创建IO完成队列命令分配IO完成队列;
(10)根据系统配置需求和控制器的数量需求,使用创建IO提交队列命令分配IO提交队列;
(11)如果想要获取可选项的异步通知,应该发送Set Feature命令去使能此项功能。
在执行完上述初始化过程后,NVMe设备端可用来执行端下发的IO指令。主机端内存中有两种队列,提交队列(submission queue,SQ)和完成队列(completion queue,CQ),分别用来存放提交命令和完成命令。提交队列存放下发给NVMe设备端的命令(64字节),完成队列存放NVMe设备端返回的完成命令(16字节)。通过写提交队列门铃信号通知NVMe控制器有新的命令需要处理,NVMe控制器检测到门铃信号之后,从提交队列中读取命令;完成命令之后,NVMe控制器回传命令完成报文到完成队列,命令执行的具体流程包括:
(1)主机端将NVMe协议命令封装之后写到内存的提交队列中,更新提交队列的尾指针;
(2)将提交队列的尾指针写到NVMe控制器的门铃寄存器中,通知设备有新的命令需处理,等待设备获取;
(3)设备端通过轮询门铃寄存器,得知有新的命令要处理,立即从提交队列中将命令取到设备固件上;
(4)设备进行命令执行,若是读命令,则通过DMA将数据传输到内存相应的位置;若是写命令,则通过DMA将数据从内存传输到设备中,然后写到对应的介质上;
(5)设备执行命令后,将执行结果封装在完成包中,传输到相应的完成队列中。完成包中包含了命令的执行情况,如命令是否正确执行,或者是否因为数据无法访问或者执行超时产生了错误等;
(6)设备发送MSI-X中断通知有新的命令完成包;
(7)选取新的完成包进行处理,从命令完成包中的内容可以得知命令的完成情况,然后进行相应的处理;
(8)写相应完成队列的门铃寄存器,告诉控制器完成包已经处理结束,设备释放完成包占用空间。至此,命令处理结束。
2 关键技术
2.1 NVMe原型仿真平台整体架构
主要由NVMe IP、MICROBLAZE、AXI_BRAM、AXI_INTC、AXI_INTERCONNECT等模块组成,系统架构如图2所示。NVMe IP模块包含了NVMe协议处理过程的可编程逻辑(programble logic,PL)部分与PCIe模块共同组成了NVMe原型仿真平台与主机端交互的底层接口;剩余的MICROBLAZE、AXI_BRAM、AXI_INTC、AXI_INTERCONNECT等模块均为赛灵思官方提供的功能性模块。MICROBLAZE包含了NVMe协议命令处理过程的可编程系统(programble system,PS)部分,二者协同处理由主机端下发的NVMe命令。AXI_BRAM作为存储器,用于存储Identify数据以及主机端写入的数据。AXI_INTC模块是一个中断控制器,通过AXI总线挂在MICROBLAZE上,用于处理NVMe命令处理完成时产生的中断。AXI_INTERCONNECT模块用于NVMe_IP模块、MICROBLAZE、AXI_BRAM、AXI_INTC各模块之间的数据传输[7,8]。

图2 NVMe原型仿真架构
2.2 PCIe模块
该模块由赛灵思官方提供的PCIe Gen3.0 IP核和PCIe传输模块两部分组成,如图3所示。

图3 PCIe IP与NVMe IP间的数据交互
PCIe Gen3.0 IP核集成了标准的PCIe协议以及与外部通信的AXI-S接口,通过AXI-S总线协议进行数据传输。PCIe Gen3.0 IP的AXI-S总线为4个,分别是m_axis_cq_*(接收端请求信号)、 m_axis_rc_*(发送方完成信号)、s_axis_rq_*(发送方请求信号)、s_axis_cc_*(接收端完成信号),请求端接口和完成端接口完全分开[9]。
PCIe传输模块则用于PCIe IP核与NVMe IP模块之间的数据交互,在NVMe原型仿真平台中起承上启下的作用,它一方面与PCIe IP核进行数据通信,另一方面通过AXI总线与NVMe IP模块中其它子模块进行交互。它通过m_axis_cq_*、m_axis_rc_*系列信号接收来自PCIe IP的数据报文,并对TLP包进行解析;通过s_axis_rq_*、s_axis_cc_*系列信号将组装好的TLP包发送到PCIe IP。PCIe传输模块主要通过存储器读请求(memory read request,MRd)、存储器写请求(memory write request,MWr)、完成包数据(completion with data,CPLD)3种格式的TLP包进行主机端和NVMe原型仿真平台之间的信息交互。
其中主机端通过MRd数据包从设备端中读取寄存器信息;通过MWr数据包来操作设备端的寄存器,也可以向设备端中写入数据,最终写入到BRAM;通过CPLD数据包来传输完成命令中的数据包到主机端;另外MSI数据包是设备端向主机传递到的中断信号。NVMe IP模块从PCIe传输模块中获得主机的下发的TLP包之后,按照不同类型的数据包,传递给不同子模块进行处理;当处理完成后,通过MSI数据包通知主机命令执行已完成。
2.3 NVMe IP模块
该模块由控制器寄存器模块、内部寄存器模块、命令处理模块以及中断模块组成。
2.3.1 控制器寄存器模块
该模块用于NVMe IP模块与主机软件部分进行通信,主机软件需要检测NVMe IP状态时,会通过读取控制器寄存器来判断当前所处状态;主机软件也可通过配置控制器寄存器状态来操作NVMe IP模块。寄存器模块均通过PCIe以MWr、MRd、CPLD报文形式进行传输,由于寄存器最大数据位宽为64位,所以对于MWr报文和CPLD报文,负载数据长度均不超过2DW。在PCIe模块中MWr、WRd数据包已经存储在FIFO中,因此控制器寄存器模块对于接收到的TLP报文处理流程为:
(1)判断FIFO是否为空,如果FIFO不空,表示有TLP报文写入,则该模块需要从FIFO中读取TLP报文,获取出TLP报文头;
(2)通过TLP报文头中Req Type字段确定TLP的类型;
(3)如果TLP为MWr报文,则需要再从FIFO中读一次数据,把负载数据读取出来,写给内部寄存器;
(4)如果TLP为MRd报文,则不用再从FIFO中读取,需要将主机所读取地址信息中的数据通过CPLD报文发送给主机。
2.3.2 内部寄存器模块
该模块是NVMe原型仿真平台内部处理器与FPGA通信时使用的寄存器,是CPU与FPGA协同工作的纽带,用于PS与PL间的数据交互,共同完成NVMe命令处理、数据的DMA传输、PCIe状态处理等任务。在NVMe命令处理过程中,PS从内部寄存器模块中读取从主机端下发的NVMe命令,通过OPC字段分析命令类型,按照不同命令类型,给PL下发相应的指令。PL按照PS下发的指令,进行后续处理,直至命令处理完毕,产生完成命令。
内部寄存器包括控制器准备信号、IO完成队列使能信号、IO提交队列使能信号、IO完成队列中断信号、IO提交队列基地址、IO完成队列基地址、IO提交队列空间大小、IO完成队列空间大小、IO完成队列向量、数据存放地址等寄存器。另外包含3个NVMe完成命令寄存器和4个DMA命令寄存器。
该模块与CPU通信的接口为AXI_Lite接口,传输数据位宽为32位,在CPU进行写寄存器操作时,取地址的高位作为使能信号,地址低位作为具体地址。NVMe完成命令分配有3个地址,在写完第3个地址时,需要给出写FIFO使能信号,用于存储NVMe完成命令。即在写寄存器地址等于0x30c时,给出使写能信号r_awaddr_hcmd_cq_wr1_en,表示将存储完成命令数据。DMA命令分配有4个地址,在写完第4个地址时,同样需要将DMA命令存储到FIFO中。在写寄存器地址等于0x31c时,给出使能信号r_awaddr_dma_cmd_wr_en,表示将存储DMA命令数据。当需要数据写入其它寄存器时,用r_s_axi_awaddr[7∶2]表示低八位地址,低两位默认为0。
2.3.3 命令处理模块
该模块是NVMe原型仿真平台中的重要模块,主要作用是从主机内存中获取提交队列命令,与PS部分配合对获取的NVMe命令进行相应的处理,完成后向主机发送完成队列命令。
命令处理模块分为提交队列命令处理和完成队列命令处理两部分。其中提交队列命令处理模块处理主机的门铃信号,通过与本地维护的提交队列头指针r_sq_head_ptr[7∶0]进行比较,如果不一致,则表示主机内存中有新命令需要处理,此时向PCIe数据传输模块发起MRd读请求。读取到提交命令后,该模块将从读取的命令中提取逻辑块起始地址(starting logical block address,SLBA)、数据占用逻辑块数量(number of logical blocks,NLB)、页地址空间(physical region page,PRP)等信息存在对应的FIFO中,并更新本地提交队列的头指针。PS检测到hcmd_sq_fifo中不为空时,则从FIFO中读取命令进行软件部分处理。命令完成队列处理模块接收从命令完成标志cpl_status[14∶13],向PCIe传输模块发出MWr请求,发出命令完成报文。该模块接收的命令完成标志有两个来源,第一个是PS下发的完成标志,PS在处理管理命令后,会通知PL端命令已完成;第二个是IO命令中数据传输完成后,该模块会收到数据传输完成的标志,再向主机发送完成命令报文。
2.4 软件部分
NVMe控制器的软件部分通过FPGA上的MICROBLAZE软核来完成。PS不断从内部寄存器NVME_CMD_FIFO_REG_ADDR中读取NVMe命令,通过Quene Identify的值判断是Admin命令还是IO命令,如图4所示。

图4 NVMe命令解析流程
NVMe Admin命令处理部分可支持NVMe1.3协议规定的大部分管理命令,不支持Abort管理命令。从命令处理主函数输入为NVMe命令结构体的nvmeCmd,通过cmdDword第一个Dword得到操作码OPC,用来区分不同的Admin命令,从而进入到不同的子函数中进行命令处理,如图5所示。
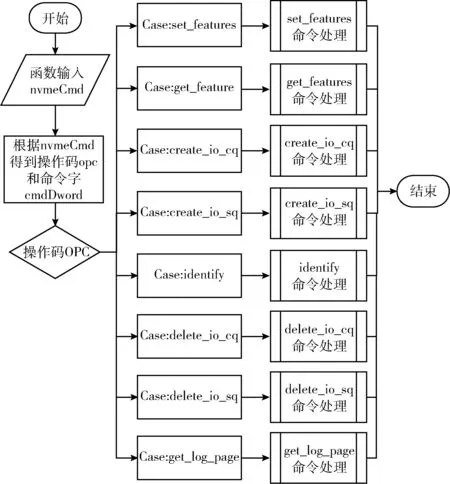
图5 Admin命令处理流程
NVMe IO命令处理部分通过AXI_Lite从NVMe IP的FIFO中读取命令,从中获取PRP、SLBA、NLB等信息,通过地址映射确定BRAM中的物理地址。此处通过DMA直接将数据从DDR存储到BRAM中,因此软件部分也可以省略FTL部分,包括磨损均衡、垃圾回收等复杂算法。
2.5 可扩展性
本文设计的NVMe原型仿真验证方案能够支持基础的NVMe管理命令如Set Features、Identify、Get Log Pagede等以及读写IO命令。同时支持自定义开发验证,可以在NVMe IP的命令处理模块中添加待验证功能的逻辑代码,在控制器内部寄存器中添加该命令的OPC、QID等状态信息,同时软件部分更新相应命令的处理流程,最后在仿真文件sample_tests.vh中添加对应的激励信号用来验证功能的实现程度。除此之外该设计可以通过改变主机端下发数据文件大小,验证数据大小对NVMe存储速度的影响,下文仿真过程将实现4 K数据文件的写操作。
3 仿真验证
3.1 仿真环境
在Windows10操纵系统下使用VIVADO 2017.4开发工具进行仿真实验。根据NVMe1.3协议中的指令操作流程,通过TestBench模块模拟主机端对NVMe设备端下发指令的过程,包括寄存器配置信号、配置控制器使能信号、等待RDY信号、下发提交队列门铃信号以及下发提交队列命令等指令信号。
3.2 仿真过程
通过IO写命令来执行写4 K数据的操作,将数据通过处理器直接写到BRAM中。验证NVMe控制器原型仿真平台能否正确执行初始化以及IO读/写命令,实现基本的读写功能。通过所占用硬件资源情况对比,体现工程结构优化前后结构复杂度的变化,同时关注仿真过程耗时情况,体现仿真平台对于加快NVMe控制器功能验证的功能。
首先主机端通过rq接口信号发送MWr请求写提交队列门铃信号,如图6所示。s_axis_rq_tdata[15:0]=0x1008表示I/O命令的提交队列门铃信号地址,s_axis_rq_tdata[159:128]=0x00000001表示I/O命令的第一条命令。

图6 发送MWr请求写提交队列门铃信号
NVMe控制器的cq接口信号接收到主机端发过来的MWr请求信号,如图7所示。第一包TLP包头s_axis_cq_tdata[15∶0]=0x1008表示I/O命令的提交队列门铃信号地址,第二包TLP数据包s_axis_cq_tdata[31∶0]=0x00000001表示I/O命令的第一条命令,和主机端发送的数据一致。

图7 接收主机端发过来的MWr请求信号
当检测到提交队列门铃信号更新表示有命令送入NVMe控制器,所以NVMe控制器通过rq接口发送MRd请求信号,如图8所示。其中m_axis_rq_tdata[78:75]=0x0表示MRd请求,m_axis_rq_tdata[31:0]=0x76543210表示创建IO提交队列(Creat_IO_SQ)中PRP1地址,即从主机内存中读取数据包的地址。

图8 NVMe控制器发送MRd请求信号
主机端通过cq接口信号接收NVMe控制器发送过来的MRd请求命令,如图9所示。可以看到m_axis_cq_tdata[31∶0]=0x76543210为PRP1地址,和NVMe控制器发出的数据包一致。

图9 接收NVMe控制器发送过来的MRd请求信号
主机端接收到MRd请求信号后,通过cc接口返回CPLD包报文,如图10所示,此512 bit全部为有效数据。

图10 主机端接收到MRd请求信号
NVMe控制器通过rc接口接收到CPLD包数据如图11所示,第一包s_axis_rc_tdata[127∶0]=0x10001a00601a0001000404210,第二包s_axis_rc_tdata[127∶0]=0x01,第3包s_axis_rc_tdata[127∶0]=0x8cb7c00000000000,第4包s_axis_rc_tdata[127∶0]=0x0,第3个数据包中s_axis_rc_tdata[63∶32]=0x8cb7c000代表PRP1的地址,s_axis_rc_tdata[127∶96]=0x0代表PRP2的地址,前3包数据都是128 bit有效,根据s_axis_rc_tkeep[3∶0]=0x0111可知最后一包数据是低96Bit有效。

图11 NVMe控制器接收CPLD命令包信号
NVMe控制器接收完主机端的CPLD命令包之后,控制器再继续发送MRd数据请求包,读取待写入NVMe控制器的数据,以实现I/O写命令,将主机中的数据写往BRAM中。
NVMe控制器通过rc接口收到主机端的CPLD数据包,如图12所示第一包数据s_axis_rc_tdata[127∶0]=0x443300000001a01001a0002000804000,第二包数据s_axis_rc_tdata[127∶0]=0x554433221100987654321099887-76655,第3包数据s_axis_rc_tdata[127∶0]=0xeeddccbbaaefcdab,第4、5、6、7、8包数据s_axis_rc_tdata[127∶0]=0x0,总共有1024 bit数据和主机端下发的一致。在I/O写命令中总共写了4 KB数据,每次写128 bit数据,共写入32次。初始地址是0x8cb7c000,按照32次写入每次0x80依次递增到0xh8cb7cf80,至此整个I/O写命令完成。

图12 收到主机端的CPLD数据包信号
上述仿真过程表明本文设计的基于BRAM的NVMe控制器原型仿真方案能够正确执行主机端下发的NVMe命令,实现NVMe仿真平台的基本功能。同时通过该工程仿真过程中的综合布线报告可以得知,在相同仿真环境下,在使用BRAM作为存储介质时所使用的FPGA内部逻辑资源相比于使用闪存作为存储介质时减少约25%,仿真环境内存占用率峰值下降约16.7%,仿真用时缩短约47%,见表1。

表1 NVMe原型仿真对比数据
4 结束语
本文设计了基于BRAM的NVMe控制器原型仿真验证方案,具有集成度高、可扩展性强、可运用灵活等特点,适用于适用于NVMe控制器的开发和验证。现阶段能够支持主要的NVMe管理命令以及读写IO命令,后续NVMe控制器还可以进一步用于开发NVMe命令仲裁机制、命令硬件卸载提速[10]、IO命令的分散聚合表(scatter gather list,SGL)寻址、指令乱序优化等功能,实现更高性能的NVMe控制器从而应用于存储技术的飞速发展中。
