基于相似度的三角模糊数组合预测模型*
2021-04-22谢小军乔希民
谢小军, 马 虹, 乔希民
(①广州工商学院,510850;②广东金融学院,510521,广东省广州市 )
0 引 言
1994年,Song在模糊集理论的基础上,研究并构建了模糊时间序列预测模型[1],打开了人们对模糊时间序列理论和应用研究的大门,此后对于模糊时间序列的研究受到越来越多的专家和研究者的关注与重视,从预测方法主要分为单一预测和组合预测方法,由于预测对象的复杂性和不确定性,利用单一方法进行预测其结果往往不够精确,甚至可能产生较大的偏差.为了改善此类问题,组合模型得到了发展[2],组合模型具有更好的预测效果,因此受到许多国内外学者的青睐,并开展了大量的研究.前期对组合预测方法的研究对象大多数是实数,但因事物的模糊性和不确定性,大多数是以区间数的形式表示,近几年对于区间数组合预测模型的研究比较多.例如文献[3]以区间长度和区间中心的误差平方和的凸组合为最优准则,结合诱导有序加权平均(IOWA)算子,构建了一种区间组合预测模型.文献[4]引入相关系数概念并集成IOWA算子,构建了多目标的区间组合预测模型.文献[5]利用对数误差平方和作为最优准则构建了IOWGA算子的变权系数最优组合预测模型.文献[6]基于不确定加权Power平均(UWPA)算子构建了连续区间组合预测模型.文献[7]结合诱导有序加权调和平均算子与向量夹角余弦,构建了联系数型区间组合预测最优化模型.文献[8]基于诱导连续有序模糊加权平均(ICOFWA)算子,构建了模糊连续区间变权组合预测模型.文献[9]采用灰色趋势关联度为相关性指标,构建了基于灰色趋势关联度的诱导有序加权的连续区间广义有序加权调和平均算子的区间数组合预测模型.文献[10]引入COWG-WPA算子,建立了基于连续区间有序几何加权平均Power算子的区间型组合预测模型.
随着社会经济的不断发展,系统的复杂性与事物的不确定性不断提高,导致事物更具模糊特征,因此用三角模糊数来描述事物的特征成为未来的趋势,例如气温的最低和最高温度可以表示三角模糊数的左端点和右端点,平均温度表示其中点.研究三角模糊数组合预测模型既具有理论意义也具有现实意义.在模糊环境下,三角模糊数是刻画事物的一种常见的不确定信息的表达形式,它弥补了实数和区间数的不足.另一方面,三角模糊数可以利用其隶属函数更好的描述事物的特征.目前针对三角模糊数为研究对象的预测方法文献相对较少,主要分为:(1)直接以三角模糊数的三个界点建立预测模型或者利用成熟的单一模型[11-13].直接对三角模糊数三个界点进行建模和预测会的缺陷是:a.不能很好的描述序列整体性的发展趋势;b.建立的模型所预测的结果容易发生错乱,导致预测失效.(2)将区间数转换为对称三角模糊数[14,15],并利用组合模型进行预测,但是对于一般三角模糊数并没有提出行之有效的方法.因此对于提出有效组合模型能够降低一般三角模糊数的预测误差具有重要的理论意义与实际价值.
文章出于数据整体性考虑,首先将三角模糊数序列转换成等量信息的三个指标数序列, 然后采用三角模糊数的相似度作为最优准则的度量指标,并引入广义诱导有序加权平均(GIOWA)算子,最终建立了基于三角模糊相似度的GIOWA算子的变权系数的三角模糊数组合预测模型.通过数据实验表明了该方法的可行性和有效性,成功的将目前研究者提出的有效组合预测方法推广的到三角模糊数上,与单一方法对比,预测精度都有明显提高.
1 理论基础
定义1[16]设序列X=(x1,x2,…,xn),其中xi=(ai,bi,ci),(i=1,2,…,n),若满足ai≤bi≤ci,则称xi为三角模糊数,当左端点ai≥0时称为非负三角模糊数,满足bi-ai=ci-bi时,称其为对称三角模糊数,满足ai=bi=ci时,即为普通实数序列.其隶属函数为
设两个三角模糊数序列xi=(ai,bi,ci)和xj=(aj,bj,cj)(i≠j),则有运算性质
(1)xi=xj⟺ai=aj,bi=bj,ci=cj;
(2)xi±xj=(ai,bi,ci)±(aj,bj,cj)=(ai±aj,bi±bj,ci±cj);
(3)kxi=(kai,kbi,kci).
定义2[13]设三角模糊数序列X=(x1,x2,…,xn),其中xi=(ai,bi,ci)的隶属函数所覆盖的面积构成的实数序列定义为面积序列, 记为S=(s1,s2,…,sn),其中
si=(ci-ai)/2.
(1)
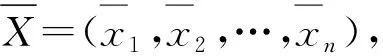
(2)
三角模糊数的各个中界点构成的实数序列记为中界点序列M=(b1,b2,…,bn).
上述方法将三角模糊数序列转换成了等量信息的3个指标:面积序列、重心序列、中界点序列.由此3个指标序列也可以推导出原三角模糊序列的上下两个界点
(3)
转换后的序列同时受到三角模糊数的3个界点的约束,从而保持了模糊数的整体性, 且避免了模糊数的3个界点产生跳跃, 也让序列的光滑性更好.
定义3[16]设两个三角模糊数序列xi=(ai,bi,ci)和xj=(aj,bj,cj),0 为三角模糊序列xi和xj的相对相似度.可知S(xi,xj)越大,xi和xj相似程度越大,特别S(xi,xj)=1时,xi=xj,任意两个三角模糊数序列xi、xj具有如下性质 (1) 有界性:0≤S(xi,xj)≤1; (2) 自反性:S(xi,xi)=1; (3) 对称性:S(xi,xj)=S(xj,xi). 定义4[14]设GIOWAW:m→为m元函数,W=(w1,w2,…,wm)T为加权向量,满足若 则称GIOWAW是u1,u2,…um所构成的m维广义诱导有序加权平均算子,简记为GIOWA算子. (4) (5) (6) 为了验证本文提出的方法是可行和有效的,本文以选取北京市2000—2009年年平均最低气温、年平均气温、年平均最高气温构建三角模糊数序列的3个界点,总共10组数据,利用公式(1)和(2)转换为对应的等量信息的面积指标、中界点,重心指标序列,并构建各单一预测模型,最后利用还原公式(3)得到拟合预测结果见表1. 表1 实际三角模糊数序列与三种单项预测方法拟合预测结果 将面积指标、中界点、重心指标序列拟合预测值分别利用公式(4)、(5)、(6)可得各单项预测方法预测精度(见表2),对于模型参数λ这里随机选取5个特殊的值,取λ=-6,λ=-1,λ=0.2,λ=1,λ=6,将表2的预测精度作为GIOWA算子诱导值,代入参数λ,利用Lingo10软件求解得模型的最优权系数见表3. 表2 单项预测方法各时点面积指标、中界点,重心指标序列的预测精度 表3 各参数值对应的组合模型的最优权系数 表4 各界点在本文组合模型不同的参数值下的预测值 表5 本文组合模型与各单项预测方法预测效果评价指标 利用表3和定义4,将各单项预测方法的各界点的预测值加权得到组合模型的各界点的预测值见表4.为了验证本文提出的模型的有效性,利用定义5计算各单一方法与本文提出的组合预测模型的各评价指标,结果见表5. 由表5可知,本文提出的基于模糊相似度的三角模糊数组合预测模型的4个指标MSES、MSEG、MSEM、MSEI的数值均都小于各单项预测方法,因此与各单项预测方法对比,本文提出的基于模糊相似度的三角模糊数组合预测模型是有效可行的,能够有效提高三角模糊数的预测精度. 目前对于三角模糊数序列的组合预测研究相对还不成熟,有必要开展三角模糊数序列组合预测方法以及理论研究.本文通过对三角模糊数进行研究分析,研究了普遍三角模糊数的特点,以三角模糊数的相似度作为最优准则的度量指标,将三角模糊数用等量信息的三个指标进行替代,引入GIOWA算子,提出了一种基于相似度的GIOWA算子的变权系数的三角模糊数组合预测模型.最后通过实例分析验证本文方法的可行性和有效性,与单项方法比较,能够有效提高三角模糊数的预测精度.
2 基于相似度的三角模糊数组合预测模型的建立


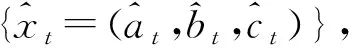

3 实例分析





4 结 语
