基于人工神经网络和支持向量回归机的干旱预测
2021-04-21赵国羊涂新军谢育廷莫晓梅
赵国羊,涂新军,2,3*,王 天,谢育廷,莫晓梅
(1.中山大学土木工程学院,广东 珠海 519082;2.中山大学水资源与环境研究中心,广东 广州 510275;3.广东省华南地区水安全调控工程技术研究中心,广东 广州 510275;4.中山大学地理科学与规划学院,广东 广州 510275)
干旱是一段时间内当降水量明显低于正常水平时发生的一种自然现象,其随时间发展缓慢、成因复杂,并且持续时间长、影响范围广[1]。干旱对自然环境和人类生活及社会经济等造成重大破坏,是现今世界上最广泛、最常见、最具灾难性的自然灾害之一,远比其他气象灾害所造成的损失更巨大[2]。从全球范围内来看,在发生的自然灾害中,22%的经济损失以及受影响人数的33%可归因于干旱[3]。干旱不仅受降水、气温以及蒸散发量等自然因素影响,还与人类活动如过度耕作、过度灌溉、砍伐森林、过度开采可用水等密切相关。近年来随着全球气候变暖及社会经济高速发展等影响,干旱发生的频率增加、强度变大、范围变广,造成的破坏更加严重[4],已经引起国内外广泛关注[5-7]。在国内,这种干旱加剧现象不仅出现在水资源相对贫乏的北方地带,也频繁发生在水资源相对丰富的南方湿润地区[8-9]。因此,准确的干旱预测,对于流域自然资源条件、地区水资源规划管理、缓解旱情的有害影响等具有重要作用,并为干旱的监测、预警及风险的评估提供科学依据,有助于相关部门优化水资源系统的运行,做好相应的防旱减灾措施及决策分析。
干旱指数通常被用来识别干旱事件及表征干旱严重程度,基于干旱指数的干旱预测近年来受到关注[10]。常用的干旱指数有标准化降水指数(Standardized Precipitation Index,SPI)[11]、标准化降水蒸散指数(Standardized Precipitation Evapotranspiration Index,SPEI)[12]、Palmer干旱指数(Palmer Drought Severity Index,PDSI)[13]等。干旱预测模型有物理模型和数据驱动模型。物理模型考虑不同的物理成因,对干旱成因进行分析,但由于其需要的数据类型和模型参数较多,模型过于复杂,多数时候难以在预测中实现。而数据驱动模型对数据要求及模型复杂性低,已经被广泛应用在各种水文预报中。Hudson、Abbot等[14-15]使用数据驱动模型和物理模型对降水量预测进行比较,发现前者相比后者的预测结果有显著改善。对于数据驱动模型主要有统计方法[10]和机器学习方法[16-18]。由于统计模型在处理非线性问题能力有限,而机器学习技术如人工神经网络(Artificial Neural Network,ANN)和支持向量机(Support Vector Machine,SVM)因其固有的非线性特性和建模的灵活性,已被应用在水文预测领域中。而ANN方法存在隐含层节点数难以确定、易陷入局部极小值等缺陷,一定程度上会影响其预测效果。Mokhtarzad 等[19]基于SPI进行干旱预测结果表明SVM比ANN更准确;Borji 等[20]用ANN和SVM对径流干旱指数进行预测,发现SVM预测效果更好。
目前研究一般基于3个月及以上时间尺度的干旱指数进行干旱预测,而对于短时间尺度的干旱指数序列如1个月时间尺度的SPEI1序列,由于存在高度非线性、变化剧烈的特征,直接使用ANN和SVR预测拟合精度不高。一种可对序列进行多时间尺度分解的经验模态分解(Empirical Mode Decomposition,EMD)方法,可将原序列分解成频率不同的分量,挖掘数据本身隐含的信息,能够提高ANN和SVR预测拟合精度。席东洁、范琳琳等[21-22]将EMD和ANN结合,发现可提高月径流预测精度。刘嘉[23]结合EMD和SVM进行大坝变形预测,发现比SVM预测效果更好。由于分解后得到的高频成分通常含有噪声,掩盖了数据真实特性,影响预测效果,而小波消噪技术可以实现信噪分离,减少干扰,提升预测精度[24]。
本文采用SPEI干旱指数,构建ANN、SVR、EMD-ANN和EMD-SVR预测模型,并应用于东江流域开展1~3个月预见期的干旱预测,对比分析干旱预测模型的适应性,为流域干旱预警和管理提供技术依据。
1 数据与方法
1.1 研究区域及数据
东江发源于江西寻乌县,是珠江三大水系之一。东江流域地处亚热带季风湿润气候区,干湿特征明显。流域内多年平均降水量约为1 795 mm,年内分配不均,汛期降水占全年80%以上。年均气温为20~22℃,年内差别不大,多年平均蒸发量约为1 200 mm。本文采用东江流域1956—2019年多个站点的月降水量和月平均气温数据,用泰森多边形法得到区域月均面降水及气温数据。东江流域主要站点分布见图1。
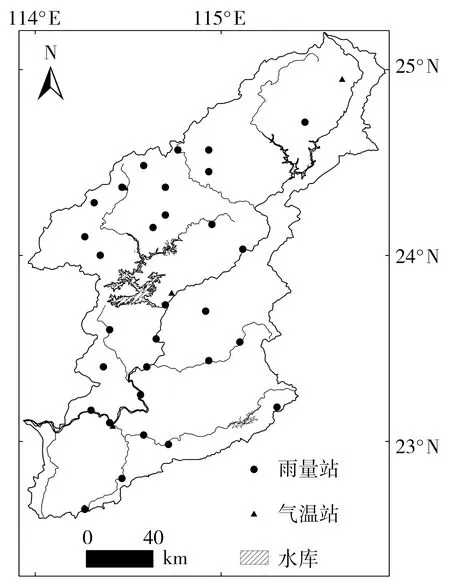
图1 东江流域主要站点分布
1.2 研究方法
1.2.1标准化降水蒸散指数
干旱涉及不同的时空尺度,PDSI、SPI、SPEI等指数是干旱评估的常用指标。PDSI对数据要求高,计算相对复杂,在干旱的多时间尺度应用上有所欠缺,在空间尺度上也不能够很好地适用于大部分地区。对于SPI和SPEI,资料获取容易,计算简便,且能很好反映不同时空尺度的干旱特征,实用性强,应用范围广。SPI仅考虑降水却未能表征温度对干旱的影响,而SPEI体现了降水和温度对干旱的作用,适合研究全球变暖背景下干旱特征的响应,是国内外研究干旱的理想指标。
东江流域即使在非夏季,温度也相对较高,由此引起流域内蒸散发量高也是造成干旱的原因。故选取SPEI,并采用1、3、6和12个月时间尺度的SPEI1、SPEI3、SPEI6和SPEI12进行干旱预测。SPEI计算采用基于三参数的Log-logistic概率分布模型[25]。
1.2.2模型构建
ANN和SVR是近年来被广泛应用于水文预测领域的新方法。本文对不同时间尺度的SPEI序列构建ANN和SVR模型。SPEI序列数据前75%为训练集,剩余25%为测试集。SPEI与降水、温度相关且具有一定的自相关性。对SPEI进行自相关性检验,滞后前6期自相关系数结果见表1,由表1结果知SPEI具有自相关性。因此降水和温度取前2个时期(Pt,Pt-1)和(Tt,Tt-1)、SPEI取前6个时期(St,St-1,St-2,St-3,St-4,St-5)为模型的输入[19],t+N时期的SPEI(St+N)为模型输出,其函数映射为:
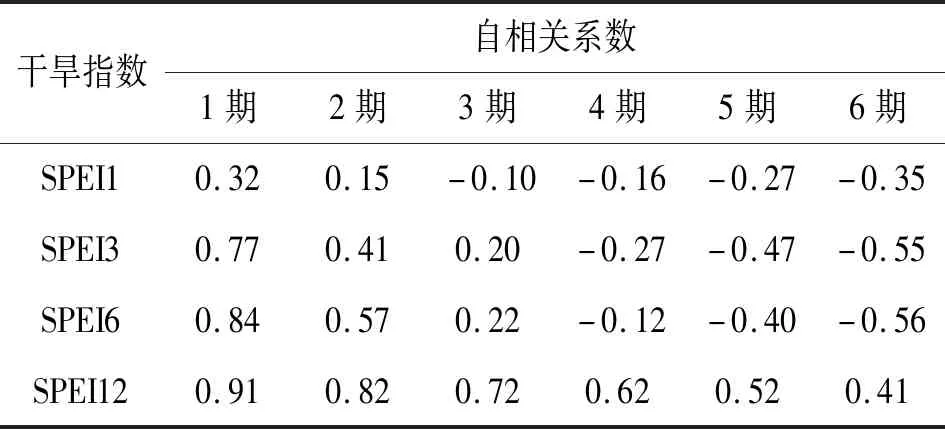
表1 SPEI自相关性检验
St+N=f[(Pt,Pt-1),(Tt,Tt-1),(St,St-1,St-2,St-3,St-4,St-5)]
(1)
式中S——SPEI;P——降水;T——温度;N——预见期,本文分别取N=1,2,3。
1.2.3人工神经网络
人工神经网络(ANN)是一种基于与神经元大规模交互作用的并行分布式数据处理系统,非线性映射能力强,能很好地识别输入和输出变量之间的关系而无需明确定义二者间的物理关联,模型易于使用,有较强的鲁棒性和容错性。神经网络一般由输入层、隐藏层和输出层组成,有研究表明仅有单个隐含层的3层网络结构就可实现任意非线性函数的逼近。
本文选用含3层结构的BP神经网络,BP神经网络是采用反向传播算法对网络权、阈值和偏差不断进行调整以达到期望输出的一种前馈网络。隐含层节点数根据试错法来择定,由于ANN初始权、阈值及其调整的不确定性,对模型进行多次训练及预测,并取其中最优5个结果的均值作为最终预测结果。隐含层神经元选用双曲正切S型传递函数(tansig),输出层神经元选用线性传递函数(purelin)采用梯度下降法(traingd)来训练网络。训练误差目标函数采用均方根误差(MSE),网络最大迭代次数为20 000次,学习率为0.05。
1.2.4支持向量机
支持向量机(SVM)是Vapnik[26]提出的一种机器学习方法,主要可分为支持向量分类机(Support Vector Classification,SVC)和支持向量回归机(Support Vector Regression,SVR),分别解决分类和回归问题。SVM基本思想是基于统计学习理论,通过非线性映射,采用结构风险最小化原则,将低维空间和线性不可分的数据映射到高维空间使其成为线性可分的,再将数据在高维空间进行分类和预测。SVM可有效避免局部极值问题,最大限度地提高预测精度,同时防止数据过拟合,并根据有限样本信息,在模型复杂度和学习能力之间寻找最优值,提高其泛化能力。
核函数选用和相关参数设定是SVM的关键,本文选用SVR模型,核函数选择应用最广泛的径向基核函数,因它适用于不同样本及各种维度问题的处理且具有很强的非线性映射能力。SVR模型中的惩罚因子C、核参数g以及损失系数ε,用网格搜索算法来寻其最优值。
1.2.5经验模态分解和小波消噪
由于SPEI1序列随时间波动剧烈,ANN和SVR模型对其预测精度有限,故针对SPEI1结合经验模态分解(EMD)和小波消噪对模型进行改进。EMD是Huang等[27]提出的一种适用于非线性、非平稳数据的处理方法,可自适应地将序列分解成多个固有模态函数(Intrinsic Mode Function,IMF)及残余项之和。本文拟对SPEI1进行EMD处理,得到3个IMF(IMF1、IMF2、IMF3)分量和1个残余项。
另一方面,时间序列数据受到多种因素影响会含有噪声,直接将含噪数据输入到模型中会影响预测精度。小波消噪是被广泛采用的去除噪声方法,其主要是对含噪数据通过小波变换得到消噪后的数据。时间序列中,噪声表现为高频信号,SPEI1经EMD处理得到频率依次递减的IMF1、IMF2、IMF3和残余项分量。IMF1变化剧烈为高频分量,噪声主要存在于IMF1中。其余分量为低频分量,受噪声影响很小。本文采用db3小波,采用启发式阈值选择规则,对含噪声较大的高频分量IMF1进行消噪处理。
因此对于SPEI1序列,构建经验模态分解神经网络耦合模型(EMD-ANN)以及经验模态分解支持向量回归耦合模型(EMD-SVR)。即对SPEI1进行EMD处理得到各分量,对高频分量IMF1先进行消噪处理,然后对各分量分别进行预测再进行叠加得到最终预测结果。
1.2.6模型性能评估
为了衡量模型预测值与实际值拟合情况,用决定系数(R2)、均方根误差(RMSE)对模型性能进行评估。计算公式为:
(2)
(3)
式中n——测试集样本个数;Oi——第i个样本实际值;Pi——第i个样本预测值。
2 结果分析
2.1 不同时间尺度的SPEI
经计算得到不同月时间尺度的SPEI序列见图2,可知随时间尺度增大,SPEI序列波动逐渐减缓。SPEI1变化最为剧烈,因为表征1个月尺度干旱的SPEI1受短期降水和温度变化影响明显,对降水和温度变化敏感、响应迅速,致使旱涝转换频繁,曲线变化剧烈。而当时间尺度增大,SPEI对降水和温度变化敏感性降低、响应减慢,故而曲线逐渐变得平滑。
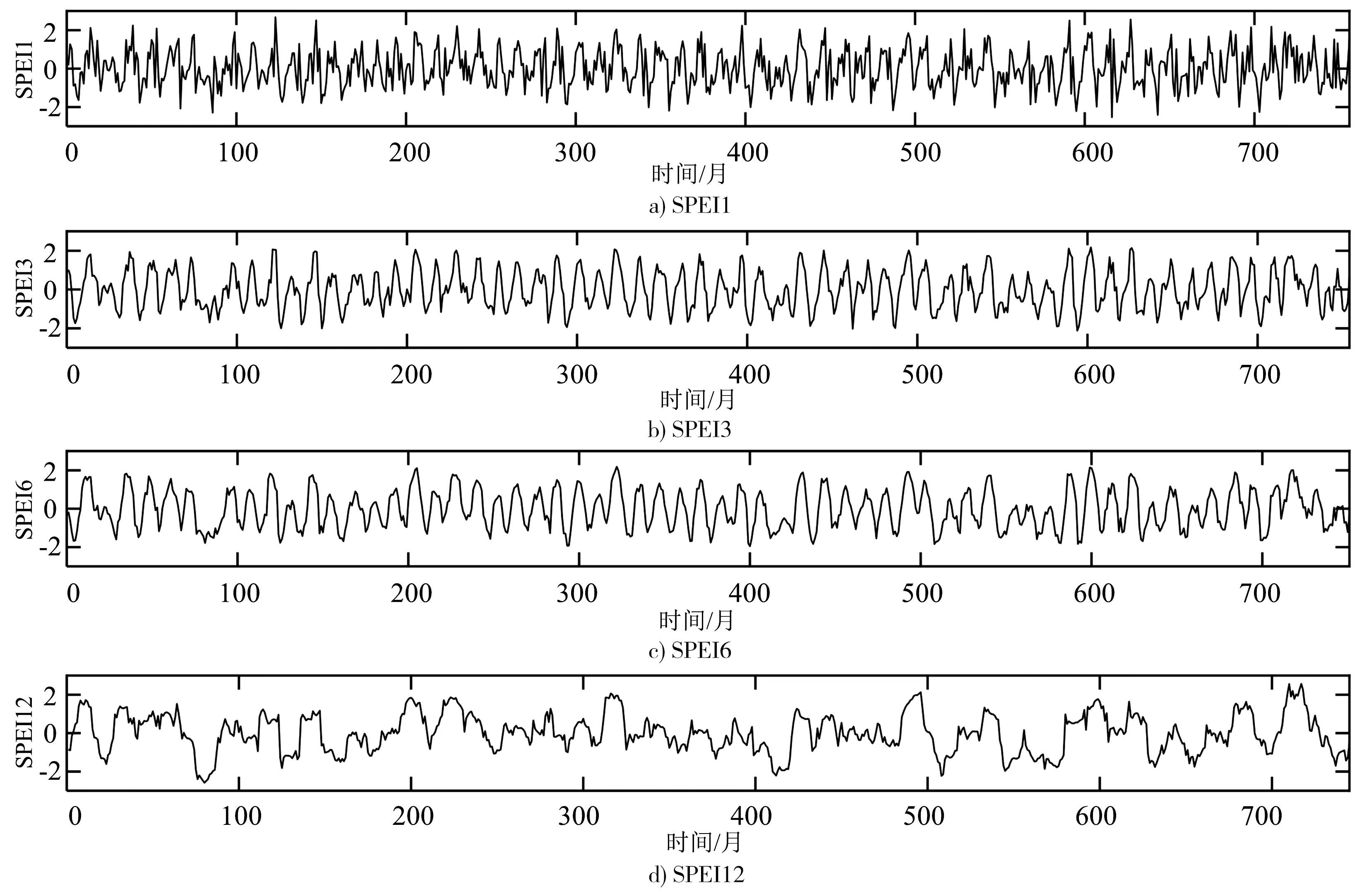
图2 不同时间尺度的SPEI序列
2.2 ANN和SVR模型预测结果
ANN模型和SVR模型在测试集中预测结果见图3(N为预见期),预测效果见图4,模型性能评价结果见表2。表2第三列是通过试错法得到的网络结构,第六列是网格搜索得到的3个参数。
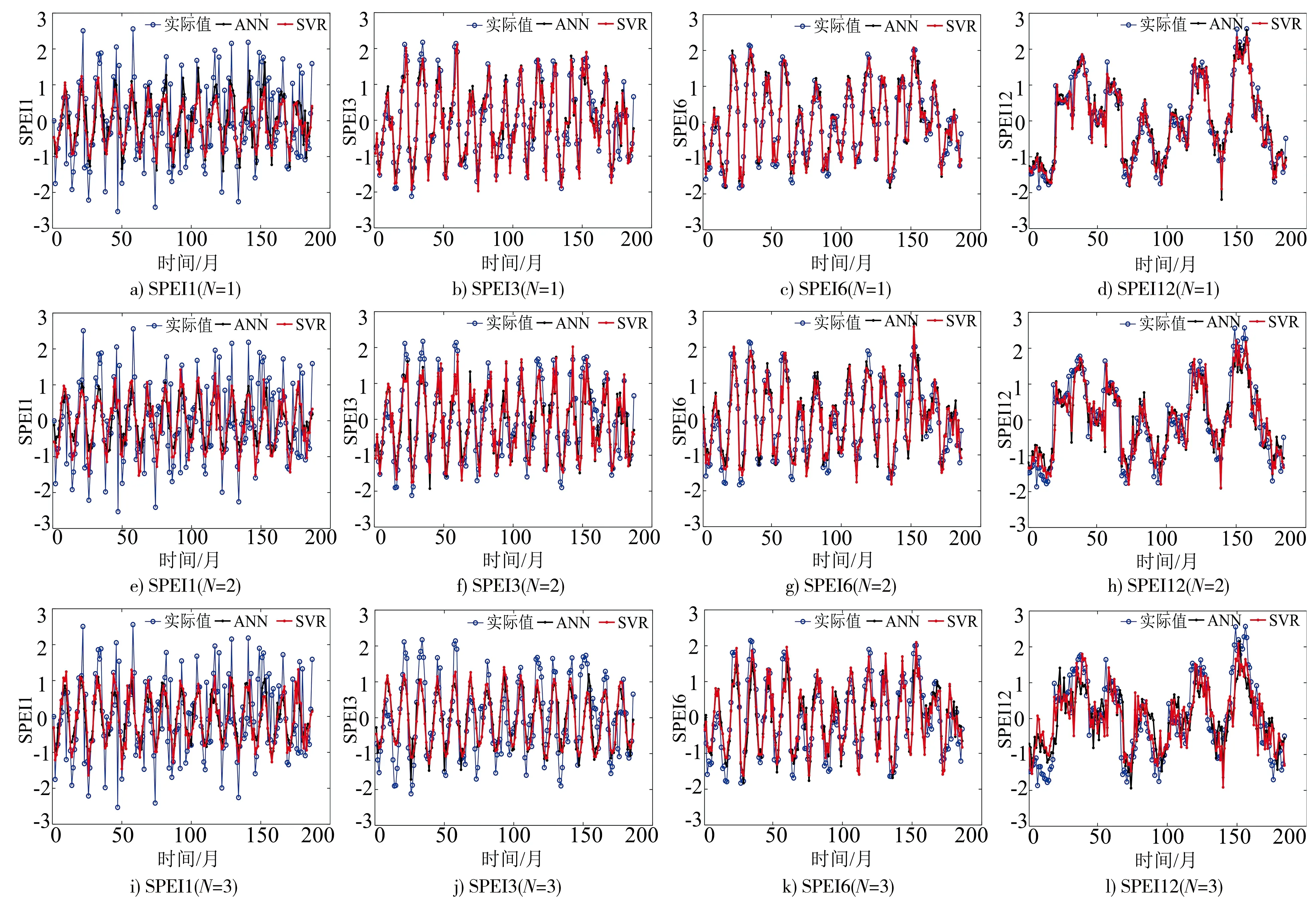
图3 基于ANN与SVR模型的干旱预测
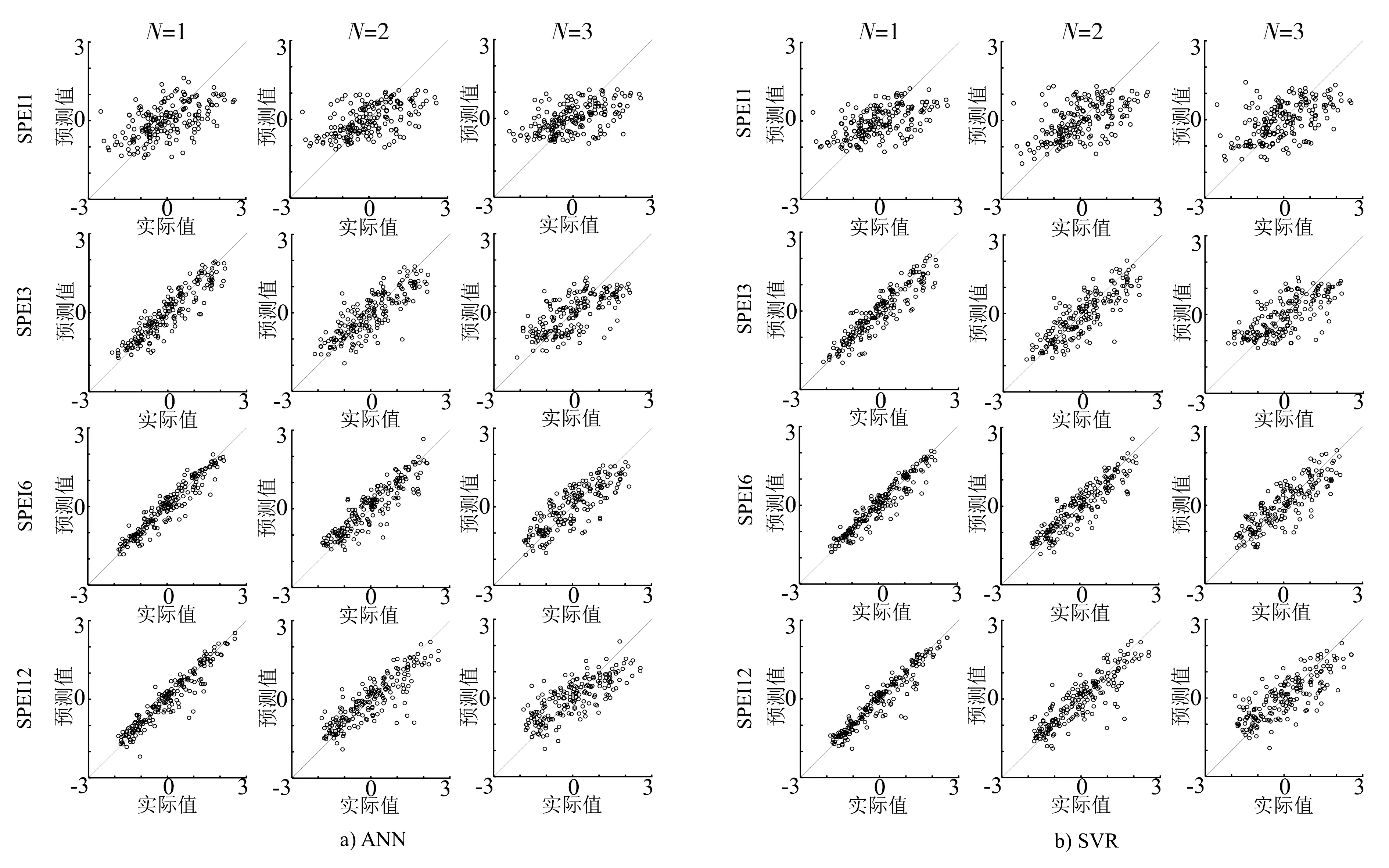
图4 基于ANN和SVR模型的干旱预测效果

表2 基于ANN与SVR模型的干旱预测效果评价
就SPEI3、SPEI6和SPEI12而言,2种模型预见期为1、2、3个月的决定系数R2分别为0.834~0.911、0.683~0.761和0.486~0.622。其中SPEI6的预测效果最好,其次SPEI12。如预见期为1个月时,SPEI6的预测效果最好,R2达到了0.908~0.911;其次为SPEI12,R2为0.900~0.907;SPEI3的R2也能达到0.834。一般来说,当时间尺度增大时,SPEI对降水和温度敏感性减弱,曲线更平滑,模型预测更准确[19]。从图4也可以看出,模型在预测SPEI12时相比SPEI6出现了更多的高估或低估的预测偏差,且当预见期增大时滞后性相对更明显,预测效果不如SPEI6。
3个月以上尺度的干旱预测效果整体上来说较好,且预见期越短,预测效果越好。就SPEI3、SPEI6和SPEI12而言,与3个月预见期的预测效果对比,ANN模型的2个月和1个月预见期的决定系数R2分别提高了16%~41%和30%~72%;SVR模型的2个月和1个月预见期的决定系数R2分别提高了14%~37%和27%~64%。
对比2种模型的预测结果可知,SVR模型比ANN模型的干旱预测效果更好。对于SPEI3、SPEI6和SPEI12,当预见期分别为1、2、3个月时,SVR模型比ANN模型预测的决定系数R2分别提高了0.3%~1.1%、1.5%~3.2%和3.0%~5.8%。这是由于ANN模型网络结构不易确定,有陷入局部极小值的问题,而SVR模型基于结构风险最小化原则,可避免局部极值问题,有良好的全局最优和预测能力,相比ANN模型其泛化能力更好。
SPEI1的预测效果相对较弱,2种模型预见期1、2、3个月的预测决定系数R2分别为0.311、0.292~0.305和0.267~0.291。因此,SPEI1的预测需要进一步改进。
2.3 基于EMD-ANN和EMD-SVR的干旱预测
2.3.1SPEI1的EMD分解及小波消噪
为了让1个月尺度的干旱获得更好的预测效果,对SPEI1进行 EMD分解,见图5。IMF1、IMF2、IMF3频率依次递减,残余项反应了原始序列的长期变化趋势。对高频分量IMF1进行消噪,见图6。消噪后序列相对平滑,在一定程度减小随机扰动的影响下仍保持了原IMF1序列的主要趋势信息,较好地提取了原IMF1序列中的有用成分。
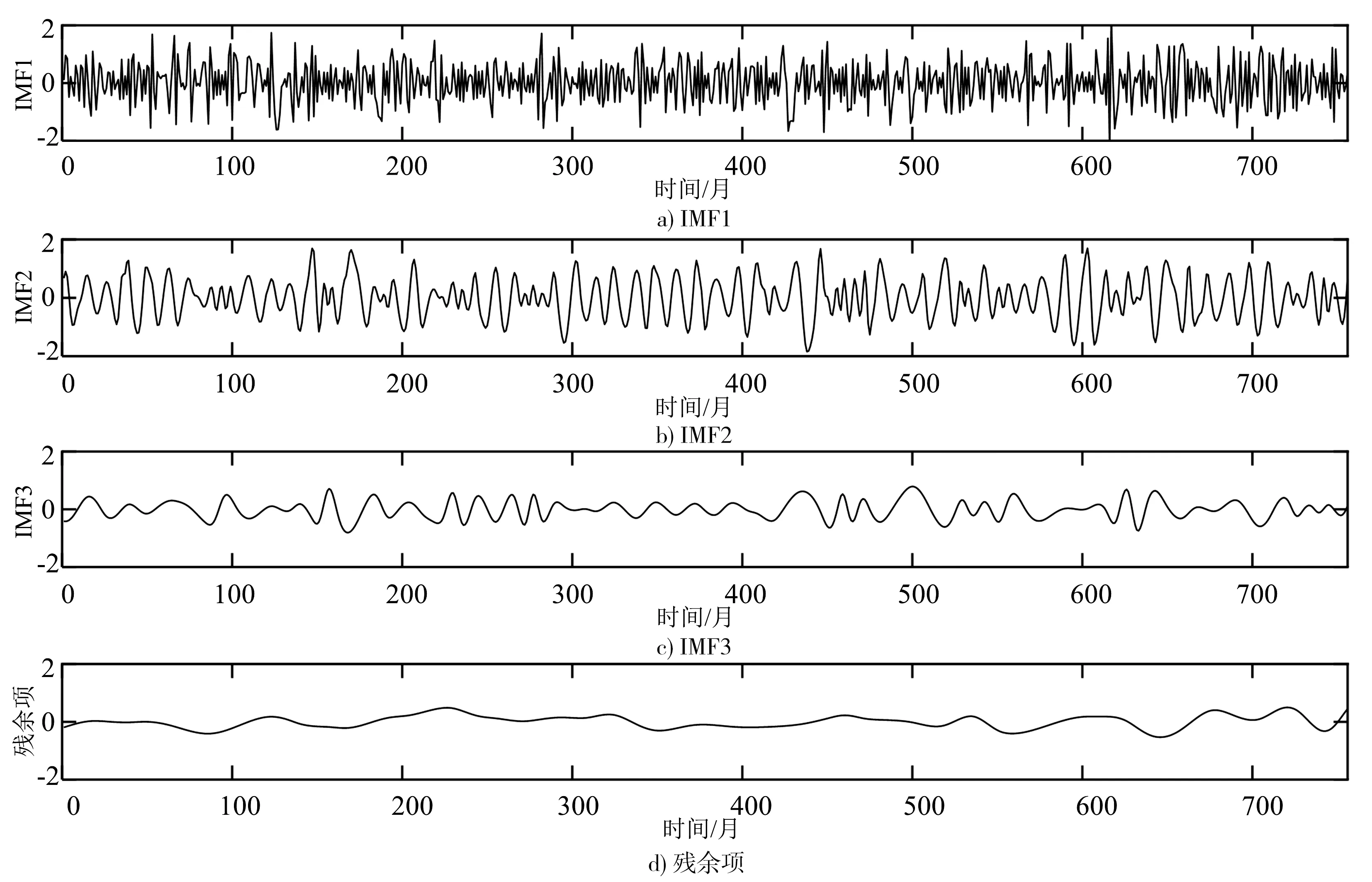
图5 SPEI1序列EMD分解

图6 消噪后IMF1序列
2.3.2基于EMD-ANN和EMD-SVR的SPEI1预测
EMD-ANN模型和EMD-SVR模型在测试集中的SPEI1预测结果见图7,预测效果见图8,模型性能评价见表3。
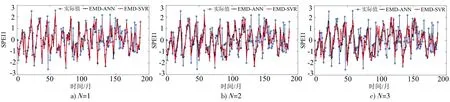
图7 基于EMD-ANN和EMD-SVR模型的SPEI1预测

图8 基于EMD-ANN和EMD-SVR模型的SPEI1预测效果
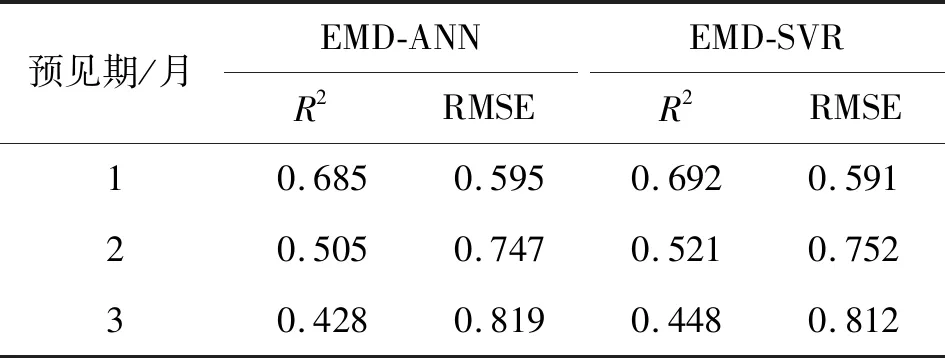
表3 基于EMD-ANN和EMD-SVR模型的SPEI1预测评价
经过EMD及小波消噪处理后的SPEI1预测效果得到了明显改善,2种模型预见期1、2、3个月的SPEI1预测决定系数R2分别为0.685~0.692、0.747~0.752和0.428~0.448,与处理前相比分别提高了120%~123%、71%~73%和54%~60%。这是因为短时间尺度SPEI1序列变化波动不稳定,有较大干扰,直接利用ANN和SVR预测时,序列自身特性没有得到深度挖掘,而EMD可将SPEI1分解成频率不同的分量,各分量数据特征更加显著,规律性更强,便于构建各分量预测模型;另一方面针对序列预测误差主要集中在含有噪声干扰的高频分量IMF1上的问题,则对IMF1先消噪,在保留原IMF1序列数据真实性的同时去除噪声干扰,提高分量预测精度。因此与ANN模型和SVR模型比较,EMD-ANN模型和EMD-SVR模型的SPEI1预测效果更好。
就SPEI1的预测,在预见期分别为1、2、3个月时,EMD-ANN模型好于EMD-SVR模型的预测结果,EMD-SVR模型比EMD-ANN模型预测的决定系数R2分别提高了1.0%、3.2%、4.7%。而在预见期分别为1、2、3个月时,SVR模型比ANN模型决定系数R2分别提高了0、4.5%、9.0%。说明应用EMD和小波消噪处理后,在预见期为1个月时SVR模型与ANN模型的预测效果差距增大,在预见期为2、3个月时SVR模型与ANN模型的预测效果差距缩小。
3 结论
通过建立ANN、SVR、EMD-ANN和EMD-SVR模型,对1、3、6、12个月的SPEI指数,进行了预见期为1~3个月的干旱预测,主要结论如下。
a)对时间尺度为3个月及以上的SPEI,ANN和SVR模型具有较好预测效果。其中SVR模型预测精度略优于ANN模型,SPEI6的预测精度略优于SPEI12和SPEI3。
b)预见期越短,干旱预测精度越高。对于时间尺度3个月以上的干旱指数,预见期1个月的ANN和SVR模型预测决定系数可达到0.834 ~0.911。
c)ANN和SVR模型对1个月时间尺度的SPEI1预测效果较差,但是通过EMD及小波消噪处理后,基于EMD-ANN和EMD-SVR模型的预测精度显著提高,干旱预测效果得到了明显改善。
