多维视角下科学主题演化分析框架
2021-04-21赵筱媛
王 康,陈 悦,苏 成,赵筱媛
(1. 大连理工大学科学学与科技管理研究所暨WISE实验室,大连 116024;2. 中国科学技术信息研究所,北京 100038)
1 引 言
著名的科学史和科学学家库恩在《科学革命的结构》中提出科学发展模式可简化为由 “前科学” 转变为 “常规科学” ,再经过 “科学危机” 和 “科学革命” 过渡到 “新常规科学” 的过程,整个科学发展依次周而复始。著名科学史和情报学家普赖斯(D Price) 早在1949 年就发现了科学指数增长规律[1],并于1971 年将其改进为S 型增长曲线[2]。随着信息技术的发展,如何从海量文献中寻找到形成科学指数及S 型增长宏观量化中的微观机制研究已成为一重要的科学学议题,其中关于科学主题的演化路径便是研究热点之一。
目前,科学主题演化路径的研究主要从引文分析、关键词聚类分析、主题相似性测度和主题模型四个方面展开。①http://cluster.ischool.drexel.edu/~cchen/citespace/download/引文分析方面:吴菲菲等[3]通过引文编年图及主路径分析3D 打印的主题发展趋势;邰杨芳等[4]通过对引文网络中重要文献解读国内隐性知识管理研究主题的演化。②https://www.vosviewer.com/关键词聚类分析方面:敦帅等[5]对中国企业可持续发展研究的文献进行关键词共现的时序分析,以揭示其态势演进与主题演化;杜丽君[6]以共现网络图的时序变化分析情报学和计算机科学的交叉主题演化规律;李秀霞等[7]通过对不同时间段图书情报界PIS(persional‐ized information service,个性化信息服务)关键词进行聚类,揭示PIS 研究热点、发展脉络及演化趋势;赵丽梅等[8]构建了我国知识管理研究领域不同发展阶段研究前沿的共词网络,并采用矢量动态模型、多维尺度分析(multidimensional scaling,MDS)和K核(K-core)等算法分别进行聚类展示;张一涵等[9]以我国用户信息行为研究为例,分阶段通过共词分析、聚类分析和战略坐标图等方法揭示研究主题演化脉络。③https://sci2s.ugr.es/scimat/主题相似性测度方面:吴江等[10]利用SciMAT 软件获取不同阶段在线医疗健康领域科学文献的研究主题和主题间的关系演化;牛力等[11]通过不同时间段聚类主题之间的相似性,勾勒中国档案学研究内容的动态变化。④主题模型方面:李湘东等[12]利用LDA (latent Dirichlet alloca‐tion)模型对科技期刊主题随时间的强度演化规律以及主题内容的演化趋势进行研究;颜端武等[13]运用LDA 主题模型进行相邻时间窗口主题之间的相似度进行时序主题关联演化分析。
上述方法从不同角度揭示了科学主题的演化规律,这对了解科学发展规律和预测科学未来发展趋势具有重要意义。同时,这些方法也存在一定的局限性,例如,基于引文分析方法的时滞性和主题难以直观展示的问题;基于关键词聚类分析、主题相似性测度和主题模型方法的关键词重要性无差别对待;主题强度难以测度和分析视角单一等问题。
为了解决上述问题,本文拟从学术论文关键词角度,多维度绘制科学主题演化路径。关键词是学术概念的体现,一系列学术概念的组合便形成一篇论文的研究主题,因此,关键词可以用于科学主题演化路径挖掘与分析。其中,关键词共现已成为研究热点或前沿分析的一种通用方法,并融入多种科学计量及科学知识图谱的绘制工具中[14]。CiteSpace①的Timezone[15]和Timeline[16]可从文献整体和各个聚类(主题)层面展示关键词首次出现的年份和累计频次;VOSviewer②依据关键词出现的加权平均时间来分析主题演化;SciMAT③依据相邻时间窗口聚类所共享的分析单元进行主题演化分析[17];NEViewer依据相邻时间窗口聚类主题相似度进行主题演化分析[18]。上述软件的开发为揭示科学主题演化提供了便利,但同样存在关键词重要性无区分、分析视角较为单一,无法多维刻画主题演化路径、部分工具无法展示关键词动态变化(仅能呈现关键词在某一年份的累加)等局限。
因此,本文引入知识单元的游离与组合理论[19-20],从知识单元提取(关键词)、主题识别(关键词关联)和知识演变(主题关联)三个层面来构建科学主题演化框架,该框架以关键词为基础,引入时间序列分析方法中的指数平滑法思想,强调时间对关键词重要程度的影响,突出主题强度变化趋势和主题交叉融合,从多视角、多层次展示科学主题的演化规律。本文以图书情报领域大数据核心文献为实证案例进行研究,以期本文的研究成果能够对科学发展过程及其预测提供参考。
2 多维视角下科学主题演化分析理论模型与测度方法
2.1 基于知识单元游离与组合的理论分析模型
赵红洲等[19]首先提出了 “知识单元” 的概念,但难以计量。他所指的知识单元是定量化的科学概念,而定性化的知识单元,就退化成科学概念,即知识单元是粒子化了的科学概念,而科学概念又是场化了的知识单元。他指出, “任何一种科学创造过程,都是先把结晶的知识单元游离出来,然后再在全新的思维势场上重新结晶的过程。这种过程不是简单的重复,而是在重组中产生全新的知识系统,全新的知识单元” ; “创造过程乃是知识单元的重组过程,乃是新知识单元的创生过程,乃是旧单元变革为新单元的过程” 。赵红洲等[19]将知识单元视为不可再分割的科学概念,属于狭义的知识单元,英文译为 “element of knowledge” ,或称之为 “知识元” 。
刘则渊等[21]在赵红洲等[19]的知识单元概念的基础上,将知识单元的定义一般化、广义化,使其适于一切知识领域,成为可计量的单位。刘则渊[21]指出,所谓知识单元(knowledge unit),是人类知识领域一般用于表征其特定内容的概念及陈述、语词及词组、术语及定律等可计量的基本单位,是知识计量学的核心概念和基本计量单位。人类知识领域,作为知识计量学的研究对象,其涵盖内容非常广泛——科学、技术、人文等不同学科门类的知识,著作、文章、专利等不同形态的知识,储存于文献、网络、信息等不同媒介中的知识,以及蕴含在个人、组织、共同体等活动主体中的知识。这些知识领域在特定的范围内或特定的场合与条件下,会发生知识单元的分解和会聚、离散和重组、演进和升华、衍生和转化,形成一个从简单到复杂、从低级到高级、从浑沌到有序的自组织系统。在一定条件下,某个关键的知识单元可能扮演 “知识基因” (knowledge gene)的角色,其决定着特定领域知识的进化与突变。这样,基于知识单元的特定知识领域所构成的复杂自组织知识系统,就能够在可视化的知识图谱上展示知识的产生、传播和应用,知识的基础、中介和前沿,知识的结构、演化和重组,知识的涌现、断层和变革等。
库恩的 “范式” 转变描述的是科学发展的宏观模式,但微观层面,科学发展还是附载在研究主题的演变,研究主题的变化往往也不是新的主题突然出现,而是在原有研究主题的基础上分化衍生而成,因而本文利用不同时期产生的主题之间的相似性来判断源与流的关系。而由关键词共现聚类而生成的研究主题,其内部仍然有着主题演变的趋向机制,而这个机制本文通过将关键词赋予不同的时间加权来体现。基于此,本文进一步扩展知识单元这个计量单位,在以探究研究前沿而进行的主题演化路径分析中,将知识单元赋予演变的含义,即越新出现的知识单元越具有预示前沿的价值。
因此,本文将关键词视为知识单元,随着研究的不断发展,游离关键词之间的关联视为知识单元的组合关系,这种科学概念的组合就形成了研究主题,主题之间的时序关联反映一个知识域的演变关系。本文首先以文献关键词为基础,由于关键词的出现时间对主题新颖性具有较大影响,因此按照关键词的出现时间对关键词赋予相应的权重,实现越晚出现的关键词权重越高,即新颖性越高;同时,考虑到绝对词频对分析结果的影响,模型中选择相对词频加权方式。通过处理后的关键词与基于绝对频次的关键词相比较,能够有效甄别研究热点和研究前沿。其次,基于知识单元游离与组合理论将关键词视为单元并进行关联分析,识别研究主题并计算主题的绝对强度与相对强度,用于辨别主题的未来发展趋势。最后,将主题视为单元,再次利用知识单元游离与组合理论对各个主题之间的关联进行测度,挖掘主题之间的融合、扩散、突现、消亡等关系。该模型以知识单元游离和组合为基础,从关键词提取、关键词关联和主题关联三个视角逐步深化进行主题演化路径研究,具备科学性和合理性,其理论分析模型如图1 所示,其中xi表示时间加权关键词,具体实现方式阐述如下。
2.2 时间加权的关键词频数测度
2.2.1 设置时间加权系数
探测核心关键词的变化趋势是快速把握科学领域研究热点及趋势的方法之一,但提取核心关键词并非易事。依据关键词频次选取高频词的传统方法,由于忽略了时间窗口期的差异,而导致不同时间点出现的同频次关键词会被同等对待;然而,旨在反映科学研究前沿的关键词,其重要程度实际上是与时间相关的,同频的关键词越新近越能体现研究的前沿和趋势。
本文借鉴广泛应用于生产预测和中短期经济发展趋势预测的时间序列分析方法中的指数平滑法思想[22],其核心思想:①时间序列的态势具有稳定性或规则性,故时间序列可被合理地顺势推延;②最近的过去态势,在某种程度上会持续到最近的未来,故新数据赋予较大的权数,旧数据赋予较小的权数。本文将指数平滑法思想应用于关键词的加权,即新近出现的关键词赋予较大权重,早先出现的关键词赋予较小权重,构建加权系数模型为
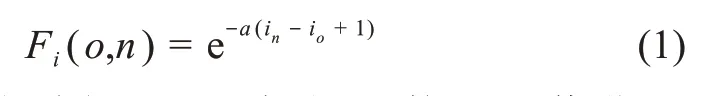
其中,Fi(o,n)为关键词i的加权系数,取值范围[0,1];io表示关键词初始出现年份;in表示当前年份;(in-io+1)是关键词年龄,表示关键词的新旧;a为参数,其值表示时间对关键词重要性的影响,当a=0时,时间对关键词的重要性不产生影响(图2)。
该模型具备的优点:①符合实际。该模型对不同年份出现关键词的非等权处理,能够体现出时间对关键词的影响,距离当前年份越近,时间加权曲线斜率越大,即时间对关键词的影响越大。②可控性强。在实际使用中,该模型只需要选择一个模型参数a即可,且通过控制该参数可着重强调新老关键词,更容易突出显示研究前沿。③适应性强。该模型可用于不同研究方向的基于加权关键词演化的前沿和热点探测。
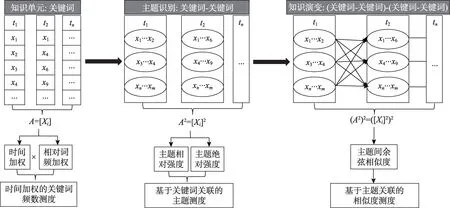
图1 基于知识单元游离与组合的理论分析模型

图2 关键词时间加权不同参数模型
2.2.2 标准化词频
关键词自身占比能兼顾削弱词频在数值上的优势,且反映出自身变化率,该指标能够突显某年度对该关键词在该年占比大且绝对频次高的数据,弱化绝对词频低的数据,更易于探测出具有发展潜力的关键词[23]。
为挖掘关键词自身的变化情况,首先,本文构建 “年度-关键词” 二模矩阵,采用水平加权处理关键词绝对词频,进而计算各关键词的相对词频R(i,j),即各关键词绝对词频与时域内该关键词总量占比的乘积:
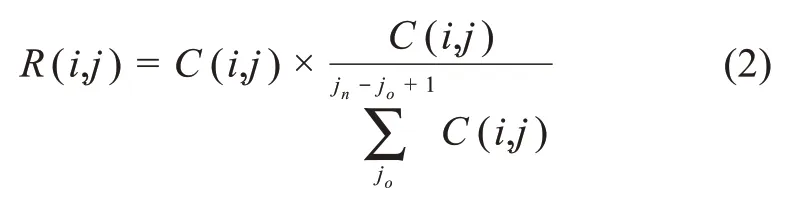
其中,C(i,j)是第j年关键词i的绝对词频;R(i,j)是第j年关词i的相对词频;(jn - jo +1)是时间长度。
2.2.3 修正关键词权重
将时间加权系数与相对词频的乘积作为本文修正后的时间加权关键词权重FR,依此,逐年统计核心关键词的权重,以借加权关键词演化分析学科热点与趋势:

其中,Fi(o,n)是关键词i的时间加权系数,R(i,j)是第j年关词i的相对词频。
2.3 基于关键词关联的主题测度
2.3.1 主题提取
利用社区探测算法对共现矩阵进行社区划分,确定目标领域主题所属类别。其中,社区探测算法选用Louvain 算法[24],该算法运行速度较快,适用于庞大网络的社群发现;同时,采用启发式方式,能够克服传统Modularity 类算法的局限,算法核心是最大化模块度Q 值。其原理如下:首先,将所有网络节点视为独立的社区,遍历每个节点的所有邻居节点,计算模块度并将其归为模块度提升最大的邻居节点所在的社区,直至每个节点所属社区不再发生变化;其次,将社区进行折叠作为一个节点,这时边的权重为两个节点内所有原始节点的边权重之和;最后,重复执行上述步骤直至迭代到完全收敛。模块度计算方法为

其中,m为网络中连线数量;ki表示所有指向节点i的连线权重之和;kj表示所有指向节点j的连线权重之和;Aij表示节点i和j之间的连线权重;ci、cj分别是节点i和节点j所属的社区,若ci=cj,则δ(ci,cj)=1,否则,δ(ci,cj)=0。
2.3.2 主题强度测度
基于时间加权关键词的频次测度,逐年获取关键词总权重,根据主题社区划分结果,计算每个社区主题下各关键词逐年权重之和。同时,考虑社区团体的大小对主题强度的影响,提出主题绝对强度和主题相对强度概念,以此构建主题绝对强度演化路径和相对强度演化路径模型,从而挖掘主题自身和主题间的强弱演化趋势:

其中,h表示主题;t表示时间区间;Cont(k)表示第t时间段主题h包含的关键词数量;Fi(o,n)是关键词i的时间加权系数;R(i,j)是第j年关词i的相对词频;表示主题h在第t时间段的绝对演化强度;表示主题h在第t时间段的相对演化强度。
2.4 基于主题关联的相似度测度
为识别依据主题关联的知识演化路径,需要对相邻时间窗口的主题进行相似度测算。本文利用余弦相似度(cosine similarity)算法,将每个主题包含的关键词映射为向量,通过计算相邻窗口不同主题之间的向量夹角的余弦值来判定两个主题的相似性,余弦值越大表明相似度越高:
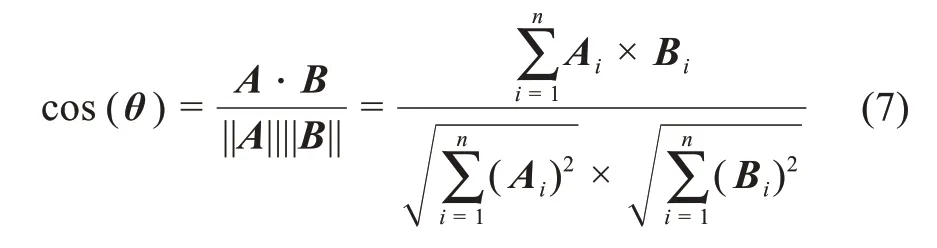
其中,A和B为两个不同主题对应的向量。
3 图书情报领域大数据研究主题演变
本文以图书情报领域大数据研究为例,对上述多维视角下科学主题演化的理论分析框架的可操作性和有效性进行实证研究。本文对中国知网(CNKI)中的1893 篇图书情报领域大数据论文①(检索日期为2020年5 月9日)检索条件:(核心期刊=Y 或者CSSCI期刊=Y 或者CSCD 期刊=Y)并且(主题=大数据)(模糊匹配):图书情报与数字图书馆的数据进行预处理,即补充缺失字段并去重、删除无关文献等,最终获得1776 篇论文作为分析研究对象。我国图情领域紧跟数据时代前沿热点,积极将大数据研究纳入其中。2012 年,瑞士达沃斯世界经济论坛发布的 “Big Data, Big Impact” 报告引发了学者们对图情领域大数据研究的热度,随后发文量快速攀升,于2016 年达到峰值,2017 年稍有下降,之后仍继续呈上升态势(图3);关键词、作者和机构数量的变化趋势与发文量一致,整体呈上升态势,这在一定程度上说明图情领域大数据研究内容越来越广泛,科研共同体规模越来越大。每年新增的关键词、作者和机构数量亦呈上升态势,反映出该领域的吸引力在持续增加。

图3 图书情报领域大数据研究主题发展趋势

表1 关键词绝对词频与修正词频变化表
3.1 基于加权关键词的主题演化
依据时间加权关键词频次修正模型,本文对373 个关键词(频次≥2)进行加权修正,累计修正词频fw与其累计词频f之间呈现出的较为显著的强正相关性(r=0.949,p=0.01),这说明了该时间加权方法的合理性。选取依累计修正频次排序Rw的前20 个关键词,将其与累计词频排序R进行比较(表1)可以判断加权修正的意义,即若两种排序的变化值R-Rw为正,则表示经修正后的关键词排序上升;若R-Rw为负,则表示经修正后的关键词排序下降;若R-Rw为零,则表示经修正后的关键词排序不变。
(1) 加权修正后,排序基本不变(|R-Rw|≤1)的关键词包括 “图书馆” “高校图书馆” “数据可视化” “智慧图书馆” 和 “文献计量” 。这类关键词出现时间较早,且词频较高,在图情领域属于一般性研究主题(general topic),从其发展趋势来看,主要存在两种类型:近期下降型和稳步发展型。 “图书馆” 在2012—2016 年借助大数据技术词频快速增长,随后趋于饱和,研究热度开始快速下降; “高校图书馆” 词频于2018 年达到顶峰,随后下降。虽然 “图书馆” 与 “高校图书馆” 均处于下降期,但两者的高频出现致使一些新兴高影响力关键词难以显现(图4a);而时间加权模型可以较好解决此类问题,当这类高频关键词研究热度下降时,虽加权词频排序并未改变,但从时间序列的角度观察其已明显低于其他上升型关键词,如 “图书馆” 于2018年、2019 年分别降为第11 位和第8 位(图4b),这就为那些潜在的有影响力的关键词显现提供可能。
(2)加权修正后,排序上升(|R-Rw|>1)的关键词包括: “情报工程” “用户画像” “智库” “人工智能” “知识图谱” “互联网+” “智慧服务” “CiteSpace” “公共图书馆” 和 “数据素养” 。从发展趋势看,存在两种类型:近期突现型关键词(如 “情报工程” 上升34 位)和新兴型关键词。其中,新兴型关键词具有出现时间晚、词频不高和增长迅速的特点,是目前值得关注的研究前沿,或即将成为未来研究热点,如 “人工智能” 和 “用户画像” 都首次出现于2017 年,随后每年词频都在增加。这类新兴型关键词基于修正词频的上升趋势更加明显,如2019 年 “用户画像” “人工智能” 和 “知识图谱” 分别排序前3 位(图4b),效果明显优于词频趋势图。
(3)加权修正后,排序下降(|R-Rw|<1)的关键词包括: “知识服务” “情报学” “数据挖掘” “数字图书馆” 和 “信息服务” ,这类关键词具有出现时间早、绝对频次中等、前中期处于上升发展期和近期总体趋势下降的特点。如 “知识服务” 从2013年的4 次升至2016 年的14 次又降至2019 年的9 次; “信息服务” 从2012 年的1 次升至2014 年的9 次又降至2019 年的2 次。基于修正频次的时间序列来看,此类关键词其下降趋势更加明显,如2019 年 “情报学” 从第8 位降至第11 位; “知识服务” 从第9 位 降 至第12 位。
由上述内容可知,本文构建的关键词加权模型在应用于研究主题演化路径上,具有如下优势:
(1) 基于时间加权修正词频排序靠前的关键词,属于绝对高频词、突现词或新兴词,对揭示研究前沿和热点趋势具有重要价值。
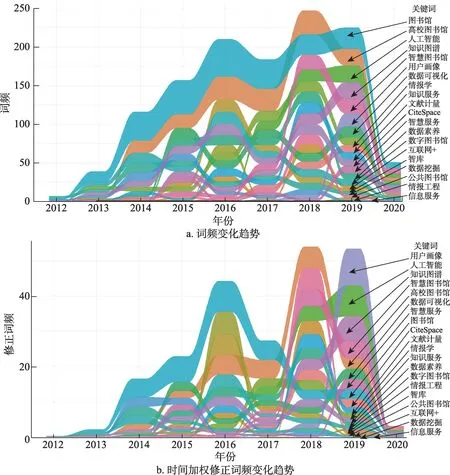
图4 图书情报领域大数据研究关键词变化趋势
(2)基于时间加权修正词频方法能够使得研究热度上升和下降的趋势更加明显,对有效甄别研究热点与前沿具有重要价值。
3.2 基于关键词关联的主题演化
关键词的变化趋势更侧重于研究概念的演变,研究主题往往是研究概念的组合,即承载于关键词的关联之中。关键词共现能够基于关键词之间的关系,发现多个关键词的复杂联系,进而从网络社区角度揭示主题演化情况。在此基础上,本文截取频次大于2 的关键词进行社区划分,得到7 个研究主题(图5a),即人工智能与智慧图书馆服务、情报与智库研究、高校科研数据管理与服务、数据挖掘方法、竞争情报与云计算、数据素养、数字图书馆与用户画像。
计算构成每个社区主题下的关键词时间加权修正词频次之和,即绝对主题强度ATTht,用于比较主题自身强度变化。考虑到每个主题所含关键词数量的不一致性,将绝对主题强度进行归一化处理,得到每个主题的相对主题强度RTTht,用于比较主题之间的强度差异。
依据绝对主题强度绘制的主题演化图谱(图5b)显示:①人工智能与智慧图书馆服务所代表的主题发展趋势最为明显。近年来,随着人工智能技术的发展,其作为嵌入式技术服务于图书馆的诸多方面,助力智慧图书馆的建设;②数据挖掘方法关注度增长迅速,排名第2 位;③情报与智库研究的关注度波动较大,因国家政策导向①2015年1月,中共中央办公厅、国务院办公厅印发了《关于加强中国特色新型智库建设的意见》,并发出通知,要求各地区各部门结合实际认真贯彻执行,进而引起图情界的广泛关注。使其于2016 年成为最受关注的主题,随后其一直排在第3 位;④科研数据管理是一个复杂的过程,涉及众多要素。高校聚集着大量的科研人员,故其成为科研数据产出的重要机构,进而成为科研数据管理与服务的主要机构,该主题在2016—2017 年关注度较高,之后关注度有所下降,排名稳定在第4 位;⑤数字图书馆和用户画像主题在2019 年之前关注度一直较低,2019 年由第7 位升至第5 位,关注度增加;⑥大数据时代科研人员的数据素养尤为重要,提供科研数据质量的高低与利用科研数据创造价值的大小很大程度上取决于科研人员自身数据素养。近年来,关于数据素养的关注度逐年提升,但增速缓慢,绝对主题强度徘徊在第5~6 位;⑦竞争情报与云计算早期关注度非常高,2012—2014 年主题强度一直处于第一,近年来该主题关注度逐渐降低,目前已经降至最低位。
与绝对主题强度相对应,相对主题强度则消除主题规模对主题强度的影响,比较主题之间的强度变化(图5c)。2019 年,数字图书馆与用户画像、数据挖掘方法、情报与智库研究三大主题的相对主题强度呈现上升趋势,特别是数字图书馆与用户画像主题强度增幅较大,随着大数据技术的发展,用户画像成为利用大数据实现用户精准服务的重要工具和技术手段,广泛应用于金融、电子商务、社交等领域。用户画像亦可作为图书馆实现精准化服务的一大工具,其是建立在一系列真实数据之上描述用户需求和偏好的目标用户模型[25]。数据挖掘方法的聚类分析、社会网络分析、时间序列分析等被广泛应用于图情领域,同时,用于大数据挖掘的新工具和方法开发成为近年来研究热点;情报与智库研究自2017 年下降后,近年来有上升趋势,建设中国特色新型智库对推进国家治理体系和治理能力现代化意义重大。
3.3 基于主题相似度的主题演变
基于关键词关联的主题演化,可使研究者对图情领域大数据主题的发展趋势有个整体的感知和预测,但尚不能发现主题间知识的细微演变。基于此,本文进一步基于主题相似度的时序演变来发掘研究主题的演变,以让研究者更加了解和去发现研究领域知识的变迁。
本文将时间窗口设置为一年,将图情领域大数据研究划分为9 个时间切片,对每个时间窗口中所有关键词进行共现矩阵构建,并利用Louvain 算法进行社区划分,得到的社区主题个数和网络基本指标如表2 所示。
提取相邻时间窗口余弦相似度大于0.15 的主题,并绘制主题演变路径(图6)。该图显示图情领域大数据研究复杂的知识演变关系(2012—2020年),如扩散、融合、突现、消失等。其中,每个矩形表示1 个主题,对应的主题名称用高点度中心性的3 个关键词标注,主题间连线的粗细表示相似度大小。

表2 时间窗口划分与主题网络指标统计

图6 图书情报领域大数据基于主题相似度的知识演变
图6 显示,图情领域大数据研究划分为两大知识群:大数据在图书馆中的应用和大数据在情报学中的应用。数据素养贯穿于其中,是大数据背景下图书馆学和情报学共同关注的主题。图书馆为促进科研数据管理人员(数据馆员、学科馆员等)及服务对象(科研人员、教师、学生等)高效管理和利用科研数据,将科研数据管理教育,即数据素养作为科研数据管理的重要内容和可持续发展的重要保障。随着大数据时代的到来,数据素养备受关注,图书馆的服务与职能已发生显著变化。数据素养教育亦将成为大数据时代图书馆的主要职能之一[26]。情报分析与服务过程中,研究人员的数据素养异常重要,数据素养高的情报分析人员对数据更敏感,更容易从数据中挖掘高价值信息,创造价值。
在图书馆中的应用除数据素养外,大数据还包括:信息服务、阅读推广、智慧图书馆与智慧服务。信息服务主题出现于2013 年,消亡于2015 年,属于昙花一现型主题。阅读推广主题最早可追溯到2013 年出现的图书馆服务,经过知识服务并在不同年份借助互联网+、人工智能技术融合成图书馆用户画像和精准服务主题,继而形成阅读推广主题。智慧图书馆与智慧服务主要由三个主题融合而成:其一,是由图书馆服务,经知识服务并借助互联网+、人工智能技术组成;其二,由个性化服务和情景化服务组成;其三,由隐私保护和数据安全组成。
大数据在情报学中的应用主要涉及情报分析与研究、大数据分析与可视化方法、情报与智库研究。其中,情报分析主要来源于2013 年出现的情报与情报学主题,然后沿着竞争情报分析、情报研究、大数据思维与分析、大数据与情报分析、数据科学与情报工作、情报分析与研究,最后汇总于人工智能背景下的情报学研究,在此过程中,情报人员的数据素养起到软支撑作用,数据挖掘与可视化方法起到硬支撑作用。图情领域大数据研究常用的研究方法包括:词频分析、共词分析、因子分析、多维尺度分析、战略坐标分析、社会网络分析、LDA 主题模型、数据可视化和知识图谱等,其研究流程通常是研究人员遵循特定学科领域的标准对数据进行抽取、集成、关联和聚合,然后利用数据挖掘技术发现其中的模式,进而通过信息可视化方法将其呈现出来。同时,利用现有数据进行挖掘和可视化分析,可以预测未来该领域的发展方向。
此外,2015 年出现了突发事件应急决策主题,并与情报研究融合,在2016 年形成情报工程与服务主题,即基于情报工程迅速响应突发事件应急决策。李阳等[27]认为,在大数据时代,应以智慧应急为 “主位” ,以情报工程为 “述位” ,构建以大数据资源为 “基” ,以情报融合为 “核” ,以专家智慧为支的智慧应急情报工程体系架构。之后,情报工程与服务主题又延伸到智库与情报服务研究,从工程化视角强化智库情报机能,保障其产品质量以及影响力[28]。
4 结 语
本文的研究成果如下:①基于知识单元的游离与组合,本文构建了多维视角下主题演化分析理论模型,并以图情领域大数据期刊数据为例进行研究,验证所构建框架的可行性和有效性。其中,基于时间加权的关键词频数测度方面,本文将关键词时间加权和关键词总频次加权的乘积作为关键词加权综合分值,通过与绝对词频的比较发现, “用户画像” “智库” “人工智能” “知识图谱” “互联网+” “智慧服务” “情报工程” “CiteSpace” “公共图书馆” 和 “数据素养” 是该领域的热点和前沿关键词;②基于关键词关联的主题测度方面,本文利用Louvain 算法识别文献主题,并基于主题加权结果计算每个主题的绝对强度和相对强度,使研究者对图情领域大数据主题的发展趋势有个整体的感知和预测,绝对强度显示人工智能与智慧图书馆服务主题受关注度最大,相对强度显示数字图书馆与用户画像主题受关注度增幅最强;③基于主题关联的相似度测度方面,本文通过探测每个区间主题,并计算相邻主题间的相似度,从而进行主题演变路径绘制,使图情领域的研究者更加了解和认识各主题之间的融合、扩散、突现、消亡等关系。
研究结果表明,数据素养主题贯穿于大数据背景下图书馆学和情报学,是共同关注的主题;阅读推广主题借助互联网+、人工智能技术转为用户画像和精准服务主题;智慧图书馆与智慧服务涉及面非常广泛,由多主题融合而成;大数据背景下的情报学研究在人工智能、数据素养和数据挖掘与可视化方法交织融合下快速发展;情报工作与突发事件应急决策融合形成情报服务,并进一步深化为智库服务。
