基于加权网络改进的中文短文本相似性度量模型
2021-04-21牛奉高高旭霞
牛奉高,高旭霞
(山西大学数学科学学院,太原 030006)
1 引 言
随着互联网技术的普及与发展,世界进入了信息爆炸的时代,数据信息的迅速膨胀给人们带来便利的同时,也增加了人们获取有价值信息的难度。在目前的海量数据中,微博、微信、短信等短文本是规模最大、使用最广泛的一类数据。短文本具有字数少、信息聚合度高、文本语言不规范等特点[1]。如何将非结构化或者半结构化的短文本转化为计算机可以处理的结构化形式,并从中高效准确地挖掘信息已成为学者们研究的热点。
短文本语义相似性的度量对于理解和分析短文本起着至关重要的作用,被大量用于信息检索、推荐系统、文本聚类领域。在信息检索中,许多学者常常通过改进短文本相似性度量模型来改进检索效果;在推荐系统中,性能优良的短文本相似性算法可以大大提高推荐系统的推荐准确度;在文本聚类中,短文本相似性度量是文本聚类的核心技术。除此之外,短文本相似性度量在邮件信息处理[2]、健康咨询对话系统[3]、房地产销售[4]、智能导游[5]等领域也极其重要。
目前,国内外对短文本相似性研究的主要方法是基于统计的方法和基于语义分析的方法[6]。基于统计的方法是将特征词作为短文本的基本元素,考虑特征词在短文本中的出现频次,从而建立特征词向量,通过计算特征向量之间的相似性来表征相应短文本之间的相似性[7]。特征向量之间的相似性常使用余弦距离和Jaccard 距离来度量。但是,基于统计的短文本相似性度量方法依赖于大型语料库,忽略了短文本中词语之间的语义信息。基于语义分析的相似性度量方法是考虑短文本中词语或句子的语义信息的一种方法,不需要大规模的语料库,不需要长时间的训练,克服了基于统计的短文本相似性度量方法的缺点。然而,基于语义分析的相似性度量方法在构建文本特征之间语义关系的时候,需要利用特定领域的知识库,一般情况下,建立完备的知识库是比较困难的。
如何表示短文本,是短文本相似性度量的核心问题。1997 年,Salton 等[8]提出的向量空间模型(vector space model,VSM)是目前国内外最常用的文本表示模型,该模型将文本映射为一个特征向量,以每个特征项的频次为向量元素,特征项可以是字、词、词组等。尽管这种方法简单明了,但忽略了文本中词语之间的语义信息。
针对上述问题,本文根据共现分析理论,利用加权复杂网络表征短文本,提出了新的短文本相似性度量模型,并经过了聚类检验。
2 相关研究工作
目前,国内外许多学者在将基于统计和基于语义分析方法融合的基础上,加入了新的元素来对短文本相似性进行度量,削弱在度量短文本相似性时对大型语料库和知识库的依赖程度。秦兵等[9]面向常见问题集,采用TF-IDF 方法和基于语义的方法计算问句间的相似度。熊大平等[10]根据问句的统计信息、语义信息和主题信息,基于LDA (latent Dirichlet allocation) 的匹配框架得到问句相似度。王荣波等[11]以Wikipedia 作为外部知识库,从语形相似性和组元相似性两个方面对短文本之间的语义相似性进行了综合度量。荆琪等[12]利用Wilipedia 的结构特征,结合类别相关度与链接相关度计算词语相关度,提出了一种基于词形结构、词序结构和主题词权重的短文本相似性度量方法。章成志[13]综合考虑相似元的字面、语义及统计等多层特征得到字符串的相似性。金博等[14]将基于语义理解的文本相似度计算推广到段落范围,又将段落相似度推广到篇章相似度计算。马慧芳等[15]针对短文本特征稀疏的问题,提出融合耦合距离区分度和强类别特征的短文本相似度算法。上述方法通过对词语相似度加权度量短文本相似性,着眼于短文本中词语之间的语义相似度,忽略了词语之间的统计联系和词语本身对于短文本的重要程度。用复杂网络表征短文本时,短文本中的重要特征词可被明显区分,为更精确的度量短文本相似性打下基础。
复杂网络作为一门新兴研究分支,是解释网络现象及复杂性的学科。近年来,学者们对复杂网络的理论与应用进行了深入研究。为了克服向量空间模型(VSM) 的缺点,2001 年意大利学者Ferrer Cancho 等[16]首次从复杂网络角度研究英语网络,语言网络连接被定义为词语同时出现在一个句子中,并且限定在距离为1 或者2 的词语之间。为了检验汉语是否有小世界特性,2004 年韦洛霞等[17]首次将复杂网络观点应用于中文,证明了汉语具有与英语一样的小世界特性,如果合理的储存和加工,可以获得与英语一样的检索效果。赵鹏等[18]研究了中文自然语言网络中的复杂网络特性,根据语言网络的 “小世界” 特点,提出了一种基于复杂网络的关键词提取算法。杨志墨等[19]将复杂网络与向量空间模型结合,并应用到中文文本分类中,解决了中文文本结构和语义信息的缺失问题。Zhan 等[20]考虑到将传统的长文本相似性度量方法直接移植到短文本时,由于短文本内容简短,数据稀疏,计算结果会出现偏差,所以将复杂网络模型用于表征短文本来计算短文本之间的相似度(STSim 模型)。利用复杂网络表征短文本是以短文本中词语之间的关系为连边,充分挖掘了短文本中的语义信息。
基于复杂网络的短文本相似性(STSim)模型,首先,对每篇短文本进行简单的预处理,包括分词、去除停用词等,形成每篇短文本的特征词向量vi=(wi1,wi2,…,wim),这里的wi1表示第i篇短文本中的第一个词。其次,以短文本中的词语为节点,词语之间的共现关系为连边,为每篇短文本构建复杂网络。再次,融合复杂网络节点的聚集综合度、中间中心度、路径系数,对每个词语节点计算复杂网络综合特征值α、β和η为调节因子,根据不同的应用可以取不同的数值。最后,利用文本的特征词向量和综合特征值,结合短文本中词语的语义相似性计算任意两篇文本的相似性,STSim(vi,vj)= cf × VecSim(vi,vj)。
为了更好地提高短文本相似性度量的精度,本文在STSim 模型的基础上,首先,考虑短文本中词语的共现强度,利用加权复杂网络表征短文本;其次,考虑词语节点在加权复杂网络中的位置,以及短文本加权复杂网络权重识别度低的特点,计算每个词语节点的加权综合特征值;最后计算短文本的相似度。
3 基于加权网络的短文本相似性度量模型的提出
3.1 加权复杂网络构建
普通的短文本复杂网络中,节点之间连边的权重为0 或者1,即词语之间仅以有无共现关系为权重构建网络,导致共现次数较多和共现次数较少的词对在短文本相似性度量中起相同的作用。实际上,共现次数较多的词对之间语义相似性更大一些,也更能体现其所在短文本的主题,理论上共现次数较多的词对在短文本相似性度量过程中有更大的贡献作用。因此,本文需要对短文本构建加权复杂网络。
在构建加权复杂网络之前,首先对短文本进行分词、去除停用词等简单的预处理,从而得到每篇短文本的特征词向量。以下是构建短文本加权复杂网络的过程。
Step1.构建每句话的加权复杂网络。以每个词语作为节点,词对在同一句子中共现作为连边,词对在句子中的共现次数作为连边的权重建立网络。本文依据文献[16]的研究,选取关联跨度为2,即词对共现的依据是两个词语在句子中的距离小于或者等于2。例如,句子 “词语相似度算法对于短文本之间词语的相似度计算有重要影响” ,分词结果为 “词语” “相似度” “算法” “对于” “短文本” “之间” “词语” “相似度” “计算” “重要” “影响” ,图1 为该句子的加权复杂网络图。

图1 一个句子的加权复杂网络
Step2.构建整篇短文本的加权复杂网络。通过合并句子网络中所有相同的节点和连边,对相同词对之间连边的权重求和,来构建整篇短文本的复杂网络。
3.2 节点加权综合特征值的计算
短文本加权复杂网络中,词语节点的位置与其重要程度有着紧密联系,如果一个词语节点处于许多子网络路径上,说明该词语是许多其他词对之间内在语义关联的桥梁,因而更重要。中间中心度测量的是一个节点位于网络中其他节点 “中间” 的程度,如果一个节点处于许多其他点对的最短路径上,可以认为该节点位于重要地位,因为处于这种位置的节点可以通过控制或者曲解信息的传递而影响群体。中间中心度的计算公式为
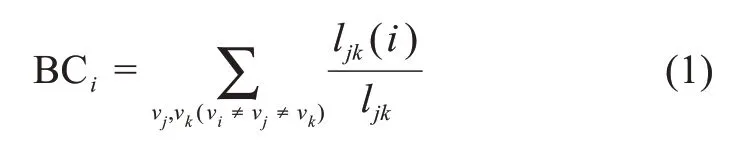
其中,V={v1,v2,…,vn}为复杂网络节点集合;ljk表示节点vj与vk之间的所有最短路径数量;ljk(i)表示节点vj与vk之间经过节点vi的最短路径数量。
由于共现次数较多的词对之间语义相似度更大一些,在短文本相似性度量中有更大的贡献作用,本文构建了短文本的加权复杂网络。词对之间的共现次数体现在词对之间连边的权重上,一个节点的权值越大,说明该词语越重要。传统节点的权重度计算公式为

其中,WDi表示由所有连接节点vi的连边的权重和;E={eij|vi∈V,vj∈V}为复杂网络连边集合。
传统的权重度算法不能针对不同网络特性进行相应的调整,只是不加区别地将连接某一节点的连边的权重相加。然而,短文本由于本身包含的信息量少,其中词语的共现次数非常少,导致短文本加权复杂网络中节点间连边的权重非常小,因此,这种节点权重度算法的识别效果并不明显。
针对短文本加权复杂网络的特点,本文提出用改进的节点权重度算法来突出词语共现次数对识别结果的影响。为词语共现次数设置一个权重函数f(x),改进的节点权重度计算公式为

加权综合特征值的计算充分考虑了短文本中词语的位置和词对的共现次数,反映了短文本加权复杂网络中词语相对于其他词语的重要度,以及词语对整篇短文本主题的贴近度,加权综合特征值的计算过程如下:
Step1.计算所有节点对其相邻节点的输出重要度比例值,得到相邻节点重要度输出矩阵,记为HIC[21]:

其中,Di为节点vi的度;δij为共现分配参数,若两个节点相连,则δij=1,否则,δij=0;对角线上的元素为1,意味着节点对自身的贡献输出比例为1;k为节点的平均

Step2.融合节点的中间中心度和权重度,得到节点的重要度评价矩HE:

其中,Ci=(n- 1)BCi。
Step3.计算节点vi的加权综合特征值WZi:
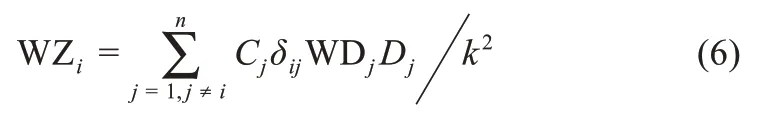
3.3 短文本相似性度量模型
设va和vb是两篇不同短文本A和B的特征词向量,其中,va=(wa1,wa2,…,wai,…,wam),vb=(wb1,wb2,…,wbj,…,wbn),不失一般性,令n≥m。构建两个短文本的词语相似性矩阵S:

其中,sij为词语wai和wbj的相似性,本文直接引用文献[22]中的词语相似性算法进行计算。
定义短文本之间的相似性为

其中,cf 表示短文本特征词向量va和vb之间相似度的加权因子,Sim(va,vb)表示短文本特征词向量va和vb的相似性。
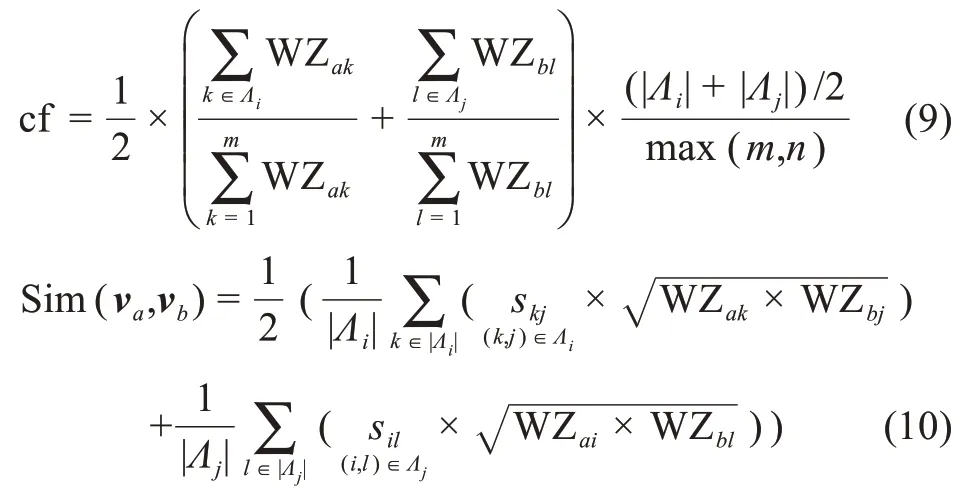
其中,WZak表示短文本A中第k个词语的加权综合特征值;skj表示短文本A中第k个词语和短文本B中第j个词语的相似性值。公式(9)和公式(10)中的集合Λi和Λj定义为
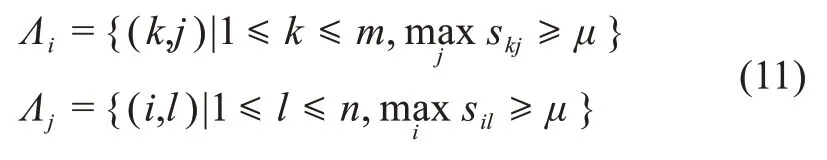
取S中每一行的最大值,即分别取特征词向量va中每个词语wak与另一个特征词向量vb中的所有词语相似性的最大值,若该最大值大于或者等于提前设定的阈值μ,则将该词语的下标放入集合Λi中;同样地,选取每一列的最大值,若该值大于或者等于μ,则将该词语的下标放入集合Λj中。|Λi|、|Λj|分别表示集合Λi、Λj中的元素个数。
4 实验与分析
4.1 数据来源
本文选取中国知网(China National Knowledge Infrastructure,CNKI)的4 个短文本子集作为实验的基准数据集,为了降低实验的时间复杂度,本文共选取了800 篇短文本进行实验。CNKI 数据库中,学科领域导航共有10 个专辑,分别是:基础学科、工程科技Ⅰ辑、工程科技Ⅱ辑、农业科技、医药卫生科技、哲学与人文科学、社会科学Ⅰ辑、社会科学Ⅱ辑、信息科技、经济与管理科学,每个专辑又包含若干个专题。
从CNKI 的10 个学科分类专辑中各选取一个专题,共选出10 个专题,依次检索每个所选专题的文献,选取前20 篇有摘要的文献,下载文献的题录信息,并提取文献的摘要,共提取到200 篇文献摘要,作为第一个短文本基准数据集,记作CNKI 1。
从CNKI 的10 个学科分类专辑中,各选取一个专题,所选专题避开CNKI 1 已经选过的专题,共选出10 个专题;用同样的方法得到200 篇文献摘要,作为第二个短文本基准数据集,记作CNKI 2;按上述步骤得到另外两个短文本基准数据集CNKI 3 和CNKI 4。最终得到数据集CNKI 1、CNKI 2、CNKI 3 和CNKI 4,共800 篇短文本,对每篇短文本进行分词,去除停用词等简单的预处理,从而形成特征词向量。
4.2 实验过程
Step1.对每篇短文本进行预处理,形成特征词向量。
Step2.构建每篇短文本的加权复杂网络。
Step3. 计算每篇短文本中每个词语的加权综合特征值。
Step4.结合公式(7)~公式(10),求得短文本数据集中短文本两两之间的相似性,得到短文本相似性矩阵。
度量短文本相似性的时候,首先要确定词语相似性阈值μ的大小对实验结果的影响。若选取较小的μ值,可能会产生较多的冗余信息,提高某些无用词在网络中重要性,同时增加计算复杂度。如果选取较大的μ值,则会因为短文本之间词语相似性大多数都低于μ值,导致短文本相似性急剧下降。图2 是数据集CNKI 1 中词语之间相似性值的分布直方图。本实验选取μ=0.6。

图2 词语相似度频次直方图
4.3 聚类评价指标
为了验证本文算法的有效性,对本文提出的短文本相似性度量模型进行聚类实验,并与STSim 算法作对比。本文利用gCLUTO 工具包[23]中的Repeat‐ed Bisection (重复二分法)、Direct(直接聚类)、Agglomerative(凝聚聚类)和Graph(图形聚类)4种聚类算法进行了聚类实验。
文本实验选用的评价指标有纯度(purity)、熵值(entropy)和F-度量值(F-measure)[24]。
设短文本原来的主题分为k类,记作Lj(1 ≤j≤k),则短文本集聚类后得到k个簇,记作Sr(1 ≤r≤k)。设有n篇短文本,nr和nj分别为簇Sr和类Lj中包含的短文本数,其中有nrj篇相同文本,则纯度和熵值为

每类文本的准确率(precision)和召回率(re‐call)定义如下:

加权平均得到整体的准确率和召回率,分别记为P和R:
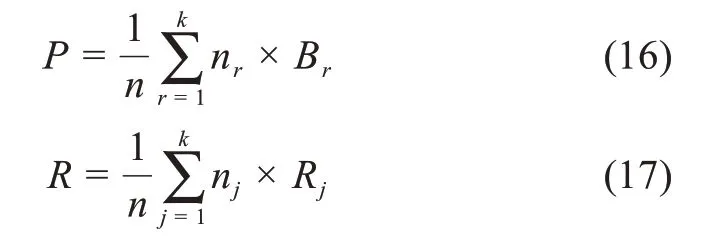
根据准确率P和召回率R,获得一个综合的评价指标来衡量聚类的效果,即
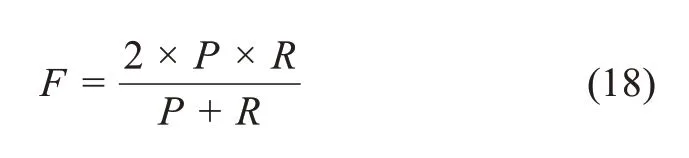
4.4 实验结果
Zhan 等[20]已经将STSim 模型与传统的基于TFIDF 方法短文本相似度算法、结合词项语义信息的文本相似度算法TSemSim 以及基于子树匹配的短文本相似度算法SubTSim 进行了聚类结果比较,验证了STSim 算法比传统算法具有更高的聚类精度。在此基础上,本文将基于加权复杂网络的短文本相似性度量模型(加权)与STSim 模型(无权)进行了聚类实验比较,每一种模型均用4 种聚类算法对4个数据集分别进行了30 次实验,利用多次实验求得的纯度、熵值和F值3 个指标的均值来对聚类结果进行评价,分析对比结果如图3~图6 所示。
图3~图6 中,每一簇的3 个线段以及其对应的数值,分别表示两种算法应用到4 个数据集上聚类结果的纯度、熵值、F值3 个评价指标。其中,纯度和F度量值越高,聚类效果越好;熵值越低,聚类结果越准确。从上述图中可以看出,利用重复二分法进行聚类时,本文提出的新算法(加权)的纯度和F度量值分别在0.637 和0.689 以上,都明显高于改进之前的模型(无权),分别平均提高了17.68%和12%;熵值都在0.273 以下,明显低于改进之前的模型,平均降低了16.15%。利用直接聚类算法进行聚类时,本文提出的新算法(加权)的纯度和F度量值分别在0.657 和0.676 以上,都明显高于改进之前的模型(无权),分别平均提高了15.73%和10.93%;熵值都在0.278 以下,明显低于改进之前的模型,平均降低了17.15%。利用凝聚聚类算法进行聚类时,本文提出的新算法(加权)的纯度和F度量值分别在0.595 和0.639 以上,都明显高于改进之前的模型(无权),分别平均提高了14.83%和10.78%;熵值都在0.323 以下,明显低于改进之前的模型,平均降低了15.15%。利用图形聚类算法进行聚类时,本文提出的新算法(加权)的纯度和F度量值分别在0.648 和0.669 以上,都明显高于改进之前的模型(无权),分别平均提高了14.2%和14.6%;熵值都在0.3 以下,明显低于改进之前的模型,平均降低了16.2%。
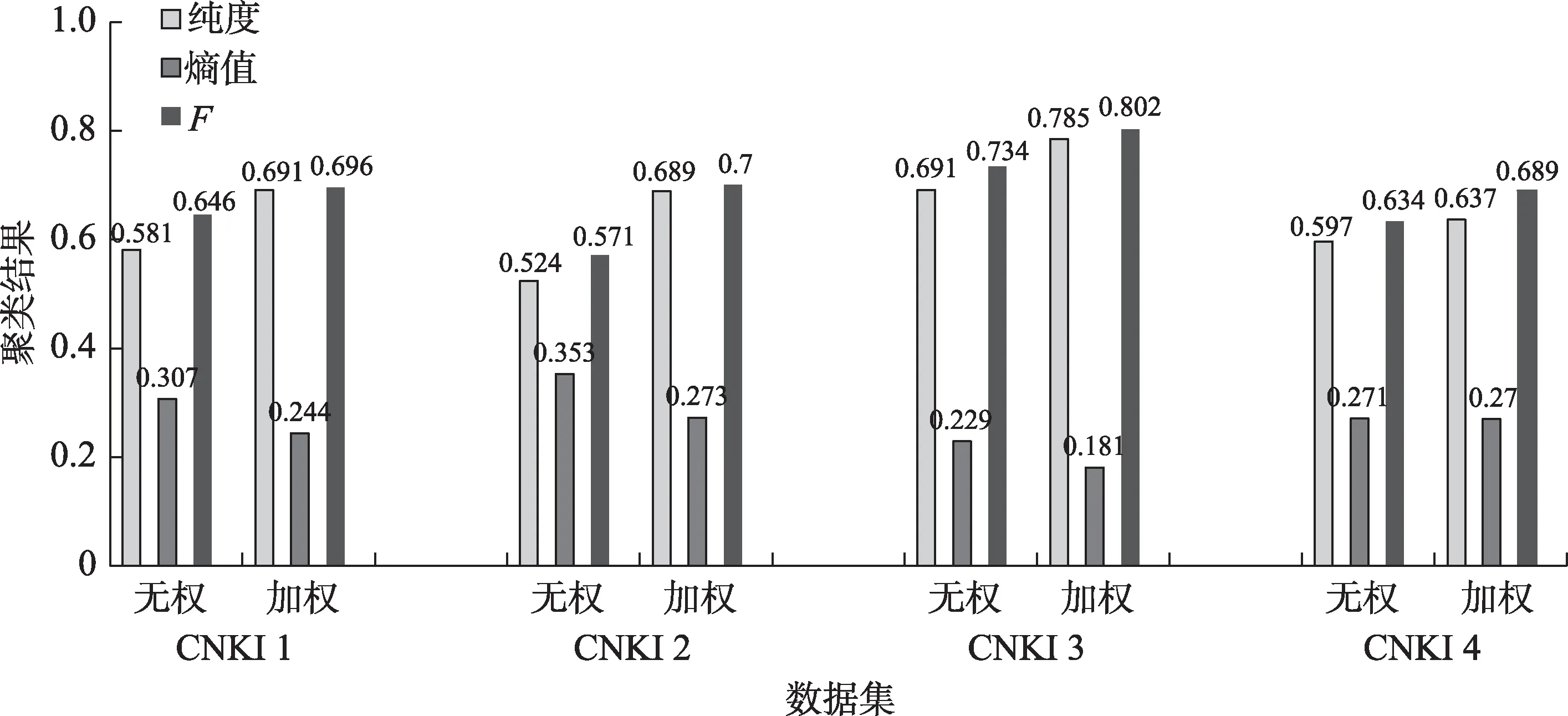
图3 重复二分法聚类结果
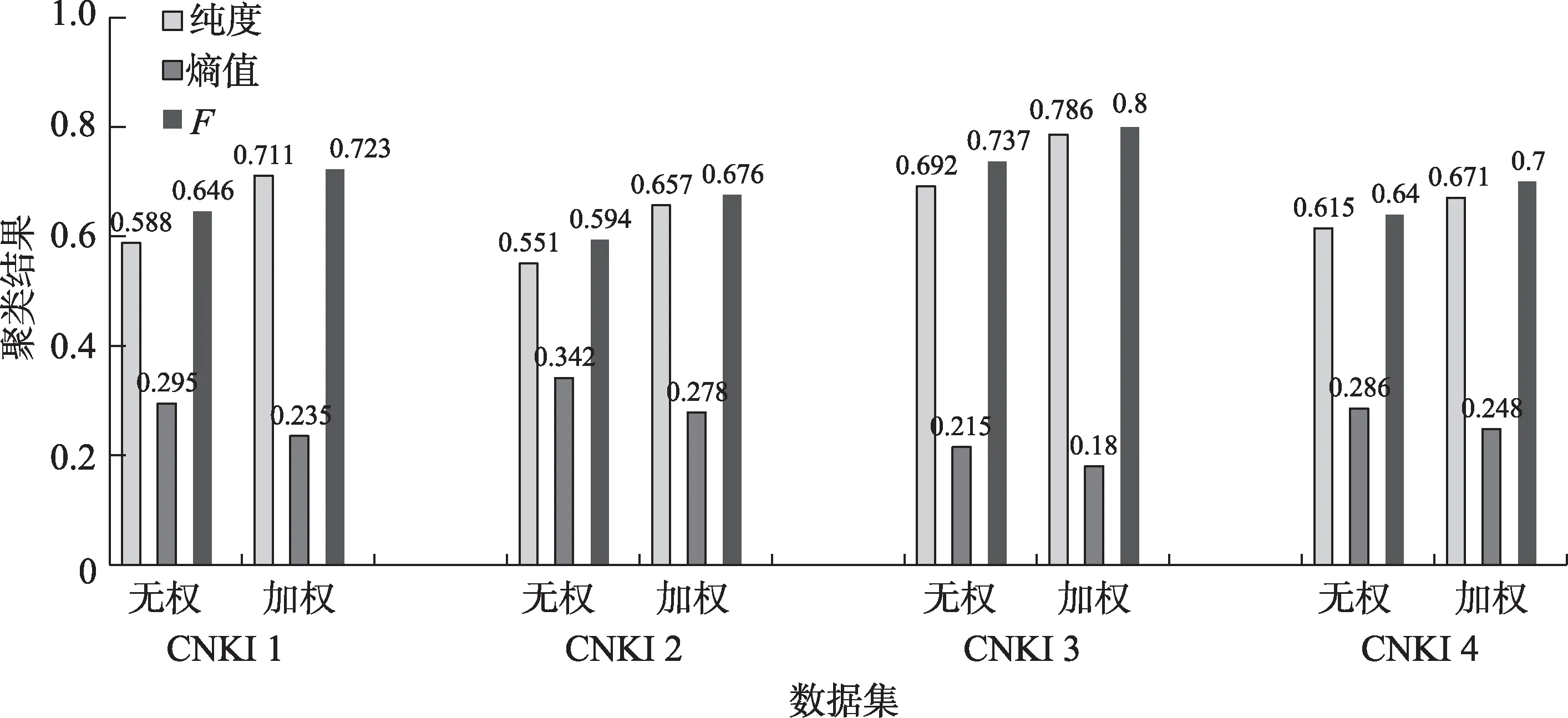
图4 直接聚类结果
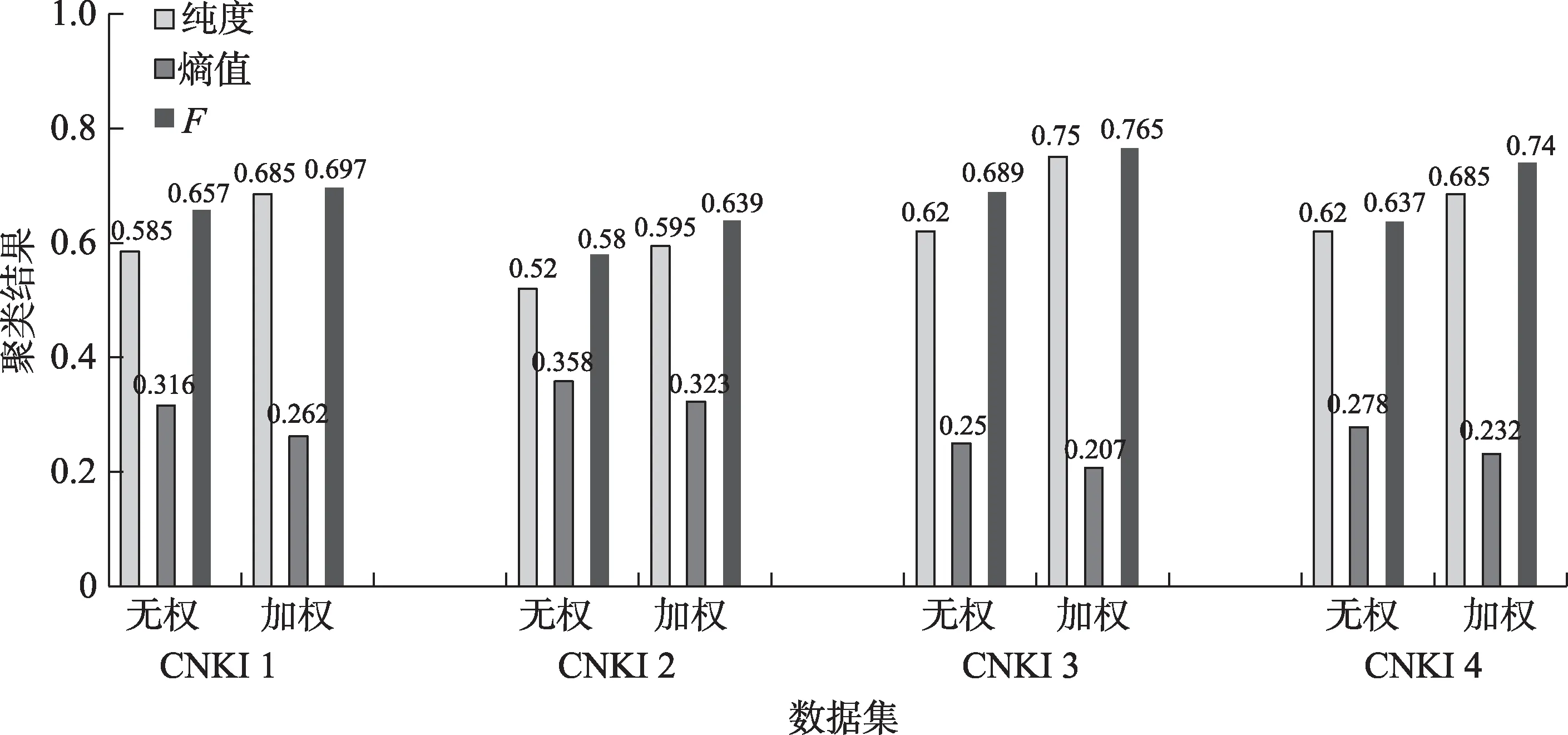
图5 凝聚聚类结果
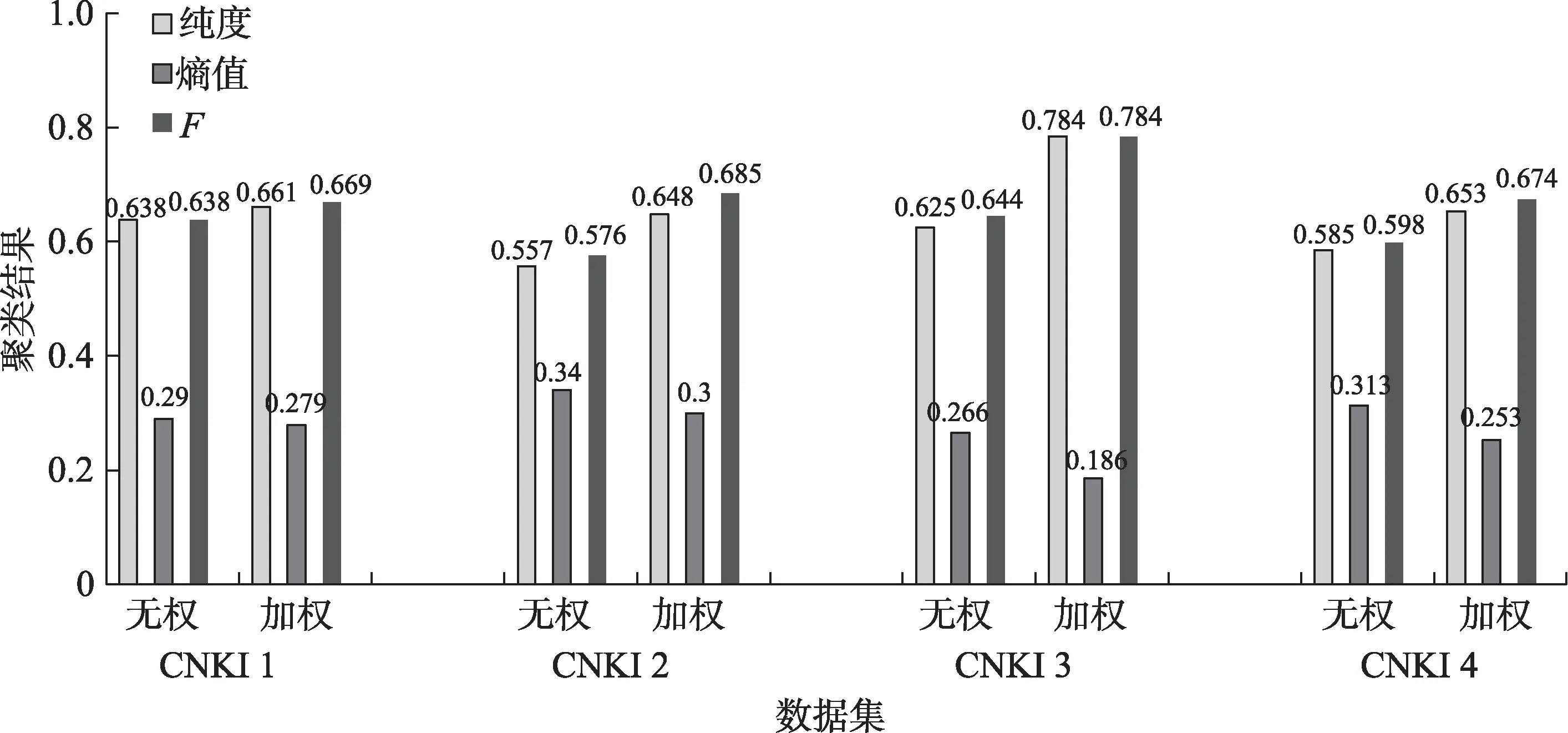
图6 图形聚类结果
在4 个短文本数据集上,不论运用哪种聚类算法进行实验,基于加权复杂网络的短文本相似性度量模型(加权)的纯度和F度量值基本分别在0.65以上和接近0.7,有的甚至达到了0.8,均高于STSim 模型(无权);熵值基本都在0.27 以下,均低于STSim(无权)的熵值。这与基于加权复杂网络的短文本相似性度量模型,考虑了词语之间的共现频次信息和短文本加权复杂网络权重识别度低的特点有关。通过计算可得,基于加权复杂网络的短文本相似性度量模型(加权) 比STSim 模型(无权)的纯度和F度量值分别平均提高了15.84%和12.02%,而熵值平均降低了16.23%。这说明本文提出的基于加权复杂网络的短文本相似性度量模型效果优于STSim 模型。
5 结 论
本文针对短文本加权复杂网络的特点,基于共现分析,提出利用改进的节点权重度算法来突出词语共现次数对识别结果的影响,进而得到新的短文本相似性度量模型。首先,利用短文本特征词间的共现关系和共现频次构建加权短文本复杂网络;其次,计算每个词语的加权综合特征值;最后,计算基于加权网络的短文本语义相似性,并在此基础上进行聚类检验。研究结果表明,就所采用中文的实验文本而言,本文提出的基于加权复杂网络的短文本相似性度量模型优于STSim 模型。本研究将继续探究文本结构对短文本相似性度量的影响,以期能够继续提高短文本相似性度量的精度。
