基于机器学习的人工智能技术专利数据集构建新策略
2021-04-21刘安蓉曹晓阳
陈 悦,宋 凯,刘安蓉,曹晓阳
(1. 大连理工大学科学学与科技管理研究所暨WISE实验室,大连 116024;2. 中国工程科技创新战略研究院,北京 100089)
1 引 言
颠覆性技术宏观逻辑路径(图1),展现出技术体系中由先导技术和主导技术突破而引起的相关技术的变革,从而发生技术体系的更新变换的历史大尺度的技术发展图景。以纺织技术、蒸汽动力技术、内燃机技术、控制技术、集成电路技术、生物技术、信息技术等为代表的颠覆性技术,带动先导技术和主导技术的突破变革,最终导致技术体系的变换而显现出颠覆性意义。
随着技术体系内部的矛盾运动,子系统内部及其之间体现出汇聚融合的趋势。当代 “会聚技术” 概念的正式提出[1]、美国国家研究理事会《融合:推动生命科学、物理科学、工程学等跨学科整合》的发布[2],表明学科交叉、技术融合趋势日益显著。日益成为关注热点的颠覆性技术更是呈现出了知识域界限日益模糊的趋势,因此,导致传统的科学技术分类方式呈现出局限性,这为本文基于学科或领域而进行的科技文献数据检索也带来了挑战。
专利是重要的科技文献数据源,获取精、准、全的技术域专利数据集是进行技术分析最为关键的基础性工作。从事科技工作查新的研究者一般善于编写较为复杂的检索式,以各种数据库中已有的分类(如专利分类代码)或技术领域的代表词汇作为数据检索依据,然而,由于学科的交叉性和技术域的组合特征,专利分类代码难以有效的涵盖所需技术领域的所有专利,枚举技术领域的术语也较难实现,因此,对于复杂的颠覆性技术领域的检索结果存在查全率和查准率低下的问题。
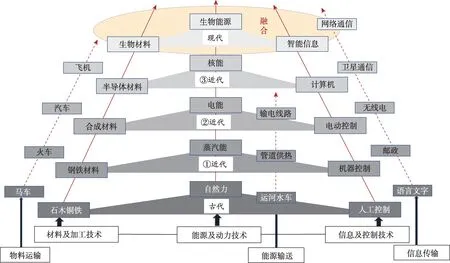
图1 颠覆性技术发展的宏观历史路径
人工智能技术是公认的颠覆性技术,由于人工智能技术的多学科综合和高度融合会聚的特征,使得该技术领域的专利信息检索一直存在查全率低下的问题,不同的检索人员所获得的数据也会具有明显的差异[3-6]。其具体表现在三个方面:①界定模糊。人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门学问。狭义上,人工智能是指基于人工智能算法和技术进行研发及拓展应用;广义上,人工智能还包括应用构建在内的产业。②涉及领域广泛。伴随着技术的快速发展,人工智能呈现出向更广泛的领域迁移的趋势。③术语表达多样化。在考察关键词时,除了要从形式、角度和意义上对人工智能全面完整表达外,还需要熟悉人工智能领域本身的算法和应用。
本文提出的基于机器学习的专利数据集构建的新策略,根本目的是构建完备和精准颠覆性技术域的专利数据集提供一种新的思路和方法。多年以来,如何根据用户的需求检索到完整且精确的专利文献一直是一个非常活跃的研究领域,查询拓展方法被广泛应用于提高信息检索的查全率和查准率。目前,专利检索拓展的方法主要包含:基于全局查询拓展、基于局部查询扩展、基于本体词表查询拓展和基于关联规则查询拓展[7](表1)。
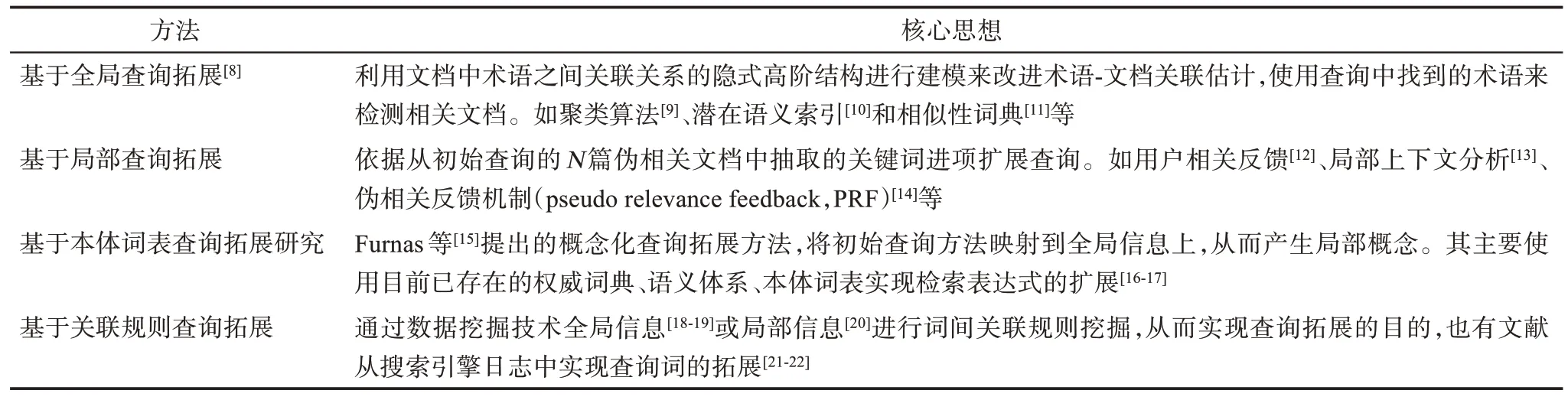
表1 专利检索拓展的主要方法
事实上,任何事物从无到有都是源于混沌或是有秩序的无序,人类为了便于对事物的认识,便努力寻找出其中的秩序,分类便是其中一种秩序的显现。一方面,对于技术组成体系复杂、融合学科较多的技术域,需要该领域专家对所有专利进行严格的人工筛选,这需要耗费大量的时间与人力。另一方面,通过上述查询拓展方法进行的专利检索任务,其本质仍然是基于扩展查询词构建检索表达式;而人工智能技术包含的知识和技能非常繁杂,这种查询拓展方法仍然不能获得高质量的搜索结果。针对这种复杂的技术知识系统,本文提出了一种基于机器学习的专利数据集构建的新策略,用文本分类的思想替代专利查询搜索方法,让事物回复到本原,通过分析专利内容对专利查询活动进行研究。基于卷积神经网络的机器学习的特点是让计算机自主学习经过专家标记好的训练集,对新的文本内容及类别信息作估计与预测,以搜集到相对 “精、准、全” 的人工智能专利数据,进一步形成用于技术分析的技术域数据集。
2 技术域专利数据集构建的设计与方法
本文的基本思想是将专利检索视为机器学习的二分类任务。以统计学理论为基础,利用算法训练机器,使其具有类似人类的 “学习” 能力,即对已知的训练数据做统计分析,从而获得规律,再运用规律对未知数据做预测分析,这样可以改善专利检索中的查不全和查不准等问题,有助于颠覆性技术域专利数据集的构建。目前,已有利用机器学习和深度学习来形成拓展检索词的相关研究[23],这种方法在一定程度上提高了专利检索准确率,但对于像人工智能技术域这样高度融合的复杂知识系统而言,还无法满足技术域专利数据集的完备性。
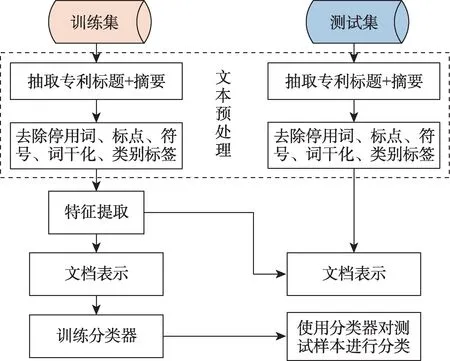
图2 专利文本分类流程图
基于上述内容,本文提出使用文本分类的方法来构建颠覆性技术专利集的新策略和流程(图2)。其中,分类模型基于对规模等同的 “正” “负” 两个样本集进行训练来建立, “正” 样本集是指确定为某技术域的专利数据集, “负” 样本集是指确定为非该技术域的专利数据集。为验证F-measure 特征最大化在特征选择阶段的优越性,进而构建合适的分类模型,本文构建了三种模型用于评估和测试,即 “基于卷积神经网络(convolutional neural net‐works,CNN)结构” 的文本分类、 “基于文档嵌入word2vec (word to vector) 的CNN” 文 本 分 类 和 “基于F-measure 特征最大化学习的CNN” 文本分类。
2.1 卷积神经网络结构
卷积神经网络(CNN)是模拟生物的视觉神经机制的一种神经元网络,最初应用在对大型图像的处理上,随后在各种自然语言处理任务中也有着令人瞩目的表现。基于CNN 的文本分类,既可以考虑到词语之间的关联联系,也可以利用单词顺序的位置信息。CNN 模型将原始文本作为输入,无需太多的人工提取特征,本文搭建的用于分类的CNN模型结构共分为7 层(图3)。第一,输入训练文本的索引单词(输入层,Input Layer);第二,将词汇索引映射到低维度的词向量进行表示(嵌入层,Embedding)①选取每条专利的长度为250个单词,每个单词表示为200维的向量,所以每条专利可以表示为一个250×200的二维向量。;第三,缩小向量长度(卷积层,Conv1 Layer),将单词向量合并为大的特征向量(池化层,Pooling Layer),卷积核宽度的设置要与每个单词的维度相等②本文中卷积核的设定为200。;第三,正则化卷积神经网络(第五层Dropout 层),使神经元可以单独学习有用的特征;第四,由于本文只有 “正” 和 “负” 两种类别,故将向量长度收缩到2(两层全连接层,Fully Connected Layer2)。
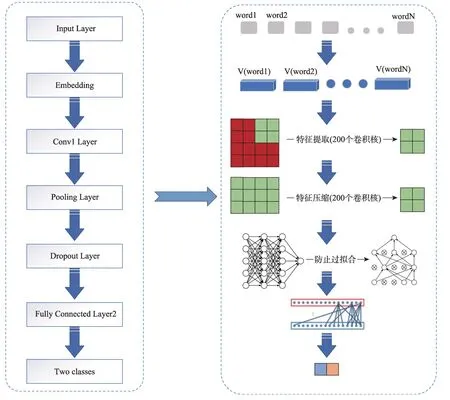
图3 CNN模型结构示意图
2.2 word2vec模型
深度学习的本质是对事物表示的学习,构建单词的表示是关键。文本分类的机器学习模型的构建前提是提取文档的特征,已有的文本特征提取方法,如TF-IDF(term frequency-inverse document fre‐quency)[24]、信息增益法[25]、互信息法[26]等,均需要人为的设置特定阈值和词语筛选,这在某种程度上会损失文档部分信息,而使用word2vec 模型可以有效解决这个问题。
word2vec 模型[27-28]是浅层的、双层的神经网络,用于生成词嵌入向量模型,其核心思想与自动编码器类似,即将某个单词作为输入的隐藏层,并试图重新建构单词的上下文。word2vec 将大量文本作为其输入,并且产生几百维的向量空间,文档中的每一个唯一的单词在向量空间中被映射为一个固定长度的短向量,向量空间为文档集合词语的向量表示,向量距离代表词语之间的相似程度。
word2vec 模型主要有两种模型,即CBOW 模型和Skip-Gram 模型。本文选用Skip-Gram 模型,其目标函数为

其中,c代表上下文的窗口大小,c越大,训练样本越多,准确率越高。基于训练数据构建一个神经网络,得到一个200 维的向量空间,利用训练好的模型所学的参数作为卷积神经网络中的嵌入层。
2.3 特征最大化方法
特征最大化方法(feature maximization)作为一种无偏度量方法,可以用于分类的质量评估,在特征选择阶段可以提取聚类关联特征,进一步提高分类器的精度。其主要优点是无参数,适用于高维数据聚类及算法设计,并在分化(discrimination)和泛化(generalization)之间表现出比通常指标(欧几里得、余弦或卡方) 更好的和解性(compro‐mise)[29]。特征最大化方法的定义为:一组特征F是数据集D经一种分类方法得到分区C的表征方式,在数据集D为文本数据的情况下,特征由文档提取的术语表示。那么,某个聚类c(c∈C)的关联特征f的度量指标FFc(f)被定义为 “特征召回率(feature recall) FRc(f)” 和 “特征主导率(feature predominance)FPc(f)” 的调和平均值。即
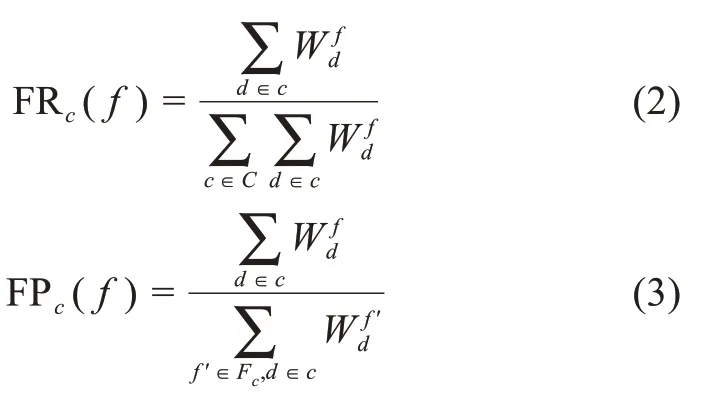
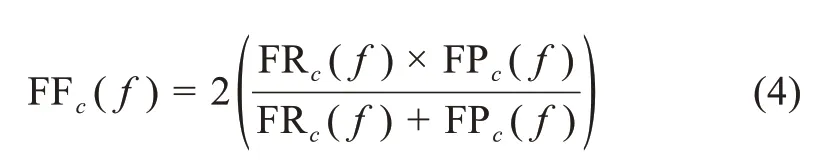
其中,表示数据d的特征f的权重;FFc(f)表示聚类c的所有关联特征;FPc(f)表示特征f表征聚类c的能力度量值;FRc(f)表示特征f表征聚类c区别于其他聚类的能力度量值。
在特征提取过程中,可以依据特征值的F测度,从中选择得分最高的特征项,被判定给某聚类的特征项的F值既要大于所属聚类的F平均值,又要大于所属分区所有特征的平均特征值,在任何类中,不满足第二个条件的特征项都要被移除。另外,定义对比度(contrast)这个特定概念来计算给定类c中保留特征f的性能:类c的特征f的对比度越高,其在描述类内容时的性能越好。对比度可以表示为
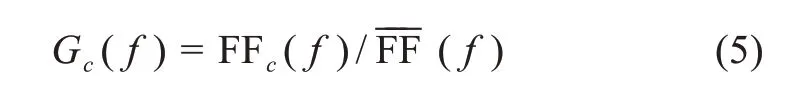
该方法已经成功地运用在许多复杂的文本分类任务中[30],与现有的一些先进的方法技术相比已经显示出非常优越的性能,其主要的优点是与语言无关,且无参数。本文将特征最大化的特征提取方法嵌入卷积神经网络的第二层中。
3 人工智能技术专利数据集的构建策略检验
德温特专利数据库(Derwent World Patents Index,DWPI)的深加工数据是现今业界最受信赖的专利研究信息来源,其收录的专利信息均是由各个行业的技术专家进行重新编写、矫正和补充,其深入缜密的编辑流程和质量控制保证了专利数据的权威性和准确性。因此,DWPI 是进行专利分析的理想数据源,但由于DWPI 中分类代码中没有人工智能的分类代码,且手工代码为 “artificial intelligence” 的专利仅有4640 条①检索日期:2020.3.14;检索式:MAN=(T01-J16 OR T06-A05A OR X13-C15B),本文无法获得明确的AI(artifi‐cial intelligence)专利数据。美国专利数据库(Unit‐ed States Patent and Trademark Office,USPTO)中美国专利分类体系(United States Patent Classification,USPC) 有一个明确的人工智能分类,即706 类 “Data processing:Artificial intelligence” 中共有专利13539 条(1974—2015)②检索日期:2020.3.15;检索式:CCL/706/$,但由 于USPTO 于2015年用联合专利分类体系(Cooperative Patent Classifi‐cation,CPC)取代USPC 分类体系,之后该分类号下的专利不再更新。为了在DWPI 中获取全部AI 专利数据,本文以USPTO 中提取的人工智能专利作为正样本数据集进行实验,形成规则,进而形成较为完备和精准的AI 专利数据集。
3.1 实验数据集
实验数据集由 “正” 和 “负” 两个样本集构成(图4)。正样本数据由13500 条源于USPTO 的AI 专利数据和依据Acemap 知识图谱(AceKG)中人工智能主题下的本体词表获取的500 条短文本数据组成。由于USPTO 于2015 年后不再使用USPC 分类体系,故对于近年的AI 专利信息是缺失的。但是AI是一个快速发展的领域,其新名词、新术语不断涌现,因而本文通过AceKG 来拓展相关信息,以保证检索的完备性。AceKG[31]提供了近100G 大小的数据集,包括论文、作者、领域、机构、期刊、会议、联盟,支持权威和实用的学术研究,通过计算机科学主题的学术知识图谱获取子话题 “人工智能” 的词表(1052 个主题词),可以生成500 条短文本信息①短文本数据示例:artificial intelligence expert system knowledge engineering environment reasoning system SLD resolution legal expert system,最终,获得正样本数据共14000 条。
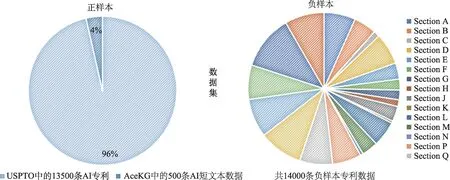
图4 训练数据集构成示意图(彩图请见http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
由于本文最终要进行分类的数据是DWPI 中手工代码Section T(computer science)下所有的专利,故负样本数据要从同一级别其他分类代码中进行选取,而且数据规模要等同于正样本集,即由14000条专利组成负样本集。具体抽取方式如附表1 所示,并且本文已通过人工专业知识从负样本专利集合中过滤掉与人工智能相关的专利,确保了负样本数据的准确性。
3.2 实验设置
3.2.1 数据预处理
抽取正、负样本数据集中的标题字段和摘要字段写入到训练文本中,训练文本中的每行数据代表一个专利的标题加摘要信息,并对每一篇专利标明类别标签,正样本为1,负样本为0。然后,对训练文本进行单词标准化和停用词的处理,并去掉标点和符号。
随机抽取1000 条专利数据(正样本500 条、负样本500 条),专利长度统计结果(图5)表明,专利文本长度基本在50~250 个单词的范围之内,为了方便之后对全部专利文本做批量处理,需要对训练文本进行固定长度截取,本文截取了每条专利的前250 个单词,尽可能保留每条专利的全部信息。
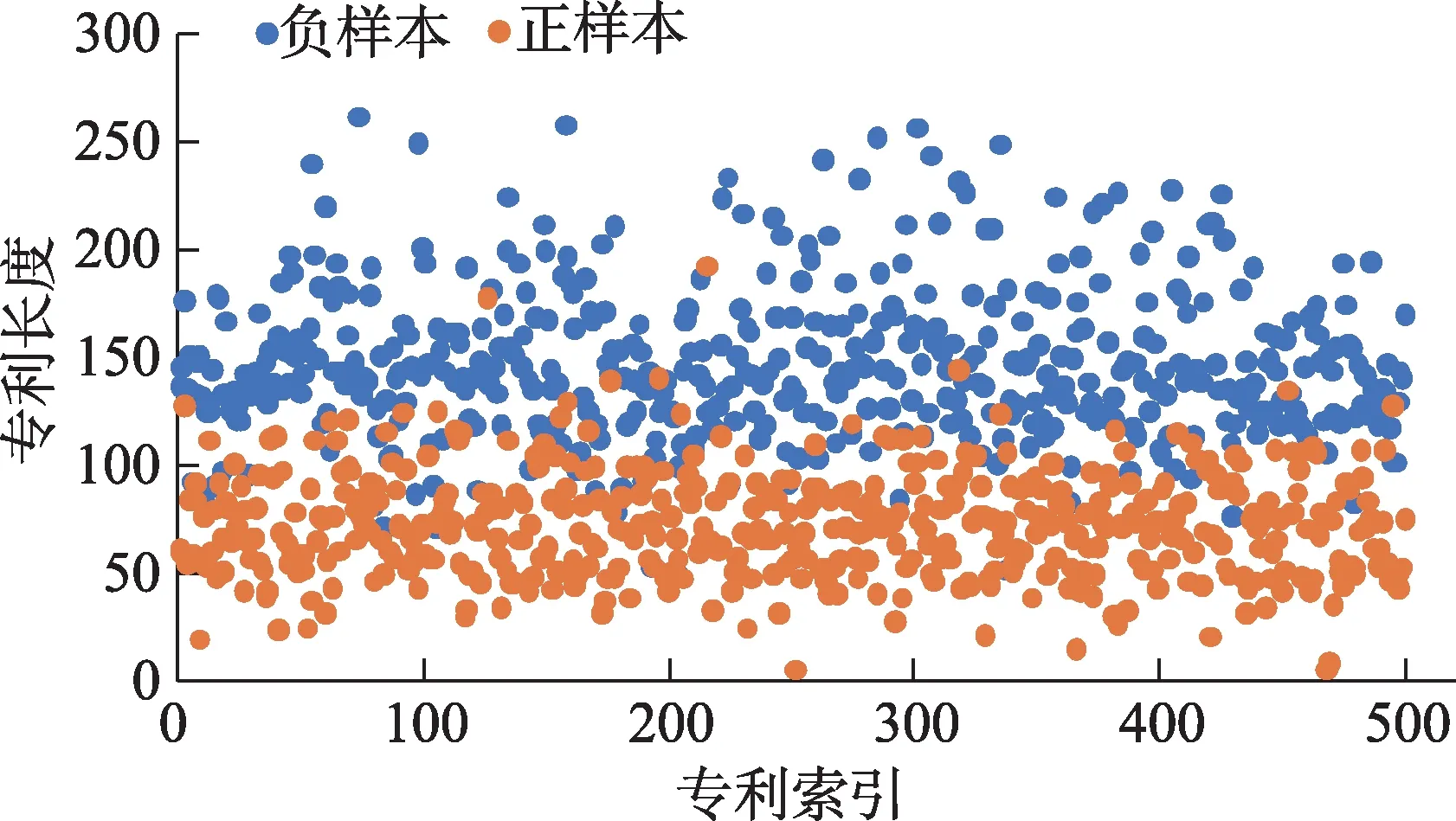
图5 专利文本长度统计
3.2.2 生成文档词向量
通常在训练机器学习模型时,将数据分为训练集、验证集和测试集。训练集用于训练模型以及确定模型权重,验证集用于进一步网络调参,测试集可以评估模型的精确度。本实验将全部数据集按照8∶2 分为训练集和测试集,将训练集按照9∶1 的比例分为交叉验证的训练集和验证集。本文使用了三种模型进行文本分类。
模型1:基于卷积神经网络结构的文本分类
首先,本文使用深度学习Keras 工具提取训练数据和测试数据的特征,将训练数据中的专利文本处理成单词索引序列,单词与序号之间的对应关系通过此单词索引表进行记录;其次,将每行专利处理成相等长度(长度不足的专利内容用0 索引填充);最后,使用图2 中的CNN 模型训练分类器进行文本分类。
模型2:基于文档嵌入word2vec 的CNN 文本分类
标记好的训练样本规模较小是本文在训练文本分类模型时面临的一个问题,这使得准确权威的训练样本尤为重要。因此,本文将预训练好的word2vec模型迁移进分类模型,替代CNN 模型的嵌入层,word2vec 模型已经被证明可以大幅度提高自然语言处理模型在文本分类上的性能[32],降低学习成本。使用预训练好的word2vec 模型,既可以间接引入外部训练数据防止过拟合,又可以减少训练参数个数提高计算效率,使本文可以在更少的训练样本上得到更可靠的分类模型。
word2vec 模型可以根据原始语料对每个词生成一个词向量,训练样本的每一行代表这一篇专利即一个词语序列,使用预训练好word2vec 的Skip-Gram 模型对训练文本进行处理,因此,对于每一篇专利都可以将其转化为一个200 维的向量,即每篇专利可以表示为一个250×200 的矩阵,其中250代表每行训练样本单词的个数,200 表示每个单词表示为200 维的向量。将通过word2vec 方法建立起的词嵌入矩阵代替CNN 模型中的嵌入层,设置嵌入层的参数为固定参数使其不再参与训练过程,这样就使得由Skip-Gram 模型提取的词向量表示嵌入到CNN 模型之中,最后进行分类器的训练。
模型3:基于F-measure 特征最大化的文本分类方法
特征最大化已被证明可以在小规模的专利数据集中有效的选择特征[30],本文利用F指标对监督学习的文本分类过程进行特征提取,将特征最大化方法与卷积神经网络模型相结合。首先,本文使用由斯图加特大学计算语言学研究所开发的TreeTagger工具[33],将训练文本转换为词袋模型,则每一篇专利可以表示为一个词频向量(由从其摘要和标题中提取的术语频率组成)。为了减少该工具所产生的噪声,在提取描述符的过程将频率阈值设置为20,整个训练文本集合表示为(N+1)×J矩阵,其中,J是N维空间中训练样本所包含的专利数量;N+1 表示为第J篇专利的N维词包加上其类标签。其次,使用TF-IDF 加权方案给出训练文本的稀疏矩阵表示[34],此矩阵为训练样本的特征词的权重矩阵,依据特征最大化方法选择文本特征,使用上述特征最大化过程选择单词的构成,在保证原文含义的基础上找到最具有代表性的单词,即过滤特征。最后,本文得到了对训练文本进行表示的特征矩阵,将此矩阵替换CNN 模型中的嵌入层进行分类器的训练。
在整个数据集上使用上述三种模型进行训练测试,并且在所有的实验中均应用十次交叉验证过程。交叉验证是用来验证分类模型性能的一种统计分析方法,是为了得到可靠稳定的模型,其基本思想是将原始数据集分为训练集和验证集。其中,训练集用于训练分类模型,验证集用于分类模型的选择。本实验选择了K倍交叉验证(K-fold cross validation),Keras 允许在训练期间手动设置训练数据集和验证数据集的比例,本研究使用全部数据集的80%用于训练、20%用于测试,将22400 条训练数据平均分成10 份,使用第2~10 份数据作为训练集训练模型,使用第1 份数据作为验证集评估模型,得到一个模型准确度评分。然后,微调网络参数,再使用第1份和第3~10 份数据重新训练模型,使用第2 份数据对模型进行精确度评估。以此类推,把每一次交叉验证结果的均值进行比较,最终选出一个最优值。
ROC 曲线(receiver operating characteristic curve)下方面积可作为评价分类模型优劣的指标,线下面积越接近于1,曲线越凸向左上方向,则分类器效果越好。由图6 可见,三个模型所训练出的分类器效果都较为理想,其中模型3 的分类器正确率最高。
3.3 实验结果评价
二分类模型的单个样本预测有4 种结果,这4种结果可以写成一个2 × 2 的混淆矩阵,如表2所示。
以表2 的混淆矩阵为基础,本文选择准确率、召回率和F1 值作为分类模型的评价指标。其中,所有样本能够被正确预测的比例称为准确率:
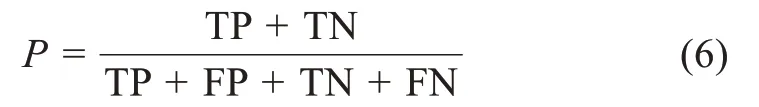
实际为正类的样本中,能够被正确预测为正类的比例称为召回率:

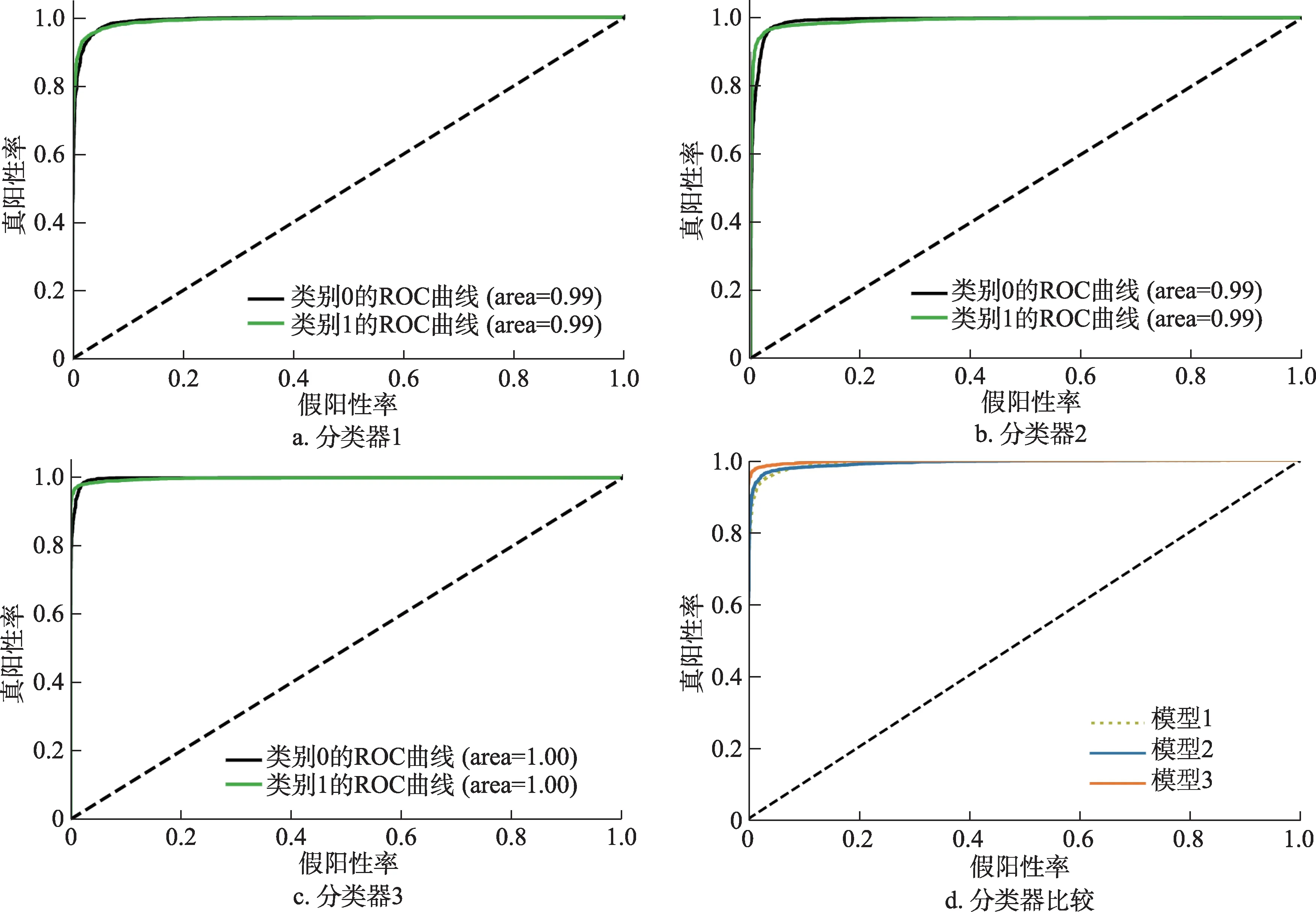
图6 不同分类器模型的ROC曲线

表2 混淆矩阵
F1 值用精确率和召回率的调和平均数表示:
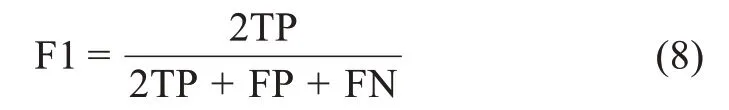
一共存在5600 条专利文本作为测试数据,对本文所训练的评估模型进行检验(表3),由模型3 训练得到的分类结果最好,将人工智能专利预测为正类的数量为2798 个,将非人工智能专利预测为负类的数量为2686 个。实验结果表明,本文所提出的技术能够在测试集上较为精确区分正例(即AI 专利)和负例(即非AI 专利),最高能够达到了98.01%的分类准确度。因此,本文所提出的方法证明了对构建人工智能技术专利数据集的有效性。
利用训练后的最优分类模型对德温特数据库(Section T)①检索日期:2020.4.20;检索式:MAN=(T01*OR T02*OR T03*OR T04*OR T05*OR T06*OR T07*);时间跨度:1963-2019;检索结果:7307036件专利中的专利内容进行遍历和挑选,分类出人工智能专利构成人工智能技术专利数据库,共693281 件。按照德温特入藏登记号(GA 字段)对专利数据进行去重,并按照申请号对同族专利进行合并,最终获取624234 件人工智能的申请专利。1963—2019 年,全球人工智能领域的专利申请数量呈现指数型增长趋势,并由三个阶段性增长曲线构成(图7)。
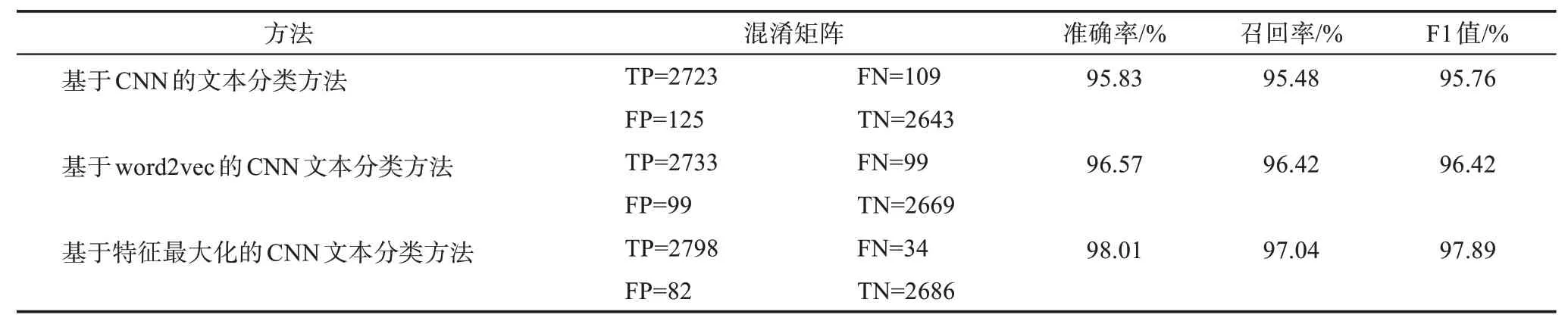
表3 分类结果
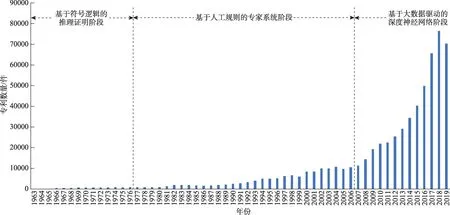
图7 全球人工智能领域专利数量及发展趋势
4 结 论
目前,人工智能无处不在,尤其在主要工业领域中均有应用。因此,有效且完整的搜索策略不能局限于特定的工业领域。此外,人工智能的定义非常灵活,会随着时间的推移而发展,昨天被视为人工智能领域的技术现在可能被视为常规技术,新技术每天都在被发明和创造中。这意味对于人工智能技术专利数据集的查询,本文必须考虑到非常广泛的技术群。
严谨的技术域专利检索不应该是一键式检索,而应该是一种探索或者说是向精、准、全的检索结果不断攀登的一个过程。传统的查全与查准平衡理论,对人工智能领域主题的全面、精准分析不再适合,在掌握数据分析的工具与理念、可视化工具的背景下,应当以查全优先,这样在后续的可视化分析中更容易提取相关的记录,而不至于有所遗漏。对于某些学科、专题和微小的遗漏或许会造成重大的失误。
本文从文本分类的角度,对人工智能技术域的专利数据集构建做了一次有效的尝试,将专利检索任务成功地转化为机器学习中的文本分类任务,并将F-measure 特征最大化方法与CNN 模型相结合获得了一个较好的分类效果,分类模型的准确率、召回率和F1 值分别达到98.01%、97.04%和97.89%。实验结果表明,利用种子数据集扩充到完整数据集的这种思想是有效的、可行的。值得强调的是,有效的语料库和干净的文本数据是本文进行文本分类的重要保障,本文所使用的训练数据集是由人工智能专家进行标注,且从时间和范围上最大程度覆盖了人工智能领域的技术群。然而,由于人工标注成本高、耗时长,训练样本集不够丰富,在未来的研究工作中,本文将通过主动学习(active learning,AL)进一步提高分类模型在人工智能领域的泛化能力。
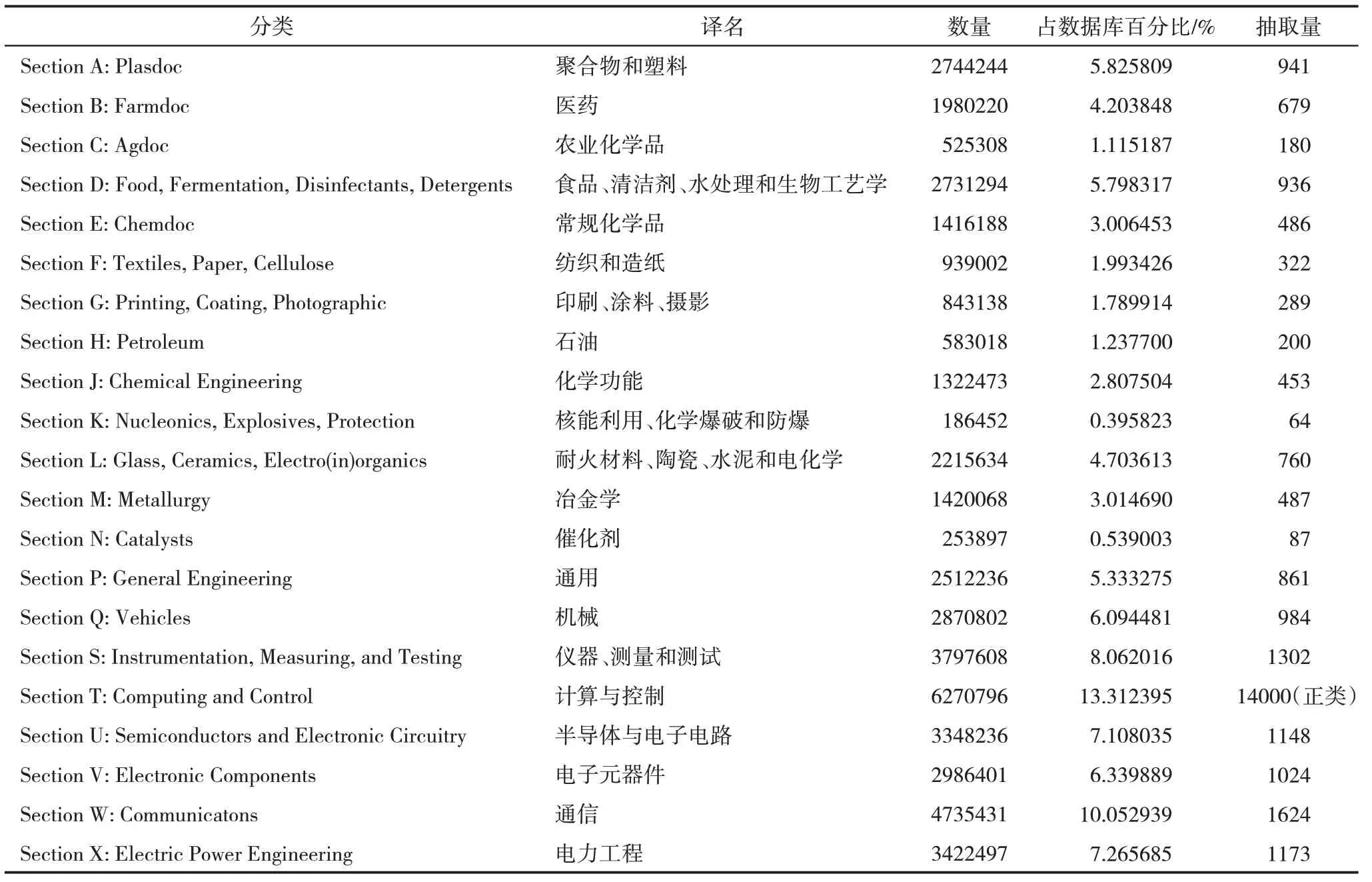
附表1 正负训练样本集抽取方法
