基于RAN 与深度哈希的图像检索方法研究
2021-04-20石灵奇王玉玫
石灵奇,王玉玫
(华北计算技术研究所,北京 100083)
基于内容的图像检索(CBIR)是计算机视觉领域重要的研究分支,近年来随着图像数据的大规模增长,传统的图像检索方式不能满足准确率和效率上的要求,因此卷积神经网络(Convolutional Neural Network,CNN)成为图像检索领域更重要的工具[1]。
由于CNN 在提取图像特征时对于图像的全部特征等价处理,因此其提取到的图像特征不仅包含目标信息,还包含杂乱的背景信息。文中提出一种改进的残差注意力网络(Residual Attention Network,RAN)[2]用于提取图像特征,该网络结合了残差网络(Residual Network,ResNet)[3]和注意力机制[4]的特点,将提取出的特征向量输入到哈希层得到图像的二进制编码,最后通过对比待查询图像的哈希码与训练集中每一张图像的哈希码之间的汉明距离来检索图像,实现端到端的训练和检索。
1 相关工作
1.1 卷积神经网络
近年来,CNN 在图像分类和目标检测等视觉任务上取得了重大突破[5],与人工提取特征相比,CNN可以通过自我学习的方式得到图像的高级语义特征表达,提取的特征也更准确[6-7]。但由于CNN 在提取图像特征时对于图像的全部特征等价处理,没有对图像重点区域进行关注,因此当图片背景信息复杂时,CNN 无法只关注目标信息。
1.2 注意力机制
在注意力研究的早期阶段,通过分析大脑成像机制并采用门控机制对注意力建模。近年来,越来越多的注意力研究工作与深度学习相结合。其中从注意力域的角度分析软注意力的实现方法主要包括3 种注意力域,即空间域、通道域和混合域。
1)空间域:图片中的空间域信息通过空间转换器[8]模块可以提取出关键信息。但空间域注意力对所有通道中的特征向量进行相同操作,容易忽略通道域中的特征信息,其对应的激活函数公式为:
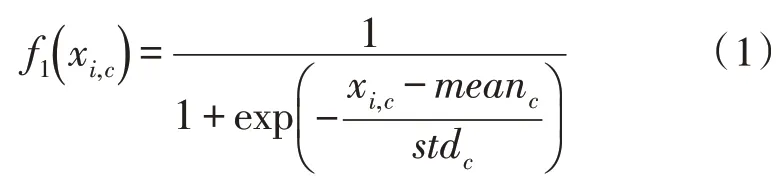
其中,i表示位置,c代表通道。meanc代表c通道的平均值,stdc代表c通道的标准差。
2)通道域:对于输入图像,使用多个卷积核可以从图像中提取多种特征[9]。输出图像的每个通道上的特征就代表该图像在不同卷积核上的分量,产生的多个通道对于图像关键信息的贡献不同。为了表示每个通道与关键信息之间的关联,可以给每个通道上的特征都增加相应权重。但该方法对每个通道的特征向量都进行了全局平均池化(global averagepooling),忽略了每个通道的局部特征,其对应的激活函数公式为:

3)混合域:混合域注意力机制结合以上两种注意力域的优点,其原理是将注意力机制与ResNet 结合使用。残差注意力学习机制把掩码操作之前的特征向量和掩码操作之后的特征向量结合起来作为下一层的输入,以便于定位图像的关键特征,其对应的sigmoid 激活函数公式为:

提出的基于RAN 和深度哈希的模型结合了ResNet 和混合域注意力机制的优点,将图像输入到RAN 模型中进行特征提取,然后将提取到的特征向量输入到哈希层得到图像的二进制编码[10],可用于图像间的相似度测量,实现端到端的图像检索。
2 文中方法
该文在模型设计上主要基于RAN 的结构层次,根据图像检索的特点,对RAN 中的模型进行改进,以便于提高图像特征提取和相似度度量的效率。改进后的网络结构由两部分组成,分别是RAN 和哈希层。其中RAN 主要由4 个残差单元和3 个注意力模块交叉堆叠而成,再经过哈希层得到图像的二进制编码。文中提出的模型结构如图1 所示。
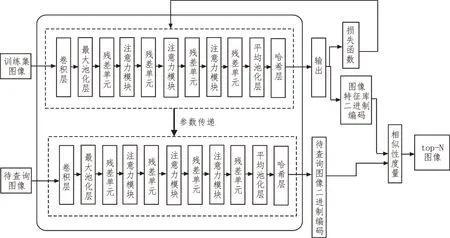
图1 基于RAN与深度哈希算法的模型结构
2.1 残差网络
文中选取ResNet-50 中的子结构作为残差单元。由于AlexNet、VGGNet 等网络加深到一定层次后继续加深也不能提升效果,反而会导致训练集准确率下降。ResNet 的出现很大程度上解决了深层网络退化和梯度消失问题,其可使网络加深到更深的层次。使用残差学习结构H(x)=F(x)+x代替原来的结构H(x)=x,这样更容易更新冗余层的参数。而残差学习结构也使得在反向传播更新参数时不会导致梯度消失,残差学习结构如图2 所示。

图2 残差学习结构
2.2 注意力模块
注意力模块由主干分支和掩码分支组成,主干分支用于提取特征,掩码分支进行特征选择。其中掩码分支使用自底向上、自顶向下的结构学习与该分支输入图像相同大小的掩码,得到注意力特征图,该特征图上的每个像素值相当于输入图像上对应位置像素的权重,它会增强有意义的特征且抑制无意义的特征。将主干分支与掩码分支输出的特征图的对应位置元素相乘得到加权注意力特征图。此时注意力模块H的输出为:

其中,i代表图像中的位置,c代表通道索引下标[11],M(x)代表掩码分支的输出,T(x)代表主干分支的输出。
由于注意力模块中掩码分支的激活函数是sigmoid 函数,其输出值在(0,1)之间,因此通过一系列乘法将会导致特征图的值变小,原始网络的特性也可能被破坏,导致层次极深时训练困难。因此可使用类似残差学习的方式解决该问题,即将上述得到的加权注意力特征图与主干特征图中对应位置元素相加,此时注意力模块的输出为:
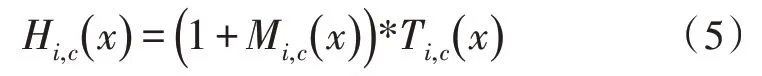
当M(x)=0 时,该层的输出等于T(x)且该层的效果不会变差,这使得主干分支输出的特征图中显著的特征得以进一步增强。通过将RAN 进行堆叠就可以使模型的深度达到很深的层次,可以逐渐提升网络的表达能力。注意力模块结构如图3 所示。
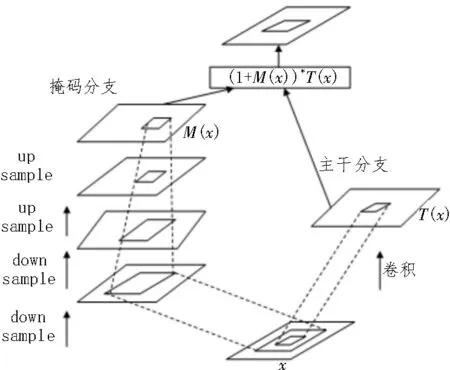
图3 注意力模块结构
在注意力模块中,掩码分支输入特征的掩码梯度为:

其中,θ代表掩膜分支的参数,φ代表主干分支的参数。这使得注意力模块对噪声的鲁棒性增强,能有效减少噪声对梯度更新的影响[12]。
在ResNet 特征提取模块的各残差单元之间加入注意力模块,可使得该网络提取的特征更好地聚焦于图像的目标对象。通过RAN 提取出图像的高维特征表达,然后将该特征向量输入到哈希层得到图像的二进制编码。文中使用的基于RAN 与深度哈希算法的模型参数如表1 所示。
2.3 哈希层
通过RAN 与深度哈希算法,借助注意力机制识别出图像中目标对象的近似位置,将图像映射成专注的特征向量,然后将该特征向量通过哈希层映射成二值编码。其中哈希码编码的主要对象为图像的目标信息。
为了解决图像检索中的检索效率问题,提出一种改进的RAN 模型,将原来RAN 模型中的最后一层——分类层替换为哈希层,该哈希层把网络提取出的高维图像特征表达映射成二进制编码。哈希层中使用tanh 函数作为激活函数,可将哈希层的连续输出用作哈希码的松弛[13]。深度哈希函数定义为:

表1 基于RAN与深度哈希算法的模型参数
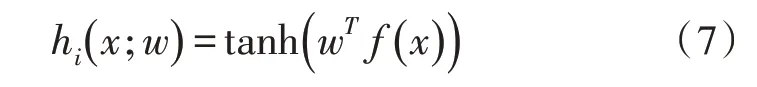
其中,w表示哈希层的权重,f(x)为上一层输出的特征向量。
2.4 网络训练
文中将相似性损失函数设置为如下公式:
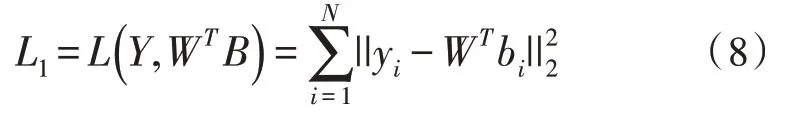
其中,Y=[y1,y2,…,yn]表示标签向量,W表示权重值,B表示二进制哈希码的集合,其中第i个样本的哈希码bi∈{-1,1}。
哈希码从连续值经过阈值化得到离散值的过程中会产生一定的量化误差[13-14],为促使深度哈希网络的输出接近二值编码,文中引入量化损失函数,其公式如下:
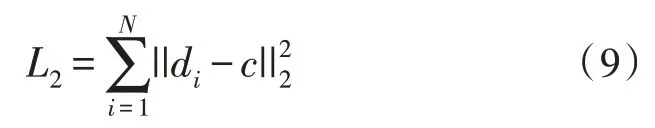
其中,di表示阈值化后的离散值哈希码,c表示未经阈值化的连续值编码,||·||2是l2范数。
通过整合相似性损失和量化损失,得到最终的目标损失函数,公式如下:
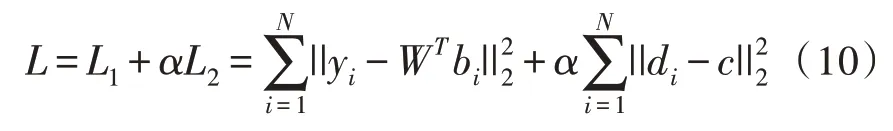
其中,a为用于控制量化损失的比重系数。
3 实验结果
3.1 数据集
文中实验使用Flickr 和NUS-WIDE 数据集对模型进行训练和验证[13,15]。其中Flickr 数据集包含25 000 张图片,每张图像至少和38 个语义标签中的一个相关联。从中选取5 000 张图片,测试集与训练集比例为4∶1,故训练集包含4 000 张图片,测试集包含1 000 张图片。NUS-WIDE 数据集包含81 个对象类别,每张图像都与一个或多个标签相关联。从中选取21 个标签,从每个标签中挑选600 张图片,训练集与测试集比例为5∶1。因此训练集图片共10 500张,测试集图片共2 100 张。实验中,将模型的输入图像大小调整为224*224。
3.2 开发环境与实验设置
该实验基于Keras 深度学习框架实现,编程语言为Python3.7。GPU 并行开发环境为CUDA 10.0、CuDNN 7.0 版本。在GPU 加速下完成算法训练与测试。实验中使用随机梯度下降算法训练网络,使用批归一化加快训练速度。
3.3 实验结果及评估
为评估提出的基于RAN 与深度哈希算法的模型在图像检索应用上的具体效果,在相同训练集的条件下,将改进的模型与ResNet 以及4 种哈希方法分别比较,其中无监督哈希方法选取局部敏感哈希和谱哈希。监督哈希方法选取KSH 和DLBHC[16]。为评估图像检索的质量,该实验采用不同位数的mAP(mean Average Precision)和不同返回最近邻样本数的准确率作为评估指标。
表2、表3 分别为Flickr 数据集与NUS-WIDE 数据集中不同bit 位的mAP 结果,可以看出,相较于ResNet,文中使用的网络结构在Flickr 数据集上对应不同哈希编码长度的mAP 提升了1.2%~2.3%。在NUS-WIDE 数据集上对应不同哈希编码长度的mAP提升了1.1%~2.7%。
与其他哈希方法中表现最佳的DLBHC 对比,文中改进的方法在Flickr 数据集和NUS-WIDE 数据集上对应不同哈希编码长度的mAP 也分别提升了大约19%和22%。
图4、图5 分别表示Flickr 和NUS-WIDE 数据集中不同返回最近邻样本数的准确率,可以看出该实验方法有较高的准确率且性能较稳定。

表2 Flickr数据集中不同bit位的mAP对比
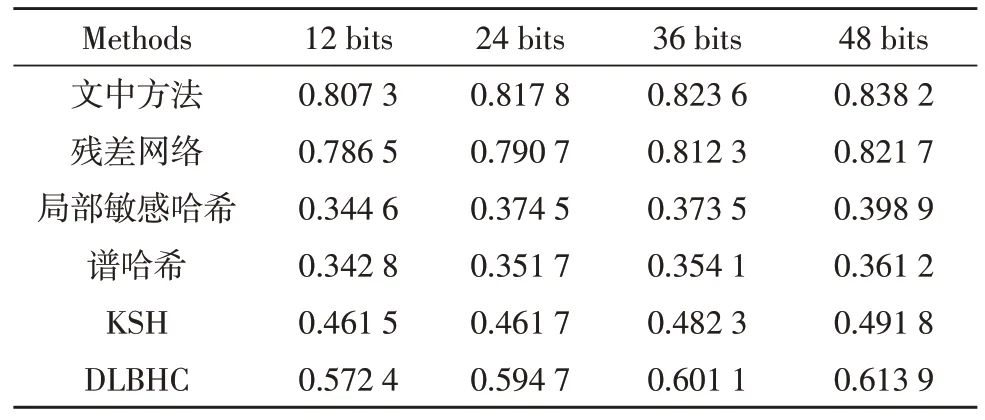
表3 NUS-WIDE数据集中不同bit位的mAP对比
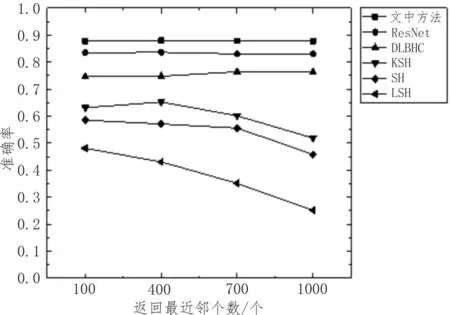
图4 Flickr数据集上不同返回最近邻个数的准确率

图5 NUS-WIDE数据集上不同返回最近邻个数的准确率
4 结束语
该文从解决CNN 提取的图像特征可能包括图像的杂乱背景信息角度出发,设计了基于RAN 与深度哈希算法的图像检索模型,将ResNet、注意力模块和哈希算法集成到同一网络,实现端到端的图像检索,提高了图像检索的准确率。
