基于ArcPy地理空间数据库批量裁剪工具设计
2021-04-20魏智东李美珍
魏智东 李美珍
(广东省国土资源测绘院, 广东 广州 510500)
0 引言
随着计算机水平的不断发展,为适应新时代对测绘事业提出的新需求,测绘地理信息行业发展由原来传统测绘逐步迈向数字化测绘[1]。地理信息数据库作为数字化测绘产品的重要载体,广泛应用在测绘地理信息产业中[2]。随着测绘地理信息产业化的不断发展,地理信息数据库应用也深入到各行各业中[3]。随着需求的不断增加,如何更好地管理地理信息数据库是目前行业发展的重要难点。申传明[4]等人对如何进行空间数据库建设进行探讨,提出了空间数据库建库的方法;刘翔宇,朱大明[5]针对相同数据结构的不同地理数据库,提出使用ArcGIS基于Python提出批量合并矢量数据的方法;曹斌[6]提出了基于ArcPy地理信息数据批处理办法;屈鹏[7]基于python介绍了批量处理地理信息数据库要素类的方法;温树栋[8]等人通过ArcGIS模型构建器,创建了批量裁剪数据库的方法,但是,针对地理信息数据库不同的存储格式、要素集与要素类并存等情况,并没有展开深入的研究。在这样的基础下,本文以广东省2019年基础性地理国情监测为例,结合生产过程中人员任务分配及任务区地理空间数据库提取,基于ArcPy编写了地理信息数据库批量裁剪工具,用于节省人员提取自己任务分区地理信息数据库,减少人员操作失误,缩减任务分工时间,提高数据生产效率,保证了基础性地理国情监测顺利开展。地理信息数据库批量裁剪工具也可应用于其他的项目,大大提高了地理信息数据库批量裁剪工具的生命周期。
1 ArcPy简介
ArcPy是python的一个原生站点包,作为脚本语言嵌入ArcGIS[9],可让我们基于ArcPy进行地理空间数据处理分析,ArcPy共分为四大模块,如图1所示,其中:Arcpy.mapping自动化模块为用户提供制图等相关函数;Arcpy.sa模块为用户提供地理空间分析等相关函数;Arcpy.na模块为用户提供网络分析相关函数;Arcpy.da模块为用户提供数据访问等相关函数[10],在本次ArcPy地理空间数据库批量裁剪工具设计中,主要运用了Arcpy.da相关函数功能。

图1 ArcPy四大模块
2 广东省2019年基础性地理国情监测应用实例
根据2019年全国基础性地理国情监测实施方案要求,基础性地理国情监测在 “多规合一”、城市规划实施监管、环境保护与治理、自然资源管理、空间用途管制等多个方面得到广泛应用,是我国生态文明制度建设中不可或缺的重要组成部分。根据《中华人民共和国国民经济和社会发展第十三个五年规划纲要》《全国基础测绘中长期规划纲要(2015—2030年)》(国函〔2015〕92号)、《测绘地理信息事业“十三五”规划》《广东省基础测绘“十三五”规划(2016—2020年)》要求和自然资源部对于2019年基础性地理国情监测工作的安排,基础性地理国情监测将会逐年开展,由于基础性地理国情监测任务时间紧,任务重,投入人员较多,任务分工存在一定的难度。为了更好地解决项目前期人员任务分工问题,基于ArcPy地理空间数据库批量裁剪工具可以直接统筹任务分发,避免每个作业人员由于自身水平等原因耗时耗力,达到节省时间、提高作业效率的目的。基础性地理国情监测作业图见图2所示。
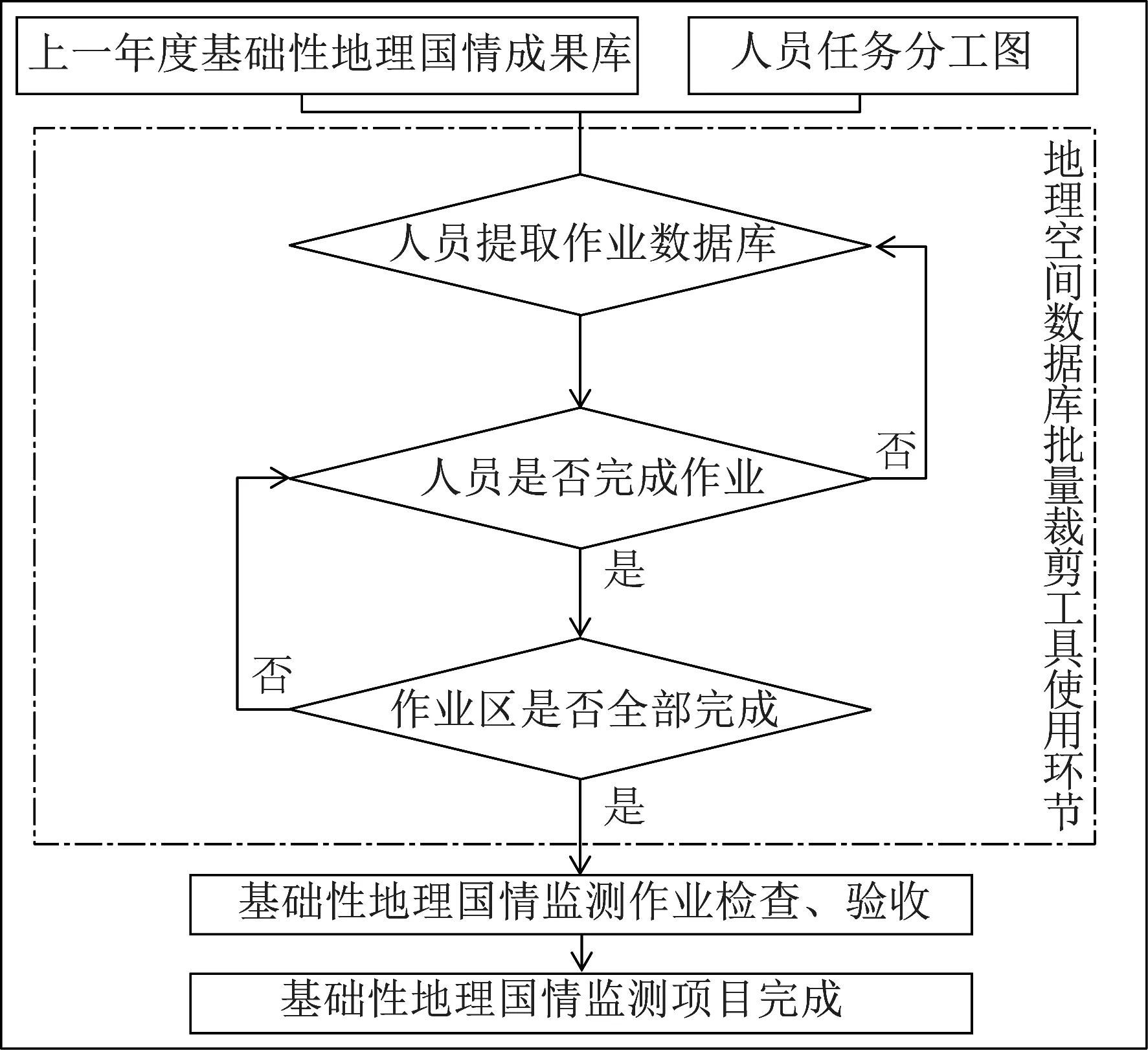
图2 基础性地理国情监测作业图
作业人员根据自己的任务范围进行基础性地理国情监测数据生产,首先需要从上一年度基础性地理国情成果库中,提取自己任务范围内地理国情矢量数据,完成第一批数据后,才能进行下一批数据的生产。从生产环节中可以得知:每一位作业人员需要多次从上一年度基础性地理国情成果库提取自己的作业数据。其中,由于上一年度基础性地理国情成果库成果较多,图层要素达40多个,若是按照传统的方式由作业人员一一提取,耗时较长,人工操作错误率较高。基于ArcPy地理空间数据库批量裁剪工具可直接按任务分工将上一年度基础性地理国情成果库分割成每个作业人员的作业数据库,大大地减少任务分工时间,提高分工准确率与基础性地理国情监测生产效率。
2.1 基础性地理国情监测地理信息数据库
基础性地理国情监测地理信息数据库采用文件地理信息数据库的存储方式进行存储,按数据集(feature dataset)和要素层(feature class)组织,要素层要素只采用简单点、线、面表达,共6个数据集,分别存储在不同的文件地理信息数据库中,具体存储情况如表1、表2所示,若是按照现有的裁剪工具,需要对每一个要素集内的每一个要素图层进行一一裁剪。这样操作数据库,容易出现因人员操作失误而导致数据裁剪出现错误,并且耗时耗力,本文设计的ArcPy地理空间数据库批量裁剪工具可以很好的避免由于人工干预而造成的错误,并且效率比一一裁剪数据要高。

表1 基础性地理国情监测分区国情数据库

表2 基础性地理国情监测不分区国情数据库
2.2 基于ArcPy地理空间数据库批量裁剪工具原理
本次设计以PyCharm作为python的编译器,通过PyCharm使用ArcGIS本身安装的python2.7版本进行程序编写,通过使用ArcPy模板,进行基于ArcPy地理空间数据库批量裁剪工具设计编写,具体实现流程如图3所示。

图3 基于ArcPy地理空间数据库批量裁剪工具原理
2.2.1 基于ArcPy实现地理空间数据库批量裁剪工具主要代码
(1) python识别中文路径
由于数据存储在中文路径,因此需要在python加入代码用于识别中文字符,便于程序识别电脑中文路径,具体实现代码如下:
# coding:utf-8
import arcpy
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
(2)基于ArcPy实现地理空间数据库批量裁剪工具代码
基于ArcPy实现地理空间数据库批量裁剪工具使用思路如下:①选择被裁剪数据库,判断数据库类型为“文件地理数据库(Geodatabase,GDB)”或“个人地理数据库(Microsoft Database,MDB)”格式,为后期创建成果数据库做准备;②判断被裁剪数据库是否存在要素数据集,若存在则遍历数据库内所有的要素数据集及其要素类,若不存在,则遍历被裁剪数据库内的要素类;③选择裁剪要素,并根据裁剪要素选择将要用于创建成果数据库命名的字段,遍历字段获取字段唯一值;④根据裁剪要素字段名创建成果数据库,并选择裁剪要素,对被裁剪数据库进行裁剪,保存在成果数据库中。核心代码如下:
1)工具箱初始参数
gdbPath=arcpy.GetParameterAsText(0) #获取裁剪的数据库路径
clp_fea=arcpy.GetParameterAsText(1) #选择裁剪要素图层
fieldname=arcpy.GetParameterAsText(2) #选择用于批量裁剪的字段
savepath=arcpy.GetParameterAsText(3) #选择裁剪数据库保存文件夹
dec=arcpy.Describe(clp_fea) #获取裁剪要素的详细信息
decbana=dec.baseName # 获取裁剪要素的名称
arcpy.env.workspace=gdbPath #设置工作空间
2)根据裁剪要素及相关字段获取属性唯一值
fielddatalist=[] #列表用于保存遍历选择要素某一字段值
#遍历要素字段属性唯一值
with arcpy.da.SearchCursor(clp_fea, fieldname) as cursor: # 通过游标获取唯一值
for row in cursor:
if row[0] not in fielddatalist:
fielddatalist.append(row[0])
3)遍历数据库所有的要素集及要素类
fcf=[] #列表用于保存数据库的要素类
fcs=[] #列表用于保存数据库要素数据集
fcs_fc=[] #列表用于保存数据库要素数据集及要素类的路径
fds_fc=[] #列表用于保存数据库要素数据集及要素类
fcs_in_fc=[] #列表用于保存数据库要素类路径
sr='' #初始化,用于保存数据库坐标信息
for fds in arcpy.ListDatasets('','')+['']: # 遍历gdbPath数据库所有要素集及要素类
if not fds=='': #如果数据库存在要素集
fcs.append(fds)
for fc in arcpy.ListFeatureClasses('', '', fds):
fcclip=os.path.join(arcpy.env.workspace,fds,fc)
fcs_fc.append(fcclip)
fdsfc=fds+ ""+ fc
采用SPSS20.0软件对本研究数据进行处理,计量资料以t检验,(±s)表示,计数资料以x2检验,差异有统计学意义为P<0.05。
fds_fc.append(fdsfc)
desc=arcpy.Describe(fcclip)
sr=desc.SpatialReference
else: #如果数据库不存在要素集
for fc in arcpy.ListFeatureClasses():
in_fc=arcpy.env.workspace+ ""+ fc
fcf.append(fc)
4)根据裁剪要素图层裁剪数据库
i1=0
lengi1=len(fielddatalist)
while i1 GDB=arcpy.CreateFileGDB_management(savepath, fielddatalist[i1]) #创建数据库 i=0 lengi=len(fcs) while i arcpy.CreateFeatureDataset_management(GDB, fcs[i], sr) #创建数据库 i+=1 clipfc=arcpy.SelectLayerByAttribute_management(decbana,"NEW_SELECTION", "%s='%s'"% (fieldname, fielddatalist[i1])) #根据遍历列表fielddatalist读取裁剪要素值 if not fcs=='': #数据库要素集裁剪处理 l=0 lengl=len(fds_fc) while l savegdbfc=savepath+ ""+ fielddatalist[i1]+".gdb"+ ""+ fds_fc[l] arcpy.Clip_analysis(fcs_fc[l], clipfc, savegdbfc) #调用裁剪工具对数据库裁剪 l+=1 if not fcf=='': #数据库要素图层裁剪处理 j=0 lengj=len(fcf) #遍历要素集所有的图层 while j savefcf=savepath+ ""+ fielddatalist[i1]+".gdb"+ ""+ fcf[j] arcpy.Clip_analysis(fcs_in_fc[j], clipfc, savefcf) #调用裁剪工具对数据库裁剪 j+=1 i1+=1 2.2.2 基于ArcPy实现地理空间数据库批量裁剪工具注意事项 (1)被裁剪数据库必须为文件地理信息数据库或个人地理信息数据库; (2)裁剪要素必须为面要素,且坐标系与被裁剪数据库坐标系一致,不然会由于坐标系不一致而导致程序无法正确运行; (3)裁剪要素所选择的字段不能出现文件命名格式不允许的情况出现,例如:“*”或“.”等。 2.2.3 地理空间数据库批量裁剪工具运行情况 工具通过ArcMap添加工具箱的方式加入即可,打开工具,选择被裁剪数据库,裁剪要素,选择字段,保存文件夹位置,然后运行程序,工具运行完成,用时1 min 53 s,工具执行完成后,结果保存在指定的目录,通过这样的工具,既可减少由于作业人员操作误差而导致的失误,亦可提高任务分工效率。 基础性地理国情监测项目是一项关乎国家民生的工作,同时也是一项时间紧、任务重、长期性的工作,如何在生产项目过程中,提高生产效率与降低错误率,是基础性地理国情监测项目生产的重中之重,以广东省基础性地理国情监测项目为例,每年投入人数不少于200人,在人员众多、工作量繁重的情况下,使用基于ArcPy地理空间数据库批量裁剪工具将人员解放出来,由专门的工作人员进行任务分配与沟通,采用1对多的工作模式,大大地提高了工作效率。总之,本文研究总结如下: (1)通过基于ArcPy地理空间数据库批量裁剪工具可以将繁重的地理信息数据库按区域提取工作交由计算机自动完成,减少人员干预,提高裁剪正确性,工具不仅可以在基础性地理国情监测项目中使用,也可应用到其他测绘地理信息项目。 (2)本文所设计工具在使用过程中,需在ArcMap工程文件的环境下方可运行,并且被裁剪数据库与裁剪要素数据两者坐标系统必须相同,不然无法得出正确的结果,未来将工具封装为单独运行的程序,做到不依赖于ArcMap工程文件运行。 (3)本文所设计的工具,仅对数据存储为个人地理信息数据库及文件地理信息数据库格式的矢量地理信息数据库有用,对其他数据存储格式的矢量数据以及栅格数据尚未完善,后期将尝试加入自动矢量数据与栅格数据,根据输入数据类型,实现自动化处理流程。3 结束语
