一种具有发育机制的感知行动认知模型
2021-04-18张晓平阮晓钢王力李志军闫佳庆毕松
张晓平 阮晓钢 王力 李志军 闫佳庆 毕松
近年来,人工智能与机器人在各国政府、研究机构及相关企事业单位中的受重视程度持续提升,其中主要研究目标之一是建立类似人或动物可以进行自主学习的认知型机器人.机器人具有认知能力表现为其能够在与周身环境的交互过程中渐进掌握知识和技能[1].受人和动物感知运动系统的启发[2],为机器人感知运动过程设计认知模型成为实现认知机器人的有效方法之一[3−5].
机器人感知行动认知模型的设计主要包含模型结构及模型算法两方面.模型结构常借鉴神经生物学相关知识[6−8],而算法方面则以心理学学习机制为指导,常见的有操作条件反射[9−11]、内发动机[12]等,其中,内发动机又涉及好奇心[13−14]、情感[7,15]等.在操作条件反射学习理论下,Cyr 等基于人工脉冲神经网络ASNN(Artif cial spiking neural networks)为机器人设计了一种大脑控制器,实现了机器人自主移动[10];Itoh 等为类人机器人设计了一种行为模型,成功实现了机器人握手行为学习[11].在内发动机理论下,Ren 等借鉴多巴胺、丘脑、基底神经节–大脑皮层工作机制,针对两轮机器人自平衡学习问题提出一种计算模型C-DCCM(Curiosity-driven cognitive computing model),成功实现了机器人的自学习和对环境的自发探索[6];Mannella 等为平面机器人提出一种计算模型,实现了机器人自身运动技能学习[12];Baranes和Oudeyer 将感知运动理论与内发动机理论结合,提出一种自适应目标生成–鲁棒智能自适应好奇心算法SAGG-RIAC(Self-adaptive goal generationrobust intelligent adaptive curiosity),实现了冗余机器人对自身逆运动学的学习[13−14];Castellanos等则考虑机器人感知行动认知过程中的情感因素,为机器人提出一种情感评估模型,实现了机器人的个性化[15].以上工作,机器人在学习过程中,其认知模型算法会在一定程度上进行更新,但模型结构均为固定,一旦设计完成,不再发生变化.
2001年,Weng 在Science上发文,首次提出自主心智发育的概念[16],后期继续提出一系列发育网络DN(Development networks)理论[17],奠定了发育机器人研究基础,其发育网络核心理念就在于学习过程中网络结构可变.Cai等以学习自动机为数学模型,结合操作条件反射机制与模糊理论设计的模糊斯金纳操作条件反射自动机FSOCA(Fuzzy skinner operant conditioning automaton)就融合了这样的思想,基于在线聚类算法实现了感知行动映射规则的增加和删除[9].发育理念对于机器人学习非常重要,以文献[18]为例,其在感知运动系统认知模型中同时结合操作条件反射与内发动机机制,为两轮机器人设计了一种具有内发动机机制的认知模型,使得机器人表现出一定的认知能力,然而,其模型结构固定,研究过程中表现出两个问题:1)模型需要学习的动作空间需要提前定义,降低了机器人的智能性,并且固定的动作学习空间存在大量对无效感知行动映射的探索和学习,造成学习的浪费,导致模型学习率低;2)固定感知行动映射空间下,模型需要对当前学习状态下所有的感知行动映射取向性进行更新,存在计算上的浪费.
受发育理论启发,本文在文献[18]的研究基础上,借鉴潜在动作理论,设计了一种新的结构可发育的机器人感知行动认知模型D-SSCM,针对模型的发育式学习过程,分别设计了模型扩展式学习方法和算法以及缩减式学习方法和算法,同时节省了机器人学习成本和计算成本,很大程度上提高了机器人的学习速度和学习稳定性.将文本模型与文献[18]在相同实验任务及参数设置下进行对比,对本文模型的特点及上述优越性进行了说明和验证.
1 潜在动作理论
潜在动作(Af fordance)理论由美国感知心理学家Gibson 于1977 年提出,认为婴儿在环境学习过程中,首先学习的是物体的潜在动作,如箱子“可堆积”、椅子“可坐”等,之后才学习物体颜色、大小等属性[19].21世纪,潜在动作理论被引入发育机器人研究领域[20],对此,欧盟还成立了专门的研究项目[21],RSS、ECCV等会议也举办了相关的Workshop[22].国内有关潜在动作的相关研究主要来自华南理工大学易长安等的工作[23−25].
潜在动作理论重点研究机器人与环境之间可能的动作关联,从而实现机器人完成不同的任务.
1.1 潜在动作定义
潜在动作理论自提出以来,各学者对其理解不一,Turvey将潜在动作定义为环境的属性[26];在Turvey理论基础上,Stof fregen 认为潜在动作是存在于动物–环境系统中的某种属性[27];Chemero认为潜在动作是动物属性与环境属性之间的关联[28];Steedman忽略感知作用,将潜在动作理解为环境与动作的关联[29];2015年,易长安等指出,潜在动作是指机器人结合自身行为能力及感知能力,判断其在当前环境下可执行的动作[30].机器人在与环境的交互过程中逐渐学习到不同环境中的潜在动作,从而完成不同的任务,并在任务学习过程中不断提高自身行为学习能力.由此可见,潜在动作是机器人学习到的关于其周身环境的知识,是机器人获得高级技能的重要基础,它能够使机器人预测动作结果,实现高效率的学习[31].
1.2 潜在动作形式化
2007 年,Sahin等[32]总结潜在动作相关知识,定义潜在动作是效果和(实体,行为)组之间的关系,并给出了潜在动作学习的形式化,具体为一个三元组,如式(1)所示,为广大学者所采用.式(1)具体表示当智能体对实体(entity)执行行为(behavior)后,产生效果(effect).
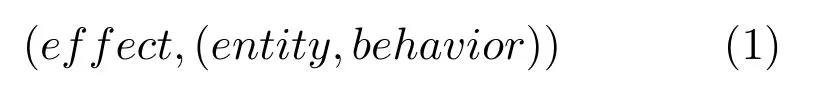
2015年,易长安等对Sahin 等的潜在动作学习模型进行扩展,针对动态环境下的复杂任务,提出了基于子任务的潜在动作描述方法[30],如式(2)所示,其中precondition表示动作执行前环境需要满足的前置条件,postcondition表示动作执行完成后环境需满足的后置条件.在该模型之上,易长安等提出潜在动作预测框架,集成了分层强化学习、状态抽象机制、任务图和物体属性等,提高了机器人学习效率.

机器人与环境的每次交互都可以产生一个潜在动作元组,多次交互可以得到更一般的关联,从而完成更复杂的任务.
2 具有发育机制的感知行动认知模型
2.1 模型结构
本文在文献[18]的基础上,结合潜在动作理论,为机器人设计了一种结构可变的具有发育机制的感知行动认知模型D-SSCM(Developmentsensorimotor cognitive model),其结构如图1所示,包含离散学习时间集t、内部可感知离散状态集S、可输出动作集M、有效输出动作空间集Ms、有效感知行动映射取向性集Os、有效感知行动映射学习次数集Ns、有效感知行动映射好奇心集Cs、状态评价函数V、取向函数Vs、有效操作函数集Ps、有效动作空间取向性学习算法Ls、潜在动作关系集AF、可输出动作空间探索率集Exp以及发育算法DL共14部分(下标s表示感知sensory,后文下标m 表示运动motor).
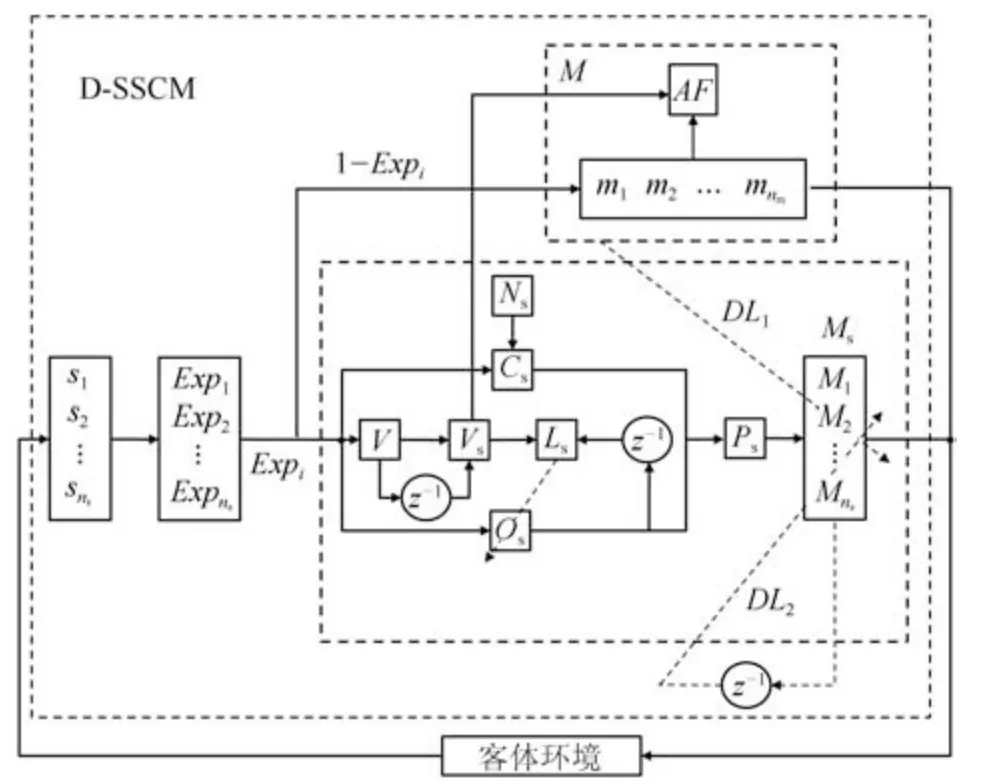
图1 D-SSCM结构图Fig.1 Structure of D-SSCM
为更清楚地显示D-SSCM中各元素的含义,给出如下定义:
定义1.具有发育机制的感知行动认知模型DSSCM是一个14元组:D-SSCM=t,S,M,Ms,Os,Ns,Cs,V,Vs,Ps,Ls,AF,Exp,DL,其中各元素含义具体如下:
1)t∈{0,1,···,nt}:D-SSCM离散学习时刻集,其中t=0表示学习初始时刻,nt表示最大离散学习时刻数;
2)S={si|i=1,2,···,ns}:D-SSCM内部可感知离散状态集,其中si∈S表示模型第i个可感知的内部状态,ns为离散状态数;
3)M={mj|j=1,2,···,nm}:D-SSCM可输出动作集,mj表示可输出动作集中第j个动作,nm为动作空间可输出动作数;
4)Ms={Mi|i=1,2,···,ns}:D-SSCM有效输出动作空间集,Mi={mik|k=1,2,···,ni}为状态si下的有效输出动作空间,mik∈M为D-SSCM在状态si下从M中学习到的第k个有效动作,ni为状态si下学习到的有效动作个数.状态si下的有效输出动作指的是该状态下能够使机器人趋向任务目标的动作,Mi是在机器人对环境的学习过程中不断构建的,随着Mi结构的不断变化,ni也随之发生变化,体现出模型发育的思想.学习初始时刻,Mi(i=1,2,···,ns)均为空,ni=0(i=1,2,···,ns);
不同于文献[18]中所设计模型需要学习的动作空间固定,在D-SSCM中各状态si所对应的动作空间Mi并非教师或专家根据经验提前定义的,而是随着学习过程渐进发育形成的,该模式下,有效避免了冗余感知行动映射造成的学习浪费和计算浪费.
5)Os={Oi|i=1,2,···,ns}:D-SSCM有效感知行动映射取向性集,其中Oi={oik|k=1,2,···,ni}为状态si下的有效感知行动映射取向性集,oik为状态si对其第k个有效动作的选择取向性;
6)Ns={Ni|i=1,2,···,ns}:D-SSCM有效感知行动映射学习次数集,Ni={nik|k=1,2,···,ni}为状态si下模型对其各有效动作的学习次数集,nik表示状态si对动作mik的学习次数,若t时刻,mik被选择,则t+1时刻:

对于其他所有没有被学习的有效感知行动映射,对应学习次数保持不变;
7)Cs={Ci|i=1,2,···,ns}:D-SSCM有效感知行动映射好奇心集,Ci={cik|k=1,2,···,ni}为状态si下模型对其各有效动作的好奇心集,cik表示状态si对动作mik的好奇度,计算方式同文献[18],具体为:

其中,kc和c为好奇心参数;
8)V:D-SSCM状态评价函数,用来评价模型当前感知状态的理想程度,机器人越接近学习目标,模型对应感知状态的状态值越大,机器人越远离学习目标,则模型对应感知状态的状态值越小;
9)Vs:D-SSCM取向函数,用于决定模型学习方向,定义为:
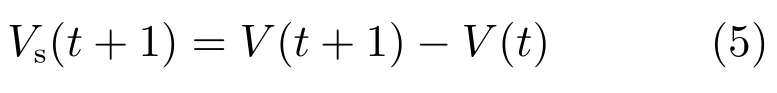
10)Ps={Pi|i=1,2,···,ns}:D-SSCM有效操作函数集,用于决定模型在有效动作空间内对动作的选择,Pi={pik|k=1,2,···,ni}为状态si所对应的有效操作函数集,pik为状态si对动作mik的操作值,具体为:

0<σ <1为操作函数参数.
11)Ls:D-SSCM有效动作空间取向性学习算法,在D-SSCM有效动作空间内各动作均能使得Vs(t+1)≥0,因此针对有效动作空间的取向性学习算法Ls简单设计为:

其中oik(k∈1,···,ni)对应被选动作mik的取向性值,oik为状态si下其余动作的取向性值,η为取向性学习算法参数.
12)AF={AFij|i=1,2,···,ns,j=1,2,···,nm}:D-SSCM潜在动作关系集,受潜在动作理论及其形式化启发,在此定义D-SSCM不同状态与不同动作之间的潜在关系,具体定义为一个三元组:
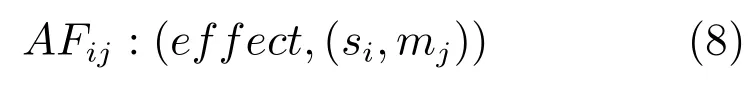
AFij意义为D-SSCM在状态si下输出mj产生的效果为effect.D-SSCM在对可输出动作空间进行探索时,每探索一个新的感知行动映射(si,mj),就会伴随着一个新的潜在动作关系组形成.
针对D-SSCM发育式学习过程:
若effect=1,表示在感知状态si下动作mj是可被选择的,即动作mj是状态si下的有效动作;
若effect=0,表示在状态si下,动作mj是不可取的,会使得学习偏离目标;
若effect值为空,即effect=∅,则表示对应的感知行动映射还没有被学习.
依据操作条件反射机制及定义的取向函数,effect值计算如下:
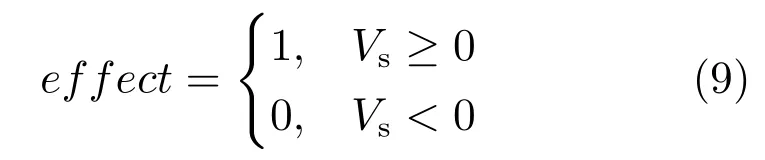
13)Exp={Expi|i=1,2,···,ns}:D-SSCM可输出动作空间探索率集,Expi表示模型在状态si下对可输出动作空间M的探索率,可通过式(10)进行计算:
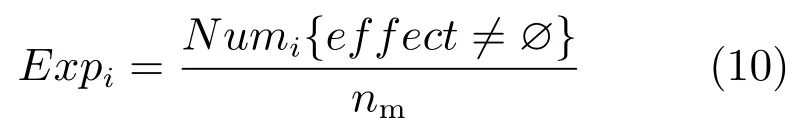
其 中,Numi{effect=∅}=nm−Numi{effect=∅}表示状态si下可输出动作空间中潜在动作关系元组effect=∅的个数,亦即状态si对可输出动作空间已经进行探索的感知行动映射数.
D-SSCM中,在任意状态si下,模型都可以选择对该状态下已发育形成的有效输出动作空间集Mi进行学习,或对该状态下可输出动作空间M的剩余空间进行探索.在此规定,D-SSCM学习过程中,在状态si下模型总是以概率1−Expi对M剩余空间进行探索,以概率Expi对其有效输出动作空间Mi进行学习.特别地:
a)在学习初始时刻t=0时,模型没有任何环境知识,任意状态si下,其潜在动作关系元组AFij(j=1,2,···,nm)中effect值均为∅,Mi也为∅,此时D-SSCM以
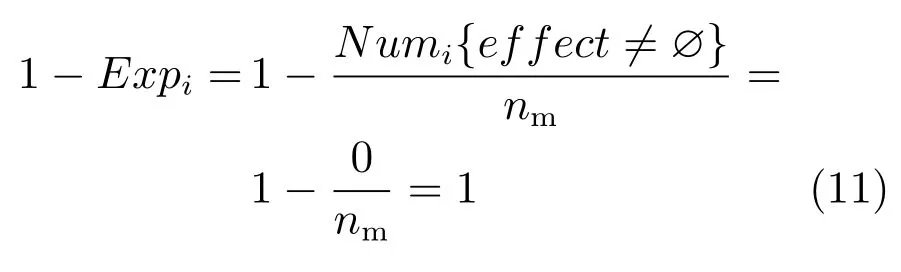
的概率从可输出动作空间集M中探索动作,以完成对Mi的构建.
b)当学习进行到某个时刻,若状态si已经完成了对可输出动作空间M的全部探索,则D-SSCM在该状态下继续对M进行探索的概率为:
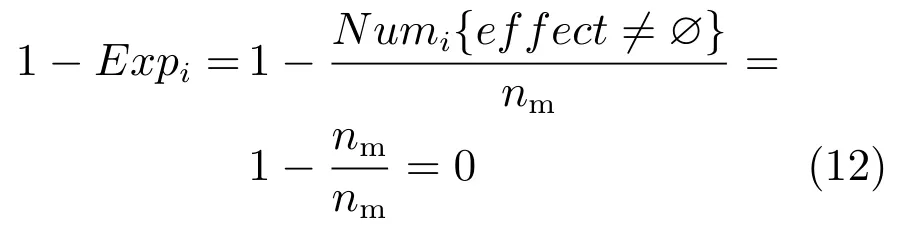
表明此时模型不再会对M进行探索.
14)DL:D-SSCM 发育算法,包含DL1和DL2两部分,其中DL1为D-SSCM探索可输出动作空间M后需要对有效输出动作空间集Ms进行扩展的发育算法,DL2是D-SSCM对有效输出动作空间集Ms不断学习后需要对其进行缩减的发育算法.
2.2 发育算法设计及分析
2.2.1 扩展发育算法DL1
在状态si下,若D-SSCM以概率1−Expi对可输出动作集M剩余动作空间进行了探索,可能出现两种情况:
1)t时刻在当前状态下探索某一动作后,t+1时刻模型受到负强化Vs(t+1)<0,则对应感知行动映射潜在动作关系元组effect=0,表明该动作在当前状态下是不应该被选择的,针对该情况,t+1时刻不需要对已建立的有效感知行动映射动作集进行更新;
2)若t时刻模型在当前状态下探索某一动作后,t+1时刻获得正强化Vs(t+1)≥0,则对应感知行动映射潜在动作关系元组effect=1,证明该动作是当前状态下的一个有效动作,t+1时刻需要对Ms进行扩展发育.
以状态si为例,D-SSCM在情况2)下Ms的结构扩展发育过程如图2所示.
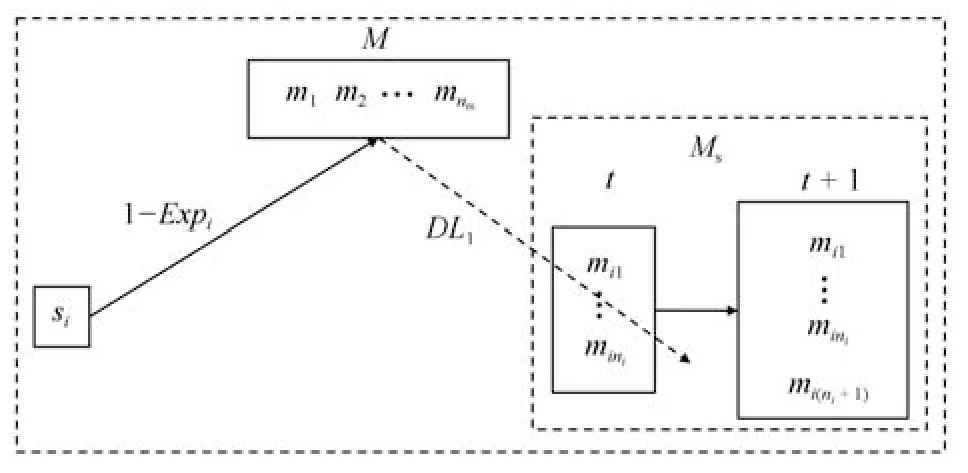
图2 D-SSCM扩展发育原理图Fig.2 D-SSCM extended development diagram
更具体的,假设t时刻,状态si所对应有效输出动作空间集Mi中的有效动作个数为ni,模型以1−Expi探索了可输出动作集M剩余空间中某一动作,设为mj,t+1时刻获得正强化,因此需要对Mi进行扩展发育,具体如下:
步骤1.动作扩展:将动作mj扩展为动作集Mi第ni+1个有效动作:
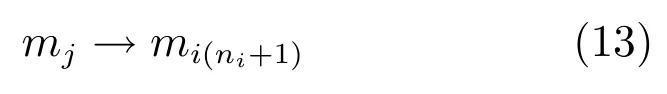
步骤2.取向性更新:按照发育算法DL1对扩展后的动作集Mi取向性集Oi进行更新,其中DL1算法学习过程具体如下:
步骤2.1.首先针对新增加动作mi(ni+1),定义其在状态si下的取向性:

步骤2.2.Mi中原有动作取向性oik(k=1,···,ni)更新如下:
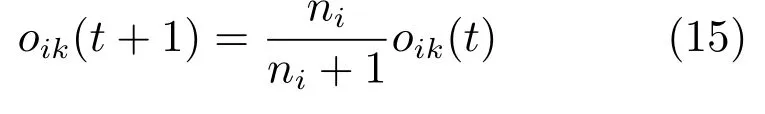
步骤3.好奇心激活:伴随着状态si下新动作mi(ni+1)的增加,除取向性按式(14)和式(15)进行更新外,状态si对mi(ni+1)的好奇心也随之被激活,用于计算动作好奇度的感知行动映射学习次数ni(ni+1)=1,并在以后的学习中不断更新.可以看出,任何新发育的动作,其所对应的好奇心值均较大,结合对新增动作定义的初始取向性值,能够保证模型对该有效动作的充分学习.
步骤4.结构发育:

DL1算法分析:D-SSCM在结构不需要发育时,其取向性学习算法如Ls所示,算法有效性在文献[18]中给出了相关证明,在此不再赘述.t+1时刻,若模型结构需要发育,则发育后模型中动作的取向性应满足Ls的学习条件,即:1)0≤oik(t+1)≤1(k=1,2,···,(ni+1)),2)oik(t+1)=1.
针对条件1):t+1时刻,对于新扩展的动作mi(ni+1)的取向性有:

满足条件,对于Mi中原有动作的取向性有:

在0≤oik(t)≤1的情况下,因为可知0≤oik(t+1)≤1成立,因此DL1发育算法满足条件1).
针对条件2),t+1时刻:
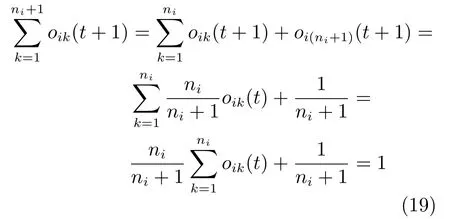
可见DL1发育算法满足条件2).
从以上扩展发育算法DL1可以看出,在潜在动作关系元组引入的条件下,相比较于文献[18]认知模型,D-SSCM对各动作的初步探索可一次完成,通过计算effect的值仅对各状态下的有效动作进行发育用于后期的学习,大大降低了对感知行动映射的学习成本以及取向性更新时的计算成本,同时模型对整个可输出动作集的探索依概率进行,从另一方面缩减了计算成本.
2.2.2 缩减发育算法DL2
D-SSCM认知模型在状态si下对其有效感知行动映射动作集Mi进行学习,遵循内发动机下的主动学习机制.Mi中,对所有的动作都有潜在动作关系元组:

成立,但在操作条件反射机制下,模型总是趋向于选择获得更大正强化值的动作,随着学习的进行,某些有效动作的取向性会随着学习的进行不断降低,当其取向值下降到一定程度以下时,D-SSCM在好奇心作用下,依据内发动机机制继续对其进行学习会同时造成学习和计算的浪费,此时需要对模型结构进行缩减发育.
D-SSCM在对其有效输出动作空间集Ms的学习过程中,如果t时刻,当前状态si下某动作mik所对应的取向性oik(t)满足:
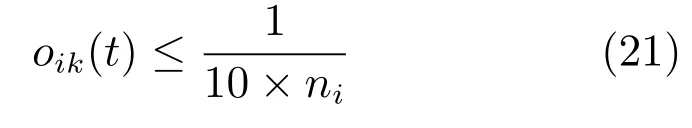
则认为动作mik不属于当前状态下的可选潜在最优动作,需要将其从Mi中剪除.不同于结构扩展发育时直接将有效动作mj作为Mi第ni+1个有效动作,D-SSCM的结构缩减发育经历一个比较复杂的过程,具体如图3所示.

图3 D-SSCM缩减发育原理图Fig.3 D-SSCM reduced development diagram
以t时刻,状态si下的有效输出动作集Mi中第j(j∈1,···,ni)个动作mij需要被剪除为例,D-SSCM的缩减发育原理具体如下:
步骤1.动作剪除:首先将mij从Mi中剪除.
步骤2.取向性更新:Mi中动作mij被剪除后,对其剩余动作取向性按发育算法DL2进行更新,具体为:

步骤3.结构发育:对剪除动作mij后的Mi结构进行更新.
步骤3.1.对于k

直至

步骤3.2.将Mi空间由ni维降低为ni−1维:

结构发育过程中,各动作相关性质如取向性、好奇心等随动作更新.
DL2算法分析:与DL1算法相同,DL2算法同样需要保证Ls的学习条件:1)0≤oik(t+1)≤成立.在结构缩减发育下,可简单描述为:t+1时刻上述步骤2中1)0≤oik(t+1)≤1,(k=1,···,ni),
针对条件1),由于对任意动作mik,其取向性满足oik(t)≤1−oij(t),因此有:
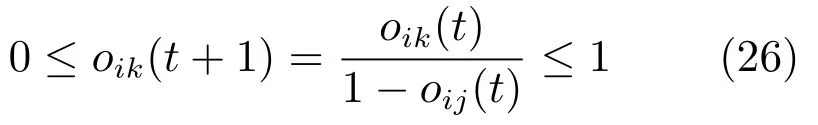
成立,满足条件.
针对条件2),t+1时刻:

条件2)成立.
学习中的某一时刻,若有效感知行动映射取向性集Oi中同时存在多个需要被剪除的动作,则按顺序依次重复上述过程.
2.3 学习过程
具有发育机制的感知行动认知模型D-SSCM学习步骤可总结如下:
步骤1.初始化.学习初始时刻t=0时,对D-SSCM中各元素进行初始化,具体包括:定义模型内部可感知离散状态集S及可输出动作集M,定义模型状态评价函数V,设置学习相关参数,设置学习终止条件.
不同于文献[18]认知模型,D-SSCM中,其要学习的感知行动映射结构是可发育的,有效感知行动映射相关元素是随着学习不断变化的,无需提前定义,以节省计算空间,具体包括有效感知行动映射取向性集Os、有效感知行动映射学习次数集Ns、有效感知行动映射好奇心集Cs、有效操作函数集Ps.
步骤2.状态感知.观察学习t时刻D-SSCM模型状态si(t),并计算当前状态取向值V(t).
步骤3.计算当前状态下的探索率Expi.依概率1−Expi对M剩余动作空间进行探索,依概率Expi对Mi有效动作空间进行学习.初始时刻,D-SSCM没有任何先验知识,Mi为∅,模型以概率1探索M,即模型需要从M中获取知识,同时,在此规定,在学习任意时刻,若Mi为∅,则模型以概率1探索M剩余动作空间.
所谓状态si下M的剩余动作空间,即状态si在可输出动作集M中所有潜在动作关系元组(effect,(si,mj))中effect值为∅的动作,effect值为∅表示感知行动映射(si,mj)没有被探索.
t时刻,若D-SSCM依概率1−Expi对剩余动作空间进行了探索,则执行步骤4.1.1∼步骤4.1.5:
步骤4.1.1.选择动作并输出.D-SSCM在当前状态的M剩余动作空间中随机选择某个动作并输出;
步骤4.1.2.状态发生转移.t时刻,模型在当前状态si(t)下从M剩余动作空间中随机选择了某个动作,假设为mj作用于客体环境,状态发生转移,观测t+1时刻模型的新状态,并计算其状态值V(t+1);
步骤4.1.3.计算取向函数值Vs(t+1).根据t时刻及t+1时刻观测到的状态值计算模型的取向函数值Vs(t+1),此处用于计算模型潜在动作关系effect值;
步骤4.1.4.更新模型潜在动作关系集.根据计算获得的取向函数Vs(t+1)值更新模型M空间潜在动作关系元组(effect,(si,mj)),若Vs(t+1)≥0,则effect=1,若Vs(t+1)<0,则effect=0;
步骤4.1.5.判断是否扩展发育.根据新生成的潜在动作关系元组的effect值判断是否需要对状态si下的有效动作空间Mi进行扩展发育,若effect=0,表明所探索的动作在当前状态下是无效的,t+1时刻无需对Mi进行扩展发育,D-SSCM有效感知行动映射结构不变;若effect=1,则表明t时刻探索到当前状态下一个有效动作,t+1时刻需要将探索到的动作扩展到Mi中,具体按第2.2.1节中扩展发育算法对模型结构及相关属性进行更新.
t时刻,若D-SSCM依概率Expi对当前状态si下有效动作空间Mi进行学习,则执行步骤
4.2.1∼步骤4.2.7,D-SSCM对Mi中各动作的学习依内发动机机制进行[18],具体为:
步骤4.2.1.计算当前状态下的好奇心集Ci(t).在感知状态si(t)下,D-SSCM有效输出动作空间Mi中某一动作,设为mik(k∈1,2,···,ni)随机引起了模型对其进行学习的好奇心,其好奇度被激发,计算该好奇心值cik(t),对于没有引起模型好奇心的其余动作,cik(t)=0;
步骤4.2.2.计算操作函数集Pi(t).结合模型当前状态下的有效感知行动映射取向性集Oi(t)及好奇心集Ci(t),计算当前状态下的有效操作函数集Pi(t);
步骤4.2.3.选择动作并输出.依据内发动机机制,选择Mi中操作函数值最大的动作,设为mib(b∈1,2,···,ni)作用于环境中;
步骤4.2.4.状态发生转移.感知模型t+1时刻新状态,计算其状态值V(t+1);
步骤4.2.5.计算取向函数值Vs(t+1).计算t+1时刻模型取向函数值Vs(t+1),此处用于决定模型已有结构下取向性学习方向;
步骤4.2.6.更新有效感知行动取向性映射集.根据式(7)对有效感知行动取向性映射集Oi进行更新;
步骤4.2.7.判断是否缩减发育.根据更新后的取向性映射集Oi判断是否需要对Mi进行缩减发育,当Oi中存在需要被剪除的动作时,依据第2.2.2节缩减发育算法对模型结构及相关属性进行更新.
步骤5.判断学习结束条件.根据设定的学习终止条件判断学习是否结束,若满足条件,则结束,否则返回步骤2.
D-SSCM的学习过程可用流程图4更清楚直观地描述.
3 两轮机器人自平衡实验
3.1 D-SSCM模型设置
针对两轮机器人自平衡任务,首先需要对DSSCM模型进行设置.
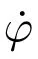
2)两轮机器人通过控制轮子的运动实现平衡,因此模型可输出动作设定为轮子的转矩,可输出动作集设计为M={−10,−5,−2,−1,−0.1,0 0.1,1,2,5,10}(N·m),机器人共有nm=11个可输出动作;
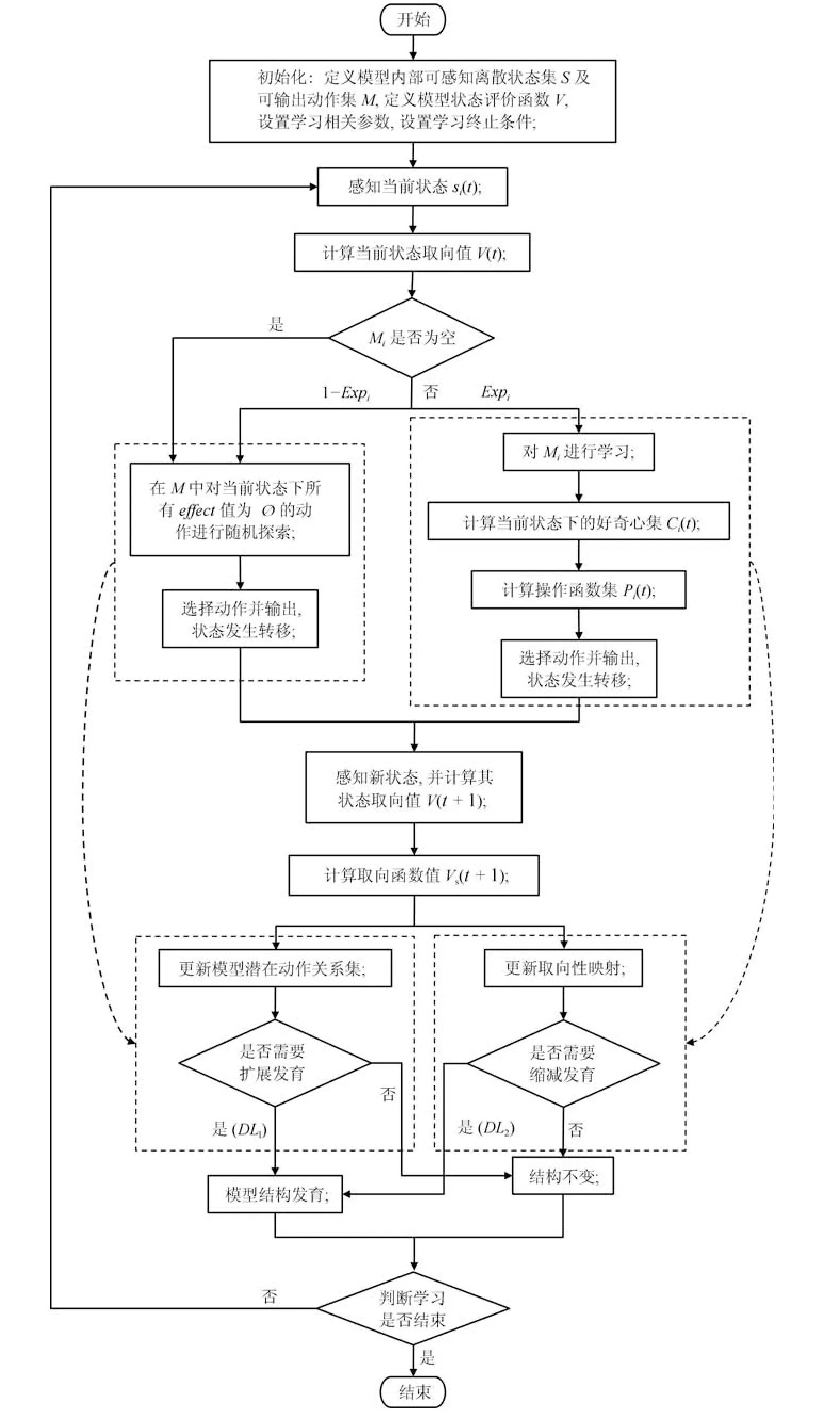
图4 D-SSCM学习流程图Fig.4 Learning fowchart of D-SSCM

表1 D-SSCM状态划分Table 1 D-SSCM state division
3)针对两轮机器人自平衡任务,根据经验,模型状态评价函数设计为:

4)其他各相关参数具体设定为kc=0.05,c=1,δ=0.7,η=0.1.
3.2 实验结果与分析
为表明D-SSCM学习的优越性,将其与文献[18]认知模型在如上相同设置下进行对比实验验证.方便期见,文献[18]具有内发动机机制的感知行动认知模型简称为IM-SSCM(Intrinsic motivationsensorimotor cognitive model)
1)基本学习过程:令机器人由初始倾斜角度−10◦开始学习,采样时间为0.01 s,学习过程中,如果机器人身姿角度|ϕ(t)|>15◦,则认为机器人发生倾倒,将其拉回初始状态继续学习.如图5∼图7所示分别为两轮机器人在50 000步学习过程中其身姿倾斜角度、角速度以及轮子输出转矩的变化曲线.可以明显看出:1)D-SSCM具有更快的学习速度:从图5及图6机器人身姿角度和角速度曲线可以看出,在IM-SSCM指导下,机器人大约经过150 s可进入平衡位置,而在结构可发育的D-SSCM指导下,机器人大约经过40 s即可进入平衡位置,这是因为在发育机制下,机器人只对有效的感知行动映射进行学习,大大节省了探索成本.2)D-SSCM具有更稳定的学习效果:从图5及图6中可以看出,IMSSCM学习过程阶段性比较明显,主要表现为学习初期(0 s∼150 s)以较大的好奇心对不同的感知行动映射进行探索,学习中期(150 s∼450 s),好奇心得到一定下降,模型以较小的好奇心对感知行动映射继续进行探索,因此在学习中期依旧可能存在一些小的波动,相比之下,D-SSCM对感知行动映射的学习仅在其有效输出动作空间中进行,其中所有的动作都使得机器人趋向目标,学习一旦完成,机器人不会发生晃动,该结论在图7 机器人轮子转矩输出中体现更加明显,从图7 中可以看出,IM-SSCM认知模型在150 s∼450 s之间尽管对±10、±5的选择有所减少,但是在好奇心作用下依旧可能会对不良感知行动映射进行尝试,而在D-SSCM发育认知模型下,机器人通过一次探索获知动作结果后,后期就不再会选择各状态下的不良动作,不至学习偏离目标.
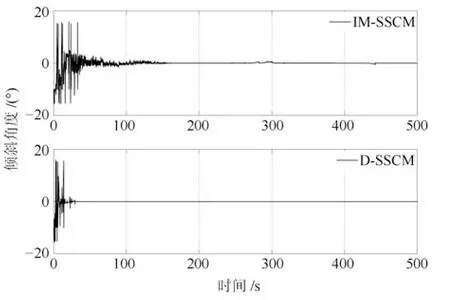
图5 两轮机器人倾斜角度Fig.5 Angle of two-wheeled robot
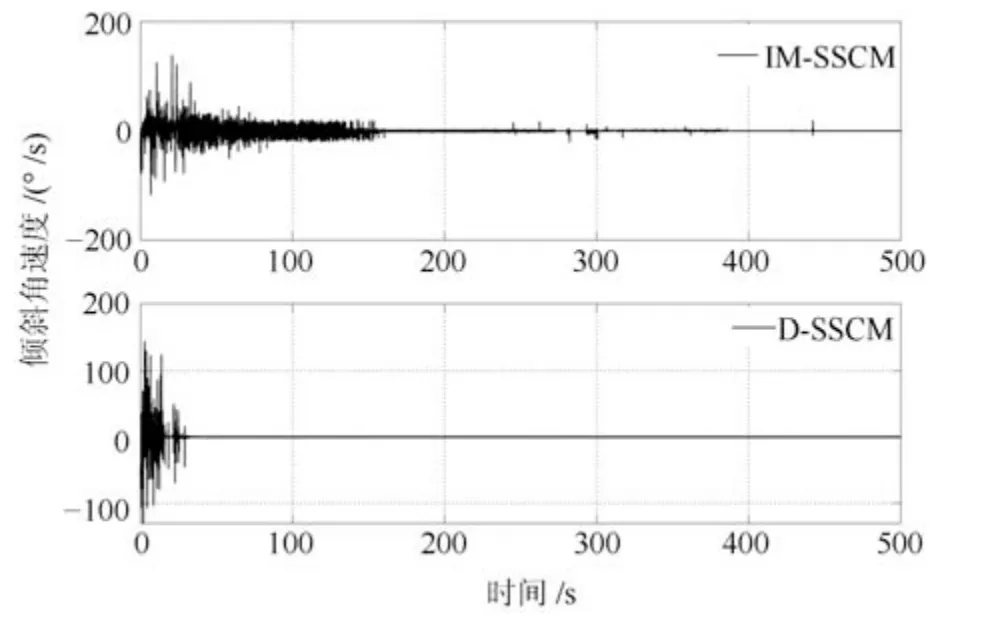
图6 两轮机器人倾斜角速度Fig.6 Angular velocity of two-wheeled robot
从以上结果可以看出,D-SSCM指导下机器人学习速度非常快,大约40 s即可完成,为说明DSSCM发育机制下的学习特点,对机器人前100 s学习过程中对M空间下感知行动映射探索次数及Ms空间有效感知行动映射构建数进行了记录,结果如图8所示.根据实验数据结果,D-SSCM在初始100 s学习中共探索M空间660次,最终在Ms中形成有效感知行动映射数179条.在IM-SSCM认知模型中,机器人在整个探索阶段中需要探索的感知行动映射数始终为ns×nm=144×11=1 584,相比较之下,D-SSCM在发育机制下,对M空间下各感知行动映射的探索只需要一次,通过计算所得的潜在动作关系元组effect值决定是否对当前感知行动映射进行发育,其需要学习的感知行动映射数仅为Ms空间下的有效感知行动映射,学习空间大大缩小.
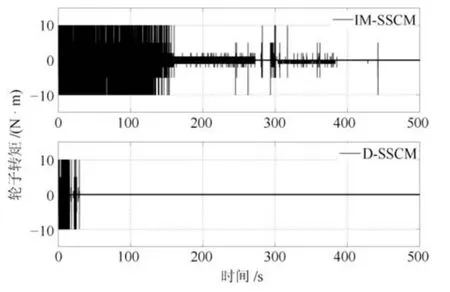
图7 两轮机器人轮子转矩Fig.7 Wheel s torque of two-wheeled robot
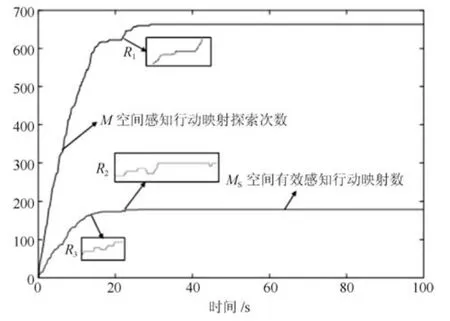
图8 D-SSCM发育过程实验结果图Fig.8 Experiment results figure of D-SSCM s development process
对M空间感知行动映射探索次数曲线进行分析,首先可以看到在前40 s的学习过程中,曲线整体呈上升趋势,表明机器人在不断探索M空间下的感知行动映射以获取新知识,进而完成对Ms的构建.此外,曲线存在如图中R1区域所示水平直线部分,M空间感知行动映射探索次数曲线中水平直线部分的出现意味着该阶段D-SSCM正在对其所构建的有效输出动作空间集Ms进行学习,表明模型对M空间的探索是依概率的,而非遍历的.智能系统学习的目标在于寻找某种可以达到目标的策略,该策略不一定是最优的,该目标下,遍历式的搜索策略是不必要的,反而会降低学习效率,D-SSCM对M空间的依概率探索则很好地避免了以上问题.
对Ms空间有效感知行动映射数曲线进行分析.不同于M空间感知行动映射探索次数表现为不减曲线,Ms空间有效感知行动映射数在缩减式发育下可能会出现下降.与R1区域所处学习阶段对应,Ms空间有效感知行动映射数变化过程如图中R2区域所示,需要指出的是,该阶段中,R2区域出现了有效感知行动映射数减小的情况,从实验角度体现了模型的缩减式发育过程,同样的过程也发生在模型学习前期阶段,具体如图8中R3区域所示.
图8清楚的显示了D-SSCM的发育过程,同时包含扩展式发育及缩减式发育.
2)轮次学习:两轮机器人的自平衡过程关键在于其由初始状态运动到平衡位置期间.为更清楚地显示D-SSCM的学习能力,令其不断在前一次学习的基础上从初始状态开始运动,观察其学习结果,并与IM-SSCM进行对比.在此设定轮次学习步数为3 000步,结果如图9∼11所示,分别为两种模型下机器人第1轮、第2轮及第3轮的学习结果,从图中可以看出,相比较于IM-SSCM,D-SSCM具有更快的学习速度.实验结果显示在具有发育机制的感知行动认知模型D-SSCM指导下,机器人一般经过一轮对知识的探索,在第二轮就能够快速从初始倾斜角度运动到平衡状态,该学习速度较其他已知操作条件反射相关认知模型有显著优势.

图9 第1轮学习结果Fig.9 Learning results of the 1st round

图10 第2轮学习结果Fig.10 Learning results of the 2nd round

图11 第3轮学习结果Fig.11 Learning results of the 3rd round
令机器人连续学习10轮,对各轮学习过后DSSCM模型对M空间感知行动映射的累计探索次数(用nM表示)及其自身Ms空间有效感知行动映射数(用nMs表示)进行记录,结果如图12所示,可以看出,不同轮次下,机器人在不同程度上完成了对M空间的探索和对Ms空间的构建.
更具体地,表2中数据与图12相对应,对其进行分析,首先,经过第1轮的学习,机器人探索了M空间下的588条感知行动映射,并经过对其潜在动作关系进行分析,在Ms空间下构建了169条有效感知行动映射;进入第2轮及第3轮,nM数与nMs数均增加1,表明在这两轮学习过程中,机器人都探索了一次M空间,同时探索的感知行动映射有效,对Ms进行了扩展发育;进入第4轮,nM数增加2,而nMs仅增加了1,说明D-SSCM探索的两条感知行动映射中一条有效,一条无效;从第4轮到第5轮,nM数不变,nMs减1,说明该轮次中,模型主要在学习Ms有效感知行动映射空间,并且在学习期间,存在感知行动映射取向性小于一定值的情况,因此对模型进行了缩减式发育;从第6轮到第10轮,nM值都不同程度的增加,nMs没有再发生变化,说明模型结构没有再发生变化.表2中D-SSCM从第1轮到第10轮中nM和nMs的变化情况,更好、更清楚地说明了D-SSCM的发育过程.

图12 10轮学习中的nM 及nMs数Fig.12 nM and nMsin 10 learning rounds
4 结论
机器人感知行动认知模型结构固定情况下,多存在学习浪费及计算浪费的问题,对此,本文在文献[18]的基础上,结合潜在动作理论,为机器人行为学习过程提出了一种结构可发育的感知行动认知模型D-SSCM,能够在探索可输出动作空间过程中自建需要学习的有效感知行动映射,同时节省了学习成本和计算成本,在实现机器人自主学习的同时,提高了机器人学习速度和稳定性.D-SSCM中,需要学习的有效感知行动映射通过自建形成,一定程度上提升了系统的智能性,但是其中状态评价函数依旧是教师依据经验设计,此外,D-SSCM中,机器人可输出动作为离散,在一定程度上都限制了机器人的智能性和学习效果,这都将成为本文下一步工作的重点.

表2 10轮学习中的nM 及nMs数Table 2 nM and nMsin 10 learning rounds
