基于改进结构保持数据降维方法的故障诊断研究
2021-04-18韩敏李宇韩冰
韩敏 李宇 韩冰
数据降维方法在众多领域应用广泛,其划分依据也不尽相同,按照数据结构特征保持与否的准则进行划分,则可根据数据的全局结构保持和局部结构保持分成两类[1],前者反映了数据的外部形状,后者反映了数据的内在属性,可以寻找出高维观测数据中所隐藏的低维流形结构.其中,主成分分析(Principal component analysis,PCA)[2]、独立元分析[3]和人工神经网络[4]等方法均为数据全局特征结构保持的代表方法,核主成分分析(Kernel principal component analysis,KPCA)[5]通过非线性映射函数将线性不可分的原始样本数据输入空间通过投影变换到线性可分的高维特征空间,然后在新的特征空间中利用线性方法完成主成分分析,从而实现数据整体方差最大化,但KPCA方法只能够提取数据的全局结构信息,若数据中低维局部结构中包含较多特征信息的话,则效果较差.另外,流形学习能够从高维历史信息中获取数据间有效的内部联系,从而得以保持局部结构特征,具有良好的非线性数据内部属性的处理能力[6−7],代表性的流行学习[8]方法主要包括等距特征映射算法(Isometric feature mapping,ISOMAP)[9],拉普拉斯特征映射算法(Laplacian eigenmaps,LE)[10],局部线性嵌入算法(Locally linear embedding,LLE)[11],局部保持投影算法(Locality preserving projections,LPP)[12]等,其中,有学者在LPP算法中引入核方法,提出核局部保持投影(Kernel locality preserving projection,KLPP)[13],其在保持局部结构特征的同时实现线性计算,反映出数据的局部结构特征,但本质上KLPP是一种基于局部结构保持的降维方法,它并不能有效提取出数据的全局特征信息[14].
针对以上问题,本研究拟对KPCA与KLPP相结合的降维方法进行探讨,提出了本文的解决办法,并把新提出的算法命名为改进全局与局部结构保持算法(Global and local structure preserving,GLSP),在进行原始数据的投影变换时,既考虑全局结构得以保持,也兼顾保持局部近邻结构.首先使用局部与全部特征提取方法,解决数据有效降维的问题,使用聚类分析中类内距离与类间距离等作为衡量指标,并使用K近邻(K-nearest neighbor,KNN)方法进行故障的检测[15].本文数据使用柴油机仿真故障数据[16]和TE过程公共数据集,用于验证方法的有效性.
1 改进结构保持方法
作为非线性特征提取的经典方法,KPCA通过非线性映射将线性不可分的原始数据从低维空间变换到一个线性可分的高维特征空间,运用线性方法进行数据降维与特征提取,其目标是使得数据方差最大化,但数据方差指标主要用来描述数据集的全局结构信息.此外,KLPP是通过建立样本点之间的近邻关系来保持数据集的局部结构,本质是保持原始数据局部结构和内部属性.综合考虑KPCA 与KLPP两种投影保持方法的思想,本文提出GLSP,其目标函数可以理解为由全局目标函数和局部目标函数共同组成.
1.1 局部结构保持算法描述
KLPP通过非线性投影映射,在投影空间建立近邻图,最大限度地保持了数据集的近邻结构,其局部结构保持目标函数定义如下[17]:假设数据集X=[x1,x2,···,xn]T∈Rn×m,n为样本个数,m为数据维数,通过非线性映射Φ将原始数据映射到高维空间中,记为Φ(xi),Jlocal(w)的目标是在特征空间中找到投影向量w,使得投影yi=ΦT(xi)w在高维特征空间保持数据点之间的近邻关系,可以认为,如果Φ(xi)和Φ(xj)是近邻,那么yi=ΦT(xi)w和yyj=ΦT(xj)w也是近邻的.其局部结构保持的目标函数定义为:
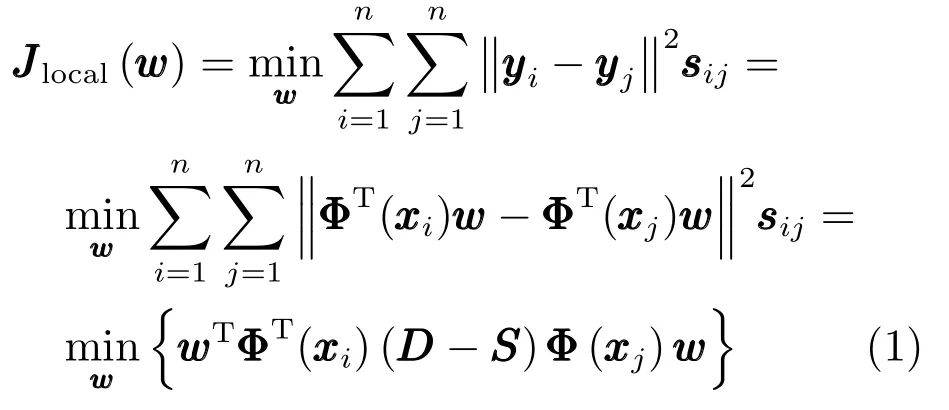
式中,sij为权重参数,表示数据点之间的近邻关系,SS为权重矩阵,D为对角矩阵,Dii=n j=1sij,sij取值一般为:
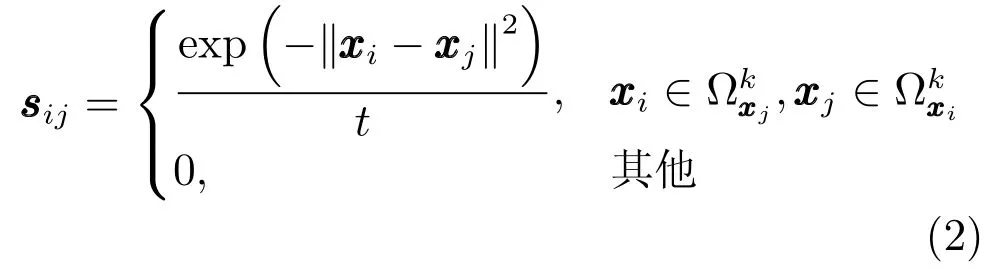
引入核函数KKKij=KKK(xi,xj)=ΦT(xi)Φ(xj),并存在系数α=[α1,α2,···,αn]对特征空间中的样本线性表示为w=局部结构保持的目标函数转化为:
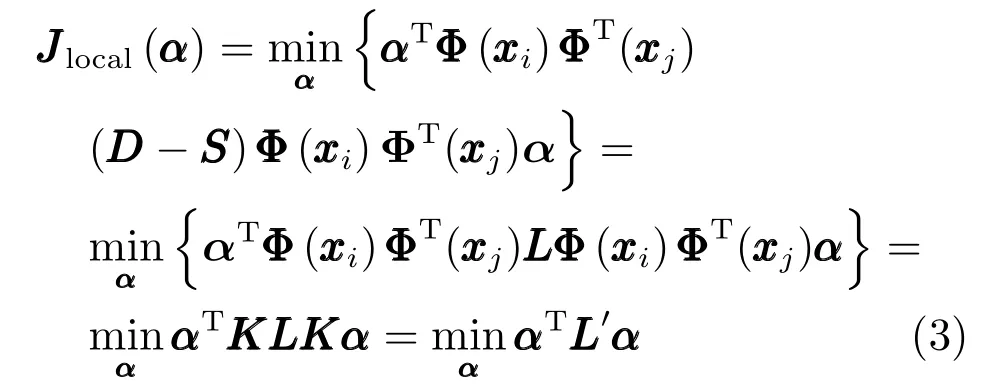
式中,L=D−S为Laplacian 矩阵,L=KLK.
KLPP算法的目的是使数据在高维映射空间中,仍能保持数据之间的近邻结构,但是算法本身忽略了对数据集的整体结构特征描述.其本质是因为局部目标函数表达式中没有显式地考虑样本点的全局特征,只是利用局部结构来代替全局信息,导致了数据在低维映射中全局特征的扭曲显示.
1.2 全局结构保持算法描述
PCA算法常用于数据主要成分的分析与维度约简,其本质是将线性数据变换为各个维度线性无关表示的几组数据,便于对数据中主要特征分量的提取.KPCA 算法由核映射将数据映射到高维核空间,然后使用PCA方法,与KLPP算法类似,通过非线性映射Φ将原始数据X=[x1,x2,···,xn]T∈Rn×m映射到高维空间,记为Φ(xi),经过投影向量w投影后的映射yi=ΦT(xi)w,在投影方向上保证数据方差最大化,这样可以充分利用高阶统计信息和全局特征结构保持.其全局结构目标函数定义为:
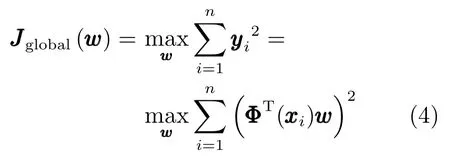
式中,wTw=1.
引入核函数Kij=K(xi,xj)=ΦT(xi)Φ(xj),可看出即使不确定核函数的具体表达形式,但是其转化为映射后的数据的内积运算,存在系数α=[α1,α2,···,αn]对特征空间中的样本线性表示为全局结构保持的目标函数转化为:

式中,αTKKKα=1,C=KK.
因为KPCA是一种面向全局的变换方法,由于其保持了原始数据的大部分方差信息,所以实现了全局结构的特征提取.然而,保持全局结构的目标函数中没有考虑各类数据点之间的内部联系,在低维空间里,数据点之间的局部几何关系与内在属性可能被忽视,甚至导致重要信息的丢失.
1.3 改进的整体目标函数
全局结构目标保持函数的思想是在最大程度保持全局信息方差不变的情况下,提取出样本数据的非线性特征;而局部结构保持目标函数的思想是在投影中保持样本对之间的远近亲疏关系,在低维空间中最小化近邻样本间的距离加权平方和,即尽量避免样本集的发散.
结合全局结构保持目标函数和局部结构保持目标函数的意义,构造一种新的结构保持目标函数,使得映射后的特征空间能够保留全局结构的同时,又可以保持数据间的局部近邻结构[18−19],构造出如式(6)的最大值选择问题,由于局部结构保持的目标函数为求取最小值,所以式(6)中引入其相反数:
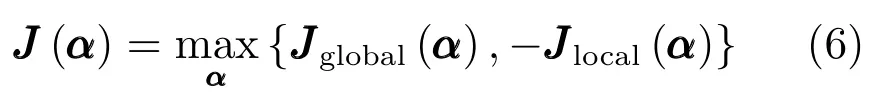
由于式(6)只从两个目标函数中选择其一,是一个典型的多目标求取最值问题,由于未考虑两个目标函数的综合效果,通常很难求解到全局最优解,因此,将式(6)中两个目标函数进行求和操作,求和后的目标函数如式(7)所示:
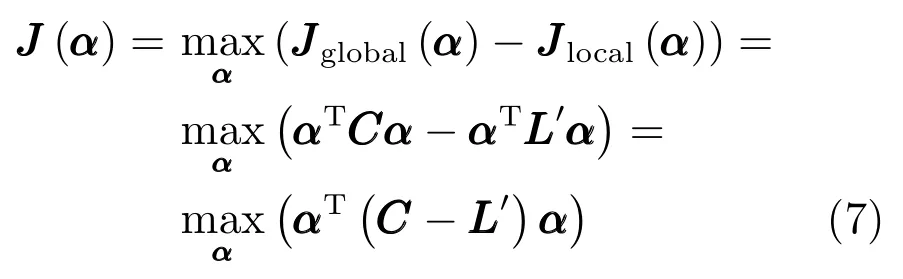
同理,这两个目标函数很难同时达到最佳效果.考虑到两个目标函数之间的差异,所以,引入一个权重参数β来平衡上述两个目标函数,β是一个介于0和1之间的值,其值的大小对于新的目标函数JJJ(α)有很大影响,因为它决定着两个原始目标函数的重要性问题[20].实际上β可以看作是平衡两个目标函数的能量变化.β越小越侧重于全局特征的提取,β越大越侧重于局部特征的提取,β值的选取按照如下准则:
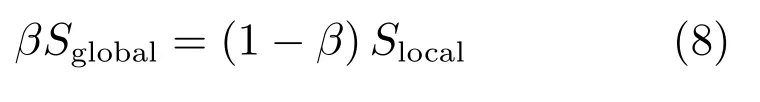
其中,Sglobal和Slocal分别表示Jglobal(w)和JJJlocal(www)的规模大小,受到参考文献[18,21]启发,定义为:

式中,ρ(·)是相关矩阵谱半径.结果表明,该平衡参数的引入策略能够很好地平衡全局和局部的行为,GLSP的降维性能也可以得到保证.事实上,权重参数也可以根据不同背景下原始数据的特性,赋予不同定义,而不仅限于本文所提方法,这使得改进的结构保持算法更加灵活.结合式(8)∼(10),可得到权重参数β的计算公式如下:
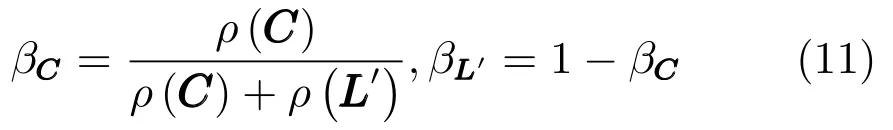
因此,改进的整体目标函数表示为:
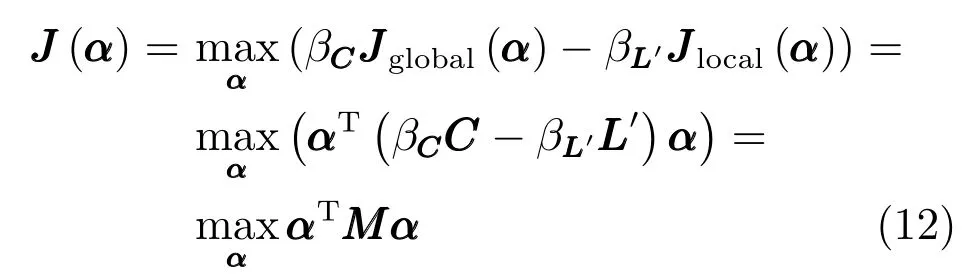
式中MMM=βCC−βLL,0≤βC ≤1,0≤βL≤1.
最后将上述目标函数的优化问题转化为求解特征向量问题.确定权重参数β的值之后,结合式(5)中的条件,引入拉格朗日乘子法,求解特征向量:
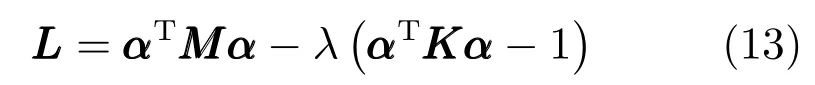

非线性问题的求解过程中,引入正则化方法,我们用KKK+ηIIIn来代替式(14)中的KKK,其中,η是一个很小的正整数,In是一个n×n的单位向量.
与PCA类似,本文使用累积方差贡献率准则选取满足贡献率达到要求的主成分个数,依据式(15)选取前p个特征值确定主成分个数,本研究中贡献率选定为85%.

2 降维方法实现
原始数据在降维时,将面临难以全面提取有用信息的困难,为解决这一问题,本文提供一种结合全局与局部结构保持的数据降维思想,实现方法为:采集原始数据,建立能够从多角度反映数据信息的高维数据集,并加以验证;再将数据集输入所提全局与局部结构保持算法中进行降维处理:将低维特征子集输入KNN最近邻分类器,计算KNN的识别率,并将聚类分析中类间距与类内距的比值SSSB/SSSW作为衡量降维效果指标[22].
2.1 降维评价指标
Fisher 判别分析是模式识别方法中的一种数据降维与分类方法.其通过投影将测试数据映射到不同方向,使得不同类别的测试样本的投影的类间离散度最大,类内离散度最小[23].类内距SW描述同一类样本内部分布的紧密程度,而类间距SB用反映不同类别之间的分离程度,定义如下[15,24]:

其中,mi表示特征空间中第i类采样均值,m表示所有样本点在特征空间中的均值.显然,SSSB/SSSW越大说明该方法的分类与聚类效果越好,因此将该指标作为降维效果的综合衡量指标之一.
KNN是对不同类别的数据信息根据训练样本特征进行分类的方法,具有操作直观、效果稳定、时效性强等优点,广泛应用到各类数据分类领域,尤其是故障数据的诊断与分类中.原始数据进行降维操作,其最终目的是实现不同故障类别的准确分类,故KNN方法的识别率越高,其反映出对数据的初始降维方法越好[25−26].
2.2 降维方法流程
总结局部与全局结构保持算法的流程图如图1所示.

图1 数据降维方法流程Fig.1 The dimension reduction process of data
算法主要流程如下.
步骤1.对于数据集X=[x1,x2,···,xn]T∈Rn×m,构造局部结构保持函数Jlocal(α).
步骤2.构造全局方差最大目标函数JJglobal(α).
步骤3.构造整体目标函数J(α).
步骤4.根据式(14)求解特征值λ1,λ2,···,λn与对应的特征向量A=[α1,α2,···,αn].
步骤5.根据式(15)求解前p个特征值λ1,λ2,···,λp与对应的特征向量A=[α1,α2,···,αp].
步骤6.根据公式T=KTA,获得样本集在低维正交特征子空间的投影.
步骤7.通过映射矩阵对训练及测试样本进行维数约简,再将得到的低维特征子集输入到KNN,并计算低维特征子集的SB,SW及SB/SW指标.
3 仿真实验与分析
3.1 柴油机故障数据仿真
船舶柴油机广泛应用于实际航运工程中,其安全稳定的运行状态对整个系统起着至关重要的影响.因此,在船舶柴油机发生故障时,如果能够准确将故障信号的有效特征提取并分析,则可提供足够多有效信息,便于故障的分类和诊断[27−28].
1)模型设计
本文以MAN公司S35ME-B9型柴油机为主要研究对象,利用专业模拟软件AVL Boost完成柴油机故障模型仿真模拟系统,图2为柴油机仿真模型.
图2中,SB1、SB2、SB3为系统边界,外界气体通过SB1进入系统,系统工质通过SB3排出系统,MP1∼MP8为测点,MP1和MP2测量中冷器前后的气体压力、温度,MP3和MP4 测量气体进入和流出进气管PL1的气体压力、温度,MP5和MP6测量进入和流出1号缸的气体压力、温度,MP7 和MP8测量废气进入和流出涡轮增压的气体压力、温度,C1∼C6为气缸,1∼29为管道连接,PL1为进气管,CO1为中冷器,TC1为涡轮增压器.
本文对正常工况以及三种常见的船舶柴油机故障进行仿真模拟,包括空冷器冷却不足,排气口堵塞以及涡轮增压器效率降低,如表1所示,由于本文采用的数值仿真模型,因此采用设置关键参数的方式对故障进行模拟.在每种工况下,记录模型中8个测量点的15个状态参数作为原始数据,分别为功率(kW),最大爆发压力(100 kPa),压力机流量(kg/c),压力机出口温度(◦C),压力机出口压力(100 kPa),中冷器后温度(◦C),中冷器温差(◦C),中冷器后压力(100 kPa),中冷器压差(100 kPa),扫气温度(◦C),扫气压力(100 kPa),排气管温度(◦C),排气管压力(100 kPa),废气进涡轮机温度(◦C),涡轮增压出口温度(◦C).

表1 正常工况与故障工况模拟Table 1 The simulation of normal and fault conditions
将故障数据集经本文所提降维方法进行处理,选取KPCA、KLPP、核Fisher判别分析(Kernel fsher discriminant analysis,KFDA)[29]、局部和全局主成分分析(Local and global principal component analysis,LGPCA)[30]、全局–局部结构张量分析(Tensor global-local structure analysis,TGLSA)[20]和本文共6种算法进行对比,在本研究中选取的目标维数为3维,研究中采用了交叉验证方法选取最优高斯核参数,实验从降维效果可视化、降维效果综合衡量指标和特征提取速度分析三方面验证方法的有效性.
2)模型验证
使用AVL Boost进行柴油机工作状态仿真模型的建立,选择台架实验的关键状态参数数据和AVL Boost对应状态参数进行对比验证.以柴油机功率、排气温度对柴油机模型正确性进行验证,以排气阀堵塞和空冷器冷却不足等故障对柴油机模型进行故障模拟验证.
表2是使用三种不同的工作状态的特定工作参数平均值与台架实验中对应参数的比较,可以发现台架实验数据与AVL Boost相差较小,可以认为使用AVL Boost建立的柴油机模型与台架实验使用柴油机具有相同的工作参数.
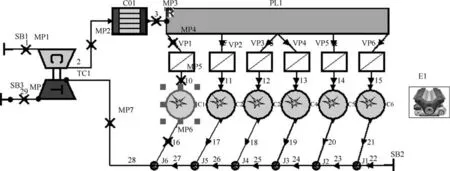
图2 柴油机模型仿真Fig.2 The diesel engine simulation

表2 AVL Boost数据与台架实验数据多工况对比Table 2 The data contrast between AVL Boost and bench test under multiple working conditions
排气口堵塞是采用逐渐减小单个气缸的排气口直径的方法进行仿真验证,排气口堵塞会造成排气效率不佳,气缸内废气无法及时排出,会造成气缸内气体逐渐增加,缸内压力逐渐增大,引起扫气压力增大,进气逐渐减少,也就是压力机流量减小.排气口堵塞还会造成气缸内高速积碳,引起后燃现象,使得排气温度上升,燃烧效率下降,但由于上述故障因素只是增加在一个气缸中,其余五个气缸的燃烧过程影响不大,因此对柴油机的功率影响不大.使用AVL Boost仿真这种故障,上述提到的理论上的参数变化均获得了较好的验证.
空冷器冷却不足是使用逐渐增加冷却液温度,逐渐降低空冷器冷却效率的方法仿真验证.这种故障最直观的反映就是空冷器前后温差降低,另外由于空冷器冷却效率下降,增压之后的气体无法较好地得到冷却,扫气温度上升,进入气缸内的气体质量会下降,随之扫气压力上升,流经压力机的空气流量会相应减小,由于进入气缸的新鲜空气减少,功率和最大爆发压力都会出现下降趋势,同时由于进入气缸的空气温度上升,排气温度也会上升.
3)降维效果可视化
为验证本文降维方法的有效性,将故障数据集经KPCA、KLPP、KFDA、LGPCA、TGLSA和本文所提降维方法进行处理,选取前480个样本作为训练样本,后480个样本作为测试样本.根据本文所提算法选取降维后的前三个主成分即可较为直观有效的表现降维效果,图3为根据贡献率原则,选择不同降维维数与对应的主元贡献率,由图中可知,本文中选择主成分为前三维,其贡献率之和即可达到总贡献率的85%,因此仿真实验中的贡献率选择为85%即可.得到降维后的测试样本三维特征量分布见图4∼9.
从图4可以看出,KPCA可以分辨正常工况与故障1,但对于故障2和故障3有较严重的数据重叠现象.从图5可以看出,KLPP对于4 种工况均不能较为有效地进行区分.
图6∼8分别为KFDA、LGPCA、TGLSA三种不同降维方法的对比实验效果图,KFDA效果较差,样本数据大部分呈现混叠状态,LGPCA和TGLSA算法也综合保持了全局结构和局部结构,因此其效果略好于KFDA、LGPCA和TGLSA三种算法,但由于其主要应用于维数较低的数据,因此对于船舶柴油机的高维复杂数据,效果一般.
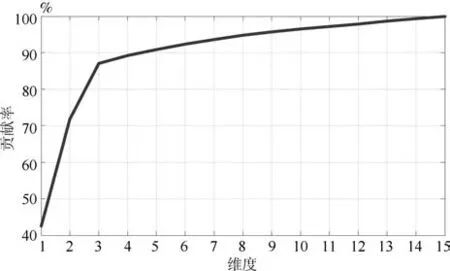
图3 不同维度贡献率统计图Fig.3 The contribution rate of dif ferent dimensions
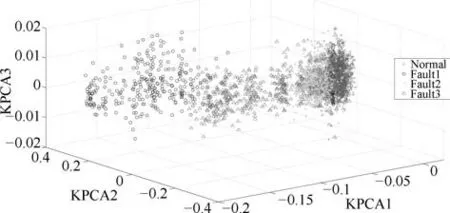
图4 KPCA降维结果Fig.4 The dimension reduction based on KPCA
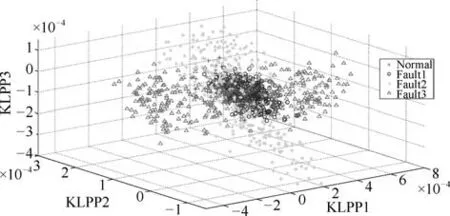
图5 KLPP降维结果Fig.5 The dimension reduction based on KLPP
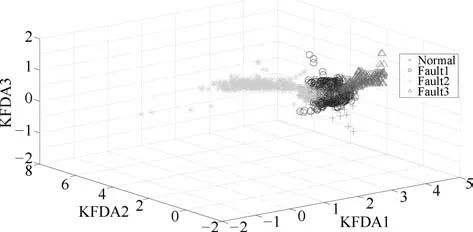
图6 KFDA降维结果Fig.6 The dimension reduction based on KFDA
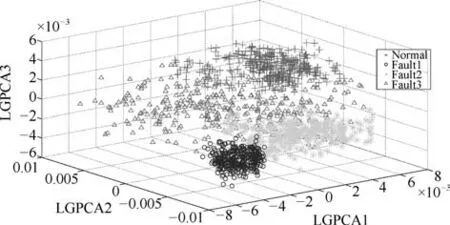
图7 LGPCA降维结果Fig.7 The dimension reduction based on LGPCA
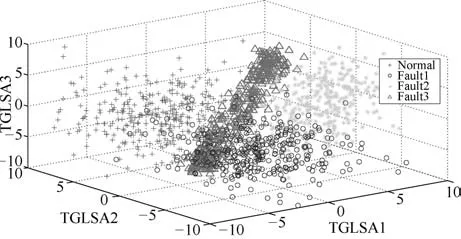
图8 TGLSA降维结果Fig.8 The dimension reduction based on TGLSA

图9 GLSP降维结果Fig.9 The dimension reduction based on GLSP
本文所提降维方法效果图如图9所示,其中,权重参数根据计算得到βC=0.79,βL=0.21,可见对于柴油机故障数据,KPCA方法所侧重的全局特征占主导地位.由于全局和局部结构特征提取过程的综合考虑,在完成数据约简和可视化的同时,有效地分离了四种状态,同时具有良好的聚类能力.因此,本文提出的方法能够提取故障特征,解决了数据降维可视化问题.
4)降维效果综合衡量指标
为直观有效地可视化各类方法的降维效果,将类间距SSSB,类内距SSSW及二者的比值SSSB/SSSW作为衡量指标,类间距SSSB及二者的比值SSSB/SSSW越大,表明分类效果明显,得到的评价结果见图10,从图中可以看出,六种方法中,本文所提GLSP方法对应的类间距及二者的比值具有最大值.分析如下:
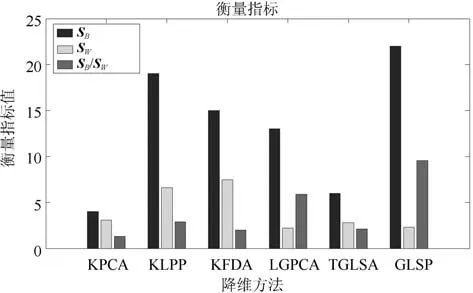
图10 六类算法降维效果衡量指标Fig.10 The dimension reduction performance of 6 methods
a)KPCA降维效果及识别率一般,虽然可以去除特征空间中的数据冗余信息,但并未达到能够有效表达最佳情况的条件;KLPP局部结构保持的方法的类间距明显提高,该方法能有效提取出数据集中局部结构,但对于综合全局与结构方法所得到的类间距与类内距的比值,还有一定差距;KFDA方法具有较高类内距,但是对于类内距没有很好的聚合效果;LGPCA和TGLSA两种方法均具有较好类内聚合作用,但是由于不同类别的类间距离较小,导致综合类间距与类内距比值较小.
b)本文所提方法的降维效果及识别率要高于其他对比方法,该方法能够避免子空间重构,更利于故障类别的划分,且具有较强的全局与局部判别信息的挖掘能力.
故障诊断的实质是模式识别,考虑船舶柴油机故障诊断的实船应用性,选择极限学习机(Extreme learning machine,ELM)、支持向量机(Support vector machine,SVM)、相关向量机(Relevance vector machine,RVM)、KNN四种基础有效的分类方法进行检验,将低维样本分别应用于上述四种方法进行分类效果比较,表3∼5给出了测试样本的故障诊断结果,可知相较传统的分类方法,对于仿真所得故障数据的诊断率均不高,但是所提出的GLSP降维方法所获得的低维有效数据在大部分情况下获得最高的故障识别精度,未获得最高识别精度情况下,其精度与最高精度相差不大.
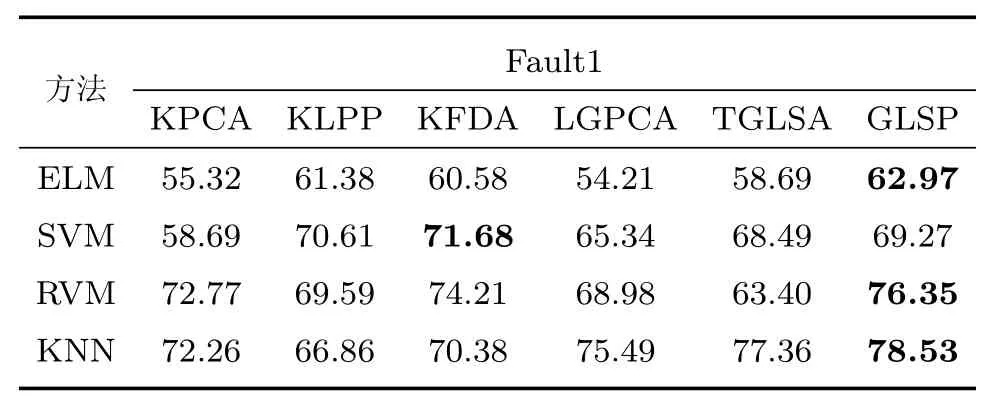
表3 故障1识别准确率(%)Table 3 The accuracy of fault1 diagnosis(%)

表4 故障2识别准确率(%)Table 4 The accuracy of fault2 diagnosis(%)
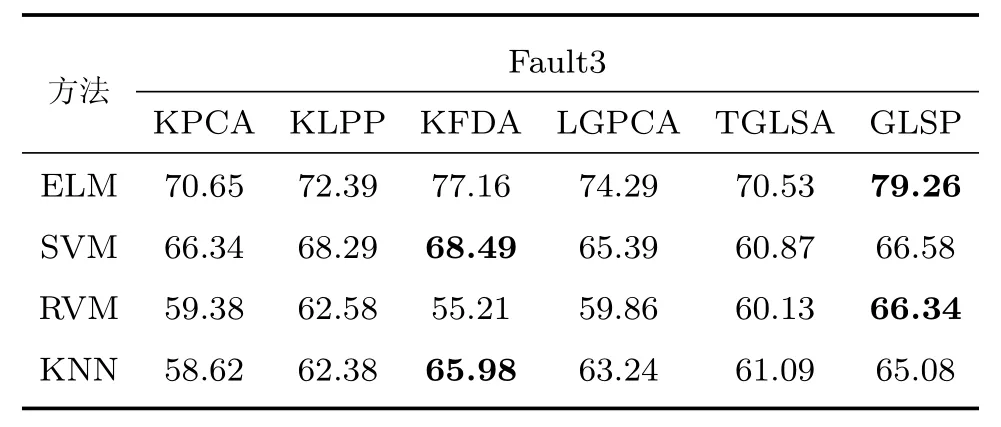
表5 故障3识别准确率(%)Table 5 The accuracy of fault3 diagnosis(%)
5)降维效果综合衡量指标
时间性能比较是在实验室中台式机电脑上进行,其配置为Intel Core i3 CPU 3.3 GHz,RAM 4 GB,Win7 操作系统,仿真软件为MATLAB 2010a,计算结果如表6所示.由表6可知,本文所提方法降维所需时间相对于其他方法有所增加,但是都是在一个数量级,且运行速度均在5 s以内,满足实际情况中对于实时的要求.

表6 特征提取所需时间(s)Table 6 Feature extraction time(s)
3.2 TE数据仿真
TE过程是一个公认的对比各种控制和监控方案的平台,为验证本文所提方法的通用性,将本文算法应用于故障检测与诊断领域被广泛使用的TE化工数据集上.TE过程是基于真实工业过程的仿真平台,包含了一组正常状态和21组不同故障状态,分别涵盖了12个操纵变量和41个测量变量,每组状态包含480组训练数据和960组测试数据,每一组故障从第160个数据点引入,过程的详细描述、工艺流程图以及其故障形式的具体介绍见文献[31].
从TE数据集中选取1组正常工况数据和3组故障数据(故障4、故障8和故障14),使用本文所提GLSP算法得到降维后的前两维特征矢量,对于TE数据,前两维即可较好体现降维效果,本文权重参数根据计算得到βC=0.64,βL=0.36,并将本文算法与KPCA、KLPP、KFDA、LGPCA和TGLSA五种降维方法进行比较,如图11至图16.

图11 TE数据下KPCA算法降维效果Fig.11 The dimension reduction performance of KPCA on TE data
从图11和图12前两维降维效果可以看出,KPCA和KLPP对于4类数据分离效果较差,特别是正常工况与故障4和故障14存在大量重合现象;图13和图14中KFDA和LGPCA方法对于正常工况和故障14难以有效区分;图15和图16的特征提取效果略好于前几种方法,但TGLSA方法虽然能够较好地区分故障4和故障14,但是正常工况和故障8仍有较大重叠,而本文所提算法提取了更为丰富的全局与局部结构信息,在完成数据降维可视化的同时能够将四类数据有效分离.
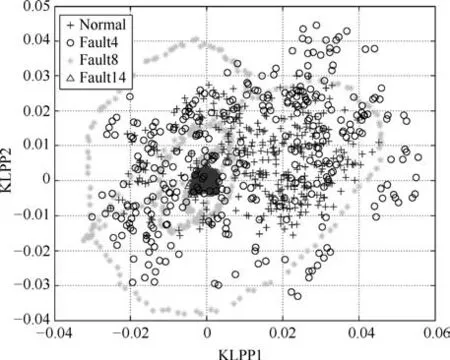
图12 TE数据下KLPP算法降维效果Fig.12 The dimension reduction performance of KLPP on TE data

图13 TE数据下KFDA算法降维效果Fig.13 The dimension reduction performance of KLPP on TE data
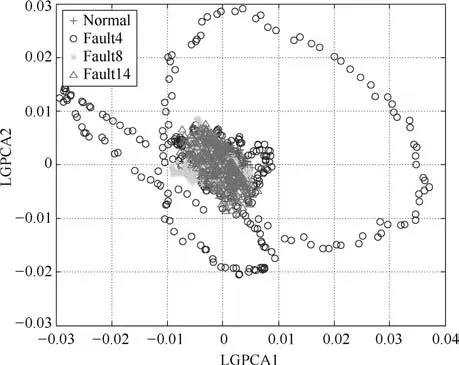
图14 TE数据下LGPCA算法降维效果Fig.14 The dimension reduction performance of LGPCA on TE data
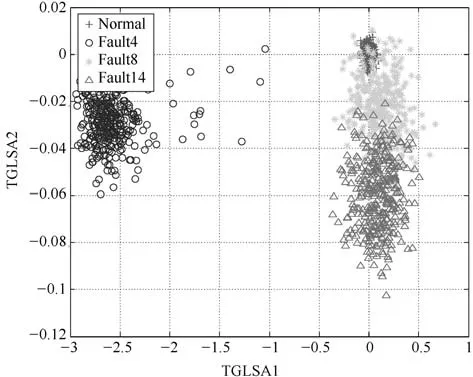
图15 TE数据下TGLSA算法降维效果Fig.15 The dimension reduction performance of TGLSA on TE data

图16 TE数据下GLSP算法降维效果Fig.16 The dimension reduction performance of GLSP on TE data
4 结论
本文通过融合全局特征提取KPCA与局部特征提取KLPP两种降维方法,提出一种结合两种降维方法的数据维数约简方法GLSP,增强了数据低维可视化效果,同时提高了识别精度,并将其应用于故障诊断中.所提方法将流形学习保持局部结构的思想融入核主成分分析的目标函数中,使得到的特征空间不仅具有原始样本空间的整体结构,还保持样本空间相似的局部近邻结构,可以包含更丰富的特征信息.使用AVL Boost软件对船舶柴油机工作过程进行故障仿真,提取正常工况与故障工况下的仿真数据,并将AVL Boost软件仿真数据和TE化工公共故障数据应用到所提方法中,实验结果证明,本文所提GLSP算法具有较好的维度约简效果,并具有较高分类精度的优势.
