基于随机森林回归的火电机组供电煤耗遗传优化模型
2021-04-17孙永平王立峰张震伟杨勤
孙永平 王立峰 张震伟 杨勤
(1. 浙江浙能技术研究院有限公司, 杭州 311121;2. 山东鲁能软件技术有限公司, 济南 250001)
0 引言
随着电力系统体制改革深化与电力市场交易机制的快速推进,发电企业之间的竞争日益激烈[1],加之在政策影响和市场选择的作用下,新能源发电扩张迅猛,严重冲击火电机组的整体容量和上网份额[2],火力发电企业生存环境日趋严峻。在此形势下,挖掘和拓展发电企业自身的节能降耗潜力、降低发电成本已成为大势所趋。供电煤耗作为衡量机组运行经济性的重要指标,同样也是发电变动成本的重要构成要素,把握机组运行供电煤耗对于发电企业竞价上网的报价决策具有重要意义。
1 供电煤耗算法概述
传统供电煤耗的计算方法主要为正平衡煤耗和反平衡煤耗两种[3],这两种计算方法都有入炉煤化验数据参与计算,但在实际生产过程中,煤质化验结果的得出与上报存在时间上的滞后性,在电厂的各类信息化系统中,实时供电煤耗的计算结果都会受到影响,出现不准确的情况。电厂锅炉制粉设备和燃烧设备的结构、选型以及锅炉受热面的布置方式对煤质都有一定的要求,入炉煤的全水分、收到基灰分、干燥基全硫、干燥无灰基挥发分、收到基低位发热量以及灰熔融性等性质都会有一定的限制性,所以一定程度上电厂的煤种又是相对稳定的[4]。
20世纪90年代以来,软测量技术逐步成为工业领域重要的研究方向[5],从理论研究到实际生产应用,软测量技术在火电行业取得了长足的发展。飞灰含碳量、烟气氧量、入炉煤种、球磨机出力等取样周期长、结果过于滞后、难以直接测量等重要运行指标,成为软测量技术研究和应用的主要对象。赵新木等[6]提出了一种基于误差反向传播(BP)神经网络的方法,建立了煤粉锅炉的飞灰含碳量预测模型。文雯等[7]利用了随机森林算法运算速度快、调整参数少、抗噪声能力强、不易出现过拟合等优点,结合供电煤耗作为机组整体经济性指标受多维参数影响的特点,提出了一种基于并行随机森林算法的火电机组供电煤耗计算模型。国内已有人基于支持向量机(SVM)在模式识别与机器学习中的良好的数学性质提出了一种基于最小二乘支持向量机和PSO算法的电厂烟气含氧量软测量模型[8]。Jamshid Khorshidi利用遗传算法可对多个自变量同时进行寻优的特点,提出了一种以主汽压力、给水温度、真空、排烟温度、排烟氧量、飞灰含碳量为自变量的煤耗率优化模型[9]。以上文献中,均是应用软测量技术对火电机组内难以直接测量的重要运行指标进行预测评估,只是应用机器学习数学模型分析出该指标与运行控制参数之间的非线性关系,缺少基于机组实际运行工况情况对软测量指标实时优化应用研究。因此,本文基于同工况种类的参数寻优思想,应用随机森林回归技术,从火电机组历史数据中挖掘供电煤耗与多种运行控制参数间的非线性映射关系;然后,基于遗传算法,提出工况距离就近匹配的优化策略,用于实现以供电煤耗最少为目标的运行参数控制优化。在工况匹配应用中,本文采用凝聚层次聚类算法对机组数据进行工况划分,实现机组相似类型数据的高效特征分析,更有利于机组煤耗的实时优化。
2 算法原理
2.1 随机森林回归算法
分类回归树(Classification And Regression Tree,CART)是一种典型的二叉决策树,依据待预测结果的数据类型可以实现数据的分类或者回归功能。随机森林回归算法是2001年Breiman[10]采用集成算法的思想,在每个CART树的构建上采取随机参数的选择,使得随机森林中每一棵树都尽可能不相关,然后组合多颗决策树进行预测。随机森林回归算法具有算法运行速度快、调整参数少、稳健性强且计算开销小的优点。
Fernandez-Delgado[11]在对121个UCI数据集上进行了179个分类算法的性能比较表明,随机森林试验效果表现最为出色。而在随机森林回归算法中,则是将每一棵CART树建立为回归树。然后,随机森林中每个决策树的预测值求平均,作为最终的随机森林预测结果。下面将对CART树的均方误差最小准则进行介绍。
假设X与Y为数据的一组输入变量与输出变量,并且Y具有连续性,训练数据集D={x1,y1,x2,y2,……,xn,yn}。
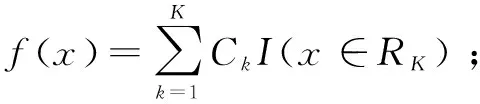
这里使用均方误差对训练数据的预测结果进行优劣评估,从而得到每个节点的最优选择。
2.2 遗传算法
遗传算法(Genetic Algorithm)由Holland建立[12],通过模拟自然界中优胜劣汰的思想来寻找全局最优解,具有良好的鲁棒性、并行性和高效性的特点。近些年,遗传算法正在不断地与神经网络、模糊推理和混沌理论等其他智能算法相互渗透与结合,已应用于电力系统的多个领域内,如电力负荷数据修正[13]、热电机组储热罐[14]。本文中机组供电煤耗优化的目的在于选取最优机组运行控制参数,最小化机组供电煤耗。经典遗传算法已具有强大的全局寻优能力,本文将应用该算法进行机组供电煤耗优化。
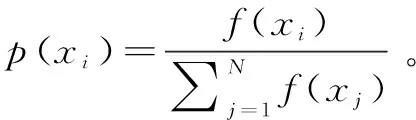
本文中遗传算法主要用于在建立煤耗值高准确度预测后,在正常可调参数范围内进行多项参数值的调节,寻找煤耗值的最小值,从而得到最优煤耗值。
2.3 凝聚层次聚类算法
凝聚层次聚类(Hierarchical Agglomerative Clustering,HAC)属于一种聚类算法,本质是将每一个样本点都当成一个聚类,通过不断合并临近的两个点,直到满足设置的迭代终止条件,最终得到的聚类中心可较高精度地代表每类数据的信息,HAC聚类算法的完整流程如下。
步骤1:将输入样本集{x1,x2,x3,x4……,xn}中的每个样本都单独的归为一类,即Cn=xn。
步骤2:分别计算样本与样本的距离,Mn,m=dist(Cn,Cm)。
步骤3:找到距离最小的两个样本,合并聚类,Cn=Cn∪Cm,将Cm后的样本聚类(簇)编号向前移动一位。
步骤4:删除Mn,m=dist(Cn,Cm)的第n行、m列,并重新更新Mn,m与样本聚类(簇)数量。
步骤5:反复进行步骤4,直到样本聚类(簇)数量达到设定的目标值。
在本文中,机组负荷、凝汽器真空、循环水平均进水温度3个参数作为工况划分参数,使用HAC聚类算法实现自动工况划分,聚类分析后,将同类别的3个参数数据集中在一定范围内。
3 基于随机森林回归的供电煤耗遗传优化模型
3.1 模型变量的选择
以某电厂1000 MW机组为研究对象,依据机组的结构设计以及机组供电煤耗的影响因素情况分析,确定以表1的47个测点作为模型测点表。应用随机森林回归模型时,模型的输出变量为机组供电煤耗率,其他46个参数作为模型的输入变量;应用遗传优化模型时,机组供电煤耗率作为模型优化的目标参数,再热蒸汽温度、再热器减温水流量补偿后、主蒸汽温度、凝汽器真空、排烟平均温度、空预器平均出口氧量6个参数作为模型优化的优化控制参数;应用凝聚层次聚类算法进行工况划分时,实发功率、凝汽器真空及循环水平均进水温度3个参数作为工况识别参数。
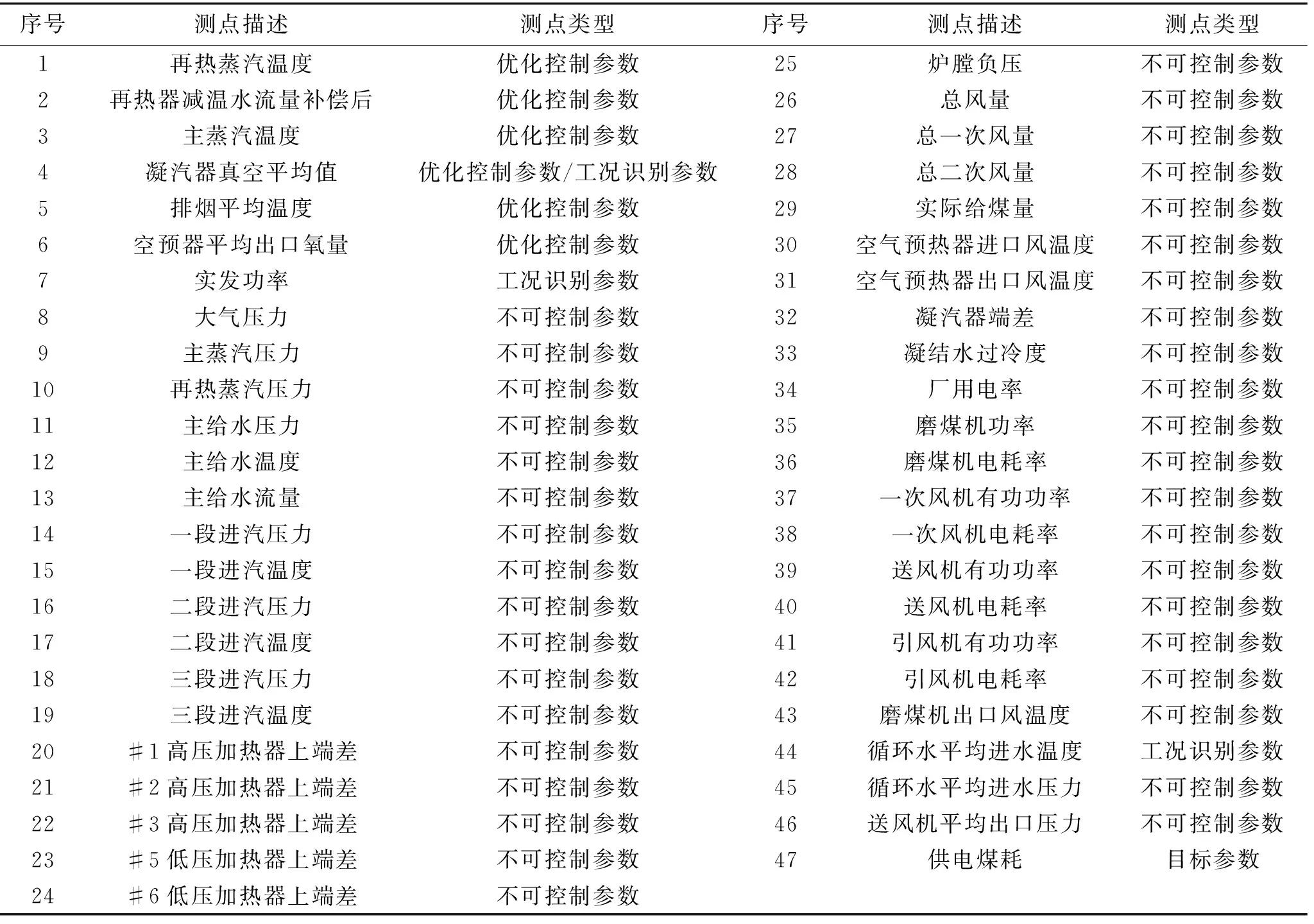
表1 模型测点表
3.2 采集数据与数据预处理
本文所采用数据中除供电煤耗率之外,其余参数全部取自电厂SIS系统存储数据库。采样频率为1 min,采样时间为3年。通过传统极差判断方式剔除历史机组数据中的非稳态数据,保留36 万组稳态数据,为检测模型的鲁棒性,随机抽取26 万组数据作为模型训练样本数据,剩余10 万作为模型测试样本数据。使用随机森林算法对机组供电煤耗软测量是在不具备实时化验数据的前提下,通过利用其他重要运行参数对供电煤耗具有的潜在关系实现的,因此为保证训练模型的准确性,需要对采集的历史数据进行预处理,包括去除离群数据、稳态数据的筛选、供电煤耗的补算,从而获取能够满足挖掘分析的样本集合。
(1)去除离群数据。离群数据多属于设备传感器受影响、损坏、脱落等问题导致的不正常数据,因此这种数据不符合数据挖掘的要求,需要去除。本文采用箱线图的方法进行离群数据去除,具体包括:计算每个参数的数据四分位距iqr、上四分位数prctile75及下四分位数prctile25,则该参数的上限阈值为:threupper=prctile75+3×iqr,该参数的下限阈值为:threlower=prctile25-3×iqr,则每个参数的数据按照超过上限阈值threupper或者低于下限阈值threlower的判断标准来剔除该参数存在的离群数据。
(2)稳态数据的筛选。受系统整体的工质和能量传递影响,机组在变工况过程中,各测点采集的数据在时间上存在不一致性,此时供电煤耗的机理计算结果存在一定的偏差,故为保证模型训练能够达到预期精度,需要区分机组历史数据是否稳态,训练阶段只使用运行稳定的工况,稳态数据的判断标准,这里使用时间窗口内的数据极差小于总体训练数据极差的10%。例如,机组负荷数据在整个历史时间段内的极差为800,则以机组负荷判定稳态数据时,其时间窗口内的数据极差值不能大于80。
(3)供电煤耗补算。由于供电煤耗数据不存在于历史数据库中,需要通过机理公式计算出来,为挖掘历史数据中关联参数与供电煤耗的回归关系模型,故需要通过机理公式计算供电煤耗。
3.3 模型流程
如图1所示,基于随机森林回归的供电煤耗遗传优化模型的模型流程主要分为以下步骤。
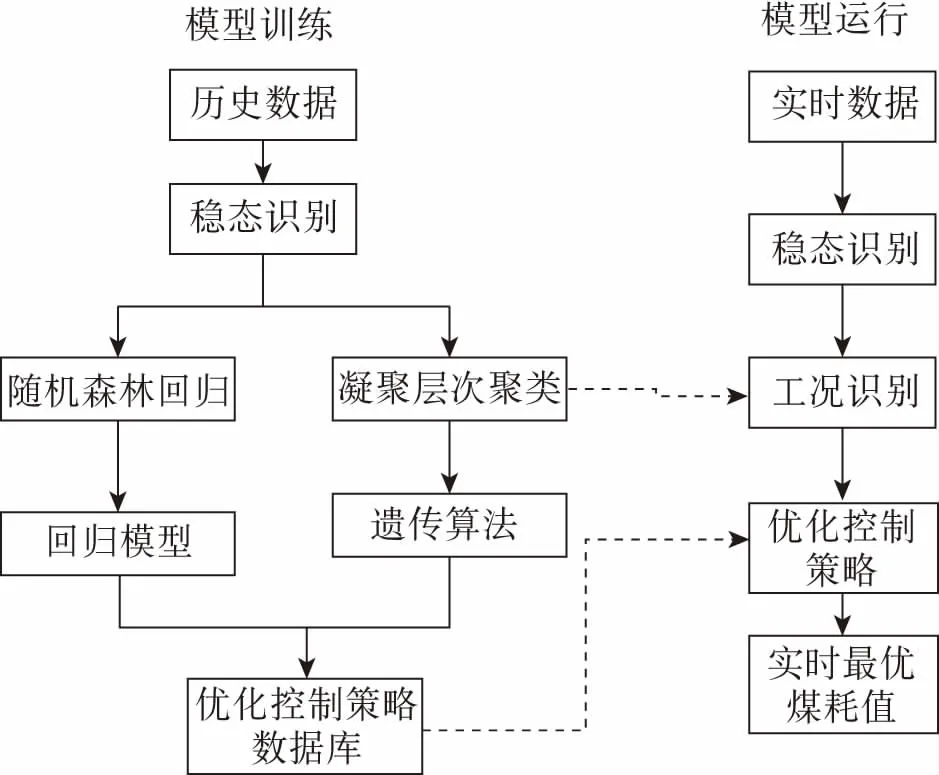
图1 机组供电煤耗优化模型流程
(1)稳态数据识别:通过极差判断方法从历史数据中识别出稳定运行工况下的数据。
(2)随机森林回归:以全部训练样本数据进行随机森林回归模型拟合,挖掘出供电煤耗跟模型输入参数的非线性关系模型。
(3)凝聚层次聚类:对工况识别参数的训练样本数据进行工况划分,实现将相似工况的样本数据作为同种工况数据。
(4)遗传算法优化:以煤耗参数最佳,通过寻优方式挖掘在同种工况下的最佳优化控制策略。
(5)遗传优化模型运行:对稳态类型的实时运行数据进行优化控制策略搜寻,并输出实时最优煤耗值。
4 案例研究
4.1 随机森林回归模型预测供电煤耗
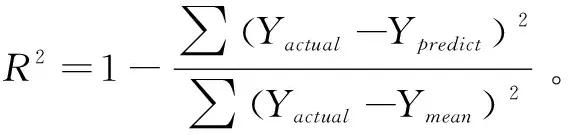
其中,Yactual为模型输出参数的实际值,Ypredict为模型输出参数的预测值,Ymean为模型输出参数的实际值的平均值。根据GridSearchCV法得到的模型超参值对26 万条训练样本数据训练随机森林回归模型,模型训练的整体拟合效果为决定系数R2为0.99,同时10 万条测试数据整体代入回归模型的拟合效果为其决定系数R2为0.988。
4.2 凝聚层次聚类工况划分与工况匹配
分析3个工况识别参数的26 万条训练样本数据可知,实发功率测点的数据分布范围为400 MW~1050 MW,凝汽器真空平均值的数据分布范围为-100 kpa~-87 kpa,循环水平均进水温度数据分布范围为3℃~36℃。按照本文凝聚层次聚类法的步骤,对全部训练样本进行工况划分,得到420 种工况类型,属于同类工况全部数据的平均值将被作为工况类中心数据(见表2)。展示部分工况下的工况类中心数据,可以看出不同工况类别下的类中心数值有明显差别,说明凝聚层次聚类法有较好的工况划分效果。

表2 基于凝聚层次聚类的工况类中心数据
在模型运行的工况匹配阶段,3个工况识别参数的实时数据与每个工况的类中心数据计算距离,距离最小的类别将作为工况匹配结果。匹配工况中的优化控制最佳参数将作为当前的优化控制策略。
4.3 遗传算法优化供电煤耗值
在火电机组的运行过程中,t时刻的供电煤耗值p(t)由多个优化控制参数a,b,c,…,n与不可控制参数A,B,C,…N同时影响,具体公式为:pt=fat+fbt+fct+…+fnt+fAt+fBt+fCt+…+fNt。
优化控制参数的取值范围依据匹配工况下的每个优化控制参数最高值与最低值。基于随机森林遗传优化算法将在全部优化控制参数的取值范围内寻优出一个优化控制策略,其能保证在该工况下目标参数最佳,即机组供电煤耗最低。
基于随机森林遗传优化算法流程如图2所示,在交叉/变异前将优化控制参数数值转换为二进制编码,交叉/变异结束后再解码成十进制常数并再次进行随机森林预测,继续从中选取表现效果好的种群个体编码成二进制再次进行交叉/变异。基于随机森林遗传优化算法在到达迭代次数设定值或者优化煤耗值不再发生变化时遗传算法停止,输出的供电煤耗最小值作为最优值输出。
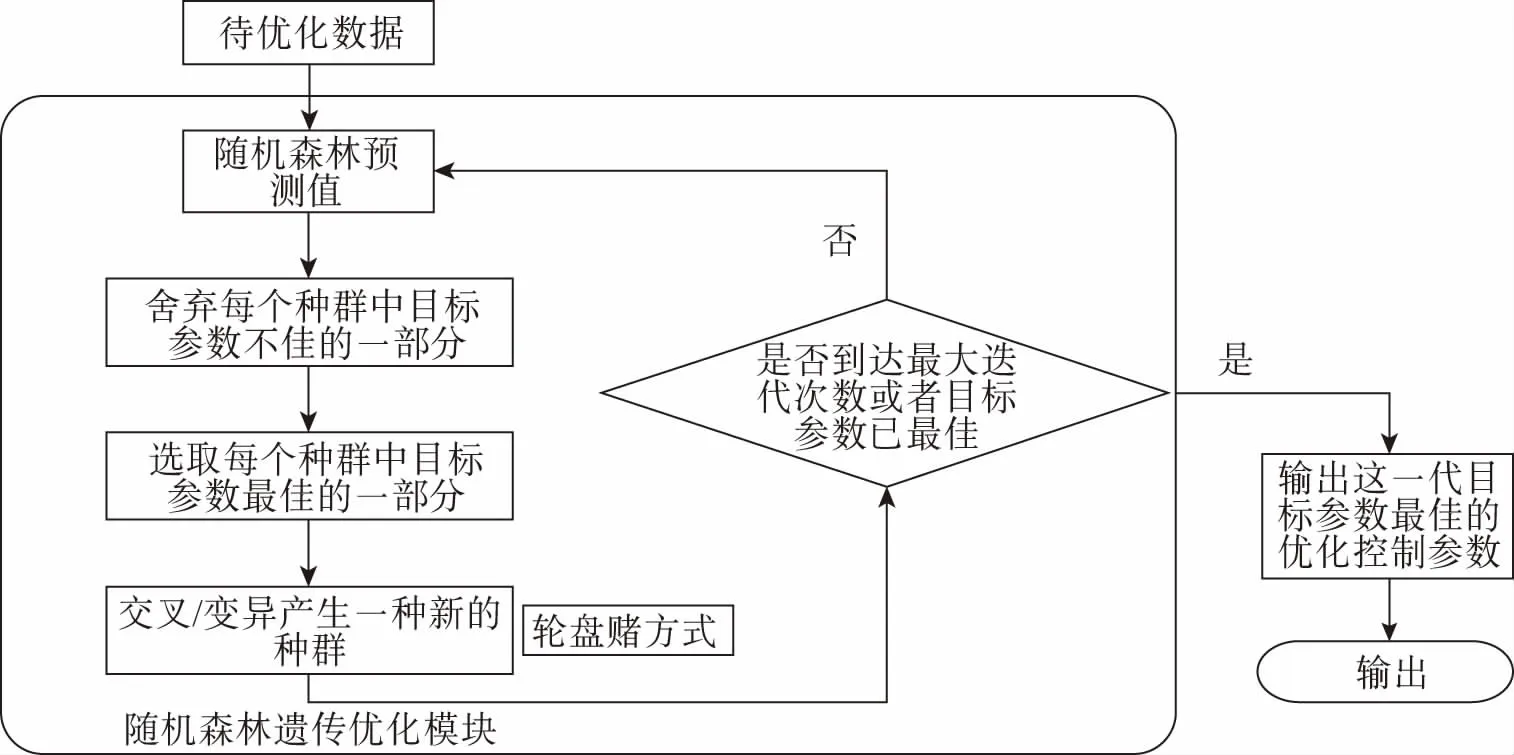
图2 基于随机森林的遗传算法流程
4.4 优化控制策略的优化效果
通过历史数据构建机组供电煤耗与相关参数的随机森林回归模型、基于凝聚层次聚类的工况划分模型,以及基于遗传算法构建每个工况的优化控制策略数据库。完整的流程如图1所示,优化控制策略数据库结构示例如表3所示,其中优化控制参数a、b、c为遗传算法对机组供电煤耗值优化后得到的数值。
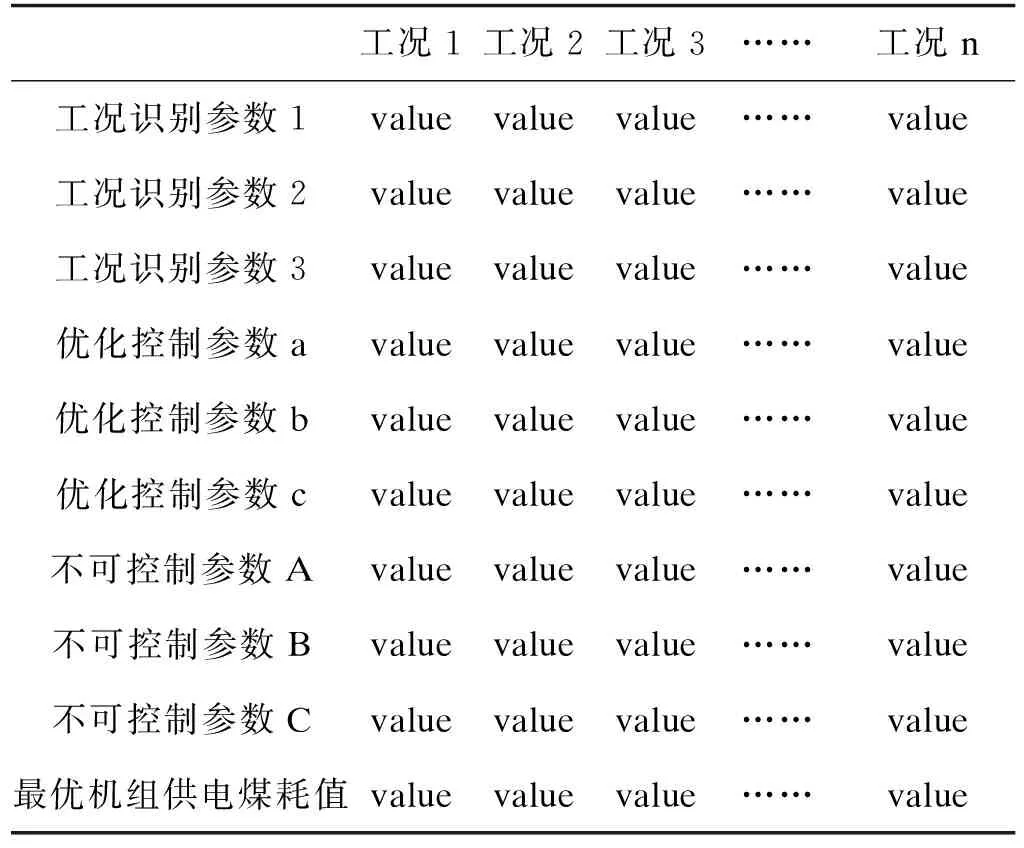
表3 最优控制策略数据库结构示例
按照上述方式,将预先拟定的主蒸汽温度、再热蒸汽温度、再热器减温水流量补偿、凝汽器真空平均值、平均排烟温度、空预器平均出口氧量等6个参数作为优化控制参数,机组供电煤耗作为目标参数,在同种工况下进行优化控制策略搜索,依据最优优化控制策略观察历史上4个时刻优化机组供电煤耗的效果,可以看出4个时刻的机组供电煤耗的优化值均小于实际值,按照搜索到的优化控制策略进行调整能起到减少机组供电煤耗的效果。
5 结束语
基于随机森林回归和遗传算法,通过实际数据测试可知优化得到的火电机组供电煤耗优化策略能够有效地降低机组供电煤耗,越低的机组供电煤耗意味着更高的煤炭利用率,对于提高电厂收益具有重要意义。通过凝聚层次聚类方法可高效实现历史数据工况划分与实时数据工况匹配,同时获取每个工况类型下的最优优化控制策略。本文以47个关联参数作为随机森林回归模型变量,得到的回归模型对供电煤耗的预测平均误差在2.4%以下,其预测精度较高,结合实际生产运行经验来优化随机森林预测模型的自变量参数,随机森林回归算法预期效果会更佳。基于随机森林回归的火电机组供电煤耗遗传优化模型依赖于火电机组供电煤耗训练数据的准确性,当火电机组供电煤耗历史数据计算不准确时,本方法将不能构建准确反映供电煤耗参数与其关联参数的回归模型。
