一种面向边缘计算的可扩展网络I/O框架
2021-04-17宋平毕立波
宋平 毕立波
(中国信息通信研究院技术与标准研究所,北京 100191)
0 引言
边缘计算在网络边缘提供了一种去中心化的计算和存储方法。与传统的云计算相比,边缘计算可以在边缘设备上分析、处理和使用采集的数据信息,无需将数据完全上传到远端集中式服务器上进行处理,从而满足低时延、大带宽和海量接入的需求。边缘计算可以广泛应用于IoT、云游戏、实时音视频分析、AR/VR等多种新兴应用场景。2016年,欧洲电信标准化协会(ETSI)提出“多接入边缘计算(Multi-access Edge Computing,MEC)”,并将其定义为一种具备多种类型接入能力,能在网络边缘侧提供IT服务环境和云计算能力的系统[1]。3GPP标准组织已将MEC作为网络架构的重要组成之一纳入5G标准[2]。
部署在网络边缘的边缘节点为海量边缘用户提供种类丰富的边缘应用。在该场景下,边缘应用需要充分利用边缘计算的计算、存储和网络资源提供边缘服务。边缘应用将同时执行计算和网络输入和输出(Input and Outpput, I/O)过程,处理海量边缘用户的请求。因此,边缘应用针对边缘用户请求的处理效率,是决定整个边缘计算系统能否满足低延时和海量接入需求的关键,而并发网络I/O是边缘应用重要的组成部分,其效率对边缘计算系统整体性能有着重要的影响。为了更及时地响应数量更多的边缘用户,需要具有良好可扩展性的支持高并发的网络I/O模型。
传统的并发网络I/O模型包含多线程模型和事件驱动模型两种,在实际应用中现有解决方案大多使用事件驱动混合模型(Event-Driven Hybrid Model)。一些方案[3-6]扩展了单线程的事件驱动模型,在多核环境下利用不同的线程运行独立的事件循环;另一些解决方案[7-9]在基于事件的系统上,为每个网络链接提供轻量级的线状结构进行处理,在处理过程中隐式地控制轻量级线程的执行状态;第三种混合模型为多阶段的事件驱动模型[10-12],其处理过程由一系列的阶段组成,不同的阶段依靠事件队列进行通信。每个阶段具有独立的处理逻辑,在阶段内部使用抢占式的多线程并行处理事件队列中的事件。不同的事件驱动混合模型在不同的应用场景下各具优势。当前高性能的边缘节点通常可以具有数十个处理器核,然而由于数据冲突和负载不均衡等原因,当前的事件驱动混合模型的处理性能可扩展性存在瓶颈。
本文提出一种面向边缘计算的可扩展网络I/O处理方法,解决在边缘计算应用场景下事件驱动混合模型的可扩展性问题。该方法在事件驱动混合模型的基础上,利用更多的线程监听网络异步事件,使用开销较低的任务窃取方法均衡线程之间的负载,并且根据工作线程的负载情况指导链接的分配,进一步提高模型执行效率。另外,针对事件处理过程中产生的数据竞争问题,本方法使用共享数据标记的方式,将事件与特定的共享数据的处理方法进行关联,实现了事件处理过程中针对共享数据操作的提取,并且针对这些共享数据,可以使用额外的状态线程进行更细粒度的数据级并行,防止事件处理中的数据冲突阻塞网络I/O。
1 边缘计算基本框架
ETSI MEC工作组定义了多接入边缘计算,并提出了如图1所示多接入边缘计算的基本框架[13]。该框架将边缘计算从宏观的角度划分为系统层、主机层和网络层。其中,系统层主要负责边缘计算系统的全局管理和编排;主机层主要负责虚拟基础设施管理、边缘计算应用管理和边缘计算平台管理等;网络层主要提供无线网络、本地网络和其他外部网络接入,使得海量边缘用户可以通过多种网络协议接入边缘计算系统。
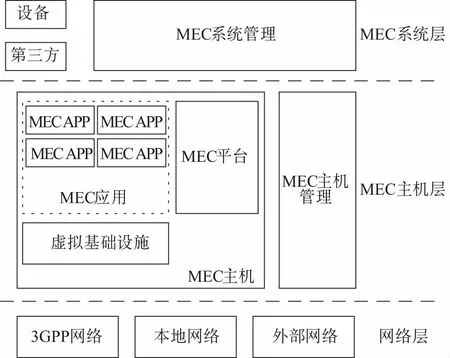
图1 多接入边缘计算基础框架
由图1可见,MEC主机包含了虚拟基础设施、MEC平台和MEC应用三部分。丰富的MEC应用将运行于虚拟基础设施上,为边缘用户提供不同的边缘服务。虚拟基础设施资源为MEC应用提供了虚拟计算资源、虚拟存储资源和虚拟网络资源。MEC应用之间依靠MEC平台上安装的转发规格进行流量转发。
当海量用户通过网络层接入边缘计算系统后,主要由运行在MEC主机上的不同边缘应用处理边缘用户请求。当前,边缘计算解决方案主要通过虚拟机或容器的方式运行边缘应用,实现不同边缘应用之间的资源隔离。因此,边缘应用利用虚拟基础设施提供的虚拟资源,针对海量边缘用户请求的处理效率,决定了整个边缘计算系统能够满足低延时和海量接入的需求。
2 事件驱动混合模型
边缘应用在处理海量边缘用户请求时,需要综合考虑计算和网络I/O,提高应用的执行效率。在网络I/O方面,基于事件驱动的混合模型主要强调利用事件编程的优势,使用多个线程或进程并行地执行不同的事件循环(Event Loop),典型的方式是一个线程或进程对应一个事件循环,处理异步的网络I/O事件和应用级(Application-Level)事件。当边缘应用使用更多的计算资源时,由于数据竞争和负载不均衡,将导致事件混合驱动的可扩展性问题。
2.1 数据竞争问题
当访问共享数据时,当前的多线程模型主要通过锁或原子操作等方式保证数据一致性。然而这些同步方式容易导致多个线程发生数据竞争[14]。
Libasync-Smp[5]使用事件染色方法对一个事件类型相关的所有事件回调函数标记不同的颜色,可解决数据竞争问题,对于具有相同颜色的事件回调函数使用同一个线程顺序执行,而对于具有不同颜色的事件回调函数则使用不同的线程并行执行,从而避免不同事件处理过程中的数据冲突。然而,一个事件回调函数内部可能存在多个共享数据操作,从而导致事件回调函数并行处理的并行度受限。
在Mace[15]提出的原子事件模型中,每个事件通过锁机制保证该事件被原子地独立地执行,并且使用一个线程处理网络I/O。该模型扩展性有限,边缘应用难以利用更多资源处理海量用户请求。为了解决该问题,InContext[4]通过对事件回调函数(Event Handler)标记原子性,实现了更细粒度的并行。与事件染色方法的问题类似,被标记为“全局”的事件处理方法在执行过程中可能包含对多个共享数据的处理,从而限制了整体事件处理过程的可并行度。
2.2 负载不均衡问题
在事件驱动混合模型中,每个线程处理不同的边缘用户链接需要处理异步网络I/O事件和对应触发的应用事件,将导致不同边缘用户链接具有差别较大的处理时延。例如,在文件服务应用中,用户请求不同大小的文件,将导致不同的用户处理开销[16]。因此,为了提高边缘应用的处理效率,需要均衡应用级事件处理负载和异步网络I/O事件处理负载。
Beacon[3]使用了轮询的方式为每个线程平均分配交换机链接,实现网络I/O负载均衡。然而,由于该方式并未考虑应用级事件处理的复杂度问题,导致负载不均衡问题依然存在。
Libasync-Smp和Mely使用基于时间染色的任务窃取算法均衡网络I/O负载和网络应用负载。在该方法中,任务窃取的粒度为具有相同颜色的事件回调函数,具有相同颜色的事件回调函数无法被并行执行,从而导致任务窃取过程具有较大的开销。虽然Mely[6]使用多种窃取方式提高被窃取任务的执行效率,但该任务窃取执行过程依然非常复杂,较大的窃取开销将降低甚至抵消平衡负载所带来的性能提升。另外,Libasync-smp和Mely使用一个Select/Epoll 实例处理异步I/O方式,容易被其他应用级事件阻塞,且性能较低[9]。
3 面向边缘计算的可扩展网络I/O模型
本文面向边缘计算场景,重点解决当前网络I/O模型存在的数据冲突和负载不均衡问题,提出一种可扩展的网络I/O模型。通过该模型,边缘应用可以充分利用边缘节点的物理资源,满足海量边缘用户低时延的处理需求。
如图2所示,在本文提出的可扩展I/O模型中,工作线程可以分为链接线程、I/O线程以及状态线程3类。不同类型的线程之间协同工作,对不同的事件进行并行处理。其中,处理的事件类型包括网络I/O事件和上层的边缘应用事件,每个事件的处理逻辑由一系列的事件回调函数组成。在负责执行事件处理逻辑的不同阶段,I/O线程和状态线程执行不同的事件回调函数,具体分工如下。
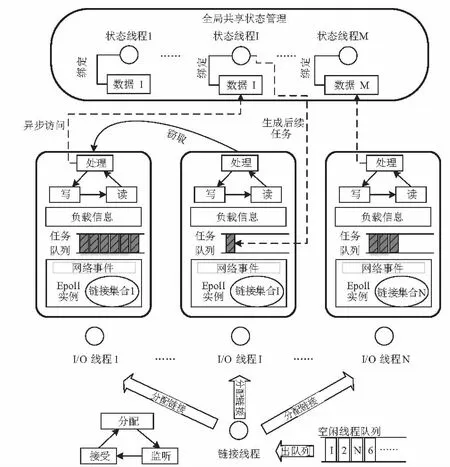
图2 面向边缘计算的可扩展网络I/O模型
(1)链接线程:在本文提出的可扩展I/O该模型中具有唯一的链接线程,该线程执行一个循环(Loop),实时地对到达的链接请求进行监听;当链接建立后,根据当前I/O线程的负载情况分配该链接。
(2)I/O 线程:I/O线程负责监听、收发由链接线程(Connection Thread)分配的不同网络链接消息,并且执行部分事件处理逻辑。每个I/O 线程绑定一个本地事件队列,队列中保存着已就绪的异步网络事件和上层应用事件。另外,每个I/O线程通过一个特定的Epoll实例,对其所属的网络链接的消息进行异步收发。在处理本地事件时,I/O 线程执行一个循环,监听链接的异步事件,对到达的网络消息进行异步非阻塞的读写并且对触发的事件进行处理。在事件处理过程中,当需要处理特定的共享数据时,I/O线程可以将该事件发送给处理该共享数据的状态线程。与此同时,每个I/O线程负责对自身工作负载情况进行统计。
(3)状态线程:状态线程仅负责对事件处理逻辑中全局共享数据的操作过程进行并行处理。其中,每个状态线程与特定的共享数据进行关联,顺序执行该共享数据的所有操作。对于不同的共享数据,则由不同的状态线程进行并行处理。当执行完某个事件的共享数据操作过程后,将该事件返回给原来的I/O线程或者其他状态线程继续执行。
在图2所示面向边缘计算的可扩展I/O模型基础上,本文分别提出了共享数据标记方法以及一种低开销的任务窃取方法,以解决当前网络I/O模型的数据冲突和负载不均衡问题。
3.1 共享数据标记方法
为了避免在事件处理过程中的数据竞争,本文将事件处理逻辑划分为共享数据操作过程和非共享数据操作过程,其中在一个特定共享数据的操作过程中不能包含对其他共享数据的操作。如图3所示,对于非共享数据操作过程,I/O线程可以高效地非阻塞地执行。对于可能产生阻塞的共享数据操作过程,I/O线程将该事件处理过程交由状态线程进行处理。为了确保不会被数据竞争阻塞,I/O线程不会等待状态线程的执行,而将继续处理本地队列中的其他事件。当状态线程执行完成后,会根据下一个事件处理过程的类型,将事件处理过程交给特定的线程继续执行。
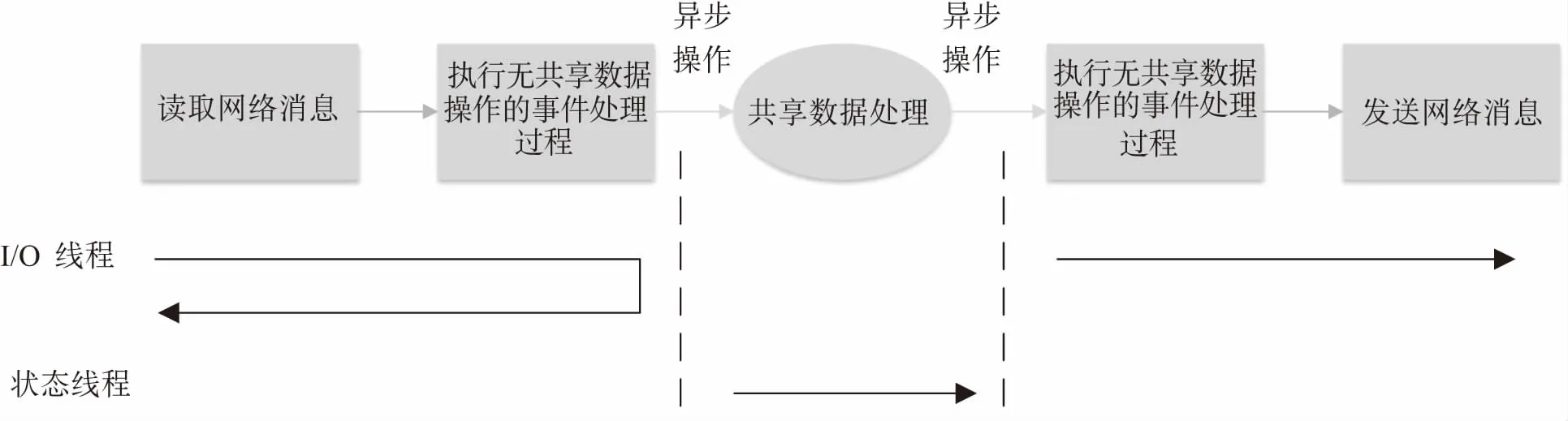
图3 异步共享数据处理过程
为了实现上述过程,本文提出了一种简单的共享数据标记方法。该方法通过将事件回调函数与特定的共享数据进行关联,实现对链接处理过程中共享数据的操作进行提取。如果一个事件回调函数与一个特定的共享数据相互关联,则表示该事件回调函数在执行过程中除操作该共享数据外,不会对其他共享数据进行操作。关联共享数据的事件回调函数将由指定的状态线程执行。如果事件回调函数没有和任何共享数据进行关联,则表示该事件回调函数在执行过程中不会操作任何共享数据,可以直接由I/O线程执行。
由于增加了线程间的通信时延,I/O线程与状态线程协作处理共享数据的方式并不适用于所有的共享数据处理。例如,当对一个共享数据操作的执行时间很短,甚至小于线程间的通信时延时,多个I/O线程互斥地操作共享数据的方式具有更高的执行效率。而共享数据标记的方式依然适用于这种互斥的访问方式。当I/O线程执行与共享数据关联的事件回调函数时,首先判断其执行的方式,对于可能产生较长时间阻塞的事件回调函数,通过异步的方式将其交由状态线程处理;反之,通过内部锁机制同步地执行该事件回调函数。
区别于事件染色方法和原子事件模型,共享数据标记方法是从共享数据的角度,对不同的事件回调函数进行标记。因此,在整体事件处理过程中,共享数据标记方法可以使整个事件处理过程具有更高的并行度。
3.2 低开销任务窃取方法
由于链接请求次数、事件处理逻辑的复杂度等原因,导致处理不同的边缘用户链接所需开销不同。因此,在执行过程中,工作线程间可能发生负载不均衡的现象,影响整体处理效率。例如,SFS文件服务应用中不同用户需求的文件大小不同,使得网络链接传输的数据量存在差异[16];SDN应用中不同的流可能具有不同QoS需求,其路由过程具有不同的复杂度。为了均衡线程间的负载,本文从两个方面动态地调节I/O线程之间的负载。
一方面,本文使用了具有较低开销、较高执行效率的任务窃取算法,动态地均衡I/O线程之间的负载。与Libasync-Smp及Mely提及的工作线程不同,面向边缘计算的可扩展I/O模型中的每个I/O线程不仅需要执行本地事件队列中的事件,还需要从底层操作系统获取该线程所属的网络链接的异步事件。I/O线程会优先执行事件队列中的事件,然后再尝试获取网络异步事件。因此,面向边缘计算的可扩展I/O模型中I/O线程进行任务窃取的触发条件为I/O线程的本地事件队列为空,且无异步的网络事件。
在选择被窃取线程后,窃取线程首先尝试获取被窃取线程所负责链接的异步网络事件,如果有异步网络事件则将这些事件放入受害者线程的本地事件队列,并且执行K个事件(K在模型初始化时设置),否则尝试获取并执行被窃取线程的本地事件队列中的事件(最多K个)。如果本地队列为空,则窃取失败。
与基于事件染色的任务窃取算法不同,低开销任务窃取方法在窃取任务时,I/O线程无需考虑事件回调函数之间的数据冲突问题,具有较低的窃取开销。与此同时,该方法还可以帮助负载较重的线程获取异步网络事件,服务更多的网络链接。
另一方面,与现有模型所使用的轮询方式不同,面向边缘计算的可扩展I/O模型在分配网络链接时,链接分配线程优先从全局的空闲线程队列中选择负载较轻的线程,为其分配链接。该方式可以使网络链接更加及时地得到响应。在面向边缘计算的可扩展I/O模型初始化阶段,全局空闲线程队列中保存所有的I/O线程号。当新的链接到达时,从该队列头部取出一个线程号进行分配。在面向边缘计算的可扩展I/O模型执行过程中,负载较轻的I/O线程会动态地将自己的线程号放入全局空闲线程队列的尾部。如果全局空闲线程队列为空,则使用轮询的方式分配网络链接。
面向边缘计算的可扩展I/O模型中每个I/O线程的任务窃取次数反映了每个I/O线程的负载情况。由于网络应用中每个任务的执行时间通常很短,因此,任务个数可以在一定程度上反映任务量。线程在进行任务窃取时,会统计已执行的任务数量(窃取的任务数NSteal、所属链接的任务数NConn及当前剩余任务数量NR算一个综合的工作负载W(0 (1) 当链接分配线程分配一个新链接给I/O线程时,将该线程的NSteal设置为0。因此,NSteal+NConn为从分配新的链接开始到每次任务窃取发生时,该I/O线程已处理任务的总个数。每次任务窃取前后,剩余任务数量NR发生变化。NSteal+NConn+NR表示从分配新的链接开始到每次任务窃取结束的总任务个数。W表示NSteal任务个数在总任务个数中占有的比例。 Web服务器应用可以部署在边缘节点,为边缘用户提供丰富的Web服务。本章通过Web服务器应用验证可扩展网路I/O模型的执行效率。本文利用网络I/O模型实现一个HTTP服务器,该程序通过频繁地创建网络链接服务大量的客户,针对每个请求执行一个不存在数据竞争的事件处理过程。 Web服务器应用运行在一台24核32 G内存的四路Intel Xeon服务器上,每路服务器有一个Intel(R) Xeon(R) E7-4087处理器,每个处理器包含6个处理器核,主频为1.87 GHz。此外,该服务器还有一个双端口Intel 10G网卡。该服务器上运行的系统软件包括:Linux系统RedHat 6.2、Linux内核版本Linux2.6.32、Linux 系统gcc编译器版本gcc-4.4.7。本文使用两台普通PC机作为测试机,每个测试机具有1个10 Gbit/s端口。测试机和服务器通过一台华为交换机连接。 为了验证Web服务器应用可以更好地利用服务器物理资源,本文针对已缓存负载的Web服务器进行测试。测试机端使用Httperf 工具进行测试[17]。Httperf是一个HTPP服务器性能测试工具,用于模拟压力负载。 本章首先针对100 KB的小文件进行I/O可扩展性测试。在服务器端,本文分别运行了3个运行时:使用任务窃取的面向边缘计算的可扩展I/O模型、不使用任务窃取的面向边缘计算的可扩展I/O模型以及使用任务窃取的Mely。每个工作线程与CPU绑定,通过调整线程个数,测试模型运行时的吞吐量。为了测试任务窃取的有效性,本文手动调整面向边缘计算的可扩展I/O模型中不同线程的负载,分配链接时按照2:1的比例为不同的线程分配链接。在测试端,两台测试机运行4个Httperf,每个Httperf模拟3万个并发用户请求,计算每秒服务的请求个数,每个用户在链接关闭前发送1个请求。针对小文件的网络I/O可扩展性测试结果如图4所示。 图4 针对小文件的网络I/O可扩展性测试结果 由图4可见,当线程个数为1时,使用任务窃取和不使用任务窃取的面向边缘计算的可扩展I/O模型具有相似的处理效率,并且处理效率略低于Mely模型。但是,随着线程个数的增长,相比于不使用任务窃取的面向边缘计算的可扩展I/O模型和Mely模型,使用任务窃取的面向边缘计算的可扩展I/O模型具有更高的处理效率。 此外,本文针对大小不同的文件集进行了测试。这些文件集根据SPECweb2009 Benchmark生成,共300 MB,其文件大小符合Zipf分布[18]。本文还在测试机上运行了Httperf,观察、对比了不同数量的并发用户下不同服务器的带宽占用情况。因每个用户在一个链接结束前产生10次请求,本文按每次测试持续60 s的频率测量了服务器在稳定状态下的吞吐带宽情况。在服务器端,本文使用了12个线程,分别运行了Mely、Apache[19]以及使用任务窃取和不使用任务窃取的面向边缘计算的可扩展I/O模型。 图5展示了不同数量的并发用户下的测试结果。可以看出,随着用户数量的增长,面向边缘计算的可扩展I/O模型的处理性能持续增长,具有更高的可扩展性。虽然Apache模型下增长的速度比本模型快,但是其很快就达到了性能峰值;Mely模型下的处理性能在整体上要低于面向边缘计算的可扩展I/O模型和Mely模型。使用任务窃取的面向边缘计算的可扩展I/O模型与不使用任务窃取的面向边缘计算的可扩展I/O模型具有相似的处理性能,主要原因是这二者都采用平均分配链接地的方式,线程间负载非常均衡,使得任务窃取影响较小。 图5 针对大文件的并发用户测试结果 本文首先介绍了边缘计算的基础架构,然后重点分析了在边缘计算场景下,网络I/O模型存在的可扩展性问题,并提出了面向边缘计算的可扩展网络I/O模型,最后通过Web应用试验,验证了本文提出的网路I/O模型具有良好的可扩展性。利用该模型,边缘应用可以更好地利用边缘节点物理资源,为海量边缘用户提供低时延的服务。4 试验


5 结束语
