基于雷达与图像数据融合的人体目标检测方法
2021-04-17李文平郑利彪汤晓龙
李文平,袁 强,陈 璐,郑利彪,汤晓龙
(安徽南瑞继远电网技术有限公司,合肥230088)
引 言
目标检测作为计算机视觉的基础任务之一,其主要目的是在点云或图像序列中精确得出各种目标的类别和位置信息[1-2]。目前,基于深度学习的二维目标检测工作已经取得了显著进展,但由于二维目标检测对真实场景的描述度不够,缺乏目标尺寸、姿态等物理参数信息,在实际应用中受到一定限制,因此结合深度信息的三维目标检测任务引起了广大学者及研究机构的关注[3-4]。基于深度学习的三维目标检测方法具有智能分析、自主检测及泛化能力强等特点[5],已逐渐应用于智能安防、自动驾驶和医疗等诸多领域[6]。
目前,在基于雷达点云与图像数据融合的三维目标检测的研究中,清华大学和百度公司的Chen等[7]提出了MV3D模型,加拿大滑铁卢大学Ku等[8]提出了AVOD模型,瑞典林雪平大学的Gustafsson等[9]提出了A3DODWTDA模型,美国斯坦福大学和Nuro公司的Qi等[10]提出了F-PointNet模型,哈尔滨工业大学的Cao等[11]对F-PointNet模型进行了改进,提出了MVFP模型。其中,MV3D模型融合了视觉和雷达点云信息,其中的三维候选网络将点云表达成具有三维信息的正视图和鸟瞰图,结合图像初步卷积处理后,把特征和候选区域进行融合,然后输出最终的目标边界框。AVOD模型对MV3D模型进行了改进,以雷达点云鸟瞰图和图像数据作为输入,采用特征金字塔网络(Feature Pyramid network,FPN)架构作为主干网络,有利于小目标的检测,提高了整体检测精度。A3DODWTDA网络首先对图像进行二维目标检测,然后将检测到的二维目标投影到三维空间中得到目标可能存在的区域,进一步对目标点云进行分割,最后通过回归得到目标的三维检测结果。F-PointNet模型舍弃了图像与雷达点云数据的融合操作,通过从图像到点云的待检测物体定位过程,实现了逐维(2D到3D)的精准定位,并且该网络直接处理点云数据,避免了点云映射过程中某一维度信息的损失,能够学习更全面的空间几何信息,在小目标的检测上有较好的效果;万鹏[12]在该网络模型的基础上进行了优化,使用不同的参数初始化、L2正则化和修改卷积核数的方法对模型进行测试,进一步提升了模型的目标检测精度。为了进一步降低F-PointNet模型的漏检率,MVFP网络添加了辅助的鸟瞰图检测部分,实现多视角的F-PointNet模型。通过F-PointNet模型获得初始目标检测结果,同时将雷达点云编码到鸟瞰图的特征图中,并据此预测二维边界框,在漏检判断中采用交并比(Intersection over union,IoU)作为F-PointNet初始目标检测结果与鸟瞰图映射预测结果的匹配准则,将鸟瞰图映射中属于漏检目标的二维边界框投影到F-PointNet通道中,直到鸟瞰图映射中的所有目标在F-PointNet检测结果集中找到匹配的检测结果,有效提高了网络在复杂环境中的目标检测精度。然而,上述网络模型均需要预先选取目标存在概率较高的候选框,然后再进行目标分类和边界框回归,属于两阶段神经网络模型。由于该类型网络模型的结构和运算过程较为复杂,使得运算速度受到限制,难以满足实时性要求较高的应用场景。
针对以上问题,本文研究并设计了一种基于改进型RetinaNet单阶段卷积神经网络的三维人体目标实时检测方法。该网络结构是在RetinaNet这一单阶段二维目标检测网络结构基础上进行改进:将主干网络与特征金字塔网络两条路径相结合,用于点云和图像的特征提取;设置一系列三维锚框并将其投影到特征图上,将投影的二维锚框裁剪为同样大小并进行融合;设计了适合三维目标检测的功能网络以输出三维边界框和类别信息。上述改进可将RetinaNet扩展为三维多传感器融合检测网络,从而提高三维人体目标检测网络的检测性能,同时保持在运算速度方面的优势。
1 改进型RetinaNet网络架构设计
RetinaNet模型主要由FPN结构[13]和聚焦损失函数构成,以VGG、ResNet等网络作为主干网络有效提取特征,利用FPN网络对提取的多尺度特征进行强化,并将所获得的表达能力更强、包含多尺度目标区域信息的特征图输入到两个子网络中完成目标分类和边界框回归任务。RetinaNet网络的损失函数由L1损失函数和聚焦损失函数组成,前者用于计算边界框回归误差,后者用于计算分类误差[14]。聚焦损失函数的引入可有效解决正样本和负样本之间的不平衡问题,提高目标检测的精度[15-16]。为了将RetinaNet扩展到三维空间,本文主要做了以下改进:
(1)主干网络包括两条路径的子网络,分别用于点云和图像的特征提取,每条路径采用Resnet网络和FPN结构。
(2)每个锚框由长、宽、高和中心点坐标的六维数组表示,同时采用聚类方法设置锚框的大小。
(3)通过投影方法,利用三维锚框对点云和图像的特征图进行感兴趣区域(Region of interest,ROI)池化和融合。
(4)损失函数中目标分类误差采用聚焦损失函数计算,边界框偏移量回归误差采用L1损失计算,此外,增加了边界框方位回归误差。
本文所设计的三维目标检测网络结构如图1所示,主要分为主干网络和功能网络。利用主干网络提取点云和图像的特征图,然后将两者的特征图经过ROI池化和融合输入到功能网络,输出目标的分类和边界框回归信息。
2 基于改进型RetinaNet的三维目标检测流程
2.1 输入数据预处理
本文基于KITTI数据集[17]进行网络训练和测试,该数据集包含大量带有标注信息的图像和点云数据,需要对其进行预处理再输入到网络中。本文采用KITTI数据集中其中一侧彩色相机捕捉的图像,同时采用数据集中Velodyne 64线雷达采集的点云数据,以提供准确的目标定位信息。数据集以相机数据采集方向为X轴,向上方向为Y轴,根据右手坐标系原则确定Z轴方向。为了利用深度神经网络来处理点云,本文将点云投影为鸟瞰图(Bird’s-eye view,BEV)以避免遮挡问题,并且可以用二维目标检测网络作为主干网络进行处理。为了将点云转换为鸟瞰图,本文在X轴和Z轴方向上将点云划分为0.1 m×0.1 m的网格,将Y轴0~3 m之间的点云等分为6层,对每一个单元格,保存高度特征为该单元格的最高点的高度信息,另外设置2个通道记录点云的强度和密度信息,因此点云鸟瞰图被编码为8个通道的特征。

图1 改进型RetinaNet网络架构Fig.1 Improved RetinaNet network architecture
2.2 基于主干网络的特征提取
本文在主干网络设计中采用Resnet网络结构[18],利用主干网络进行特征提取。通过将卷积层和池化层逐层叠加,不断增加每层的通道数,以减小特征图的大小。大多数网络只输出最后一层的特征图以用于后续的分类和检测任务,这往往会导致小目标占据较少的像素,不利于对其进行检测。采用FPN结构可以有效地解决这一问题。如图2所示,FPN结构主要包括3个基本过程:自下向上的通路,即自下向上的不同维度特征生成;自上向下的通路,即自上向下的特征补充增强;主干网络层特征与最终输出的各维度特征之间关联表达。改进型RetinaNet在特征金字塔的各个层上进行ROI池化操作,然后将不同尺寸的输出结果输入到功能网络中,从而提高检测效果。
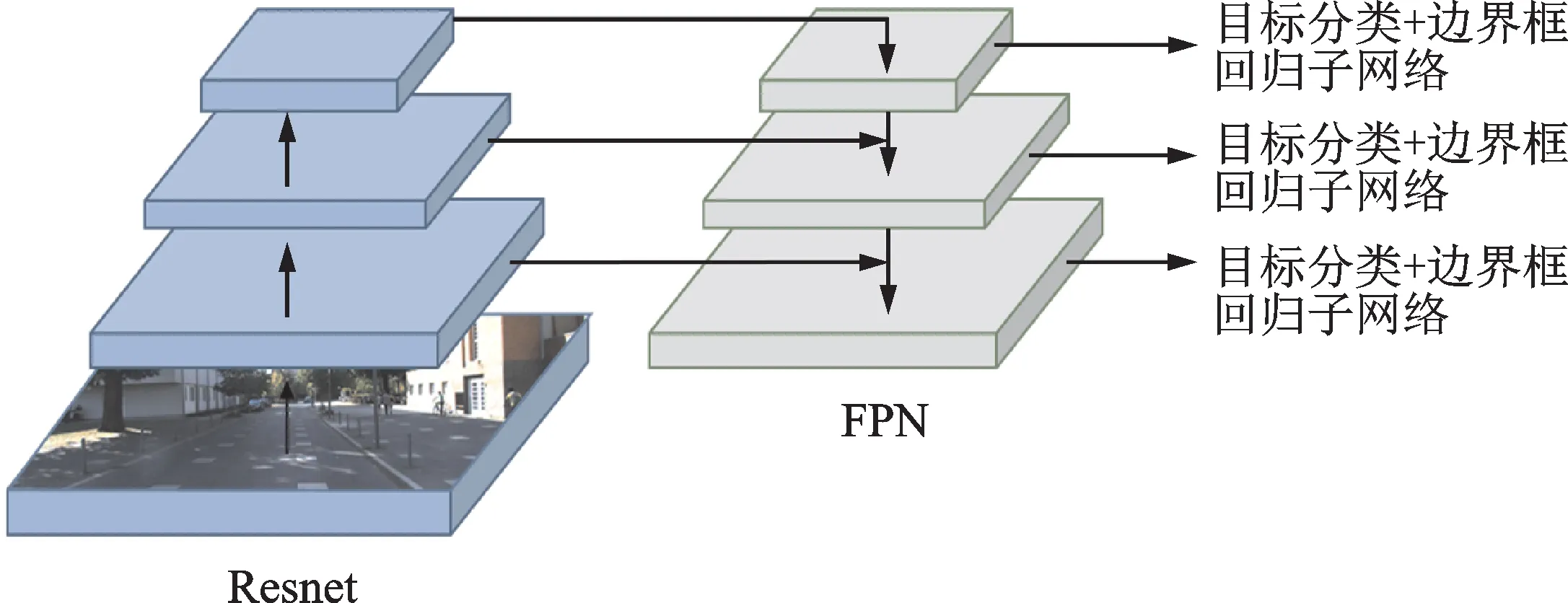
图2 FPN基本架构Fig.2 FPN basic architecture
2.3 ROI池化和多传感器信息融合
为了提高边界框位置回归的计算效率,本文设置了一定数量的锚框(预先设定的、按一定规则密集排列的边界框),从而通过锚框偏移量确定目标边界框。对于主干网络输出的特征图,首先将三维锚框投影到其中,然后根据投影结果对特征图进行裁剪,得到大量大小相同的特征图二维锚框,从而进一步完成对点云鸟瞰图和图像特征图的ROI池化操作,最后对点云鸟瞰图和图像特征图计算均值进行特征融合。
由于锚框通常不能很好地包围目标,所以需要通过神经网络进行回归,以帮助网络输出更为准确的边界框。在2.4节中将进一步论述将这些融合特征图输入到功能网络中进行最终分类和回归的过程。
2.3.1 三维锚框设置
本文以KITTI数据集中的行人为检测目标,考虑到检测目标的尺寸差异不大,为了降低不必要的计算复杂度,本文设置了3种尺寸的锚框,锚框由其中心坐标(x,y,z)和长度,宽度、高度(l,w,h)六个参数表示。其中,x和y值由点云鸟瞰图中以0.5 m的间隔通过均匀采样获得,z值由传感器距离地面的高度和物体高度来计算。锚框的大小通过对数据集中检测目标的标签信息进行聚类来确定。由于雷达点云稀疏会导致许多空锚,对于不包含点云的空锚,根据锚框中点云的总和是否为零来决定是否将其剔除。
2.3.2 ROI池化和融合
为了实现雷达点云和图像的特征融合,需要对特征图进行ROI池化。因此,本文将三维锚框投影到点云鸟瞰图和图像的特征图上,然后对其进行裁剪和尺寸调整。对于三维锚框(xp,yp,zp,l,w,h),点云鸟瞰图上投影区域的左上角和右下角可以表示为(xl,left,zl,left)和(xl,right,zl,right),即

将三维锚框投影到图像特征图上的计算过程比较复杂。由于KITTI数据集有许多坐标系,如图3所示,其中点云和三维锚框在雷达坐标系Ol-XlYlZl中表示,而图像在坐标系Oi-XiYi中表示,因此有必要将三维锚框参数转换到图像坐标系下。
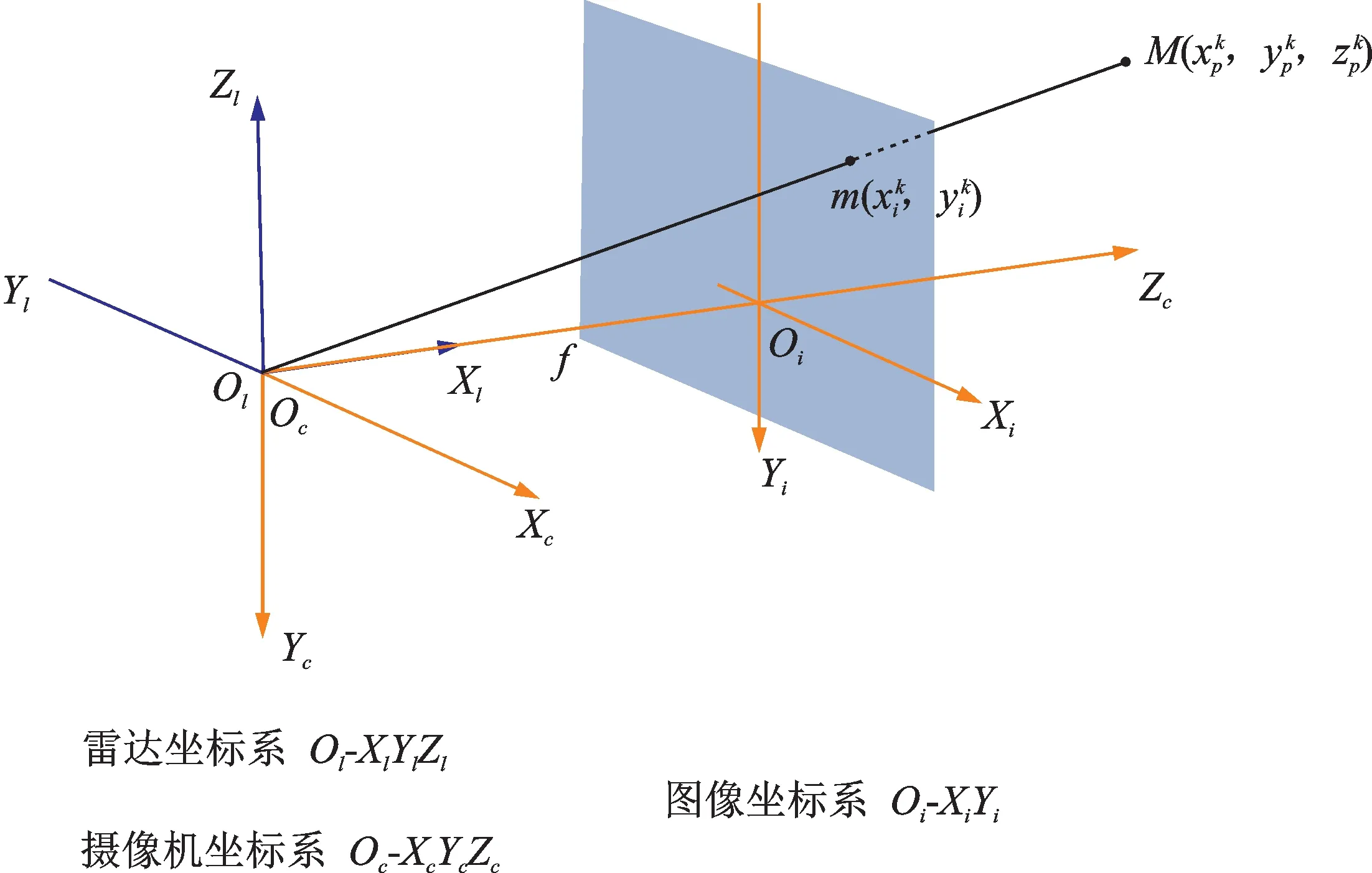
图3 多传感器坐标系Fig.3 Multi-sensor coordinate system
首先,根据锚框中心坐标、长度、宽度和高度计算出其8个顶点的坐标,k=1,…,8,然后将顶点坐标转换到图像坐标系。其中,从雷达坐标系转换到摄像机坐标系,需要乘以相应的转换矩阵。如果锚框中的顶点设置为,转换为摄像机坐标系表示为


其矩阵形式为

式中f表示摄像机的焦距。利用数学关系式(2,4)将三维锚框从雷达坐标系转换到图像坐标系,得到,k=1,…,8。考虑到遮挡效应,三维锚框的投影区域的顶点可以表示为

根据三维锚框投影区域的参数,对特征图进行裁剪,并将其大小调整为4×4,使特征图尺寸相同。采用元素平均法实现多传感器特征图的特征融合[19]。
在训练阶段,通过计算锚框与真实边界框之间的交并比,对特征融合锚框进行标记,当IoU大于阈值时记录为正样本,反之为负样本。
2.4 基于功能网络的目标检测
将特征融合锚框输入到功能网络中进行目标分类和边界框回归。最终的预测边界框通过基于具有相应偏移量的三维锚框得到,与传统的边界框直接回归方法相比,该方法不仅降低了回归的难度,而且边界框定位更准确。功能网络由3个并行的全连接层组成,分别完成分类、边界框偏移量回归和方位回归3个任务。
2.4.1 功能网络输出结果
对于N个特征融合锚框,分类信息包括目标和背景,分类网络的输出维数为2N;对于边界框偏移量回归网络,为了说明锚框和真实边界框之间的中心坐标、长度、宽度和高度的偏移量,回归结果表示为(Δxp,Δyp,Δzp,Δl,Δw,Δh),输出维数为6N。对于边界框方位回归网络,本文采用计算边界框在点云鸟瞰图中投影角向量(xor,yor)=(cosθ,sinθ)的方法,输出维数为2N。
2.4.2 损失函数设计
为衡量网络模型的三维目标检测性能,本文设计了一个多任务损失函数。用2个平滑L1函数计算边界框偏移量和方位回归的误差,用聚焦损失函数计算目标分类误差。其中,聚焦损失函数通过减小背景样本的权重,可有效解决类别分类不平衡的问题。
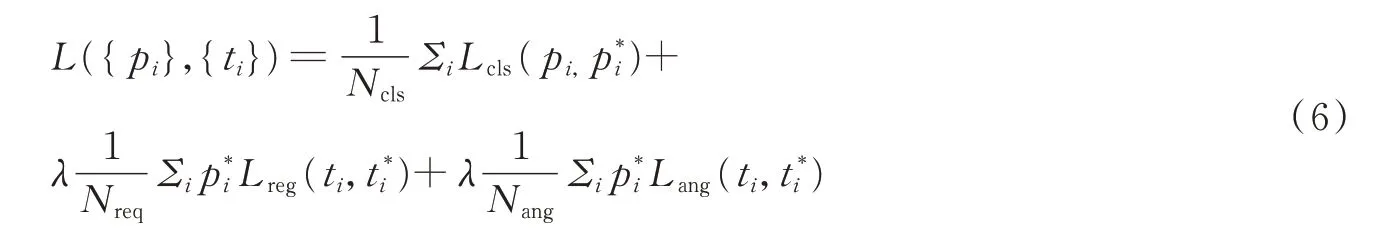
式中:i表示锚框的索引;pi表示预测目标类别的概率值;表示标注目标类别信息;正样本和负样本分别标记为1和0;ti表示边界框的预测结果;表示正样本的边界框的标注信息。等号右侧第1项Lcls表示预测类别与真实类别之间的偏差值;第2项Lreg表示预测边界框位置与真实值之间的偏差,其中表示该项仅与正样本有关,对于那些具有小于0.5的IoU记录为负样本,标记为0;第3项Lang表示边界框方位角预测值与真实值之间的偏差,其中表示该项仅与正样本有关,对于负样本标记为0。Ncls、Nreg和Nang分别对上述3项进行规范化,超参数λ用于平衡3项之间的权重。
3 人体目标检测实验及结果分析
本文在KITTI数据集上对所研究的改进型RetinaNet网络进行训练和测试,将已标注标签的7 481个样本按照3∶1的比例划分为训练集和测试集。根据边界框高度、遮挡程度和截断程度,将样本分为简单、中等、困难3个等级。深度学习计算机的CPU配置为Intel Xeon E5-2678 V3,GPU配置为2套NVIDIA GeForce RTX 2080 Ti。
图4、5显示了本文方法在测试集中的三维行人目标检测可视化结果示例。图4(a)、5(a)分别对应于2幅图像,其索引号分别为000199和000202,图像中的行人目标会根据边界框高度、遮挡程度和截断程度划分为简单、中等、困难3个等级并标注出来。图4(b)、5(b)为在上述2个样本的雷达点云数据图中表示的三维目标检测结果。其中,红色三维边界框为标注的真实边界框,白色三维边界框为本文方法的检测结果。从图中可以看出,所研究的网络对于标记为“简单”和“中等”的目标其检测效果较好,而对于标记为“困难”的目标,可能会出现检测不到的情况。
为验证本文所研究的基于雷达点云和图像数据融合的三维人体目标检测性能,开展了分别以图像(主干网络只保留图像处理分支)和雷达点云(主干网络只保留雷达点云处理分支)作为数据来源对网络进行训练和测试的对比实验。三维目标检测结果用平均精度(Average precision,AP)进行评估,其中IoU阈值设置为0.5,对比结果如表1所示。从表1可以看出,雷达点云和图像数据融合作为数据来源的目标检测AP值相比于单独以图像作为数据来源提高了8%左右,相比于单独以雷达点云作为数据来源提高了5%左右,表明将雷达点云与图像数据融合处理可以捕捉到更丰富的行人特征,从而提高三维人体目标检测的精度。
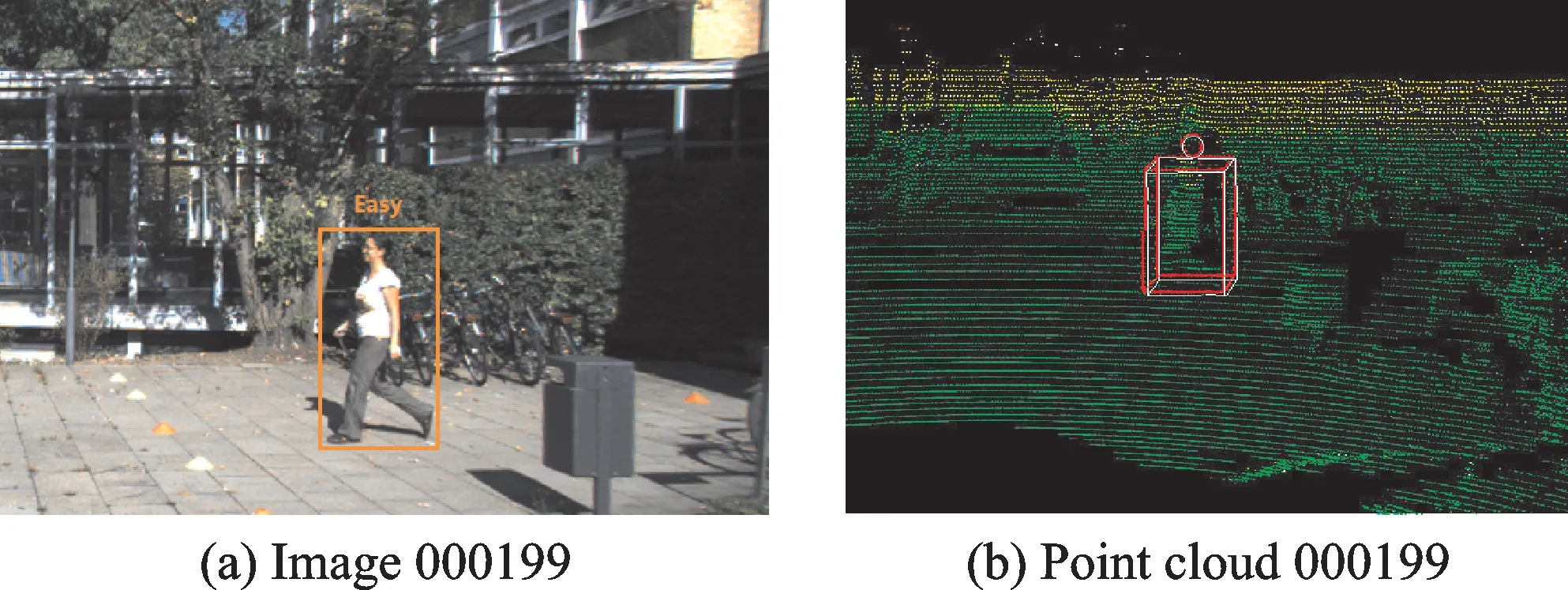
图4 图像000199三维目标检测可视化结果Fig.4 Visualization results of 3-D object detection of image 000199

图5 图像000202三维目标检测可视化结果Fig.5 Visualization results of 3-D object detection of image 000202

表1 基于不同数据来源的改进RetinaNet模型人体目标检测平均精度对比Table 1 Comparison of human target detection average precision of improved RetinaNet model based on different data sources %
采用图像与雷达点云数据融合作为数据来源,基于不同深度学习模型的三维人体目标检测结果对比如表2所示。从表2可以看出,本文方法在检测准确性和实时性方面相对于MV3D模型均有大幅提高;相较AVOD模型,本文方法在实时性方面略有提高,运行时间缩短了0.02 s,在准确性方面也有一定程度的提高,对于标记为“简单”和“中等”目标的AP值提高了5%左右;同时,本文方法在实时性方面明显优于F-PointNet和Virtual Multi-View Synthesis方法,在检测精度方面也均有一定程度的提高。综上所述,对于数据集的简单、中等、困难3个等级的行人目标检测,本文方法在检测准确性和实时性的综合性能上优于对比算法,实现了在提高检测精度的同时有效降低网络运行所消耗的时间。但是本文方法对于标记为“困难”的目标,检测精度的提升尚不明显。因此,在严重遮挡情况下提高多目标检测精度的问题,将是本文方法后续研究的重点。

表2 基于不同模型的人体目标检测结果对比Table 2 Comparison of human target detection results based on different models
4 结束语
本文研究了一种基于雷达与图像数据融合的三维人体目标实时检测方法。通过改进现有的RetinaNet,设计了用于三维目标检测的统一体系结构。由于改进型RetinaNet为单阶段卷积神经网络,不涉及区域候选网络,并且通过引入聚焦损失函数减小负样本的权重以解决正负样本不平衡的问题,有效提高了目标检测的实时性和准确性。在KITTI数据集上进行的实验表明,本文方法在行人目标检测的平均精度和时间消耗方面均优于对比算法,适用于依托巡检机器人、高清摄像头与雷达的自主巡检系统。
