基于医学影像和病历文本的甲状腺多模态语料库构建与应用
2021-04-17林玉萍郭钦钵
林玉萍,龙 红,李 彪,郭钦钵,王 娟,岳 婕
(1.西安交通大学 外国语学院,陕西 西安 710049;2.西安交通大学 软件学院,陕西 西安 710049;3.西安交通大学 生命科学与技术学院,陕西 西安 710049;4.西安交通大学第二附属医院 医用超声研究室,陕西 西安 710004;5.西安交通大学第一附属医院 儿科,陕西 西安 710061)
随着计算机技术的迅速发展,在医学领域中引入语料库以辅助治疗以及教学研究已经成为一大趋势。语料库作为一种先进的教学工具与研究方法,在语言学方面已经取得了巨大的成功[1]。例如,Romer给出了通用和专用语言语料库的使用方法,并讨论了它们在教学语境中的应用[2];Lobsang建立了一个多模态普通话-藏语语音语料库,通过元音空间比较发现了藏语元音空间比普通话元音空间更像英语[3];吕颖基于中外医学英语论文摘要语料库,探究两库高频名词的频率差异和使用差异,并试图运用语料库检索来发现英语母语使用者的语言使用范式,提出医学论文的英译策略[4]。除此以外,国内外语料库在人工智能、医学等领域仍存在巨大的研究空间。
20世纪90年代以来,我国在医学英语语料库的建设取得了一定的进步,电子病历(electronic medical record,EMR)的实体识别成为医学语料库构建的重要组成部分[5-6]。随着机器学习的发展以及其在电子病历实体识别研究的深入,较多优秀的算法能够从自由文本电子病历中高效获取到有用的关键信息,如支持向量机(support vector machine,SVM)和BERT(bidirectional encoder representations from transformers)等[7]。欧阳恩提出了一个基于双向 RNN+CRF(Bi-RNN-CRF) 的中文电子病历实体识别模型,该方法充分利用病历文本的上下文信息,探索了分词、医学词料库以及病历文档类别特征在提升系统表现方面的作用[8]。李培林等研究旨在通过探索深度学习方法来提高命名实体识别(named entity recognition,NER)和医疗关系抽取两项任务的识别率[9]。然而,这些方法只能提供文本的信息,对于大多数疾病的诊断而言,医生还需要相应的医学影像分析。除此之外,在医生进行案例分析以及教学过程中,结合文本病历与影像分析的教学模式能够帮助其更为清楚地分析病情,让医学生容易理解与接受[10]。
随着深度学习在医学影像分析中的快速发展,诸多深度学习分类模型被提出并应用于影像的分类与标注中。Bud等针对甲状腺结节数据训练了多任务深度卷积神经网络,从而决定是否应对甲状腺结节进行活检以辅助医生的临床诊断[11];Kawahara等提出了一种从未标记数据中学习特征层次的方法,通过从乳房X射线影片中提取一组手工标注的特征,并将相应特征直接或间接与乳腺癌风险相关联,从而自动进行乳房X射线风险评分[12]。然而,医学图像的特征复杂多样,传统深度学习方法的分类识别精度有限,这些都会影响多模态语料库的构建。
针对上述问题,本文提出了一种基于特征筛选的深度学习分类方法,解决了由于复杂多样的医学图像中存在冗余以及与目标相关性低的特征而导致分类精度低的问题。同时,该方法结合基于自然语言处理的文本特征提取,构建了一个医学影像和电子病历的多模态语料库。在甲状腺超声影像数据集上实验结果表明,本文所提出的方法可以实现甲状腺结节良恶性的精确分类识别。
1 基于特征筛选的深度学习分类算法
1.1 算法框架
甲状腺结节的声像图表现复杂多样,良恶性判断困难。同一患者的甲状腺结节,不同的超声医师认识迥异,报告结论差别很大,工作复杂且容易受医生个体主观性因素影响,给临床处理带来困惑[13-14]。因此,自动化的诊断识别可以缓解医生的工作强度、辅助诊断、降低患者治疗成本,一定程度上可以实现医疗资源的公平。医学图像分析中主要采用卷积神经网络,通过卷积层初步提取特征,结合池化层提取主要特征,并用全连接层将各部分特征汇总以产生分类器,最后进行预测识别。具体来说,全连接层将各部分特征汇总用于后续的分类预测,保留了所有相关特征,包括弱相关和不相关的特征,在数据集较小和特征复杂的情况下,其分类能力较差并且对噪声极为敏感,因此导致预测不准确。
针对上述问题,本文提出了一种基于特征筛选的深度学习分类算法,模型框架如图1所示。首先,在深度学习分类模型基础上,基于皮尔逊相关系数分析特征与目标类别之间的相关性,将与目标不相关或极弱相关的特征舍弃,筛选出高相关性且低冗余的特征子集,这可以简化模型的计算、提高分类能力。其次,结合该特征子集,使用经典的机器学习算法,如支持向量机SVM、决策树(decision tree,DT)和逻辑回归(logistic regression,LR)等,从而克服传统深度学习算法的缺点,实现更加精确的分类结果。

图1 基于特征筛选的深度学习分类模型框架Fig.1 Framework of deep learning classification model based on feature selection
1.2 基于深度学习的特征提取
深度学习模型通过有监督或无监督的方式学习层次化的特征,即通过卷积池化操作提取图像的特征,经过全连接层将各部分特征汇总送入分类器,最后进行预测识别。卷积神经网络利用医学影像的像素信息作为输入,最大程度上保留了输入图像的所有特征信息,这种端到端的模型学习方式取得了非常好的效果,在医学领域得到了广泛的应用。
本文首先在多个深度卷积神经网络,如Xception、ResNet、DensNet模型上使用相同的训练集数据进行训练,通过初始化的模型相关参数θ,使用前向传播算法得到预测值,深度卷积神经网络模型如图2所示。根据预测值与样本数据的真值计算损失,通过梯度下降法反向传播来更新模型权重以减少样本的损失,参数的迭代更新计算公式为

图2 深度卷积神经网络模型Fig.2 Deep convolution neural network model

(1)

本文通过梯度以及学习率来更新参数,以找到最优的参数集θ,模型在验证集上的损失不再下降或者迭代训练的次数达到设定值,则停止训练。此时的模型为最优的分类模型,使用该模型可获得输入图像的所有特征。
1.3 基于皮尔逊相关系数的特征筛选
在大数据时代下,特征选择对于模式识别来说非常重要,好的特征能够更大程度上改进模型的性能,帮助相关工作人员理解数据的特点、内部潜在的信息。由于医学影像复杂多样,借助深度学习模型从影像中提取的特征信息并非都是有用的,冗余的特征信息对模型的建立没有任何帮助,甚至有些冗余特征还会使模型的预测误差变大,因此,特征筛选显得尤为重要。特征筛选的原则是在不降低分类精度、不影响分类的分布以及特征子集稳定的基础上获取尽可能小的特征子集,以期达到预测效果最优的分类模型。
本文提出将特征筛选的方法与深度学习相结合,通过皮尔逊相关系数筛选深度学习提取的所有特征中有效的特征,在此基础上做进一步的分类识别。衡量两个变量P,Q之间的相关程度,可通过计算它们的皮尔逊相关系数ρPQ,
(2)
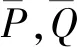
图3给出了基于皮尔逊相关系数的特征筛选流程图。对所有的n个样本数据{(X1,Y1),(X2,Y2),…,(Xn,Yn)},其中,每个样本数据Xi由m个特征(Ai1,Ai2,…,Aim)表示,Aij表示样本Xi的第j个特征。首先,计算提取的所有特征与目标之间的皮尔逊相关系数,得到所有样本的第j个特征Aj与目标类别y的皮尔逊相关系数ρ(Aj,y)。其次,按照|ρ(Aj,y)|>r进行特征筛选,r为阈值,即如果第j个特征Aj(1≤j≤m)与目标类别y的相关系数大于r,则保留此特征,反之则丢弃该特征。
通过上述筛选方法得到原始特征集的子集,即筛掉一些极弱相关和不相关的冗余特征,减少了模型的计算复杂度,为建立更加精确的分类模型奠定基础。

图3 基于皮尔逊相关系数的特征筛选Fig.3 Feature selection based on Pearson correlation coefficient
1.4 基于特征子集的分类方法
本文提出的特征筛选方法去掉了一部分弱相关以及不相关的噪声特征,增强了特征与目标之间的关联性,充分发挥数据驱动下的特征对目标类别的表示能力。常见的基于特征的机器学习分类方法有支持向量机(SVM)、决策树(DT)和逻辑回归(LR)等算法,这些算法利用该特征子集可以实现医学影像数据的分类识别[15]。
1)支持向量机是一种二分类模型,它是定义在特征空间上间隔最大的线性分类器,也可以通过核方法达到非线性分类的目的。该算法学习的基本思想是求解一个分离超平面,能够正确划分数据集并且使得几何间隔最大。给定一个特征数据集D={(x1,y1),(x2,y2),…,(xn,yn)},其中,xi∈Rm,表示第i个样本的特征向量,且每个特征向量xi都有l个特征(1≤l≤m),yi∈{+1,-1}。因此,求解最大分割超平面问题可以表示为如下不等式约束最优化问题:
s.t.yi(wT·xi+b)≥1,i=1,2,…,n。
(3)
其中,w和b分别为分离超平面的法向量和截距。该算法的学习策略就是间隔最大化,如式(3)的SVM算法就是求解凸二次规划的最优化算法。
2)决策树是一种基本的分类与回归方法,其模型呈树状结构,通过特征对数据实例进行分类。决策树由节点和有向边组成,其中,内部节点表示一个数据的特征或者属性,而叶节点表示一个类,即数据所属分类类别。将无序数据划分到类别叶节点,需要考虑如何选择特征划分数据使得分类结果更好。针对如何划分数据集,引入信息增益gR(D,Aj),即样本的第j维特征Aj对于训练数据集D的信息增益g(D,Aj)与训练数据集D的经验熵H(D)之比,定义如下:
(4)
以信息增益比作为划分数据集特征的一个准则,信息增益比越大说明用该特征划分当前数据集最优。以信息增益比最大的特征划分数据集,在各个数据子集中再挑选信息增益比最大的特征划分数据集。如此递归迭代下去,就生成了一棵分类决策树。

(5)
其中,hw(xi)的取值介于0和1之间。基于上述逻辑回归模型可以实现以下分类:
P(yi=1|xi,w)=hw(xi),
P(yi=0|xi,w)=1-hw(xi)。
(6)
其中,yi表示类别标签,取值为0和1,hw(xi)为特征向量xi在参数w下分类为1的概率,1-hw(xi)为分类为0的概率。
2 实验与讨论
2.1 数据资源与评价指标
本文采用的甲状腺结节数据集来自西安交通大学第二附属医院超声科的甲状腺二维声像图,所有的数据包含结节区域良恶性的类别标签,其中类别标签来自于专业影像科医生的标注,并且都是已经确诊的患者,保证了数据的真实可靠。图4为良恶性甲状腺结节的影像示例。

图4 甲状腺结节示例图Fig.4 Examples of thyroid nodules
该甲状腺结节声像图数据集包含良性结节1 759张,恶性结节1 009张,总共2 768张。数据集被划分为3部分,分别为训练集、验证集和测试集。3个数据集的比例分别为70%,15%和15%,其中,每个数据集里均有相同比例的良恶性结节,确保3个数据集的良恶性结节分布均匀。具体的实验数据分布如表1所示。

表1 实验数据的分布Tab.1 The distribution of experimental data
为了实现甲状腺结节良恶性分类的评价,本文采用的衡量指标为分类准确率Accuracy,其计算公式为
(7)
其中:TP(true positives)为将正样本识别为正样本的数量;TN(true negatives)为将负样本识别为负样本的数量;total指的是所有测试集上数据的数量。准确率可以衡量一个算法的整体性能好坏,有利于直观地比较各个模型之间的差别。
另一个评价指标是受试者工作特征曲线(receiver operating characteristic curve,ROC曲线)。该曲线的横坐标为假阳性率(false positive rate,FPR),纵坐标为真阳性率(true positive rate,TPR)。ROC曲线下的面积为AUC(are under curve),AUC值越高表明分类器的分类性能越好。
本文的深度学习模型在TITAN XP显卡的ubuntu16.04系统上运行,所有模型采用Keras框架以及Python语言实现。本文还对数据进行了旋转、缩放以及裁切来扩充数据以增强模型的鲁棒性。
2.2 实验结果
为了验证深度学习模型对于甲状腺的分类能力,本文对ResNet、Xception和DenseNet 3个深度学习模型做了对比实验,实验结果如表2所示。表2中显示3个模型的准确率均大于70%,与专业医生的诊断能力类似。

表2 深度学习模型ResNet、Xception和DenseNet的分类性能对比Tab.2 Contrastive classification performance of deep learning models of RESNET,Xception and DenseNet %
从表2可以看出,ResNet模型的准确率最高,因此,用它来提取甲状腺结节的特征,其特征向量为2 048维。本实验使用决策树(DT)、支持向量机(SVM)和逻辑回归(LR),分别采用所有特征和特征筛选子集进行分类,比较结果见表3。

表3 特征筛选子集与所有特征的分类结果对比Tab.3 Contrastive classification results of feature subset and all features %
从表3看出,使用所有特征直接分类的结果的准确度相对较低。这主要是因为某些特征相互之间有冗余,而且存在部分与目标类别弱相关和不相关的特征,这些特征对于模型而言相当于噪声,影响了分类精度,而使用特征筛选子集实现分类识别的所有模型准确率均高于所有特征直接分类的结果。表3中逻辑回归的准确率最高,相比深度学习模型ResNet提升了4个百分点。同时从图5的ROC曲线图可以看出基于特征筛选的逻辑回归模型的AUC值较高,这表明该分类器的分类性能较好,也证明了特征筛选对于分类器性能的提升效果显著。
临床超声影像医师主要是定性地用甲状腺结节二维声像图的特征,包括甲状腺结节的形态、边缘、回声与成分等形态学特征来诊断其良恶性。目前,临床诊断中由于甲状腺良恶性的形态学特征重叠较多且表现复杂多样,专业医师的识别能力有差异,经常会出现误诊,因此良恶性的鉴别诊断相对较低,为70%左右,这给临床诊断良恶性带来了很多困惑和挑战[16]。

图5 基于ResNet与特征筛选的逻辑回归ROC曲线图Fig.5 ROC curves of logistic regression based on ResNet and feature selection
实验结果证明了深度学习应用于甲状腺结节良恶性鉴别诊断的准确性与专业医生的鉴别诊断能力相当,在一定程度上可以对医生在临床上的诊断提供一些参考价值;其次,在这种特征少数据多且特征之间冗余程度高的数据集,使用皮尔逊相关系数计算特征与目标之间的相关性,基于一定的筛选原则设置阈值,得到所有数据的一个特征子集,可以简化模型的复杂度,提高特征对类别的表达能力。
2.3 讨论
本文提出的基于特征筛选的深度学习方法能够获得较好的分类结果,但仅依赖于影像的结果并不能为医生的教学和研究提供足够的信息。病人的电子病历为医生的辅助诊断提供了大量有效的信息,因此,构建基于影像标注信息和电子病历文本特征的多模态语料库对于人工智能、医疗诊断与康复、外语教学、翻译研究等领域具有重要的意义。
首先,关键词是能够表达电子病历文本有效信息的词语,自然语言处理(nature language processing,NLP)技术是关键词提取常用且有效的方法之一。用Word2Vec模型可以对电子病历语料库进行训练,获得词向量文件。在此基础上,提取候选关键词的词向量表示,并采用聚类方法按照大小进行降序排序,将前k个候选关键词作为文本关键词。借助NLP方法可学习出电子病历文本中共有特征的关键词,如甲状腺结节的大小、形态(规则与否)、边界(结节与其周围组织分解清不清楚)、成分(囊实性回声)、钙化类型(粗钙化,微小钙化),形成带有关键词的标注文本病历,结合影像标注信息可构建多模态语料库。
其次,在电子病历中,一个词向量通常是多维度的,用t分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)可以把相近意思的词聚拢在一起,形成一意多词的描述。例如:甲状腺疾病中结节的中文描述术语有甲状腺结节、甲状腺肿物、甲状腺病变、甲状腺肿瘤、甲状腺赘生物等,其对应的英文描述术语有thyroid nodule、thyroid mass、thyroid lesion、thyroid tumor、thyroid neoplasm等。对于良恶性的甲状腺结节而言,归纳为恶性结节的中文术语有甲状腺恶性肿瘤、甲状腺癌、甲状腺乳头状癌、甲状腺髓样癌、甲状腺滤泡状癌、甲状腺未分化癌等,其对应的英文术语有thyroid malignant tumor、thyroid cancer/carcinoma、palillary thyroid cancer/carcinoma、medullary thyroid cancer/carcinoma、follicular thyroid cancer/carcinoma、undifferentiated thyroid cancer/carcinoma等。归纳为良性结节的中文术语有结节良性肿瘤、结节性甲状腺肿、甲状腺囊肿、甲状腺滤泡状腺瘤、甲状腺腺瘤等,其对应的英文术语有thyroid benign tumor、thyroid nodular goiter、thyroid cyst、follicular thyroid adenoma、thyroid adenoma等。通过对多模态语料库中各种不同语言多样化表述的分析,结合关键词之间的关联,为医学语言规范化的表达及至多语言多模态语料库的教学和研究提供帮助。
此外,研究发现,结节特征书写报告的描述也存在多样化,比如无回声或囊性回声结节、混合或囊实性结节、椭圆形或形态规则的结节、边界不清晰或边缘不光滑的结节、结节内部强光点或者微小钙化等。英文也会面临同样的问题,如anechoic or cystic echo nodule、mixed or cystic-solid nodule、oval or regular-shaped nodule、unclear or irregular boundary nodule、hyperechoic spots or microcalcification within a nodule等。通过将结节特征的不同描述聚类,可将相关性较强但文字表达不同的特征病历整合在一起,这为相似病例的检索提供了基础,也为同一大类里面病例的细分提供了可能性。
本文构建的基于医学影像标注和电子病历文本特征的多模态语料库可以提供一个有利于医学生自我学习相关医学病理知识的平台,将课堂理论知识与大量真实的病例结合起来,增强了学习的主观能动性,丰富了学习形式及内容,有利于为医学领域储备更有专业素养的医务人员。与此同时,多模态语料库中文本和影像大大丰富了教学内容,有利于学生的理解和专业技能的培养。其次,多模态语料库的构建可以辅助医生对病人的诊断治疗,根据语料库可以搜索类似病情的病人,借鉴类似病人电子病历中的治疗方案和疗效,提高医生的工作效率以及诊治效果。最后,建立多模态的医学语料库可以辅助相关领域专家学者的研究,对于本文甲状腺结节良恶性而言,影像和电子病历的集中分析,可以帮助发现数据中很多不被临床重视的有重大意义的隐藏特征信息,有利于推动相关医学的发展。
3 结语
本文提出一种基于特征筛选的深度学习分类算法,该方法实现了更加精确的甲状腺结节良恶性分类识别,其结果与专业医生诊断能力的结果近似相当。结合影像的类别信息,通过自然语言处理的方法提取电子文本病历中的特征信息,从而构建基于医学影像和电子文本标注的甲状腺多模态语料库。
在下一阶段的研究中,可以通过引入甲状腺结节的其他医学影像如血流图以及特征数据来进一步挖掘语料库更多模态的信息,以提高识别精度,丰富语料库资源。本文的算法也可以应用于其他领域的多模态语料库,辅助相关医学领域工作人员学习、教育教学以及科研工作。
