基于深度学习的番茄病害检测识别算法
2021-04-16陶国柱廖义奎董力量
陶国柱 廖义奎 董力量
(广西民族大学电子信息学院,广西 南宁 530006)
引言
农作物生长周期易遭受到病害的侵袭,而我国是农业病害多发重发的国家,农作物每年遭受病害侵蚀经济损失程度巨大,根据联合国农粮组织估计,全世界范围内每年农作物病虫害自然损失率在37%以上。由此可见,病虫害的防治对我国的农业发展具有至关重要的作用。病虫害种类繁多,而传统的病虫害检测方法依靠人工凭借经验判断种类,难以准确诊断。改变传统的病虫害检测方式,能更有效的满足病虫害的防治需求。近年来,智能检测技术不断应用于农业上。刘洋等提出一种轻量级 CNN 的植物病害识别方法,并将其移植到 Android 手机端,并在识别精度、运算速度和网络尺寸之间取得不错的效果。孙俊等通过改进卷积神经网络的初始化参数和尝试不同类型的激活函数对多种植物叶片病虫害进行识别,平均测试识别准确率达到 99.56%。魏丽冉等在Lab彩色空间模型下的a、b分量上进行叶片分割并提取特征,然后采用基于核函数的支持向量机多分类方法对病害进行检测识别并分类,识别率最高达到89.5%。赵立新等基于迁移学习的棉花叶部病虫害识别,通过改进 AlexNet模型的迁移学习,源领域学习到的知识迁移到目标领域,数据增强技术能有效缓解过拟合,能取得不错的效果。Sumita Mishra等将通过预训练的卷积神经网络模型部署到专门的CNN硬件模块中,使玉米叶疾病的识别模型准确率达到了88.46%。刘君等针对背景环境的要求较高,同时不能实现病虫害的定位的问题,提出基于YOLO卷积神经网络的番茄病虫害检测算法并建立数据库,对8类番茄病虫害的检测平均精度高达85.09%。本研究采用的是YOLOv4目标识别算法对番茄病害进行识别与定位,YOLOv4是YOLOv3的改进版,在结合YOLOv3的基础上提出一系列新的方法。YOLOv4在YOLOv3的基础上,在FPS不下降的情况下,mAP达到了44,提高非常明显。通过调整原始 YOLOv4 网络参数来适应番茄病害检测任务,研究优化改进模型效果,相对于深度学习病害图像识别来说,YOLOv4目标检测算法对病害的检测效果有较大提升,并能对发病位置进行精确定位,同时还拥有不错的速度和精度。
1.YOLOv4算法结构框架
YOLOv4是在YOLOv3基础上进行了改进,主要改进的地方有将YOLOv3的主干特征提取网络DarkNet53改为CSPDarkNet53,其结构图如表1所示,加入SPP、PAN特征金字塔,使用mish激活函数代替LeakyReLU,使用CutMix数据增强和马赛克(Mosaic)数据增强。YOLOv4相比于YOLOv3检测速度更快,精度更高,对小目标检测更敏感。在FPS一样的情况下YOLOv4比YOLOv3的AP大概高出了31.25%。

表1 CSPDarkNet网络结构图
CSPDarkNet一共有5大残差块,每个残差块分别包含小的残差块为1、2、8、8、4。在每组Residual block加上一个Cross Stage Partial结构。并且CSP-DarkNet中也取消了Bottleneck的结构,减少了参数使其更容易训练。相比于普通的残差卷积块具有加强CNN的学习能力、消除计算瓶颈、降低内存成本的优点。SPP传统的CNN结构中,由于全连接层的特征数是固定的,所以输入的图片大小是不变的。而SPP使用多个不同大小的窗口对特征图进行pooling,然后将分别得到的结果进行合并就会得到固定长度的输出。
2.番茄病害检测算法
本实验提出的YOLOv4病害检测算法首先对病害图像进行预处理,图片仍然保持原来的颜色3通道以便保留更多的原始病害信息,将病害图像resize到416×416像素大小尽量保证其病害像素值在合理范围内,然后通过特征提取主干网络对病害进行特征提取,将提取到的特征图进行网格划分。最后将提取三个大小为52×52、26×26、13×13的特征层进行预测。不同大小的网格可以感受不同大小的病害信息,13×13的网格用来感受大目标,而52×52的网格感受小目标,能逐步提取更高更丰富的病害语义特征信息,方便检测到不同大小的病害病斑,本实验算法流程如图1。对于每个相应的网格都有一定数量的anchors,然后微调每个anchors形成预测框。对于每个预测框模型需要预测输出P0=(tx,ty,tw,th,Pobj,P1,P2,...,PC) 其中Pobj是anchors是否包含病害的概率,P1,P2,...,PC则是锚框包含的病害属于每个类别的概率。tx,ty,tw,th则是预测框需要调整病害发病的位置。对于一个预测框,网络需要输出(5+C)个实数来表征它是否有病害、发病位置和形状尺寸以及属于那个病害类别的概率。由于我们在每个anchors都生成了K个预测框,则所有预测框一共需要网络输出的预测值数目是:
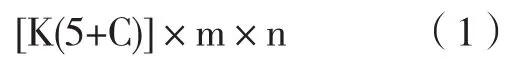
m,n为划分的网格数。接下来将病害表征输出和预测框关联起来,也就是要建立起损失函数跟网络输出之间的关系。CIOU将检测物体和每个锚框之间的距离、重叠率、尺度以及惩罚项都考虑进去,使得预测框波动更小,不会像IOU和GIOU一样出现训练过程中发散等问题。而惩罚因子a,v把预测框长宽比拟合目标框的长宽比考虑进去。

a与v的公式如下:
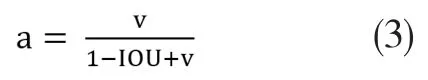

总损失函数LOSS为计算xy和wh上的LOSSciou、计算置信度的LOSSobj、计算预测种类的LOSSclass三者之和。

LOSSobj表示obj中是否包含病虫害情况预测:

LOSSclass表示对病虫害类别的预测:

考虑到在真实自然环境下病害的发生概率并没有那么高,由此可知大多数网格anchors置信度都为0,为了解决正负样本不平衡的问题,将正样本,即有病害的样本IOU阈值设置为0.5,该目的是为了平衡正负样本。大于这个阈值的样本都会被算为正样本,大于阈值但是置信度为0的样本obj被标记为-1,不会被计算在LOSS内。因此,加大其中存在病害目标的网格的权重,将权重更改为λciou=5,λnoobj=0.5。

图1 病害检测算法流程图
3.实验数据
本文从Plantvillge开源数据集中选取不同种病害番茄图像各500张,共计2000张,因农业领域数据图片较少不好获取,且病害的种类发病与天气及种植环境等多种因素相关,通过筛选网上权威网站获取部分由各种植户上传的自然光下拍摄的番茄早疫病415张、晚疫病413张、白粉病426张、细菌性斑点病417张、叶霉病423张、病毒叶435张。针对数据集中图片相对较少而产生的样本失衡的问题,本文利用随机的裁剪、旋转、色彩变换、抑制噪声等方法对部分数据进行样本增强,将病害数据集扩展到5574 张,这使得样本多样性增加,提高了样本质量,同时有效缓解训练过程中的过拟合现象。按照9:1的比例划分训练集和测试集。利用 LabelImg 软件进行了病害信息的人工标注,生成包含病虫害目标的种类和位置的 xml文件,并将其转换成训练使用的 Label 文件,从而为试验做好数据准备。样本数据如表2所示。

表2 番茄病害数据统计
4.实验结果分析
本实验系统为win7,CPU为i7-9400,显卡GPU Nvidia GTX1080,8GB内存,程序使用python编写,调用Keras、OpenCV等库并在Pycharm上运行。
4.1 评价指标
在深度学习中为了能更准确衡量模型对病害检测的检测性能,本文选用Precision(精准度,P)和Recall(召回率,R)两者结合作为模型的评价指标。具体计算如式(9)(10)所示,其中:TP表示分类器认为是病害样本并且分对的例子,即被正确检测到的病害样本数;TN 表示分类器认为是正确样本但分错的例子,即没有框选的病害的部分;FN 是分类器认为不是病害样本且分错了的例子,即没有检测到病害数;FP是分类器认为不是病害样本但分对了的例子,即检测到了病害的其他区域。


图2 各算法对病害的总体检测情况
分别取召回率R和精确率P的值作为横坐标和纵坐标,绘制一条 P-R 曲线,如图2,精准度 P 表示模型分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例;而召回率 R 表示模型分类器认为是正类并且确实是正类的部分占所有确实是正类的比例,可以反映网络模型的整体性能。本试验的番茄病害检测结果通过Precision与Recall曲线来描述。其中,Precision和Recall定义如下。
Precision=正确检测病害样本数/(正确检测病害样本数+错误检测病害样本数)
Recall=正确检测病害样本数/(正确检测病害样本数+没有检测到的病害样本数)
4.2 病害检测精度
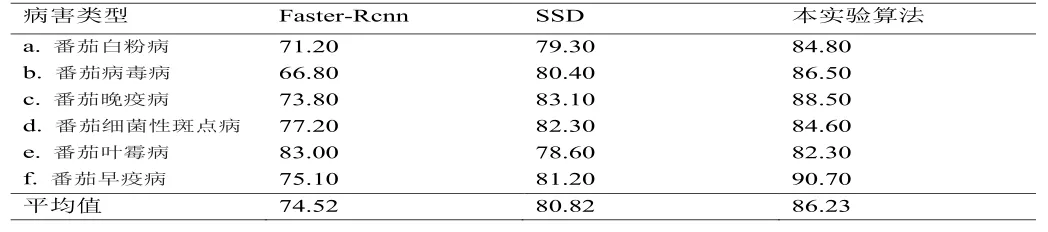
表3 各算法对病害的平均检测精度 %

图3 本实验算法对各病害检测效果
4.3 病害检测速度

表4 各算法对病害检测速度
对各算法对6种病害的检测精度统计如表3所示,检测效果如图3所示,与其他算法相比,本算法对番茄白粉病、番茄病毒病、番茄晚疫病、番茄细菌性斑点病、番茄叶霉病、番茄早疫病的检测精度分别为84.8%、86.5%、88.5%、84.6%、82.3%、90.7%。平均精度达86.23%,在提升病害检测精度的同时也拥有不错的检测速度,FPS达75,能够应用于实时病害检测中。
5.结语
本文利用 YOLOv4 卷积神经网络实现对番茄病害识别与定位检测,并与两个主流深度学习目标检测算法做了对比,通过试验测试,基于的 YOLOv4 网络的番茄定位识别模型平均精确度达到 86.23%,相对于Faster-Rcnn、SSD两种网络,平均精确度分别提高11.71%、5.41% ,本试验方法较前人的方法在病害检测准确率上有较大提升,同时能实现图像中病害位置的精准定位,能够对病害实行实时监测,说明该方法具有一定的实用价值。
