土壤有机质可见光–近红外光谱预测样本优化选择①
2020-06-15肖云飞高小红李冠稳
肖云飞,高小红,李冠稳
(青海师范大学地理科学学院,青海省自然地理与环境过程重点实验室,青藏高原地表过程与生态保育教育部重点实验室,西宁 810008)
土壤有机质是土壤的重要组成成分,是植物主要营养来源之一,是土壤肥力的重要指标[1]。近年来可见光–近红外光谱技术以高效性、实时性、成本低的特点在土壤理化性质中得到了快速发展[2]。为提高可见光–近红外光谱对土壤有机质的预测精度,国内外学者从土壤粒径[3]、光谱预处理[4]、特征光谱波段选择[5]、建模方法[6]等方面分别研究了对有机质预测精度的影响,期待找到最佳的土壤有机质可见光–近红外光谱预测方法。近来有学者从建模样本选择优化角度出发[7-8],研究最佳建模样本集,以提高模型精度。
实际情况中,由于土壤样本的采集受多种原因影响,如交通可通达性、采样区域的范围大小、经费的不足等未能全面地考虑成土母质、理化性质、地理空间位置等,使采样不具有代表性、样本空间分布的不均匀等情况,影响建模样本的选择,进而影响模型的预测能力。目前常用的建模样本选择方法有浓度梯度法、Kennard-Stone(KS)方法、Rank-KS(RKS)方法。KS 方法以土壤光谱差异性作为建模样本与验证样本选择的依据,当样本之间的光谱差异较小时,选择出的建模样本就不具有代表性;浓度梯度法主要考虑了土壤有机质的含量,但未考虑土壤的光谱特性、地理位置及其他理化性质对建模样本选择的影响;RKS方法虽考虑了土壤有机质含量与土壤光谱特性,但也未考虑土壤的其他理化性质。所以该方法也使得挑选的建模样本因未考虑其他因素的影响而缺少代表性,且RKS 方法在利用有机质含量对样本分类时没有一个具体的标准,可能会造成建模样本的挑选不均匀。
陈奕云等[7]分别采用KS、RKS、SPXY(Sample set Partitioning based on joint X-Y distance)3 种方法挑选不同比例的建模样本来预测固定验证样本的精度,研究表明KS 方法无法提高模型预测精度,SPXY 方法用50% 总建模样本数就能达到建模预测精度,RKS方法在保证建模预测精度时可以减少70% 的建模样本。刘艳芳等[8]利用土地利用类型结合土壤理化信息、光谱信息挑选建模样本集,研究表明具有多种土壤信息结合的方法选择的建模样本更具有代表性,可以有效地提高模型预测精度。邬登巍和张甘霖[9]研究表明母质和土地利用类型的差异会显著影响异地模型的适应性,一个地区建立的估算模型不可随便用于母质和土地利用类型不同的其他地区。Liu 等[10]利用含有不同土地利用类型的建模样本的模型很好地预测了单一土地利用类型有机质含量。刘伟等[11]提出将光谱信息和理化信息结合构成的RKS 方法能够明显地提高二甲亚砜溶液浓度的预测精度。以上研究表明加入土壤多种信息的建模样本选择方法,可以构建更具有代表性的建模集,从而提高模型预测精度。
土壤光谱反射率是土壤的众多理化性质的综合反映,理化性质不同,光谱反射率也就不同。有机质含量相同的不同土壤类型的光谱也可能不尽相同[12-14]。本文将土壤类型加入建模样本的选择方法中,结合浓度梯度法、KS 方法,构成5 种建模样本选择方法,对比不同建模样本选择方法的模型精度,研究土壤类型对建模样本选择的影响,寻找最佳的建模样本构建方法,以及在固定验证样本情况下模型达到一定预测精度至少所需的建模样本数,为今后湟水流域有机质预测提供较好的建模集构建方法,同时为湟水流域野外采样提供数据支持。
1 材料与方法
1.1 研究区概况
湟水是黄河上游最大的一级支流,发源于青海省海晏县境内,青海境内全长336 km。湟水流域位于青海东部地区,地处36°02′ ~ 37°28′N,100°42′ ~103°04′E(图1),是黄土高原向青藏高原的过渡地带。流域内地形比较复杂,内有河谷盆地、丘陵和中高山地,海拔1 655 ~ 4 860 m,流域西宽东窄,西高东低,为高原干旱、半干旱气候,气温由西向东逐渐升高[15]。流域内主要土壤类型为灰钙土、栗钙土、黑钙土、灰褐土、高山草甸土、山地草甸土等,主要农作物有油菜、马铃薯、春小麦、玉米、青稞、燕麦等,是青海省主要的农业区。
1.2 样品采集与分析
研究所使用的土壤样本为2015 年、2016 年采集的418 个土壤样品,采样点空间分布如图1,采样时间选择在农作物收割结束的10 月至11 月初,共计34 d,为了与野外光谱采集时间一致,土壤采样在天气晴朗的11:00—15:30 间。采集土壤样本时考虑土壤类型、可到达性、耕地类型、采样地未翻晒等因素,相对均匀地分布在整个流域内。土壤样本采集方式在相对平坦的地方采用“梅花型”方法采集,坡耕地采用“S”型方法采集,采集土壤表层0 ~ 20 cm 的表土,去除植物根系和石粒,搅拌均匀装入密封袋,使用GPS 实时记录采样点坐标和高程。土壤样本在实验室避光条件下自然风干过100 目筛,用于土壤反射光谱的测量和有机质的实验室分析测试。有机质含量的测定采用重铬酸钾外加热法。有机质含量特征统计结果见表1。
变异系数用来衡量土壤特征的空间变异强度,变异系数 0 ~ 10% 为小变异,10% ~ 100% 为中等变异,大于100% 为高度变异[16]。从表中可以看出不同土壤类型的有机质含量都属于中等变异,且变异大小为高山草甸土<灰钙土<灰褐土<黑钙土<山地草甸土<栗钙土<总体变异系数,高山草甸土与山地草甸土的土壤有机质含量较高,平均值分别达到了91.53、67.47 g/kg,灰钙土有机质含量最低,平均值为16.96 g/kg。
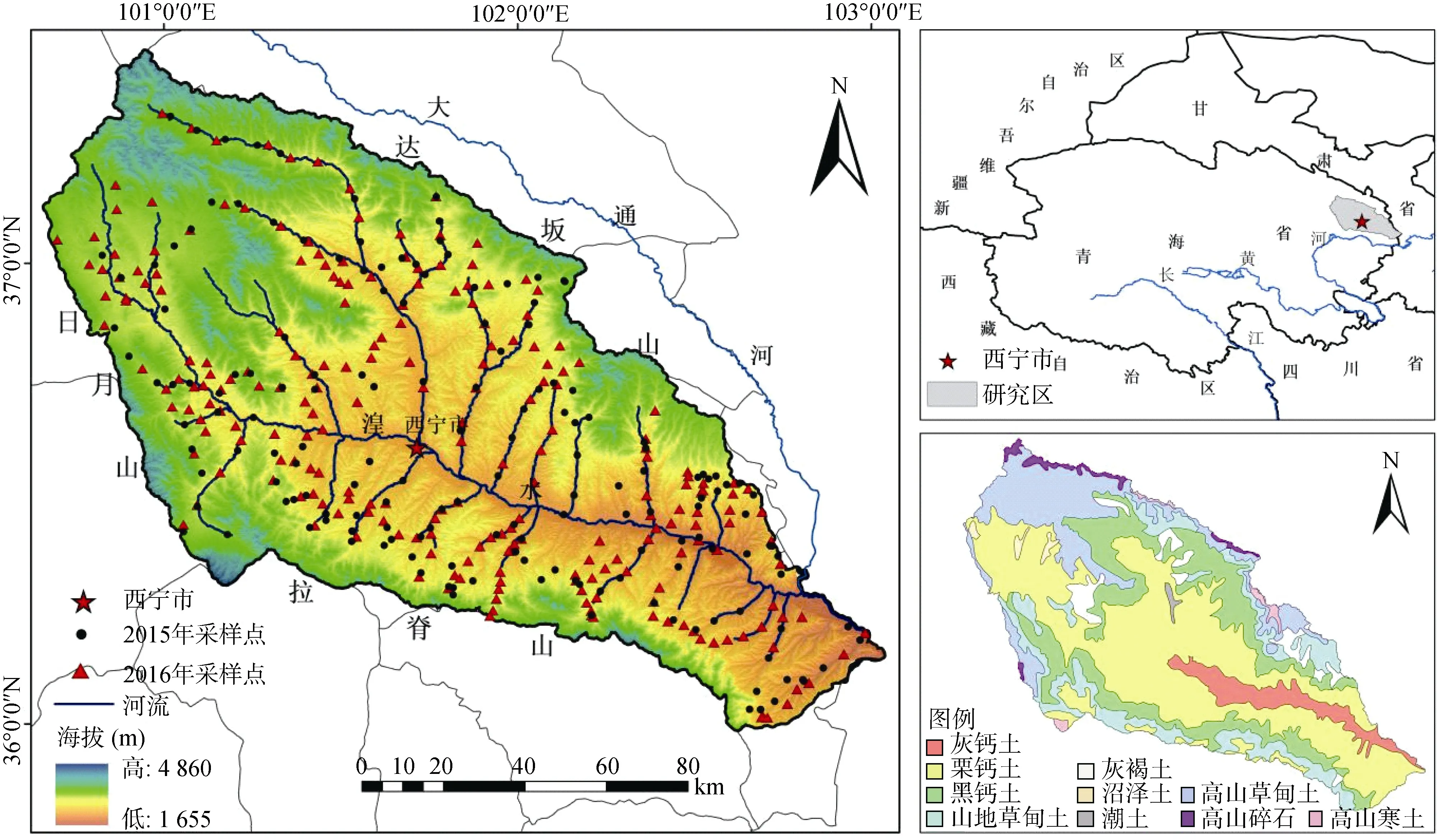
图1 研究区采样点空间分布及土壤类型Fig. 1 Spatial distribution of soil types and sampling sites in study area
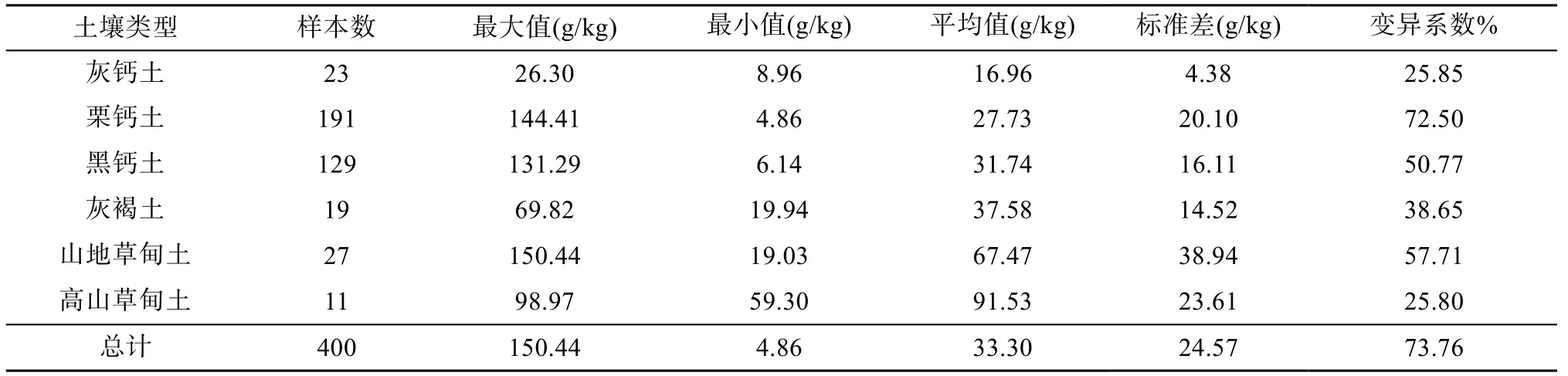
表1 土壤有机质含量特征统计Table 1 Descriptive statistics of soil organic matter contents for different soil types
1.3 室内光谱的测量及预处理
采用美国ASD Field Spec 4地物光谱仪在暗室内测量光谱,波长范围为250 ~ 2 500 nm,重采样间隔为1 nm,输出波段2 151 条。将土壤装入直径为12 cm、高为2 cm 的黑色玻璃器皿中。用75 W 卤素灯作为光源,光源入射角为30°,距土壤样本表面中心30 cm。光谱探头距土壤样本中心15 cm 处垂直向下,土壤样本每旋转90°测5 条光谱,共20 条光谱,光谱测量中每测5 个土壤样本白板定标一次。检查光谱中是否有异常光谱,剔除异常光谱计算平均值作为土壤的原始光谱。利用主成分分析方法剔除光谱异常值18 条,剩余400 条光谱进行后续研究。
在光谱测量中,由于光谱测量环境、测量仪器等因素的影响,光谱中会出现噪声,噪声的存在会影响光谱信息的表达、分析及模型的精度[17]。光谱的微分变换可以减少噪声和背景的影响,放大光谱特征的差异[18]。本文中首先去除噪声比较大的350 ~ 399 nm、2 401 ~ 2 500 nm 波段。光谱预处理方法选择Savitzky-Golay(SG)加一阶微分变换。原始光谱及一阶微分光谱反射率如图2 所示。
1.4 建模集样本选择方法
本文考虑土壤有机质含量、光谱特征和土壤类型构建了5 种建模样本优化选择方法。浓度梯度法是一种基于理化性质的建模样本选择方法,将土壤有机质含量按大小顺序排列,并依顺序每隔一个样本抽取两个样本为建模样本,剩余为验证样本;土壤类型结合浓度梯度法原理是首先将土壤按照类型分开,每一种土壤类型按土壤有机质含量大小排序,按顺序每隔一个样本抽取两个样本,将每种土壤类型所抽取的样本合为一个整体作为建模集的样本;KS 方法根据光谱主成分空间的欧氏距离选择样本,先寻找全体样本空间中欧氏距离最远的两个样本,归入建模集。再依次计算全体样本中每个剩余样本到建模集样本的距离,选取每个剩余样本的最短距离,将这些剩余样本最短距离中的最长距离所对应的样本选入建模集。重复上一个步骤,直至建模集中样本的数量和所需建模集样本数量一致;土壤类型结合KS 方法原理是先将土壤按类型分开,每种土壤类型中按KS 方法挑选出一定数目的样本作为建模样本;RKS 法是一种既考虑土壤样本的理化性质又考虑其光谱性质的建模样本挑选方法,首先按样本有机质的含量将样本分为多份,每一份中再按KS 方法选择一定数目的样本作为建模样本[11]。

图2 土壤原始光谱反射率及一阶微分变换Fig. 2 Soil original spectral reflectance and first-order differential spectra of different soil types
1.5 偏最小二乘回归(PLSR)建模与验证
偏最小二乘回归(PLSR)是由Wold 和Albano 等在1989 年提出的,模型同时实现了多元回归、主成分分析、变量之间相关分析的新型多元统计分析方法。通过因子分析实现了光谱数据的降维,同时也除去了干扰组分和干扰因素的影响,消除了自变量间多重共线性,很好地解决了样本数少于变量数的问题[19]。模型采用留一法交叉验证方法。模型精度评价指标采用决定系数(R2)、均方根误差(RMSE)、相对分析误差(RPD),当R2、RMSE 越小,RPD 越大,模型的预测效果越好,Chang 等[20]认为当RPD≥2 时模型有较好的预测效果,当1.4≤RPD<2 时模型有粗略估算能力,当RPD<1.4 时模型不具备估算能力。
1.6 不同级别样点数的建模样本选择方法
为了研究不同级别样点数的最佳建模样本选择方法以及加入土壤类型对建模样本选择方法的优化效果,将剔除异常值后的400 个土壤样本点按其经纬度坐标导入到研究区地理空间中,在满足样点相对均匀分布在整个研究区内且包含不同土壤类型的条件下,计算样本点之间的空间距离(ArcGIS 软件中完成)。在样本数分别为400、350、300、250 时,土壤样点空间分布图上计算相同土壤类型样点的空间距离,考虑每一类土壤类型的样点占总样点的百分比,依据经验样点间距离分别不小于0.12、0.22、0.32、0.44 km 对样点进行删除,按土壤样点间隔数50 剔除样本数,最后得到350、300、250、200 的样点分布图。在样本数分别为200、150 时,土壤采样点空间分布图上不考虑土壤类型计算邻近点之间的距离,删除距离较近两采样点中的一个样点(删除样点为土壤类型样本数较多的样点),按土壤样点间隔数50 剔除样本数,得到150、100 的样本分布图。最终样本分成7 个级别,即样本数为400、350、300、250、200、150、100,并分别应用浓度梯度方法、KS 法、RKS法、土壤类型结合浓度梯度方法、土壤类型结合KS方法,按建模样本与验证样本比为2︰1 确定每一级别样本的建模样本与验证样本。不同级别样点的空间位置如图3 所示。
1.7 固定验证样本下不同建模样本数的建模样本选择方法
将400 个土壤样本考虑空间位置、土壤类型、有机质含量挑选出1/5 样本(80 个)作为验证样本,剩余的4/5 的样本(320 个)作为总建模样本。浓度梯度方法、KS 方法、RKS 方法按占样本数的90%、80%、70%、60%、50%、40%、30%、20%、10% 分别挑选出建模样本。土壤类型结合浓度梯度方法、KS 方法按土壤类型将总建模样本分开,每种土壤类型的建模样本占该土壤类型样本数的90%、80%、70%、60%、50%、40%、30%、20%、10% 挑选出来作为一个整体作为总建模样本。验证样本地理空间分布见图3H。不同建模样本特征统计见表2。
2 结果
2.1 不同级别样本数的建模样本选择方法模型精度对比及变化趋势
不同级别样本数的 5 种建模样本选择方法模型精度结果如图4。KS 方法在样本数为400、350时,建模R2与验证R2差值较小,模型具有较好的预测能力(RPD>2);且在样本数为400 时RPD 值最大(RPD=2.459),模型具有最佳预测能力;当样本数小于300 时,建模R2不断在增大,而验证R2不断减小,差值不断增大,模型有过拟合现象,预测能力较差。浓度梯度法在不同级别样本数的模型精度变化不大,表现为在样本数分别为400、350、250、200 时,RPD>2,模型具有较好的预测能力;且在样本数为200 时RPD 为2.579,模型具有最佳预测能力;在样本数分别为 300、150、100 时,RPD<2,模型具有粗略预测能力;样本数在150 时建模R2为0.896,验证R2为0.707,差值变大,模型不稳定。RKS 方法在样本数分别为400、350、300、200、150 时,RPD>2,模型较稳定,具有较好的预测能力;在样本分别为250、100 时,RPD<2,模型具有粗略预测能力,且样本数为100 时建模R2为0.909,验证R2为0.667,模型不稳定。土壤类型结合浓度梯度法挑选的建模样本的模型整体RPD>2,具有较好的预测能力;当样本数为300 时RPD 为3.237,模型具有极好的预测能力。土壤类型结合KS 方法,样本数为300 时,RPD 为1.910,模型具有粗略预测能力;样本数为200 时,RPD 为3.01,模型具有极好的预测能力;其他样本数时,RPD>2,具有较好的预测能力。
当样本数为350、400 时,不同的建模样本选择方法的模型RPD 值都大于2,模型预测精度差值不大,且在样本数为400 时,不同建模样本选择方法的建模R2、验证R2、RPD 值都较接近,说明对本研究区来说样本数为400 是最佳的样本选择。当样本数小于350 时,不同建模样本选择方法的建模R2值差值不大,但验证R2的差值变大,RPD 值差值也变大。当样本数为150、100 时,验证R2、RPD 值都较小,说明样本数少于150 时,模型只具有粗略的预测能力。
对比模型预测精度发现加入土壤类型的浓度梯度法和KS 方法挑选的建模样本集的模型相比其他建模样本选择方法挑选的建模样本集的模型验证R2和RPD 值相对较大。且在样本数较少时更加明显,说明加入土壤类型可以很好地优化建模样本选择方法满足样本点较少达到很好的预测效果。
2.2 固定验证样本下建模样本选择方法精度对比
在固定验证样本的情况下,建模样本的不同选择方法精度对比如图5。对于任何一种建模样本选择方法挑选的子建模集,在建模样本≥50% 时,建模R2>0.82,验证R2>0.75,RPD>2,且差值较小,模型较稳定。说明不考虑建模样本选择方法情况下,只需要50% (160) 的建模样本数就能保证模型具备好的预测精度。当建模样本小于总建模样本的50% 时,不同建模样本选择方法的模型预测能力的差异变大,首先RKS 方法的模型精度下降,说明RKS 方法的建模样本数量在下降到一定比例时,容易丢失对模型预测精度有显著贡献的建模样本。加入土壤类型的浓度梯度法和KS 方法在建模样本数只有总建模样本数的20% 时,RPD≥2,模型具有好的预测精度,很大程度减少了建模成本。

表2 固定验证样本下的不同建模样本特征统计Table 2 Descriptive statistics of different calibration samples under fixed verification samples

图4 不同级别采样点建模样本选择方法模型精度Fig. 4 Models accuracies for different calibration samples at different samples levels
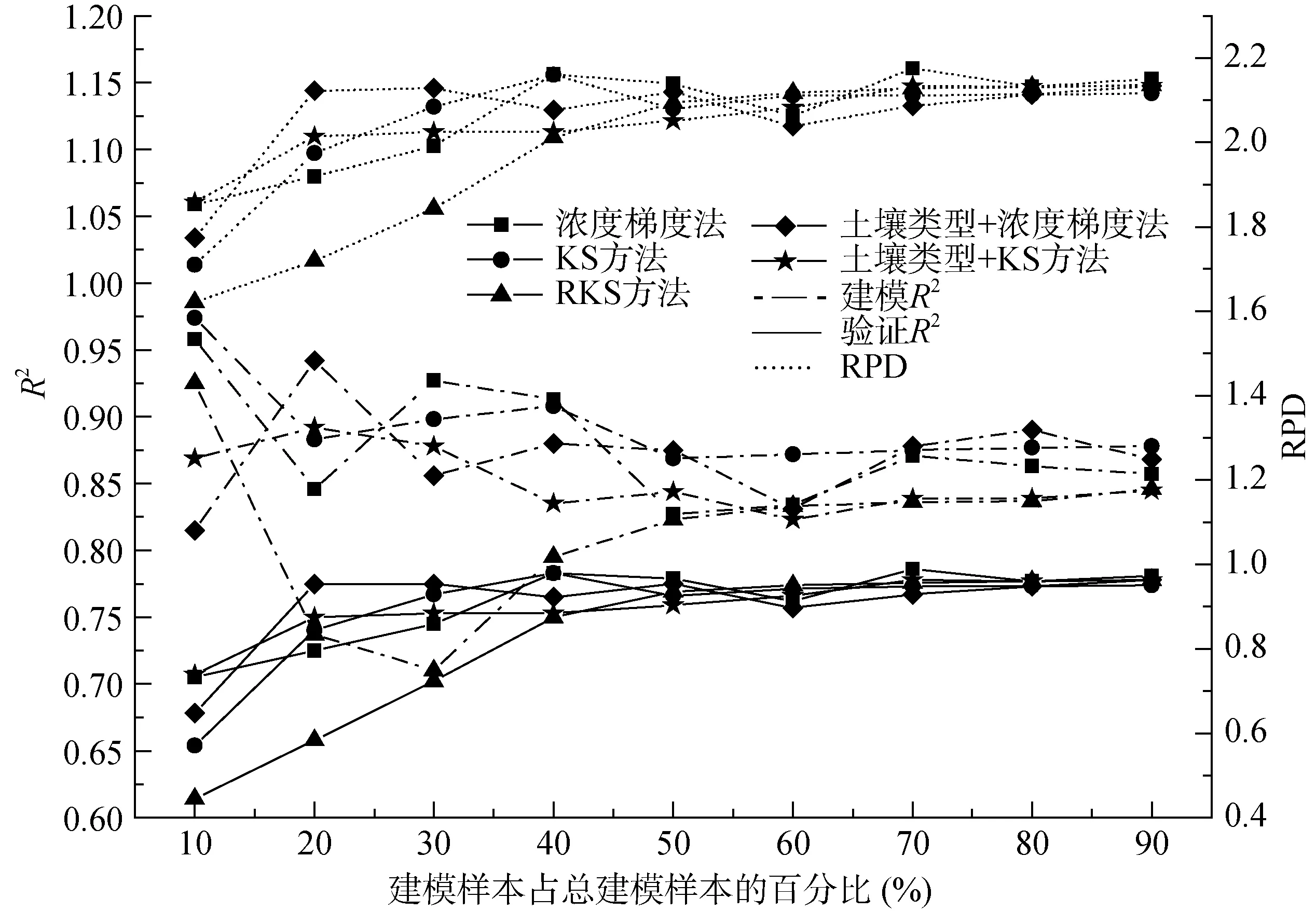
图5 固定验证样本下不同建模样本选择方法精度Fig. 5 Models accuracies for different calibration samples under fixed validation samples
3 讨论
不同类型土壤的反射光谱曲线存在着一定的规律性及基本一致的变化趋势,但土壤可见光-近红外光谱只能反映土壤一部分理化性质的差异,不能很好地揭示不同类型土壤的类间差异[21]。加入土壤类型有效地控制了地理空间位置、环境背景、其他理化性质对光谱的影响,使得建模样本选择更具有代表性。
本文研究与刘艳芳等[8]在江汉平原的研究结论是一致的,即加入土地利用类型可以构建更具有代表性的建模样本集。在该结论的基础上利用湟水流域400 个土壤样本,对比不同样本数级别下加入土壤类型对建模样本选择方法的优化效果表明:当样本数大于350 时,土壤类型的加入对建模样本选择方法的优化效果并不显著;而当样本数小于300 时,土壤类型对建模样本选择方法的优化效果则较为显著。
KS 方法在本文有机质预测中表现为:当样本数在400、350 时模型预测精度较好,模型相对稳定;但当样本数小于350,模型精度较差,模型较不稳定。土壤类型对KS 方法的优化结果表现为:在样本点为400、350 时,土壤类型结合KS 方法相比KS 方法的模型预测精度提高并不明显;但当样本数小于350时,土壤类型结合KS 方法相比KS 方法模型精度明显提高,模型变稳定。出现上述情况的原因是:在不断剔除样本数的过程中可能缩小了有机质含量范围使光谱差异逐渐变小,或当样本理化性质含量低或含量范围较窄时,采样点间光谱差异较小,导致KS 方法所挑选的建模样本不具代表性[10];而加入土壤类型可以弥补KS 方法的不足,使建模样本集更具有代表性。进而表明当样本较多时,在保证模型预测精度的情况下,为考虑建模时间成本,可以只选择KS 方法挑选建模样本;当样本较少的时候,为保证模型的预测精度,加入土壤类型可以优化KS 方法,挑选出更具有代表性的建模样本。
RKS 方法考虑了土壤的光谱信息与理化性质,相比KS 方法也有效地提高了模型的精度,但整体提高效果没有土壤类型结合KS 方法好,可能因为RKS方法是将样本按有机质含量排序划分等级,再进行KS 方法挑选建模样本集,不同等级的划分没有指定的标准,随机性比较大。
土壤类型结合浓度梯度法相比浓度梯度法模型精度提高不明显,可能是由于有机质含量的考虑进而也间接考虑了光谱的原因。有研究证明有机质含量高低在可见光-近红外波段对光谱反射率有较大的影响,有机质越低,反射率越高,反之亦然[22]。
固定验证样本(考虑了验证样本的空间分布位置、土壤类型及有机质含量),减少建模样本数量,研究在保证预测精度情况下建模的最小成本。表2中建模样本占总建模样本的不同比例下,KS 方法的建模样本的有机质含量平均值与固定验证样本的有机质含量平均值差值相对较大,而其他建模样本选择方法的建模样本有机质含量平均值与固定验证样本的有机质含量平均值接近,且不同建模样本选择方法的建模样本有机质含量的范围变化不大,固定验证样本的有机质含量都在建模样本有机质范围以内,但模型预测精度不同。说明土壤光谱是土壤众多性质的综合反映,只考虑单一因素的建模样本选择方法不能很好地挑选出具有代表性的建模样本集,且在样本数量较少时更为显著,加入土壤类型可以有效地优化建模样本选择方法,提高模型精度和减少建模样本数。
陈奕云等[7]在固定验证样本的情况下,KS 方法建模样本数仅占总建模样本数的70% 就能很好地保证模型的预测精度。本文中KS 方法建模样本数仅占总建模样本数的30% 就能很好地保证模型的预测精度,KS 方法在保证模型精度下选择的建模样本占总建模样本的比例更小,可能是因为样本数不同和固定样本选择考虑的因素不同,或因地区之间的土壤类型及有机质差异所造成的。以后的研究中在选择验证样本时可以考虑加入更多的因素,如耕地类型、地形、土壤质地等因素,增加验证样本数量,使验证样本相对于本研究区域更具有代表性,为以后该区域野外采样方案提供参考意见,减少野外采样成本。
不同样本数的不同建模样本选择方法的模型精度对比以及在固定验证样本下不同建模样本选择方法达到一定的预测精度所需的最少的建模样本对比表明:具有多种土壤要素考虑的建模集更具有代表性,土壤类型对建模样本选择方法的优化具有可行性与必要性。
4 结论
本文通过对不同建模样本选择方法的模型精度对比,比较了不同建模样本选择方法的构建对模型精度的影响。结果表明浓度梯度法和KS 方法所选的建模样本集所建立的模型预测能力较差。加入土壤类型后使所选择的建模样本更有代表性,模型精度得到提高。不同级别的样本数下最佳建模样本选择方法不同,但整体表现为土壤多种信息结合的建模样本选择方法模型精度较高。在固定验证样本下不同建模样本选择方法预测模型精度对比表明,浓度梯度法、KS方法及RKS 方法3 种方法建模样本数至少要分别达到总建模样本数的40%、30%、40% 时,才能保证模型精度较好。土壤类型结合浓度梯度法与土壤类型结合KS 方法在建模样本数占总建模样本数的20%时,就能保证很好的建模精度,有效地减少了建模样本数,减少了建模成本。
