基于深度学习的财务机器人自动撰文场景研究
2021-04-16孟志刚吴云伟姜宇杰
孟志刚,吴云伟,姜宇杰
(长沙学院计算机工程与应用数学学院,湖南 长沙 410022)
电力企业会计工作面临着诸多困难和挑战[1],会计模式亟待创新。部分企业的财务人员虽然具有相关从业资格,但因缺乏工作经验或对会计职责的正确认识,做出的财务报告质量较低;同时,部分企业的会计人员甚至缺乏基本的道德与法律意识,出现财务造假等违规行为,这些都导致企业在财务人员的培养上付出更高的成本[2]。此外,企业财务报表编辑烦琐、机械,繁重的压力促使财务人员难以按时上交中期表,影响企业决策的进行,且纷繁复杂的信息常会使得财务人员撰写财务报告时顾此失彼,出现对现金流量表述过于详细的情况,导致财务报表中很多周期性和季节性的信息无法被表露出来,不能有效突出重点,造成财务报告的信息量不足[3]。
为解决以上问题,本文提出了基于深度学习的财务机器人的设想,希望通过信息化手段实现自动撰文,旨在协助财务人员解决以往财务报告中所出现的问题,节省企业培养成本,减轻工作压力,提高工作效率。
采用深度学习技术产生语料是业界常用方法,如循环神经网络(Recurrent Neural Networks,RNN)是将序列数据作为输入,顺着序列的传播方向进行链式递归的递归神经网络[8]。自然语言数据是典型的序列数据,所以对序列数据学习有一定优势的RNN在NLP(Natural Language Processing)问题中得以应用。RNN具有分布式表达、能在序列预测中明确地学习和利用背景信息、长时间范围内学习和执行数据的复杂转换能力,因此,RNN在对序列的非线性特征进行学习时具有一定优势[9]。常见的RNN有长短期记忆网络(Long Short-Term Memory,LSTM)和双向循环神经网络(Bidirectional RNN,Bi-RNN)。
综上所述,本文将撰写报告建模为基于深度学习的文本自动生成问题模型,分别选择深度学习算法中的LSTM算法和GRU算法进行建模并进行比较。实验表明,在大规模语料库的基础上,模型生成的文本涵盖的信息更加全面,与人工生成的文本意思更相近。
1 问题描述
为提高电力企业报告质量,减轻电力企业财务人员工作压力,本文提出了基于深度学习的财务机器人自动撰文的模型,财务报告的撰写目标是构建一个文本生成算法,此算法接收大规模语料库句子输入,经计算后输出关联句子,并找出输入和输出之间的对应关系,自动从语料库中获取语义和语法知识,模拟人工写作来生成财务报告。本文分别使用了LSTM算法和GRU算法进行算法开发,并对两种算法的效能进行比较评估。
2 基于深度学习的文本生成技术
文本生成技术分为文本到文本的生成、数据到文本的生成和图像到文本的生成三类。本文所讨论的是文本到文本的生成,日常在社交媒体中见到的“机器人写作”“人工智能写作”“自动对话生成”“机器人写古诗”等,都属于文本生成的范畴。近二十年来,学界都是使用高维稀疏的特征,通过机器学习方法来训练模型。随着深度学习技术的突飞猛进,稠密矩阵表征的方法使自然语言处理任务得到更好的解决,词向量技术(vector to vector,Vec2Vec)的发展,增广了深度学习技术在自然语言处理中的应用。深度学习应用在文本生成中就是将生成文本的过程看成是生成动作,而且深度学习模型需要根据相应的环境信息来学习文本生成的知识。
基于RNN的文本生成算法是当前研究的主流。相比一般的神经网络来说,RNN能够更好地处理序列变化的数据,比如某个单词的意思会因为上文提到的内容不同而有不同,RNN可以很好地解决这种问题,在此基础上,有研究将RNN的隐藏层数量控制在1500 个,使得生成文本的效果得到了极大的提升。还有研究基于RNN算法自动生成小语种诗歌,但缺点是需要花费大量时间,并且生成的效果不够好。
原则上来说,足够大的RNN应该足以生成任意复杂度的序列。但是,实际上,标准RNN无法长时间存储过去输入的信息。往往是网络结构太深,造成网络权重不稳定,从而导致梯度消失和梯度爆炸等问题,而LSTM就是为了解决长序列训练过程中梯度消失和梯度爆炸的问题而构建出的特殊的RNN。相比于普通的RNN,LSTM能够在更长的序列中有更好的表现,还能更好地存储和访问信息,将LSTM单元作为隐层单元构建RNN,并采用字符级语言模型缩小了解空间,极大地提升了模型的效能和文本生成的效果。
2.1 基于LSTM的文本自动生成模型
2.1.1 预处理
定义序列长度、正向序列长度,创建存储提取句子的列表,存储每个句子的下一个字符(即预测目标),创建一个字典,主要以训练文章中的每一个字符为键。
2.1.2 模型构造
本文提出的基于LSTM的文本自动生成模型是以句子作为输入,通过LSTM网络获取特征,最后通过全连接层(Dense层)将提取的特征输入损失层。使用交叉熵损失函数得到损失值后,用RMSProp算法进行神经网络权重的优化。如图1所示。
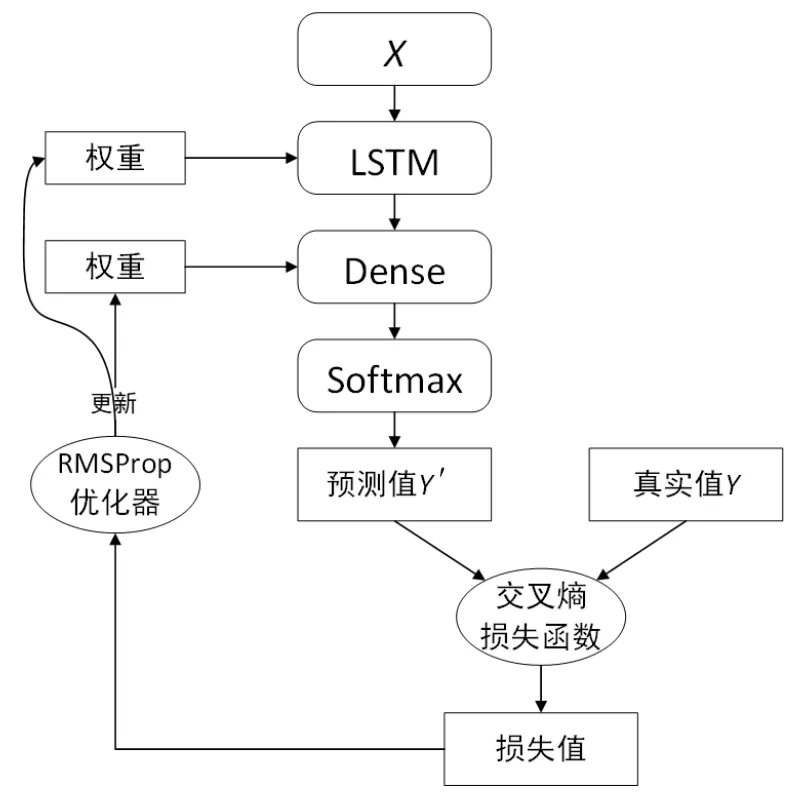
图1 基于LSTM的文本自动生成模型
此模型由以下结构组成:
(1)X表示三阶张量,主要有句子数、序列长度和字典长度。序列长度就是句子的长度,字典长度是指语料库中不重复的字的个数。
(2)Y表示二阶张量,主要有句子数和字典长度。
(3)基础模型创建:通过Keras来构建模型Sequential。
(4)LSTM层:通过model.add(layers.LSTM(256, input_shape=(maxlen, len(chars))))来创建模型的第一层,为长短期记忆网络层,其中每一批输入的尺寸为(256,maxlen,len(chars))。
(5)Dense层:通过深度学习框架Keras的代码 model.add(layers.Dense(len(chars), activation='softmax'))来创建模型的第二层,主要定义为语料中所有不重复的字符的总数个节点,以及使用softmax激活函数的神经层。
(6)优化器:在这里使用的是RMSProp 优化器。 RMSProp算法计算了梯度的微分平方加权平均数。此种做法有利于消除大幅度摆动的方向,用于修正摆动幅度,减小各个维度的摆动幅度。RMSProp优化算法框架如下:
(a)计算目标函数关于当前参数的梯度:

(b)根据历史梯度计算一阶动量和二阶动量:
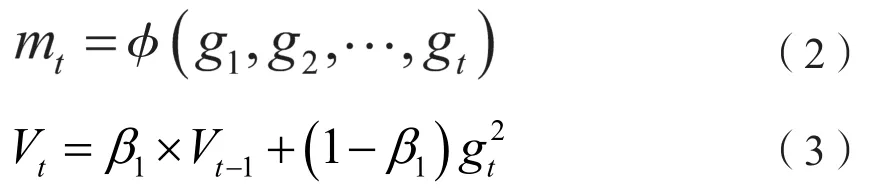
一阶动量mt,二阶动量Vt,Hinton建议设定超参数β1为 0.9,学习率a为10-3。
(c)计算当前时刻的下降梯度:

a是实际的学习率(也即下降步长)是实际的下降方向,ηt是下降的梯度。
(d)根据下降梯度进行更新:

(7)损失函数:在该模型中,主要使用的是categorical_crossentropy(交叉熵损失函数),交叉熵损失用来评估当前训练得到的概率分布与真实分布的差异情况。交叉熵的值越小,两个概率分布就越接近,它刻画的是实际输出概率与期望输出概率的距离,公式如下:
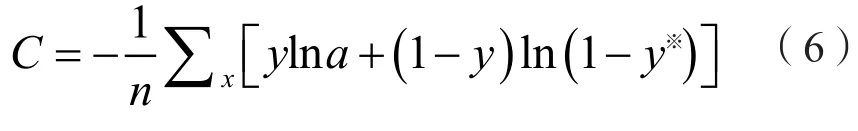
y为期望的输出,y※为神经元实际输出。
(8)模型训练:以X为输入数据,Y为标签,其中batch_size设置为512来进行为期10轮的训练。
2.2 基于GRU的正反序列文本自动生成模型
2.2.1 预处理
定义序列长度、正向序列长度、反向序列长度,创建存储提取句子的列表,存储每个句子的下一共字符(即预测目标),创建一共字典,主要以训练文章中的每一个字符为键。
2.2.2 模型构造
本文提出的基于GRU的正反序列的基础神经网络模型(见图2)是以句子的正序与反序两种序列作为数据输入网络。网络模型由三纵列组成,第一纵列接收句子的正序序列,词嵌入(Embedding)后通过GRU单元获取特征。第二、三纵列分别接收正、反序列,都是词嵌入后卷积、池化提取特征。最后三个纵列的输出全部拼接后,经过全连接层输入损失层。
此模型由以下结构组成:
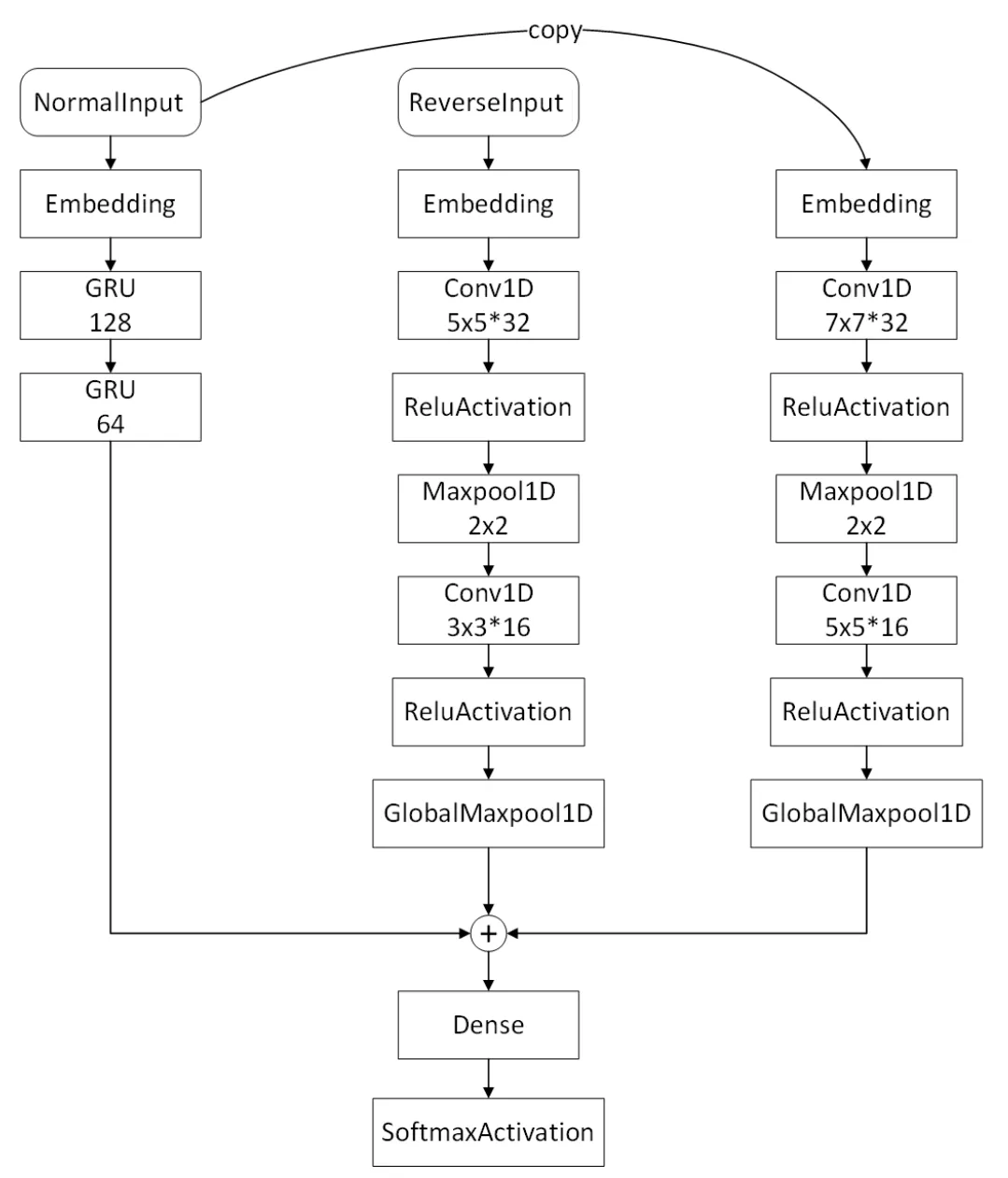
图2 基于GRU的正反序列的基础神经网络模型
(1)NormalⅠnput为二阶张量,张量内容为(句子数,正向序列长度)。训练时,假若语料库内容为“我是中国人民的好干部”,则NormalⅠnput的内容为[“我是中”“是中国”“中国人”“国人民”],输入层的数据通过循环遍历往下层输入数据。
(2) ReverseⅠnput为二阶张量,张量内容为(句子数,反向序列长度)。训练时,假若语料库内容为“我是中国人民的好干部”,则ReverseⅠnput的内容为[“的民人”“好的民”“干好的”“部干好”],此层的数据通过循环遍历往下层输入数据。
(3) 第一纵列:第一纵列以Embedding作为该纵列的第一层,它的输入是一阶张量,长度为正向序列长度,输出张量为(字典长度,64,正向序列长度)。该层的输出层为GRU层,通过layers.GRU(128,return_sequences=True)(model_1)来构建第一纵列的输出层,该纵列的作用是返回所有GRU单元的输出。
(4) 第二纵列:第二纵列的第一层为Embedding层,它的输入是一阶张量,长度为反向序列长度,输出张量为(字典长度,64,反向序列长度);通过该层转换之后的数据再进入该层的第二层Conv1D层,该层的激活函数为relu,通过激活后的该层宽度默认为第一层Embedding的维度之后便进入该纵列的第四层Maxpool1D层(1D输入的最大池化层),通过在这层进行数据最大池化之后便按照之前两层进行返回。
(5) 第三纵列:第三纵列的第一层Embedding层的长度为正向序列长度,与第二纵列相对应,该层的模型与第二纵列是完全一样的卷积、池化层,只是其长度转换为了反向序列长度,并且输入的数据与第一纵列相同,通过两个一样的层,来进行正反向一同学习词的前后概率,进而达到文本生成的效果。
本文基于GRU的文本自动生成模型(见图3)采取上文提出的基础模型,通过交叉熵损失函数计算损失值,采用RMSProp优化器进行神经网络权重的优化。
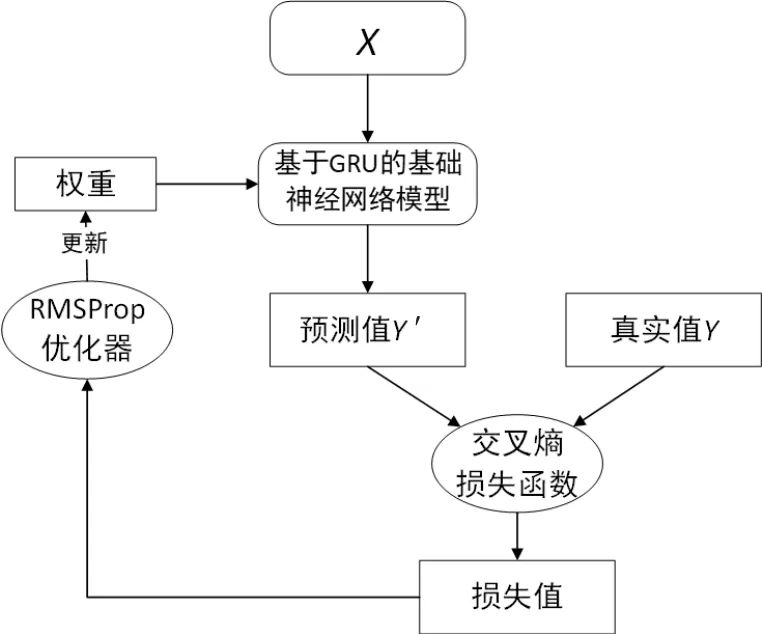
图3 基于GRU的文本自动生成模型
此模型由以下结构组成:
(1)基于GRU的基础神经网络模型创建:通过Keras来构建上面的三纵列的神经网络模型进行训练。
(2)Y为一维张量,主要有句子数。训练网络时,其内容是一个个的用来检验预测结果的单字;训练时,假若语料库内容为“我是中国人民的好干部”,则Y的内容为[“国”“人”“民”“的”]。
(3)优化器:此处同样使用RMSProp优化器,学习率同为10-3。
(4)损失函数:该模型主要使用的是数字编码,因此使用的损失函数为sparse_categorical_crossentropy交叉熵损失函数,它与categorical_crossentropy一样都是用于衡量真实分布与训练分布的差值,只不过前者接收数字编码,后者接收one-hot编码,在此不赘述公式。
(5)模型训练:通过以X作为三层的输入数据,Y为标签,其中batch_size为128来进行为期10 轮的训练。
3 文本自动生成技术对比与分析
文本自动生成技术主要采用两种深度学习方法进行实验对比,分析结果如下。
3.1 数据来源
文本自动生成训练数据由电力公司A提供,主要提供的数据集是日常撰写的电力报告,根据已提供的数据,进行模型训练,实现文本自动生成。
3.2 实验过程
本文中,分别分析了基于LSTM和GRU的文本生成方法,在LSTM和GRU的算法中,使用相同的初始句:在较多高度重复的手工操作,耗费大量的人力和时间。手工处理存在,但可以从结果中看到,基于LSTM的模型输出的结果可以生成一些连续的句子,但这些句子不通顺,如表1所示。这可能是因为LSTM更适合运用在长结构网络中的训练,能保证信息不被丢失,但由于存在许多相似的句子,以及这些句子的上下文语境并不相同,模型容易越走越歪。
其中,LSTM模型输入输出如表1所示。

表1 LSTM模型输入输出
而基于GRU的正反序列算法是在LSTM基础上进行改进得来,GRU花费的时间成本更低,同时对硬件计算能力的要求也更低,参数较LSTM也更少,可能正是这些原因,在实验结果中,GRU算法结果中出现的非汉字也更多,句子更不通顺,如表2所示。

表2 GRU正反序列模型输入输出
3.3 评价指标
由于生成的文本是供人阅读的,所以评价的直观方法是人主观来评价句子是否通顺、合理,较片面。所以本文还另外采取程序化的评价方法,从多方面对算法作用的效果进行对比[10]。
(1)BLEU指标
BLEU是由ⅠBM公司Kishore Papineni等人在2002年对机器翻译的结果进行评价时提出的基于文本相似度的评价指标,原理是计算待评价译文和一个或多个参考译文间的距离。距离是文本间n元相似度的平均,n=1,2,3(更高的值似乎无关紧要)。也就是说,如果待选译文和参考译文的2元(连续词对)或3元相似度较高,那么该译文的得分就较高。BLEU指标计算如下式:
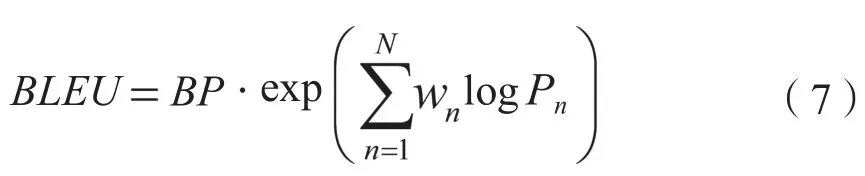
其中,BP表示惩罚项因子,乘法右边表示n-gram精度的几何加权平均,N一般取值为1~5,表示n-gram的权重,取值为
式(7)中惩罚项因子BP的取值如下:
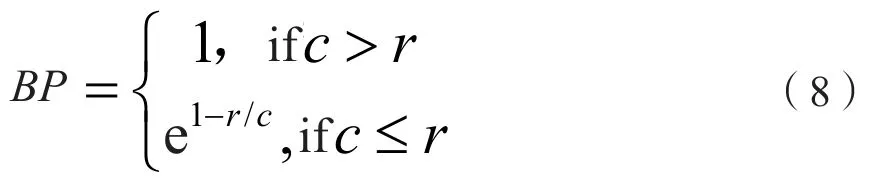
两个算法实现效果的BLEU指标对比结果如表3所示。
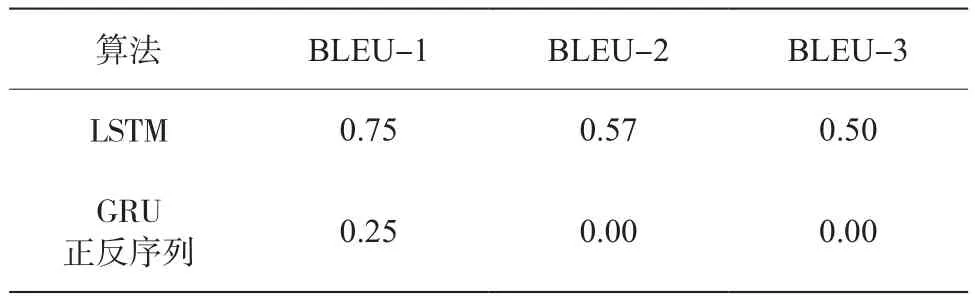
表3 生成100长度文本的BLEU指标对比
结果表明,简单的LSTM算法比采用正反序列融合训练的GRU算法效果更好,这里可能是因为LSTM模型一开始输出的内容同输入内容一样,导致得分偏高,所以单靠自动化指标评价并不完善。
(2)人工主观评价
对于两个模型分别30 次输出的语句进行人工打分,以语句通顺和上下文相关为标准,进行人工评估,结果如表4所示。
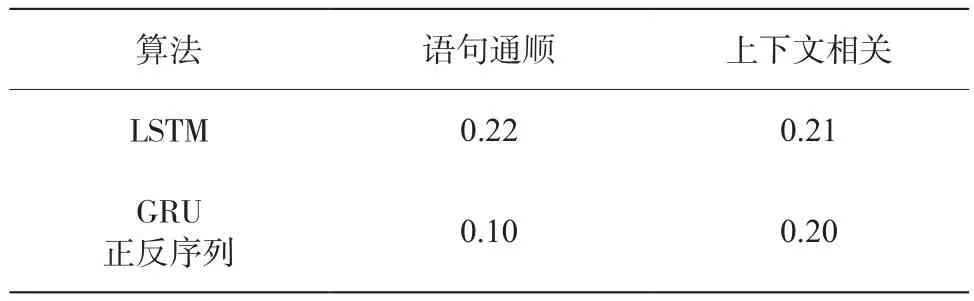
表4 人工评测对比
4 总结
本文通过系统地分析文本自动生成问题的特点,提出了财务机器人自动撰文的问题,采用深度学习算法解决文本自动生成问题。由上述结果可知,直接采用LSTM神经元堆叠的办法比GRU采取句子正反序列训练更为简单,可以有效地处理文本连续动作集的问题。因此,深度学习算法对文本自动生成具有重要意义。
5 展望
如果用小说作为语料库来训练以上的神经网络,生成的文本语句语义将更加连贯,语句将更加通顺。而采用电力公司A的多篇报告拼凑成的文本作为语料库,训练的神经网络生成的文本效果不尽如人意。这可能是因为小说文本较通俗、连贯性强,神经网络学习的任务比较简单。而电力报告语义紧凑,用词比较专业化,做数据工程的时候也没有把各种序号、非语义的间隔符号除去,数据比较烦琐。
因此,本研究可进行以下改进:
第一,清洗数据,保留报告中语句通顺的部分,剔除无关符号。
第二,通过一句话来生成一段文字报告难度太大,通过若干关键词来组合生成句子可能生成效果更好。
