基于可控重连的Tor流量隐蔽
2021-04-15徐婉冰王轶骏姜开达
徐婉冰 王轶骏 薛 质 姜开达
(上海交通大学网络空间安全学院 上海 200240)
0 引 言
随着计算机网络的快速发展,暗网的规模也快速增大。暗网在广义上指无法被搜索引擎收录内容的站点,目前最流行的访问暗网的方法是Tor[1]。Tor是一种暗网协议,通过在Tor网络的入口和出口节点间随机选择若干匿名中继节点建立加密链路,实现类似洋葱的逐层加密网络。
由于Tor具有双向匿踪特性,即消息的发送者和接收者无法知道彼此的IP地址,它可被用于抵御网络监控、分享私密信息、浏览被禁网站等,因此一些国家或企业会禁用Tor,最直接的方法是封锁Tor目录服务器和所有已知节点的IP。为了应对IP封锁,诞生了Tor bridge(网桥)[2],它本质是Tor的入口节点,部署在不受监控的区域。由于官方不会公开完整的bridge列表,所以ISP无法彻底封锁bridge。
然而审查者仍可以基于TLS handshake的指纹特征检测Tor流量及其他可疑流量[3]。对此,研究者们提出了Pluggable Transports(PT),一种用于隐藏Tor流量的网桥工具。PT连接Tor客户端和Tor网桥,通过混淆和伪装等手段,使Tor流量看上去是普通的协议,从而躲避检测。
当前,国外对于PT流量检测的研究主要从熵检测、语义分析和机器学习三方面开展,检测的目标以Tor官网建议的Meek[5-7]、Obfs系列、FTE系列为主,在理想环境下都能以较高准确率进行识别。相比检测,近年来几乎没有新的流量隐蔽方案。同时,国内对Tor流量隐蔽问题[4]整体缺乏研究。本文主要贡献如下:
(1) 研究了已有的PT方案,分析了常见检测方法的优缺点;
(2) 不同于以往仅对通信内容加以混淆伪装的隐蔽方案,本文创新性地提出了在TCP层面修改连接特征的流量隐蔽思路,表明依赖连接时长和连接数量作为特征的机器学习检测算法是存在弱点的;
(3) 设计了基于TCP转发的可控重连算法,实验分析了该算法对连接时长和数据包大小的影响,为后续隐蔽信道的检测和研究提供了新的方向。
1 PT方案及其检测
PT通过对Tor流量进行混淆、加密、伪装成正常协议的字段等方法,消除Tor流量的特征。PT方案和其检测方法介绍如下。
1.1 Meek
Meek的原理是以未禁的协议作为隧道使隧道内的Tor流量通过。它采用了域前置(Domain Fronting)技术[8],利用HTTPS和CDN绕过审查。Domain Fronting指的是在DNS请求数据包和TLS的SNI字段使用未被禁止的前置域名,而在HTTP Host头部字段使用被审查者禁止的隐藏域名。审查者只能看到前置域名,而看不到被TLS加密的HTTP中的域名。数据包到达前置域服务器(比如CDN)后,服务器解密数据包,并将其转发到隐藏域。Meek的原理如图1所示。
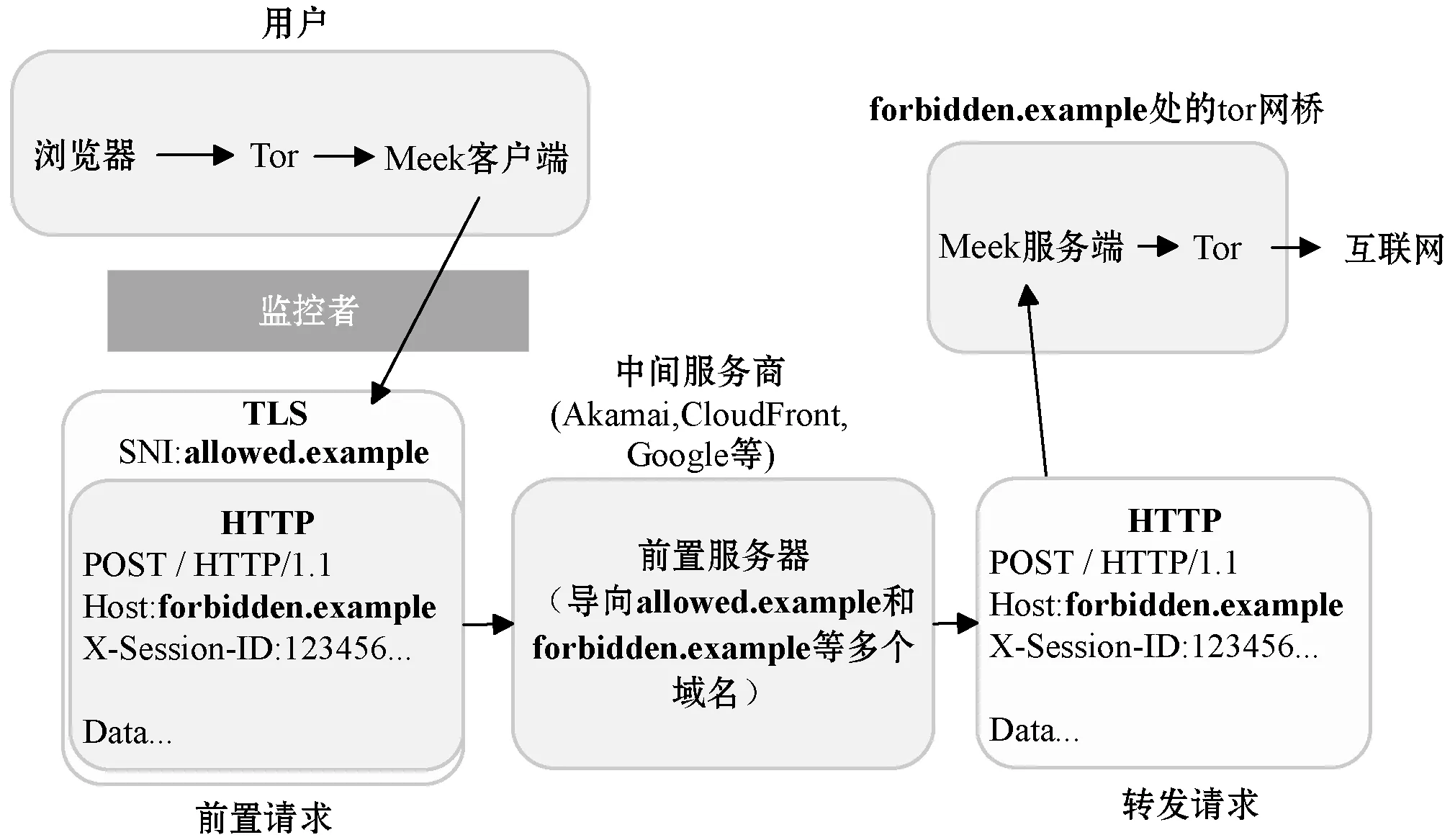
图1 Meek原理图
针对Meek的检测以机器学习为主。Shahbar等[9]通过C4.5决策树分类器,分析连接的时间跨度、连接的数量和重复性、传输数据量和建立的连接的数量,或者包大小、发出的字节数、最大的包大小[10],进行学习后可以识别出Meek流量。Fifield等[5]指出,正常HTTPS和Meek的TCP连接的总持续时间不同,TCP payload长度分布比例也不同。Cuzzocrea等[11]采用state-of-the-art算法(包括J48、J48Consolidated、BayesNet、jRip、OneR、REPTree法)研究了Tor流量分类问题。此外,Meek的熵值特性[12]在机器学习的检测中也有一定效果。
除了连接相关的特征外,呼吸包也是Meek的一个特点。Meek无法由服务器主动推送消息给客户端[12],客户端为了获取数据必须主动向Tor网桥发送大量心跳数据包,55%的TCP ACK包间隔小于10 ms,基本上间隔都小于1 s。
1.2 Obfs系列
Obfs系列包括Obfs2、Obfs3、Obfs4[13]和Scramblesuit[14],目前最常使用的是Obfs4。其原理是对Tor流量加密,使之看起来像随机字节,避免基于黑名单的指纹检测。且Obfs4通过密钥协商可以对抗active-probing attacks[15],防止审查者利用连接发现网桥。
在检测方面,Wang等[12]发现基于熵的检测和简单启发式算法(如长度检测)进行联合检测可以识别Obfs流量。熵值的计算公式是:
(1)
式中:pi表示第i个字符出现的频率,即该字符出现的次数除以总的字符数。熵的大小可以反映出一个数据包的字符分布是否正常。由于Obfs系列直接对传输的内容进行加密,因此整体流量都有着较高的熵值。而正常的协议,包括如TLS这样的加密协议,在握手时往往有着熵值更低的明文头部。检测者可以对应用层第一个数据包的前2 048个字节使用熵检测,实现对Tor的拦截。其他检测方法还包括数据包长度检测和截尾序贯概率比检验(truncated SPRT)[16]等。
1.3 FTE系列
FTE系列包括FTE(Format-Transforming Encryption)[6,17-18]、Stegotorus[19]、SkypeMorph[20]、CensorSpoofer[19]、Marionette[21]等。其原理是通过模仿其他协议的格式,使审查者对流量错误分类,从而达到躲避审查的目的。FTE通过简单模仿HTTP流量的格式躲避审查;Stegotorus在Obfs的基础上对包切分,改变包大小和时间、建立多个连接,并采用隐写技术,模仿HTTP、Skype、Ventrilo等合法流量;SkypeMorph伪装成Skype视频流量;Marionette在FTE的基础上加入带有随机性的状态转移,使之对于HTTP协议的模仿更逼真。
FTE只是简单模仿协议的格式,并没有模仿协议的语义。所以,Houmansadr等[22]提出了基于语义的方法,检测流量与预期行为之间的差异,比如服务器能否正确返回404错误等。
另一方面,由于FTE的URI字段是直接加密形成的,所以也可以通过熵检测[12]来识别FTE流量。相比正常HTTP包中的可见字符及英文单词,FTE伪装的HTTP包有着更高的熵值。
1.4 检测技术汇总
检测技术[23]主要可以分为以下四类:(1) 基于语义的检测;(2) 基于熵值的检测;(3) 基于机器学习的检测[24];(4) 基于DPI与防火墙的组合检测[25-26],可以重建完整数据流,分析具体协议,对数据包进行关键字识别,并主动探测可疑服务器,避免误报。这四类检测技术中,基于熵值和DPI的检测本质都是对数据包的内容进行分析,因此PT在进一步完善后(例如冗余处理)可以针对性地绕过它们的检测;基于语义的检测本质是对客户端与服务器的交互过程进行合理性判断,PT同样可以在精心完善后实现绕过;而基于机器学习的检测由于分析的是TCP连接层面的特征,层次更低,改变特征就更加困难,因而这种检测正在逐渐成为主流的检测手段。本文针对这种TCP层面的检测提出了可控重连算法,通过修改TCP连接时长和包大小分布,从而形成可定制的TCP连接特征。
2 流量隐蔽架构
图2为Tor流量隐蔽系统的部署结构,系统部署在Tor客户端的下层,包括PT客户端和PT服务端,充当类似Shadowsocks的角色。用户、Tor客户端、PT客户端位于被审查的区域内,而PT服务端和Tor网络位于审查区域外。
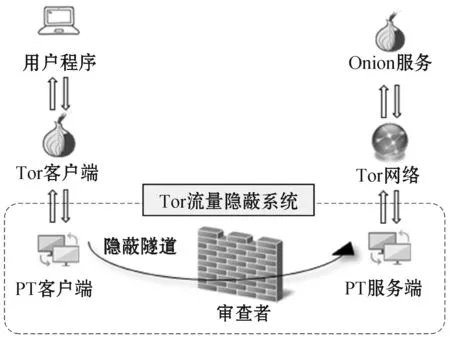
图2 系统部署示意图
为了方便后文描述算法,图3展示了请求数据的流向,响应数据反之亦然。
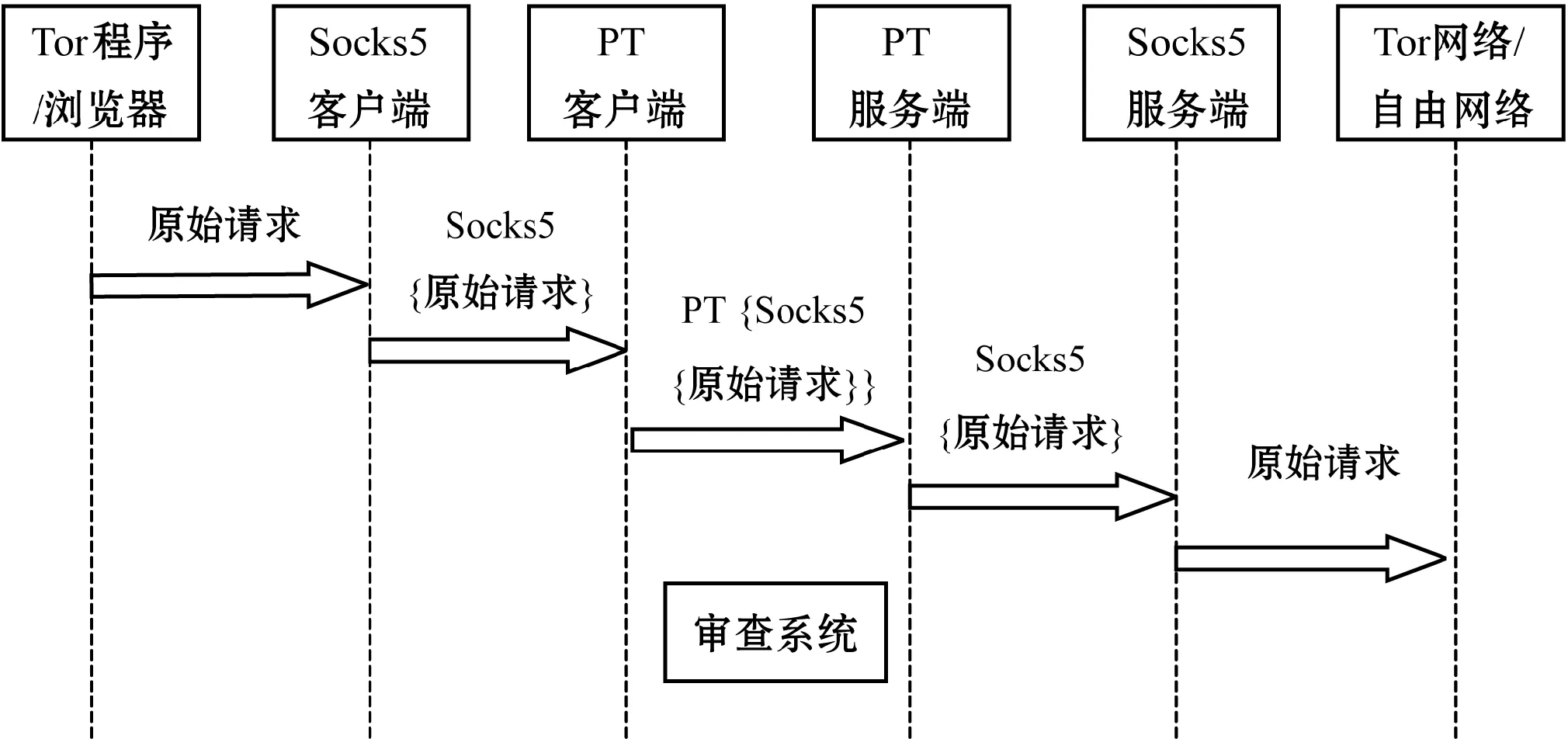
图3 请求数据流示意图
Tor程序(不使用Tor时,浏览器产生常规HTTP/HTTPS请求)将原始请求提交给本地Socks5客户端代理;Socks5客户端再以Socks5协议的格式交给PT客户端;随后PT客户端在{Socks5{原始请求}}的TCP流基础上,加上流量隐蔽系统PT的封装,绕过审查系统到达PT服务端;之后PT服务端恢复出{Socks5{原始请求}};最后同在代理服务器上的Socks5服务端解析Socks5请求并转发到Tor网络或目标网站。
3 可控重连算法
根据Tor官方的文档[27],Tor采用连接复用,在Tor代理中对多条TCP连接使用同一条TCP连接,因此连接时长比一般通信更长。机器学习检测算法往往把连接时长和数据包大小等作为重要的检测指标。由此本文提出了可控重连的算法。一方面,从TCP重连的角度,自定义PT客户端与PT服务端之间的连接时长;另一方面,从数据包大小可控的角度,基于已有数据包的分布比例,计算转发数据包的大小。
3.1 重连算法
图4显示了TCP重连的基本过程,涉及以下三个重要阶段。

图4 新旧连接示意图
1) 新连接的建立。Tor建立新链路或浏览器产生新请求时,Socks5客户端与PT客户端建立连接x,随后PT客户端与PT服务端建立连接a,PT服务端也与Socks5服务端建立连接y。在后续的重连过程中,连接x和连接y保持不变。
2) 重连的握手。PT客户端到达预期连接时长后启动重连,暂停向PT服务端的数据发送,对PT服务端新建连接b,并协议握手告知PT服务端,新连接b即将替换旧连接a。
3) 旧连接的挥手。PT客户端发送FIN包关闭旧连接a,服务端也发送FIN关闭连接a后,两者正式改用新连接b来通信。
为了兼顾转发效率,PT服务端的主线程负责接收PT客户端的新连接请求,而各个子线程(或称“转发线程”)负责进行PT客户端与Socks5服务端之间的双向转发。
多线程的使用会导致同步问题,例如主线程中新连接b建立的同时,PT服务端的子线程可能正在进行旧连接a上的数据收发。因此,PT服务端不可能在新连接b建立后,立刻完成从a到b的新旧替换,所以连接a中剩余数据的读取和连接a的完整关闭需要按照TCP四次挥手的原理进行设计。
本文的重连算法中,对于旧连接a,PT服务端在第三阶段收到的来自PT客户端的FIN包,标志着从PT客户端到Socks5服务端方向的数据流动的停止;而PT客户端收到PT服务端回复的FIN包后,才标志着从Socks5服务端到PT客户端方向的数据流动的停止。此后,双方的转发才正式使用新连接b进行。
重连算法的关键是PT服务端需要正确鉴别PT客户端在对其建立/关闭连接时的意图,区分来自PT客户端的新连接请求/FIN包,是重连过程中新旧连接的切换所致,还是Tor/浏览器在进行常规连接的建立/关闭。
对此,本文算法的核心是,PT服务端维护一个全局map,以连接y的描述符作为key,再以与PT客户端当前连接的描述符作为value。第一阶段建立连接a时,PT服务端就将连接y的信息(即key)告诉PT客户端,那么在第二阶段PT客户端建立新连接b时,只需将连接y的信息反馈给PT服务端,就可以使其知道新旧连接a与b的对应关系,进入重连流程。从而,当PT服务端的转发线程收到关闭连接的请求时,也可以通过查询value是否改变,判断当前是否正处于重连流程中。另外,PT服务端使用了全局互斥锁,确保握手过程不会在多线程运行中被其他连接信息或重连过程打断,也避免了map的读写相关性问题。
图5描述了阶段1的连接建立过程,关键步骤③、步骤⑤实现了PT客户端与PT服务端之间传递连接y的信息。

图5 新连接的建立
图6描述了阶段2(步骤①-步骤③)的重连过程和阶段3(步骤④-步骤⑤)的旧连接关闭过程。
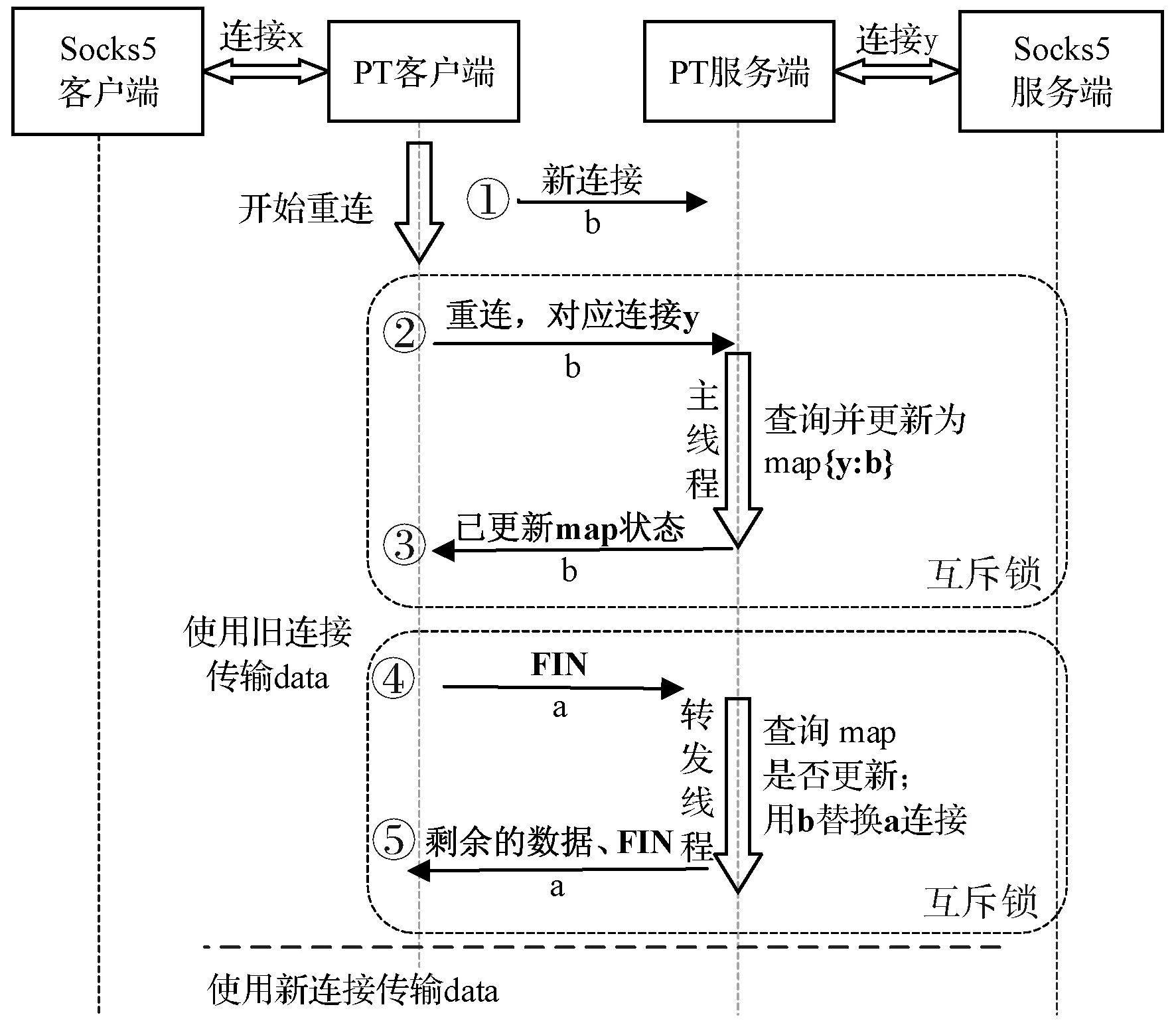
图6 重连握手和旧连接挥手
为了使描述更清晰,以PT服务端主线程处理来自PT客户端的连接请求为例,算法1给出了图5(步骤②-步骤⑤)和图6(步骤①-步骤③)PT服务端的伪代码。
算法1PT服务端的main函数
输入:收发PT客户端。
输出:Socks5服务端的流量。
top:
1. conn_PTc←accept_conn_from_PT_client()
2. mutex_lock()
3. handshake_msg←recv_from_PT_client()
4.ifhandshake_msg=NEW_CONNthen
5. conn_Ss←connect_Socks_server()
6. //为双向数据传输创建线程
create_thread(conn_PTc,conn_Ss)
7. add_to_map {conn_Ss:conn_PTc}
8. tell_PT_client(info=conn_Ss)
9. mutex_unlock()
10.else
//重连握手
11. //从msg里提取conn_Ss信息
conn_Ss←extract(handshake_msg)
12. old_conn_PTc←query_map(key=conn_Ss)
13.ifconn_PTc≠old_conn_PTcthen
14. //用current conn_PTc替换旧值
renew_map {conn_Ss:conn_PTc}
15. tell_PT_client(MAP_RENEW_OK)
16. mutex_unlock()
17.elseerror()
18.endif
19.endif
20.gototop
3.2 可控算法
数据包可控算法研究了在已知正常流量的数据包大小分布的情况下,如何改变转发数据包的大小,使其与正常流量相似。由于改变一个数据包大小的方式只有拆分和冗余两种,故算法的目标是在使转发数据包大小符合正常流量分布比例的同时,尽可能减小拆分和冗余对信道与时间的浪费。
设通过抓包等前期手段,已知一段时间内正常流量的数据包大小分布如图7(a)所示,大小在ci-1~ci范围(记为区间i)的有yi个数据包(共n个区间),当前待转发的原始数据包大小为x,算法完成后实际发送的称为结果数据包。
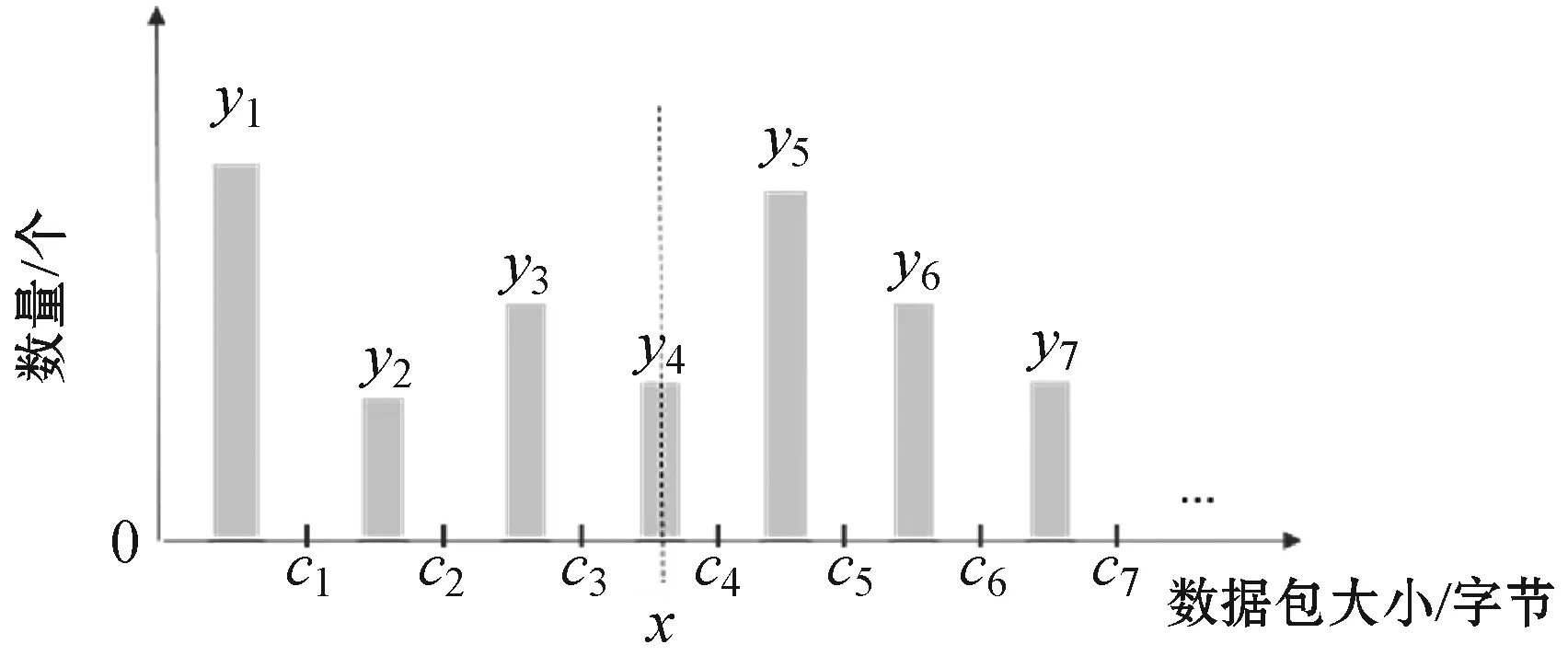
(a) 正常流量的数据包大小分布
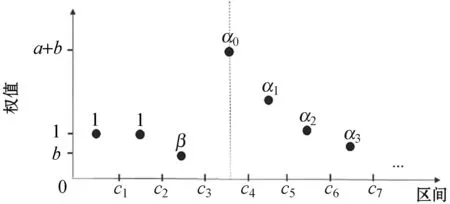
(b) 权值序列与当前数据包的关系图7 当前数据包与正常流量分布和权值序列的关系
算法需要考虑如下几点:(1) 结果数据包的大小分布应当接近正常流量数据包的大小分布,同时要保持一定的随机性;(2) 为了节省信道资源,需要适当减少拆分和冗余次数;(3) 如果要冗余处理,应当避免结果数据包的大小和原始数据包相差过多,比如原始数据包大小在区间i内,那么同样条件下计算结果数据包在区间i+1的概率应当比在区间i+5的概率大;(4) 如果要拆分,将一个数据包拆成比原始数据包略小的包意义不大,反而造成浪费,所以假设原始数据包在区间i内,那么结果数据包在区间i-1的概率应该适当减小。
根据上述要求,算法的过程如下:
1) 找到x所属的大小范围xi∈[ci-1,ci),即区间i。
2) 根据i,对表示正常数据包大小分布的y序列乘以一定权值得到y′序列,用来计算临时概率:
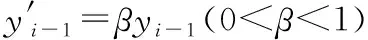
(2)
3) 根据y′序列,按概率生成结果数据包所属的区间i′,例如结果数据包仍在i区间的概率为:
(3)
随后根据i′和i的大小关系决定拆分或者冗余:
(1) 如果i′等于i,则直接发送,无须处理;(2) 如果i′落在大于i区间,表明结果数据包比原始数据包大,应加冗余;(3) 如果i′落在小于i区间,则需要拆分成两个包,计算原始数据包和预期结果数据包大小的差值,得到预期结果包1(区间i)和差值结果包2(由差值确定)。由于差值结果包2并不是主动计算概率得到,而是被动生成的,所以在对应区间的y序列值减1,减小后续数据包落入该区间的概率。
算法中值得关注的是β和α序列的取值,如图7(b)所示,假设原始数据包x在c3~c4范围,计算y′序列时的权值序列应当如图中那样,β应小于1,减少不必要的拆包;α序列应当是递减序列,在α0处是最大值,并逐渐趋近于一个略小于1的值b。本文算法中,α序列采用式(4)得到,其中Δi指区间序号与原始数据包所属区间i的差值:
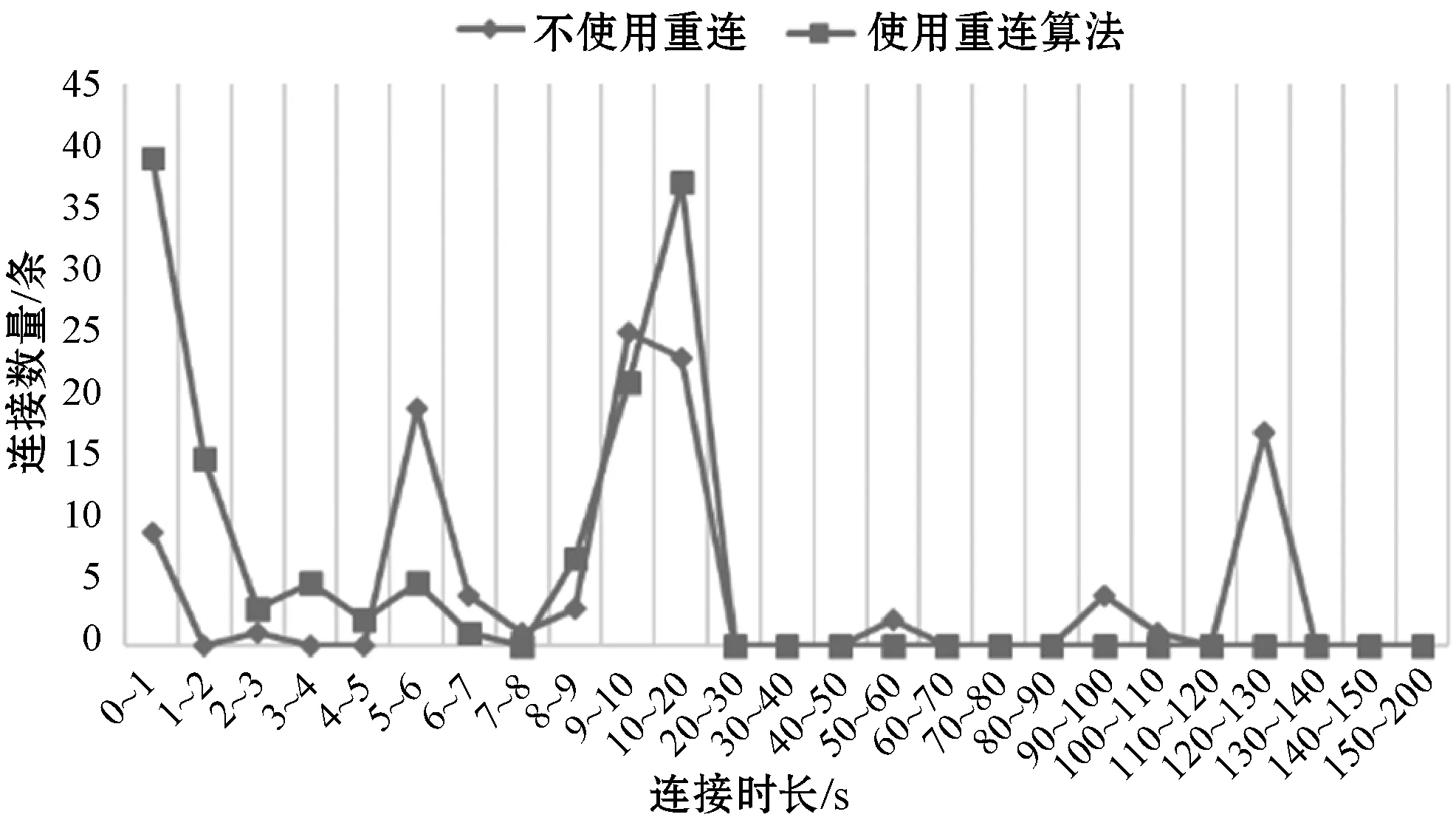
αΔi=ae-Δi+b(a>1,0 (4) 即α0=a+b,α1=ae-1+b,α2=ae-2+b,…。 由此得到算法第2步中计算y′序列时的权值。 算法2描述了生成结果数据包的大致过程。 算法2根据正常数据包大小生成结果数据包 输入:原始包大小before_size;分布序列y在区间i有yi个正常数据包;参数β、a、b。 输出:{after_i,another_i},结果数据包所属的区间(假设共有N个区间)。 1. before_i←before_size.region() 2.y′ ←deepcopy(y) 4.forj=0:N-before_i-1do 6.endfor 7. //根据y′序列和随机值产生结果数据包的区间 after_i←rand_region(y′) 8.ifafter_i=before_ithen 9.return{after_i,None} //直接发送 10.elseifafter_i>before_ithen 11.return{after_i,None} //加冗余 12.else //拆分成两个数据包 13. another_i←calc_difference_i(before_size,after_i) 14. //因被动产生的结果包调整y序列 y.adjust(another_i) 15.return{after_i,another_i} 16.endif 根据可控重连算法,分别针对连接时长和数据包大小的计算进行了如下实验。 图8对比了重连前后的连接时长。实验在局域网的两台主机上完成,主机1访问视频网站(2分钟视频)产生连接时长超过10 s的原始流量。使用重连算法时,主机1部署PT客户端(PT客户端对超过10 s的连接启动重连),主机2部署PT服务端,配合PT客户端实现重连。 图8 重连前后的连接时长对比图 可以看出,不使用重连时,存在超过10 s的连接,最长的持续了整个实验过程;而使用重连算法后,时长在10~20 s范围的连接数量增加(实际上时长集中于10 s左右,且都小于11 s),超过此范围的连接数量为0,实现了秒级精度的控制,表明重连算法取得了理想效果。 图9对比了数据包大小可控算法前后的数据包大小与累积分布函数CDF的关系,实验中参数β取0.6,a取2,b取0.8。为使仿真结果更贴近实际,实验中原始数据包CDF的来源为3分钟内访问YouTube视频的Tor下行流量,正常流量CDF来源为3分钟内直接访问YouTube视频的下行流量。 图9 数据包大小可控算法结果图 可以看出,原始数据包和结果数据包的比例分布在大于1 280字节时有较大不同,而结果数据包和正常流量分布的折线非常接近,说明可控算法对原始数据包的大小进行了有效调整。 可用余弦相似度进一步分析结果流量与正常流量的接近程度,给定两个序列A和B,其余弦相似性θ由点积和向量长度给出,越接近1表示越相似: (5) 表1给出了不同β、a、b取值时的结果包数量、总计冗余次数、总计冗余跨度(比如原始包在区间i,结果包在区间i+3,则冗余区间跨度为3)和相似度值。原始数据包数量为7 741个。 表1 不同β,a,b取值的结果数据包 以β取0.6、a取2、b取0.8为例,约8%的数据包经历了拆分,不到一半的数据包经历了冗余处理,平均每次冗余跨1至2个区间,这样的拆分和冗余处理是可以接受的,同时相似度也较高,达到了预期需求。表1中,β取值无明显的影响;a的增大会减少拆分和冗余情况,但会降低相似度;b的增大会减少拆分,增加冗余,提高相似度;若不考虑权值因素(即表中最后一行)直接按照正常流量的分布比例计算概率,会导致更多的拆分和冗余出现。 本文分析了已有的Tor隐蔽方案和对应的检测算法;针对TCP连接层面的Tor流量特征提出了一种新的流量隐蔽思路;通过可控重连算法实现了对TCP连接时长的控制;研究了调整数据包大小使其符合正常流量数据包大小分布的方案;为流量隐蔽的研究提供了新方向。 在本文基础上,未来可从以下两个方向开展进一步研究:(1) 高丢包率的网络环境会影响TCP连接的数据通信和四次挥手,使连接时长超过预期。未来可以研究恶劣网络环境的优化重连算法,除了从重连协议的角度进行设计,也可以引入对历史实际重连时长的统计,计算重连计时的提前量。(2) 研究不同应用在连接时长和数据包分布上的规律,设计能够定制连接特征的可控重连算法。将优化后的算法部署到海外云服务器上,加上基本的混淆功能,测试实际Tor流量和伪装后流量的差别。4 实 验
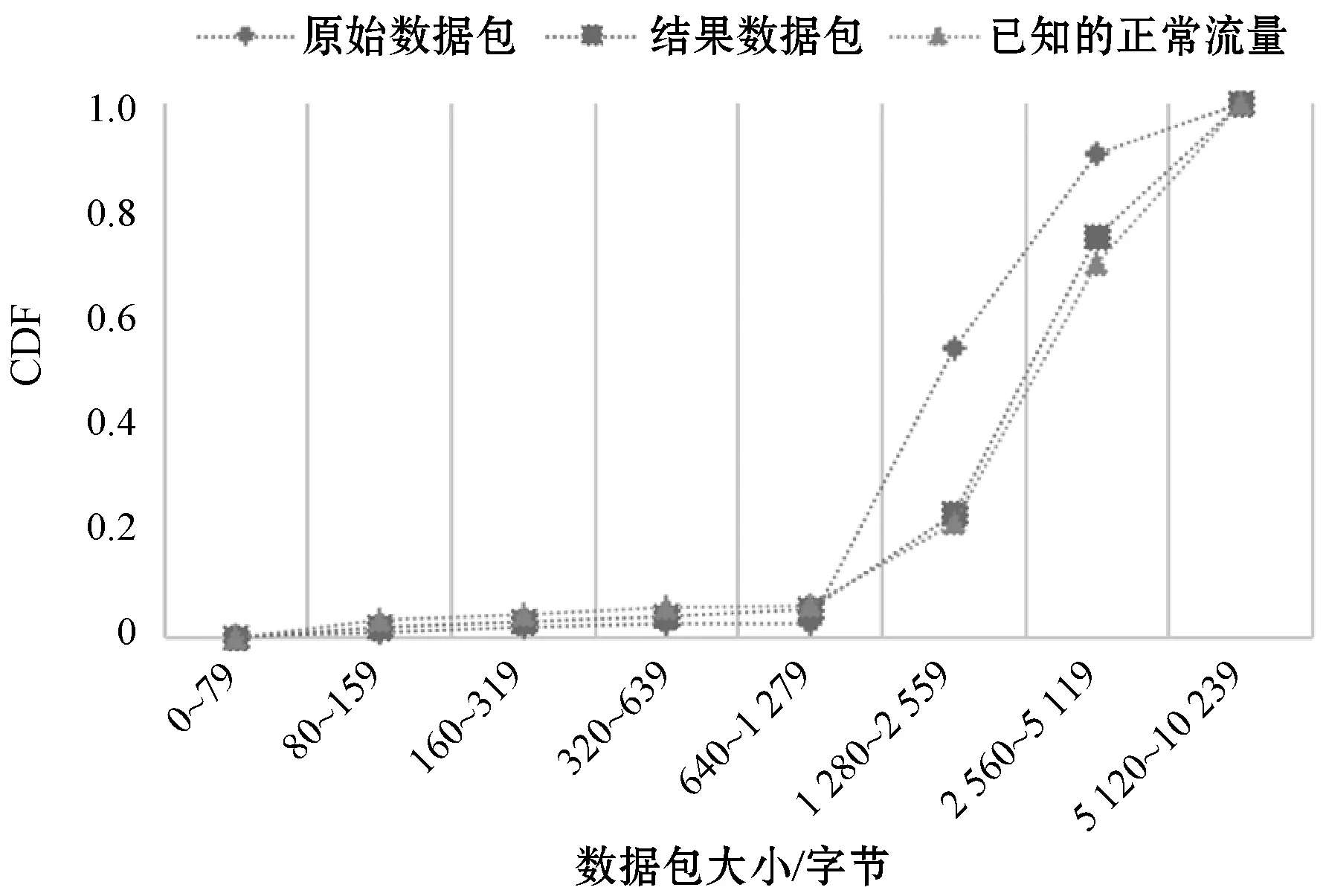
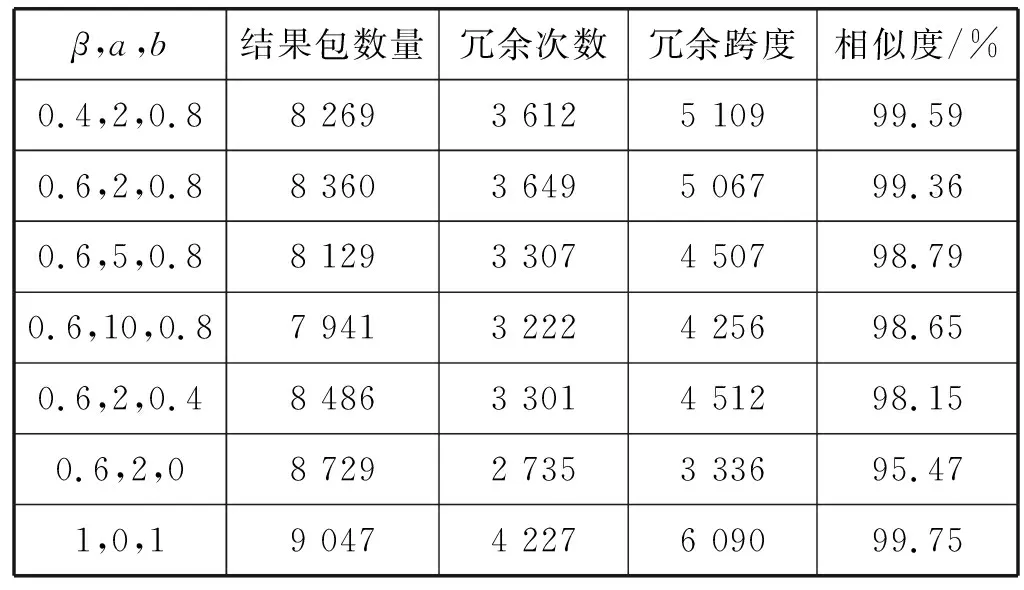
5 结 语
