一种子孔径ωK聚束SAR成像算法的GPU实现
2021-04-15陈家瑞
司 军,陈家瑞
(中国船舶重工集团公司第七二三研究所,江苏 扬州 225101)
0 引 言
合成孔径雷达(SAR)是一种高分辨率成像雷达,相比光学和红外遥感成像,其全天时、全天候和透射性强等特点在军用和民用领域发挥着重要作用[1]。随着SAR成像技术的不断发展,对分辨率提出了更高的要求,因此SAR回波数据量更大,成像算法更复杂,传统基于CPU的处理已经无法满足成像需求。
近几年,图形处理器(GPU)发展迅速,其拥有强大的浮点计算能力和很宽的存储器带宽,为大规模SAR数据处理与分析提供了新的运算平台。2007年,计算通用设备架构(CUDA)发布。CUDA的出现为充分利用GPU的强大性能提供了条件。CUDA对图形硬件单元和应用程序编程接口(API)进行了封装[2],开发人员不需要太过关注图形学硬件和编程接口,只需在掌握了GPU架构和并行算法的基础上使用类C语言进行开发,这大大简化了编程过程。SAR成像处理的步骤主要包括快速傅里叶变换(FFT)/逆快速傅里叶变化(IFFT)、复数相乘和插值等,都具有高度并行性,因此可以利用GPU强大的并行处理能力来实现算法的加速。当前支持 CUDA 技术的GPU 产品的显存一般不超过6 GB,尚不能对大场景SAR数据进行一次性处理,因此需要对其进行分块操作[3]。
本文以Omega-K算法为基础,通过研究聚束模式SAR成像特点,提出了一种针对GPU加速处理的子孔径成像处理方案。该方案将全孔径划分成若干个子孔径,然后在GPU上分别成像,最后将子图像相干融合以获得高分辨率图像。
1 子孔径ωK算法
子孔径的划分主要是依据脉冲重复频率(PRF)和多普勒带宽之间的关系[4]。由于聚束式SAR是通过天线长时间照射成像区域来获得更长的相干积累时间,因此其多普勒带宽也相应变大。为了避免方位频谱出现混叠,必须满足PRF大于多普勒带宽。
如图1所示为子孔径ωK算法中每个子孔径的处理流程。将回波数据根据PRF与多普勒带宽之间的关系划分为若干个子孔径,并分别成像。子孔径处理时,需要通过补零来扩展方位处理长度。每个子孔径的处理过程包括以下步骤:
(1) 通过二维FFT将SAR回波数据转换到二维频域。假设距离方程是双曲形式,则距离R0处的点目标的相位为:
θ2df(fτ,fη)=
(1)
式中:fτ和fη分别为距离和方位频率变量;f0为雷达中心频率;c为光速;Vr为雷达有效速度;Kr为距离chirp调频率。
实际处理中,在方位向FFT后会乘以补偿相位φ1(t),使得后续处理中产生的移位引起的方位处理长度展宽最小化[3]。
φ1(t)=exp(-j2πfdcη)
(2)
式中:fdc为多普勒中心频率;η为方位时间。
(2)第1个关键聚焦步骤是参考函数相乘(RFM)。参考函数根据选定的距离Rref来计算。经过参考函数相乘,参考距离处的目标得到了完全聚焦。经过RFM滤波后,二维频域中的残余相位近似为:
θRFM(fτ,fη)≈
(3)
(3) 第2个聚焦步骤是Stolt插值。它在距离频域通过插值操作完成其它目标的聚焦:
(4)
为了更好地理解Stolt插值,上式等号左边的根号项可以根据泰勒公式展开得:
(5)
(6)
(4) 通过距离向IFFT转换到距离多普勒域。在距离多普勒域,采用方位向Scaling与谱分析结合[5]的方式,乘以方位Scaling因子:
(7)

再通过方位向IFFT转换到方位时域。
(5) 在方位时域乘以压缩因子:
φ3(t)=exp(jπfηη2)
(8)
完成去调频操作。最后经过方位向FFT即可得到子孔径图像。
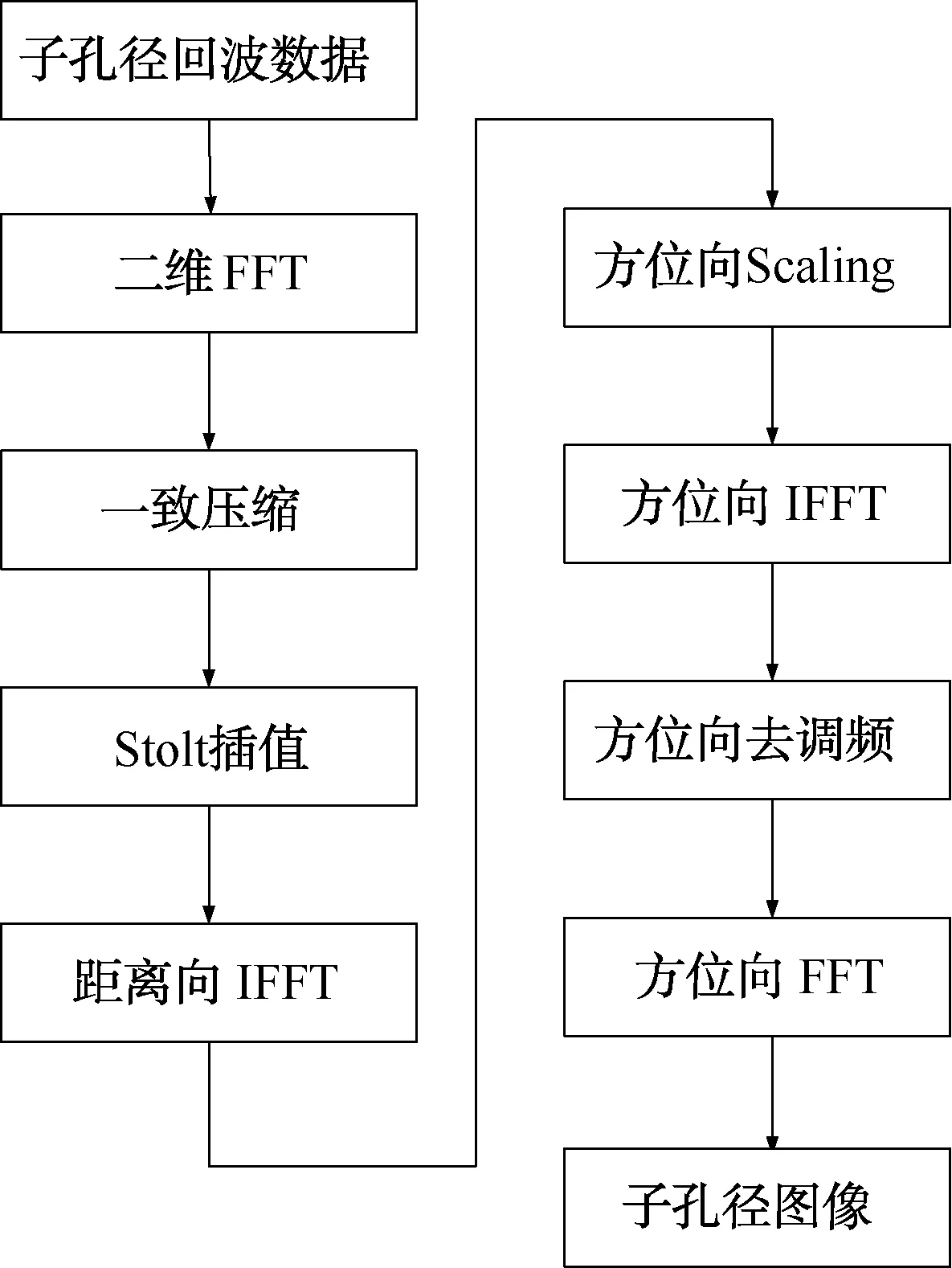
图1 单个子孔径处理流程
2 CUDA具体实现
子孔径ωK算法实质上是在CPU+GPU异构平台上完成的,CPU主要负责简单的串行计算和逻辑事务处理,GPU则专注于大规模并行化数据运算。如图2所示为CUDA环境下子孔径ωK算法的处理流程。CPU负责数据的读写和主机内存与设备显存之间的数据拷贝,GPU负责各个子孔径的成像处理。最后将图像数据拷贝到CPU进行融合获得高分辨率的图像。

图2 CUDA环境下子孔径ωK算法处理流程
子孔径ωK算法在GPU上的处理流程包括:5次FFT/IFFT,4次相位相乘和1次插值。其中5次FFT/IFFT可以通过CUDA自带的CUFFT库函数快速实现,该库对FFT以及IFFT操作能够达到很高的运算性能,其余处理需要编写对应的Kernel函数[2]实现。
(1) 距离向FFT/IFFT
首先,使用cufftHandle制定1个FFT计划plan;再利用cufftPlan1d函数创建1个CUFFT 句柄,对Na×Nr的数据分段批量实现FFT/IFFT,即cufftPlan1d(&plan,Nr,CUFFT_C2C,Na),其中Nr为距离向采样点数,Na为方位向采样点数;最后调用cufftExecC2C函数完成距离向FFT/IFFT。
(2) 方位向FFT/IFFT
由于数据都是按先排距离向存储的,因此进行方位向处理前需要进行转置处理。转置后的处理与步骤1基本相似。实现方位向FFT/IFFT后,再进行转置处理,将数据按先排距离向存储。
(3) 复数相乘
子孔径ωK算法中包含复数相乘的处理过程有:一致压缩,方位向Scaling,方位向时移,方位向去调频。
对于Na×Nr大小的数据,我们定义Na×Nr个并行线程来完成复乘操作。在CUDA中可以使用dim3类型的内建变量threadIdx和blockIdx定义一维、二维和三维的索引来标识线程。本文采用二维索引的方法,定义block的尺寸为(16,16),即每个block包含256个线程。由于采样点数通常为2的n次幂,因此不存在不能整除使得block数量为小数的情况。距离向处理时,定义grid的尺寸为(Nr/16,Na/16),总的并行线程数为Na×Nr,每一个线程独立完成1个采样点的相位生成和复乘操作。方位向处理同上。
(4) 插值
本文中的Stolt插值采用sinc插值核,卷积核为8点,实现插值的关键步骤是找出待插点位置。对于8点插值,每个脉冲左右两端各4个点无法覆盖8个点,因此在处理时令它们的值与最接近的可以实现插值的点相同,其余点根据二分法寻找待插点位置。在插值kernel函数内为每个插值点分配1个独立的线程,则8点sinc插值只需要在单个线程内完成8次循环即可完成插值操作。
待子孔径成像完成之后,在CPU端将子图像相关融合以获得高分辨率图像。
3 实验结果
本实验使用的GPU是NVIDIA Tesla C2075,硬件具体配置如表1所示。

表1 CPU与GPU型号及配置
本实验中采用的SAR仿真数据方位向大小Na为16 384,距离向大小Nr为32 768,表2是本实验用到的SAR实验数据的相关参数。

表2 聚束SAR实测数据
根据表2数据,经计算可得仿真数据的大小为4 G。本实验划分了4个子孔径,则每个子孔径的数据大小为1 G。子孔径处理时,需要通过补零来扩展方位处理长度。因此,在子孔径的方位向左右两边各补2 048个零,数据大小增加为2 G。显存上需要分配2块同样大小的存储空间,一块用来存储从主机内存拷贝的数据,一块用来存储运算处理的中间结果。另外,利用CUFFT库函数实现FFT/IFF时,会根据数据大小调用cuffftPlan1d函数来创建一个plan配置数据。以上三项的存储空间之和未超过显存大小6 G。
4个子孔径的运算时间取平均后可得,在GPU端的平均耗时为11.735 s,而同样大小数据在CPU端的平均耗时为956.796 s,速度提高约81倍。
子孔径相干融合后的点目标仿真结果如图3所示。
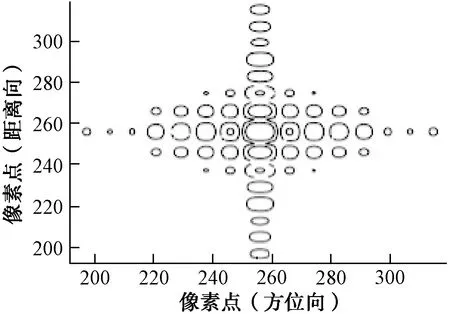
图3 子孔径融合后点目标仿真结果
下面给出实测数据相干融合后的成像结果,成像大小为4 096×4 096,如图4所示。
4 结束语
根据聚束SAR成像模式特点,本文提出了一种适合GPU加速的子孔径成像方案。首先将回波数据划分为若干个子孔径,分别进行子孔径成像,最后在CPU上将子孔径图像相干融合,获得高分辨率图像。通过对实测数据的成像处理,可以看出本文提出的子孔径成像方案可以有效地实现算法的加速。从Tesla C2075上的实验结果可见,本方案有效地解决了GPU显存小,不足以容纳大场景SAR数据的限制,且取得了良好的成像效果,与CPU上的处理速度相比,有81倍的效率提升。本文中的子图像相干融合仍然是在CPU上实现的,未来将把这一处理放在GPU上实现,实现算法的加速。

图4 实测数据成像
