An Overview of Recommendation Techniques and Their Applications in Healthcare
2021-04-13WenbinYueZidongWangFellowIEEEJieyuZhangandXiaohuiLiu
Wenbin Yue, Zidong Wang, Fellow, IEEE, Jieyu Zhang, and Xiaohui Liu
Abstract—With the increasing amount of information on the internet, recommendation system (RS) has been utilized in a variety of fields as an efficient tool to overcome information overload. In recent years, the application of RS for health has become a growing research topic due to its tremendous advantages in providing appropriate recommendations and helping people make the right decisions relating to their health.This paper aims at presenting a comprehensive review of typical recommendation techniques and their applications in the field of healthcare. More concretely, an overview is provided on three famous recommendation techniques, namely, content-based,collaborative filtering (CF)-based, and hybrid methods. Next, we provide a snapshot of five application scenarios about health RS,which are dietary recommendation, lifestyle recommendation,training recommendation, decision-making for patients and physicians, and disease-related prediction. Finally, some key challenges are given with clear justifications to this new and booming field.
I. INTRODUCTION
WITH the explosive growth of online information, it has become increasingly difficult for people to obtain highquality and valuable information. As an efficient information filtering tool to help people deal with information overload,recommendation system (RS) has been widely used in various fields, such as E-commerce, movies, music, news, and so on(more examples are shown in Fig.1) [26], [27], [44], [87]. RS has the capability to provide personalized recommendations effectively by using recommendation techniques to learn user requirements from massive user behavior data [80], [117]. At present, recommendation techniques can be roughly divided into collaborative filtering (CF), content-based filtering, and hybrid filtering methods, see Fig.2 and [3], [24].

Fig.1. Examples of different recommendation systems in reality.
The health topic has gained increasing attention from people around the world due to the rapid development of modern society and the dramatic improvement of living standards.More and more people are eager to live a healthy life and maintain a healthy body state. The modern view of health tells us that health is no longer merely the absence of disease.World Health Organization defines “health” as a state of complete physical, mental, and social well-being. On one hand, health contributes to longevity and, on the other hand,health determines the quality of life and career success to a large extent. Non-communicable diseases are currently the main killers that endanger human health. Many common noncommunicable diseases, including cardiovascular diseases,cancer, chronic respiratory diseases, diabetes, etc., account for more than 63% of the total deaths worldwide. The main causes of these diseases are occupational, environmental,dietary, and lifestyle factors. Generally speaking, most of the causes can be prevented. Behavior changes can also effectively improve the current health state.
In terms of diet, people increasingly pursue green and healthy food. In addition, physical exercise and various health checks are becoming more frequent. However, due to busy work, bad habits, lack of health knowledge, ambiguous health-related information, and other reasons, people cannot maintain a healthy life and often make wrong decisions that affect their physical and mental health. Generally speaking,although people have different views on a healthy lifestyle, it is widely believed that the key factors to stay healthy are keeping optimistic mood, healthy diet, and regular exercise.Nevertheless, some unavoidable questions are 1) how to maintain a positive mood; 2) how to make a healthy diet; and 3) how much exercise one should do every week. Clearly,health standards/requirements are different for people of different ages and genders. For different individuals, the health status they pursue is also different. Therefore, a huge challenge lies in how to provide people with scientific yet personalized suggestions that can meet their needs and help them with the maintenance/promotion/improvement of the health conditions.
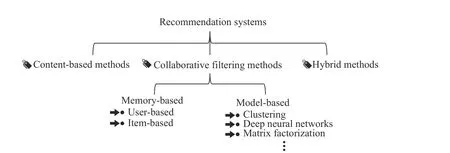
Fig.2. Different types of recommendation algorithms.
With the development of digital health, individuals and doctors are faced with a huge amount of health data leading to a significant increase in decision-making time. In recent years,RS for health has become a hot topic in the RS community[132]. Due to the unique advantages of RS and its rapid development over the decades, experts believe that RS can help individuals and doctors deal with the burden of choice that comes with information overload by providing valuable and accurate advice on, but not limited to, disease severity estimation, disease diagnosis and treatment, health management and promotion, and behavioral change [37], [63]. At the same time, applications of the RS in the field of healthcare also pose huge challenges to the RS community as never before, such as the accuracy of estimation, reliability of diagnosis, satisfaction, diversity of recommendations, etc [51], [73].
With the continuous development and deepening applications of the health RS, new application scenarios and issues are emerging one after another, which brings both new opportunities and challenges to the RS community. This paper is aimed to provide readers with an overview of different recommendation techniques and how such techniques are applied to different healthcare scenarios. To be specific, three famous recommendation techniques are first provided with a detailed explanation. Some variants are discussed for providing an overview of the evolution of these algorithms.Then, recalling the existing literature, many results have been reported on “recommendation techniques over healthcare”.Among those results, it is found that the following topics are the most investigated: dietary recommendation, lifestyle recommendation, training recommendation, decision-making for patients/physicians, and disease-related prediction. Several challenging issues of health RS are highlighted, which should be handled in an efficient manner for better design of health RS in the future.
The overall structure of this paper takes the form of eight sections, including this introductory section. Section II begins by providing a brief introduction to content-based filtering.Then, two types of CF methods are reviewed in Section III,which are memory-based CF and model-based CF. In Section IV, several forms of hybrid systems are introduced.After that, typical metrics are discussed in Section V. The applications of recommendation techniques in the field of healthcare are highlighted in Section VI. Finally, key challenges and conclusions are presented in Section VII and Section VIII respectively.
II. CONTENT-BASED FILTERING
Content-based filtering is one of the common techniques in building RS [100]. In a content-based RS, new items will be recommended to a user according to their content features similar to the items that this user has acted on [121]. The way to determine whether the user likes the item is usually based on his explicit feedback (rating) and implicit feedback(browsing/purchasing history) [148]. There is a typical example in Fig.3 to show how content-based RS works, for example, if a user has watched an action movie, then the system will suggest other action movies that the user has not watched before. Another example about how content-based filtering works in health RS is that, for food recommendation,the way to determine the similarity between foods is through their content information which could be their categories,nutritional components, and so on.

Fig.3. Illustration of content-based filtering.
The high-level architecture of content-based RS mainly has the following three components:
1) Content Analyzer (Feature Extraction): For structured information, the content features can be easily extracted [35].For unstructured information such as music or text files, preprocessing is needed to extract the content features [4]. The main function of the content analyzer is to utilize feature extraction techniques to extract content features of the items from different data sources so as to facilitate the subsequent processing.
2) Profile Learner (User Profile Learning): The user preference data is used here, including explicit feedback and implicit feedback, to build a user-specific interest model.Machine learning techniques are utilized to analyze preference data to construct accurate use profiles [64].

Fig.4. Illustration of user-based CF.
3) Filtering and Recommendation: In this step, the recommendations are given by matching the user profiles and item contents.
Content-based methods only depend on content information,so it will be affected by two aspects which are limited content analysis and over-specialization. Limited content analysis means that user information and item information in the system are limited. Over-specialization refers to the lack of differentiated recommendations.
III. COLLABORATIVE FILTERING
Since the appearance of the first papers on collaborative filtering (CF) in the mid-1990s, over the decades, CF-based techniques have not only been thoroughly studied in academia but also widely used in industrial circles such as Amazon,YouTube, and Netflix. Unlike the content-based filtering, the CF is to provide recommendations by processing a large amount of user behavior data collaboratively. CF only utilizes the user behavior data without considering the content information of the items, so it will not be restricted by limited content. As long as a user has new behaviors on different items, there are some differences in what is recommended.Therefore, CF can effectively solve the two main disadvantages in content-based filtering.

It is well known that in reality users only produce behavior on a small number of items. Take the example of the movie review site, many users may only rate a small number of movies, and these known ratings are referred to as observed ratings. Unknown ratings are referred to as missing ratings or unobserved ratings. The CF can be simply understood as estimating unobserved ratings from observed ratings. The well-known CF-based methods can be categorized as memorybased CF algorithms and model-based CF algorithms.
A. Memory-based CF Algorithms
Memory-based CF algorithms, known as neighborhoodbased CF algorithms, can be divided into the user-based CF(UBCF) and item-based CF (IBCF) approaches. Memorybased CF is a heuristic algorithm, which is simple in thought,easy to implement, and with good interpretability. The main idea of user-based CF is to analyze user behaviors to find a subset of users (named as neighbors) who are sharing similar tastes. Then, the items will be recommended to a target user based on his neighbors’ tastes. Similar to the user-based CF,the item-based CF considers the similarity between items rather than users, and then recommends to a target user those items similar to the ones that this user preferred in the past.
An example is shown in Fig.4, if two users have acted on some of the same movies, the user-based CF deems that they are the similar users. If one user has a new behavior for a movie, and then this movie will be recommended to another user. In the health RS, for the training recommendation/food recommendation, different training programs/different foods can be regarded as movies in the previous example.
1) User-based CF: The user-based CF approach is to utilize the neighbors who are similar to user u to predict the rating ru,ithat the user u is likely to give on item i by observing his neighbors’ ratings on that item. According to the above explanation, the user-based CF approach can be divided into four parts: similarity computation, neighbor selection, rating prediction and recommendation.
a) Similarity Computation: For any user, once he interacts with the platform, his behavior data is stored in the system and described as a vector. The similarity between users can be described by the distance relationship between the vectors.This part shows how to calculate the similarity between two users by different similarity measures. Some commonly used similarity measures include
Cosine:

Pearson Correlation Coefficient (PCC):

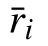
From (1) to (3), we can see that, compared to cosine similarity, adjusted cosine (AC) and Pearson correlation coefficient (PCC) do the data centralization. The difference between AC and PCC lies in the way of centralization. More specifically, AC is to subtract the average rating of all users for this item, while PCC is to subtract the average rating of all items given by the current user. Although a lot of work has proved that using PCC similarity measure can bring higher prediction accuracy, which similarity measure to choose needs to be determined according to the actual situation [21].
b) Neighbor Selection: This part selects the nearest k neighbors based on the similarity degree to make subsequent predictions. Neighbors are a group of users that similar to the target user. In a typical scenario, the number of k will be selected from the following three main methods:
i) Experience-based Method: This method is based on the previous experience. Usually, the number of neighbors is chosen between 20 and 50.
ii) Experiment-based Method: The optimal number of neighbors is selected by experiment such as cross-validation.
iii) Rule-based Method: This method usually sets a rule to help select, for example, the similarity between users should be greater than 0.5 and joint rated items are more than 3.
c) Rating Prediction: The target user’s rating of an unrated item depends on the ratings of this item by his neighbors.Assume that uais a set of neighbors of user u. The most commonly used rating prediction formula is

Comparing to the formula that takes an average of all neighbors’ ratings, (4) takes into account the effect of similarity between users on the results. Similarity can be seen as the weight of the neighbor’s rating. The greater the weight,the more important the neighbor’s rating is to the final result.The first part of the formula reflects the overall rating habit of the target user, and we can also understand this part as the user’s initial expectation for the item. Then, the second part of the formula is to revise the initial expectation by using the neighbors’ ratings.
d) Recommendation: This part ranks the items according to the size of the predicted ratings and then recommends the items with the highest ratings to the target user.
2) Tem-based CF: Later than user-based CF, in 1998, the concept of item-based CF has been proposed and used by Amazon.com [92]. Item-based CF is similar to user-based CF in terms of steps and purpose, but the starting point of their hypothesis is different. The main idea of item-based CF is that you like something similar to what you like before [128]. An example is shown in the Fig.5, if many users have watched the movie A and the movie B at the same time, the item-based CF deems that movies A and B are similar. Then, if the target user has watched movie A, the item-based CF will recommend movie B to this user. To be specific, the first step of itembased CF is to determine the similarity between items. Then,when the target user behaves toward an item, the item-based CF method will recommend similar items to him.

Fig.5. Illustration of item-based CF.
Item-based CF and user-based CF have the same procedure.There are only some differences in similarity computation and rating prediction parts. Item-based CF considers the similarity between items i and j rather than between users u and a. In the rating prediction part, in order to predict user u’s rating on item i, item-based CF is to correct the average value of all users’ ratings on i by using u’ s ratings on i’s similar items.Here, we only list similarity computation and rating prediction parts:
a) Similarity Computation: This part calculates the similarity between items. Three commonly used similarity measures are as follows:
Cosine:
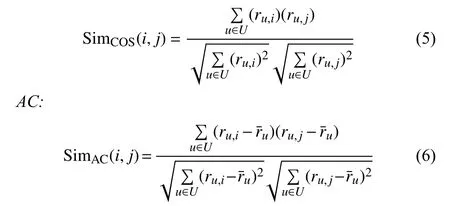
PCC:

where U=Ui∩Ujis the subset of users who have rated both items i and j , where Ui(respectively, Uj) denotes the users who have rated item i (respectively, j).
b) Rating Prediction: Assume that ijis a set of neighbors of item i. The rating prediction formula is

i) Improvements of Memory-based CF: According to the nature of the memory-based CF algorithms, it can be seen that how to choose the most suitable neighbors for the target user/item is the key factor in determining the quality of the recommendations. At the same time, low efficiency and sparsity are two major problems faced by memory-based CF algorithms. Many improved methods and novel strategies have been proposed for addressing the above problems. In the selection of neighbors, many modified similarity measures have been proposed to describe the relationship between users/items more accurately [18], [109]. Some of the work has taken into account the individual differences and rating habits in the calculation of similarity [45], [72]. Other work has discussed the excessive similarity that results from too few corating items of users [162], [170].
Aiming at the low efficiency, incremental learning has been used to alleviate the computational burden caused by too much calculation [103]. Clustering methods are commonly used to improve the efficiency of memory-based CF algorithms [46], [157], [158]. Clustering methods can also be used to help memory-based CF alleviate the sparsity problem[46], [162]. Many graph-based approaches have been proposed to alleviate the sparsity problem [36], [42]. All of the above work is about rating prediction, the related work of top-n recommendation through the memory-based CF methods can be found in [33], [114], [171].
ii) Discussions of Memory-based CF: Although both userbased CF and item-based CF predict how user u will rate the item i, the emphasis of the two methods is different. Itembased CF usually recommends items that are similar to what has been purchased or viewed. User-based CF considers the hotspots in the community. There will be many similarities between similar users, while at the same time there will be some differences, so user-based CF will recommend something novel. Item-based CF and user-based CF each have their own advantages and shortcomings. In terms of accuracy,item-based CF is usually superior to user-based CF, while in terms of variety and novelty, user-based CF is usually better than item-based CF. Therefore, user-based CF is more suitable for news recommendations, while item-based CF is more suitable for e-commerce recommendations. In terms of time complexity, the offline time complexity of UBCF and IBCF is O(m2n) and O(mn2), respectively, where m denotes the number of users and n denotes the number of items. If there are too many users in the user-item matrix, then user-based CF will be very time-consuming in calculating the similarity between users. Correspondingly, if there are too many items,then item-based CF will be very time-consuming in calculating the similarity between items. In the actual application, which algorithm should be used will depend on the specific situations of the target requirements.
iii) Memory-based CF vs. Content-based Filtering: Similarity, as defined in memory-based CF, refers to the similarity of user behavior rather than the similarity of item contents.Similarity calculations are based on either explicit feedback or implicit feedback of users. Using item-based CF to illustrate the point, item-based CF does not take content features of items into account but rather calculates the similarity between items by analyzing the user’s behavior history data. For example, historical information shows that users who give high marks to the movie “Justice League” tend to like the movie “Frozen” even though both movies are very different in content. Even so, if a user has given a high mark to Justice League, the item-based CF algorithm will recommend Frozen to him.
B. Model-based CF Algorithms
With the advent of the big data era, the volume of data is increasing rapidly. This leads to very large size of the useritem rating matrix in RS. In this case, the memory-based CF methods will consume a lot of computing resources resulting in system performance degradation. The model-based CF recommendation algorithms can provide faster training speed,occupy less memory, and obtain better accuracy in most cases.The model-based CF recommendation algorithms build a model and then predict the unknown information by training the known information in the user-item rating matrix. This is similar to the traditional classification methods in machine learning, so it can be found that many classification models are generalized to CF scenarios, such as decision tree,Bayesian classifier, support vector machine, neural network,and so on. However, it is very difficult for these classification models to do missing value prediction when the user-item matrix is very sparse. Because of its scalability and advantage in dealing with sparsity problem, the matrix factorization technique has always been favored and paid attention to by researchers. Next, the basic matrix factorization technique in RS is briefly introduced.
1) Matrix Factorization-based CF: Matrix factorization is one of the most successful techniques in RS [105]–[108].When talking about matrix factorization-based algorithms,singular value decomposition (SVD) is the first thing that comes to mind because it has been widely used in the field of mathematics for a long time. A fatal flaw in SVD is the requirement that the user-item matrix must be dense, which is far away from the practice applications. Although some methods can be used to simply fill in missing values, it is often not effective in the face of the extreme sparseness of user rating data. Moreover, when the number of users and products is very large, the computation of traditional SVD is also huge.

Fig.6. Illustration of matrix factorization.

An example of LFM is shown in Fig.6, the first user’s rating on an item (the yellow square) equals to that the latent factors of this user (the yellow row vector) times the latent factors of this item (the yellow column vector). In health RS,the items can be foods or training plans. Through LFM, the RS is able to obtain the user preferences for all foods or training plans so as to make reasonable recommendations subsequently.


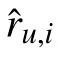

where K is the number of latent factor, pu,krepresents the value at the uth row and kth column in P and qk,irepresents the value at the kth row and ith column in Q.
The loss function is to minimize the error sum of squares(SSE) between known and predicted values


The improvement includes the addition of regularization terms to prevent overfitting due to oversize of elements inside user matrix P and item matrix Q. The equation is shown as follows:
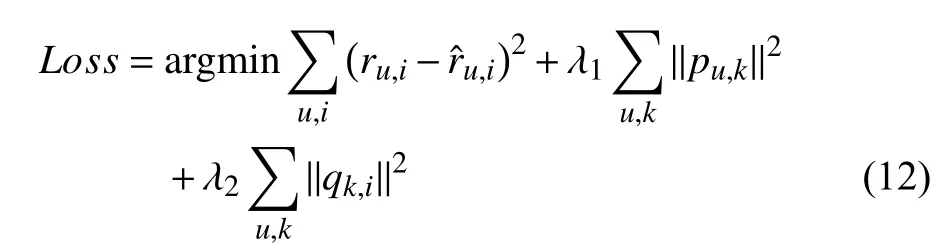
where λ1and λ2are the positive constants denoting the regularizing coefficients for user matrix P and item matrix Q respectively.
It is necessary to consider the unique characteristics of users and items themselves, for example, some users have harsh ratings and some have loose ratings, or some items have good quality and some do not. Therefore, another improvement is the addition of bias terms, and the improved prediction equation is as follows:

where σ is the average value of the matrix R, budenotes the bias of user u and biis the bias of item i. The improved loss function of (13) is
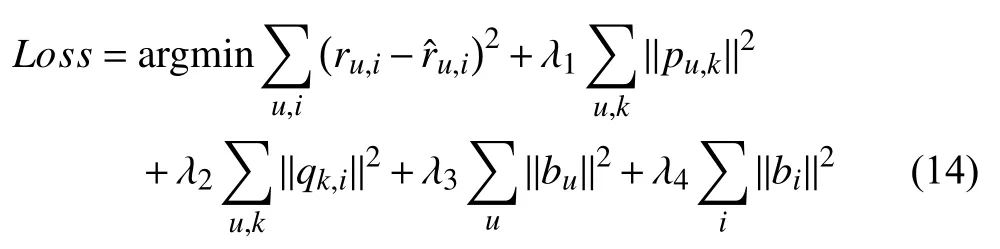
where λ3and λ4are the positive constants denoting the regularizing coefficients for buand bi.
There are many other different forms of matrix factorization models that have been applied to the RS. Koren [79] has proposed the SVD++ model which taken into account the implicit feedback of users while considering the explicit feedback. Afterward, the timeSVD++ model has been proposed to discuss the influence of time factors on user interest [81]. The matrix factorization based improvements are mainly in the prediction formula and loss function part by considering different situations [60], [84], [111]. For several common problems in RS, such as data sparsity, cold-start, and efficiency problems, many novel solutions and improved methods have been proposed for matrix factorization models[101], [102], [104], [131], [133], [155], [156], [173]. In recent years, matrix factorization with deep learning techniques has become a very hot research direction [12], [76], [88], [159],[168]. In the next part, we will introduce some deep learning models and their applications in RS.
2) Deep Learning-based CF: Deep learning has flourished in areas of computer vision, pattern recognition, speech recognition, and so on [165]. In recent years, deep learning has been widely used in RS [167]. A large number of deep learning models have been applied to the RS, which provide novel frameworks to the RS community and improve the performance of the RS. Deep learning can effectively mine the non-linear relationship between users and items and learn the hidden features of users and items. Some of the most commonly used deep learning models in RS are briefly introduced in this part, which are multilayer perceptron(MLP), autoencoder (AE), convolutional neural network(CNN), and recurrent neural network (RNN).
MLP is a feed-forward artificial neural network, which contains at least one hidden layer between the input layer and the output layer. MLP is a model that represents the nonlinear mapping between input and output vectors. Most of the existing recommendation algorithms are linear methods, so the knowledge of MLP is able to provide nonlinear transformation to existing methods. Neural CF [54] is the representative work of the MLP model in RS. Neural CF has achieved a significant result by using a neural architecture to replace the inner production on the user- and item-latent vectors in the MF model. By leveraging the neural architecture of MLP, neural CF can learn the nonlinear interaction between the users and the items. Other well-known work can be found in [90], [91], [151].
AE is a kind of artificial neural network that is used for unsupervised learning. By taking the input data as the learning target in the output layer, AE is used for dimensionality reduction or feature learning. In general, the data in the bottleneck layer represent the low dimensional form of the input data. Representative AE models are denoising AE,sparse AE, contractive AE and variational AE [77], [110],[127], [150]. The application of AE models in RS is very successful. AutoRec [130] has trained the AE model so that the observed ratings in the output layer are as good as possible as the input layer. In this way, the bottleneck layer can learn the user features through the observed ratings to predict unobserved ratings. In the input layer, the ratings of the unobserved part are set as 3. The loss function only considers the observed ratings without taking into account the unobserved ratings. The extension of AutoRec can be found in[139], which has introduced side-information to alleviate sparsity and overcome cold start problems. Other well-known work of different AE models in RS is [89], [115], [154].
CNN is a feed-forward neural network with a deep structure. In general, CNN consists of three structures which are convolution, activation, and pooling. CNN can effectively capture features from a large amount of data, so it has achieved great success in many research fields, such as speech recognition, image recognition, natural language processing,etc. The main applications of CNN in RS focus on accurately extracting the features of users and items from multi-source data in order to improve the recommendation accuracy. In the process of fashion consumption, consumers’ preference for products is inseparable from the visual appearance of products, meanwhile, consumers’ preference will evolve over time. In order to provide users with more accurate recommendations, He and McAuley [53] have adopted the CNN model to extract visual features from the product images and identify evolving trends to evaluate the complex and evolving visual elements considered by the users in purchasing the products. A Deep Cooperative Neural Networks model has been proposed in [172] which consists of two parallel neural networks. One neural network consists of learning user behavior through the user comments, and the other one consists of analyzing what the user has commented to determine the features of the product. These two parallel neural networks first use the word embedding technique to obtain semantic information in comments. Then, the CNN model is used to discover multilevel features for users and items from semantic information. Finally, the two networks are coupled together, and factorization machine techniques are utilized to interact with the latent factors learned by CNN to complete the final prediction. There are many irregular data in the form of graphs in real life, such as social networks,knowledge graphs, and so on. The graph convolutional network (GCN) has become a key research direction because of its great advantages in extracting the characteristics of irregular graph data [29], [30], [55], [70], [140], [141].
RNN is a kind of neural network with short-term memory capabilities to describe the relationship between the current output of a sequence and previous information [49]. In RNN,a neuron can receive not only information from other neurons but also its own information. These neurons form a network structure with loops and memories. In general, RNN is used for sequential data processing. In session-based recommendation, RNN can be used to integrate current browsing history and browsing order to effectively model the dynamics of user preferences to provide more accurate recommendations. GRU(gated recurrent unit, a variant of RNN) has been used in [57]to model short session-based data. Other RNN methods used in session-based Recommendation can be found in [93], [142],[153].
IV. HYBRID FILTERING
Hybrid filtering methods are a class of methods that combine the advantages of content-based filtering and CF methods to process different data sources in order to improve prediction accuracy [74], [119]. Three primary ways of creating hybrid RS can be found in Fig.7, which are ensemble design, monolithic design and mixed system [6]. These three ways include 7 methods, which are weighted, switching,cascade, feature augmentation, feature combination, metallevel and mixed [6], [24], [68].

Fig.7. Different kinds of hybrid filtering methods.
Ensemble design combines the results of different recommendation algorithms into a single output by rules. The commonly used methods are:
1) Weighted: The weighted linear combination of the prediction results from different recommendation algorithms is used to obtain the final prediction result.
2) Switching: According to current needs, this method switches between various recommendation algorithms.
3) Cascade: This is a multistage method using the sequential design that the subsequent recommendation techniques will optimize the results of the previous one in order of priority.
4) Feature augmentation: This is another multistage method using the sequential design that the output of the previous recommendation algorithm is used as the input features to the subsequent recommendation algorithm.
Monolithic design integrates multiple recommendation strategies into one algorithm. The representative methods are:
5) Feature combination: The features from different data sources, for example, the user ratings and content features, are combined together and used to do the recommendation.
6) Meta-level: The model generated by the previous recommendation algorithm becomes the input of the subsequent recommendation algorithm.
Mixed system is that a list of all the recommendation results obtained by different recommendation algorithms are shown to users directly.
V. EVALUATION OF RS
Typical metrics used in RS can be divided into three groups on the basis of their particular purposes, which are accuracybased metrics, decision-based metrics, and rank-based metrics.
1) Accuracy-based Metrics: MAE (mean absolute error)[21] and RMSE (root mean squared error) [16] are the most representative metrics in this group. The purpose of accuracybased metrics is to measure the average error between the true and predicted values [48]. RMSE is more sensitive to large errors than MAE, therefore, RMSE is more useful for the system where large errors are particularly undesirable. The mathematical expressions of MAE and RMSE are
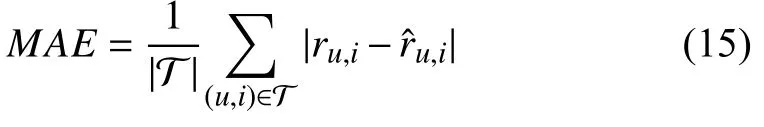
and
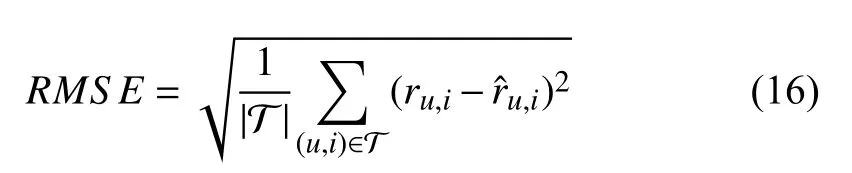

2) Decision-based Metrics: The most popular metrics among this group are precision [83] and recall [34]. The purpose of decision-based metrics is to distinguish the right predictions from those wrong predictions. Precision represents how many selected items are relevant and recall represents how many items are selected

and

where Precision (respectively, Recall) takes all recommended items (respectively, all possible relevant recommendations)into account. If only top N recommendations are considered,P@N (precision at cutoff N) and R@N (recall at cutoff N) are used to represent.
3) Rank-based Metrics: RS generates personalized recommendation lists for users by analyzing their preference.Then, rank-based metrics are used to evaluate the effectiveness and accuracy of these recommendation lists. The most representative rank-based metrics are MRR (mean reciprocal rank) and nDCG (normalized discounted cumulative gain) [69]. MRR measures the mean of the reciprocal ranks of multiple relevant items
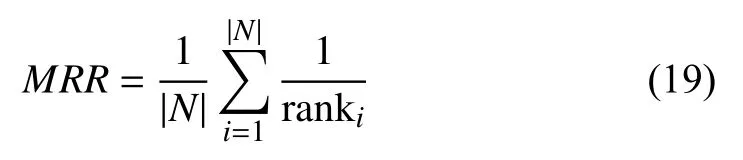
where rankirepresents the rank position of ith item when it first appears, and nDCG is used to measure the ranking quality as compared to the ideal situation
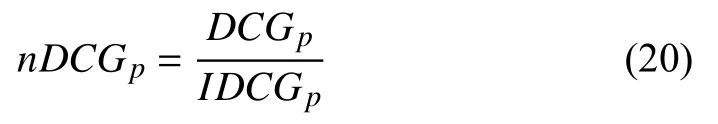
where DCGpis the discounted cumulative gain accumulated at rank position p
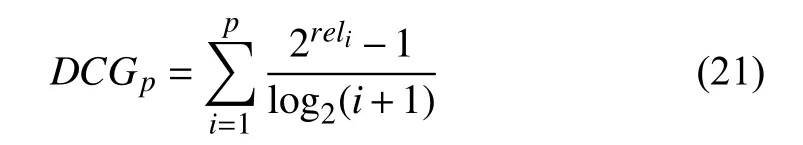
and IDCGpis the ideal discounted cumulative gain accumulated at rank position p
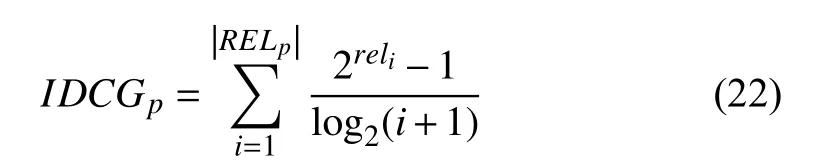
where r elidenotes the graded relevance of the ith item the and RELpdenotes a list of the first p items sorted by their relevance from big to small.
VI. APPLICATIONS OF RECOMMENDATION TECHNIQUES IN HEALTHCARE
The rapid development of the times has made people’s life rhythm faster and faster. Busy work, life pressure, irregular diet, and bad habits make more and more people in a subhealth state. If the sub-health state is not improved in time, it will cause various diseases. Experts believe that the recommendation technology can help people improve their health by providing constructive personalized suggestions[147], [152]. COVID-19 pandemic in 2020 has swept across the world causing tremendous changes in people’s daily life and having lasting impacts on the economy and society. The pandemic has also affected the entire medical field and promoted the rapid development of health-oriented systems,services, and solutions, among which health RS is able to play an important role in assisting professionals and individuals in clinical and non-clinical applications [149].
Before 2015, although there is not much work related to health RS, researchers have noticed the great research and application potential of health RS [129]. The successful holding of the first health RS workshop co-located with the 10th ACM (Association for Computing Machinery) Conference on RS in 2016 has provided a very good platform for communication and cooperation of researchers, which promoted the spread and development of health RS. The experts have focused on how to use the RS techniques to help people adopt a healthier lifestyle and improve their own health, including the improvement of cognition, the deepening of understanding, and the improvement of behavior.
After years of development, there is a lot of work to show that recommendation techniques have been successfully applied to disease prediction, disease prevention, medical diagnosis, and so on [62], [65], [85], [112], [113], [143],[161], [166]. Moreover, recent work has indicated that health RS has developed from the applications of basic recommendation techniques to the algorithm improvement and model innovation [13], [19], [67], [122], [146]. Here, the applications of recommendation techniques in healthcare are mainly divided into the following topics:
1) Dietary Recommendations: The choice of healthy food is affected by many aspects including culture, preferences,personality goals, and economic conditions. Improper choices will not only affect physical and mental health but also pay high economic and time costs. In general, the way that people choose healthy food is basically through active methods rather than passive recommendations. Dietary (or food) recommendation is aimed at utilizing recommendation techniques to provide users with personalized dietary recommendations based on their needs, including healthier foods, correct diet combinations, and reasonable eating methods.
In order to help people improve their health by providing healthier dietary recommendations, a method of substitution among different foods has been proposed in [1], which has used positive pointwise mutual information and truncated SVD to analyze the attributes and contextual relationships among foods with the aim to find a set of similar alternative foods that are healthier on the premise of satisfying the user needs. In [50], the content-based recommendation technique has been adopted to design and implement a personal health augmented reality assistant that can help people choose healthier alternative products in daily life. A context-aware RS has been proposed in [8]. By analyzing whether two foods have been consumed in similar situations to estimate the substitutability, a personalized dietary recommendation has been established to help people improve their eating habits instead of simply providing general dietary guidelines.
Knowledge of eating habits is the cornerstone of the personalized dietary RS. In order to explore the eating habits of users, Akkoyunlu et al. [9] have proposed a novel meal based method. This method has used Doc2Vec technology to learn the similarity of meals between users in the embedding space to determine the similarity between users and then analyze the user eating habits through the clustering method.Food RS called DIETOS (DIET Organizer System) has been mentioned in [5] for health profiling and diet management in chronic diseases by using content-based filtering technique.DIETOS has provided personalized dietary recommendations by analyzing the consumption data of healthy people and dietrelated chronic disease patients. In [25], multi-objective optimization technology has been introduced into the RS to do healthy menus recommendation by considering healthy nutrients, harmonization, and coverage of ingredients in the pantry. For different practical situations, the objectives can be replaced, increased, or decreased. The knowledge-based RS technique has been used in [71] to provide personalized health advice by using medical claims, demographics, and symptoms. A mobile nutrition assistance system has been designed to provide personalized persuasion for nutritional intake [86].
Ensemble topic modeling (EnsTM) based feature identification technique has been studied in [75] to achieve effective user modeling and recipe recommendation. This technique has taken into account not only food tastes,demographics, and costs, but also user nutritional preferences,which has helped users find recipes under different nutritional categories. Alcaraz-Herrera et al. [10] have introduced an evolutionary RS, which has recommended diet plans and training packages to users based on their preferences and goals, with the aim to provide users with a more comprehensive experience. As the user’s current preferences may conflict with the new dietary goals and lead to a decline in recommendation quality, Starke [138] has discussed how the Rasch model can be used to obtain changes in user habits to help CF-based approaches. In order to provide valuable suggestions and bring new thinking to the RS community, a series of CF and content-based algorithms have been tested on food recommendations in a large online recipe dataset with the aim to give a comprehensive analysis of different recommendation algorithms’ advantages and limitations[146].
2) Healthy Lifestyle Recommendations: A healthy lifestyle can effectively improve people’s health [32], [124]. Many experts and professional organizations have given suggestions and standards for healthy lifestyles. However, many people are unwilling to adhere to a healthy lifestyle. Even if some people make a series of health plans, many of them may give up halfway due to boredom. The personalized recommendation is an effective way to promote their lifestyles.
A cyber-physical RS has been proposed in order to allow people to actively participate in exergames rather than to immerse themselves in electronic media (smartphone and Internet) in their spare time [7]. Exergaming is a form of physical exercise that can combine sports and games to achieve the ultimate workout. This cyber-physical RS first has collected users’ measurable and implicit indicators through smartphone sensing technology, then analyzed their preferences through the RS technology, and finally recommended the appropriate exergames.
Siriaraya et al. [134] have introduced the project they are developing, which is a mobile app used to record three happy things that are happened to users every day. The CF technique has been used to analyze the historical behavior of a large number of users to find neighbors with similar interests for the target users. Then, interesting activities and places nearby will be recommended to the users according to their neighbors’interests via mobile app, thus helping users increase their sense of well-being.
3) Training Recommendations: In order to achieve the ideal physical state, many people may sign up for training programs or make individual exercise programs. However, users may suddenly abandon the training programs because of decreased motivation and lack of enthusiasm, which will make the training results fall short of success. In [123], some modelbased CF methods have been used to predict whether the users will give up their training plan by analyzing the user behavior changes. If any abnormal situation has been found, the RS will remind the coach in time. For the actual remote fitness platform e4fit, the coach sometimes has to be responsible for multiple students and may not be able to help the students in a timely manner. Boratto et al. [20] have adopted the RS technique to find the problem in time by analyzing the student behavior data. Then, any problems have found that will be notified to the coach, which not only effectively improves the user experience but also reduce the burden on the coach.
The basic neighborhood-based CF method has been adopted to analyze the training plans of a large number of runners to recommend appropriate elite training plans and competition strategies to target users with the hope to make significant progress in a short time [17]. The impact of two dimensions of visual aesthetics (classical and expressive) has been discussed in [116] on perceived credibility in fitness applications, which has provided valuable suggestions for the design of health RS.A hybrid RS combining content-based filtering technique and neighborhood-based CF technique has been proposed in [39].By analyzing user preferences, historical viewing information,and like-minded users’ information, the proposed hybrid RS has recommended tailored fitness videos for users.
4) Decision-making for Patients/Physicians: a) For patients: An argumentation-based RS called ArgoRec has been proposed to provide complex chronic patients with personalized recommendations to effectively support their daily activities. ArgoRec has utilized argumentation for leveraging explanatory power and natural language interaction to improve the patient experience and recommendation quality[41]. In [47], the neighborhood-based CF has been applied to clinical decision support systems with the aim to provide the best-personalized treatment plan for psoriasis patients. b) For medical staffs: By analyzing the patient behavior, the most suitable patient ranking list has been proposed to nursing staffs for increasing the number of closed care-gaps of patients [145]. In order to provide consumers with timely and personalized suggestions to improve the consumer’s medical experience, a mixed technology considering probabilistic graphical models (PGM), random forest (RF), and CF techniques, has been proposed in [67] to obtain a vector of recommendations. Then, an ensembler has been used to combine the results and decide which results will be recommended to users.
5) Disease-related Prediction: The essence of the RS can be seen as predicting unknown data through the analysis of known data, so a large number of recommendation algorithms are used for disease-related prediction work [11]. Most of these papers are based on the assumption of “Similar users will have similar preferences for items” in which users and items will be replaced by different patients and disease-related items. CircRNA, as a marker of many diseases, is often used to identify the correlation with diseases. Lei et al. [85] have employed a CF-based recommendation algorithm to predict circRNA – disease associations. Based on the assumption that similar cell lines and similar drugs exhibit similar drug responses, a hybrid interpolation weighted CF method has been adopted to predict the missing drug response [166].Traditional memory-based CF recommendation algorithms have been employed in [160] to predict missing values during Friedreich’s ataxia (FRDA) baseline data collection. After that, a hybrid model- and memory-based CF approach and an optimally weighted user- and item-based CF approach have been used to dispose of different situations in the FRDA baseline data collection process so as to improve the accuracy of results [161], [162].
6) Other Aspects: In addition to the five main aspects mentioned above, some work has been proposed on the health RS improvement, sleep improvement, smoking cessation, and so on. For improving user trust and overall experience of health RS, the prediction uncertainty has been fully discussed in [56], which has made the recommendations of user healthrelated behaviors more transparent. In order to increase the understanding of health RS, Torkamaan et al. [144] have discussed multi-criteria grading with the aim to analyze the criteria that users should consider when evaluating health promotion recommendations.
Context-aware lifestyle RS has been proposed to improve sleep [118]. In [58], a hybrid RS has been used in the smoking cessation app. This app can push personalized information to users at the right time to help them strengthen their confidence in quitting smoking. There has been also a study designing hybrid RS through merging trust with health-sensitive semantic information in a complex environment to accurately discover and recommend the great potential collaborators to help medical product development [22]. Adaji et al. [2] have discussed how hedonistic and meritocracy values affect their healthy shopping habits among people of different ages. Pasta et al. [120] have extended the application to hearing aids. By analyzing user preferences, the personalized hearing aid parameters have been configured for users. More than 85 percent of participants have shown that their user experience has been improved.
VII. CHALLENGES
The health RS brings additional challenges to the RS community. In what follows, a number of challenging issues worthy of future work are listed.
1) Consequences of a Bad Recommendation: In e-commerce platforms, bad recommendations may only affect the shopping experience. However, in the health RS, bad recommendations can cause harm to users’ physical and mental health, and even more consequences [66]. In the training aspect, bad recommendations will cause users to adopt the wrong training plan,which can lead to physical damage or undesired training effect. In the disease-related aspect, wrong recommendations will have a serious impact on the patients including the wrong treatment, excessive psychological pressure, and so on. In the dietary recommendation aspect, defining a healthy and nutritious diet in different environments may lead to inappropriate dietary recommendations [38]. For example, a good dietary suggestion for user A may not be a good suggestion for user B, such as excessive food cost,cumbersome production process, food taboos, etc. Bad recommendations will not only make users lose confidence in the RS but may also cause some mental illnesses, such as being frustrated, feeling discriminated against, etc. For different individuals with different physical conditions, some seemingly healthy recommendations may be unhealthy.
For all these negative effects of bad recommendations, the recommendations must be as close as possible as the actual situation. Here, the most important point is the recommendation accuracy. In order to improve the prediction accuracy,the mutual assistance of many interdisciplinary experts and data providers is required, include providing high-quality data,providing professional opinions, developing targeted recommendation algorithms, etc [82].
2) Data Collection and Integration: Existing diet, training,or health information sharing platforms can provide researchers with massive amounts of data. However, while acquiring massive amounts of patient data, there will include a lot of bad data that lacks quality, consistency, and compatibility in many places [61]. The reasons for the bad data include data loss, inaccurate data, inaccurate data,inconsistent data format, data duplication, data input error, etc.There are application scenarios where patients interact with the appropriate devices (i.e., wristband with smartphone or wireless medical devices) to obtain their preference and behavior data, which is very difficult and time consuming to clean and extract valuable data.
3) Lack of High-quality Public Data Sets With Domain Characteristics: Research of health RS is still preliminary.Most of the existing papers are about the applications of RS techniques in different healthcare scenarios, which focus on the innovation of ideas on different application scenarios with low requirements on data quality. Most of the datasets in the existing health RS papers are collected by authors or provided by cooperation partners. Rather than being data-driven, most health RS articles tend to be problem-driven, which means the datasets are collected in response to the questions raised by the researchers. These datasets typically face the following problems, such as non-public, lack of generality, too much or too little data, poor data quality, lack of peer use or recognition, and so on. At this stage, although many datasets for different application scenarios have been made public with the publication of the papers, no recognized high-quality public dataset has emerged yet.
4) Interpretability: The most common view of interpretability in RS is to increase the transparency of algorithms[14], [15], [40], [43], [164], which is especially important in health RS. Reliable explanations can greatly improve endusers’ confidence in the recommendation results [126]. Even if an inaccurate recommendation occurs, the users can determine whether the recommendation is accepted or not from explanations.
5) Beyond Accuracy: In health RS, accuracy is sometimes not the only important indicator [28], [52]. For example,during the dietary recommendation, novelty, richness, and cost are also several important indicators for users to consider.During the disease-related recommendation, the acceptability of users needs to be considered because sometimes an accurate recommendation is not necessarily a good recommendation. Some accurate recommendations may be impractical, such as exorbitant cost or painful treatment,which sometimes lead to arguments between patients and their families. The challenge here is how to define and depict different indicators and deal with the multi-objective optimization problems [78], [97], [98].
6) Privacy Preserving: Healthcare-related applications and smart devices can collect real-time and continuous data on the entire health process of users, including user personal information, electronic health files, disease medical records,physical signs, and so on [23]. A large number of user-related data allows health RS to provide accurate personalized recommendations, but at the same time comes the risk of data leakage. The leakage of data will bring potential threats to patients and their families, as well as a devastating blow to the development of the mobile medical industry. Therefore, how to protect data security and user privacy are of utmost importance [73].
VIII. CONCLUSION
RS has been a hot topic for over two decades. Boosted by the rapid development of information technology, RS has been widely used in reality. In recent years, RS for health has become a trending issue within the RS community because of its outstanding advantages in helping people promote their health by providing useful personalized recommendations. In this paper, we have reviewed the basic ideas of three widelyused recommendation techniques and their latest developments. The applications are highlighted from the perspective of “recommendation techniques on healthcare”, which involve five main aspects, including dietary recommendation, lifestyle recommendation, training recommendation, decision-making for patients/physicians, and disease-related prediction. Further research topics include the 1) time series forecasting by using the recommendation technique and some filtering strategies[59], [94], [125], [169], [174]–[179]; and 2) the improvement of the performance for the RS by using some latest optimization algorithms [31], [95], [96], [99], [135]–[137],[163]. As more and more people in related fields pay attention to and join in the research of health RS, we are confident that the RS techniques will definitely bring significant assistance to the healthcare field in the future.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Dynamic Evaluation Strategies for Multiple Aircrafts Formation Using Collision and Matching Probabilities
- Task Scheduling for Multi-Cloud Computing Subject to Security and Reliability Constraints
- Vibration Control of a High-Rise Building Structure: Theory and Experiment
- Residual-driven Fuzzy C-Means Clustering for Image Segmentation
- Decoupling Adaptive Sliding Mode Observer Design for Wind Turbines Subject to Simultaneous Faults in Sensors and Actuators
- Property Preservation of Petri Synthesis Net Based Representation for Embedded Systems