事件要素注意力与编码层融合的触发词抽取研究
2021-04-12黄德根
潘 璋,黄德根
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引 言
事件抽取主要是采用自动抽取方法,将非结构化自然语言文本中用户关注的事件信息抽取出来,以结构化的方式表示.在自动问答、知识图谱、自动文摘、信息检索等任务中具有广泛应用.
ACE(Automatic Content Extraction,ACE)[1]会议描述事件抽取任务包含触发词抽取以及事件要素抽取.其中,事件触发词是指能够引发相应事件的主要词汇,通常事件的类型由事件触发词类型表示,事件要素是指事件所对应的参与者.例如,在句子“He died in the hospital.”中,事件触发词是“died”,事件要素分别是“He”(Role=Person)和“hospital”(Role=Place),触发的事件类型是“Die”事件.
事件触发词抽取的难点在于:同一事件可能出现在不同的触发词中,以及同一个事件触发词,由于在不同的句子中,可能触发不同的事件类型.对于句子“Mohamad fired Anwar,his former protégé,in 1998.”中,事件触发词是“fired”,触发的类型为“End-Position”,由于“fired”是一词多义,会将该事件类型划分为“Attack”.但是,如果利用事件要素信息“his former protégé”(Role=Position),则可以将触发词分类为“End-Position”.
事件触发词与事件要素之间存在紧密的联系,有效利用事件要素信息,能够提升触发词抽取性能.例如:
S1:MSNBC,an obscure cable channel,has fired Phil Donahue,the host of its highest-rated show.
S2:North Korea′s military may have fired a laser at a U.S.helicopter in March.
S3:It has refused in the last five years to revoke the license of a single doctor for committing medical errors.
如表1所示,S1、S2对应不同的事件类型,但含有同一个事件触发词“fired”.同时两个句子的事件要素类型不同,在S1中利用“Person”和“Position”要素,可以将触发词分类为“End-Position”事件,同样,在S2中,通过“Attacker”和“Target”要素,可以分类为“Attack”事件.而且在每句话中,有相同类型的事件要素含有相似的事件类型,如表1中S1、S3,对应的事件触发词分别是“fired”和“revoke”,但是含有相同的事件要素类型“Person”和“Position”,为同一事件类型“End-Position”.
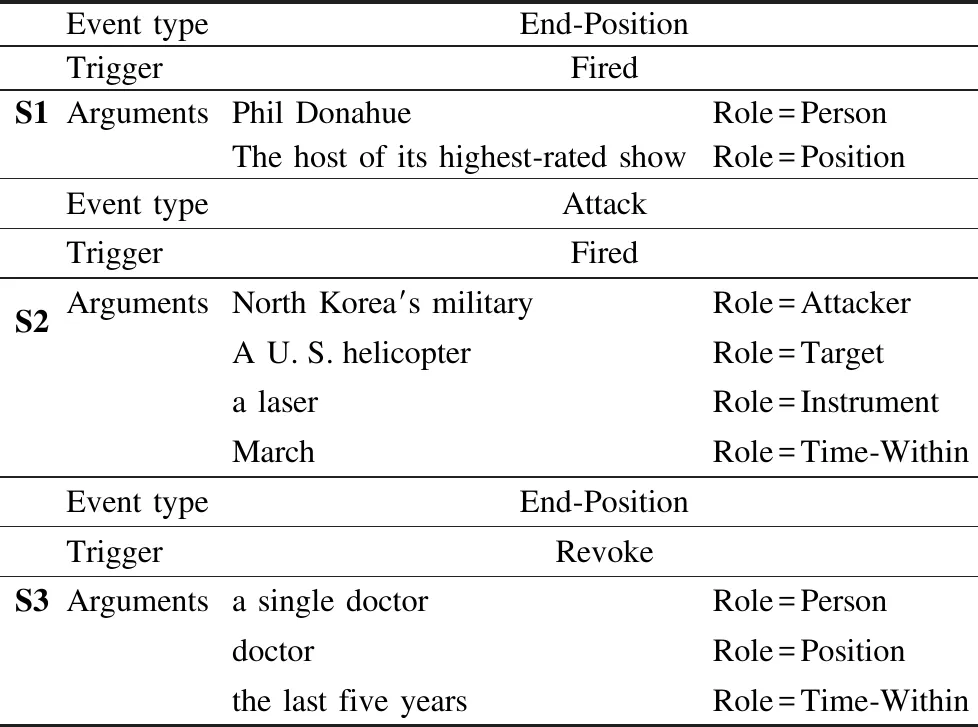
表1 事件触发词例句Table 1 Event trigger example
为了利用事件触发词与事件要素之间的关联信息,本文提出一种事件要素注意力与编码层融合的事件触发词抽取模型.该模型主要通过计算事件要素与触发词之间的相关性,以及编码层中的自注意力机制学习句子内部结构信息,特别是,可以学习事件要素和触发词之间的关联性,将两者融合作为特征送入编码层中再次训练,更新事件触发词权重.此外,通过词特征模型来获取语义信息,然后将两个模型进行拼接,通过softmax分类器判断事件触发词的类型,得到抽取结果.
2 相关工作
传统事件抽取方法依赖于人工从句子中抽取特征(如词本身、词性、依存关系等),通过最大熵和支持向量机等统计机器学习分类模型进行事件抽取.这些方法需要依赖一定的专业领域知识,人工特征选取的好坏影响事件抽取的性能,此外,需要借助自然语言处理工具与资源是否可以选取出和事件抽取任务相联系的特征,导致抽取效果不能进一步提高[2-5].
近年来,事件抽取任务逐渐采用深度学习模型.Nguyen等人[6]将候选触发词的上下文信息、周边的实体信息作为输入,利用CNN模型自动挖掘隐含特征,从而避免了特征工程中词性标注等预处理步骤的错误对抽取结果的影响;Nguyen等人[7]实现了双向循环神经网络(Recurrent Neural Network,RNN),捕获触发词和要素之间的关系,同时进行触发词和事件要素抽取;Chen等人[8]根据事件触发词和事件要素采用动态多池化层来保留更多关键信息进行事件抽取;Feng等人[9]提出一个混合神经网络(HNN),以捕捉特定背景下的序列和块信息,并且在没有任何人工特征编码的情况下,对多种语言训练事件抽取模型.深度学习模型可以自动学习句子的特征表示,不需要人工干预以及减少使用自然语言处理工具,防止特征设计过程中的错误对事件抽取性能的影响.
基于外部资源的方法旨在利用外部资源增强事件检测,Zhao等人[10]提出将文档级别的特征信息加入模型(DEEB-RNN)中,并验证了文档级的信息有利于提高模型的实验效果;Liu等人[11]分析从FrameNet(FN)到事件类型的映射,然后利用FN中自动检测到的事件,提高事件检测的性能.
神经网络模型自动提取事件特征以及外部资源增强事件特征的方法,主要关注事件触发词本身信息,较少考虑事件要素信息以及词间依赖信息.本文提出事件要素注意力与编码层融合模型,能获取事件要素信息,同时捕捉词间的特征信息,提高事件触发词抽取性能.
3 事件触发词抽取模型
事件触发词抽取主要由3部分构成:事件要素注意力与编码层融合模型、词特征模型、分类器,其抽取框架见图1.
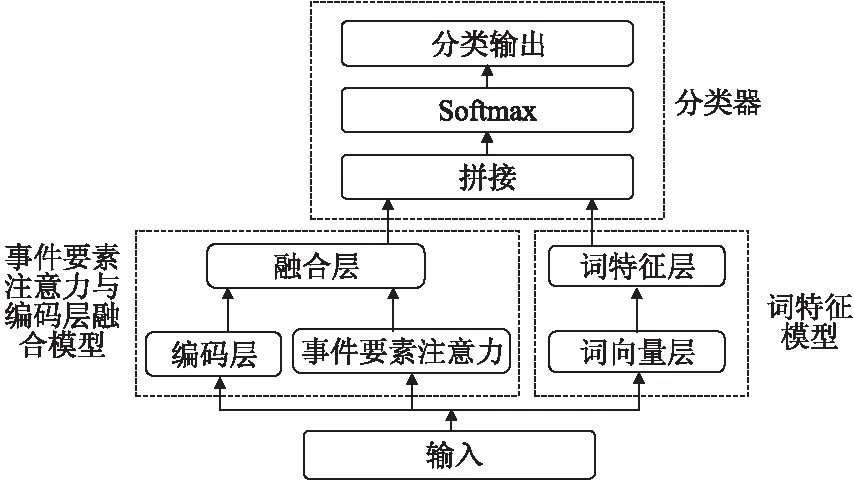
图1 事件触发词抽取整体框架Fig.1 Event trigger extraction framework
3.1 事件要素注意力与编码层融合模型
事件要素注意力与编码层融合模型如图2所示.事件要素注意力,将BERT[12]训练的词向量作为输入,用双向LSTM[13]分别得到前向与后向两种不同隐层表示,获取上下文不同的语义信息,并且通过自注意力机制得到句子表示H=[h1,h2,…,hn],同时通过ACE语料库中对事件要素标注的类型,构建事件要素初始向量,输入到双向LSTM中,获得事件要素特征向量arg∈Rn×d,将两个特征向量应用事件要素注意力计算.编码层,通过BERT训练的词向量作为输入,采用双向LSTM学习句子语义信息以及序列位置信息,并且利用编码层多头自注意力机制加强关键词的权重信息.融合层,将事件要素注意力与编码层得到的分值向量进行融合,再次通过单层编码层更新权重进行训练.
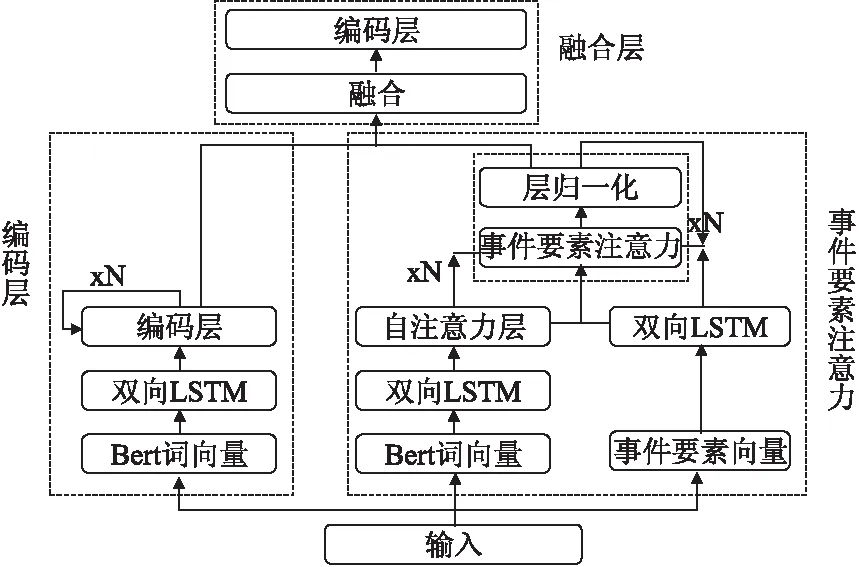
图2 事件要素注意力与编码层融合模型Fig.2 Event argument attention and encoding layer fusion model
3.1.1 事件要素注意力
为了计算事件触发词与事件要素之间的关联信息,构建了事件要素注意力网络.事件要素注意力,即是利用文档中注释的事件要素信息,将事件句子表示与事件要素特征表示进行相关性计算,从而让句子中的事件触发词能够获取注意力.事件要素注意力网络整体包含N层,每层的输出作为下一层的输入,与事件要素特征表示计算相关性,引用残差网络[14]思想,将之前每一层的句子表示与初始句子表示进行合并作为当前层的输入,以及将之前层的注意力与当前层合并,并且采用层归一化[15]进行连接,具体见算法1.
算法1.事件要素注意力算法
输入:事件要素特征向量arg、初始句子表示H
输出:事件要素注意力句子表示
1.for要素注意力层数=1 toNdo
2. 将事件要素特征向量arg作为查询向量q,与句子表示H进行乘积,计算事件要素与事件触发词之间的相关性注意力分数S:
S=HargT
3. 通过softmax函数将分数映射为0-1之间的实数,得到句子中每个词的权重信息a:
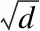
4.if层数大于1then
5. 将上一层中归一化的注意力分数与当前层注意力分数相加合并,增强事件触发词权重信息,并且与句子特征结合,得到新的句子表示H*:
H*=H(abefore+a)
6.else层数等于1then
7. 将注意力分数与句子特征结合得到新的句子表示:
H*=Ha
8. 采用层归一化来降低过拟合以及提高训练速度
9. 为了同时利用所有层的不同信息,以及由于随着网络层数的不断加深,导致句子信息丢失,本文将之前每一层的句子表示与初始句子表示进行合并作为当前层输入:
其中l是当前层数,H是初始句子表示,Hi是每一层输出的句子表示
10.endfor
3.1.2 编码层
为了捕捉事件要素和事件触发词的依赖关系,以及控制不同部分对句子表示的贡献,提取重要信息.引用transformer[16]中的编码层来增强事件触发词的权重信息.编码层如图3所示,包含多头自注意力机制层与全连接前馈神经网络层,并且每一层之间采用残差网络和层归一化连接.与事件要素注意力结构类似,本文编码层也是由多层网络构成,将之前每一层的句子表示与初始句子表示进行合并作为当前层的输入,并且将当前层的注意力分数与上一层的注意力分数合并,作为当前层的注意力分数.
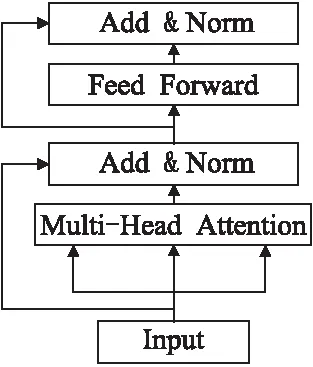
图3 编码层结构图Fig.3 Encoding layer structure
注意力机制[16]通过控制句子中每一部分不同的权重信息,使得模型关注句子中重要的信息,而忽略不重要的信息,从而抽取出更加准确的结果.本文主要采用放缩点积注意力(Scaled Dot Product Attention)进行注意力计算.对于给定长度的为n的queries值Q∈Rn×d,keys值K∈Rn×d和values值V∈Rn×d,放缩点积注意力的计算如公式(1)所示:
(1)
其中,d是网络隐藏层参数,自注意力机制即是K=Q=V=X,输入句子向量,句子中每个词与词之间通过放缩点积来计算注意力,减少对外部信息的依赖,获取句子特征内部的相关性.
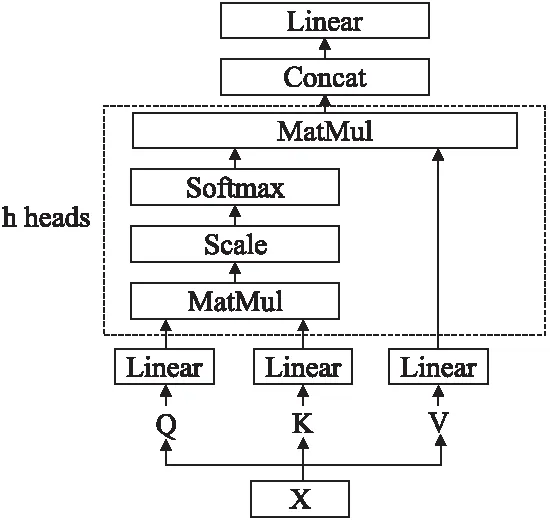
图4 多头自注意力机制结构图Fig.4 Multi-head self-attention mechanism structure
为了能够聚焦不同维度空间的特征,采用多头自注意力机制结构,如图4所示.将输入向量分别经过3个不同的线性变换,并且将线性输出结果分割为h个head,对于每个head主要是采用放缩点积注意力(Scaled Dot-Product Attention)进行注意力的并行计算.
3.1.3 融合层
将事件要素注意力得到的句子表示以及编码层得到的词间依赖关系,通过相加运算进行合并,将结果作为特征,再次送入编码层中通过多头自注意力机制,更新事件触发词权重信息.
3.2 词特征模型
词特征模型包括3类特征,即实体特征、字母特征和词本身特征.
通过事件抽取系统中注释的实体信息,随机初始化每个实体类型的嵌入向量,得到句子的实体向量作为输入,利用双向LSTM分别得到前向与后向隐层输出,并且采用自注意力机制,得到实体特征HN=[hn1,hn2,…,hnn].
单词中的字母通过随机初始化的字母查找表转换为实值向量,得到每句话对应的字母向量作为输入,利用双向LSTM以及自注意力机制得到字母特征HL=[hl1,hl2,…,hln].
对每个词向量不同部分加强权重,得到不同位置的特征信息.对句子随机初始化向量X=[x1,x2,…,xn],其中xi,i=1,2,3…,n都是m维的连续向量作为输入,对每个xi切分成两部分xi-1和xi-2,则词本身特征见公式(2):
Hw=w1(w2xi-1+w3xi-2)
(2)
其中w1、w2、w3是随机初始化的权重向量.
为了防止向量维度过于稀疏,将实体特征HN∈Rn×d、字母特征HL∈Rn×d以及词本身特征HW∈Rn×d进行融合,得到语义信息表示为Hs∈Rn×d,其中,n为序列长度,d为隐层输出维度,如公式(3)所示:
Hs=tanh(w1(HNw2+HLw3+Hww4))
(3)
其中,w1、w2、w3、w4为随机初始化的权重向量,采用tanh作为激活函数,扩展语义信息,得到词特征输出.
3.3 分类器
对于句子X=[x1,x2,…,xn],通过事件要素注意力与编码层融合模型,得到事件触发词与事件要素之间的关联信息表示为Ha∈Rn×m1,以及采用词特征模型得到语义特征信息表示为Hs∈Rn×m2,将两者的分值向量拼接为H∈Rn×(m1+m2),如公式(4)所示:
H=Ha⊕Hs
(4)
其中,⊕表示行向量的拼接.然后将事件触发词抽取模型得到的特征向量送入softmax函数中进行训练,输出分类的结果,进行事件触发词抽取.
4 实验与分析
4.1 数据集
为了验证模型的有效性,触发词抽取实验采用的数据集为ACE2005英文语料,数据集包含冲突、商业、生活、交易等8种大类型,33子类的事件实例,总共含有599篇文档.和已有的事件抽取任务研究一样,只考虑识别33个事件子类型.并且采用同样的数据集划分方法,其中,训练集为529篇文档、测试集为40篇新闻语料、验证集为随机30篇文档.采用准确率P(precision)、召回率R(recall)和F值作为实验的评价指标.
4.2 实验参数设置
词向量采用BERT预训练模型,输入维度是768维,事件要素注意力与编码层各8层,编码层中head个数设置为8,训练过程中每个batch的大小是30,dropout概率为0.2,学习率为0.001,LSTM隐藏层节点数是128.
4.3 实验结果及分析
4.3.1 与其他方法对比
为了评价本文方法的性能,我们选择了如下5种方法进行对比:
在依赖于人工设计特征的方法中,Combined-PSL方法[5]提出概率软逻辑模型(PSL)对全局信息进行逻辑编码,并且结合全局信息和局部信息进行事件分类;
在通过表示学习自动提取事件特征的方法中,JRNN模型[7]提出的一种双向循环神经网络的联合框架,通过引用记忆向量和记忆矩阵来存储在标记过程中的预测信息,从而获取事件触发词和事件要素的依赖关系进行联合抽取;DMCNN模型[8]通过自动地学习文本级别和句子级别的特征,不需要使用复杂的NLP工具,以及利用动态多池化层保持更多关键信息,进行事件抽取;
在通过添加外部资源增强事件特征的方法中,SA-ANN模型[17]通过注释的事件要素信息对每个候选触发词构造的注意力,增强事件要素获取注意的能力,并且以监督的方式共同学习注意力和事件检测器;Bi-LSTM+FN[18]通过框架语义知识库FrameNet(FN)中定义的框架和事件检测中定义的事件具有极其相似的结构来构建映射关系,选取FN中合适的例句作为事件检测的扩充语料,缓解事件检测任务中的语料稀疏和样例分布不平衡问题.
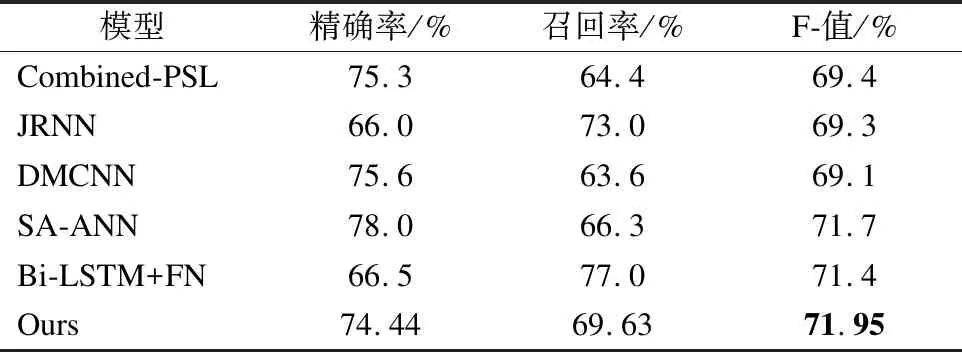
表2 本文模型与其他模型实验结果对比Table 2 Comparison experimental results between the model and other models
实验结果如表2所示,相较于基于特征的事件触发词抽取方法,本文方法在事件触发词抽取中有明显的提升.与通过神经网络自动提取事件特征进行事件触发词抽取的JRNN和DMCNN模型相比,事件要素注意力与编码层融合方法F值高出2.65%以上.与通过外部资源的方法对比中,Bi-LSTM+FN通过扩充语料缓解数据稀疏问题从而充分训练模型,极大提高召回率,但是扩充语料产生的噪音导致准确率相对较低,因此没有达到更好的结果.对于同样使用事件要素信息的SA-ANN模型,是通过在监督学习中增加事件要素的注意力,而本文方法在训练过程中显示和隐式的利用事件要素信息构建注意力模型,增加触发词权重,该方法比SA-ANN的F值高0.25%.相较而言,通过事件要素注意力显示利用要素信息,同时采用编码层中的多头注意力间接学习事件要素与事件触发词之间的依赖关系,提升事件触发词的抽取性能.
4.3.2 实验分析
为了验证模型的有效性,本文对模型的深度以及融合方法进行实验分析.
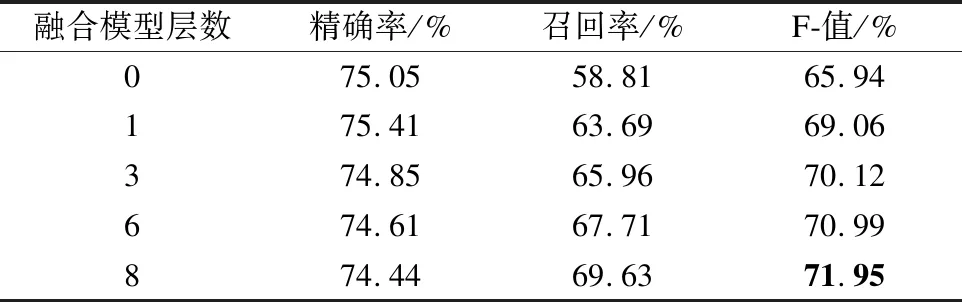
表3 不同层数实验结果对比Table 3 Comparison experimental results of different layers
1)模型的深度影响事件触发词的抽取效果,表3展示了不同层数的实验结果,事件要素注意力和编码层采用同样层数.与不利用融合事件要素注意力与编码层相比,利用事件要素注意力与编码层融合模型对事件触发词的抽取性能明显提升,可见事件要素能够为事件触发词提供关键信息,通过计算事件要素与触发词的相关性,增加了事件触发词的权重信息.对于使用不同层数的模型,最终得到的F值是不同的,当模型只有一层时,模型处于欠拟合状态,随着层数的增加,模型逐渐拟合,虽然精确率在小幅度下降,但召回率明显提升,实验结果F值也逐渐增加,当层数为8时,模型F值达到最优结果.
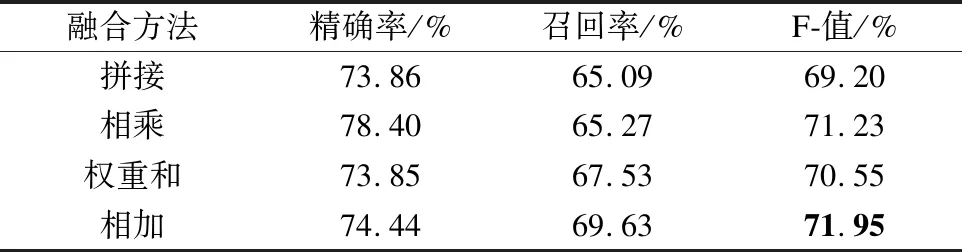
表4 不同融合方法实验结果对比Table 4 Comparison experimental results of different fusion methods
2)表4中展示了不同融合方法的实验结果,主要对事件要素注意力模块与编码层模块输出的分值向量进行融合,分别采用拼接、相乘、权重和以及相加.权重和是通过sigmoid函数得到两模块不同的权重值,对两分值向量进行融合.相比较其他3种融合方法,相加能够增强事件触发词权重,获得更多语义信息,得到最好的抽取效果.
5 结 论
针对事件触发词抽取任务,为了充分利用事件要素信息,本文提出一种事件要素注意力与编码层融合的事件触发词抽取模型,提高事件触发词抽取性能.通过事件要素注意力来计算事件要素与事件触发词之间的关联性,同时利用编码层中的多头自注意力机制来得到词间的依赖关系.实验结果表明,该方法在事件触发词抽取的F值为71.95%.
事件要素注意力与编码层融合的事件触发词抽取方法存在语料数据稀疏,类别分布不平衡问题,在下一步工作中,将融入更多的外部资源来扩充语料,平衡事件类别,提高事件触发词抽取效果.
