互联网新闻敏感信息识别方法的研究
2021-04-12张祥祥于碧辉于金刚
李 姝,张祥祥,于碧辉,于金刚
1(沈阳理工大学 装备工程学院,沈阳 110159) 2(中国科学院大学,北京 100049) 3(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引 言
据第45次《中国互联网络发展状况统计报告》统计,截至2020年3月,我国网络新闻用户规模达7.31亿,占网民整体的80.9%.新闻资讯聚合平台每天整合着海量新闻媒体内容.随着以手机为载体的移动互联网普及,社会的新闻传播方式途径以及舆论生态正在发生巨大变革.
在自媒体时代,网民个体可以依托新闻资讯聚合平台产出新闻信息,在“内容为王”的大基调下,却也存在着利用新闻发放平台进行色情信息传播、发表反社会言论、销售国家违禁物品的现象.这些质量不佳的敏感信息严重损害了和谐社会的媒体生态和舆论生态,甚至会对价值观未成型的未成年人造成极为恶劣的影响.因此对互联网新闻信息进行有效监管是当前的重要命题,是人民群众网络空间权益的重要保障.识别并过滤互联网新闻中的敏感信息,具有深刻的社会意义与现实意义.
对于互联网新闻的敏感信息识别,现有的方法主要是基于敏感关键词的方法进行过滤[1],这种方法有两个非常明显的缺陷,一方面,由于互联网新闻是不断变化的,每天都会产生新的术语和词语,需要不断更新迭代敏感关键词,费时费力,泛化性能弱;另一方面,基于敏感关键词的方法很容易对正常新闻造成误伤,也就是将正常新闻误认为是敏感新闻,所以也就导致了基于敏感关键词的方法识别准确率不高.而最近几年,随着硬件设备、计算能力的提高,深度学习开始流行并快速发展着.深度学习的最大优点是利用神经网络从文本信息中自动学习敏感信息特征,无需人工制定敏感信息特征,是端到端的方法,对于敏感信息识别可以取得良好的效果,深度学习中的预训练模型在大规模语料上通过无监督的方法学习到了大规模的先验知识与语义特征,往往可以取得很好的效果.
本文所要识别的敏感信息包括反动、色情、暴力、违禁4种类型,反动主要指涉及革命英雄人物、国家领导人、社会的消极反面言论,色情主要指低俗、有害未成年人身心健康的不良信息,暴力主要指暴力行为,违禁主要指国家命令禁止的相关物品.
本文首次将传统敏感关键词方法与深度学习方法相结合应用于互联网敏感信息识别,提出 Mer-Hi-Bert(Merge Hierarchical Bert )即融合敏感关键词特征的分层Bert模型识别互联网敏感信息.本文的创新之处在于:一是对Bert模型进行改进,原始的Bert模型不适合互联网新闻长文本任务,改进后的分层Bert模型与Attention机制相结合更适合于新闻长文本的敏感信息识别;二是将敏感关键词策略融入深度学习模型中,融合了传统敏感关键词特征的Mer-Hi-Bert模型性能优于未融合关键词特征的Hi-Bert模型,在本文数据集上取得了最好的效果.
2 相关工作
目前,已经有很多研究者探索如何识别互联网信息中的敏感信息.早期的主流方法主要是基于关键词的方法.关键词方法包括硬匹配、跳词匹配[2]等,但是为逃避计算机的识别,敏感信息往往以变形形式出现,使得敏感信息的识别变得困难.针对这一问题,Forman等[3]提出了一种多模式模糊匹配的敏感关键词过滤算法.通过对用户自定义的关键词进行拆分,并利用拼音编码为关键词建立索引表,实现同音变形的匹配.关键词方法是最基础、最有效的方法,但是容易误伤,且关键词难以穷举.
统计机器学习模型如SVM[4]、XGBoost[5]等被成功地用于敏感信息识别,且获得了较好的效果,主要是通过文本分析的操作,提取页面文字的特征为样本进行词法分析,并以词频和加权的方法,来甄别该页面是否存在敏感内容.但是领域内资源或特征的获取耗时耗力,传统的特征提取过程中会用到复杂的NLP 工具,会造成误差传递,大量的特征工程难以实现.
最近几年,随着硬件设备、计算能力的提高,深度学习开始流行并快速发展着[6].深度学习的最大优点是利用神经网络从文本中自动学习语义特征,无需人工制定特征.Yoon Kim[7]等提出了 TextCNN,首次将卷积神经网络 CNN 应用到分类任务中,CNN 模型利用多个不同尺度的卷积核可以提取局部的 n-gram 特征,但是对于远距离特征,单层 CNN 无法捕获.Zhou等[8]等提出BiLSTM与Attention相结合用于分类任务,BiLSTM[9]模型利用门控机制可以捕获长距离依赖,进而更好的对文本信息进行语义特征编码,但缺点在于不能并行计算,Attention机制可以更好的抓住分类的重要特征如敏感信息的特征;Transformer[10]是 Google 的团队在 2017 年提出的一种NLP经典模型.Transformer利用self-attention 机制[11],允许词之间直接建立联系,能更好地捕获长距离依赖,其编码能力超过了LSTM,且可以并行计算.
以Transformer为基础的预训练模Bert[12]、Roberta[13]、XLnet[14]等在大规模语料上通过无监督的方法学习到了大规模的先验知识与语义特征,在下游任务互联网敏感信息识别上只需要进行微调就可以取得很好的效果.
3 本文的方法与模型
本文提出的融合关键词特征的互联网新闻敏感信息识别模型 Mer-Hi-Bert结构如图 1 所示,该模型由 4 部分组成,第1部分是分句模块,将文档级别的互联网新闻分成若干个片段,每个片段长度不超过设置的最大长度.第 2 部分是敏感关键词抽取模块,该模块通过使用关键词策略,提取切分后的互联网新闻片段中的敏感关键词,然后使用[SEP]分隔符将敏感关键词拼接在片段后面.第 3 部分是互联网新闻文本语义特征编码器模块,使用目前最先进的预训练模型Bert对互联网新闻进行语义编码,但是原始的Bert模型不适合互联网新闻长文本任务(文本长度>512)[15],由于第1部分已经将长文本切分成多个片段,所以本文改进后的分层Bert模型可以对切分后的互联网新闻片段进行语义编码,提取每个片段语义向量.第4部分是Attenion模块,相比与直接将第3部分得到的每个片段的语义向量进行求和拼接(Add),Attention模块将第3部分得到的每个片段的语义向量按照重要性进行求和拼接,进而实现对整篇新闻的语义编码,最终将整篇新闻文档的语义编码用于敏感信息识别.

图1 模型结构图Fig.1 Model structure diagram
3.1 分句模块
针对互联网新闻长文本问题(文本长度>512不能直接使用Bert进行语义编码),本文使用了基于标点符号的归并切分策略对长文本进行切分,保证了每个片段长度相当且不会在句子中间进行切分,使得语义信息更加完整.具体做法时首先按照“。;? !”等符号对文本进行切分,接着由于切分后的句子可能过短,本文采用归并的策略,将短文本归并,使得归并后的文本长度不超过设置的最大长度.
3.2 敏感关键词抽取模块
关键词抽取模块的作用就是提取互联网新闻每句话中的敏感关键词,然后使用
提取互联网新闻中的敏感关键词并不是简单的基于关键词的匹配,为逃避计算机的识别,敏感关键词往往以变形形式出现,因此需要使用多种关键词策略来识别出关键词.最基础的关键词策略,就是对关键词的硬匹配[16].比如,添加“枪支,联系”这样的组合关键词,就可以拦截“需要xx枪支的,请联系我,微信号:efc123”这样的敏感信息.除此之外,关键词策略通常还包括,拼音关键词策略(qiangzhi--> 买枪支的找我)、跳字匹配(枪支 --> 买?枪?支的找我)等.
本文使用的敏感关键词词典来源于互联网公开的敏感关键词词典与长期以来的积累,最终本文所使用的词典包含反动、色情、暴力、违禁4大类共计4639个敏感关键词.
3.3 互联网新闻文本语义特征编码器模块
为了将经过关键词抽取模块处理后的互联网新闻文本输入到模型中进行处理,需要使用编码器对文本进行语义特征提取[17].本文使用目前最先进的预训练模型Bert对互联网新闻进行语义编码,预训练模型在大规模语料上通过无监督的方法学习到了大量的先验知识与语义特征,有很强的上下文建模能力.但是原始的Bert模型对于长度为N的文本来说,复杂度为O(N2)且最大编码长度为512[18],所以原始的Bert模型并不适合对互联网新闻这样文档级的长文本进行建模.由于第1部分分句模块已经将长文本切分成多个片段,每个片段的长度小于512,所以本文改进后的分层Bert模型可以对切分后的互联网新闻片段进行语义编码,提取每个片段语义向量.
本文使用的Bert模型由12层Transformer 编码器组成的,具有很强的上下文语义编码能力.Transformer 利用 self-attention 机制,允许词之间直接建立联系,能更好地捕获长距离依赖,其编码能力超过了 LSTM[19],且可以并行计算.
(1)
Transformer实际使用的是基于self-attention机制的Multi-Head Attention相当于 h 个不同的 self-attention 的集成,可以从多个维度来把握词的语义信息,语义特征提取能力更强.
MultiHead(Q,K,V)=Concat(head1,…,heads)WO
(2)
3.4 Attention模块
在第3部分得到的每个互联网新闻片段的语义向量基础之上使用Attention机制,注意力机制将每个片段的语义向量按照重要性进行求和拼接而不是简单的求和拼接(Add),进而实现对整篇新闻的语义编码,最终将整篇新闻文档的语义编码用于敏感信息识别.Attention 机制可以描述为一个查询到一系列键值对的映射,假设输入为 query,source中以(key,value)形式存储需要的上下文[20].如图2所示.

图2 键值映射Fig.2 Mapping of key and value
在计算 Attention 时主要分为3步:将查询和每个关键字进行相似度计算得到权重;一般再使用一个 softmax 函数对这些权重进行归一化;最后将权重和相应的键值进行加权求和得到最后的 Attention:
ei=a(q,ki)
(3)
αi=softmax(ei)
(4)
(5)
所以 Attention 的本质是对 Source 中元素的 Value 值进行加权求和,权重的分配就是模拟人类的注意力的重点关注和自动忽略.从而有效的从海量的数据信息中有侧重点的进行选择具有高价值的信息.
4 实验
4.1 实验数据
目前国内还没有互联网新闻敏感信息数据集,实验所用数据集为使用 Python 爬虫抓取的互联网新闻资讯,来源包括新闻门户网站、社区论坛等.因为原始数据来源较多,含有较多非法字符,所有数据都经过了预处理,包括使用正则表达式删除特殊符号、删除url链接等.通过整理实际获取到的新闻数据为141000条,所有新闻数据平均长度为823字,是典型的长文本问题.另外,本文定义了反动、色情、暴力、违禁4大类4639个敏感关键词.将新闻数据分为训练集(80%,112800条数据)、验证集(10%,14100条数据)和测试集(10%,14100条数据)用于模型训练、验证与测试,实验数据分布如表1所示.
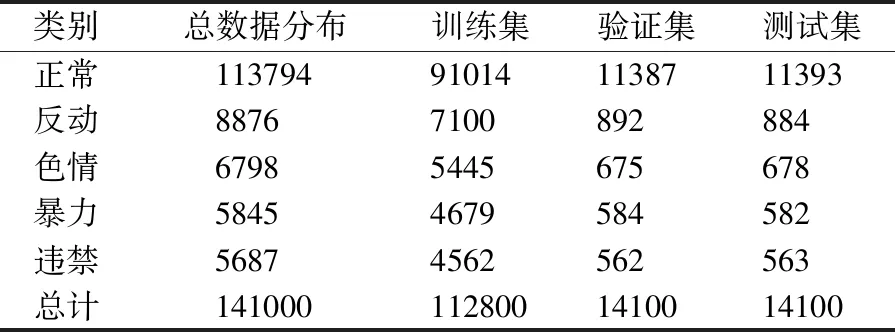
表1 实验数据分布Table 1 Data distribution
4.2 实验环境与参数设置
实验环境如表 2 所示.
在实验中,我们使用了谷歌开源的Bert预训练权重[12],隐层输出维度为768,我们使用差分学习率,Bert层学习率设为2e-5,Attention层和分类层学习率设为2e-3,优化器使用AdamW,dropout率设置为0.2,设置切分后的每个互联网新闻片段最大长度为200.
表2 实验环境Table 2 Lab environment
4.3 实验结果与分析
在本实验中,采用准确率,召回率以及精确率和 F1值作为评价指标,为了验证模型的有效性,本文实现了 3 个对比实验模型与本文提出的模型进行比较.
KWM:是指基于关键词策略的敏感信息识别方法[2],这也是目前用的最多的方法,但是由于互联网新闻信息是不断变化的,每天都会产生新的术语和词语,需要不断更新迭代关键词,费时费力,泛化性能弱,且很容易对正常互联网新闻造成误伤.
TextCNN:Yoon Kim[7]提出了 TextCNN,首次将卷积神经网络 CNN 应用到自然语言处理任务中,利用多个不同 size 的 kernel 来提取句子中的关键信息(n-gram 特征),从而能够更好地捕捉局部相关性,该模型经常作为敏感信息识别的基准模型.
Hi-Bert(Att):本文提出的对Bert模型进行改进使其可以适应互联网新闻长文本的分层Bert模型,该模型没有融合传统方法关键词特征,与融合了关键词特征的Mer-Hi-Bert模型作为对比,从而验证融合了关键词特征的Mer-Hi-Bert模型的有效性.
Hi-Bert(Add):直接将互联网新闻每个片段的语义向量进行求和拼接(Add),而不是使用Attention模块将互联网新闻每个片段的语义向量按照重要性进行求和拼接.与Hi-Bert(Att)形成对比,从而验证Attention模块的有效性.
对比模型和本文提出的模型在互联网新闻数据集上的实验结果如表3所示.
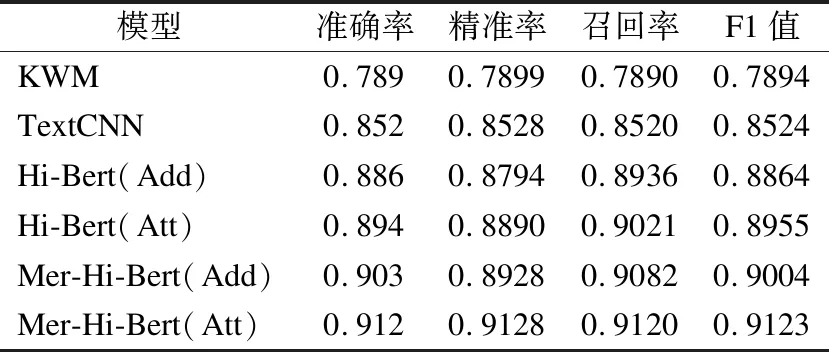
表3 实验结果Table 3 Lab result
由表 3 可以看出:
1)基于基于关键词策略的敏感信息识别方法KWM准确率与F1值都不是很高,这是因为在互联网新闻中,文本都很长,相比于短文本来说,更容易误认为正常新闻为含有敏感信息的新闻.
2)与KWM相比,TextCNN模型有较大的提升,这是因为深度学习方法可以学习到文本更深层次的语义特征,从而减少误伤情况,并且有些文本仅凭关键词是无法识别敏感信息的,必须更深层次的去理解上下文的语义和逻辑才能准确识别是否属于敏感信息.
3)与TextCNN相比,Hi-Bert模型有了很大的提升,这是因为目前自然语言处理领域最先进的预训练模型在大规模语料上通过无监督的方法学习到了大规模的先验知识与语义特征,在下游任务如敏感信息识别上只需要进行微调就可以取得很好的效果,相比于TextCNN来说,Hi-Bert模型的上下文语义编码能力更强,可以学到更多深层次的语义信息.
4)与Hi-Bert模型相比,融合了敏感关键词特征的Mer-Hi-Bert模型有一定的提升,在本次数据集上取得了最好的效果.这说明将传统的基于敏感关键词策略的方法与目前深度学习中最先进的预训练方法相结合可以取得更好的效果,不应该彻底抛弃传统的方法.
5)相比与直接将互联网新闻每个片段的语义向量进行求和拼接(Add),使用Attention模块(Att)将互联网新闻每个片段的语义向量按照重要性进行求和拼接更有效.
5 结束语
针对于互联网新闻的敏感信息识别任务,本文提出了一种融合关键词特征的互联网新闻敏感信息识别模型 Mer-Hi-Bert.该模型改进了Bert模型,原始的Bert模型不适合新闻长文本任务,改进后的分层Bert模型第1层是通过分句模块将长文本分句归并成多个片段,对每个片段使用Bert模型提取语义特征,第2层是对于提取后的多个语义特征向量使用Attention机制按照重要性进行求和拼接,相比与直接求和拼接更适合于新闻长文本的敏感信息识别,因为每个片段对于整篇文档的敏感信信息识别贡献程度不同,包含了敏感信息的片段重要性更高,给与更高的权重更有利于敏感信息识别.融合了敏感关键词特征使得模型能更大程度上的学习到互联网新闻敏感信息特征,传统方法与深度学习方法相结合产生了更好的效果.最终,通过爬取的真实互联网新闻数据集上进行实验对比,本文的模型比其他方法在敏感信息识别上有更好的准确率与F1值.目前文章模型中传统方法与深度学习方法结合较为简单,未来可以进一步设计模型加强传统方法与深度学习方法的结合.
