Bert在微博短文本情感分类中的应用与优化
2021-04-12刘彦隆
宋 明,刘彦隆
(太原理工大学 信息与计算机学院,山西 晋中030600)
1 引 言
近年来,随着互联网技术的迅猛发展,微博、推特等社交媒体的出现使用户从信息的接收者转变为主动发起者,海量数据的迸发,给文本处理任务带来了挑战,单单依靠人工方法来挖掘信息不切实际,因此,通过某种技术手段自动化、智能化地处理任务成为迫切需求.与此同时,深度学习,机器学习等人工智能技术正渗透到各行各业,为中文短文本情感分析技术革新带来了参考意义.
文本情感分析是自然语言处理研究的一个热点,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1].其中一个重要问题就是情感分类,也就是情感倾向性判断,即判断文本的观点是积极褒义的,消极贬义的还是客观中性的.自然语言处理技术快速发展,越来越多的研究者关注于网络用户的情感分析.Yang 等[2]改进 Kim的模型,基于卷积神经网络理论,对 Twitter 推文进行了分类研究,并验证了卷积神经网络对 Twitter 信息情感分类的优越性能,这种方法只考虑到了文本局部特征,未能捕获较长文本前后的信息相关性;周瑛等[3]引入深度学习理论,提出了基于注意力机制的LSTM(Long-Short Term Memory)模型,模型解决了长文本微博信息的情感特征分析.但LSTM仍具有计算费时,梯度消失等局限,同时标注成本高,同一词汇在不同领域的多种含义仍限制了性能的提升;对于小数据集的自然语言处理任务,ULMFiT[4](Universal language model fine-tuning for text classification)提出了一种高效的迁移学习方法,缓解了数据集不足的问题;为平衡简单样本和困难样本的贡献,OHEM[5]算法选取高损失值的样本作为训练样本,加强了对困难样本的学习程度,但完全忽略了高概率的简单样本对模型的贡献.
现有微博数据内容涵盖范围较广,同时关注敏感话题、相关领域等.从头训练的机器学习方法训练费时,对数据量也有一定要求,成本较高.因此本文提出Bert[6](Bidirectional Encoder Representations from Transformers)预训练模型作为网络结构,初始化网络参数进行迁移学习,以获取深层语义信息,提升泛化能力.首先将此算法与经典情感分类算法卷积神经网络TextCNN[7](Convolutional neural networks for sentence classification)、长短期记忆网络LSTM[8]、通用语言模型微调Ulmfit等模型进行性能对比.并针对困难样本容易分错的问题,将Focal Loss[9]引入到中文文本情感分类任务中,结合对比实验,本文提出的方法在多分类任务中优于同类算法,Focal Loss一定程度提升对困难样本的分类能力.
2 相关工作
2.1 Bert语言模型预训练
通过预训练得到语言的表征工作已经进行了数十个年头,从传统密集分布的非神经词嵌入模型[10]到基于神经网络的 Word2Vec[11]和 GloVe[12],这些工作提供了一种初始化权值的方法,在多项自然语言处理任务中,不仅使训练方式便捷很多,模型的效果同时有明显的提升作用.Bert把语言模型作为训练任务,通过无监督预训练的方式抽取大量语言信息,并迁移到其他下游任务.
采用Transformer[13]网络结构进行预训练,受完型填空任务的启发,采用“masked language model”(MLM),并在所有网络层中把上下文信息同时考虑在内,此方法突破了单向语言模型的局限.进而可以得到深层双向的语言表示.
Bert采用双向 Transformer 结构,通过放缩点积注意力与多头注意力直接获取语言单位的双向语义关系.通过 Transformer 结构获取到的信息优于传统的RNNs 模型以及对正反向 RNNs 网络直接拼接的双向 RNNs 模型.
2.2 输入表示
Bert的输入是由两个句子相连的序列,每个句子前面添加一个标识符[CLS]表示句子开始,尾部添加一个标识符[SEP]作为结束,两个句子通过分隔符[SEP]隔开.对于每个单词,Bert进行了3种不同的嵌入操作,分别是对单词位置信息进行编 码position embeddings、对单词进行Word2vec 编码token embeddings、对句子整体进行编码segmentation embeddings.将这3种嵌入结果进行向量拼接,可以得到Bert输入,如图1所示.

图1 Bert的输入表示Fig.1 Input representation of Bert
2.3 Masked LM
ELMo[14]使用经过独立训练的从左到右和从右到左LSTM的串联来生成用于下游任务的功能.OpenAI GPT则是使用从左向右的单向Transformer作为网络结构.事实上,深层双向模型比从左向右模型或从左向右和从右向左模型的浅层连接更强大.不幸的是,因为双向条件将允许每个单词在多层上下文中间接“看到自己”.故标准条件语言模型只能从左到右或从右到左进行训练.
为了解决语义单向问题,Bert将输入词的15%随机进行掩蔽(Mask),其中被掩蔽掉的词80%几率被[MASK]替代,10%几率是正确的词汇,10%几率替换成词汇表中随机词汇,通过训练语言模型预测这些词来抵消“镜像问题”的影响.但是语言模型无法学习到句子间的关系,于是 Bert引入下句话预测(NSP)任务来解决这个问题.预训练后 Bert无需引入复杂的模型结构,只需要对不同的自然语言处理任务进行微调、学习少量的新参数,即可通过归纳式迁移学习将模型用在源域与目标域不相同的新任务中.Mask LM流程如图2所示.
2.4 Transformer编码器
Bert模型采用Transformer作为特征提取器,模型由多个Transformer层叠加构成.Transformer 编码器有两个子层,分别是基于自注意力机制的自注意力层和全连接前馈网络层.同时,在每个子层内都加入了残差结构(residual)和归一化层(layer nomalization),结构图如图3所示.
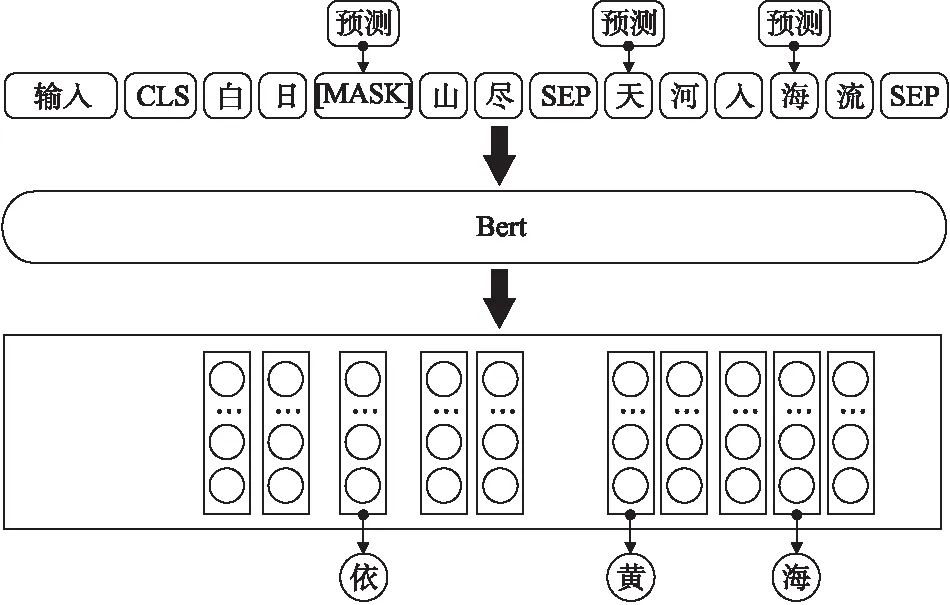
图2 Masked LM流程Fig.2 Process of Masked LM
其中h个缩放点积注意(Scaled Dot-Product Attention)组成多头自注意力模型(Multi-Head Attention).作为基本单元,缩放注意力计算公式为:
(1)

MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
(3)

图3 Transformer编码器Fig.3 Transformer encoder
如果对矩阵Q、K和V进项线性计算,转换成不同的矩阵,然后使用 h 个缩放点积单元进行计算,把h个缩放点积单元计算的结果组合起来,就能够获得更多的语义特征.由于每个缩放点积单元的输入 K、Q 和 V 在进行计算时的权重不同,就能够获取来自文本不同空间的语义特征.以捕捉句子中的每个词关于上下文的信息.
前馈网络层由两个大小为 1的卷积核组成,使用 ReLu 激活函数做两次线性转换
FFN(x)=max(0,xW1+b1)W2+b2
(4)
其中W1和W2是权重,b1和b2为偏置项.最后经过残差网络和层归一化得到最终输出.
Transformer 编码器网络总共使用n个编码器抽取文本的特征,后将学习到的分布式特征使用全连接层将特征整合映射到样本标记空间,以便进行文本情感倾向性分类.
3 基于Focal Loss优化Bert微调模型
3.1 交叉熵损失函数
对于大多数文本分类任务,通常采用交叉熵(Cross Entropy,CE)作为损失函数,其计算公式为公式(5):
CE(pt)=-log(pt)
(5)
其中:
(6)
pt是某事件发生的概率,pt属于[0,1].对于多分类情况,实际为二分类扩展,如公式(7)所示:
(7)
其中M为类别数量,yc指示变量,如果样本预测类别和该类别相同则为1,否则为0,pc为预测样本属于类别c的概率.
3.2 引入权重的Focal Loss 算法
传统交叉熵作为损失函数时,未考虑到简单样本和困难样本对模型优化的贡献程度差异,数量多且简单的样本占loss优化的绝大部分,此类样本容易分类loss值较低,相对而言,数量少的困难样本对loss的优化贡献下降,导致模型的优化方向并不理想.故本文提出了基于Bert迁移学习模型fine tuning时,采用重塑交叉熵损失的方法Focal Loss,降低被良好分类样本的损失权重,并把重点放在稀疏的困难样本上,即情感倾向较难划分,预测概率较低的一类样本.以优化损失函数,进一步提升情感多分类模型效果.
首先在传统交叉熵基础上,添加了调制因子(1-pt)γ,计算公式为式(8):
FL(pt)=-(1-pt)γlog(pt)
(8)
其中(1-pt)γ为调制因子,γ∈[0,5]为聚焦参数,γ取不同值对结果影响不同,当γ=0时,FL=CE,等于传统的交叉熵函数;当γ>0时,降低了简单样本的相对损失值,进而将注意力放在困难样本和分错的样本上.例如当pt=0.9且γ=2时,FL=0.01CE,即得分越高pt越接近1,损失权重越小,简单样本对损失函数的影响越小;相反,当pt=0.2且γ=2时,FL=0.64CE,这样得分值越低pt越接近0,损失权重越大,而不是将CE同比降低,困难样本对损失函数的影响越大.因此,在训练过程中加强了困难样本的训练,对简单样本减少训练.
FL(pt)=-α(1-pt)γlog(pt)
(9)
进一步α作为平衡权重,如式(9)所示,α∈[0,1],控制正负样本对总的loss的共享权重,调节缩放比例.FocalLoss同时在一定程度上能缓解数据不均衡问题,无论哪种类别数据较少,由于样本少导致在实际训练过程中更容易判错,种类特征学习不够,置信度也变低,损失也随之增大.同时在学习过程中逐渐抛弃简单样本,因此,剩下了各类别的困难样本,可以达到同样的训练优化目的.
3.3 情感分类模型训练流程
具体基于Bert与Focal Loss的情感分类模型微调流程如图4所示,首先对标注的微博语料进行数据预处理,包括去除无关字符,特殊符号等;然后进行分词,根据position embeddings、token embeddings、segmentation embeddings得到Bert的输入向量表示;输入到经过初始化的预训练Bert模型中,利用分类器预测值与真实标签值对比并通过Focal Loss算法得到损失值;最后优化器进行优化调整权重参数,重复fine tuning过程直至迭代结束.

图4 Bert-FL模型训练流程Fig.4 Training process of Bert-FL model
4 实验与分析
4.1 实验数据
本文数据是针对广播电视领域,通过网络爬虫爬取新浪微博某时间段热点话题评论数据,通过人工对微博评论数据的情感倾向进行标注整理,得出积极正面语料5027条,消极负面语料5058条,中性语料9939条,共计20208条数据集.
微博数据内容不规范,通常包含一些与情感分类无关的符号,例如网址链接url,话题内容“#话题#”,“@用户”,类似的这些字符并不是人们想要表达的信息,这些无用的信息可能对接下来的情感分类效果造成一些影响.所以首先要删除过滤掉这类无关字符,一般通过正则表达的方法来处理,去除特定字符进而保留文本的主要内容.在运行各算法之前,通常要对文本分词,本实验统一采用jieba来分词.另外,根据个别算法的要求,有时也需要对停用词进行处理,对照停用表将其去除.将预处理后的数据存放在本地数据库中,进行下一步语料库的划分,其中每个类别随机抽取439条,共计1317条用作测试集.剩下每个类别随机抽取90%用于训练构建模型,10%用于验证调整模型参数.详见表1.
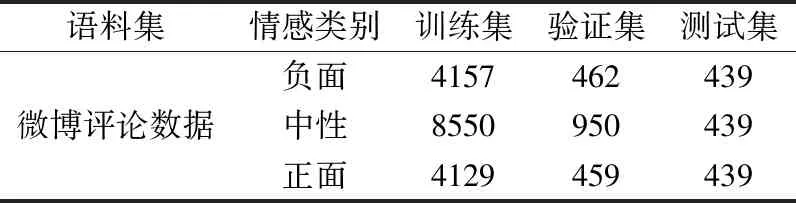
表1 数据集划分Table 1 Date set partition
4.2 评价指标
准确率(Accuracy)是在衡量文本分类结果时常用的直观的评价指标.它是在测试文本中,预测标签与实际标签吻合的文本所占的比率.计算公式为:
(10)
预测时长是指在同等文本数量情况下,各模型完成预测所占用的时间.
4.3 结果及分析
为验证双向语义编码表示Bert的有效性,实验首先构建Bert网络结构,并用同样的数据集在一些经典情感分类方法上进行训练预测,多次训练得出各自最优模型对比.
由于实验数据是中文微博短文本,且微博规定评论内容不超过140个词,结合实验所用服务器的内存大小,故处理文本的最大长度设置为150,同时对过短为句子也不做处理.Bert模型训练的具体参数如表2所示.实验在Linux CentOS 7.3.1611下进行,采用Anaconda虚拟环境编程,实验基于Tensorflow 1.11.0和Pytorch 1.3.0深度学习框架来搭建模型,并使用两块TITAN X(Pascal)GPU来运行模型.

表2 Bert超参数设置Table 2 Bert hyperparameter setting
实验结果如表3所示,从实验结果可以看出,在整体准确率方面,基于预训练的迁移学习模型都在90%以上,均优于从头训练的网络模型,其中Bert的分类准确率最高,达到91.56%.由于Transformer编码器在处理文本序列时,序列中单词之间不受距离的限制,任意单词之间的关系都可以捕获.一定程度证明Transformer编码器效果优于LSTM.TextCNN准确率最低,因为其提取的局部特征在任务中会缺失部分前后相关语义信息.LSTM准确率相较于TextCNN提升不明显原因可能是大部分句子长度较短,简单的单向LSTM并没有发挥提取长期特征的优势.但在分类速度上,TextCNN的分类速度远远超过迁移学习类模型,仅需1s,原因是CNN其权重共享特征,参数大大减少,Bert模型速度最慢.另外无论LSTM与Transformer网络结构都相对复杂一些.对比试验表明,Bert模型在短文本情感分类任务中准确率最高,但分类速度表现略差.

表3 各模型分类结果对比表Table 3 Comparison table of classification results of each model
虽然Bert网络模型整体预测准确率略有提升,但由于数据中存在情感倾向较难区分的句子,这些因素都不同程度对分类准确率造成了影响.为解决此问题,进一步构建基于Focal Loss的Bert模型,进行多组实验,选出最优权重因子α参数,如表4所示.

表4 Bert-FL不同参数在测试集的表现Table 4 Performance of different Bert-FLparameters in the test set
由表4可以看出,当γ= 2且α= 0.75时,能达到最高准确率92.39%,证明了此参数更适合本次情感分类任务.同时与Bert的最高准确率91.56%相比,提升0.83%,可以得出,此方法在整体准确率上略有提升.各类别预测结果如表5所示,对比实验结果表明,改进后的Bert-FL模型在数据相对较少的负面和正面的分类准确率均有一定提升,整体准确率分布更加均衡.
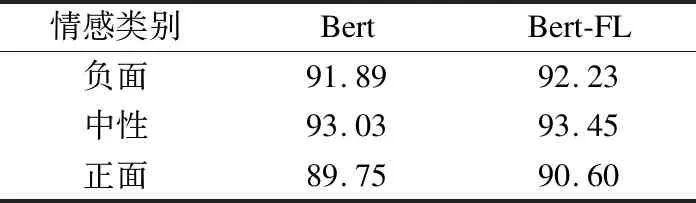
表5 各情感类别准确率对比Table 5 Comparison of accuracy rates of various emotion categories
为进一步验证Focal Loss对困难样本的学习能力,实验从439条测试集中人工筛选出408条简单样本,31条困难样本进行测试.Bert和Bert-FL 在简单/困难样本中的表现如表6所示.

表6 Bert-FL在简单/困难样本中的表现Table 6 Performance of Bert-FL in easy / hard samples
由表6可以看出,将Bert的损失函数替换成Focal Loss后,简单样本的准确率变化不明显,而对于31条困难样本预测准确率,模型有一定程度的提升.这是因为简单样本置信度高,损失小,权重因子α与γ参数的作用使得损失变化更小,参数更新越微小;与之相比,困难样本置信度低,损失较大,优

表7 各类别例句Table 7 Example sentences for various category
化器着重学习此类样本.实验结果一定程度验证了改进后的算法在不影响简单样本分类效果的情况下,提升了困难样本的分类准确率.证明了该算法的可行性与有效性.表7展示了数据集中正面、中性、负面3类别例句以及困难样本例句.
5 结束语
本文在面向广播电视微博领域的中文短文本情感多分类任务中,提出了Bert作为预训练模型初始化网络参数,在模型微调时刻采用Focal Loss替代交叉熵,一定程度缓解训练数据稀疏的困难样本和较多的简单样本对分类器学习贡献度不同的问题.该方法仍然有不足之处,训练模型大及参数过多,预测时间长等.在今后的研究工作中将继续优化算法模型,改进模型缺点.提升模型在工程中的应用效果.
