基于Deeplabv3+模型的成都平原水产养殖水体信息提取*
2021-04-09苟杰松蒋怡李宗南董秀春吴柏清刘忠友
苟杰松,蒋怡,李宗南,董秀春,吴柏清,刘忠友
(1.四川省农业科学院遥感应用研究所,成都市,610066;2.成都理工大学旅游与城乡规划学院,成都市,610059)
0 引言
水产养殖提供优质蛋白营养产品,是满足人们食物消费升级的重要途径[1]。水体信息反映了水量、水质、时空分布等特征,是研究动植物生存、生态系统调节、水产养殖活动等水资源需求的基础数据[2-3]。提高水体信息的提取能力有助于水产养殖业科学化管理,对提升渔业信息化具有重要作用[4]。
光学遥感与微波遥感是获取大范围水体信息的有效途径[5-6]。由于数据源较多,光学遥感提取水体信息研究更为成熟和广泛[7-8]。水体具有典型光谱特征,其光学反射集中于可见光波长范围尤其是蓝绿波段内,在红外光谱反射率低,易于与其他地物区分[9]。根据光学遥感提取水体信息的技术原理,当前常用的方法主要有基于像元分类的阈值法[10-13]和基于目标分类的分类法两种[14-17]。
阈值法主要是基于影像的光谱特征构建各种分类模型和水体指数,根据阈值判定水体;目标分类法包括支持向量机、面向对象法、最大似然法等,该类方法能较充分利用影像的光谱、纹理和空间几何等特征来提取水体信息。遥感影像中水体存在同物异谱、异物同谱的现象:受漂浮物、水草、水深等影响,部分水体光谱特征差异较大;建筑物、阴影等在部分光谱波段的低反射特征与水体近似。因此,阈值法易将低反射率的地物错分为水体。目标分类法能较好地利用影像的光谱特征、像元间的空间临近关系,相比于阈值法能部分抑制背景噪声。
随着卷积神经网络(Convolution Neural Network,CNN)在图像分类和图像识别方面的成功应用[18-20],深度学习在遥感影像水体分类和语义分割中能更有效地利用遥感影像的光谱和纹理等特征,减少光谱特征近似水体地物的错分现象,逐渐得到研究及应用[21-26]。Yuan等[21]使用CNN和Landsat OLI影像识别格林兰冰原湖泊水,水体识别结果优于多种传统分类方法。Zhang等[22]建立一种基于CNN和残差网络ResNet等集成的水体分类模型,在Landsat TM/ETM+和HJ-1影像上有效区分了水体和阴影区。Long等[23]集合CNN和逻辑回归分类器提取Landsat影像水体,比支持向量机和传统人工神经网络具有更好的性能。陈前等[24]分别用CNN和Deeplabv3对高分一号影像的水体进行分类和语义分割。
随着深度学习在遥感影像处理方面的应用,越来越多的研究基于Tensorflow、Caffe、Pytorch等平台搭建深度学习模型,但这些平台同时存在流程处理较繁琐和结构调试较困难等问题。近年来,国产深度学习平台不断得到建设发展,提供多种从实际业务中反复淬炼优化的训练模型,并支持多种数据接口类型和工业级部署,以百度PaddlePaddle和阿里X-Deep Learning等为代表。已有相关研究鲜有利用国内深度学习平台开展水体信息提取研究。
因此本研究基于百度的PaddlePaddle平台搭建遥感水体信息提取模型,分析Deeplabv3+语义分割模型和Sentinel 2A遥感影像提取水体信息的效果,为水产养殖遥感水体信息的快速准确提取提供依据。
1 材料与方法
1.1 研究区概况
研究区为四川省成都平原,经纬度范围为103.7°~104.27°E,29.27°~31.34°N,幅员面积约1.3万km2。该区域属于亚热带季风性湿润气候,年均气温16 °C,年降雨量1 000 mm左右,干湿明显,雨季主要集中在6月中旬到9月中旬,区域内地势平坦、城镇密集、遍布农田、水体类型丰富,满足研究条件。其中,本文水体信息提取模型的训练区选择有河流、湖泊、水库、坑塘等广布的区域,主要分布于都江堰市及周边地区,占地面积约500 km2;测试区用于评估本文模型和其他对比方法的分类精度,选择存在大量阴影、建筑和农田等对比区,主要分布于新津县及周边地区,占地面积约400 km2。
1.2 数据来源
Sentinel2A(S-2A)多光谱影像设有13个3种不同空间分辨率的波段(10 m、20 m和60 m),高分六号(GF-6)是中国首颗精准农业观测的高分卫星,配置2 m 全色/8 m多光谱和16 m多光谱相机。研究选取S-2A卫星10 m和GF-6卫星16 m多光谱影像为数据源。为保证GF-6影像与S-2A影像空间分辨率一致,将GF-6数据重采样为10 m空间分辨率。
该研究训练区、测试区、成都平原应用提取区选取2018—2019年多幅S-2A影像和GF-6影像,包括不同区域、不同季节、不同时相。其中,(1)训练区选用3个不同时期同一区域S-2A影像,该3幅影像质量相对较好,伴随少量云雾,水体信息季节性变化明显,能反映受水量、水质变化影响水体表现的不同光谱、纹理特征,可以兼顾到训练模型的泛化能力;(2)测试区选用1幅S-2A影像,检验测试模型的分类精度和迁移能力;(3)在成都平原水体面积泛化提取应用中,选用2018年的不同区域S-2A影像拼接得到2018年研究区,选用2020年的不同区域GF-6影像拼接得到2020年研究区。
1.3 研究方法
研究基于Deeplabv3+语义分割模型和遥感影像提取水体信息,主要包括3个步骤:(1)搭建环境依赖;(2)建立水体信息语义分割数据集;(3)训练并保存Deeplabv3+语义分割模型。
1.3.1 Deeplabv3+模型结构
Deeplabv3+[27]是Deeplabv系列的最新版本,在Deeplabv3[28]的基础上,其加入了解码器模块,通过编码器—解码器(Encoder-Decoder)借鉴跳步的方式连接低层特征和高层特征,进行多尺度信息的融合,原理如图1所示。
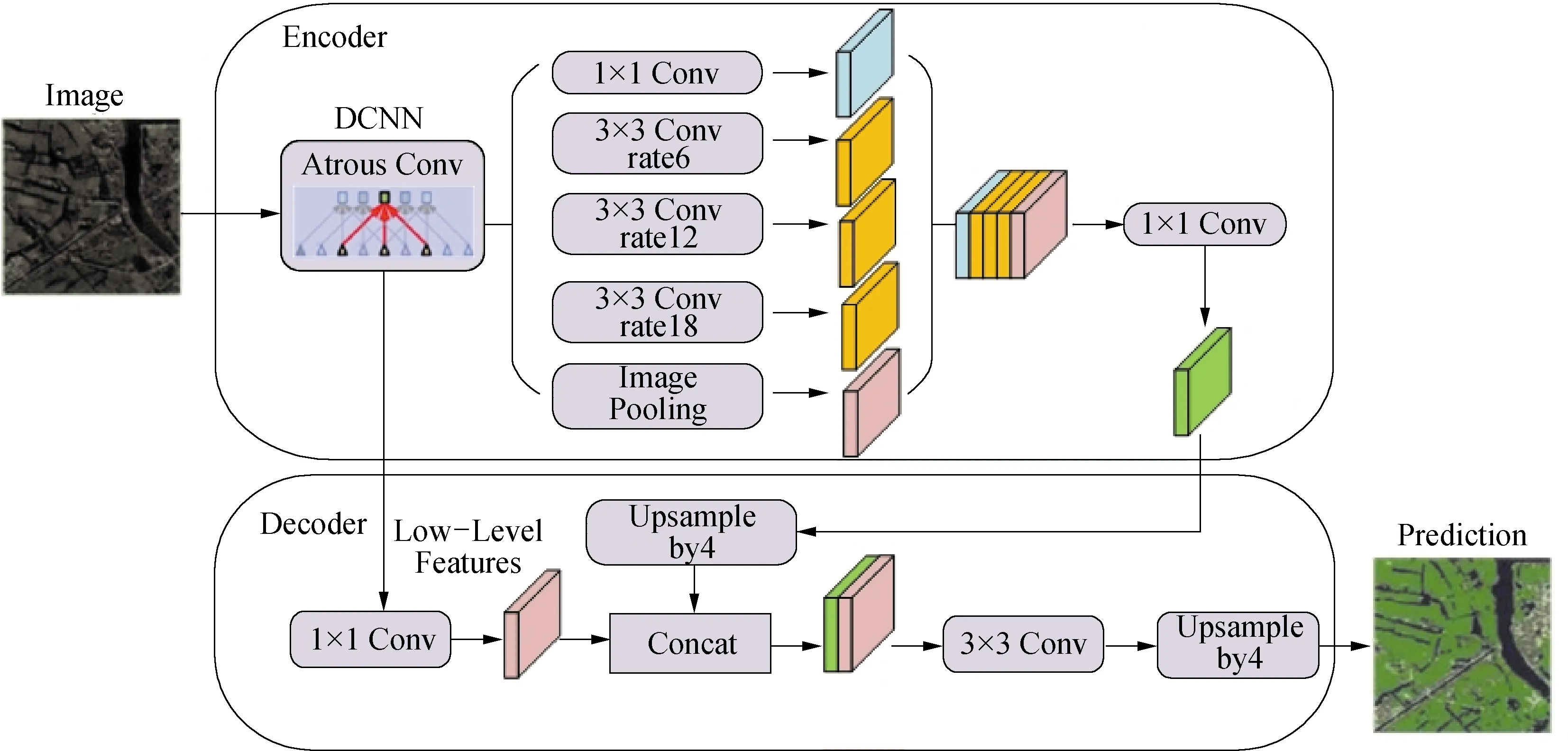
图1 Deeplabv3+模型原理图
Encoder以改进的Xception替换了ResNet作为骨架网络,该网络由一系列深度可分离卷积组成,提高了模型语义分割的健壮性和运行速率。其中,多孔卷积(Atrous Convolution)控制DCNN计算特征响应的分辨率,采用多种不同比率来获取多尺度的内容信息,分别输出高层特征图和低层特征图。Encoder中多孔空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)采用4个并行带有不同比率的多孔卷积和1个全局池化(Image Pooling)对高层特征图分别进行单独处理,处理后的5个特征图融合输入到一个1×1卷积中,然后经过4倍双线性内插上采样(Upsample)输入到Decoder中使用,连接低层网络中具有相同空间分辨率的特征图。
Decoder中首先用一个1×1卷积处理低层特征图,减少特征图通道数,再将其与经过4倍双线性内插上采样的高层特征图进行融合,然后3×3卷积后经4倍双线性内插上采样恢复至原图分辨率,最终完成语义分割。
1.3.2 Deeplabv3+模型搭建
研究基于百度PaddlePaddle平台的PaddleSeg搭建水体信息提取模型。PaddleSeg是端到端图像分割开发套件,集合了Deeplabv3+、U-Net、ICNet、PSPNet、HRNet、Fast-SCNN等主流分割模型,支持rgb、rgba和gray三种图片数据接口,内置数据校验、训练、评估、可视化、预测等脚本并支持不同的命令行来开启特定功能和修改默认配置。此外,还包括数据增强模块、多进程训练和混合精度训练等高级功能。本研究Deeplabv3+模型搭建具体过程如下。
1)搭建环境依赖。安装模型运行的相关环境依赖,主要包括PaddlePaddle 1.6.1、Python 3.7、CUDA 9、PaddleSeg 0.4.0版本。
2)建立水体信息语义分割数据集。(1)样本标注:在Deeplabv3+模型的样本组织过程中,相对于纯人工手动标记,依靠现有的遥感影像与其对应目标的矢量数据,半自动采集大规模的遥感影像语义分割样本,是一种便捷高效方式。本文从成都平原S-2A影像截取了3景同一区域、不同时期22 500像素×22 500像素大小的影像切片,在Arcgis中以人工目视解译的方式,对研究区具有代表性的水体进行标记,水体像素被标记为1,背景像素则标记为0,标记结果转换成png格式,共两种类型作为深度学习模型的训练标签数据与模型精度验证的标准。(2)样本影像的波段选择:从S-2A 10 m空间分辨率的4个波段中选取识别率均值最高的3个波段,本文分别试验了红—绿—蓝、近红—红—蓝、近红—红—绿等波段组合,最终选取水体信息提取精准度最高的近红(R)—红(G)—绿(B)波段顺序进行组合。(3)样本影像裁剪:由于截取的研究区影像切片尺度较大,不能直接输送到模型中训练,因此在语义分割模型训练前要对训练样本分割。综合考虑模型训练速度、训练精度以及训练样本空间结构特征的整体性,通过多尺度的训练样本分割试验,将影像裁剪为512像素×512像素尺度大小的训练样本,并转换成jpg格式。(4)数据集格式:用于水体信息语义分割的数据集采用Cityscape数据集格式。训练集标注数据和图像数据各1 176张,用于训练模型。测试集940张图像数据,用于检测模型的精度和泛化能力。其中,部分训练样本如图2所示。

图2 水体信息语义分割训练数据集
3)训练并保存Deeplabv3+语义分割模型。(1)训练模型:通过PaddleSeg库上yalm文件配置各项参数,以微调(Fine Tune)的方式训练模型,主要设置包括6项:模型骨架网络选取Xception_65;初始学习率(Learning Rate)为0.001;学习策略(Learning Policy)为“poly”[29];权重衰减(Weight Decay)为0.000 04;训练批数(Batch Size)为8;迭代次数(Epoch Number)为50。训练过程中还通过增添数据增强模块(Aug),防止样本不足带来的过拟合,提升模型泛化能力和鲁棒性,即通过随步长随机缩放、镜像翻转、图像旋转、非等比例缩放、色彩抖动等多种方式来增加训练数据量。(2)保存模型:导出模型及其参数配置文件,生成预测yalm配置文件。
1.4 水体信息提取
执行基于Python端的模型预测脚本,通过训练好的Deeplabv3+模型在线分割测试集S-2A影像和研究区全域影像,预测分割后的结果按文件编号匹配对应遥感图像,并拼接研究区全域矢量水体图斑。
1.5 精度评价
本研究以归一化差分水体指数法(Normalized Difference Water Index,NDWI)[30]和最大似然法(Maximum Likelihood,ML)[31]等两种水体信息提取方法作为参照,再辅以2019年3月28日0.5 m的Worldview2高分遥感影像获取高精度水体分布数据,评估Deeplabv3+水体信息语义分割方法的性能。随机选择4个500 m×500 m包含坑塘、水库等多种水体类型的样方,获取0.5 m分辨率水体分类结果,再重采样为10 m分辨率的结果,通过设定阈值保证重采样后的结果与0.5 m水体图斑总面积不变,以此作为水体信息精度验证的标准。计算各类方法的水体分类混淆矩阵,得出各方法的漏分误差、错分误差、总体精度和Kappa系数。
2 结果与分析
2.1 测试区水体信息提取结果
根据表1的精度验证结果,使用来源于S-2A的样本数据在Deeplabv3+模型下提取水体信息性能最优,总体精度、Kappa系数分别达到94.14%、0.88,较之ML方法和NDWI方法的总体精度分别提升了2.53%和6.04%,Kappa系数提升了5%和12%,且漏分误差和错分误差最低,为6.76%和6.21%。说明该语义分割算法在面对复杂的地物条件下,通过逐层神经网络训练,学习目标深层次信息和整体规律,实现目标像素级的分类,可提高水体信息的提取精度。
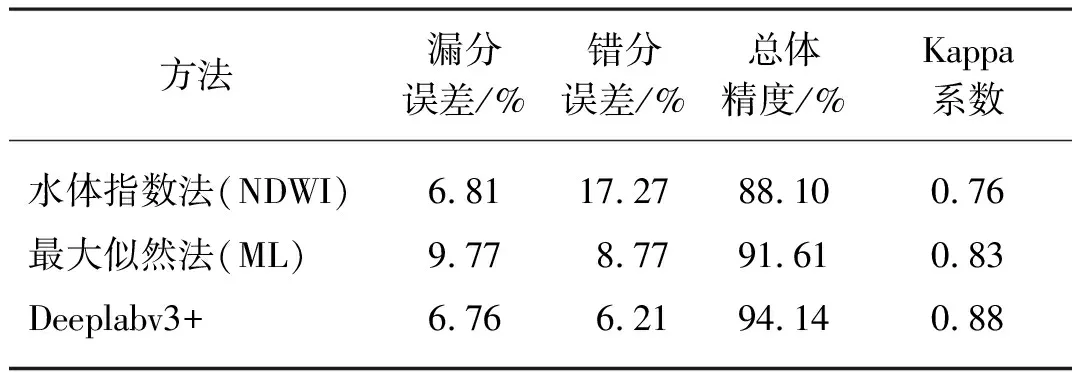
表1 不同水体信息提取方法的精度对比
各方法在不同场景下提取水体信息的具体效果见图3,其中,图3(a)以大水面为主;图3(b)以大面积池塘为主;图3(c)以小面积池塘和河流为主。各图周围均分布建筑、阴影和农田作为提取效果对比区。
在水体面积较大的河段水面和池塘上(图3(a)、图3(b)),3种方法的水体信息提取效果与地面真实标签吻合度都较好,但Deeplabv3+语义分割模型能更有效抑制水面周围的阴影和建筑等背景干扰,水体错分现象几乎不存在,ML方法能在一定程度上去除背景干扰,NDWI方法可以通过简单操作和较快速度提取出大部分水体区域,有效抑制植被等因素,但背景噪声相对较多。在小面积池塘和细长水体分布的场景中(图3(c)),Deeplabv3+语义分割模型表现较差,小面积水体信息提取效果较一般,对细小线状水体提取能力较弱,水体边缘整体呈现出平滑、规整的状态,无法充分描述目标边缘的细节信息,而ML方法和NDWI方法在此类场景中则无明显漏分现象,整体提取效果较好。

(a)
2.2 成都平原养殖水体面积提取
水体面积是决定水产养殖产出能力的重要影响因素[32],本研究中的水产养殖水体主要是指内陆养殖水体(包括池塘、山塘水库以及大水面等封闭型水体,不包括水稻田),而海水养殖水体(包括海水池塘、浅海设施养殖区)和典型非养殖水体(包括河流、进排水渠等流动性水体及公园内观赏水体)不作为该文的研究范畴养殖[33]。
本研究利用深度学习模型分别对研究区2018年S-2A卫星影像和2020年GF-6卫星影像进行了水体信息提取,通过规则识别方法和目视解译判断出养殖水体信息,选取2018年青白江区、新津县和广汉市作成都平原养殖水体面积精度验证区,2018年青白江区、新津县和广汉市的养殖水体提取面积分别为472 hm2、615 hm2和785 hm2,对应的渔业统计年鉴面积分别为490 hm2、571 hm2和805 hm2,验证结果误差均≤±10%,达到全国水产养殖水体资源遥感监测项目相关技术要求[33-37],满足区域级泛化提取条件。
对比分析成都平原两年间养殖水体面积的变化,结果如图4所示。
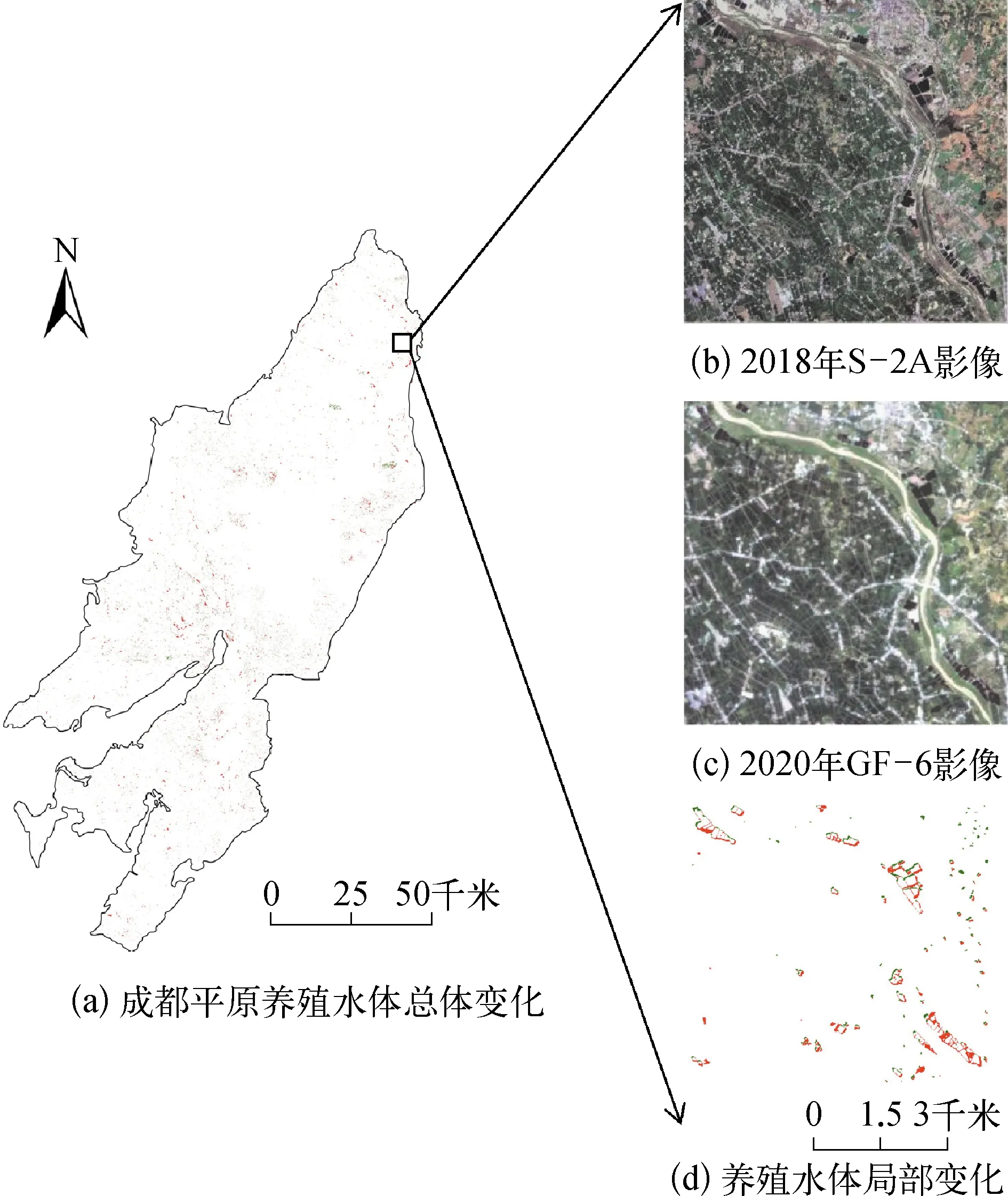
图4 成都平原养殖水体面积变化
成都平原2018年和2020年养殖水体面积分别为22.3 khm2和28.6 khm2。图4(a)中部成都市主城区范围基本上无养殖水体面积变化,而成都平原范围内其它区域如图4(d),养殖池塘水体面积发生较多变化。通过对比研究区S2-A和GF-6两年的养殖水体影像,发现养殖水体面积变化易受人类活动和季节性变化影响,人类活动如政策驱动限制或禁止某一区域水产养殖活动的产生(如城市建成区、大型湖泊和水库等),而季节性降雨和排灌也对养殖水体面积也有较大影响。
3 讨论
3.1 深度学习模型的构建选择
通过验证表明本研究建立的Deeplabv3+语义分割模型可准确提取水体信息,精度总体优于NDWI及ML方法,且能较好地抑制阴影等背景影响,但受限于S-2A遥感影像的空间分辨率较低、训练样本影像波段数少、模型误差等因素,该方法对部分小面积和细小线状水体的识别、语义分割等存在不足。对此,通过深度学习方法进一步提高水体信息提取的精度有待更多相关工作的改进,包括测试更多类型的高分辨率遥感数据、通过改进数据接口使用3个以上波段的遥感影像训练及分割、优化模型结构及参数等。
3.2 内陆养殖水体信息提取不足
由于文中定义的养殖水体不包括河流、进排水渠等流动性水体及公园内观赏水体,这些非养殖水体与内陆养殖水体有着共同的纹理和光谱信息,深度学习模型提取水体信息是基于像素特征而得,因此无法判断水体像元是属于哪一类水体。海水养殖有网箱养殖、滩涂插养、浮筏养殖等,在遥感影像上有其明显的空间纹理特征,其影像光谱在浅海养殖与深海区域也有明显的区别,已有相关研究取得了不错的海水养殖水体信息自动化提取效果,而内陆淡水养殖水体信息提取自动化程度也有待进一步提升和挖掘。
4 结论
1)基于Deeplabv3+模型的水体信息提取总体精度为94.14%,Kappa系数为0.88,相比于其他方法,Deeplabv3+语义分割模型能有效抑制阴影、建筑物等背景噪声,提高了水体信息提取精细化程度,具有水体信息提取的适用性。
2)基于深度学习平台PaddlPaddle的PaddleSeg建立的水体信息提取模型,通过较少样本数据、参数微调、简易脚本命令,可迁移模型实现水体信息区域级泛化提取能力,提高了水体信息提取自动化程度,具有水体信息提取的便利性。
3)对研究区的养殖水体面积提取结果表明,2018年和2020年成都平原养殖水体面积分别为22.3 khm2和28.6 khm2,验证区结果误差≤±10%,达到全国水产养殖水体资源遥感监测项目相关技术要求。
