基于改进AdaBoost算法对环柄菇毒性判别研究*
2021-04-09李健熊琦胡雅婷
李健,熊琦,胡雅婷
(吉林农业大学信息技术学院,长春市,130118)
0 引言
随着社会经济发展和人类对生活质量要求的不断提高,食用菌出现在人们的餐桌上的频率越来越高,但食用菌的安全性问题一直存在很大的争议。由于中国地大物博,食用菌种类繁多,对食用菌毒性判定的方式也是多种多样[1]。其中民间对蘑菇毒性的判别方式主要依赖观察其外形外观,颜色和菌类的特征,闻菌类的气味等方法,这些方法对判别人的经验有较大依赖性,判别误差率高等缺点。学术界则是通过研究菌类的成分进行毒性判别[2]。这类方法虽然准确率大大提高,但是存在检测效率不高,实验要求苛刻等缺点。
近年来,随着机器学习在人工智能领域的大火,近年来,随着机器学习在人工智能领域的大火,机器学习算法对解决工业问题提供了新的思路,众多学者[3-5]开始将机器学习模型开始与工业领域相结合,比如李卓识等[6]将机器学习算法引入到真菌分类问题中,王聃,毛彦栋等[7-8]将机器学习算法引入到病虫害识别问题中,陈桂芬等[9]将机器学习算法引入到遥感图像分类中,这些模型均能与各自领域的实际情况与存在的问题相结合,提供了有效的解决办法。随着大数据时代的到来,数据的种类、数量都有极大的提升,由于某些机器学习模型针对海量数据存在着运行时间慢,准确率低等问题,特征筛选方法[10-12]被提出,该方法可以解决数据集高维度,高密集的问题,降低了模型的复杂度,使得机器学习更好地融入各个领域之中。
由于菌类的特征值存在不连续,多维度等特点,非常适合用机器学习中的分类算法进行判别,目前业界中有很多使用机器学习算法对蘑菇毒性判别的案例,均取得了不错的准确率,对蘑菇毒性判别具有重要意义。刘斌等[13]将基于贝叶斯算法应用到了蘑菇毒性判别之中,这种算法必须满足样本特征独立分布的前提,且这种算法不存在很好的实际物理意义,不易于理解,对数据要求较高等缺点。樊哿等[14]利用了支持向量机算法,这种算法预测的准确率很高,但是这种算法基于较小的数据集为前提才会获取到较好的效果,不适用于规模较大的数据集。李旺等[15]提出了基于宽度学习的蘑菇毒性判别方法,该模型具有极高的准确率,但是需要极高的数据量作为训练基础,对数据集的要求非常苛刻,适用的领域并不广泛。因此,集成学习方法[16]被引入。集成学习是一种通过构建多个弱分类,再将其组合成一个强分类器的学习方法,AdaBoost算法作为目前最具有价值的集成学习算法,众多学者[17-18]将该算法引入工业界解决分类问题。但该算法的权值更新机制容易造成不公平的权值分配,且容易导致噪声样本权值的无限增大,不少学者针对该缺点对算法进行了改进[19-20]。
本文针对AdaBoost算法存在的问题,提出了一种改进权值更新方式的AdaBoost算法,该算法基于逻辑回归为弱分类器,在弱分类器训练阶段和弱分类器的组合阶段,两部分对原算法进行了改进,删去了特征中权值系数过小的特征,针对多次分错的样本,添加惩罚系数降低该样本的权值,以提高整体分类的准确度,为食用菌毒性判别问题提供了新的思路和解决方案。
1 材料和方法
1.1 数据采集
本文使用的公用数据集是加州大学欧文分校提供的环柄菇数据集,该数据集中共包含8 124组样本,共22个特征,分别为帽形,帽面,帽色,瘀伤,气味,鳃附着,鳃间距,鳃大小,鳃颜色,茎形,茎根,茎表面在环上,茎—表面—环下,茎—颜色—环上,茎—颜色—环下,面纱类型,面纱颜色,环号,环状型,孢子印刷色,种群,栖息地。部分数据集如表1所示。

表1 部分环柄菇数据集
1.2 研究方法
1.2.1 传统AdaBoost算法
AdaBoost算法是一种通过迭代将多个弱分类器组合成一种强分类器的算法。算法本身是通过不断改变数据的权值来实现的,针对弱分类器中错误分类的样本,算法会逐渐加大错误分类样本的权重,并降低分类正确的样本的权值,使得算法在下一次弱分类器选定数据样本时,会着重于上一次迭代中错误分类的样本,通过这种方式,AdaBoost的训练过程会聚焦于容易分类错误的样本,最终将每次训练得到的弱分类器加权求和,形成了最终的决策强分类器。算法框架如图1所示。
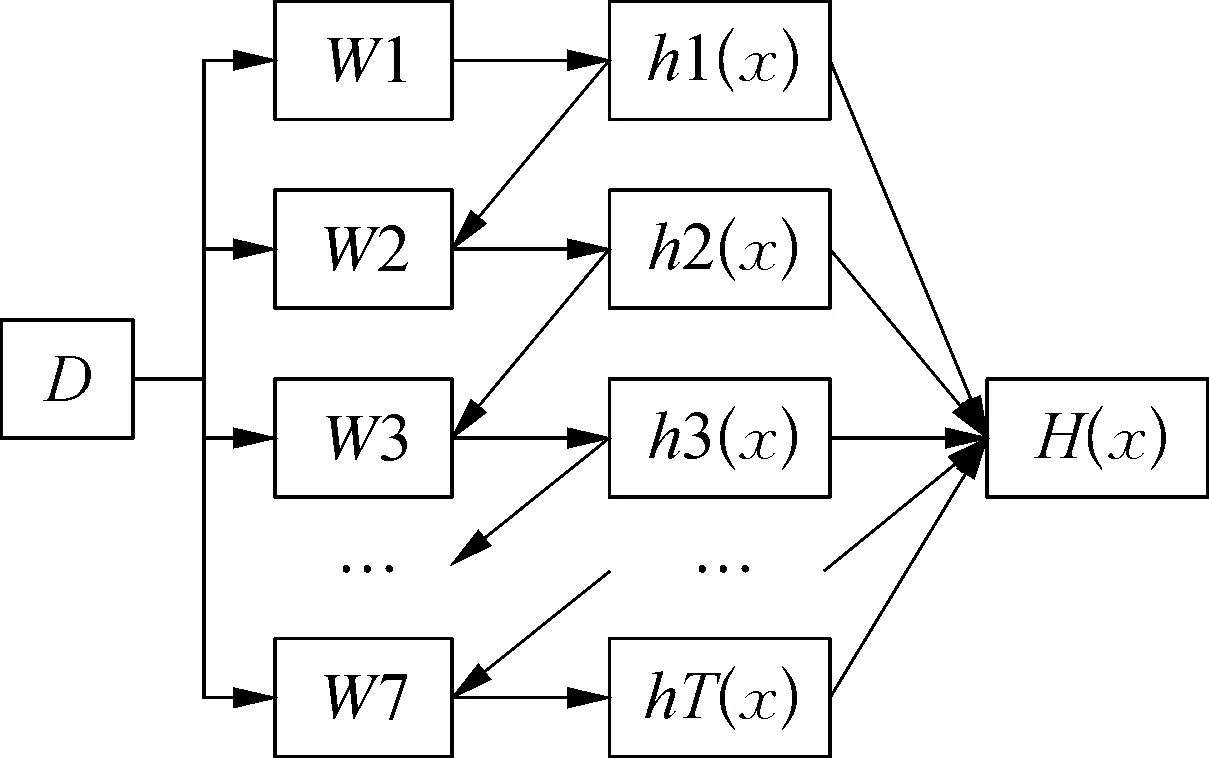
图1 AdaBoost算法框架
相比较单个的分类器,经过AdaBoost算法集成的最终决策强分类器具有更好的稳定性和分类准确率,但是AdaBoost算法的缺点也很明显,在算法的数据划分阶段,AdaBoost算法的迭代次数不好确定,如果定的过少,算法拟合不足,如果迭代次数过多,则会导致弱分类器的运行时间过长。在算法的迭代过程中,噪声样本点在迭代的过程中权值会无限增大,从而使非噪声样本点选入到新的弱分类器的概率降低,从而降低最终的强分类器的准确率。
1.2.2 逻辑回归算法
逻辑回归实际上是一种线性分类器,是基于线性回归变化而来的一种模型,由于满足线性规律的真实场景并不多,为了解决该问题,线性回归在实际应用中引入了诸多变化形式,将对数函数融到线性回归中就得到了逻辑回归的基本表达式,函数如式(1)所示。
(1)
二元逻辑回归的样本服从伯努利分布(即0~1分布),由此可得预测标签分别为0和1时的概率如式(2)和式(3)所示。
P(y=1|x)=y(x)
(2)
P(y=0|x)=1-y(x)
(3)
由式(2)和式(3)可得P(y|x)的表达式如式(4)所示。
P(y|x)=y(x)y×[1-y(x)]1-y
(4)
假设样本独立且同分布,求得式(4)的最大对数似然估计就得到了最终的损失函数,如式(5)所示。
(1-y)×log[1-yθ(xi)]}
(5)
采用梯度下降法求取损失函数的极小值,就可以得到该逻辑回归算法的最优的系数,达到该逻辑回归模型的最好效果,同样逻辑回归的缺点也很明显:在特征空间很大时,计算的复杂度会很高,会大大降低逻辑回归算法的性能,所以在特征数目很多的数据集下,通常不使用逻辑回归算法。
1.2.3 改进的AdaBoost算法模型
通过分析作为弱分类器的逻辑回归算法和AdaBoost算法,可以很直观的得到算法的缺点,针对上述问题,本文提出了一种基于改进数据特征筛选和弱分类器权值更新的AdaBoost算法,该算法分为弱分类器训练和弱分类器组合两个阶段。
在改进之后的AdaBoost算法的弱分类器阶段,针对作为弱分类器的逻辑回归算法无法很好的处理样本特征空间过大的问题,本文提出了根据各个样本特征所占的权重大小,逐步减去样本特征数目的方法。本文提出了根据各个样本特征所占的权重大小,逐步减去样本特征数目的方法。该方法首先将全部特征带入到算法中运行,计算出每一个特征的特征权重,将特征权重最小的特征删除,就能得到新的特征子集,将新的特征子集带入算法之中重新计算新的特征权重并删除特征权重最小的特征,重复执行该过程,直到算法准确率小于阈值,特征筛选结束,得到了最佳特征子集。流程如图2所示。
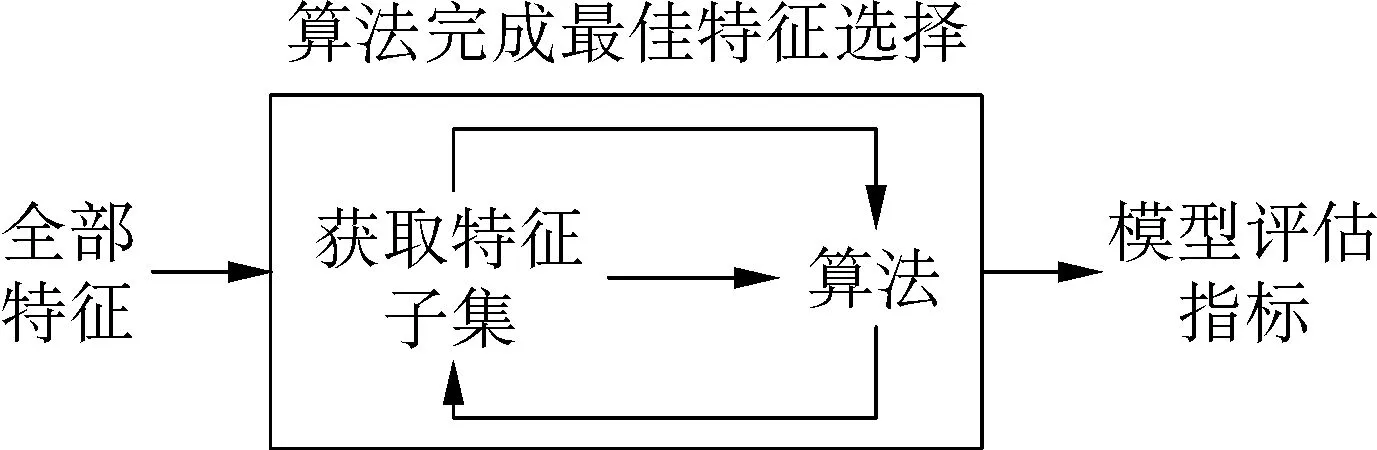
图2 数据集特征空间筛选方法
样本特征的权值系数代表了每个特征在对样本预测值得重要性,信息熵是度量样本几何纯度的最常用的一种指标,假设样本集合D中第k类样本所占的比例为Pk,则D的信息熵如式(6)所示。
(6)
假定离散的属性a有V个可能的取值,若使用a来对样本D进行划分,则会产生V个子集,其中第V个子集包含了D中所有在属性a上取值为av的样本,记作Dv,根据式(6)得到信息增益的公式如式(7)所示。
(7)
假设样本集D上第j个特征,可以计算出每个训练集D下的信息增益,在对得到的K个信息增益值进行归一化处理,就可以得到每个特征所占的权重,如式(8)所示。
(8)
根据式(8)对弱分类器数据集中的每个特征分别计算权重,并从大到小进行排序,根据设定的权值系数的阈值ω0对特征空间进行筛选,使得下一次迭代的弱分类器的数据集中删去了权值系数过小的特征,从而提高了运算效率,解决了弱分类器逻辑回归中由于特征空间太大,使逻辑回归算法效果不好的缺点。
针对迭代过程中噪声点权值系数过大的问题,本文提出了在权值过大的样本点加上惩罚项的方法,如果迭代结束的样本权重大于阈值w,则会在权重加上惩罚项,降低该样本的权重,减少了由于样本噪声点对整个模型的影响,如果迭代之后的样本权重小于阈值w,则不会对该样本点加上惩罚项。对于给定的数据集x={(x1,y1),(x2,y2},…(xn,yn)},首先计算出在第i次迭代后,样本X的权重Dx并对所有样本的权重进行归一化,本文使用了混淆矩阵中的FN值和FP值的比值作为权重的惩罚项,混淆矩阵如表2所示。

表2 混淆矩阵
混淆矩阵中的列元素代表了真实样本中的标签,所有的行元素代表了模型输出的预测标签,将FN/FP的比值ψ作为惩罚项是为了能够更好地看清该样本是对标签为0的样本分类能力较差还是标签为1的样本分类能力较差,可以更好地锻炼模型。每次迭代之后的样本的错误率如式(9)所示,根据错误率可得样本的权重如式(10)所示。
(9)
(10)
根据本文设计的改进之后更新权值方法,当预测值等于真实值时,样本在下一轮迭代时的权重如式(11)所示。
(11)
在预测值不等于真实值,权重小于等于阈值时,样本在下一轮迭代时的权重如式(12)所示。
hi(xi)≠yi,Dt(xj)≤Wt
(12)
在预测值不等于真实值,权重大于阈值时,样本在下一轮迭代时的权重如式(13)所示。
hi(xi)≠yi,Dt(xj)>Wt
(13)
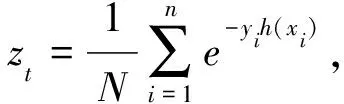
1.2.4 改进的AdaBoost算法模型
上述的两点改进措施分别针对了AdaBoost算法和逻辑回归中的两种缺点,整个改进后的算法流程如下。
输入:训练数据集x={(x1,y1),(x2,y2),…,(xn,yn)},权值系数的阈值ω0。
输出:最终得到的强分类器F(X)。
1)对数据进行归一化处理,使样本值分布在[0,1]之间。
2)初始化训练样本的权值分布并初始化训练数据的权重分布值:Dm表示第m个弱学习器的样本点的权值D1=(ω11,ω12,ω13,…,ω1N),ω1i=1/N,i=1,2,…,N。
2 结果与分析
2.1 环柄菇毒性判别模型
本文提出的环柄菇毒性判别模型首先将数据集的特征进行数值化处理,再进行归一化处理,采用3∶7的比例,随机划分数据集之后,得到了测试集和训练集,对训练集集样本进行特征筛选,建立起了改进后的AdaBoost模型,将测试集带入模型并对模型进行评分,根据模型分数再进行调参,得到最终的模型,输出最终的预测结果,如图3所示。
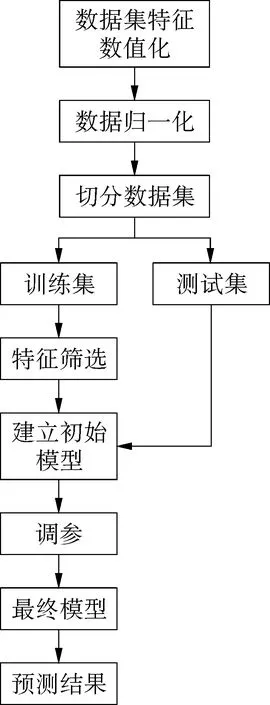
图3 模型流程图
2.2 结果分析
本文为了突出改进之后的AdaBoost模型的优化效果,分别建立了单一的逻辑回归分类器和传统的AdaBoost分类器模型进行比较,本文采用了混淆矩阵作为算法模型的评判指标,根据混淆矩阵可以得到该模型的准确率,精度,召回率和F1-值。准确率是混淆矩阵中的TP值和TN值的和除以样本总数,表示了分类模型中所有判断正确的结果占总样本数的比例,精度是由混淆矩阵中的TP值除以TP值和FP值的和,表示了在模型预测为1的所有样本中,真实值也为1的比重,召回率是由混淆矩阵中TP值除以TP值和FN值的和,表示了真实值为1的所有样本中,模型预测正确的比重,而F1-值是结合了精度和召回率的指标,取值范围在0到1之间,越靠近1表示模型的预测效果越好。同时也分别计算了真实值为0和1时的各个指标的大小,各项指标的平均值和加权平均值。
按照上述试验流程分别对三种不同的算法进行了测试,测试样本总数为2 438个样本,最后将三种算法的指标值简化整合后,得到了最终的测试对比结果如表3所示。
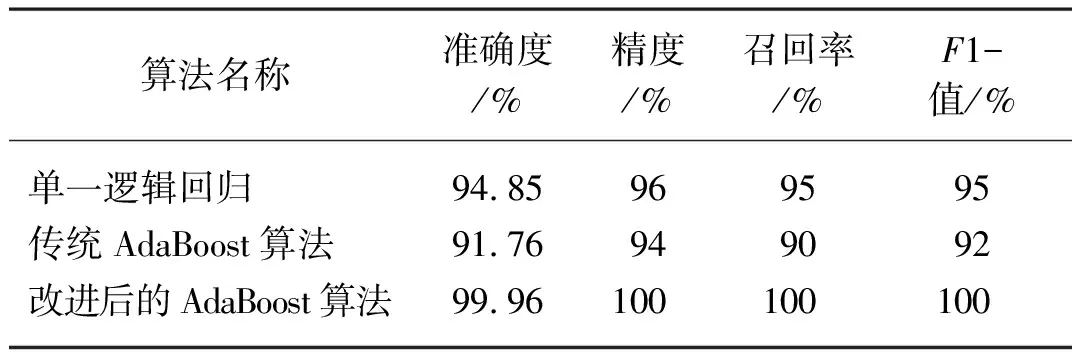
表3 不同算法测试结果对比
由表3可以看出本文提出的改进的AdaBoost算法在各项指标中均有极高的评分,模型分类效果远超其他两种算法。通过对比三种算法的准确度可得,单一的逻辑回归分类器达到了94.85%的准确率,传统AdaBoost算法易受噪声点的影响只达到了91.76%的准确率,而本文提出的改进后的AdaBoost算法解决了这一问题,准确率达到了99.96%,比单一的弱分类器模型和传统的AdaBoost分类器的准确率平均提高了7.5%,且并不易受噪声点影响。考虑到模型是为了判定环柄菇是否具有毒性这一目的,召回率的大小对模型优劣起到了很大影响,逻辑回归算法成功分类出95%的有毒样本,传统AdaBoost算法只成功分类出90%的有毒样本,而改进后的AdaBoost算法成功分出了所有的有毒样本,改进后的模型在判定环柄菇是否含有毒性的问题上具有很高的稳定性和安全性。
为了更直观的观察到改进后的算法的性能,本文引入了ROC曲线,ROC曲线可以很容易的查出任意界限值时对性能的识别能力,从而选择最佳的界限值,本文提出的改进后的算法的ROC曲线如图4所示。
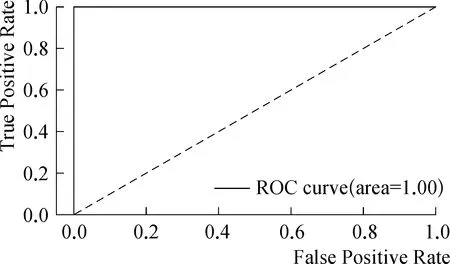
图4 改进的AdaBoost分类器的ROC曲线
ROC曲线越靠近左上角,实验的准确性就越高,亦可通过计算ROC曲线下的面积AUC进行比较,AUC越大,模型的效果越好,由图4可以观察到,改进后AdaBoost算法的ROC曲线下的面积AUC为1,达到了AUC的极大值。
通过在公用数据集的实验表明,本文提出的改进后的AdaBoost算法性能远高于单一的逻辑回归分类器和传统的AdaBoost分类器,在对环柄菇毒性判定中取得了完美的效果,在一定程度上改进了传统AdaBoost分类器中权值更新中存在的缺陷导致拉低模型评分的局限性。
3 结论
1)本文提出的改进后的AdaBoost分类器模型,通过添加了对数据样本的特征筛选环节和在集成迭代的过程中调整样本权值更新的方式,以避免样本产生过大的权值并对新建的弱分类器产生影响为目标,运用了混淆矩阵中的FN值和FP值,并将两者的比值作为了惩罚项,添加到了更新权值的公式中。
2)该改进后的模型远优于单一的逻辑回归弱分类器和传统的AdaBoost分类器模型,分类的准确率平均提高了7.5%,在一定程度上解决了蘑菇毒性判定的问题,并树立了新的判别模型,但改进之后的模型存在计算量较大,运行时间较长的问题,将成为日后蘑菇毒性判别模型改进的研究方向。总体而言,本文提出的模型确实提高了预测的准确率,在蘑菇毒性分类问题上有较高的实际利用价值。
