基于MSD-Vnet 的三维医学图像配准
2021-04-08李姗姗张娜娜张媛媛丁维奇
李姗姗,张娜娜,张媛媛,丁维奇
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
图像配准提供了对通过不同方式获得图像进行视觉分析的能力。医学图像配准的目的是建立两个或多个三维医学图像之间的解剖对应关系,提高医学AI 分类诊断和定量疗效评价等。近年来,基于深度学习的图像配准方法证实了神经网络的能力,取得了不错的成果。文献[1-3]提出的医学图像配准方法在训练过程中需要大量人工精确标注的真实变形场,然而获取精确标注的真实变形场是个难题,且配准的精度受人工标注的影响。文献[4-7]提出的医学图像配准方法解决了真实变形场方面的难题,但文献[4-5]的部分方法只支持小的变换,意味着在配准任务中可能丢失解剖结构的位置信息。此外,上述方法的精度有待提高。因此,提出了一种新的医学图像配准方法,可变形配准网络为编解码结构,在没有任何标注的真实变形场预测整个位移向量场。所提方法在训练过程中不需要真实变形场等标注信息,且为了提高配准精度,在标准编解码结构上做了多尺度跳过连接、选择核注意力机制和深度监督3 方面改进。在ADNI 脑数据集上对所提出方法进行评估,验证了所提方法的准确性。
1 方 法
所提配准方法的整体架构如图1 所示。使用可变形配准网络MSD-Vnet 端到端预测整个位移向量场,其中固定图像F 和移动图像M 作为可变形配准网络的输入,MSD-Vnet 对函数gθ(F,M)=φ 进行建模。
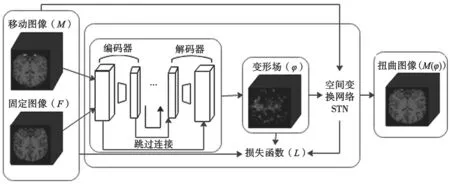
图1 三维医学图像配准的整体架构
训练过程中,通过空间变换网络(Spatial Transformer Network,STN)将位移向量场φ 和移动图像M 扭曲获得扭曲图像M(φ),通过最小化扭曲图像M(φ)和固定图像F 之间的相似性损失和位移向量场φ 的正则化损失来指导训练找到最佳的参数θ,表示为:
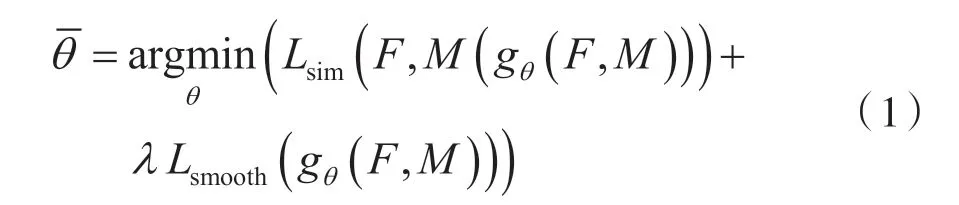
式中,对于每个体素p ∈R3,φ(p)使F(p)和M(φ(p))定义相似的解剖位置。M(φ)为通过空间变换网络(Spatial Transformer Network,STN)对移动图像M 施加位移向量场φ 扭曲后的图像,Lsim(·)度量扭曲图像M(φ)和固定图像F 之间的相似性,Lsmooth(·)表示对变形场φ施加正则化,λ是正则化参数。在配准过程中,给定一个图像对M 和F 的情况下,可以通过一组最优化的参数θ 快速获得位移向量场φ,从而得到扭曲图像M(φ)。
1.1 可变形配准网络MSD-Vnet
可变形配准网络MSD-Vnet 遵循编解码结构,如图2 所示。在编码器阶段,使用步长为2 的卷积对图像进行降采样。降采样操作执行3 次,使图像的分辨率分别为之前的1/2、1/4 和1/8。3 层结构中,卷积层的数量分别为1、2、3,其中最后两层结构中的卷积使用残差单元。然后,使用具有3 个卷积层的残差单元连接编解码底端。在解码器阶段,使用上采样恢复空间分辨率。与编码器阶段类似,上采样和卷积操作重复3 次,3 层结构中卷积层的数量分别为3、2、1。特别地,MSD-Vnet 在编解码结构之间引入多尺度跳过连接。在解码器端对来自各个尺度的特征映射进行级联,并将级联得到的特征映射经过一个选择核注意力机制网络,从而充分利用医学图像的多尺度特性获取更多与配准有关的信息。同时,MSD-Vnet 包含深度监督机制,可以使配准网络更好地学习,最终输出位移向量场,即一个具有3 个通道(x、y、z 位移)的三维特征图。它的大小与输入相同,均为160×192×224。
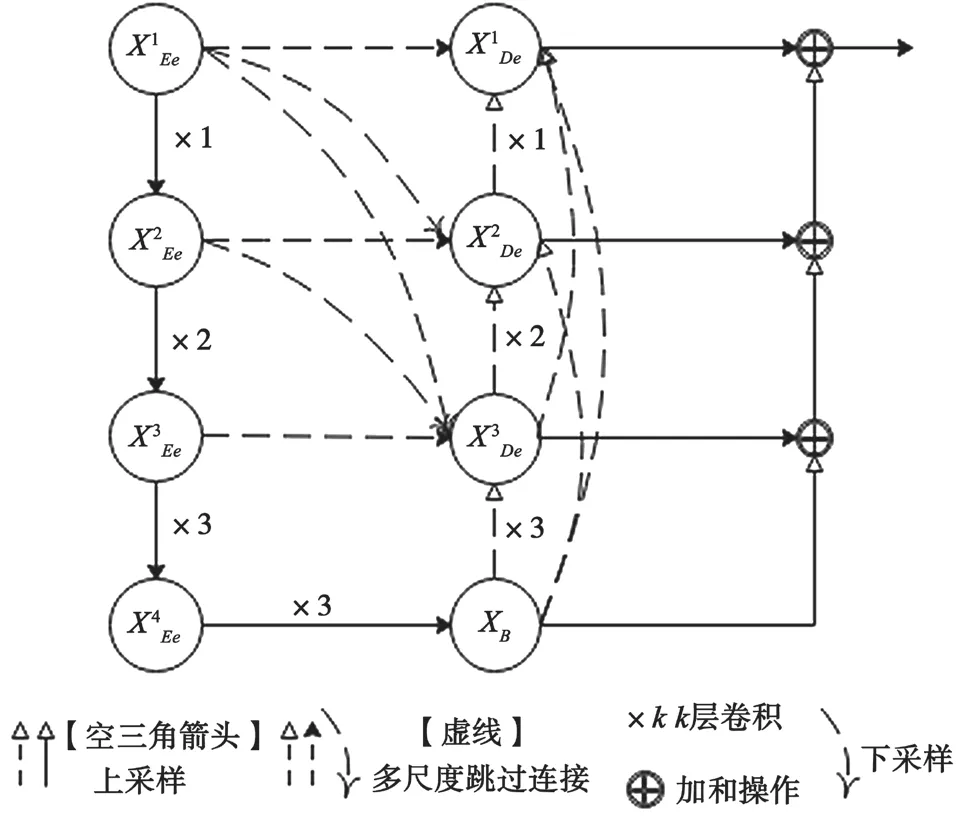
图2 可变形配准网络MSD-Vnet
1.1.1 多尺度跳过连接
基于编解码结构的卷积神经网络中,由跳过连接连接的特征映射之间存在差异。以可变形网络最顶层的跳过连接为例,编码器端的特征映射是原始图像,而解码器端的特征映射类似于最终的位移向量场。这两组差异较大的特征映射进行级联,会对预测过程产生不利的影响。基于此,MSD-Vnet 在编解码器之间引入多尺度跳过连接,以使医学图像的解剖结构位置信息更加精确。
多尺度跳过连接使每一个解码器层都结合了小尺度的特征映射、同尺度的特征映射以及大尺度的特征映射[8],过程如图3 所示,展示了构造层的特征映射方法。
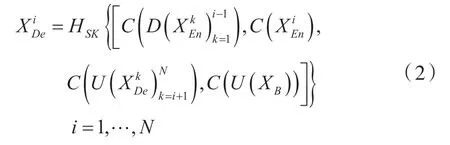
式中,i 是沿着编码器下采样层的索引,N 与下采样的次数相同,C(·)表示卷积操作,D(·)和U(·)分别表示下采样和上采样操作,[·]表示级联操作,HSK(·)表示选择核注意力机制。
1.1.2 选择核注意力机制SKNet
MSD-Vnet 的编码器端使用选择核注意力机制SKNet。这种非线性的多核信息聚合方法能够根据输入信息自适应地调整感受野的大小,获取更多与配准有关的信息。选择核注意力机制SKNet 由分离、融合及选择3 部分组成。具体地,对于给定的特征映射X ∈RD×H×W×C,首先通过两个卷积核大小不同的卷积进行两个变换,分别为F1:X →U1∈RD×H×W×C和F2:X →U2∈RD×H×W×C。通过加和的方式融合两个分支变换得到的结果,即:

通过一个全局平均池化嵌入全局信息,生成信道统计信息s ∈RC。式中,s 中的每个元素都是通过在空间维度D×H×W 对U 进行压缩得到,第c个元素的计算公式为:
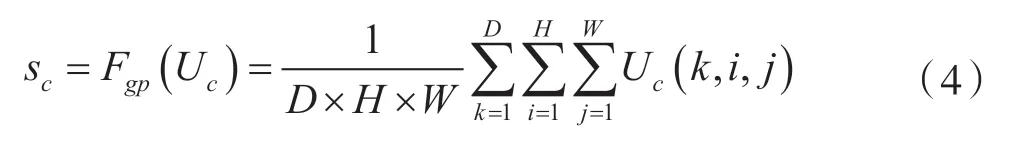
使用完全连接层将压缩得到的特征变得更加紧凑z ∈Rd×1,其中d 是再次压缩后的通道数。通过上述操作可达到提高效率的效果:

最后,使用softmax 函数,根据不同核上的注意力权重a和b 得到最后的特征映射Fclast,即:
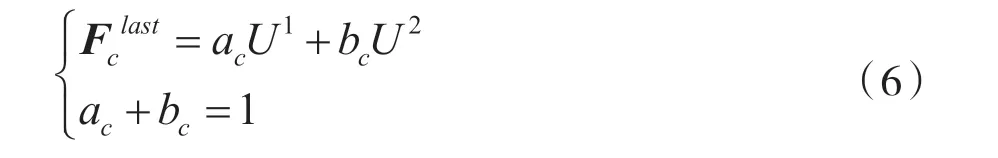
式中:
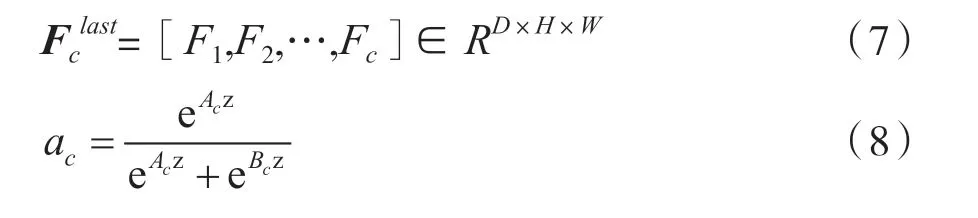

图3 基于多尺度跳过连接的特征融合

式中,Ac,Bc∈Rc×d,Ac是A 的 第c 行,ac是a 的第c 个元素;Bc与bc同理。
1.1.3 深度监督
可变形配准网络MSD-Vnet 在各个层添加了深度监督辅助分支,从MSD-Vnet 底部依次提取不同分辨率层次的阶段性预测结果作为生成层的输入。低层特征生成的阶段性预测结果进行上采样,并依次与高层特征生成的阶段性预测结果进行融合,从而综合多个分辨率下的阶段性预测结果生成融合预测结果。
1.2 损失函数
损失函数由两部分组成:一部分是扭曲图像M(φ)与固定图像F 之间的相似性度量Lsim,另一部分是施加于位移向量场φ 的正则化损失项Lsmooth。相似性度量惩罚外观上的差异,正则化损失项惩罚位移向量场φ 的局部空间变化。
损失函数L 计算公式如下:
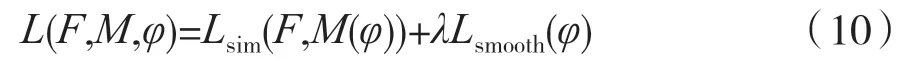
式中,λ 是正则化参数。
均方体素差MSE 作为相似性度量为:
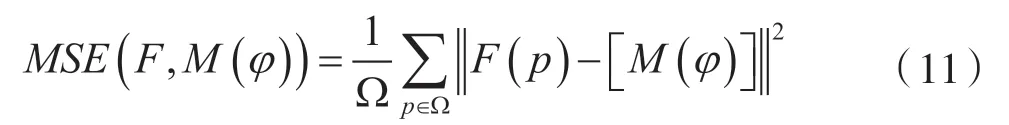
式中,Ω 表述输入图像的空间域,p 表示空间域内的体素。
在其空间梯度上使用扩散正则化器平滑φ,有:
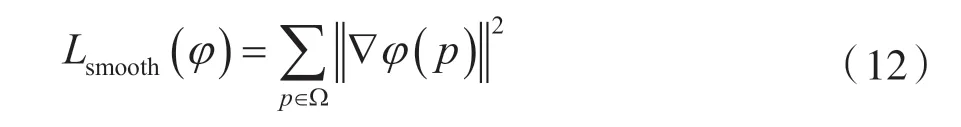
式中,Ω 表述输入图像的空间域,p 表示空间域内的体素,φ(p)是相邻体素之间的差异。
2 实 验
2.1 数据集
通过公共数据集ANDI[9]的脑MRI 数据评估提出的方法。首先,使用FreeSurfer[10]对大脑数据进行剥离和重采样,将体素间距变为1 mm×1 mm×1 mm。其次,将图像大小切割为160×192×224,并对数据进行归一化。最后,用ANTs[11]进行仿射变换(Affine)。另外,采用数据增强的方法对图像进行不同程度的扭曲,达到扩增数据的目的。
2.2 评估方法
在对配准后的图像和固定图像的解剖结构进行分割的基础上,使用戴斯相似性系数(Dice Smilarity Cefficient,DSC)来评估网络的性能。戴斯相似性系数(DSC)的计算公式为:
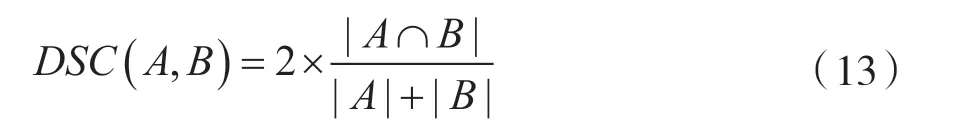
式中,A 和B 是某个解剖结构组成的一组体素。A 和B 重叠的区域越大,DSC 的数值越大。完全重叠的区域DSC=1。数值越接近1,说明配准的精度越高。
2.3 实 施
实验在Ubuntu 16.04 操作系统下进行,使用Keras 和Tensorflow 后端实施,硬件设施为显存16 GB 的NVIDIA Quadro RTX 5000 GPU,内存大小为128 GB。训练过程中使用Adam 优化器,学习率为1e-4,批量大小为每训练批一对。
3 结 果
为了验证方法的有效性,将提出的方法与经典的传统配准算法(包括基于ANTs[11]的Affine 和SyN[12])以及当下流行的基于深度学习的方法(包括3 层U-net[13]和体素变形[6])进行比较。这些方法在大脑数据集ADNI 中的一个示例上的可视化结果如图4 所示。以二维切片的形式展示结果,仅用于可视化目的。
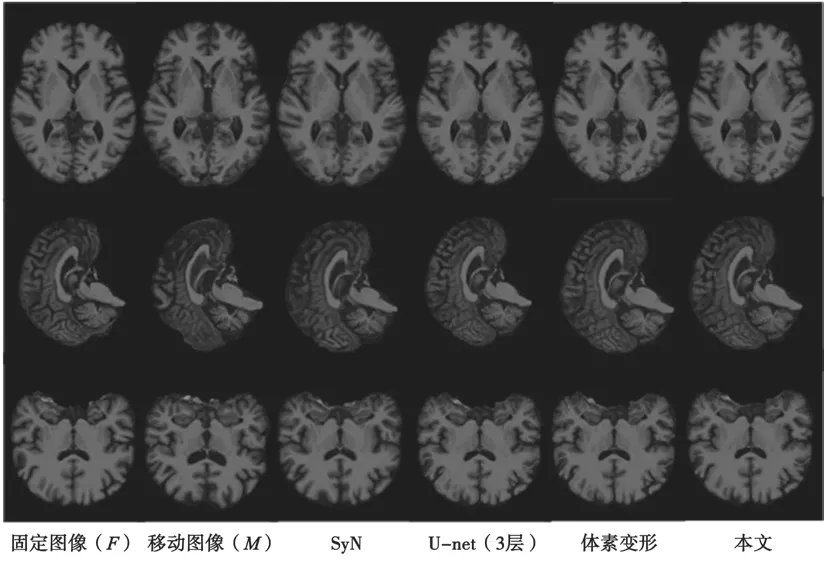
图4 各种方法的可视化结果
基于ANTs[11]的Affine、SyN[12]、3 层U-net[13]、体素变形[6]以及提出的架构的平均戴斯相似性系数(DSC)如表1 所示。可以看出,与前几种方法相比,提出的方法在精度方面达到了最先进的性能。
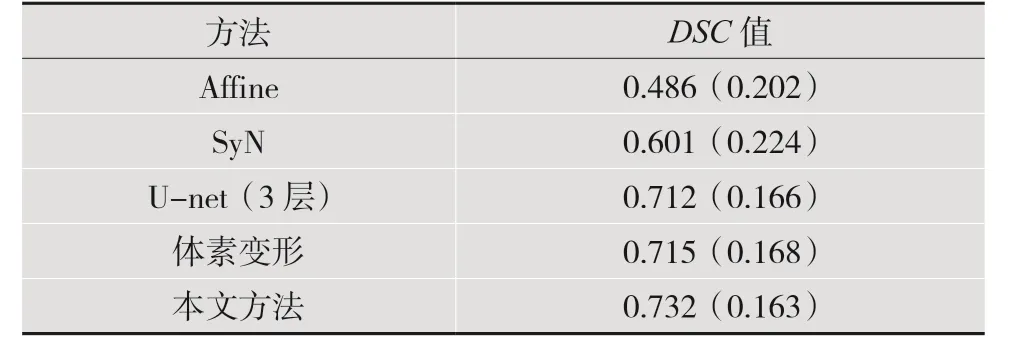
表1 平均戴斯相似性系数(DSC)
接下来进一步展示30 个解剖结构体积重叠的戴斯相似性系数。表2 列出了30 个解剖结构,并将所有解剖结构对应的平均戴斯相似性系数可视化为如图5 所示的直方图。由图5 可以看出,在30个解剖结构中,提出的方法有27 个解剖结构的戴斯相似性系数(DSC)表现出最佳性能。

表2 30 个解剖结构索引表
4 结 语
三维医学图像配准具有重要的研究意义。针对编解码结构的神经网络模型在配准中的不足,提出一种新的卷积神经网络MSD-Vnet 用于医学图像的端到端配准。与只支持小的三维图像块或者是二维切片的方法相比,该方法可以一次性预测整个位移向量场。该模型使用多尺度跳过连接来精确定位解剖结构的位置和边界,使用选择核注意力机制更好地学习医学图像的多尺度特性提高配准精度,同时使用深度监督对整个可变形配准网络进行监督来防止过拟合。利用公共数据集ADNI 对提出的方法进行评估,评估指标为平均戴斯相似性系数,与Affine、SyN、U-net(三层)以及体素变形比较,分别获得24.6%、13.1%、2%以及1.7%的精度提升。由于将图像配准到同一模板图像是大多数医学图像分析方法(如atlas 比对)的一个重要预处理部分,因此该模型的重点是将目标图像配准到一个固定的模板图像上。未来将致力于研究将目标图像配准到不同模板图像上。
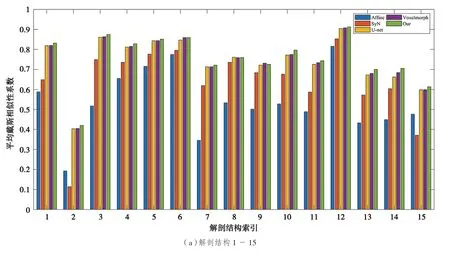
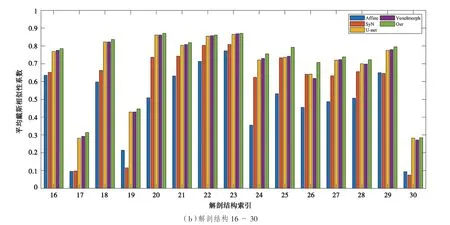
图5 5 种方法解剖结构的平均DSC
