一种基于条带的一致性散列数据放置算法
2021-04-07高艳珍孙凝晖
魏 征 窦 禹 高艳珍 马 捷 孙凝晖 邢 晶
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)2(中国科学院大学 北京 100190)
在大数据时代,数据因为其体现的价值而越来越多地受到重视.数据规模正呈爆发式地增长,根据互联网数据中心(International Data Corporation, IDC)的统计预测,预计到2022年市场规模将达1 891亿美元[1],到2025年全球数据总量将达175 ZB[2].面对持续增长的海量数据,分布式存储系统成为存储研究方向的热点之一.
分布式文件系统通常在数据中心中以存储集群的方式来实现[3].在数据中心中包含了计算存储、网络、电力等众多设备,各类设备故障都威胁着存储数据的可靠性.各类出错因素的积累,使得存储服务器的失效成为常态[4].分布式存储系统通过副本和纠删码机制提供数据可靠性存储技术,保证当某个节点失效时不会对存储的数据产生影响.其中纠删码能够达到甚至超过3副本的可靠性[5-6].纠删码在Google的GFS[7]、Microsoft的Azure[8]以及Facebook的存储系统[9]等商业系统中都有应用.纠删码与RAID类似,将数据分组组成条带(stripe).每个条带中有N块数据,数据经过编码矩阵编码产生N个数据块和M个校验块.N个数据块和M个校验块构成一个纠删码条带.纠删码条带中的数据块用于数据读取.纠删码编码产生的纠删码条带具备最大距离可分码(maximum distance separable, MDS)性质[10],即任意不多于M块数据丢失,都能恢复原始数据.
分布式文件系统从系统结构上可以分为有中心和无中心2种.有中心的分布式文件系统是在集群中选择1个节点,负责管理整体集群,记录每个数据块的放置位置.其他节点通过与中心节点通信,确定数据的存放位置.在谷歌文件系统(Google file system, GFS)[11]、Hadoop分布式文件系统(Hadoop distri-buted file system, HDFS)[12]、百度文件系统(Baidu file system, BFS)[13]等文件系统中,均采用这类系统结构.有中心的分布式文件系统实现简单,能够收集全局信息,比较均衡地放置数据,并且数据放置的位置灵活可变.但存在单点故障,当中心节点失效时,可能导致整个系统进入不可用的状态.同时每次获取数据存放位置时,均需要与中心节点进行交互,中心节点负载压力较大,不利于集群的扩展.面向EB(exabyte)级大规模分布式存储机群,元数据管理成本较大,位置信息等元数据查询效率影响了IO时延和吞吐量.有中心数据放置算法需要维护大量元数据信息,维护成本较高.文件信息、目录信息、块位置信息等元数据请求使得元数据服务器成为访问热点,不利于性能优化.
无中心的分布式文件系统是基于Hash算法实现的,即根据数据块的某个或某些特征值,通过Hash函数等机制映射出实际存放的存储节点,所以系统中不需要中心节点进行系统管理.在Ceph[14],Swift[15],Gluster[16]等存储系统中,均采用这类系统结构.无中心的分布式文件系统不存在中心节点,避免了单点故障.在一般情况下,Hash函数取值呈均衡分布,各节点间负载均衡.同时每次查询数据位置时,只要通过计算就能确定存储节点,不存在单节点查询的性能瓶颈,可扩展性好.因此,在集群规模较大、IO请求密集的情况下,无中心的分布式文件系统能够在保证可靠性的同时,表现出更加优秀的性能,正被越来越多的分布式文件系统所采用.
在纠删码的存储方式下,无中心的分布式文件系统在实现数据恢复的过程中,还面临2个方面的挑战:1)纠删码中将数据块和校验块组成条带,数据放置位置相对固定,需要保持放置规则,在节点恢复过程中易造成额外的数据块迁移;2)纠删码条带的恢复过程中涉及更多的并发IO操作,这些IO操作间相关度大,并行度低,恢复带宽不高.为了获得更高的性能和扩展性,本文采用了无中心的系统结构,针对基于纠删码的分布式文件系统恢复机制进行了研究,通过改进数据放置算法,减少恢复过程中变动的数据量,通过调度并发IO,提高恢复带宽.
数据放置算法是分布式文件系统的核心问题,数据放置的方法决定了其他功能的实现,也影响着系统的整体性能.首先,数据需要均衡放置.数据放置不均衡导致某个节点的负载过高而崩溃,从而导致整体系统的不可用.其次,要保证数据的可靠存储.针对纠删码而言就是要保证其MDS性质,即任意节点上同条带内的块不能超过M块.再次,数据放置算法要使系统具备良好的扩展性.在系统扩展和数据恢复过程中,数据放置的位置会发生变化,需要依据数据放置算法,选择新的位置存放数据.最后,数据放置算法应具有较高的查询性能.在读写数据等操作中,都会包含查询数据位置的操作,查询的效率会对系统的性能产生较大影响.
纠删码的引入对于数据放置的可靠性、均衡性影响不大,但给扩展性和查询性能带来了挑战.在纠删码的数据恢复过程中,条带内的每个块的内容并不相同,为了保证相同的读取策略,需要依次迁移数据块,产生了额外的数据迁移开销.同时,在选择数据放置位置时,还要考虑查询的性能,不能带来较高的查询开销.因此,本文提出了一种新的数据放置算法,既有较好的查询性能,又能减少节点变动时的数据迁移量.
分布式文件系统的数据恢复过程,是从存活节点上读取数据,然后写入重建节点.整个恢复过程包含大量的数据IO操作,IO操作涉及到块的读写数量是确定的,为数据恢复过程中进行精确地并发IO调度带来了可能.纠删码数据恢复过程中,每个块的恢复需要读取N个块,块间存在约束关系,需要等待数据读取IO的完成,再进行纠删码的恢复计算,才能执行写入丢失块的IO操作.同时,在数据恢复过程中,可能对条带内没有丢失的块进行迁移,产生额外的迁移IO,迁移IO与恢复IO可能读取同一个节点,影响IO的并行执行.所以,在纠删码中应该把一个条带内的块看做是一个整体,在条带内统一调度包含恢复IO和迁移IO的所有并行IO操作.而对于条带间的IO操作相互独立,可以采用与数据块调度类似的策略进行调度.因此,本文提出了基于条带的并发IO调度恢复策略,将条带内的恢复IO与迁移IO统一调度,提升数据恢复的速度.
本文的主要贡献有3个方面:
1) 提出了一种基于条带的一致性Hash数据放置算法(consistent Hash data placement algorithm based on stripe, SCHash).SCHash算法以条带为单位放置数据,减少了节点变动过程中的数据迁移量,从而在恢复过程中降低了变动数据的比例,加快了恢复带宽.同时,该算法还具有较好的均衡性和查询性能.
3) 基于纠删码文件系统(erasure coded file system, ECFS)[17-18]实现了基于条带的一致性Hash数据放置算法SCHash,并通过测试验证了SCHash放置算法针对数据迁移和恢复的优化目的.
1 相关工作
本节首先介绍了纠删码文件系统中所采用的数据放置策略,及其对于数据恢复的影响.然后介绍了数据恢复过程中IO调度策略的相关研究工作.
1.1 采用纠删码的数据放置算法
数据放置算法是分布式文件系统中的核心算法,对于读写性能和恢复性能都会产生影响.分布式文件系统中的每次读写操作,都需要查询数据的放置位置.在数据恢复时,需要依据数据放置算法,选择重建节点恢复数据,并对其他数据放置的位置进行调整.所以数据放置算法应具备较高的查询性能,还应减少数据恢复中变化的数据量.
1.1.1 APHash
APHash(Arash Partow Hash)[19]是一种类似顺序放置的数据放置算法,该算法是先将数据块映射为一个整数值,再根据当前节点的数目取模,得到实际存放的位置.APHash不同于其他Hash算法的地方在于,同一条带上连续顺序编号的数据块,可以映射到一段连续的Hash值.从而使得同一条带中的块,在存储节点上顺序排列,保证了纠删码的MDS性质.APHash算法实现简单,查询效率高,并且数据分布基本均匀.但文件一旦写入,每个数据块对应的存储位置也就唯一确定.当节点数据发生变化时,基本上所有的数据都要发生迁移.
1.1.2 一致性Hash算法
一致性Hash算法(consistent hashing)[20]将Hash空间分组映射到存储节点上,从而在节点变化时,减少了数据的迁移.一致性Hash算法首先构造了一个环形的Hash空间,例如0~(232-1)的一个范围.数据块经过Hash算法,映射到该Hash空间上的某个位置,同样,待存储的节点也映射到这样一个Hash空间上,从块映射的位置开始,顺时针选择最近的节点映射值,对应的节点就是数据存放的节点.同样,在增加节点时,也只需要迁移被分割区域内的块即可.在频繁地增减节点后,节点在Hash空间上的分布不一定均衡,最终就可能导致负载不均衡.因此,需要再增加数目固定的虚拟节点,替代物理节点映射到Hash空间上.虚拟节点可以看作是节点在Hash空间上的复制品,一个物理节点可以对应多个虚拟节点.当物理节点发生变化时,只需要更改虚拟节点到物理节点的映射关系即可.例如在文献[21]中,通过动态调整虚节点优化数据布局.一致性Hash算法有效地解决了节点数目变化时数据大量迁移的问题.但对于纠删码存储系统,并不能保证满足MDS性质,即同一个条带中的块可能被映射到同一物理节点上,或者映射的虚节点被指向同一物理节点.
1.1.3 CRUSH算法
CRUSH(controlled scalable decentralized place-ment of replicated data)算法[14]是分布式文件系统Ceph中采用的数据放置算法,是对一致性Hash算法的进一步扩展,能够支持更加复杂的集群结构.存储文件首先被划分为相同大小的对象(object),每个对象可以由文件索引节点号(inode)与块号(object number,ono)组成的对象号(object id,OID)唯一标示,即(inode,ono).然后对象号经过Hash取模映射到放置组(placement group, PG)中,PG相当于一致性Hash中的虚拟节点.PG再经过CRUSH算法,映射到存储的对象存储设备(object storage device, OSD)上.当节点数目变化时,只需要移动节点上存储的PG即可.CRUSH算法选择OSD的过程,是按照一定层次顺序选择存储设备,然后在同一层次中,根据负载、可靠性、故障情况选择最合适的设备.CRUSH算法能够根据集群特点,分层逐步选取存储设备,对于不同结构的存储集群都能获得较好的数据可靠性.
在纠删码环境中,同一层次选取设备的过程还需要考虑纠删码的MDS性质.假设需要选取6个存储节点存储1个条带中的6个块,依据一定的Hash算法,选取好6个存储节点后,会检查这6个存储节点是否有重复,是否满足纠删码MDS的约束条件.如果某个存储节点不满足条件,会将Key值增加条带长度,重新Hash选取节点,直到选出的存储节点间满足负载、故障和纠删码的MDS性质.CRUSH算法相对比较复杂,在每个层次选取存储设备的过程中,可能存在多次失败重试的情况,对于资源相对紧张的中小集群,发生冲突的可能性比较高,会造成重复尝试多次的问题.CRUSH算法本质上是随机选取一些可行的节点组,再在这些节点组中依次存储数据块.当节点失效后,存储节点的拓扑结构发生变化,同一块的Hash结果难免不发生改变.虽然CRUSH算法给出了4种数据Hash方式,但并不能保证一定不发生额外的数据迁移,并且迁移数据量最小的Straw方式查询效率比较低.
综上所述,目前在分布式文件系统中所采用的数据放置策略,多是基于3副本存储方式而设计的,并没有针对纠删码做太多的优化适配.因此并不能完全适应于纠删码文件系统中数据放置的需要,在数据恢复中仍会带来其他开销.
1.2 采用纠删码的I/O调度策略
数据恢复是某些块丢失后,通过仍然存在的其他块,恢复丢失块的过程.在纠删码环境下,恢复一个块需要读取N块数据,包含了大量的并发IO操作.这些IO操作就会在系统内随机执行,甚至可能导致恢复操作以串行的方式执行,降低系统的恢复效率.在(N,M)纠删码中,最多支持M个数据块的丢失.依据Facebook统计的集群失效情况[22],单块丢失占据了98.09%以上的比例,并且多块丢失主要是因为单块丢失没有及时恢复造成的.在调度过程中,应主要考虑对单块丢失的情况进行调度.在分布式文件系统中,一般会有负载均衡策略,恢复中的IO操作与用户读写IO操作相比较,涉及到的块是确定的,具有一定的规律性,同时也具有较强的数据约束性.数据恢复过程中的IO操作,可以通过更加具体的策略进行调度.本节中将首先介绍文件系统中的数据IO调度策略,再说明针对纠删码的恢复调度策略.
1.2.2 基于数据位置的调度
Shen等人在文献[28]中提出了最少跨机架传输(minimizing number of accessed racks)的方法.该方法依据数据块所存储的机架位置,在选取提供数据块时,选取的数据块尽量避免跨机架的数据迁移.假设每个机架上的节点连接同一个汇聚层交换机,同条带中的数据块会分布在不同机架的不同节点上,在选取同组数据块时,选取的数据块应尽量少地跨交换机传输,提高了传输速度.
1.2.3 基于网络带宽的调度
Li等人在文献[29]中提出了树型恢复方案(tree-structured regeneration scheme).该方法将每个存储节点假设为图中的顶点,节点间的网络带宽表示为节点间边的权重,那么存储系统中就可以用一个带权无向图,表示恢复时的网络情况.当恢复IO在存活节点中选取同组节点时,就可以依据边的权重,选取合适的网络路径.但在实际的恢复过程中,网络带宽不断变化,无法准确判断节点间的带宽情况.并且树型恢复过程中,恢复数据要经过一些节点的路由,会带来额外的传输开销.
2 基于条带的一致性Hash数据放置算法SCHash
分布式文件系统中的数据恢复过程,是将丢失数据重新放置的过程,数据放置算法决定了数据与存储节点之间的对应关系,因此数据放置算法是数据恢复过程中的关键问题之一.在数据恢复中,为了满足纠删码数据块间的约束关系,大部分情况下除了恢复丢失的数据块外,还需要额外移动一些数据块,造成不必要的开销.因此构建迁移数据量小的数据放置算法,是分布式文件系统中数据恢复的基础.
本文提出了一种基于条带的一致性Hash数据放置算法SCHash.纠删码中的数据是以条带为单位组织的,条带间的数据并不存在约束关系.所以在纠删码环境下,应以条带为单位进行数据放置.这样就能通过一致性Hash算法,确定每个条带的存储位置.每个条带要存储到多个节点上,这就要把待存储数据的节点组织成节点组,从而把数据块到节点的映射过程转化为从条带到节点组的映射过程.因此,SCHash算法以条带为单位放置数据,保证了节点间的约束关系,通过一致性Hash算法提高了数据放置算法的扩展性,减少了节点变动时的数据迁移量.
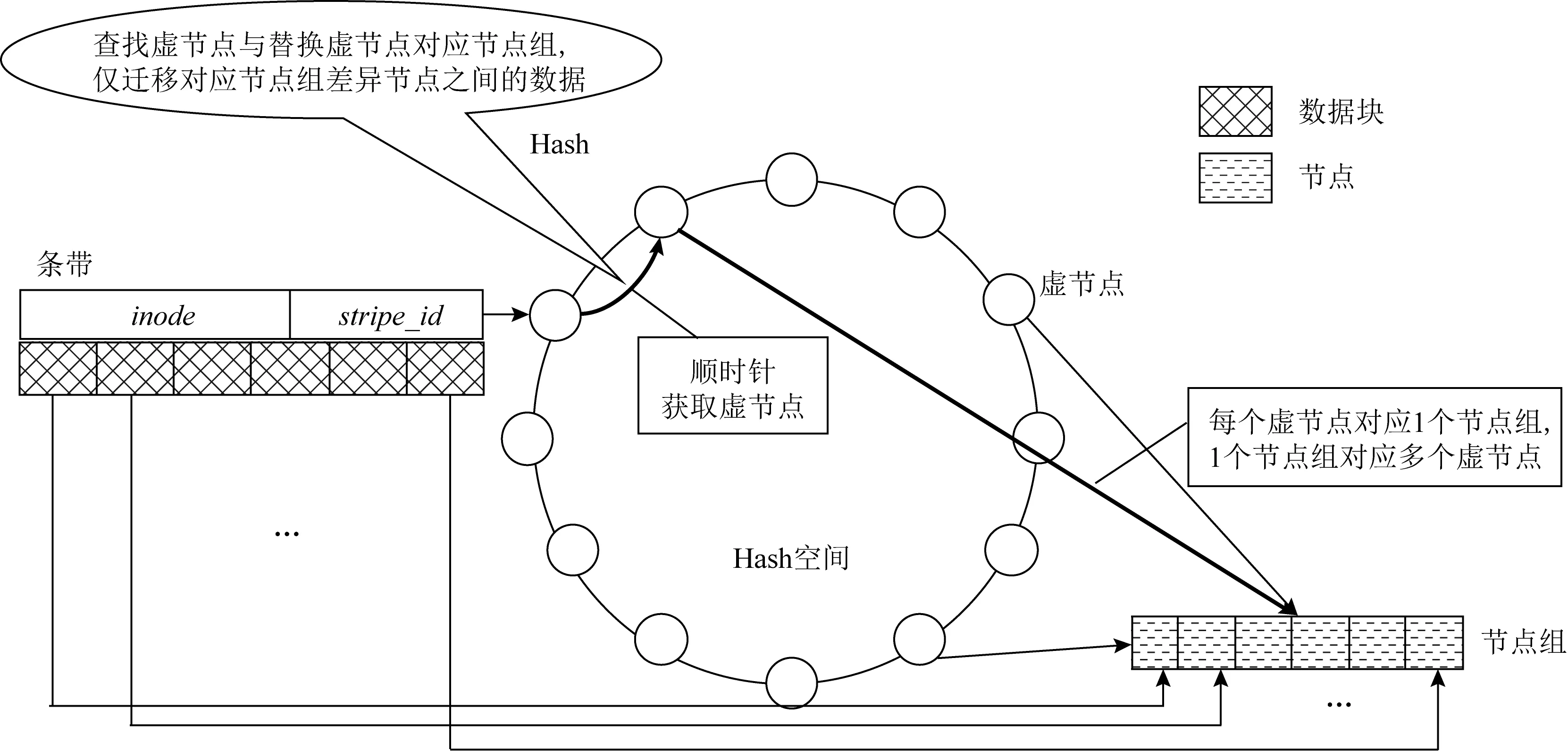
Fig. 1 SCHash algorithm图1 SCHash算法
SCHash算法的数据放置过程如图1所示.首先,依照一致性Hash算法的设计构造一个环形的Hash空间,生成一定数目的虚节点,这些虚节点均衡地分布到Hash空间上.例如图1中构造了一个Hash空间并产生12个虚节点(用白色点表示,在工程实现中,虚节点数目与实际节点组数量成倍数或数量级关系,用于保证数据的均衡分布和节点的负载均衡),虚节点均衡地分布在Hash空间上.每个虚节点对应一个节点组,每个节点组可以根据权重,分配不同数目的虚节点.通过inode,stripe_id(inode为文件的唯一标识号,stripe_id为当前数据的条带号)可以唯一确定每个文件中的每个条带.条带以inode,stripe_id为Key可以根据Hash函数映射到Hash空间上的某个值.最后,从条带映射的位置开始,在Hash空间上顺序查找最近的虚节点,该虚节点对应的节点组,就作为存储该条带的节点组.在条带与节点组之间,每个数据块依次存储在节点组中对应的节点上.
节点组的结构从根本上满足了纠删码的MDS性质,只需要在构建节点组时,每个节点组内满足约束条件,就能使任意条带内的数据块满足MDS性质,保证了系统的可靠性.数据条带到虚节点的映射是一个Hash的过程,可以认为数据均衡地分布在虚节点上.只需保证每个节点分配的虚节点数均衡,就能使系统均衡地存储数据.在系统拓扑确定的前提下,整个查询过程都是确定的计算过程,并且与系统中存储节点的数目没有关系,因此查询效率为O(1).
NG=(n0,n1,…,nN+M-1).
(1)
(2)
节点组(node group,NG)根据式(1)定义,依据采用的纠删码编码方案,由N+M个节点构成的N+M元组表示.节点组间的差异度(difference,Diff)由式(2)定义,表示节点组间对应位置上不同节点的数目.差异度越小,相同节点越多,节点组越相似,节点组间替换时迁移的数据量越小.在选取替换节点组时,就可以选取差异度最低的节点组.在理想情况下,总存在1个替换节点组,与原节点组的差异度为1.在数据从原节点组迁移到替换节点组时,只有对应位置上不同的节点需要迁移数据.因此,SCHash算法能够提供较好的可靠性、均衡性、扩展性,具备良好的查询效率.
2.1 构建节点组
SCHash算法,将数据条带映射到节点组进行存储.节点在节点组中的组织决定了数据存放的可靠性、均衡性和扩展性.节点组中的节点需满足约束条件,即相同的节点数目小于M个,才能保证系统存储数据的可靠性.为了达到数据均衡存储的目的,存在3个基本原则:1)在节点同构的环境下(同构表示节点配置相同,反之为异构),每个节点组对应的虚节点个数相同,构建的节点组应保证所有节点组中各节点的占比大体相同.2)在节点异构的环境下,需要调节节点组对应的虚节点数目,使数据按比例分布在各节点上.3)为了提升系统的扩展性,在增删节点时,新产生节点组或减少节点组后,应选择差异度较低的替换节点组,保证迁移的数据量在可以接受的范围之中.综合考虑这3个方面,本文提出了3种节点组的构建方式,供不同场景选择.
为了方便说明节点组的构建过程,在本节中假设存储系统中有S个同构的存储节点,采用(N,M)的纠删码编码方式,则每个条带中有K(K=N+M)个数据块.显然,存储节点的个数S与K满足3个关系:
1) 当S≥K时,则可以选取任意K个存储节点组成1个节点组.
2) 当K>S≥KM时,则每个存储节点先放置KS个数据块,再从S个存储节点中选取(KmodS)个存储节点,一同组成1个节点组.
3) 当KM>S时,则不可能满足纠删码MDS性质.
我们以S=4,K=3,N=2,M=1为例,分别阐述排列法、组合法和单点冗余法在S≥K情况下的组合情况,通常在存储系统的实际部署环境下,机群节点数量S远大于条带长度K.
2.1.1 排列法
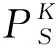
1,2,3 1,3,2 2,1,3 2,3,4 3,1,2 3,2,4 4,1,2 4,2,3
1,2,4 1,4,2 2,1,4 2,4,1 3,1,4 3,4,1 4,1,3 4,3,1
1,3,4 1,4,3 2,3,1 2,4,3 3,2,1 3,4,2 4,2,1 4,3,2
2.1.2 组合法

1,2,3 1,2,4 1,3,4 2,3,4
2.1.3 单点冗余法
单点冗余法是选取K个节点组成一个节点组NG,然后再选取1个节点,依次替换节点组NG中的每个节点,从而再构建K个节点组,总共构建(S-K)×K+1个节点组.重复上述过程直到所有的节点都组成了节点组.本例中,从4个节点中选取3个节点组成节点组(1,2,3),然后用剩余节点4依次替代节点组(1,2,3),组成新的节点组,与节点组(1,2,3)一起组成4个节点组,NGi=(n0,n1,n2),i=1,2,3,4,即:
1,2,3 4,2,3 1,4,3 1,2,4
单点冗余法同样选取了部分的节点组合方式,每个组合方式间的节点各不相同.在扩展性方面,同样由于只选取了部分节点组,不能保证每个节点组在单节点丢失时,都存在差异度为1的替换节点组.但采用了替换的策略,在单点丢失时能尽可能小地减少迁移.单点冗余法仅构建了(S-K)×K+1个节点组,节点组数目较少且线性增加,需要存储的元数据最少.
2.1.4 构建Hash空间
假设Hash空间大小为R(一般取值为232-1),节点组个数为NG_Num,虚节点个数为V_Num,虚节点V_Num与节点组NG_Num成倍数关系(V_Num≫NG_Num),每个的权重为NG_W(权重默认为1,根据存储空间设置,存储空间越大,值越大,若100 GB存储空间赋权重值为1,则200 GB节点为2.每个存储节点组按权重分配的虚节点数目NG_V满足关系:
(3)

1) 根据节点组编号对Hash空间R执行Hash取模映射,将节点组映射到Hash空间上的某个位置.
2) 顺时针选取最近的虚节点.
3) 如果该虚节点已经分配了节点组,则执行步骤4,否则执行步骤5.
4) 顺时针前进Step的长度,执行步骤2.
5) 如果查找到的虚节点没有分配节点组,则将该虚节点分配给节点组.
6) 如果已经分配足够的虚节点,则退出,否则顺时针前进Step的长度,重复执行步骤2~6,直到分配足够的虚节点后,退出.
2.2 节点变动
在节点发生变动时,待存储数据的节点组成的节点组也会发生变化,但条带到虚节点的映射关系保持不变,只需调节某些虚节点与节点组的对应关系,将虚节点从原节点组指向替换节点组即可.如图2所示,当存储机群添加存储节点时,待添加节点与原有节点组织成为待添加节点组,待添加节点组在系统中查找差异度最小的节点组,然后调整与虚节点的对应关系,完成数据的迁移.
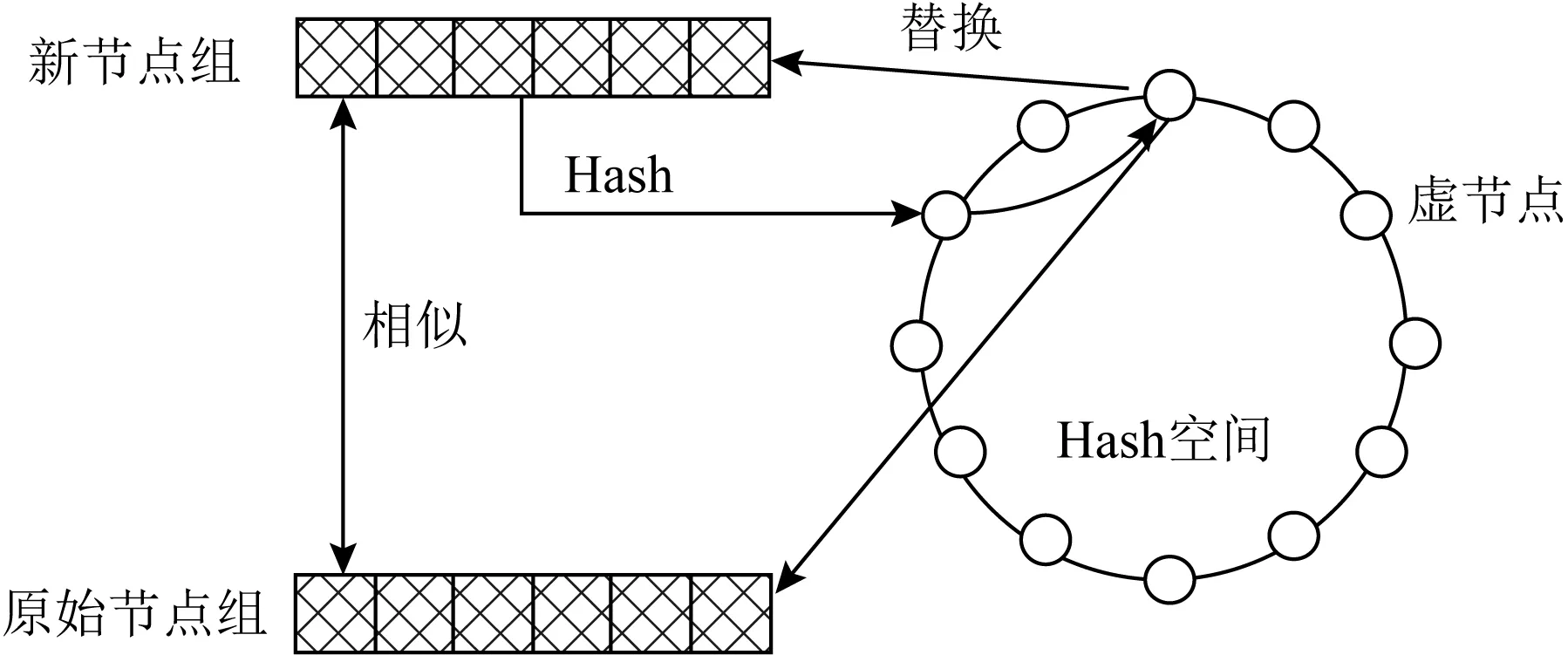
Fig. 2 The process of adding node group图2 节点组的添加过程
具体实施步骤为:
1) 将待添加存储节点与现存节点构建待添加节点组.
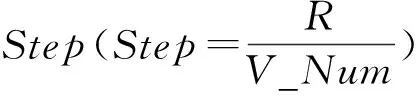
3) 将被替换的节点组中与添加节点组差异的节点进行数据的迁移.
如图3所示,当系统中存在节点损坏或丢失时,该节点所在的所有节点组为待删节点组,查找差异度最小的替换节点组,调整与虚节点的对应关系,完成数据的迁移.只有发生变动的虚节点上的数据会发生迁移,从而防止了整个Hash空间上的数据迁移.任意2个节点组中的对应位置上的节点会有不同,数据在节点组间迁移时,也可能会有比较大的数据迁移.因此在选择替换节点时,应选择与原节点组最相似的替换节点组,此时迁移的数据量最小.
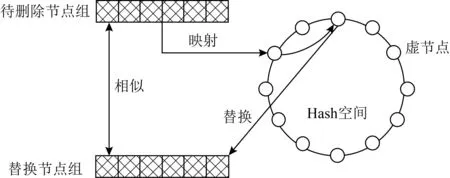
Fig. 3 The process of replacing node group图3 节点组的替换过程
2.3 节点分区
在实际部署的分布式存储运行环境中,存储节点的数目往往比较大,直接构建节点组的方法并不现实.需要先将存储节点分区,再在区域内构建节点组.这样一方面可以减少构建节点组的数目,从而减轻元数据存储的压力;另一方面也可以将恢复分区,在发生故障后,只有组内的节点进行数据恢复操作,其他分区的服务不受影响.
3 基于条带的并发IO调度恢复策略
数据恢复是在数据丢失后,分布式文件系统通过未丢失数据主动恢复,从而得到丢失数据的过程.数据恢复的效率,对于分布式文件系统至关重要.在纠删码环境下,条带内块间存在较强的约束关系,数据恢复涉及到条带中多个块的并发读写.因此,在纠删码环境下,数据恢复与调度的单位是条带与节点组,应从条带和节点组的角度考虑数据恢复的过程.纠删码数据恢复就是选取重建节点组,进行数据恢复IO和数据迁移IO的过程.
3.1 重建节点组
SCHash算法以条带为单位放置数据,提供了一种重建节点组的选择策略.从条带与节点组的角度看,任何纠删码的数据恢复过程中,为保证纠删码的MDS性质,都是将数据从原节点组恢复至重建节点组.假设存储系统中有S个同构的存储节点,采用(N,M)的纠删码编码方式,则每个条带中有K(K=N+M)个数据块,需要K个不同节点存储.那么:
4) 对于每一个失效节点组,拥有S-K个差异度为1的重建节点组.即仅将丢失节点替换为其他节点,不存在数据迁移IO.
3.2 条带外节点重建的并发I/O调度
在数据恢复中,重建节点往往是条带外的其他节点.如图4所示,可以将存储集群中的节点分为同组节点、重建节点和其他节点.其中只有同组节点上存储条带数据.那么恢复一个条带时,存在2种IO:1)从同组节点到重建节点的数据恢复IO(图4中实线);2)从同组节点到同组节点和其他节点的数据迁移IO(图4中虚线).
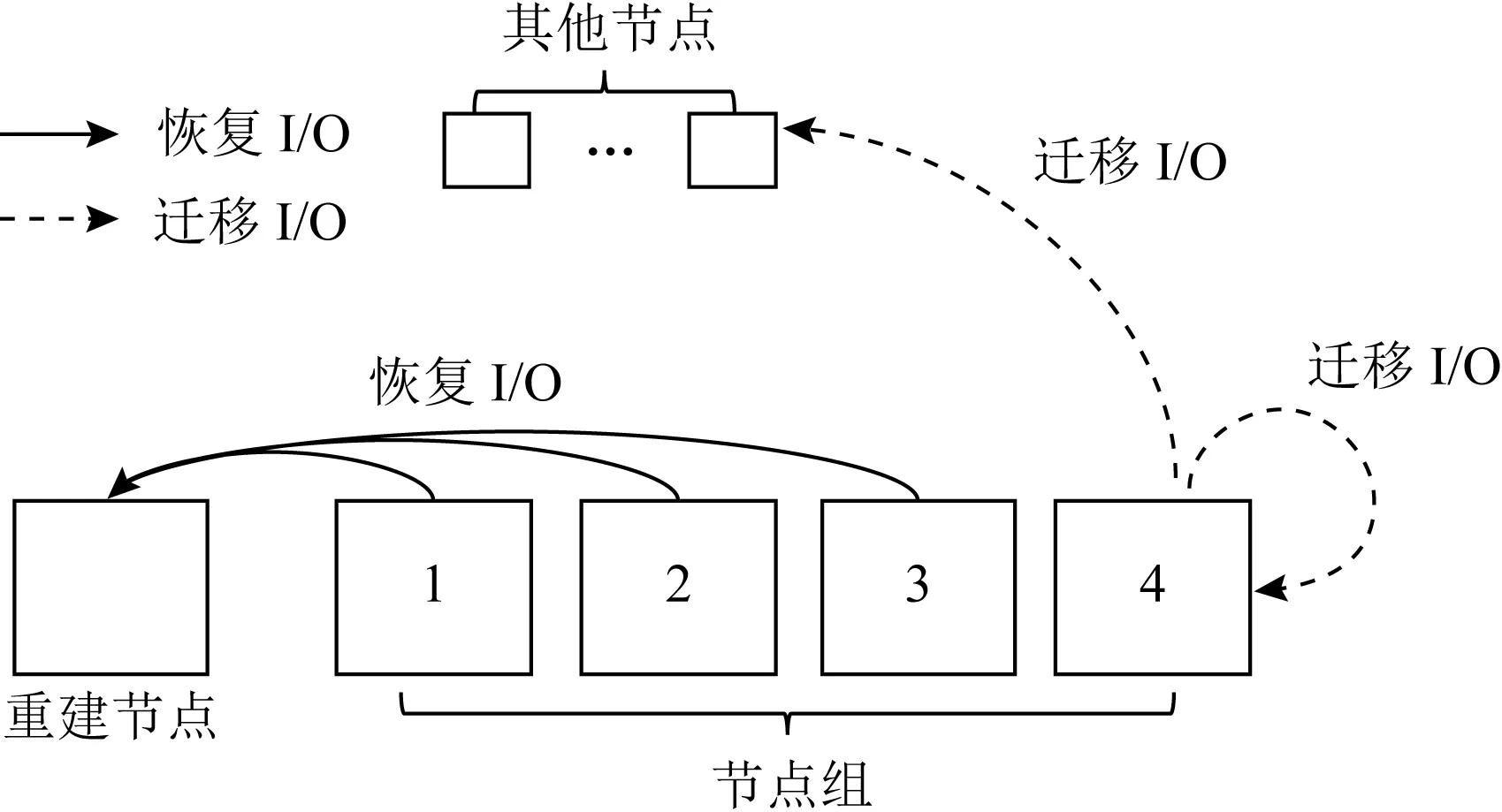
Fig. 4 The concurrent IO during data reconstruction out of stripe图4 条带外节点重建时的并发IO情况
3.3 条带内节点重建的并发I/O调度
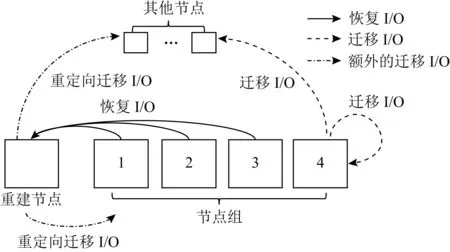
Fig. 5 The concurrent IO during data reconstruction in stripe图5 条带内节点重建时的并发IO情况
在数据恢复时,如果可选的重建节点组比较少,就可能会出现重建节点是条带内同组节点的情况.如图5所示,同样可以将存储集群中的节点分为同组节点、重建节点和其他节点.其中重建节点、同组节点上都存储条带数据.因为每个节点上至多存储1个数据块,所以重建节点上必然存在1个迁移IO.那么恢复1个条带时,与条带外节点重建时相比,还额外存在从重建节点到同组节点和其他节点的数据迁移IO(图5中点画线).
通过分析,3.2节中采用的策略依然有效,同时可以再采取3个策略,使得重建节点上的恢复IO与迁移IO并发进行:1)选取重建节点作为一个恢复IO的读节点,该策略可以减少1次IO.2)重建节点与同组节点同时读取.在恢复IO读操作时,重建节点处于空闲状态,因此可以进行恢复IO的读操作.3)重建节点与同组节点、其他节点同时写入.由于每个节点上至多存储一个数据块.每个迁移IO的写操作必然不在同一个节点上进行,因此可以并发写入.
4 ECFS数据恢复模块的设计与实现
为了评测基于条带的一致性Hash数据放置算法SCHash和基于条带的并发IO调度恢复策略的实际效果,本文在基于纠删码的分布式文件系统(ECFS)[17-18]中改进了数据放置算法,设计并实现了数据恢复模块.
如图6所示,ECFS包括文件系统客户端(client)、元数据服务器(MDS)、存储服务器(OSD).为了实现数据恢复的功能,在系统中增加了管理服务器(manager)和脚本接口(shell).所有节点之间通过TCPIP通信库AMP连接.
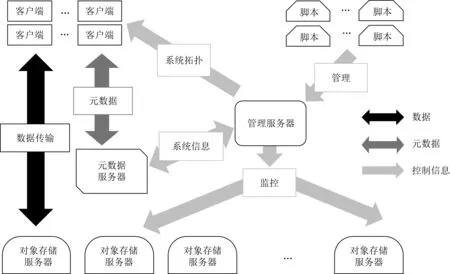
Fig. 6 ECFS architecture图6 ECFS系统架构图
客户端是基于用户态文件系统(file system in userspace, FUSE)[30]构建的.通过数据放置算法,客户端可以直接确定数据的存放位置,然后直接与存储服务器进行交互,完成数据读写操作.元数据服务器主要提供文件系统命名空间的管理,为用户提供对文件的按名访问服务.有关元数据的IO操作占据了超过整个文件系统IO操作的50%.为了使得元数据服务器能够提供更好的IO吞吐率,在分布式文件系统中,元数据服务逐渐从文件系统中独立出来,由专门的元数据服务器完成[31].存储服务器是实际存储数据的节点,负责数据块的存取工作.客户端通过数据放置算法,将数据块发送到存储服务器,存储服务器将数据块和校验块以文件的方式存储在本地磁盘上.在数据更新时,数据块会直接更新存储的文件.
管理服务器中的信息均从系统中统计而来,当管理服务器丢失时,可以重新从系统中统计相关信息,重建管理服务器.因此,管理服务器并不会成为系统中的单点.为了增强系统的可靠性,可以同时部署多台管理服务器,再通过选主协议保证多活管理服务器的可靠性.该方式与单台管理服务器提供服务的方式并无区别,本节中通过单台管理服务器说明系统设计.
5 测评与分析
本节基于分布式文件系统ECFS评测了基于条带的一致性Hash数据放置算法SCHash的均衡性、扩展性和查询性能,同时评测了基于条带的并发IO调度恢复策略的调度效果.
5.1 测试环境
本节的相关测试是在一个拥有10个节点的机群上完成的,该机群中的所有节点采用星形网络连接到同一个核心交换机上.为了减少操作系统IO的影响,操作系统与ECFS的数据分别存储在不同的硬盘上.每个节点的软硬件配置如表1所示:
Table 1 The Configuration of Machine表1 测试节点配置表
ECFS的部署方案为:选取一个物理节点同时作为元数据服务器和管理服务器,其他物理节点同时作为客户端和存储服务器,从而避免元数据操作与数据操作之间相互影响.所有评测中对纠删码的编码方式并无特殊要求,所以在测试中如无特殊说明,均采用RS(4,2)编码方式,每个数据块大小为1 MB.为了消除测试过程中操作系统缓存的影响,每次测试前需清空系统缓存.
5.2 数据放置算法的测试
本节主要测试SCHash算法的查询性能、扩展性和均衡性.假定每个写入文件的大小为1 GB,inode号随机产生,条带号和块号通过计算产生.逐渐向ECFS中写入数据,测试数据放置算法的各项性能.
5.2.1 数据放置算法的查询效率
APHash是一种类似顺序放置的数据放置算法,同一条带上连续顺序编号的数据块存放到连续的节点,且APHash实现简单,查询效率高效.SCHash以条带为单位管理数据的放置关系,保证了条带的连续存放,与APHash算法类似,同时SCHash针对APHash在数据节点发生变化时需要迁移的问题进行了优化.

Fig. 7 Read and write performance of SCHash and APHash图7 不同数据放置算法的读写性能
5.2.2 节点变动时的迁移数据比
通过计算节点变动时的迁移数据比来反应节点变动时的迁移数据量.在节点变动后,存储位置发生变化的数据块数目,即为实际的迁移数据量.数据放置算法中数据存放的位置与纠删码编码、数据传输等步骤无关.因此本测试采用模拟的方式,分别计算不同节点变化的模式下,节点变动前后数据块的存储位置,并统计存储位置发生变化的数目,然后计算迁移数据的占比情况.
随着系统存储数据量的增长,在节点增加时迁移的数据量也会增长,这就可能对迁移数据比造成波动.如图8所示,通过从6个节点增加到7个节点和12个节点,反映了不同节点增加情况下的迁移数据比与数据总量的关系.随着数据总量的增加,迁移数据的比例基本不变,说明SCHash算法与APHash算法的迁移数据比均与总数据量的大小无关,SCHash算法迁移数据的数目要明显少于APHash算法.
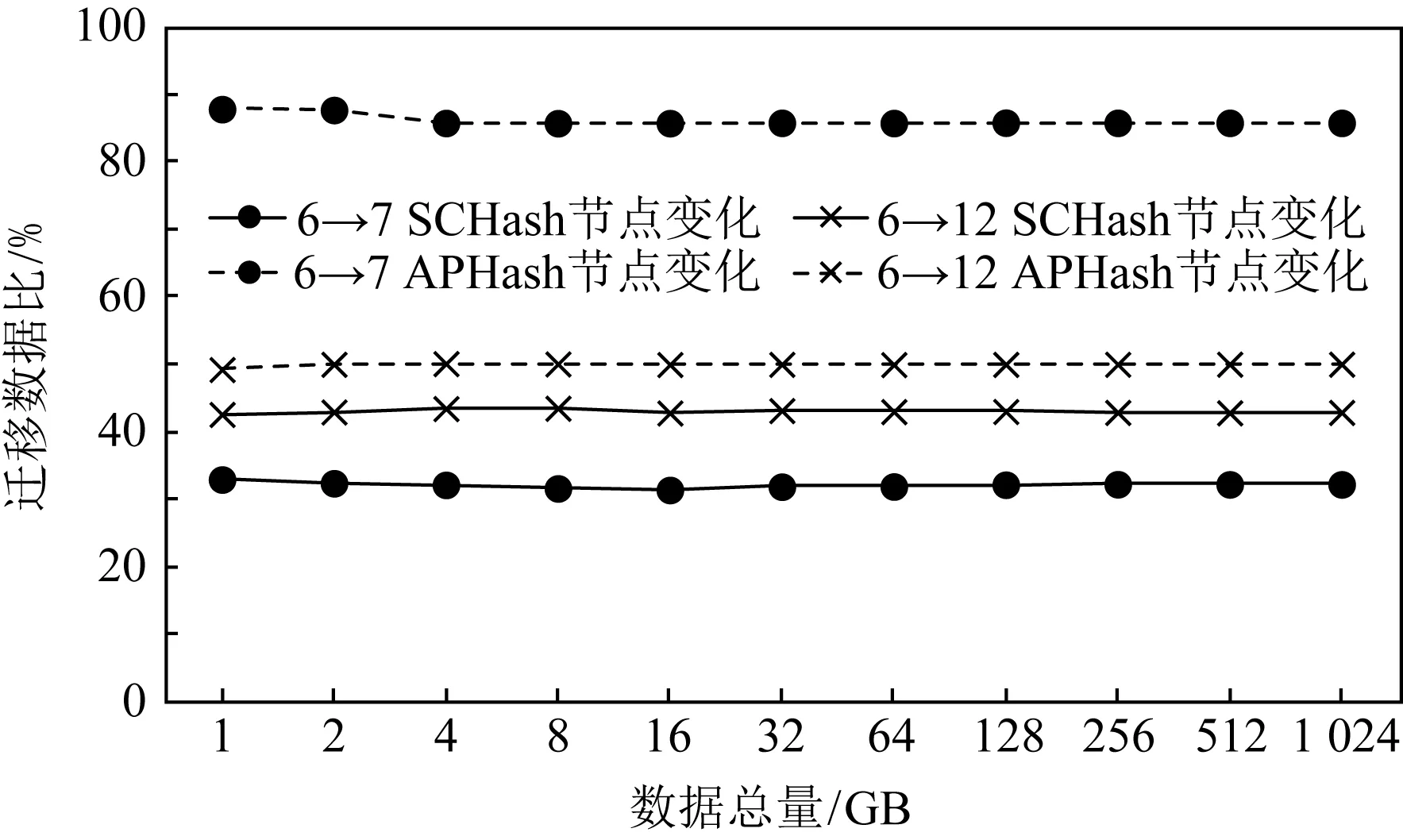
Fig. 8 Relationship between migration data ratio and total data when increasing the number of nodes图8 增加节点时迁移数据比与数据总量的关系
5.2.3 数据放置算法的均衡性
通过计算每个存储服务器中,存储数据的相对标准差来反映数据放置的均衡性.与迁移数据比的测试相同,本测试采用模拟的方式,分别统计8,12,16个节点的集群,在数据放置的过程中,每个存储服务器编号出现的次数,即可反映出实际存储的数据块数.
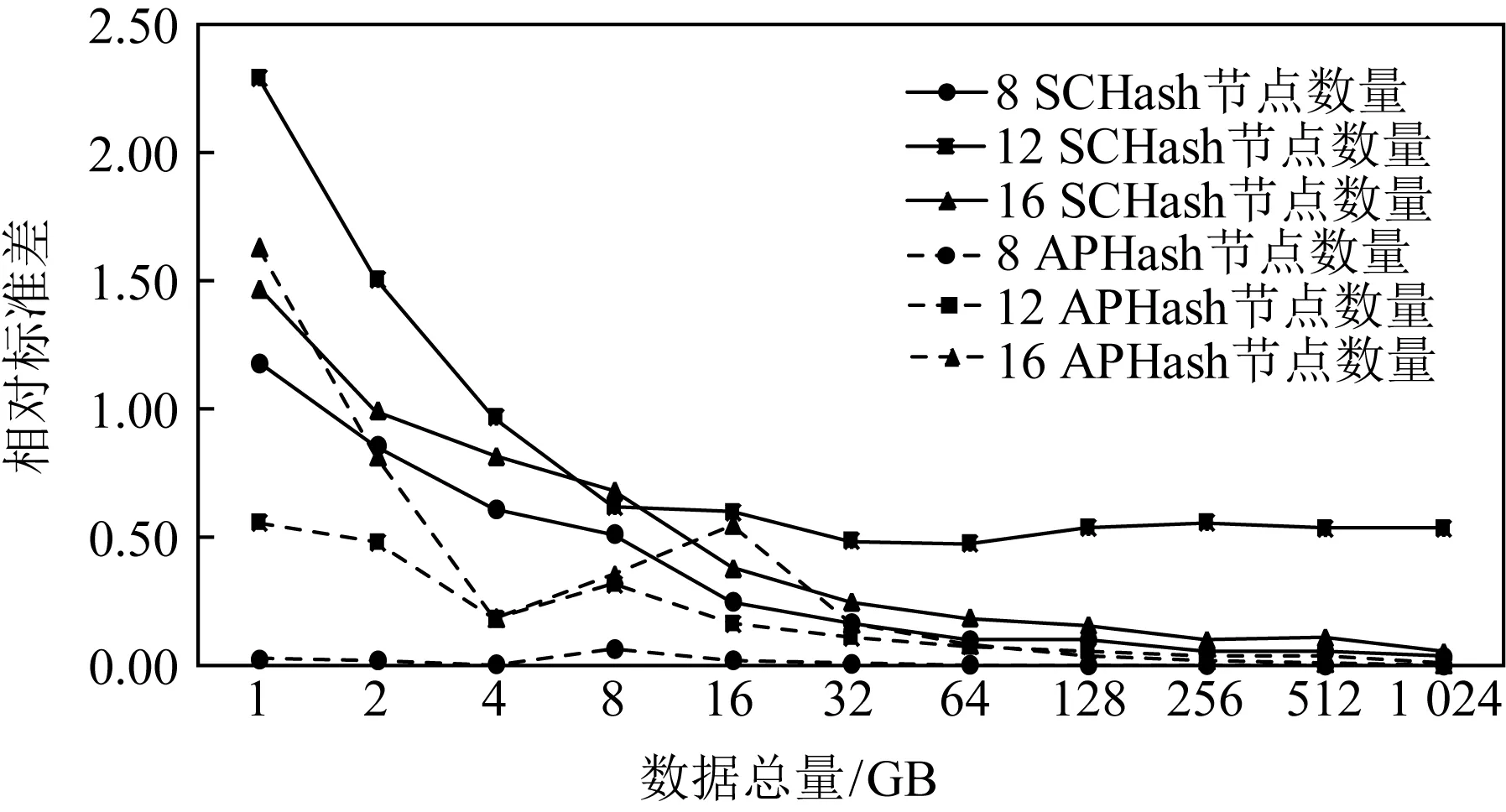
Fig. 9 Relationship between standard deviation and total data图9 数据放置的相对标准差与数据总量的关系
如图9所示,当数据量较少时,Hash算法的Hash值只分布于部分Hash空间上,SCHash算法与APHash算法的相对标准差都比较大,数据存储不太均衡.但随着存储数据量的增大,相对均方差快速下降.当总数据量达到32 GB时,相对均方差降到0.5%以下且波动不大,说明各存储服务器间存储数据量的差异小于0.5%.一般来说,随着数据量的增加,随机放置算法放置的数据越均衡,相关测试基本反映出该趋势.比较2种数据放置算法的均衡性,SCHash算法相对较差,但随着数据量的增加差异逐渐减小,可以忽略不计.
5.3 系统恢复性能测试
数据恢复的性能受到网络、磁盘、调度等多种因素的影响,应在分布式文件系统中测试实际的恢复带宽.本节测试中采用7个节点作为存储服务器,通过将某个节点的网卡关闭,模拟节点丢失的情况.统计从数据恢复任务开始到全部数据恢复结束中各部分操作的时间,并记录期间恢复IO和迁移IO的数量,计算出恢复带宽,从而反映系统的恢复性能.
如图10所示,测试了采用不同的节点组构建方式时,系统恢复带宽与总数据量的关系.其中,排列法构建的系统平均恢复带宽为308.06 MBps,迁移数据比为21.65%;组合法构建的系统平均恢复带宽为65.06 MBps,迁移数据比为59.59%;单点冗余法构建的系统平均恢复带宽为61.57 MBps,迁移数据比为39.37%.排列法构建的系统,在节点丢失时,迁移的数据最少,同时能够在多个节点上并发恢复数据,因此拥有较高的恢复性能.组合法与单点冗余法的恢复性能都相对较低.组合法迁移的数据量远大于排列法,因此恢复性能较差.单点冗余法虽然迁移的数据量比较少,但主要在一个节点上重建数据,IO的并发度比较低,所以恢复性能也不高.通过对不同节点组构建方式的分析可知,恢复过程中的迁移数据量和IO的并发度,对于系统的恢复性能都有较大的影响.

Fig. 10 Influence of node group construction on recovery performance图10 节点组构建方法对恢复性能的影响
5.4 并发I/O调度的测试
本节测试与系统恢复性能的测试方法相同,同样模拟节点故障,通过测试系统的恢复带宽,反应实际的恢复性能.在测试数据恢复之前,首先在恢复过程中,只执行恢复IO操作,不执行迁移IO操作,此时的恢复带宽可以认为是基准恢复带宽.然后再在恢复中加入迁移IO,分别测试有无调度时的恢复带宽.通过对比有无调度时的恢复带宽,计算恢复带宽与基准恢复带宽的比值,反映出并发IO调度的实际效果.在测试过程中,同时记录每秒执行的IO数目.通过对比有无调度时单位之间的IO数目,反映出恢复过程中IO的并发度.
在组合法构建的系统中,当单个节点丢失时,不能保证每个丢失的节点组都存在差异度为1的重建节点组,这时选取的重建节点就可能在条带以外,并产生同组节点间和同组节点到其他节点的迁移IO.因此本节测试采用组合法构建节点组,测试在8个节点中丢失1个节点时,条带外节点重建的数据恢复中,并发IO调度的效果.
如图11所示,测试了在32~256 GB存储容量下有无调度时的恢复带宽.首先测试了基准恢复带宽,在图11中以实线方形表示,平均值为73.54 MBps.然后分别测试了有无调度时的恢复带宽.图11中虚线圆形表示没有调度时的恢复带宽,平均值为27.73 MBps.实线圆形表示有调度时的恢复带宽,平均值为66.11 MBps.通过测试可见,通过对并发IO的调度,恢复带宽提升了138.44%,达到了基准恢复带宽的89.93%(图11中实线三角表示).

Fig. 11 The relationship between concurrent IO scheduling and data volume during data reconstruction out of stripe图11 条带外节点重建时并发IO调度与数据总量的关系
如图12所示,测试了128 GB存储容量下,在数据恢复过程中,每秒执行的IO数目.深色区域表示有调度时每秒的IO数目.浅色表示无调度时每秒的IO数目.通过调度,减少了迁移IO与恢复IO在同组节点上的竞争,每秒执行的IO数目普遍多于无调度的情况,并且执行数据恢复的时间更短.说明通过IO调度,提高了恢复IO与迁移IO的并发度,单位时间可以执行更多的IO操作.在有调度的情况下,随着IO操作的逐步执行,IO操作的执行越来越呈现随机性,最终导致调度失效.因此在调度过程中增加了同步操作,保证恢复IO与迁移IO能够依照调度规则执行.所以从图12中可见,在有调度的情况下,每执行一定数目的IO后会产生一次波动,执行的IO数目降为0,此时正在执行同步操作.
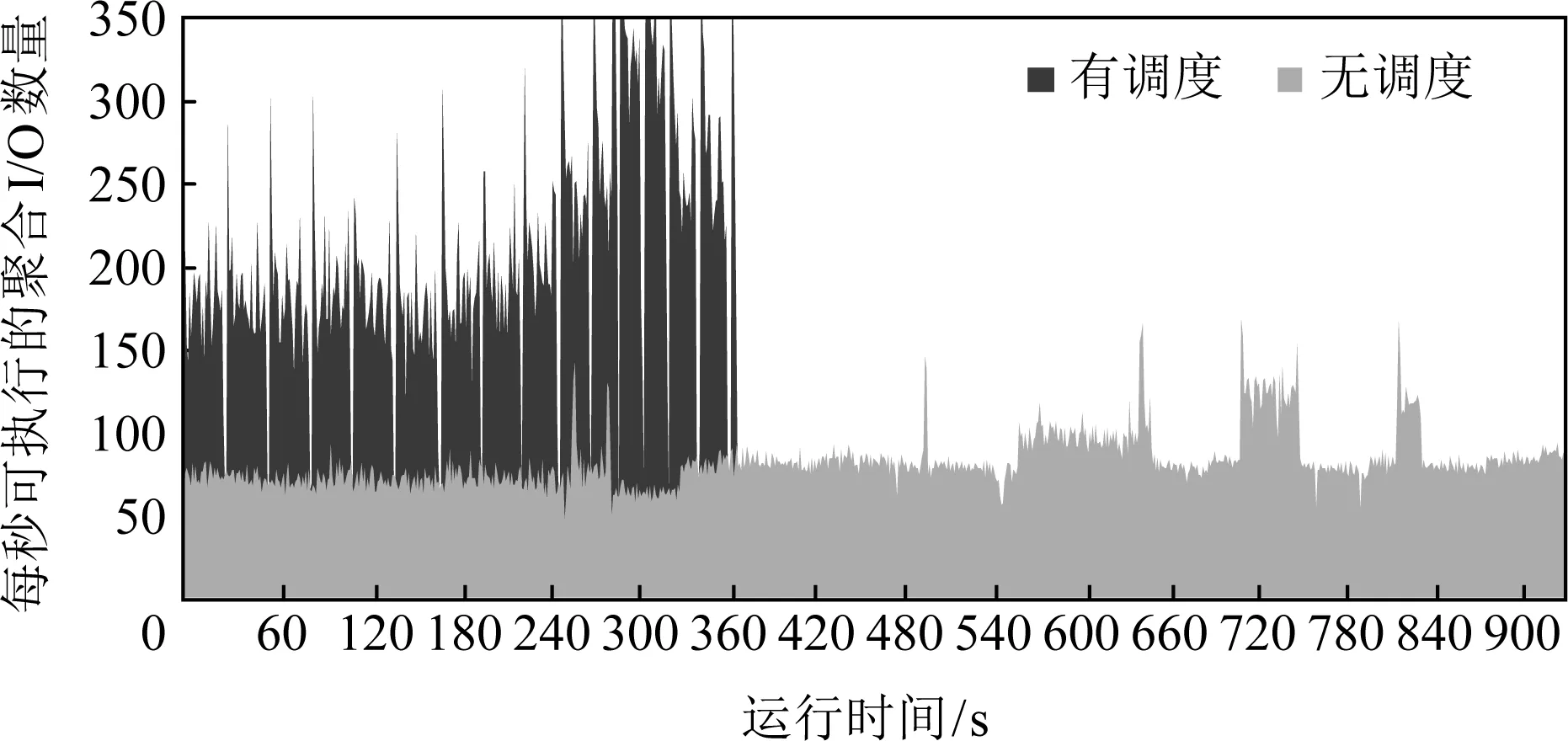
Fig. 12 The IOPS during data reconstruction out of stripe图12 条带外节点重建时每秒的IO总量
在单点冗余法构建的系统中,当单个节点丢失时,会在冗余的节点上恢复丢失的数据,冗余的节点同时也是条带内的节点,这时就会产生从重建节点到同组节点的迁移IO.因此本节测试采用单点冗余法构建节点组,测试在7个节点中丢失1个节点时,条带内节点重建的数据恢复中并发IO调度的效果.
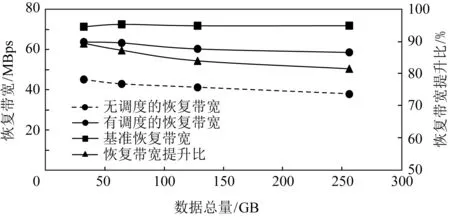
Fig. 13 The relationship between concurrent IO scheduling and data volume during data reconstruction in stripe图13 条带内节点重建时并发IO调度与数据总量的关系
如图13所示,测试了在32~256 GB存储容量下有无调度时的恢复带宽.首先测试了基准恢复带宽,在图13中以实线方形表示,平均值为71.96 MBps.然后分别测试了有无调度时的恢复带宽.图13中虚线表示没有调度时的恢复带宽,平均值为41.56 MBps;实线圆形表示有调度时的恢复带宽,平均值为61.57 MBps.通过测试可见,通过对并发IO的调度,恢复带宽提升了48.16%,达到了基准恢复带宽的85.57%(图13中实线三角表示).
如图14所示,测试了128 GB存储容量下,在数据恢复过程中,每秒执行的IO数目.深色区域表示有调度时每秒的IO数目.浅色表示无调度时每秒的IO数目.通过调度,重建节点上的迁移IO与恢复IO可以同步执行,每秒执行的IO数目普遍多于无调度的情况.并且执行数据恢复的时间更短.说明通过IO调度,提高了恢复IO与迁移IO的并发度,单位时间可以执行更多的IO操作.与条带外节点重建的情况相同,在有调度的情况下,同样存在同步操作产生的波动.

Fig. 14 The IOPS during data reconstruction in stripe图14 条带内节点重建时的IO总量
条带内节点重建与条带外节点重建相比较,在恢复相同数据块时,条带内节点重建涉及到的节点比较少,IO操作之间更容易发生冲突.因此,在条带内节点重建时,IO调度所带来的恢复带宽的提升,小于条带外节点重建时恢复带宽的提升.
6 总 结
本文主要研究了纠删码分布式文件系统的恢复机制.纠删码作为一种数据存储方式,既具有较高的空间利用效率,又能保证存储数据的可靠性.但纠删码的引入给数据恢复带来了新的挑战.一方面,纠删码中将数据块组成条带,数据块间放置位置的约束增强,在节点恢复中易造成额外的数据块迁移;另一方面,纠删码的恢复过程中涉及更多的并发IO操作,这些IO操作间相关度大、并行度低,恢复带宽不高.本文从条带的角度出发,分析研究了纠删码在数据放置和恢复调度方面的特点,将文件系统中的处理单位从数据块与节点,变化为条带与节点组,从而解决了纠删码所引入的问题.
