基于元路径嵌入的移动应用需求偏好分析方法
2021-04-07丁治明
宋 蕊 李 童 董 鑫 丁治明
(北京工业大学信息学部 北京 100124)
随着信息技术和移动应用平台的快速发展,用户在使用移动应用的同时产生了海量的用户数据.这些用户数据蕴含用户与移动应用的交互信息,表达了用户需求偏好.因此,用户数据是分析用户需求偏好的重要数据源[1].
为了理解用户对移动应用的需求,已经有很多学者基于用户数据来挖掘需求偏好,进而为用户实现个性化的移动应用推荐.典型的推荐方法通常使用基于协同过滤(collaborative filtering, CF)和基于内容(content-based, CB)的技术[2].然而,传统推荐技术的相关工作集中分析用户对产品的评分[3],而用户评分只是用户表达其需求偏好的一个维度,未能有效利用多维度的特征信息(如用户评论、用户使用记录等).此外,还有工作基于用户的历史数据分析产品之间的相似性来满足用户偏好[4],但这样的思路不易发现用户和移动应用之间的关联,无法准确全面地刻画用户需求偏好.
本文认为移动应用的类别、功能描述信息以及用户评论等都是有价值的数据源.尤其是用户评论数据,它包含了大量的隐式信息,如用户对移动应用的态度、情感等[5].上述不同类型的多维信息可以形成异构的信息网络[6].对多维信息网络的有效表征能准确地刻画用户对移动应用的需求偏好.图嵌入技术已被证明是挖掘数据相互联系的有效方法[7].根据现有研究,元路径(meta-path)可以捕获异构信息网络中的语义结构[8].因此,在多维数据异构信息网络中,合理设计元路径能有效地表达用户需求偏好的语义.
本文提出了一种基于元路径嵌入的移动应用需求偏好分析方法,进而为用户推荐个性化的移动应用来评估方法的有效性.具体地,我们首先分析移动应用的文本信息中的语义主题,深入挖掘用户需求偏好的分析维度.其次,本文基于移动应用需求分析领域的概念和关系构建概念模型,来表征用户偏好的多维度信息(包括用户、移动应用、应用类别、功能描述、用户评论信息).然后,本文根据概念模型设计了一组具有特殊语义的元路径,来精准地刻画用户需求偏好的语义.最后,本文利用元路径嵌入技术为用户行为画像,为用户推荐满足需求偏好的移动应用.图1展示了本文的方法框架,具体贡献分为4个部分:
1) 基于语义相似性分析移动应用文本信息(功能描述、用户评论)的语义,从非结构化的文本中提取语义主题词,丰富用户需求偏好分析的特征.
2) 针对移动应用多维信息设计了一组包含特定语义的元路径,有效关联不同类型的信息,实现对用户需求偏好准确全面的表征.
3) 基于元路径嵌入技术分析用户对移动应用的需求偏好.通过采用元路径的引导,将用户需求信息嵌入到模型中.利用个性化的移动应用推荐效果探究用户对移动应用的需求偏好.
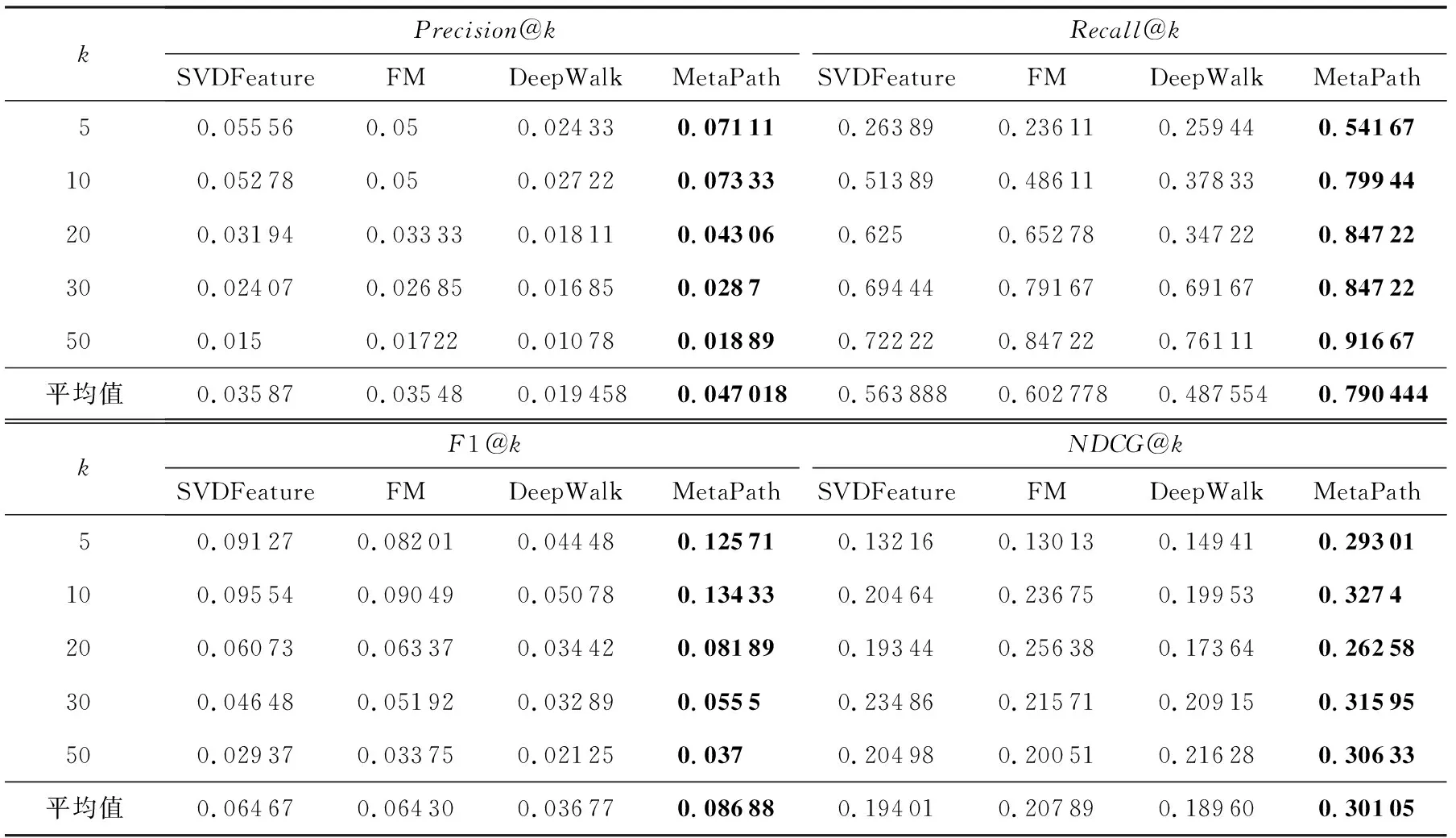
4) 在苹果应用商店的真实数据集上评估,数据集包括1 507个移动应用和153 501条用户评论.结果表明本文提出的方法在4个指标上均优于基线模型,其中平均F1值提升0.02,平均归一化折损累计增益(normalized discounted cumulative gain,NDCG)提升0.1.
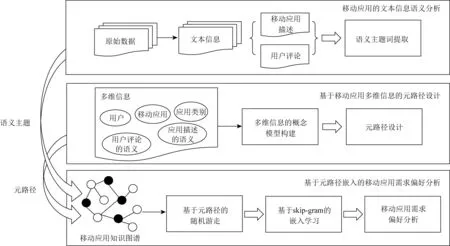
Fig. 1 The user preference analysis of mobile applications based on meta-path embedding图1 基于元路径嵌入的移动应用需求偏好分析方法
1 相关工作
本节介绍与研究内容相关的现有工作,包括用户评论需求挖掘、移动应用推荐和图嵌入技术3部分.
1) 用户评论需求挖掘.随着用户需求的不断变化,移动应用的数量和种类越来越多.各类应用平台都允许用户以评分和评论的形式对其所使用的软件应用进行评价.用户对于应用软件的评论中蕴含丰富的用户需求偏好信息[5].因此,用户评论信息是移动应用需求偏好分析任务的重要数据源.
目前已有很多研究工作致力于从用户评论中分析用户需求偏好.一部分研究者发现用户评论的内容可以分为不同的类别.Pagano等人[1]研究了苹果应用商店的超过100万条用户评论,研究发现,用户评论通常包含多个主题,例如用户体验、错误报告和功能需求.Guzman等人[9]对Twitter平台上有关移动应用的推文进行描述性统计,使用机器学习技术自动识别和收集需求信息.随后文献[10]采用机器学习和主题建模技术,进一步分析移动应用的推文,并完成自动分类、分组和排序.
另一部分研究工作在用户评论分类的基础上提取用户需求偏好信息,便于进一步应用其他分析任务.Iacob等人[11]针对移动应用的在线评论研究了功能需求的自动检索系统,该系统分为评论检索、需求信息挖掘、需求信息概述以及数据可视化4个部分.Guzman等人[12]提出了一种挖掘用户评论中需求偏好信息的方法.该方法根据用户评论中的词语出现频率来提取特征,然后通过情感分析来确定用户需求偏好.Zhang等人[13]提出一个显式因子模型(explicit factor model)来实现推荐任务,他们分析用户评论中的情感,发现了用户评论中存在情绪差异.在文献[14]中,作者从用户评论中提取用户需求偏好,进而完成个性化推荐任务.
以上的工作都说明用户评论中蕴含丰富的用户需求偏好信息,影响他人对移动应用的选择.本文将用户评论信息应用于移动应用的需求分析任务,便于为用户推荐满足需求偏好的移动应用.
2) 移动应用推荐.目前许多研究人员已经对移动应用推荐任务进行了广泛的研究.个性化移动应用推荐是为了对用户需求偏好进行建模,形成一种可解释的、高效的推荐方法.传统的推荐技术有基于协同过滤(CF)和基于内容(CB)的方法.现有的CF方法可以分为3种类型:基于用户的方法、基于项目的方法和基于模型的方法.Amazon提出了一种基于项目的协同过滤算法,目的是寻找相似的商品[4].矩阵分解(matrix factorization, MF)是一种基于模型的协同过滤推荐方法[15].Kim等人[16]提出了一种个性化的应用推荐方法,他们探究了用户与其使用的移动应用的语义关系.Xu等人[17]提出了基于应用-许可的二部图模型来计算对移动应用的评分.Cheng等人[18]将短期上下文、共安装模式和随机选择作为用户需求偏好的影响因素,基于隐马尔可夫模型实现移动应用推荐.
尽管有各种模型可以应用于移动应用推荐,但以上的工作考虑的因素仍然不够全面,例如用户评论.为此,有研究人员采用图来清晰地表达各种知识之间的关联.Zhang等人[19]划分了用户评论的类型,并结合评论中的情感因素形成本体概念,为用户推荐合适的产品.文献[20]通过将用户-产品的权重矩阵转换为关联图来分析用户画像,并将其用于推荐系统.
① https://stanfordnlp.github.io/CoreNLP/
本文侧重融合移动应用的多维信息,形成含用户需求偏好语义的表示方法,以获得更好的推荐性能.
3) 图嵌入技术.嵌入学习是指通过特定的方法学习对象在另一个度量空间中的向量表示,如LINE[21],DeepWalk[22],Node2vec[23]等.LINE解决了将大型信息网络嵌入低维向量空间的问题.DeepWalk利用网络中节点的随机游走路径来模拟文本生成过程,然后基于自然语言模型实现节点向量化.Node2vec是对DeepWalk的改进,通过优化节点转移概率来改进随机游走策略.DeepWalk和Node2vec技术对图结构进行转化,具体是通过在网络中随机游走得到节点路径,然后应用skip-gram模型[24]实现节点嵌入.其中skip-gram模型是一种用于自然语言处理的神经网络模型.这些嵌入工作将节点路径视为句子,将每个节点视为一个单词,然后使用skip-gram模型计算节点的嵌入向量.这些嵌入学习技术可以学习节点的上下文关系,便于计算节点之间的相似度.本文将嵌入学习技术应用于移动应用需求偏好分析领域,可以挖掘用户和移动应用间的潜在联系.
由于嵌入学习技术在数据挖掘方面具有巨大潜力,许多研究者已经将嵌入技术应用到了推荐领域.例如文献[25-27]都采用了图嵌入技术实现兴趣点推荐.Shi等人[28]通过在异质网络中的元路径嵌入技术,实现电影推荐.淘宝、阿里的电商平台也采用图嵌入技术进行商品推荐[29-30].
本文研究的移动应用多维信息类型不同,可以构成含不同类型节点的图网络——异构信息网络.已有研究表明,异构信息网络中的许多数据挖掘任务都得益于元路径[31].元路径可以看作是异构信息网络中的结构.相比于DeepWalk等没有引用元路径的方法,元路径引导的随机游走,可以捕获不同类型节点之间的语义和结构相关性,促进异构节点的转换,具有推荐可解释性.Dong等人[32]构建了作者发表论文的异构信息网络,并采用元路径嵌入技术对学术领域的作者和会议进行分类.Zhao等人[28]设计了元路径捕获用户观看电影的语义,完成了电影推荐任务.但是他们的工作关注的特征信息较少,且适用于移动应用领域的多维信息.因此,本文基于移动应用的多维信息,设计了不同的元路径以捕获用户需求偏好,并基于对需求偏好分析的理解来实现个性化推荐.
2 移动应用的文本信息语义分析
移动应用的文本信息蕴含用户与移动应用之间的交互情况,如应用功能描述、用户评论等.这些交互信息影响用户对移动应用的需求偏好.例如,用户会选择含有特定功能的移动应用来下载,也会根据用户评论的内容来挑选更心仪的软件.因此,本文认为有必要从移动应用的文本信息中提取语义主题,这样能够多维度地分析用户对移动应用的需求偏好.
在本节中,我们主要介绍移动应用文本信息的语义分析,文本信息包括移动应用的功能描述以及用户评论2部分.本文语义分析的思路是通过词向量模型计算语义相似性,并提取文本语义主题词.因此,语义分析包括语义词向量模型训练和词向量模型应用2个阶段.在训练阶段,本文首先对文本信息进行自然语言处理形成语料库,然后基于Word2vec[33]技术训练词向量模型.在应用阶段,基于词向量模型自动提取本文信息的语义主题.图2为语义分析的整体框架,下文将详细描述每个部分.
2.1 词向量模型训练阶段
本文分别处理移动应用的描述文本和用户评论文本.首先基于自然语言处理技术对原始数据预处理,包括去停用词、词性标注、词形还原,以保证分析得到的语义主题词具有实际意义.然后利用Word2vec模型分析语义,最终得到2个词向量模型,分别用于功能描述和用户评论.
1) 去停用词.本文根据常用的停用词列表,删除本文信息中的停用词,如“the” “I”“is”“%”“#”.这些停用词不影响文本信息的语义,删除它们可以减少噪音.而只保留其他的信息词,如“account(账户)”或“monitor(监控)”会更有意义,因为这些词能提高后续模型的学习效果.
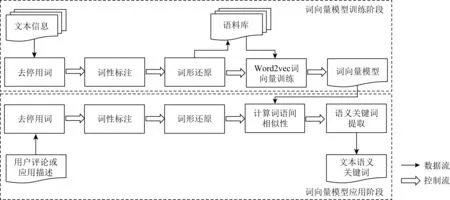
Fig. 2 The semantic analysis framework for text information of mobile applications图2 移动应用文本信息的语义分析框架
2) 词性标注.本文的目的是选择用户评论和应用描述的语义主题,副词和代词不能很好地代表文本的意义,而名词、形容词或者动词则能更好地表达文本的特征.因此,为了确保选择的关键词具有代表性并涵盖大部分单词,本文选择名词、动词和形容词来筛选语料.在自然语言处理工具①中,“NN”代表名词,如“cost(成本)”“time(时间)”和“payment(支付)”等;“JJ”代表形容词,如“high(高的)”“special(特殊的)”“local(本地的)”等;“VB”代表动词,如“spend(花费)”“drive(驱动)”“assess(评估)”等.此外,这些词语也包括不同的形态变化.
3) 词形还原.词形还原是将一个词的不同形式还原为它们的基本词根,作为一个单词进行分析的过程.这一步识别了单词的不同形式,解决了单词冗余的问题.在分析过程中,出现在不同文本信息中的不同单词,只要被识别为相同词根,就按照同一个单词进行训练.具体来说,本文将单词复数形式(ess)、过去式(ed)、现在时(ing)、副词(ly)等多形式转换为基本形式.例如“fixing”“fixed”以及“fixes”都会还原成原型“fix(修复)”.词形还原有助于模型统一语义相同但语言形式不同的关键词,从而保证关键词的质量.
4) 基于Word2vec训练模型.通过上述1)~3)过程,本文分别构建应用描述的语料库以及用户评论的语料库,然后采用Word2vec模型提取语义主题词.相比于传统的TF-IDF模型根据单词出现频率计算关键词,Word2vec能够进一步分析文本的语义信息.它的原理是通过单词的上下文预测中心词,或者通过中心词预测上下文.利用条件概率建模和神经网络模型将词语嵌入到高维空间中,形成单词的向量化表示.单词转化为数值型的数据有利于后续计算.本文对已形成的语料库进行词向量训练,最终得到2个模型.
2.2 词向量模型应用阶段
我们的目的是提取每一个应用描述或者用户评论文本的语义关键词.在这个步骤,我们首先对文本数据进行去停用词、词性标注、词形还原的预处理,然后载入训练好的模型,计算词语间相似性,进而提取语义主题词.
1) 计算词语间相似性.我们根据功能描述或者用户评论文本中的每一个单词,从对应的模型中获取该单词的向量表示.通过Word2vec计算的词向量能够在语义空间中得到数值和方向上的表示,即:2个词向量在空间中越接近,说明2个单词的语义越相似.基于这个原理,本文利用向量数量积的方式计算2个词语间的相似性:
similar(u,w)=u·w,
(1)
其中u,w代表2个单词的向量.
2) 语义关键词提取.对于每一个待分析的文本,我们计算文本中每个单词与其他单词的相似性.然后我们将结果按照相似性数值从高到低排序,选取前3个相似性高的单词作为该文本的语义主题词.例如,一个移动应用的功能描述为“Through our Alliance Media app, access the latest videos, podcasts, and photos from The Alliance, as well as blog messages from Andy Albright, President & CEO of National Agents Alliance.”,它的中文含义是:“通过我们的联盟媒体应用软件,可以访问联盟最新的视频、播客和照片,以及联盟总裁兼首席执行官Andy Albright的博客信息”.这段文本经过我们的语义分析处理后,会提取到“Alliance(联盟)”“President(总裁)”以及“video(视频)”,这3个词表达了该移动应用的关注对象和内容,能够代表语义主题.
① 本文使用单引号‘’表示概念.使用斜体表示概念间的关系.
3 基于移动应用多维信息的元路径设计
本节详细介绍基于移动应用多维信息的概念模型构建以及元路径的设计方式.概念模型能够关联融合移动应用的多维信息,为元路径的设计提供知识基础.元路径用于捕捉用户需求偏好,有助于为用户推荐满足需求偏好的移动应用.
3.1 概念模型构建
移动应用的多维信息(例如应用类别、功能描述、评论)都影响着用户的下载和使用意愿.这些信息形式不一,类型不同.为了同时考虑移动应用的多维信息,我们认为有必要建立一个概念模型来关联不同类型的数据.
概念模型的作用是整合多个概念和关系,有助于精确地观察数据之间的联系,和发现更有意义的路径或结构.我们构建的概念模型为后续的用户需求偏好分析提供理论基础.此外,只要明确概念以及关系的定义,就可以扩展概念模型以进一步丰富信息,这体现了我们方法的泛化能力.
本文使用概念建模技术[34]有效地建立移动应用多维信息概念模型.概念建模技术能够表达异构实体之间的语义关系,挖掘数据中的特定概念,并处理概念之间的关系.我们将多维信息集成到概念模型中,能够丰富用户需求偏好的分析维度.为此,针对移动应用的需求偏好分析任务,我们研究多维信息间的关联,构建了一个概念模型来统一动态的用户需求偏好.图3展示了我们设计的概念模型.

Fig. 3 The conceptual model of mobile applications’ multidimensional information图3 移动应用的多维信息概念模型
下文将详细说明设计细节.
1) 概念定义.本文分析了现有的移动应用需求偏好分析工作[35-37]中的数据,总结了常用的多维信息,包括用户、移动应用、应用类别、功能描述、用户评论、评分信息.我们将这些多维信息总结为3个核心概念:‘用户’①‘移动应用’‘评价’.具体来说,从用户对移动应用的需求偏好分析任务本身的角度来看,‘用户’和‘移动应用’的概念必不可少.从影响用户需求偏好分析效果的角度来看,用户与移动应用之间的交互信息——评价,会影响用户需求偏好,因此需要定义‘评价’概念.这3个概念存在于许多数据集中,具有广泛的应用价值.
此外,根据3个核心概念,本文衍生了其他相关概念.具体地,‘用户’具有‘姓名’概念(研究人员可以根据需求考虑用户的性别、年龄等其他概念);‘移动应用’具有‘名称’‘类别’‘功能描述’,以及根据功能描述提取的语义‘主题’等概念.‘评价’包括用户的‘评分’‘评论’以及提取到的评论语义‘主题’.
2) 关系设计.这些不同的概念依靠不同的关联关系连接.在核心概念中,用户与移动应用间是使用关系,用户会发表对移动应用的评价,然后移动应用拥有了评价信息.对于用户概念来说,用户拥有姓名;对于移动应用概念来说,它拥有名称,属于某个类别,拥有描述信息,其中描述信息包含我们提取得到的语义主题;对于评价概念来说,它包括评分和用户评论,同理,评论信息包含了我们提取到的语义主题.
最后我们得到了如图3所示的概念模型,以便于挖掘概念间的语义关系和用户需求偏好信息.
3.2 元路径设计
概念模型包含了领域中经常出现和可解释的路径,路径具有特定的语义.通过定义和分析路径能有效地描述用户需求偏好.因此,本文基于概念模型,将用户的行为信息提取到元路径中,从而设计了不同的元路径.目的是抽象地表达用户和移动应用之间的语义结构,来分析用户对移动应用的需求偏好.下面首先给出元路径的定义:
定义1.元路径.元路径m是一条包含关系的路径,这些关系定义在不同的概念之间.元路径是定义在一个图网络G(V,E)中的结构S(A,R),其中V表示节点集,E表示边关系集,A∈V,R∈E,m可以表示为A1→A2→…→An(简写为A1A2…An),其中“→”用R连接[38].例如,图4给出了用户使用移动应用的简单示例,其中“小赵—微信—小钱”就是一条元路径,含义是小赵和小钱都使用微信,说明小赵和小钱具有一定的相似行为.
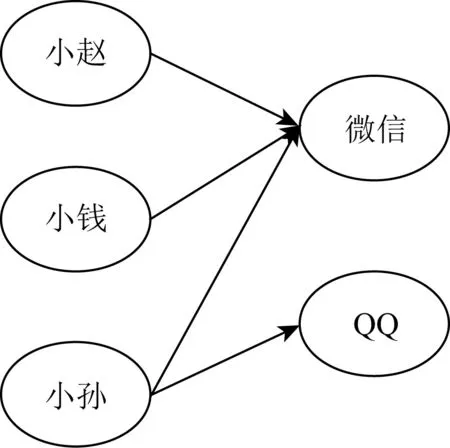
Fig. 4 The example of graph data for users using mobile applications图4 用户使用移动应用的图数据示例
图5展示了本文设计的4条有意义的元路径(M1,M2,M3,M4).从基础的需求任务角度出发,只涉及用户和移动应用2个概念,我们设计了基础路径M1,它表示的含义是2个用户都使用了同一个移动应用.这条元路径能够发现使用相同应用的用户需求偏好相似性.

Fig. 5 The meta-path designed in this paper图5 本文设计的元路径
从探究影响用户需求偏好效果的角度来看,我们分别根据应用类别、应用描述、用户评论3个概念设计了3条元路径(M2,M3,M4):

Fig. 6 The example of requirements analysis model图6 需求分析模型示例
考虑到应用类别的影响,我们设计了元路径M2,它表示的是2个用户使用了不同的移动应用,这2个不同的应用属于同一个类别.这解释了使用相同类别应用的用户需求偏好相似性.例如,小赵使用微信,小孙使用QQ,微信和QQ都属于社交类别的应用,说明小赵和小孙在应用类别选取上有相似性.
考虑到应用描述的影响,为了方便对比不同应用描述的相似程度,我们使用提取到的描述语义主题代表描述文本.因此我们设计了元路径M3,用来表示2个用户使用了含有相似主题的不同移动应用.这解释了使用相似功能移动应用的用户需求偏好相似性.
考虑到用户评论的影响,同理使用提取到的评论语义主题代表评论文本.我们设计了元路径M4,用来表示2个用户对同一个应用发表了相似的评论.这解释了2个用户对同一个应用的需求偏好相似性.
4 基于元路径嵌入的移动应用需求分析模型
基于概念模型,移动应用的多维信息有效地关联在一起,真实的数据能被转化为一个图网络.嵌入技术能将图网络中的数据节点计算为低维向量表示[39],便于在需求分析任务中计算.元路径是图网络中具有特殊意义的结构,便于表征用户需求偏好.因此,本文提出了基于元路径嵌入的移动应用需求偏好分析模型.
在本节中,我们详细介绍模型的细节,包括3部分,图6给出了模型示例.
1) 基于元路径的随机游走.目的是挖掘用户的历史需求偏好.利用改进的元路径引导的随机游走策略,将移动应用的图数据转化为一系列有意义的节点序列.输入是用户数据和元路径,输出是节点序列.
2) 基于skip-gram的嵌入学习.目的是学习节点序列的语义,将节点转化为向量表示,便于后续计算.采用skip-gram模型,输入为一系列节点序列,输出为每个节点的向量表示,这些向量能够概括元路径中的多维信息.
3) 基于嵌入向量的移动应用推荐.目的是验证模型是否能有效分析用户的需求偏好.本文基于向量设计打分公式,根据每个用户需求偏好提供个性化的移动应用推荐列表.输入是节点嵌入向量,输出是用户的移动应用推荐列表.
4.1 基于元路径的随机游走
随机游走技术能模拟一个节点在图网络中可能的路径.由一个节点开始的多次随机游走,则能模拟出该节点在图网络中的邻域.2个节点在图网络中的领域越相似,说明2个节点越相似.节点的邻域被表示为一系列有意义的节点序列,这些序列能作为后续嵌入模型的输入得到向量化的表示.通过对节点邻域的学习,我们能很容易地发现图中相似的节点.
根据上述原理,本文基于元路径改进随机游走策略,模拟出每个节点的具有用户需求偏好语义的邻域.具体来说,元路径限制了每一次游走的节点类型.以元路径M1(U-A-U)为例,若用户节点U为起始节点,下一个必须游走到移动应用节点A,接着必须是用户节点U,依次类推,直至达到设置好的路径长度L结束.最终得到U-A-U-A-U-A…的序列,长度为L.
本文规范化基于元路径随机游走的节点转移概率,给定一个图网络G(V,E)和元路径m,转移概率公式为
(2)
其中,φ(·)计算节点的类型,φvi-1(vi)表示vi-1之后的节点vi的类型,Nφvi-1(vi)是类型为φvi-1(vi)的节点数量.如果vi∉V, 转移概率为 0.
对于含有语义主题词的元路径(M3,M4),本文做出了进一步改进.为了挖掘相似的节点信息,我们希望在随机游走出的路径中,语义主题词节点具有相似性.因此,本文在随机游走过程中限制主题词节点的相似性.如果当前的主题词节点与上一个主题词节点的相似性满足设定的阈值,则保留当前主题词节点并继续随机游走,否则将当前节点更换为其他的主题词节点,再次判断阈值.其中,语义主题词相似性依据词向量模型和余弦公式计算.算法1给出了本文基于元路径的随机游走过程.
算法1.基于元路径的随机游走算法.
输入:图网络G(V,E)、元路径m、随机游走路径长度L、每个节点随机游走路径条数n、主题词相似性阈值s;
输出:记录节点序列的文件path.txt.
① for eachvinVdo
② fori←0 tondo
③path=[v];*路径初始节点为v*
④ forj←0 toLdo
⑤ 按照元路径的节点转移概率,随机游走到nv节点;
⑥ if (φ(nv)==“主题词”且
similar(nv′,nv) ⑦path.append(nv); ⑧ end if ⑨ end for ⑩ end for 通过元路径引导的随机游走,我们能得到每个节点的邻域序列.该部分的目标是将节点转化为向量,为后续计算做铺垫. 具体来说,给定一个图网络G(V,E),嵌入的任务是将节点计算为维数为d的潜在向量X∈R|V|×d(也称为嵌入向量).在本文中,我们选择skip-gram模型来学习节点的嵌入向量.该模型已在现有工作中得到有效性验证[22-23].依据文献[40],skip-gram在上下文窗口为w的条件下,通过最大化节点v的上下文节点“Context(v)”出现的概率来学习节点的嵌入向量: (3) 其中,Context(v)属于节点v的邻域,由元路径引导的随机游走序列得到.P(v′|v;θ)通过softmax函数归一化.为了加速训练,本文参考文献[40],采用负采样的方式: (4) 本文设计了4条不同的元路径,分别是基线元路径(M1)、蕴含类别信息的路径(M2)、蕴含功能描述的路径(M3)以及蕴含用户评论的路径(M4).本文将融合多条路径综合考虑用户的需求偏好,为用户提供个性化的移动应用.步骤分为2部分:基于单条元路径计算用户对移动应用的需求偏好打分、融合路径计算综合得分. 1) 基于单条路径计算用户对移动应用的需求偏好打分.通过嵌入技术,我们已经计算了每条元路径的节点嵌入向量.节点的嵌入向量在空间中越接近,说明节点的相似性越高.因此,用户对移动应用的需求偏好可以转化为2个节点之间的相似度计算.相似性越高,需求偏好程度越高,说明用户选择该移动应用的可能性越大.用户对移动应用的需求偏好由节点嵌入向量的数值大小和方向决定.向量数量积公式能考虑向量的大小和方向,因此,本文使用数量积来计算节点的相似性.具体来说,给定查询用户节点uq,对每个移动应用打分: score(uq,aq)=uq·aq, (5) 其中,uq为用户节点向量,aq为移动应用节点向量. 2) 融合路径计算综合得分.对于每个用户,我们分别基于除基线(M1)外的3条元路径(M2,M3,M4),计算用户对候选移动应用的打分值score2,score3和score4(分别基于元路径M2,M3和M4计算).用户对移动应用的综合打分为s=score2+score3+score4.然后我们对候选移动应用的所有综合得分(s值)进行排序,选择得分最高的前k个移动应用来个性化推荐. 在本节中,我们使用本文提出的方法构建了一个移动应用需求偏好分析模型,并使用真实数据集测试和评估.下面详细介绍实验设置以及实验结果. 本文的实验关注2个研究问题: 1) 本文提出的基于元路径嵌入的移动应用需求偏好分析方法是否能够对用户需求偏好进行有效的分析,并提高个性化推荐的准确性? 2) 本文的方法融合了3条单一的元路径,路径融合是否比单一路径的效果更好? 我们利用网络爬虫技术获取了苹果应用商店的移动应用数据以及用户评论数据,并将其作为原始数据集.原始数据集包含7 214 条移动应用记录(包括应用编号、应用名称、应用功能描述、应用类别编号、应用类别名称),以及164 670条用户评论记录(包括应用编号、评论者姓名、评分、评论标题,评论内容).其中,应用编号和用户名是唯一的,数据表可通过应用编号关联.由于本文分析的文本信息为英文,且需要用户使用移动应用的真实数据来进行实验,因此本文要对原始数据按需求进行过滤.本文利用“应用编号”字段关联数据,然后分为2步过滤数据:1)筛选英文文本.剔除无法识别、含乱码、含非英文文本、不含英文文本的记录.2)筛选用户使用移动应用的记录.剔除没有用户评论的移动应用,剔除没有移动应用信息的用户评论记录.经过数据的筛选,最终得到1 507个移动应用,包含来自153 501条用户评论. 我们收集每个用户使用移动应用的情况,对每个用户,随机选取80%的使用移动应用的记录构成训练集,其余20%的使用记录构成测试集. 为了评估本文模型,我们采用需求分析和推荐领域中主流的评价指标:前k个结果的查准率(Precision@k)、查全率(Recall@k)、F1值(F1@k)以及归一化折损累计增益(NDCG@k)[36,41].其中,Precision@k衡量结果的准确性;Recall@k衡量结果召回情况,即推荐的移动应用与实际使用移动应用的比例;F1@k综合考虑查准率和查全率;NDCG@k衡量推荐的排名质量,即排名越高,得分越高.对于每个用户的移动应用推荐列表,我们分别计算这4个指标,最后取各指标的平均值作为最终结果: (6) (7) (8) 其中,topku表示为用户u推荐的前k个移动应用列表,Dtestu表示的是测试集中用户u真实使用的移动应用列表. (9) 其中, (10) 其中,reli表示的是在排名结果中的第i个位置的相关性.在我们的方法中,如果推荐的移动应用是真实值,那么rel=1,否则rel=0.折损累计增益(discounted cumulative gain,DCG@k)表示对于k个候选排名结果列表,惩罚排名靠后的结果相关性数值,用于衡量一个推荐结果的排名质量.理想折损累计增益(ideal discounted cumulative gain,IDCG@k)表示理想的DCG@k结果,即首先将k个排名结果按相关性从高到低排序,再计算DCG@k.NDCG@k表示对结果归一化,用于衡量不同推荐结果的排名质量. 在本文中,我们计算了所有用户Precision@k,Recall@k,F1@k和NDCG@k(k=5,10,20,30,50)的平均值,作为最终的评估指标.这4个指标的数值范围都为[0,1],且数值越高,推荐的效果越好. 本文的模型涉及多个参数.我们采用控制变量法进行了不同参数的实验.以主题词相似性阈值的设置为例,当其他参数不变时,我们调整不同的阈值来观察我们方法的结果变化.图7展示了k=10时4个指标的变化情况.从结果中看,Recall@10的变化起伏较大,其他指标的变化程度较小.3个指标都在0.75处取得了峰值.因此本文将相似性阈值设置为0.75. Fig. 7 The impact of similarity threshold on results图7 相似性阈值对结果的影响 通过对不同参数的实验,本文给出了最佳的参数设置.其中,学习率learningrate=0.01,上下文窗口w=5,随机游走路径长度L=30,每个节点随机游走路径条数n=20.主题词相似性阈值s=0.75.在本文中,针对所有的嵌入方法都使用相同的参数. 实验1.针对研究问题1,为了验证需求偏好分析方法的有效性,本文将我们提出的基于元路径的移动应用模型与现有的模型对比.从推荐任务和图嵌入技术2个角度考虑,本文采用的对比模型包括推荐模型(SVDFeature[42]和FM[43])以及图嵌入模型(DeepWalk[22]).SVDFeature是一种基于特征的,可以添加辅助信息的推荐模型.本文使用移动应用的类别、功能描述主题以及用户评论主题作为SVDFeature的辅助信息.FM模型是基于矩阵分解的推荐模型,它通过构建特征交叉来考虑特征之间的联系.为保证数据的一致性,本文将用户编号、移动应用编号、应用类别、功能描述主题、用户评论主题作为FM模型的特征.DeepWalk模型不使用元路径技术,直接通过节点转移概率随机游走,进而学习嵌入向量.为保证结果可比性,本文使用相同数据实验. 实验2.针对研究问题2,本文在相同的参数下,对比融合路径与单元路径的推荐效果.元路径M1为基线路径,表示不同用户使用了同一个移动应用;元路径M2表示不同用户使用同类别的不同移动应用;元路径M3表示不同用户使用功能相近的不同移动应用;元路径M4表示不同用户对同一个应用有相近的评论含义.因此本文设计的元路径M2,M3,M4能够分别表示应用类别、应用描述主题以及用户评论主题的语义.融合路径(即模型MetaPath)包括这3种信息,通过对比实验结果来分析各路径的影响情况. 实验1.本文提出的元路径(MetaPath)方法与其他模型的对比结果如表1所示.从指标平均值可以看出,我们的方法在4个指标中都展示了最优的结果.仔细分析结果,发现的结论为: 1) 与推荐模型相比,MetaPath的F1@k平均值为0.086 88,比基线模型中表现最佳的SVDFeature提升了0.02左右.在NDCG@k平均结果上,MetaPath的值为0.301 05, 比FM模型提升了0.1左右.与图嵌入模型相比,本文方法的结果更佳,说明引入元路径的技术对推荐结果有积极影响. 2) 从Precision@k,F1@k和NDCG@k这3个指标来看,对于本文模型k=10时效果最佳.在真实情况中,用户使用的移动应用数量有限,推荐列表中过多的移动应用数量会降低准确性,且可视化方法不易查看.过少的移动应用数量无法尽可能覆盖用户的需求偏好.因此,当任务的目标是追求推荐的准确性时,为每个用户推荐10个候选的移动应用列表,这样能最大程度地满足用户需求偏好. 3) 对于Recall@k来说,随着k的增大,推荐效果越好,用户需求偏好分析越准确. 对于研究问题1,总结来说,本文提出的基于元路径的移动应用需求偏好分析方法,能有效分析用户的需求偏好,并完成更优的个性化推荐. Table 1 The Comparison Results of Our Method (MetaPath) with Others Models 实验2.不同元路径的对比结果如图8所示.仔细分析结果,我们发现的结论为: 1) 总体来看,融合路径的方法(MetaPath)在各指标结果上优于其他单独的路径.融合路径综合了移动应用类别、功能描述以及用户评论信息,这说明融合多维信息的方法能更全面地捕捉用户对移动应用的需求偏好. 2) 从整体看,MetaPath,MetaPath-M2,MetaPath-M3以及MetaPath-M4在各指标结果上均优于基线MetaPath-M1,这说明应用类别、功能描述以及用户评论能有效挖掘用户对移动应用的需求偏好,并提高结果的准确性. 3) 对于MetaPath-M2,MetaPath-M3和MetaPath-M4这3条单一路径来说,在Precision@k,Recall@k和F1@k指标上,当k>5时MetaPath-M2效果最好,MetaPath-M4优于MetaPath-M3.当k=5时,MetaPath-M4有最优值.这说明在用户的移动应用需求偏好分析任务中,推荐列表数量较小时,用户更看重评论信息.而推荐列表数量大于5时,移动应用的类别信息占主要影响因素,其次是用户评论信息,最后是功能描述信息.对于NDCG@k指标,k≤20时,MetaPath-M4优于MetaPath-M2;k>20时,MetaPath-M2的效果更优.说明从排名质量的角度看,推荐列表数量小于等于20时,用户优先根据评论下载使用移动应用.因此,在后续工作中,针对不同的指标和任务,我们可以调整不同维度信息的权重来获取更优结果. 对于研究问题2,总结来说,本文通过融合路径综合多个信息,能更全面地分析用户需求偏好.移动应用的类别主要影响用户的需求偏好,其次是用户评论信息,最后是功能描述信息. 本节将对本文的方法和实验细节深入讨论,包括数据集、元路径设计和路径融合方式3个方面. 本文使用的数据集是来自苹果应用商店的真实数据集.我们根据用户使用移动应用的记录来分析用户行为背后的隐式需求偏好.用户记录数量的不同可能对结果产生影响.在一般情况下,大多数用户不会频繁下载多个移动应用.本文使用的数据集中,同一个用户最多使用7个移动应用,这符合实际情况.因此本文模型目前在用户记录相差不大的数据集上得到有效性证明.今后我们将探索有更大差异的数据集来开展实验,进一步验证方法的有效性. 基于概念模型的元路径设计方式多种多样,不同的元路径具有不同的语义,推荐的效果和意义也是不同的.元路径数量每增加一条,模型的时间代价将增加一倍.元路径的数量越多,模型越耗时.本文的首要目的是验证元路径引导的用户需求偏好分析是否有效.因此,我们选取了有语义的且最重要的4条元路径来开展实验.实验表明本文的模型能有效分析用户的需求偏好.在未来工作中,我们将探索并设计更多的元路径来优化模型. 本文的目标是验证元路径引导的用户需求偏好分析是否有效.在此基础上,我们初步研究了融合路径方式以及不同的单一路径对结果的影响.相加求和是最基本和最直接的融合方法,实验结果也表明融合路径能够提升效果.事实上,元路径的融合方式是一个需要深入探索的问题,例如在嵌入空间融合、对分值设置权重融合,这将涉及嵌入模型的优化、权重量化等多个问题.这并不是本文的研究重点,因此我们未深入分析打分相加的权重以及权重量化问题.基于融合路径效果更佳这一初步结果,我们将在未来工作中重点研究高效的路径融合方式. 本文提出了一种基于元路径嵌入的移动应用需求偏好分析方法.首先提取了应用功能描述、用户评论的语义关键词;然后综合移动应用的多维信息构建概念模型,进而设计一系列含有特殊语义结构的元路径;最后基于元路径改进随机游走策略,利用嵌入技术学习节点向量,完成用户对移动应用需求偏好的分析任务.实验结果表明:本文提出的基于元路径嵌入的移动应用需求偏好分析是可行且有效的.4.2 基于skip-gram的嵌入学习
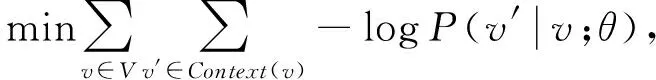

4.3 基于嵌入向量的移动应用推荐
5 实验与结果
5.1 研究问题
5.2 数据集
5.3 度量标准

5.4 参数设置

5.5 实验设计
5.6 实验结果
6 讨 论
6.1 数据集
6.2 元路径设计
6.3 路径融合
7 总 结
