一种用户故事需求质量提升方法
2021-04-07王春晖赵海燕崔牧原
王春晖 金 芝 赵海燕 崔牧原
1(高可信软件技术教育部重点实验室(北京大学) 北京 100871)2(北京大学信息科学技术学院计算机科学技术系 北京 100871)3(内蒙古师范大学计算机科学技术学院 呼和浩特 010022)
用户故事用简洁的自然语言形式表达用户或客户对系统的需要,在敏捷开发中被广泛采用[1-3].用户故事通常包括故事陈述和故事对话2部分.故事陈述概要表达了用户对系统的需要,一般包含谁想要这个功能(角色)、想要系统什么样的功能(意图),以及为什么需要系统提供这样的功能(目的收益)3部分信息;故事对话则通过对故事需求存在疑问的不断澄清而形成关于故事测试的描述[4-6];故事测试用于判定故事是否符合客户的期望.一些敏捷开发实践还进一步用场景表达故事实例化需求[7].
用户故事一般由客户或用户从业务需求的视角编写[5].由于客户和用户常常缺乏经验,所编写的用户故事经常在写作规范和表述上出现缺陷[8-9].例如,忘记写角色,使开发者无法确定该故事的功能满足哪类用户的需要;将多个意图写在一个故事中,造成用户故事的功能很难确定并难以测试;从不同角色写具有同样意图和或目标的故事,常会引入重复与冲突,等等.这些缺陷影响了需求的质量,导致需求不完整、不一致和不可测等问题.
发现故事中存在的质量问题(缺陷)是保障故事需求质量和敏捷开发顺利实施的关键[8-9].INVEST准则是目前广泛采用的故事质量分析准则(1)https://xp123.com/articles/invest-in-good-stories-and-smart-tasks/,它认为故事需求应该是独立的(independent)、可讨论的(negotiable)、有价值的(valuable)、可估算的(estim-able)、小规模的(small)和可测试的(testable).然而,INVEST准则仅对用户故事表达应该具备的良好性质进行了概括,是一种高层抽象说明,并不能直接用于对实例化故事需求的质量评测[9].
有研究者提出一些更加具体的准则,对故事陈述中角色、意图、收益等描述信息以及故事之间存在的冲突和重复性等质量问题进行描述和说明[10-11],并结合自然语言处理技术实现部分质量准则的自动化检测[10].然而,这些细粒度的准则仅关注故事陈述本身,没有关注同样重要的故事测试信息以及用户故事间关系.因此,现有研究在故事间冲突、独立性、可评估性以及故事功能完整性等自动化检测方面缺乏适用性.
本文关注故事陈述和故事测试2部分信息,提出采用自然语言分析技术和模型驱动相结合的方法,对用户故事需求进行全面的质量检测.从故事缺陷定位的角度构建了一种用户故事概念模型,根据实际案例,结合故事需求的完整性、一致性和可测试性,总结出11条用户故事编写应该遵循的质量准则.提出采用故事结构分析、句法模式分析以及语法分析等技术自动构建带场景的用户故事的模型,并根据准则进行故事缺陷检测.实现用于用户故事缺陷发现和修改的工具,通过不断修正用户故事中存在的缺陷提升用户故事质量.
本文的主要贡献包括4个方面:
1) 提出一种针对故事缺陷定位的细粒度用户故事模型,结合故事质量准则支持用户故事质量分析与生成缺陷报告;
2) 提出了11条质量准则,用于评估故事中出现的不完整、不一致以及不可测试等不同类型的缺陷;
3) 提出包括故事结构分析、句法模式分析以及语法分析等3个层次的用户故事分析技术,根据质量准则,发现并报告故事中存在的缺陷;
4) 实现支持用户故事质量检测和提升的工具,并在一个含36个用户故事和84个场景的真实项目数据集上进行了实验研究,表明了本文提出的需求缺陷检测方法的有效性.
1 相关工作
近年来,随着敏捷项目规模变大,项目中的故事数量不断激增,提升故事需求质量显得越来越重要.研究者在需求质量准则制定和用户故事需求建模方面开展了一系列研究工作.通过制定需求准则规范用户故事需求写作和实施质量检查;通过从用户故事中提取信息构建模型,形成全局的观察视角分析需求的完整性以及一致性等.在需求质量检查和从文档到需求的建模活动中,一些研究借助自然语言分析的技术和方法实现(半)自动化.
① https://standards.ieee.org/standard/830-1998.html
② https://xp123.com/articles/invest-in-good-stories-and-smart-tasks/
③ http://www.isys.ucl.ac.be/descartes/index.php
1.1 需求质量准则
需求质量是软件需求工程领域关注的主要问题之一[12-13].存在多个用于表征软件需求质量的准则,以验证需求是否按照正确的方式编写.其中,IEEE-830标准①,定义了传统软件开发中需求规格说明的质量标准,包括完整、明确、具体、一致等.
针对用户故事需求,有研究者提出写好故事应该遵循的准则.Wake②提出一个好的用户故事遵循INVEST原则.Cohn总结编写优秀故事的经验[5],包括明确故事的目标、编写封闭的故事、使用卡片约束、不过早涉及用户界面、由客户和用户编写故事等.这些质量准则给写高质量的故事提供指导和建议.但仍然是一种高层抽象说明,并不能直接用于对实例化故事需求的质量评估.
一些研究者针对用户故事描述提出敏捷需求质量检测框架.Heck等人[11,14]引入传统需求文档质量评估准则,从完整性、一致性和正确性的视角对故事描述进行质量评估.Lucassen等人[10]基于INVEST原则,根据故事的写法和故事描述特性,从自然语言分析的视角将质量评估准则划分为句法(syntactic)、语义(semantic)和语用(pragmatic)三方面.句法层的准则对故事描述的格式和每个特征信息的句法规则进行规范化;语义层的准则对用词表达和一致性方面进行规范化;语用层对故事描述中的完整性、唯一性等方面进行规范化.但它们对有些准则(如独立性、可估算等)没有明确的界定,缺乏自动化检测质量缺陷的可操作性.
本文认为用户故事除了包含故事的基本描述信息,还包括故事需求澄清和测试的相关信息.充分分析用户故事描述和测试场景等信息,有助于发现用户故事在语句表达以及故事间关系等方面存在的质量问题.本文从完整性、一致性和可测性3个方面重新组织用户故事质量评估准则,并对每个准则给出了详尽解释和说明,进而实现支持故事缺陷发现的工具,提升用户故事写作质量.
1.2 用户故事与建模
每个用户故事表达一个相对独立的功能需求.不同利益相关者从自身的角色出发,提出与某个特定功能相关的用户故事.对用户故事建模有助于理解用户故事需求的特性以及多个用户故事之间的关系.目前,一些研究通过建立用户故事与某种模型的映射,形成不同的视角观察和分析用户故事需求.
Wautelet等人[15]提出从用户故事到用例(use case)的映射方法.将故事中的角色映射到use case中的角色(actor).从意图和收益中分解目标和任务,映射为use case中的节点,并在目标与任务之间识别包含关系与扩展关系.该项工作还提供了编辑工具③,支持从用户故事、use case以及类图3个视角观察需求.Mesquita等人[16]提供了一种图形编辑工具US2StarTool,支持将一组用户故事映射为一个i*模型,帮助开发人员以系统的视角考察参与者如何达成目标,以及分析目标之间的关系.Trkman等人[17]提出从用户故事中提取本体以构建业务过程模型(business process model),建立用户故事之间的顺序依赖关系.Lucassen等人[18]从用户故事中提取概念模型检测故事需求的完整性.他们总结出提取概念和关系的启发式规则,并根据规则抽取概念建立关联关系.
我们在带场景的用户故事建模方面开展了初步的研究工作[19],将一组由不同利益相关者提供的用户故事需求文本通过人机协同的方式半自动化地转换成用户故事模型.该模型用于综合不同视角的模型,形成一个系统模型,并支持系统需求的迭代式演进.与构建系统需求演化模型不同,本文从故事缺陷定位的角度构建了一种用户故事概念模型,通过自动化的模型构建发现用户故事需求中存在的完整性、一致性和可测试性方面的缺陷.
1.3 需求工程中的自然语言处理
在需求工程中,自然语言处理技术广泛应用于模型的(半)自动化构建和需求质量自动化检测等.
在需求模型构建方面,一些研究借助自然语言分析技术从需求文档中提取模型中的概念及关系信息,构建实例化模型.例如,Yue等人[20]从RUCM(格式受限的use case需求文档)中提取模型相关信息,生成活动图、时序图以及类图模型.Kamalrudin等人[21]提出一种自动化的工具从文本需求中提取基本用例(essential use case, EUC)模型,并通过与基准EUC比较来检测不一致、不完整和不正确的情况.
在需求质量自动化检测方面,一些研究者借助自然语言分析技术中的词法分析器或句法分析器检查需求规格说明文档中存在的质量问题.SREE工具[22]采用词法分析器识别需求中存在的模糊性问题,其准确率和召回率分别达到了66%和100%.Yang等人[23]将词法和句法分析器与机器学习领域的条件随机场技术相结合,检测自然语言需求中的不确定性.他们在11个需求规格说明文档中识别辅助词、动词、名词和连词的不确定性,检测结果的F值平均达到62%.
本文采用自然语言分析技术从带场景的用户故事文档中提取用户故事概念信息,包括从故事陈述中提取故事描述相关的概念,从故事测试中提取故事功能相关的业务实体以及状态变迁关系信息.在实例化用户故事模型概念提取的过程中,定义了规范化的带场景用户故事表达框架,并制定了从框架中特定的位置提取相应概念的句法模型,定义了识别用户故事状态变迁、用户故事间关系的规则和方法.本文结合自然语言分析技术,在构建模型的过程中发现用户故事中存在的违背故事需求质量准则的信息,反馈用户故事中可能存在的缺陷信息.
2 用户故事质量模型
本节首先介绍一种带场景的用户故事表示,接着从故事缺陷定位的角度定义故事概念模型表达.
2.1 带场景的用户故事
Wynne等人[24]提出使用Gherkin语言来编写便于实现自动化验收测试的故事写作模板,包括功能(feature)和场景(scenario)两部分信息,表达用户故事实例化需求.该模板及主要概念如图1所示.
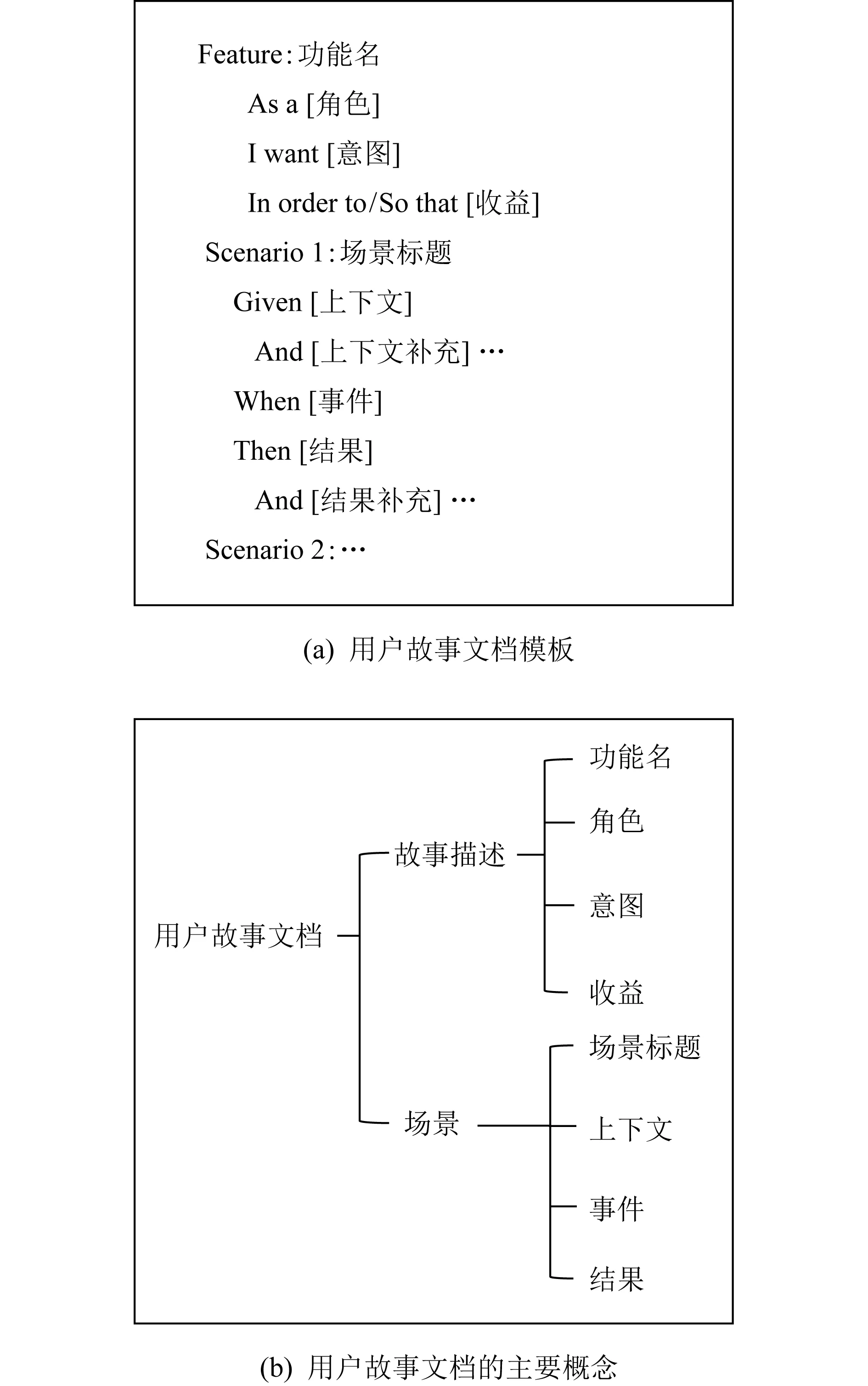
Fig. 1 The template of user story description with scenarios and its hierarchy of conceptual element图1 带场景的用户故事描述模板及其概念元素层次关系
其中,“Feature”后面是一个故事陈述,表示一个独立的功能,即以某个“角色”为视角,提出对使用软件系统的“意图或功能需要”以达成某种“目的收益”.其中,“Scenario”后面是特征的实例化描述.即,在某个状态和条件满足的情况下,执行某个动作或发生某个事件,系统达成了某种结果状态.一个功能包括至少一个或多个场景,用来探索一些边界情况,帮助实现该功能需求的正确性检验和测试.其中,所有场景都遵循同样的模式:将系统置于某种特定的上下文(Given和And描述的部分);戳一下(或者点一下)系统(When描述的部分);系统置于新状态(Then和And描述的部分).
场景建立了一个上下文,继而描述一个动作,最后检查结果是否符合预期.表1描述了“持卡人在ATM机上取现金”的用户故事示例.该用户故事包括3个场景,用于描述意图是否达成:“成功取款”、“卡余额不足不能取款”和“卡无效无法取款”.取现金业务与账号余额、卡是否验证通过(是否是合法用户)、取款金额以及ATM机余额等业务实体相关.这些业务实体在每个场景中被实例化,即赋予某个具体的值,表示这些业务实体处于某个“上下文”的状态下(前置状态).由于某个事件发生,而处于某个“结果”状态(后置状态).例如,“成功取款”这一场景中,表达前置状态的信息是:在账号的余额是balance,卡被验证通过且ATM机有足够的现金.当执行“持卡人取现金cash”事件后,该场景的业务实体的后置状态描述是:ATM吐出现金,系统提示取款成功,账号余额会修改.
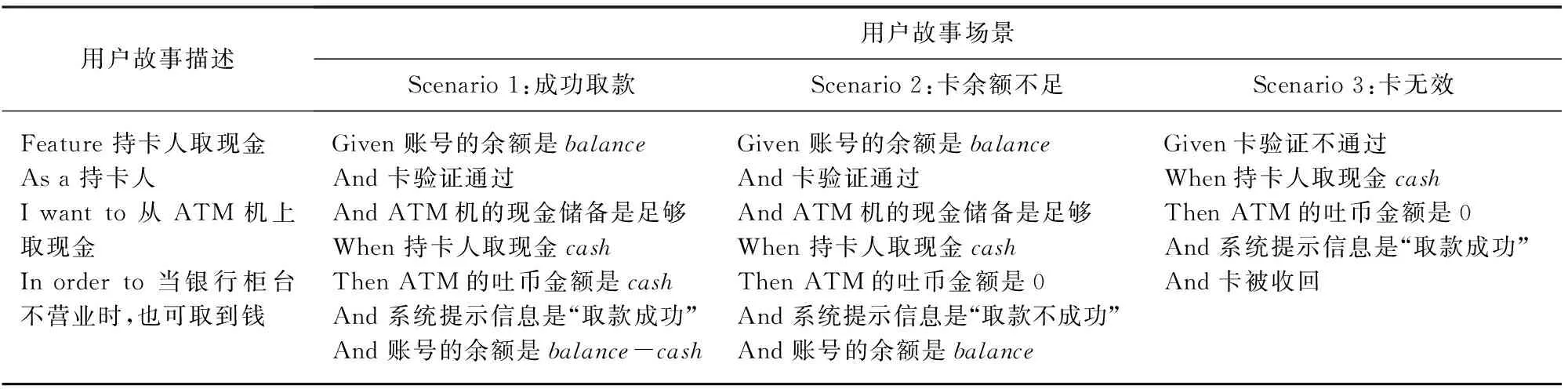
Table 1 User Story Description of “cardholder withdraw cash”
2.2 用户故事质量概念模型
根据2.1节描述的带场景用户故事信息表达的特性,用户故事包括故事描述、特征属性及状态变迁3个核心概念.其中故事描述包括故事名、角色、意图和收益;特征属性由业务实体组成;每个业务实体处于某个特定上下文时对应一个原子状态.将多个描述业务实体的原子状态组合在一起,形成组合状态.状态变迁是一个由状态变迁序列组成的集合.其中,状态变迁序列是由每个场景的上下文、事件、结果形成的状态迁移关系;其中上下文是该状态变迁的前置状态,结果是该状态变迁的后置状态.
任意2个故事之间可能存在3种关系:合作关系、依赖关系以及重复关系.1)合作关系是指故事具有相似的特征属性集,即在描述业务需求时具有较高的相关度,可能共同合作完成一个“史诗”故事;2)依赖关系是指故事的实现存在先后关系,即一个故事的完成依赖于另一个故事的实现;3)重复关系是指2个故事具有相同的文字表达或相同的语义,即相同的故事陈述和故事场景.存在合作关系的用户故事通常是由一个相对规模较大的故事分解而来,例如:用户在线挂号的故事分解为创建账号、填写挂号信息、编辑挂号信息等3个更具体的用户故事,而这些具体的用户故事合作完成用户在线挂号的故事.重复的用户故事通常是由于写故事的人在互相没有交流的情况下,从相同的角色出发,写出2个功能相同的用户故事.例如,有2个用户都写了“As a病人I want to创建账号”的用户故事,此时这2个用户故事存在重复关系.
用户故事质量相关的另外一个关键概念是缺陷.本文将用户故事看成一个由自然语言描述的文档,每行由一个关键词开头,如表1所示.用户故事可能存在不完整、不一致或不可测试等方面的缺陷.其中,缺陷主要包括3部分信息:出错的位置(通常定位到用户故事中的某一行语句)、出现质量问题的种类(某种出错类型),以及如何修改该缺陷的指导性建议(修改推荐).
综合上述用户故事质量相关概念,针对故事缺陷定位的故事质量概念模型包括单个故事、故事之间的关系以及缺陷3个核心概念,如图2所示.
1) 故事描述
故事描述包括故事名、角色、意图、收益4个部分.其中故事名是对故事特征的简短描述,用于区分不同故事.角色表示该需求是为了满足哪个(些)利益相关者的需要,一般表示一个具体的用户或客户的身份.角色通常是一个专有名词,例如,在线购物系统中的购买者、快递员、系统管理员等.意图通常表达功能性的需求.采用的句型为:[状语]+动词+[定语]+操作的直接对象.例如:As a 新闻网站访问者 I want to查看最新的新闻.“查看”是与请求的功能相关的动词;“新闻”是直接对象.收益中包括一个或多个成份,用于解释为什么需要这个功能.收益通常与3种信息相关:澄清意图、表达与其他故事依赖关系和或质量需求.例如,3个故事的收益部分分别表达上述3种信息.“As a 购买者 I want to 修改地址信息 In order to 纠正任何错误的地址信息”;“As 持卡人I want to 验证持卡人身份In order to 可以办理取款业务”;“As a 购买者 I want to 按照价格排序商品 In order to 能够容易的查看结果”.
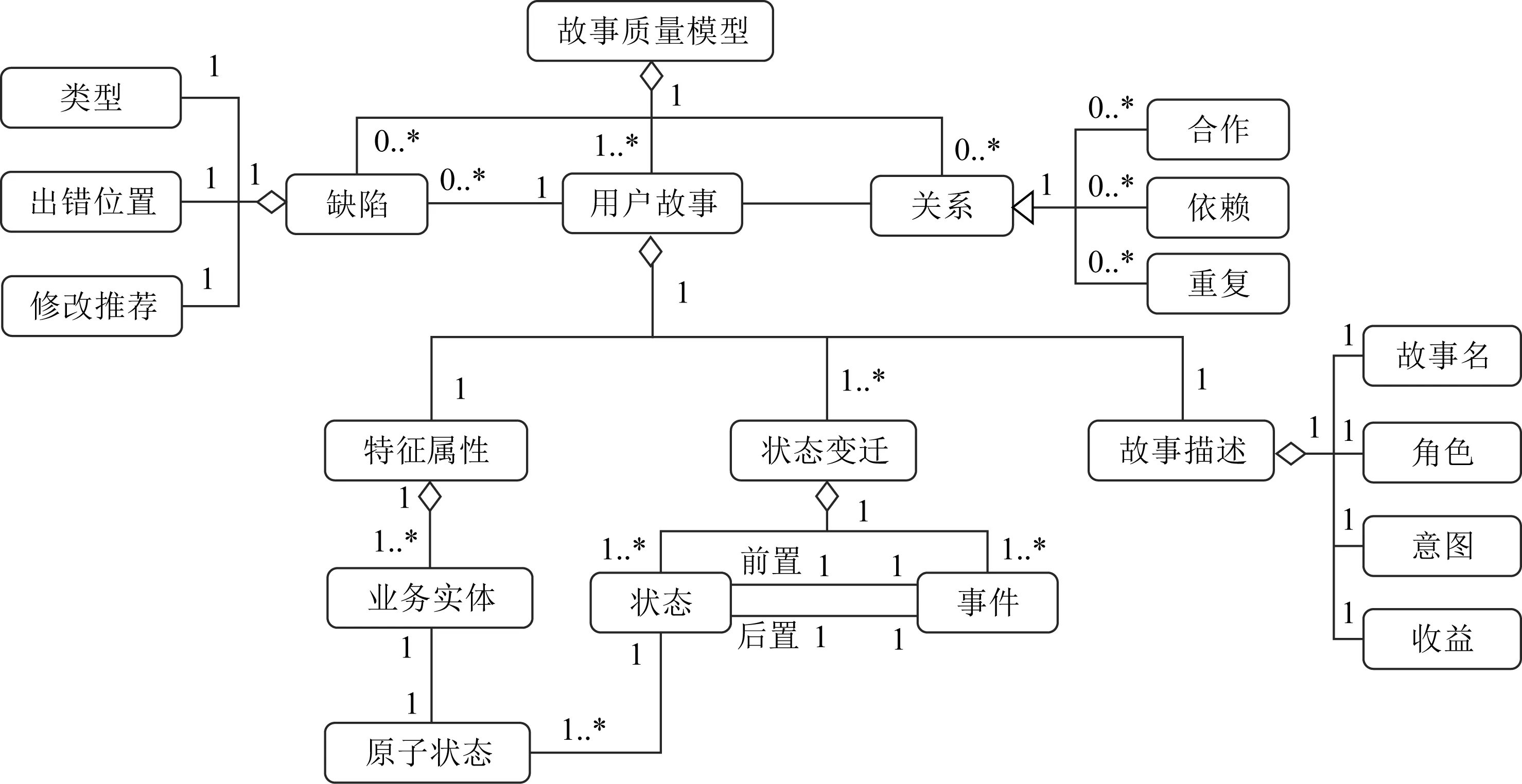
Fig. 2 Conceptual model of quality of user story图2 用户故事质量概念模型
2) 状态变迁
状态变迁由状态和事件组成.任一场景可以表达为一个状态和事件的序列.包括前置状态、事件、后置状态、事件、后置状态…其中,场景描述中GivenThenAnd关键词后面的语句对应于某个状态(其中Given,Then,And 关键词后面的每个句子表达一个原子状态).即:实体+属性+值.通常采用的句型为:名词+ [“的”+名词] + “是不是处于不处于”+ 名词形容词+ [“状态”];例如:“账号的余额是balance”.事件通常表示动作或状态,对应于场景描述中When关键词后面的语句.表示动作的描述通常采用的句型为:主动者+[状语]+动词+ [定语]+对象;例如:“持卡人取现金”.有些情况会省略主动者,此时主动者为角色.
3) 特征属性
场景是故事的实例,表达了系统在某个特定的上下文状态下,当某个事件发生时,系统所处的结果状态.场景的状态表达了系统业务实体的取值.将业务实体构成的集合称为故事的特征属性,用于记录场景描述中业务相关的信息.例如表 1的特征属性可以表示为集合:{账号.余额,卡.状态,ATM.现金储备,ATM.吐币金额,系统.提示信息}.针对具体场景,特征属性被实例化.例如,场景1中前置状态为:{账号.余额=balance,卡.状态=有效,ATM.现金储备=足够,ATM.吐币金额=NULL,系统.提示信息=NULL};经过事件“账号持有者取现金cash”,后置状态为:{账号.余额=balance-cash,卡.状态=有效,ATM.现金储备=足够,ATM.吐币金额=cash,系统.提示信息=取款成功};前置状态、事件、后置状态形成一个状态变迁.
4) 关系
在一组故事集合中,任意2个故事可能存在3种关系:合作关系、依赖关系和重复关系.存在合作关系的故事可能共同合作完成一个“史诗”故事.例如,“持卡人验证身份”“持卡人查询余额”“持卡人取款”合作完成“在ATM机上取现金”这个“大”故事.存在依赖关系的故事在实现上存在先后关系,即一个故事的完成依赖于另一个故事的实现.例如,故事“持卡人验证身份”发生在“持卡人取款”之前,即只有具有合法身份的持卡者才能取款.存在重复关系的故事通常是由于不同人在没有相互协商的情况下,从同样的角色和功能出发,写出了在表达和语义上相同的用户故事.例如,有2个写故事的人都想要系统提供登录功能.他们都提交了故事:“As a 用户 I want to 使用用户名和密码登录系统”.此时,将产生2个重复的故事.
5) 缺陷
缺陷记录了故事中不满足质量评估准则(见第3节)的信息,包括缺陷的种类、出错位置及修改这些质量问题的建议(推荐信息).本文定义了11种质量评估准则,并对故事描述逐行进行分析,从中提取出用户故事质量模型中的概念,并进行用户故事建模.在建模过程中分析是否存在缺陷(即是否该行违背了准则),如果违背了准则,则反馈该故事行的信息、出错的类型和修改该种类错误的建议.
3 故事质量评估准则
从需求质量评估的角度,用户故事表达应该满足完整性、一致性和可测试性.完整性体现在2个方面:一方面单个故事应该在表达上描述完整的需求信息,以便于其他人充分理解.具体表现在故事至少应该具有角色、功能点描述(意图)等关键字段信息,场景要包含上下文、事件和结果;另一方面所有故事应该覆盖一个完整的系统功能,即不缺失步骤功能要素.一致性同样体现在2个方面:1)每个用户故事应该使用统一的模板表达需求,以便于讨论者和分析者较容易地从中获取相应成份的信息(如角色、功能需求、场景等);2)不同故事在表达习惯(描述句式和句型等)和术语表达上具有一致性,且不存在冲突和重复的故事.除了完整性和一致性这2个因素外,每个用户故事应该满足可评估、不模糊、最小化和原子性,同时与其他故事具有尽量少的依赖(独立性),上述准则体现了故事的可测试性.本节根据实际案例,结合故事需求的完整性、一致性和可测试性,参考已有工作中针对用户故事描述的质量评估准则,对带场景的用户故事质量评估准则进行细化.表2展示了故事质量相关的因素及这些因素其对应的11条准则.
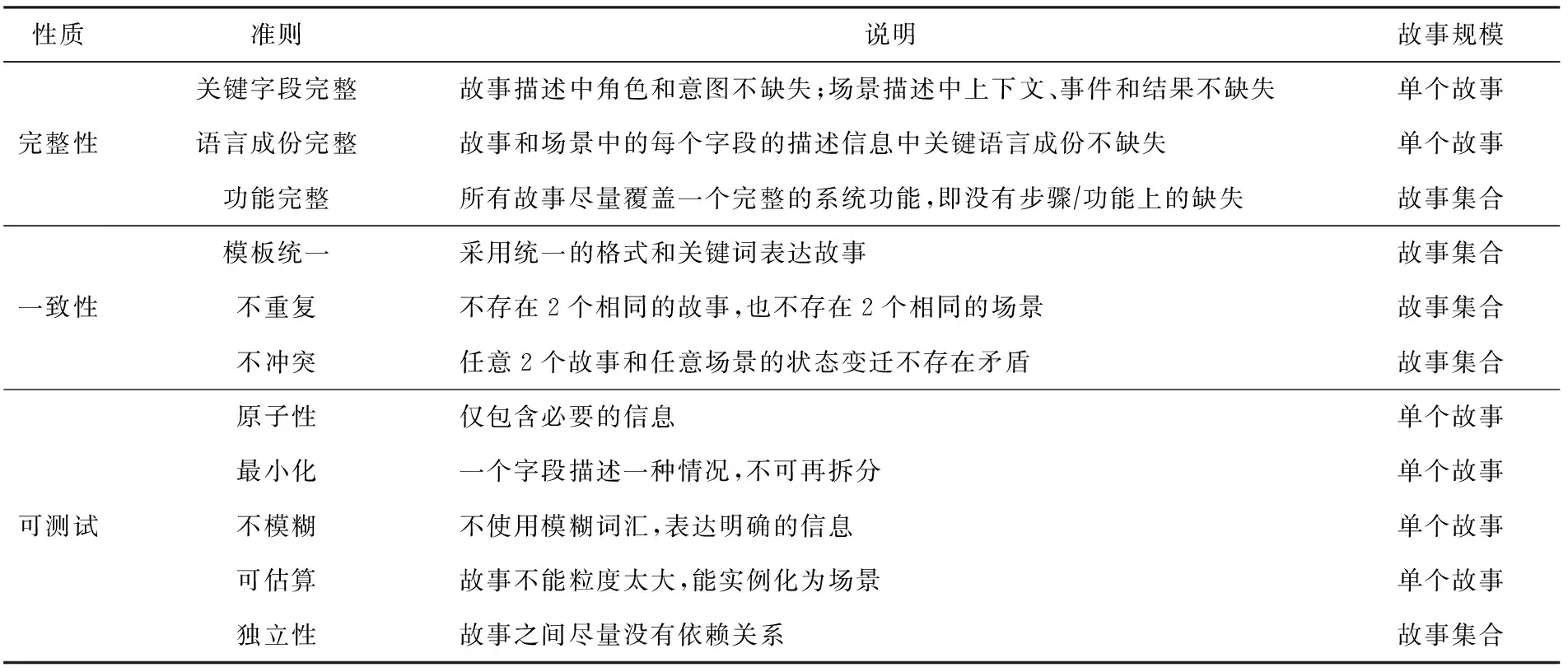
Table 2 Quality Criteria of User Story Requirements
1) 故事的关键字段完整
一个用户故事通常包括故事描述和故事场景2个部分.故事描述中至少要包括2种成份,即角色和意图.缺少这2种成份的故事描述是不完整的.例如,附录A中用户故事US1“I want to 当文件不能打开时,可以看到出错提醒”缺少角色说明.可以修改为:“As a合法成员 I want to当文件不能打开时,可以看到出错提醒”.此外,故事中的每个场景都包含上下文、事件和结果信息.缺失了上述任何一种信息的场景都是不完整的.关于缺失不同关键字段信息的示例,参见附录A.
2) 故事的语法成份完整
一个用户故事中包含角色、意图、收益、状态和事件等概念.一个清晰的故事描述中应该具有完整的语言成份,以表征故事的每个概念.例如,在故事描述中意图(I want to后面描述的信息)捕捉一个具体的功能特征,至少包括一个动作和动作操作的对象.用户故事“As a 用户I want to 打开共享地图 In order to 知道我和朋友之间的距离”,意图是“打开共享地图”,由动作“打开”和对象“共享地图”构成.附录A中故事US2“As a 用户I want to 界面一致 In order to 不会产生混淆”中,意图缺少必要的动词,使得含义不明确.可以写成“As a 用户I want to 在使用拨号盘时看到界面一致 In order to 不会产生混淆”.
3) 功能完整
4) 故事模板统一
故事集中的每个故事采用团队认可的用户故事模板格式和关键词书写故事.为了实现故事模板统一,需要事先定义一种大多数人习惯使用的格式,并取得整个团队成员的认可.团队成员在写用户故事时都应该遵循事先定义的格式.例如,团队认可的用户故事描述模板是“As a 角色 I want to 意图 In order to收益目的”,如下用户故事不符合模板统一准则:US4“As a 管理员,When 一个用户已经注册,可以收到邮件”.
5) 故事间无重复
故事集中任意2个故事描述不相同,即表达不同的含义.当2个写故事的人都从同一个角色出发,有可能写出重复的故事描述.例如,有2个成员都写了 “As a 新闻网站访问者 I want to查看最新的新闻 In order to 知道当前最新的新闻”.为了尽量避免重复,写故事的人应该写更为具体的需求.例如上述故事可以分别表达为“As a 新闻网站访问者I want to 查看最新的时政新闻”和“As a 新闻网站访问者I want to查看最新的体育新闻”.
任一故事中的任意2个场景或2个故事中的任意2个场景也不应该重复.例如,附录A中2个场景S1_1,S1_2存在重复.在一个故事中出现了2个相同的场景通常是由于书写上的疏忽.而不同故事中出现了重复的场景时,通常这2个故事具有较高的相似性,而场景可能存在省略状态的情况.
6) 故事间无冲突
故事集中任意2个故事不冲突.本文认为故事冲突主要包括2类:故事陈述中的冲突,包括角色、意图和目标之间存在描述逻辑问题;故事场景之间的冲突,包括状态变迁的逻辑关系存在矛盾.
故事陈述中的冲突主要存在2种情况:
① 相同“意图”达到不同“目标”.2个或多个用户故事有相同的意图,但达成不同目标.例如,附录A故事US6_1“As a 购买者I want to搜索图书In order to找到我想买的书”和故事US6_2“As a 购买者I want to搜索图书In order to查看是否存在该图书”存在不一致.为了消解这个不一致,这2个用户故事需要增加或细化信息,以明确需求.例如,故事US6_1可以改写为:“As a 购买者I want to输入想购买图书的关键字In order to看到相关图书的列表”.
② 不同“角色”相同意图和目标.2个或多个用户故事具有不同的角色但有相同的意图和目标,通常这些用户故事需要考虑合并.例如,附录A中的故事US7_1“As a 购买者I want to 输入注册信息In order to成为合法用户”和US7_2“As a 快递员 I want to输入注册信息In order to成为合法用户”可以合并为“As a 系统用户 I want to输入注册信息In order to成为合法用户”.在合并后的故事中,可以考虑增加场景对不同种类的角色进行测试.
对于2个状态变迁S1=〈s1,e1,t1〉,S2=〈s2,e2,t2〉,其中s1,s2表示前置状态,e1,e2表示事件,t1,t2表示后置状态.状态变迁冲突主要包括2种情况:
① 不同前置状态,相同事件和后置状态,即s1≠s2∧e1=e2∧t1=t2.通常这些场景上下文中有冗余的状态或结果中有状态描述不全.例如,附录A中场景S2_1“Given 账号的余额是充足的When 输入取款金额 Then 显示成功取款”和S2_2“Given 卡验证通过When 输入取款金额 Then 显示成功取款”可以合并为“Given 账号的余额是充足的 And卡验证通过When 输入取款金额 Then 显示成功取款”.
② 2个状态变迁的方向相反,即s1=t2∧e1=e2∧s2=t1.例如,附录A中场景S3_1“Given 提示信息是“请输入密码”When 选择进入键 Then 系统显示主界面”和S3_2“Given 系统显示主界面When选择进入键 Then 提示信息是“请输入密码”存在矛盾.
7) 故事原子性
一个故事中仅包含与某个业务功能需求相关的必要的信息,不能包含多个意图.同样,一个场景中表达状态信息的字段中仅包含一种业务实体及其状态的信息,不能包含多个业务实体 (如果想表达当前上下文包含多个业务实体的状态信息,则不同业务实体对应的状态信息之间用And进行分隔).例如,如下故事表达了多个意图:附录A的US8“As a 用户 I want to单击地图上的一个位置,并执行与该位置关联地标的搜索 In order to 反馈到关联地标的路线”.这个故事包含2个意图,应该拆分成2个故事:“As a 用户 I want to 单击地图上的一个位置In order to 选中该位置”和“As a 用户 I want to搜索与地图选中位置相关联的地标In order to反馈到关联地标的路线”.附录A中场景S4的Then字段中包含了2个状态信息:“Then 进入在线视频界面,显示视频详细信息”中包含2个状态,可以改写成“Then 进入在线视频界面 And 显示视频详细信息”.
8) 故事最小化
一个故事中除了角色、意图、目的、场景等关键信息,不包含其他无关的信息.例如,附录A故事US9“As a医生 I want to查看本周的预约时间(分为手术和出诊)”.尽量去掉括号里的补充信息,表达成明确的需求.该故事可以改写成2个故事:“As a医生 I want to查看本周手术预约时间”;“As a医生 I want to查看本周出诊的预约时间”.
9) 故事不模糊
故事中应不使用模糊词汇,且尽量使用统一和规范的术语,表达明确的信息.例如,故事US10“As a 注册用户I want to查看医生详细信息 In order to 选择合适合的医生”,其中“医生详细信息”不够明确,可以写成“医生的职称、科室、专长等信息”.模糊词汇还包括一些不确定的修饰词,例如:快速、短时间、几个、少量等.
10) 故事可估算

Fig. 3 User story quality analysis process based on natural language processing and model expression图3 基于自然语言处理与模型表达的用户故事质量分析过程
故事不能粒度太大,这样不便于估算其工作量和评估优先级.例如,附录A中故事US11“As a 求职者I want to 发布自己的简历 In order to招聘方可以看到”这个故事粒度太大了,可以分解成一些小故事:求职者可以创建简历(US11_1)、求职者可以修改简历(US11_2)、求职者可以删除简历(US11_3)等.
11) 故事彼此独立
故事在概念上应该不重叠,并且按任何顺序安排和实施故事的开发顺序.例如,附录A中故事US12_1“As a 采编网用户 I want to 编辑稿件”依赖于故事US12_2“As a 管理员 I want to增加一个用户 In order to增加的用户可以使用采编系统”.这2个故事不是独立的.
然而,在实际敏捷开发过程中,用户故事需求之间可能存在相互的依赖关系.例如,一个用户故事的实现依赖于另一个用户故事的完成.从需求管理的视角,建议通过发现依赖关系使故事之间的关系可见.一种常见的方法是在故事卡片上增加一段注释,以链接的方式或者自然语言描述的方式说明故事之间的依赖关系.例如,上面2个故事可以在故事“As a 采编网用户 I want to 编辑稿件”的卡片上加如下注释:“采编网用户由管理员添加,详见故事US12_2”.
故事间除了具有上述基于实现先后顺序的依赖关系(例如,故事US12_1与故事US12是一种依赖关系),还可能具有合作关系和重复关系.合作关系是一组可组合关系,即存在合作关系的小故事组合形成一个规模更大的用户故事.例如:表2中故事US11和US11_1,US11_2,US11_3之间是一种合作关系.重复关系是指不同人提供的故事在语言表面含义上存在重复(详见质量准则5).
4 故事需求缺陷识别方法
本节介绍发现故事中违背质量准则的自动化方法.图3展示了从一组用户故事中发现其可能存在的缺陷并反馈错误报告的框架.该框架主要包括3个关键模块:结构分析、句法模式分析以及语义分析.结构分析以格式受限的故事文档为输入,识别故事的字段信息,并发现违背关键字段完整和模板统一准则的故事;句法模式分析采用自然语言分析技术分析每个字段的句型和语句成份,识别出场景对应的状态变迁序列和特征属性信息,同时发现违背语言成份完整、原子性及最小化准则的故事;语义分析先对输入的一组故事进行相似度计算,发现重复的故事和相似度高的故事.然后对每个故事和每对相似度高的故事中的状态变迁序列进行规则检查,发现冲突.借助同义词库、模糊词库识别故事中是否存在模糊性和用词上的不一致.此外,本文还通过故事之间的关联关系挖掘的方法识别故事之间可能存在的合作关系和依赖关系.将关系反馈给写需求的群体,帮助他们分析如何提升故事独立性和功能完整性的质量.
① https://hanlp.hankcs.com
4.1 结构分析
给定一个采用图1所示模板编写的用户故事,结构分析以故事文档中的关键词(Feature,As a,I want to等)为特征词,识别字段:故事名(name)、角色(role)、意图(mean)、收益(benefit)、场景名(scenario)、状态描述序列(state)、事件描述序列(event).在解析故事文档结构过程中,结构分析过程发现每个故事是否违背了关键字段完整性和模板统一性的准则.
对于任一用户故事ui∈U,设其角色和意图分别表示为ri和mi,关键字段完整性检测的规则是:
conComplete(ui)↔ri≠∅∧mi≠∅.
对于任一用户故事ui∈U,其模板统一性的检测规则是:检查是否包含事先设定的特征词 (As a,I want to,…),如果没有完全覆盖这些特征词,则查看是否在“常用特征词表”中存在,如果存在则认为违反了模板统一性准则.
4.2 句法模式分析
在结构分析过程中故事的关键字段被存放在故事结构化文档(.json)文件中.句法模式分析则将每个关键字段看成句子,采用自然语言分析技术识别出每个句子的成份,然后根据规则提取图 2故事质量概念模型中的概念并检查相应字段成份完整性.具体而言,对于任一句子S,本文借助自然语言处理工具HanLP①先对句子进行分词和依存文法分析,识别出句子的成份.例如:“账户的余额是balance”这个短句中,“账户的余额”是主语,与动词“是”之间形成主语和谓语(主谓)关系,其中“账户”和“余额”是一种定语和中心词(定中)关系,而“是”和“balance”是动词和宾语(动宾)关系.(HanLP工具针对该句子的句法分析结果如图4所示).根据分词和文法分析结果,可以发现句子的成份.针对场景中Given,And和Then关键字段,同样可以识别出实体、属性、和值等概念,并生成状态信息.

Fig. 4 An example of dependent grammar analysis in HanLP图4 HanLP依存文法分析示例
句法模式分析过程可以发现用户故事是否违背了成份完整、原子性及最小化的准则.语言成份完整的判断依据是检查句子中是否包含了完整表达该字段应该具备的语言成份.例如,When关键词后面的字段信息应该表示一个动作或状态,当从这个字段信息提取不出关于动作和状态信息时,将生成该字段语言成份不完整的缺陷信息.本文针对每个字段的关键信息定义了推荐的句法模式(详见附录B),认为没有采用句法模式的表达可能存在成份不完整的缺陷.
1) 句子中含有连接词“和、或者、并且”等;
最小化主要检查“意图”字段中是否包含括号等备注信息.本文在对意图字段进行句法分析时,分析括号“(),[],{},〈〉”中间的语句,如果该语句包含选择性信息(如:并、或、且、和等),则认为违背了最小化准则.
4.3 语义分析
语义分析过程主要包括4个部分:相似度度量,故事陈述和场景的冲突检查,基于同义词库、模糊词库、术语表等知识库的质量检查,以及基于关系挖掘的故事间关系识别.
1) 相似度度量
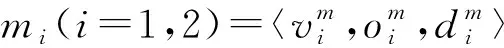

其中s:String×String→[0..1]是一个词到词相似度计算函数.即给定2个词x,y,s(x,y)返回一个0~1之间的小数.本文综合自然语言分析工具中基于词向量的相似度[25]和基于语义相似度的计算方法(采用HanLP计算中文词语义相似度计算方法①)分别计算2个词的相似度,并通过加权平均得到这2个词的相似度.这种综合词向量和语义相似度的计算方法综合考虑了词在字符表达和同义词之间的差异.
① https://github.com/hankcs/HanLP
② http://www.hankcs.com/nlp/hanlp.html
③ http://mlwiki.org/index.php/TF-IDF
④ https://insulation.org/io/articles/k-value-u-value-r-value-c-value/
系数α1+α2+α3+α4=1,2个用户故事的相似度sim(u1,u2)是一个0~1之间的小数.sv(x1,x2)表示2个意图或2个收益之间的相似性,计算为
sv(m1e1,m2e2)=
当2个故事的描述信息完全相同时,这2个故事的相似度为1.当2个故事对应字段描述越相似,相似度值越接近1.当2个故事对应字段的描述信息完全不相似,相似度接近为0.
2) 冲突检查
对于任意2个相似度较高的故事(例如,相似度大于80%)需要进一步检查故事是否存在冲突.设故事u1=〈r1,m1,e1,F1,S1〉,u2=〈r2,m2,e2,F2,S2〉具有较高的相似度.满足2个条件的故事描述存在冲突:
① 相同“意图”达到不同“目标”
Conflict1(u1,u2)↔m1=m2∧e1≠e2;
② 不同“角色”相同意图和目标
Conflict2(u1,u2)↔r1≠r2∧m1=m2∧e1=e2.
设S1=〈s1,e1,t1〉,S2=〈s2,e2,t2〉是2个状态变迁.满足2个条件的状态变迁存在冲突:
① 不同前置状态,相同事件和后置状态
Conflict3(S1,S2)↔s1≠s2∧e1=e2∧t1=t2;
② 2个状态变迁的方向相反
Conflict4(S1,S2)↔s1=t2∧e1=e2∧s2=t1.
3) 基于知识库的质量检查
本文通过创建相关的知识库辅助不模糊、不重复以及功能完整性的质量检查.
在编写故事时,不同人在表达相同的概念时可能使用不同的术语,影响了团队成员对需求的理解和相似性计算.为了减少这些影响,本文针对特定领域的故事需求质量检查问题,创建了同义词库.在同义词库中包含同义词和该同义词的使用频度.当某个故事中出现了同义词词汇并使用频度低,则认为存在用词上的不一致,并反馈相关的缺陷信息.此外,本文还创建了模糊词库,包括一些经常出现的模糊词,例如大概、很多、很快、快速、几秒等.当某个故事中出现模糊词时,反馈存在违背不模糊质量准则信息.
为了实现基于知识库的质量检查,提高汉语言分词准确率,本文采用基于统计分析与规则学习的领域术语词抽取的方法半自动化地构建领域术语库.具体包括4个步骤:
① 对一组用户故事文档进行分词与词性标注.
② 进行候选词提取.采用基于互信息和左右信息熵的短语提取方法(HanLP命句实体识别②)从用户故事需求文档集中获取候选短语列表.
③ 候选词过滤.对候选短语列表中的短语分别计算TF-IDF③和C-Value④值,并按短句的TF-IDF值和C-Value值加权值进行排序,选取排名靠前的短语作为候选领域术语词.
④ 人工确认领域术语词.人工从过滤后的候选词中选择并确定领域术语词.
4) 故事间关系识别
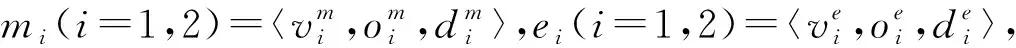
simdep=max(sr(m1,e2),sr(m2,e1)),
其中,sr(m,e)表示2个故事意图(m)和收益(e)之间的相似度,该相似性计算为
其中,v为意图收益中的动词,o为意图收益中动词操作的直接对象,d为意图收益中动词操作的间接对象.
合作关系的相似度采用比较特征属性集F1,F2之间共有元素的占比:
另外,对于可估算这一质量检测标准,本文认为那些具有场景描述的故事是可估算的.即用户故事ui满足的规则为
ConEvalated(ui)↔Fi≠∅∧Si≠∅.
5 实验与结果
基于本文提出的用户故事缺陷检测方法,我们实现了一种支持带场景用户故事质量提升工具USQI(user story quality improvement).本节先介绍该质量提升工具,然后以一组面向智能手机需求的用户故事集为案例,验证本文提出的用户故事缺陷检测方法的效果.
5.1 工具介绍
USQI工具主要包括2方面的功能:报告用户故事文档中存在的缺陷和交互式地提取用户故事文档中的领域术语词.图5展示了该工具在执行一个用户故事的检测后反馈的结果,包括用户故事文档(详细信息)、用户故事结构、用户故事出错信息和领域术语候选词.用户故事文档是由写故事的人编写的用户故事文件,每一行均以一个特征词开头;用户故事结构按照用户故事模型中的特征词组织用户故事视图,帮助用户查看用户故事描述的关键字段信息;用户故事出错信息主要包括错误发生的位置(行数)出错的信息(是哪一种类的错误以及如何修改的建议),并按照出错程度分为错误(缺少必要成份的情况)和异常(其他情况);领域术语候选词是系统从该用户故事文档中提取并反馈的候选领域术语,供领域专家从中确认并选择.确认后的领域术语词被加入领域术语库,用于系统的分词,促进用户故事模型构建.

Fig. 5 A screenshot of the workspace of the USQI tool图5 USQI工具用户故事质量检测工作界面
USQI工具采用基于Java的编程语言,遵循MVC(model-view-controller)的设计思想,其组成构件如图6所示.USQI主要包括4个子系统:用户故事建模(user story modeling)、缺陷检测(detecting defects)、领域知识库构建(knowledge base generator)以及数据存储(data storage).用户故事建模从用户故事中抽取关键概念信息并对这些关键概念进行缺陷检测,进而生成用户故事质量模型(user story model,USM).缺陷检测主要包括结构分析、句法模式分析以及语义分析3个构件,分别用于发现用户故事中存在的违背11条质量准则的用户故事缺陷.领域知识库的构件识别用户故事文档中的领域知识(领域术语、同义词、模糊词等).数据的存储包括用户故事质量模型(USM)的存储、缺陷信息的存储以及知识库信息的存储,为不同构建提供数据支持.
5.2 度量标准
检测工具反馈故事中可能存在的缺陷信息.本文采用准确率和召回率度量缺陷反馈结果的效果.准确率表示在工具反馈的结果中正确反馈的占比.召回率指在故事集的所有缺陷中正确反馈的占比.设Def表示工具反馈的缺陷数量;FP表示工具反馈结果中误报的缺陷数量;FN表示工具反馈结果中漏报的缺陷数量.准确率prec和召回率rec分别计算为
5.3 用户故事集
本文针对来自某企业的关于智能手机的一组用户故事数据集开展实验研究.该组数据集共有36个用户故事,包含84个场景,所有用户故事均采用图1所示的推荐格式编写.为了对这些数据进行有效分析,首先征集6名来自需求分析研究小组的研究生组成了评估小组,分别对这些用户故事进行缺陷标注、分类以及对自动化工具反馈结果进行正确与否的确认工作.经过人工分类和整理,将这些用户故事按照联系人、邮件、短信、备忘录、在线市场等分为5类关注点.自动化检测工具反馈了173个缺陷.表3展示了故事数量(#Fn)、场景的数量(#Sn)以及缺陷数量(Def).
表4统计了工具反馈的173个缺陷的类型:针对联系人、邮件、短信、备忘录、在线市场为关注点的故事集分别统计违背了表2所示准则(本实验没有考虑功能完整性和独立性)的缺陷数、误报数和漏报数.
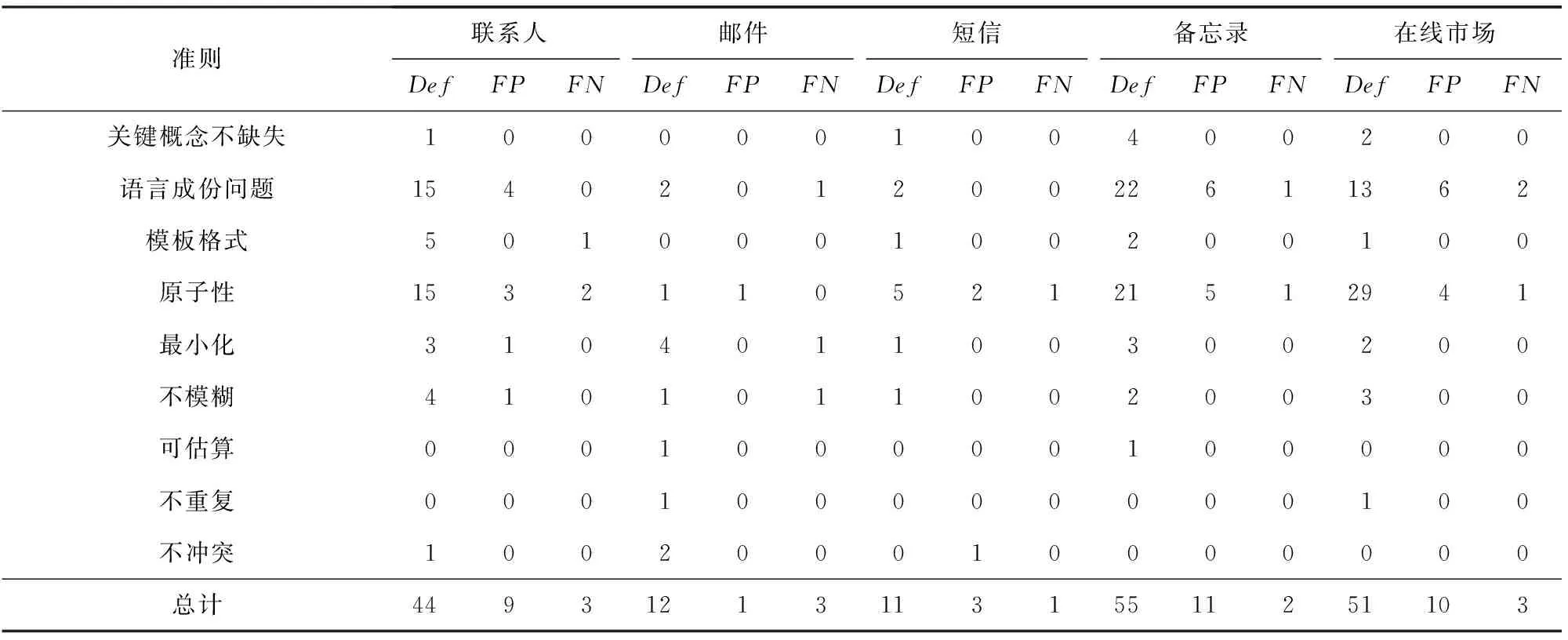
Table 4 Number of Defects,False Positives and False Negatives for Each Quality Criterion in the Experimental Data Set
表5展示了所有反馈结果中不同准则的缺陷数、误报数、漏报数以及准确率和召回率的统计结果.结果表明针对智能手机的这组实验数据集,平均准确率为88.79%和95.06%.
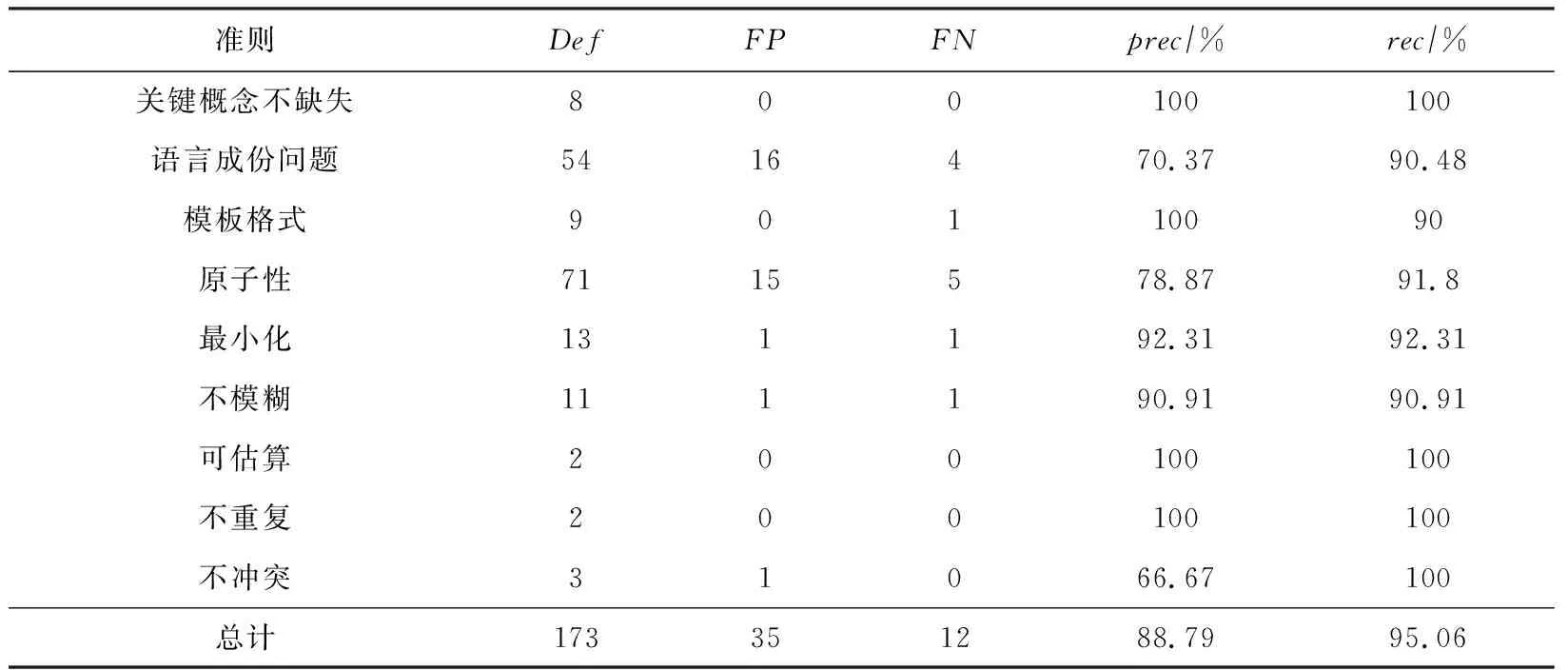
Table 5 The Number of Defects,False Positives, False Negatives, Precision and Recall for Each
表6展示了当阈值为0.7,0.8和0.9时智能手机用户故事实验数据集中故事之间合作关系与依赖关系的识别结果.包括对联系人、邮件等用户故事集合中合作关系与依赖关系的数量(Rel)、误报的数量(FP)、漏报的数量(FN).采用5.1节中准确率和召回率的计算方法(其中Def替换为Rel).从统计结果可以看出,合作关系和依赖关系的反馈结果在阈值为0.8时取得较好的结果:平均准确率分别为83.33%和72.73%,平均召回率分别为80.35%和80%.

Table 6 Statistics Table of User Story Relationships When the Thresholds of Cooperation and
5.4 结果与分析
从表5的统计结果可以看出,出现缺陷最多的类型是语言成份问题和原子性问题,其数量在总缺陷数的占比分别为31%和41%;缺陷反馈结果的准确率分别是70.37%和78.87%;召回率分别是90.48%和91.8%.我们对产生缺陷的故事描述进行分析,发现出现“语言成份”问题的主要原因是省略了一些必要的语法成份,使得自然语言分析工具不能识别出完整的句子成份.例如:“Then 无法点击”(省略了主语);“I want to本地文档名称及文档内容”(省略了动词).还有一些描述增加了一些不必要的信息,例如,“用户输入关键字搜索”(输入和搜索都是动词).存在原子性问题的缺陷的描述通常也是由于写故事的人在表达句式方面存在问题,例如,有的描述经常会省略一些表示定语关系或状态的助词(的,地, 在…上,当…时等),使得自然语言分析工具认为一个短句有2个动词,如“全局搜索在线电子书中信息”,“When 进入全屏模式查看图片”.也有一些描述包含了过多的信息,应该拆分.例如,“跳转到Email正文详情界面显示Email全部信息”实际上是2部分信息.
针对检测结果中误报的情况,分析表明不准确的分词是产生误报的主要问题.例如,一些术语词汇没有被包含到术语库中,使得自然语言分析方法不能准确地分析句子的成份.例如,“进入在线生活服务”,“启动商品购买界面”中“在线生活服务”和“商品购买界面”是术语词,而自然语言分析工具将其分割为多个词.本文将领域术语抽取方法加入到需求质量提升框架中,通过不断地更新领域术语词库,提高分词的有效性,经过人工核查,一些由于分词原因造成的误报有所降低.
在自动化缺陷检测结果中,关键概念不缺失、可估算、不重复方面的缺陷反馈结果的准确率和召回率都达到了100%.主要原因在于认定违背上述准则的规则较为简单:关键概念的判断通过分析角色和意图是否非空;可估算是判断一个故事是否有场景描述;关于不重复的判断问题,本文主要根据文本表达是否完全相同.
从表6的统计结果可以看出:基于关系挖掘的方法从一组用户故事中发现存在合作关系及依赖关系的故事对,具有较高的准确率(83.33%和72.73%)和召回率(80.35%和80%).人工检查误报和漏报的关系发现:对于合作关系的故事,通常由于角色和意图中操作对象不同时,会产生漏报;当一些故事省略了一些状态信息时,会产生误报.对于依赖关系,漏报主要发生在一些目标中没有描述与其他故事之间的关系;误报主要发生在有些动词和对象具有较高的相似性(但在语义上并不相似).
6 总 结
本文提出了一种基于自然语言和模型驱动相结合的故事需求质量提升方法,以检测一组给定的用户故事是否存在不完整、不一致和不可测方面的缺陷.该方法主要包括3个关键部分:故事质量准则的制定、故事质量模型的构建和基于故事质量准则的缺陷检测.本文根据实际案例总结出11条用户故事编写应该遵循的质量准则.与现有故事质量准则相比,本文提出的故事质量准则一方面在完整性和一致性方面对故事的质量进行评估,另一方面考虑了故事测试及故事间关系相关的质量问题.提出采用故事结构分析、句法模式分析以及语法分析等技术自动构建带场景的用户故事的模型,并根据准则进行故事缺陷检测.最后,本文针对包含36个用户故事和84个场景的数据集开展实验研究,结果表明本文提出的需求质量缺陷检测方法的有效性.本文提出的方法将有助于迭代式的用户故事需求建模和用户故事质量的不断提升.
