基于Spark的医疗设备运维信息挖掘分析研究∗
2021-04-04饶季勇钱雪忠
饶季勇 李 聪 钱雪忠,2
(1.江南大学物联网工程学院 无锡 214122)
(2.江南大学物联网技术应用教育部工程研究中心 无锡 214122)
1 引言
随着各医院医疗设备数量和种类的不断增长,设备的运维问题也日益凸显,做好医疗设备运维的质量保证,对于临床诊断和治疗工作有着重大的意义[1],数字化时代的到来,更激发了对制造业及其运营的全新思考,工业4.0运用IOT技术动态响应设备需求,机械传感器与控制系统互联互通,可实现医疗信息化系统用于医疗设备的预测性维护、统计评估等[2]。根据大数据的定义,医院所生成的医疗设备运行数据可以被认为是大数据[3]。这些海量数据蕴含着大量对设备运行有应用价值的信息。数据挖掘能从这些历史数据中提取出故障相关信息,进行设备故障的诊断。
传统的数据挖掘面对海量医疗设备大数据时,难以满足性能需求。越来越多的学者开始向大数据预测性维护方向进行研究[5~6],但针对医疗设备运维大数据研究却不多,通过对Spark的研究发现,Spark是一个基于内存的并行计算框架,避免了Ha⁃doop将中间结果存入磁盘,再从磁盘中重读的繁琐问题,因此Spark相比于Hadoop MapReduce在迭代计算方面更加高效。在面对设备异常数据时,通常采用聚类算法进行数据分析,例如孟建良、刘德超[12]就电力系统不良数据采用并行K-means算法进行实验,实现电力系统负荷信息的检测;宋鸣程等[15]提出一种基于Spark的K-means算法和FP-Growth算法结合的新方法对火电大数据进行处理,挖掘到目标的强关联规则,从而得到各工况下的参数达到过的最优值,并对机组运行进行优化指导。聚类算法众多,最为常用的是K-means算法,为了提高算法的聚类效果,学者们针对K-means算法提出了很多优化算法,比如Bahmani B和Moseley B等[7]提出的Scalable K-Means++算法,优化了K-means对随机生成初始质心的问题,使K-means算法的效率得到很大提升;张玉芳等[10],使用基于取样的划分的思想改进了K-means算法,在算法的稳定性上获得了提升。
针对以上问题,提出了基于Spark的医疗设备运维信息挖掘分析方法,该方法通过K-means算法在Spark平台上并行计算,根据数据的挖掘结果对设备运行参数进行故障归类,有效地解决了传统数据处理面对海量数据时的迭代计算问题,提高了医疗设备运维信息的处理能力。同时,该方法根据真实的医疗设备运行状态,对其运行参数进行了型号、阈值的划分,保证了数据挖掘的可靠性和高效性。
2 Spark平台架构
2.1 Hadoop
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。它是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
Hadoop的核心部分包括HDFS、MapReduce和YARN。HDFS是分布式文件存储系统,用于管理同一网络下跨多台计算机的文件,包含名称节点(NameNode)和数据节点(DataNode)。MapReduce是一种分布式并行编程框架,主要用来处理和产生大规模数据集,“Map”和“Reduce”是其中的两大基本操作,Map函数对数据进行分块处理并产生中间结果,Reduce函数则对Map函数产生的中间结果进行归约产生最终结果。YARN是统一的资源调度器,完成对任务资源的管理、调度等功能。
2.2 Spark
Apache Spark是一个开源集群运算框架,最初是由加州大学伯克利分校AMPLab所开发,它是一个类Hadoop MapReduce的通用并行计算框架,使用了存储器内部运算技术,在原有的Hadoop Ma⁃pReduce优点上,弥补了其在迭代计算方面的不足,提高了运算速度。
Spark由Scala语言编写,Spark的核心是弹性分布式数据RDD,Spark其他功能都是基于RDD和Spark Core之上的,RDD抽象化是经由一个以Sca⁃la、Java、Python的语言集成API所呈现。Spark包含用于在内存上提供数据查询功能的Spark SQL、机器学习库MLlib、流式计算Spark Streaming、用于图分析的算法合集Graph X等模块。

图1 Spark系统架构
如图1所示,Spark运行架构包括集群资源管理器(Cluster Manager)、工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体进程的执行进程(Executor)。其中,Cluster Manager可以是Spark自带的Standalone资源管理器,也可以是YARN或Mesos等资源管理框架。
3 算法分析
3.1 K-means算法
K-means是一个数据挖掘算法,属于无监督学习,可以根据对象的属性或特性将N个对象聚类到K个簇,同一簇中的对象相似度较高;而不同簇中的对象相似度较小。让数据与相应簇质心间的距离的平方和最小,这样就可完成这个分组。其算法表达式为

其中xn表示n个d维数据,μi表示簇中心的平均值,rnk表示数据被归类到簇的时候为1,否则为0。
K-means算法的第一步是根据给定的k值,取k个样本点作为初始划分中心。第二步将数据点分配到最近的簇质心。对于一个给定的d维数据点,可以使用距离函数来确定最近的簇质心,采用欧式距离函数来计算这个质心生成该数据点的可能性有多大。若要得出两个d维数据点x=(x1,x2,…xd)和y=(y1,y2,…,yd)之间的欧式距离,欧式距离公式为

第三步,计算每个划分中样本点的平均值,将其作为新的中心。循环2、3步直至达到最大迭代次数,或划分中心的变化小于某一个预定义阈值。
3.2 基于Spark的K-means算法
K-means算法需要重复迭代计算每一个数据与质心的欧式距离,所以K-means算法的时间复杂度会随着数据量的不断增大而不断增大,处理大数据时会出现计算瓶颈。其次,在单机平台上由于无法完全将数据加载到内存进行计算,所以需要重复读写内存和磁盘,浪费大量资源。本系统采用基于Spark平台的K-means算法处理医疗设备运维大数据,将医疗设备运行时产生的大数据分发到各个计算节点,同时进行计算,解决了单机状态下处理大数据的计算瓶颈,又由于Spark是基于内存计算的框架,还可以优化诸如K-means等迭代算法的计算。其算法流程如下所示。

4 系统设计与实现
实验在ecs服务器单机伪分布式配置上进行,伪分布式Spark集群环境如表1所示。按照安阳市人民医院型号为3.0T HDXT的仪器运行参数,模拟高斯分布数据进行实验。Hadoop进程以分离的Ja⁃va进程来运行,节点既作为NameNode也作为DataNode,同时读取的是HDFS中的文件。软件开发环境采用IntelliJIDEA 2018.2.4。单机上所有软件在安装并配置完成后即可启动Spark伪分布式集群进行测试。基于Spark的医疗设备运维系统架构如图2所示。

表1 计算节点配置

图2 系统架构
数据采集方面,对于DataBase数据采用Sqoop工具将储存于MySQL的数据抽取到HDFS中,对于文本文件采集我们使用传统的Kettle导入HDFS或MySQL中。采用HDFS作为分布式文件存储,MySQL作为传统数据库,Standalone资源管理器,采取伪分布式部署,使用基于Spark的K-means聚类模型进行数据处理,构建离线医疗设备运维分析模型,表明Spark平台的高可靠性和运算速度快的特点。数据可视化方面,采用Java编写MySQL数据库连接模块,结合JavaScript技术,利用Json作为数据传输类型。可视化的结果以静态图像和动态图像结合的方式呈现,使得用户能够从不同的角度去观察数据视图。Echart提供了丰富的数据交互能力及各种各样的图表结构,本系统选择了Echart中多种图表与百度地图API结合的方式将结构呈现给用户。可视化界面主要分为设备基本信息和数据运维信息两个部分。设备基本信息部分主要针对设备的基础信息,健康状况,分布情况及整个系统的错误日志进行展示,并实时更新。数据运维信息部分主要针对算法中分析出来的数据利用Echart图表动静结合的呈现出来。
5 系统测试与分析
运用安阳市人民医院3.0T HDXT型号设备在2018-06-27~2018-11-16这段时期运行产生的数据归结出的运行参数阈值进行预测的标准。型号3.0T HDXT设备运行参数阈值如表2所示。

表2 型号3.0T HDXT设备运行参数阈值
K-means算法使用Scala语言,在IntelliJ IDEA 2018.2.4内进行编译。类比型号3.0T HDXT设备运行数据,采用高斯分布的模拟数据进行实验,共有3万组9维数据,选取液氦压力、扫描腔温度、液氦水平、水温、水流等9项参数,运用基于Spark的K-means算法进行聚类计算,产生的3个聚类中心如表3所示。与表2设定的阈值相对照可以看出,位于第一、二类的数据点的液氦水平较高,磁体屏蔽层温度较低;第三类的数据点的液氦压力很低,扫描腔温度较高,水温较高,冷头温度较高,由此可以将这3万条数据简单分为3类做初步的预测。

表3 K-means聚类中心
为了验证基于Spark的K-means算法相对于一般的K-means算法,对大数据的挖掘效率更高。该方法使用单机并行K-means算法与基于Spark平台的并行K-means算法进行比较,对3百、3千、3万、30万、300万组9维数据进行测试,聚类个数都设为3,最终比较两算法的运行时间,结果如图3所示。
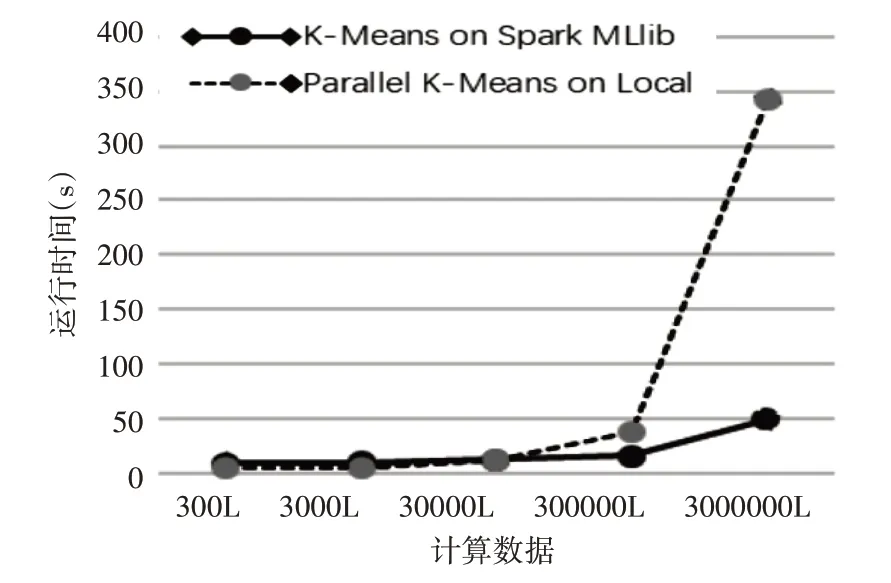
图3 K-means运行时间对比结果
由图3可以看出,最大迭代次数相同的情况下,在数据量不大的情况下,两种算法的运行时间相差不大。当数据量小于3万组9维数据时,由于Spark集群需要启动和调用MLlib库,消耗了一些时间,单机并行的K-means算法要比基于Spark平台的K-means算法更快。但数据量上升到十万以上,基于Spark的K-means算法运行速度明显要优于单机并行的K-means算法,当数据量为300万组9维数据时,基于Spark的K-means算法运行时间仅为单机的七分之一。由以上分析可知,基于Spark的K-means算法能够高效地处理医疗设备运行大数据问题。
6 结语
本文提出了一种处理医疗设备运维信息的新方法,基于Spark的K-means聚类模型进行医疗设备运维信息预测分析。该方法结合Spark内存计算模型,解决了大数据的迭代计算问题。通过Spark平台上并行K-means算法与单机状态下的K-Means算法的比较,以及对医疗设备运维信息数据的算例分析和实验,选择K-means算法模型,并引入分布式存储系统HDFS,解决了传统方法难以有效处理医疗设备大数据的问题,满足了预测系统处理大量数据的需求,在医疗运维方面具有十分重要的应用价值。
