基于深度学习的陆空通话标准用语处理与建模∗
2021-04-04
(中国民航大学空中交通管理学院 天津 300300)
1 引言
管制员和飞行员之间利用陆空通话标准用语来进行沟通,而通话用语错误造成飞行事故和不正常情况占总事故65%,因此规范陆空通话用语标准势在必行。通话标准用语的培训通常借助空管模拟机,模拟机设有管制员席位和飞行员席位,飞行员席位通常由教员或学员自行承担,由于培训人员的数量限制,难以有效保证管制学员训练时间和训练效果[1]。因此,利用自然语言理解相关技术,由计算机理解和回答管制员指令,从而替代飞行员席位,可有效提升管制员培训效率和效果,节约人力物力资源。
模拟管制训练流程,计算机先通过语音识别模块将管制员指令转化为文本指令,再利用自然语言理解模块理解文本指令并给出文本回答,最后通过语音合成技术,播报语音回答,处理流程如图1所示。语音识别与合成技术已趋于成熟,要实现管制模拟机飞行员席位的自动化,必须克服自然语言理解关键技术问题。陆空通话语法简单,句式简洁,变化单一,基本无歧义,其语言特征大致符合计算语言学等相应要求[2]。机器只需认知理解陆空通话语言,不需对其进行高层的推理,因此相较于常规自然语言的多性、复杂性、歧义性,自然语言理解相关技术在陆空通话这一特殊领域或能取得优异的成绩。
本文从深度学习出发,旨在解决人机对话系统中自然语言理解关键问题,协助语音识别模块实现飞行员席位的自动化,提升管制员培训效果和效率。
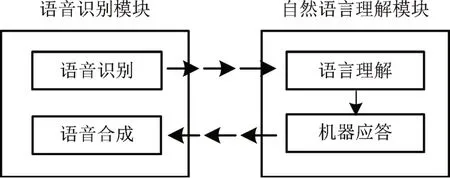
图1 管制员培训计算机处理流程
2 深度学习
目前深度学习已广泛应用于机器翻译、问答系统、信息提取、情感分类、图像识别[3]。人类语言过于复杂,且本身还在不断演化当中。因此语言学家整理出的各种形式逻辑规则作用十分有限。而在例如机器翻译和人机对话的语言预测上,基于统计学方向的深度学习看似简单,却能取得良好效果[4]。总结目前对话系统和机器翻译系统,模型各自得分如表1所示。
Ritter仅采用基于短语的统计机器翻译(Statis⁃tical Machine Translation,SMT)框架[5]。Sordoni使用了上下文敏感的循环神经网络(Recurrent Neu⁃ral Network,RNN)编码器-解码器[6]。Li利用长短期记忆网络(Long Short-Term Memory,LSTM)编码器-解码器框架来强化模型[7]。Lowe使用LSTM对问题和回答进行编码,然后使用两个句向量内积来选择候选答案[8]。Zhou在句子级卷积神经网络(Convolutional Neural Networks,CNN)嵌入之上使用LSTM编码器[9]。
在机器翻译领域,基于SMT框架的模型主要通过匹配源句和目标句中短语的对应概率来进行翻译。Cho在SMT基础上,使用RNN编码器-解码器来学习该翻译概率[10]。Wu完全摒弃了传统的SMT系统,训练了包含8个编码器层和8个解码器层的深度LSTM网络[11]。Gehring提出了一种基于CNN的机器翻译seq2seq学习模型[12]。
机器翻译和聊天机器人的实质就是寻找两个序列之间的对应关系,而管制员和飞行员之间的通话其本质也是一个序列到另一个序列的映射。借助这一思想,通过分析表1目前人机对话和机器翻译领域热门方向,本文选择seq2seq(Sequence to Se⁃quence)框架来构建陆空通话深度学习网络模型,实现输入管制文本指令,即可输出飞行员文本应答。
2.1 seq2seq框架原理
seq2seq,全称Sequence to Sequence,是一种通用的编码器-解码器框架,可用于机器翻译、文本摘要等场景中。2014年Kyunghyun比较了RNN编码器-解码器模型与现有翻译模型各自得分,表明RNN编码器-解码器能很好地学习短语的连续空间表示,捕捉短语表中的规则性,保留了短语的上下文语义和语法结构[13]。其网络构架可以用图2简单说明。

图2 经典seq2seq模型网络架构
编码器(RNN层或其堆叠):是将输入序列xi通过非线性变换编码成一个指定长度的中间向量C,用以表示该输入序列相关信息。解码器(RNN层或其堆叠):根据中间向量C和上阶段生成的单词y1,y2,...,yt-1来生成t时刻要生成的单词yt。

表1 深度学习对话系统和机器翻译模型(BLEU)
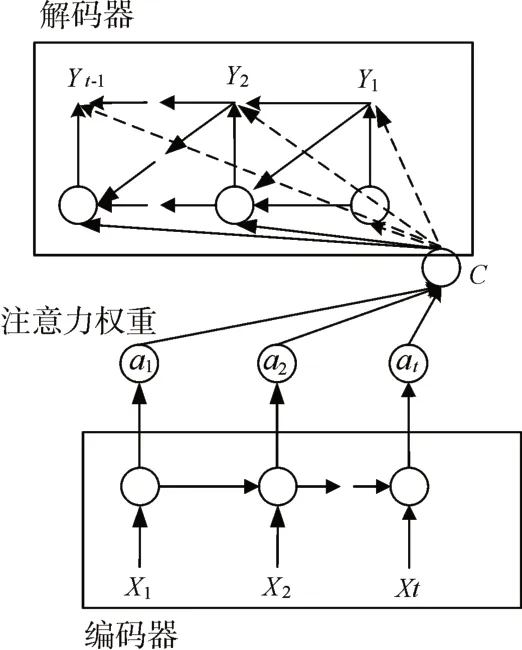
图3 改进seq2seq模型网络架构
1)编码阶段
当前时间的隐藏状态ht由上阶段和当前阶段信息共同决定,f和q为非线性函数。

在获取各阶段隐藏层信息之后,由汇总信息或最后的隐藏层信息来生成语义向量C。

2)解码阶段
该阶段可以看做编码的逆过程。这个阶段,我们根据给定的语义向量C和之前已经生成的输出序列y1,y2,...,yt-1来预测下一个输出的单词yt,即
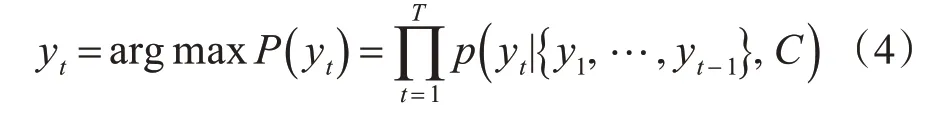
2.2 改进seq2seq模型框架
seq2seq模型框架虽然非常经典,但存在一定局限性,序列信息被编码器压缩进固定长度的中间向量C中,导致语义向量C无法完全表示整个序列的信息,且后输入内容将覆盖稀释之前输入内容所携带的部分信息。由于在一开始解码时未能获取足够序列信息,解码准确率表现欠佳,输入序列越长,这个现象就越严重。为了增加长句的预测准确率,可在seq2seq框架的基础上增加了注意力机制(Attention)。改进seq2seq模型框架在产生输出的时候,会确定输入序列中重点关注的部分,据此来产生下一个输出,提升了文本预测的效果。
改良后模型框架和经典seq2seq框架的不同之处在于中间向量。注意力机制模型中每一个C会自动去选取与当前所要输出的y最合适的上下文信息。其网络构架如图3所示。
ait用以衡量编码时间第i阶段的xi和解码时第t阶段的相关性。最后解码器中第t阶段的上下文信息输入ct就来自于ait和第t阶段隐藏信息的加权和。权重ait计算公式如式(7)。eit是一个对齐模型,用于评估输入t和输出i的匹配程度[14]。

3 陆空通话模型
3.1 数据集创建
模拟真实管制员飞行员用语习惯和对话规则,创建陆空通话数据集。数据集分为训练集和测试集,来源于真实英文陆空通话,涉及飞行进离场阶段航向、速度、高度等指令,包括航班号、导航台、跑道号等信息,共计633529条语句对。训练集主要用于模型训练,测试集主要用于模型评估。为让机器更贴近飞行员真实回答,同时体现数据集中管制指令的统计特征,在训练集中加入常规自然语言,语料来源于康奈尔电影对话语料库中的电影台词[15]。
3.2 模型训练
陆空通话模型训练实验运行环境是Py⁃thon3.6,Windows7操作系统平台。经过迭代训练50000次,直到损失函数趋于稳定,训练结束。

图4 单词权重注意力聚焦图
图4通过可视化等式(6)中的权重ait,提供了一种直观的方式来检查生成的单词与源句中单词之间的对应关系。图中,x轴和y轴分别对应陆空通话源句中的单词(指令)和生成的目标单词(应答)。每个像素以灰度(0:黑色;1:白色)显示第i个目标单词和第t个源单词的对应权重ait,由此我们可以看到在生成目标词时,源句中哪些位置被赋予更多注意力。
3.3 模型评估
损失函数用以评估模型收敛效果,数值越小证明模型训练效果越好。经过50000次训练,损失函数在0.01上下小幅波动,认为模型训练达到最佳状态。在训练模型过程中,随着训练迭代次数增多,损失函数逐渐减小,如图5所示,x轴为迭代次数,y轴为损失函数值。

图5 模型损失函数递减图
本文选择三段真实陆空通话资料用于测试模型准确率,并对比了单纯陆空通话模型和添加电影台词的陆空通话模型各自效果,回答准确率分别如表2所示。图6以统计图的形式可视化了模型1和2各自准确率,以及模型2相对于模型1准确率的增长情况。
结果显示,在当前语料数据的基础上,模型1和模型2对话准确率分别为90.1%、91.3%、90.9%,91.5%、91.7%、91.2%,模型2对话准确率稍微高于模型1,证明本文采用的深度学习方法具有一定有效性和适用性,其次添加电影台词的陆空通话模型更能模拟真实飞行员席位用语习惯。同时经过分析,准确率的下降主要集中在某些语句对学习效果不佳。
随着模型的优化和训练集数据的扩充,准确率将进一步提高,应能较好满足当前管制员训练要求,有效协助语音识别相关技术,基本实现飞行员席位的自动化,提升管制员培训效果,减少人物力成本。
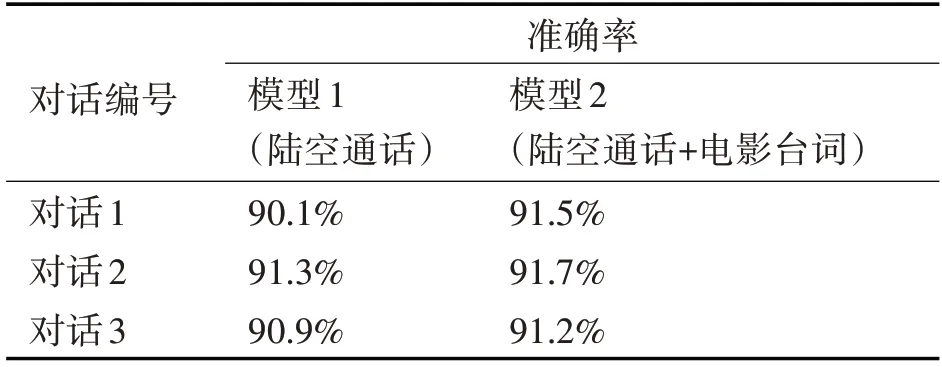
表2 陆空通话模型准确率
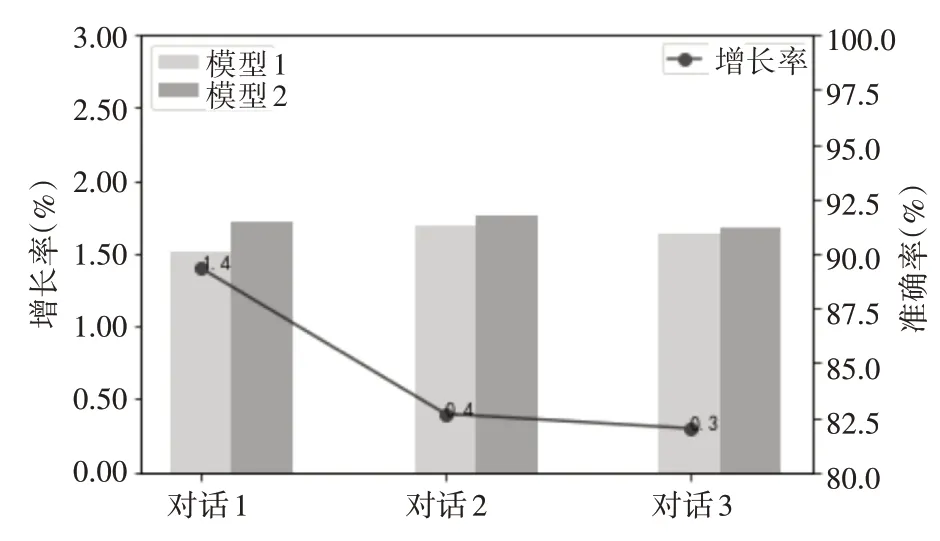
图6 陆空通话模型准确率对比图
4 结语
本文利用基于统计原理的深度学习技术,对进近阶段陆空通话标准用语进行处理与建模,实现了输入管制员本文指令,输出相应的飞行员文本应答。三段真实陆空通话测试结果证实,本文模型具有较高准确率,证明论文方法在陆空通话领域具备实用性和有效性。
真实陆空通话中,飞行员席位具有一定自主性,能主动报告自身情况并提出请求。目前的深度学习模型无法胜任此类自主性语言任务,同时随着训练集数据的扩充,准确率虽能得到提高,但语言复杂度也将提升,因此下一步研究工作的重点将聚焦于语法规则、深度学习、模拟仿真的综合应用。
