基于改进的Faster R-CNN模型的树冠提取研究
2021-03-27黄彦晓方陆明黄思琪高海力杨来邦楼雄伟
黄彦晓,方陆明,黄思琪,高海力,杨来邦,楼雄伟
(1.浙江农林大学 信息工程学院,杭州 311300;2.林业感知技术与智能装备国家林业和草原局重点实验,杭州 311300;3.浙江省林业智能监测与信息技术研究重点实验室,杭州 311300; 4.浙江农林大学 暨阳学院,浙江 诸暨 311800;5.浙江农林大学 林业与生物技术学院,杭州 311300)
树冠是树木进行光合作用和蒸腾作用的重要场所,冠幅是树冠结构的重要特征因子之一,是预测树木生物量、树冠表面积、林分郁闭等的重要变量[1]。因此,在森林资源调查中,对树冠信息的获取具有重要意义。传统的测量冠幅大小的方法,是以实地调查为主[2]。但是这种方法不仅要消耗大量的人力与物力,同时还具有调查周期长、受天气制约、存在人为误差、更新困难等缺陷,不利于森林资源的科学管理和集约化经营[3]。遥感(Remote Sensing,RS)技术的发展,为森林资源调查提供了新的数据获取手段。国内外学者对于树冠信息的获取进行了大量的研究。刘玉锋等[4]利用WorldView-2高空间分辨率卫星遥感数据从林木树冠的空间几何特征出发,通过分析天山云杉林木树冠的形态特征及其在遥感图像上的成像规律,结合多尺度斑点检测和梯度矢量流Snake模型来提取树冠信息;李永亮等[5]基于相邻木特征与对象木冠幅间的复杂关系,以杉木为研究对象,提出了一种基于自适应神经模糊系统的冠幅估算方法;Erfanifard等[6]以0.06m空间分辨率的UltraCam-D航空影像为基础,通过Taguchi方法来优化支持向量机(Support Vector Machines,SVM)分类技术[7]识别树冠,总准确率达到了97.7%;Wu等[8]利用基于图论的局部等高线方法,捕捉森林的拓扑结构,量化树冠的拓扑关系,并通过对地形图识别树冠的类比,对单个树冠进行分割,相比于分水岭与局部最大值算法提高了1.8%~4.5%的精度。
近年来,随着机器学习(Machine Learning,ML)和神经网络的发展,深度学习(Deep Learning,DL)[9]技术慢慢渗入到森林资源调查领域中。本研究以杭州市临安区青山湖绿道中的水杉林为数据源,通过无人机拍摄获得高分辨率的正射影像图,利用基于改进的目标检测(Object Detection)方法Faster R-CNN[10]模型进行树冠提取研究。
1 数据获取与准备
1.1 研究区概况
研究区(30°14′26″~30°14′30″N,119°44′39″~119°44′55″E)位于杭州市临安区内。临安地处浙江省西北部、中亚热带季风气候区南缘,属季风型气候,温暖湿润、光照充足、雨量充沛、四季分明。该研究区的两块样地(图1)都位于青山湖绿道,为水杉纯种林木,树种组成简单,地势平坦,林分郁闭度较高。这两块样地背景复杂,树冠之间存在相连和覆盖的情况,与背景颜色相似,不易区分,且因为拍摄时间已近秋,部分水杉树冠树叶已逐渐开始变黄,同样增加了树冠识别难度。

注(a)为Google卫星地图上两块水杉林的位置,其中红色方框内为样地1,黄色方框内为样地2;(b),(c)分别为无人机拍摄样地1和样地2得到的正射影像图。
1.2 无人机影像数据获取
本研究利用大疆Phantom4 Pro V2.0无人机飞行拍摄进行数据采集,该无人机配备1英寸2 000万像素影像传感器,最大上升速度为6m/s,最大飞行时间为30min。为了无人机成像时光线充足和减少地面阴影影响,选取天气晴朗、无风和太阳照射强度稳定时段进行无人机影像数据获取。无人机飞行时,遥控器前端搭载Pix4Dcapture软件来进行飞行控制。本实验设置的影像重叠率为90%,速度为72km/h。
拍摄得到的无人机摄影数据包含POS数据以及精准的GPS坐标(WGS84),将这些数据导入Agisoft Photo Scan软件中。该软件对导入的影像数据进行处理生成高分辨率正射影像图,主要步骤为:对齐照片、建立密集点云、生成网格、生成高分辨率正射影像图。具体的研究区位置和生成的正射影像图如图1所示。
其中样地1的无人机飞行高度为60m,获得的正射影像图大小为18 181×14 536像素,分辨率为0.012 71m每像素;样地2的无人机飞行高度为50m,获得的正射影像图大小为24 425×15 376像素,分辨率为0.011 55m每像素。由于每张正射影像图的分辨率已知,可以根据图中的像素点测量出每个树冠上的长和宽的实际距离,长宽的平均值就是实际的冠幅大小。
1.3 数据集制作
将样地1的整张正射影像图和样地2正射影像图的一部分进行裁剪作为样本。每张样本的大小为500×500像素左右,并包含若干水杉树冠,共制作256张样本。将样地2的正射影像图中未进行裁剪的部分作为测试集,共112株水杉。
这些样本用LabelImg软件进行人工注释。LabelImg是一个常用的用于深度神经网络训练的数据集注释工具,采用Python编写而成,并使用Qt作为其图形界面。该软件用矩形边框标注出每张样本中的树冠,每张图片标记后的注释以PASCAL VOC格式[11]保存为XML文件,文件内容包含图片的路径、名称、大小以及已标注的所有目标的类别名和边框坐标等信息。目标类别名用树冠的英文单词“CTree”表示,目标边框位置信息用边框的左上角(xmin,ymin)和右下角(xmax,ymax)坐标表示。
2 方法
2.1 Faster R-CNN
Faster R-CNN模型是真正意义上端到端的目标检测模型,最大的改进地方是废除了选择性搜索(Selective Search)[12],引入了区域提取网络(Region Proposal Network,RPN)来提取候选区域(Region Proposal),节省了大部分时间。
Faster R-CNN由RPN和Fast R-CNN[13]这两个模块组成,进行联合训练,总体流程如图2所示,将整张图像输入网络得到相应的特征图,使用RPN结构生成候选框,并投影到特征图上获得相应的特征矩阵,使用感兴趣区域池化(ROI Pooling)将每个特征矩阵映射为相同尺寸的特征向量,最后把特征向量经过全连接层传送给分类器判别属于某一个类,对于属于某一类的边框位置,用回归器进行进一步调整。
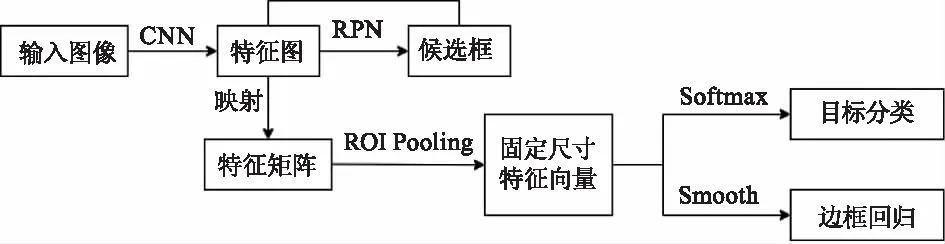
图2 Faster R-CNN算法流程图
2.2 基于Faster R-CNN的改进方法
Faster R-CNN模型的基础网络是VGG16[14],VGG16是由若干卷积层和池化层堆叠而成的,卷积核大小都为3×3的具有16层结构的简单网络。当图像在进行卷积操作时,总会出现信息丢失的情况。本研究采用ResNet101作为基础网络来提取特征。ResNet101采用残差[15]结构解决了网络在加深层次的同时克服了梯度消失等问题。残差结构能将低层的特征图直接映射到高层次的特征图中,建立恒等映射,使前面的信息更多地传递给后面,增加了提取目标特征的深度,保留了更多有效的信息。ResNet101共101层,具体网络结构图如3所示。

图3 Resnet 101网络结构图
特征金字塔网络(Feature Pyramid Network,FPN)[16]是传统CNN网络表达输出图片信息方法的增强,该网络利用特征金字塔在不同层次的特征进行尺度变化后,进行信息融合,从而提取到较为低层的信息,使得小物体的信息也能够比较完整地反映出来。FPN主要有3个步骤:自下向上不同尺度特征图的生成、自上向下的特征增强和横向连接。假设自下向上生成不同层级的卷积结果为Cx,那么中间生成的特征图为Mx,最后融合得到的特征图为Px,三者相互对应。
FPN在Faster R-CNN模型的改进为基于RPN的改进,即将RPN中的尺度分离。在结合ResNet101作为基础网络和融合FPN改进后的Faster R-CNN_Res101_FPN模型的具体结构如图4所示。

图4 基于改进的Faster R-CNN模型结构图
2.3 模型评估
对于模型评估,共有两个方面,即树冠识别和冠幅提取。对于树冠识别,采用分类指标精确率(Precision)、召回率(Recall)和准确率(Accuracy)来衡量;对于冠幅提取,通过与真实的冠幅值比较,可以用回归指标均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2)来表示。
3 实验与结果分析
3.1 数据增强
一般情况下,利用神经网络进行目标检测都需要成千上万的图片来训练,进行调参追求模型损失较低的最佳点,以得到理想的效果。但是现实中所拍摄得到的可标注数据集往往是有限的。因此,为了获得更多的数据,需要对现有的数据集进行微小的改变,这就是数据增强(Data Augmentation)[17]。
常用的数据增强方法有随机裁剪、随机旋转、翻转变换等,但是这些变换只是简单地增加了数据集数量,对提升网络提取树冠特征的影响较小。针对树冠具有单一颜色聚集分布明显,但是内部亮度变化不均衡、大小和形状各不相同的特点,实验利用增大或减小样本亮度和对比度的方法来扩充数据集,同化和增强了树冠的颜色特征。图5以其中一张样本为例,展示了数据增强的效果。

图5 数据增强效果图
3.2 实验步骤
原始的Faster R-CNN模型使用在ImageNet数据集[18]上预训练的VGG16模型作为初始化训练,总共迭代了40 000次,batch size为8,学习率为0.001;改进后的Faster R-CNN_Res101_FPN模型在与FPN融合中,设定P2,P3,P4,P5和P6这5层特征层分别定义不同尺寸的anchor,即32×32,64×64,128×128,256×256和512×512,每个anchor又有1∶1,1∶2和2∶1这3种长宽比例,共15种不同大小的anchor。模型使用在ImageNet数据集上对已经预训练好的ResNet101网络进行训练,batch size设为1,总共迭代了20 000次。前5 000次迭代的学习率为0.001,后5 000次为0.000 01,中间10 000次的学习率则为0.000 1。这两个模型训练的损失函数如图6所示。可以看到,这两个模型分别在20 000次迭代和7 500次迭代后的损失值趋于稳定。

这两个实验均在Windows10系统,Intel(R)Xeon(R)Silver 4110 CPU @ 2.10GHz(32 CPUs),2.1GHz处理器,64GB内存和GPU为NVIDIA GeForce GTX 1080 Ti,11GB显存的计算机配置下实现。实验环境为Python 3.6,Tensorflow[19]1.14.0。
3.3 实验结果与分析
为了更好地展示模型识别树冠的效果,实验将整张样地2的正射影像图输入训练好的模型中进行检测。正射影像图中每个被检测到的树冠用红色边框标注其位置,并显示树冠的编号,根据分辨率计算得出冠幅大小和置信度。图7展示了两个模型检测结果中部分测试集的效果图。通过简单观察可以发现,未改进的Faster R-CNN模型树冠漏识别情况较严重,且对于冠幅大小的提取不如改进后的模型更精确。

两个模型在测试集上各指标值的对比如表1所示。可以看到,改进后的Faster R-CNN_Res101_FPN模型与原来的Faster R-CNN相比,各个指标都得到了提升。其中,精确率、召回率和准确率分别提升了0.06%,5.36%和5.31%,分别达到了99.06%,93.75%和92.92%的水平;均方根误差和平均绝对误差分别降低了0.10和0.04,而决定系数则提高了0.12,3项指标分别达到了0.36,0.27和0.84的水平。结合图8展示的冠幅真实值和两个模型预测值的线性模型图,证明了基于改进的Faster R-CNN模型的优越性。

表1 模型评价指标对比表

4 结论
本研究通过无人机拍摄两个水杉林样地获得的高分辨率正射影像图为数据源,利用原始的Faster R-CNN模型和改进后的Faster R-CNN_Res101_FPN模型进行树冠提取的实验。改进后模型树冠识别的准确率达到了92.92%,冠幅提取的R2达到了0.84,两项指标分别比改进前的模型提高了5.31%和0.12,证明了利用目标检测算法提取树冠的可行性和基于改进的Faster R-CNN模型的优越性。
