基于迁移学习的园艺作物叶部病害识别及应用
2021-03-26江朝晖
李 博,江朝晖,2,谢 军,饶 元,2,张 武,2
(1安徽农业大学信息与计算机学院,合肥230036;2智慧农业技术与装备安徽省重点实验室,合肥230036)
0 引言
受全球气候和环境问题的影响,植物发生的病害愈加复杂,对植物病害进行识别和防治越来越重要[1]。随着计算机技术的发展,深度学习被应用到植物病害识别,其可缩短病害识别时间,极大减轻了农户的工作量。
近年来,越来越多的国内外研究者尝试将卷积神经网络用到植物病害识别上[2-3]。孙俊等[4]提出了改进AlexNet网络对多种植物叶片病害识别方法,识别14种不同植物共26类病害,刘永波等[5]提出了一种在自然环境条件下基于深度卷积神经网络的玉米病害识别方法。DeChant Chad等[6]集成多个卷积神经网络,识别玉米大斑病。为进一步提高植物病害识别准确率,减少模型训练需要的样本量[7],更深层的卷积神经网络和迁移学习[8]被应用到植物病害识别。陈娟等[9]通过改进ResNet,提出了改进残差网络的园林害虫图像识别方法。许景辉等[10]提出基于迁移学习的卷积神经网络玉米病害图像识别方法。
在将植物识别模型运用到实际过程中,杨林楠等[11]设计了甜玉米病虫害的树型图和推理机等,基于Android系统手机的甜玉米病虫害智能诊断系统。然而其在识别病害过程中需要用户手动根据叶、穗、茎、籽等部位特征进行一系列配置,操作不方便。刘洋等[12]提出了将MobileNet移植到智能手机直接在手机端进行植物病害识别,减少了图片上传到网络的时间,对网络依赖性不强。这种方式虽然十分方便,却对用户设备有一定要求,不同设备识别时间不同,同时使用轻量级模型难以满足用户对作物病害高精度识别的需求。
笔者通过对深度学习在作物病害识别方面的研究[13-14],综合考虑模型大小、识别准确率和识别时间,设计分别使用ResNet18、ResNet50和ResNet152模型进行迁移学习训练,然后通过Flask将训练好的园艺作物叶部病害识别模型部署到云服务器上的方案。提供园艺作物叶部病害识别Web服务,旨在尽可能满足农户实际使用过程对病害识别时间和识别准确率的需求,降低病害识别对农户设备要求。
1 材料与方法
1.1 材料
笔者使用的PlantVillage数据集[12]包含14类园艺作物,分别是苹果、蓝莓、樱桃、玉米、葡萄、柑橘、桃、辣椒、马铃薯、树莓、大豆、南瓜、草莓、番茄。其中有26种病害叶片、12种健康叶片,共38个类别的样本图像。根据ResNet的输入尺寸,将图像的大小尺寸调整为224×224像素进行训练和测试。
由于PlantVillage数据集的图像是在实验室中拍摄的,背景很干净。然而实际应用场景图片清晰度可能比较低,为了尽可能提高实际使用过程中园艺作物叶部病害识别的准确率,对PlantVillage数据集里的所有图片,随机使用3种不同的图像处理技术中的1种或者不采取任何处理方式处理。其中3种不同的图像处理技术包括图像伽马校正(Gamma correction)、噪声注入(noise injection)、PCA颜色增强[15](PCA color augmentation)。同时,为解决实际使用中存在检测不到园艺作物叶部的情况,利用爬虫技术在互联网上随机爬取一些作物生长环境图片,并将这些图片标记为无叶片背景标签。
最终实验数据集共61486幅图像,通过统计图片数目以及类别样本的分布情况,随机抽取70%的数据集作为训练集,20%作为验证集,剩余10%作为测试集。为方便模型训练,将数据集中的39类图片按0~38编号(如表1所示)制作为训练标签,每个编号分别代表一类图片。

表1 实验数据集分类
1.2 研究方法
1.2.1 模型选择 使用何凯明等提出的ResNet[16]作为基准模型。ResNet通过在网络中增加恒等映射来解决神经网络中的梯度消失问题,通过配置不同的通道数和模块里的残差块(residual block)[16]数(图1)可以得到不同的ResNet模型。综合考虑网络层数以及计算量,分别使用ResNet18、ResNet50、ResNet152在数据集上进行训练,并对实验结果进行对比分析,结合实际使用情况选择合适的模型。
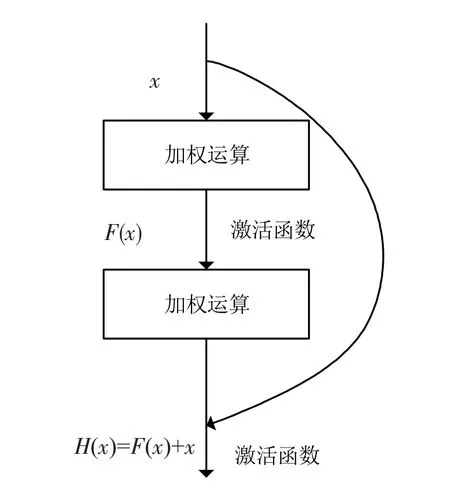
图1 残差模块
1.2.2 迁移学习 迁移学习[17]可以加快网络收敛速度,减少网络训练需要的样本数量和时间。利用迁移学习(transfer learning),将 ResNet18、ResNet50、ResNet152预训练模型从ImageNet数据集学到的通用图像特征迁移到本实验数据集上,实现对园艺作物病害识别。迁移学习常用的方法有特征迁移和模型迁移2种[18]。本研究使用的是模型迁移的方法(表2),重新初始化3个预训练模型最后一层参数,其他层直接使用预训练网络的权重参数并且冻结,然后再利用实验数据集重新训练整个模型。

表2 模型参数
2 结果与分析
实验平台是基于Ubuntu 18.04系统的服务器,硬件配置CPU是Intel(R)Xeon(R)CPU E5-2630 v4@2.20 GHz,GPU是Tesla P100-PCIe 16 G英伟达显卡。软件环境为 CUDA 9.6、CUDNN V7.6.3、Python 3.7、PyTorch 1.4。
2.1 迁移学习训练实验
将实验数据集按照7:2:1的比例分成训练集、验证集和测试集。使用训练集分别对ResNet18、ResNet50、ResNet152进行迁移训练,获得3种分类模型。训练中采用批量训练的方法将训练集、验证集和测试集分为多个批次(batch),每个批次中数据集图片数量(batch size)设为64,训练集和验证集全部图片通过模型作为1个周期(epoch),共迭代100个周期,学习率设置为0.001,模型优化使用Adam[19]优化算法实现。
2.2 评价指标
模型识别的准确率(accuracy)[12]计算如式(1),交叉熵(cross entropy)[20]计算如式(2),交叉熵损失函数[18]计算如式(3)。

式中,Nr是识别正确的预测数,n表示数据集中样本总数。y(i)代表真实的标签概率分布向量表达式,代表预测概率分布向量表达式,向量元素非0即1,yj(i)是向量y(i)的元素,是向量的元素。n为训练集的样本数,θ为模型参数。
2.3 模型训练结果及分析
ResNet18、ResNet50、ResNet152模型训练过程的Loss曲线和准确率变化如图2~3所示。从曲线中可以看出,ResNet152准确率上升与Loss曲线下降速度较快,ResNet50最初准确率上升与Loss曲线下降速度都比ResNet18慢,直到ResNet18曲线逐渐收敛后才开始超过ResNet18。

图2 训练过程Loss曲线

图3 训练过程准确率曲线
表3记录了ResNet18、ResNet50和ResNet152模型在实验数据集上使用迁移学习训练,测得在训练集、验证集和测试集上的准确率。3个模型的训练集准确率均小于测试集的准确率,未出现过拟合和欠拟合现象。随着神经网络层数增加,3个模型在训练集、验证集和测试集上识别准确率逐渐提高。
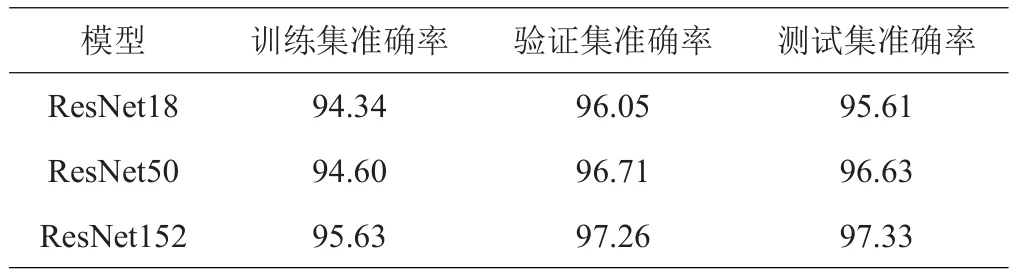
表3 不同模型训练结果 %
3 模型部署
3.1 开发环境的搭建
Flask[21]是Armin Ronacher使用Python编写的一个轻量级Web框架,它之所以被归类为轻量级Web框架,是因为其本身相当于一个内核,不需要特定的工具或库,使用Flask-extension来管理各种扩展[22]。Flask很容易使用,简单几行代码就可以搭建一个稳定Web应用。由于模型训练的代码同样使用Python编写,所以安装好Flask后可以直接使用模型训练过程的软件环境部署训练好的模型,降低了模型部署的难度。
笔者在Linux操作系统下进行开发,硬件配置CPU和GPU与模型训练一样。软件环境在模型训练过程中使用的软件环境基础上,通过Python的包安装程序pip安装Flask,然后创建code和models文件夹分别保存源代码和训练好的3个模型。开发IDE使用微软开发的免费跨平台编辑器Visual Studio Code,通过安装扩展支持不同的编程语言开发。
3.2 3种识别模式设计
训练好的ResNet18、ResNet50、ResNet152的模型大小分别是43.3、92.0、224.6 MB。在GPU上测试结果表明模型加载时间分别是48.2、81.3、160 ms,识别单张图像的时间分别是10.9、17.9、33.7 ms。综合考虑模型大小、识别准确率及识别时间对识别结果的影响设计了快速、标准和准确3种识别模式,3种识别模式分别使用训练好的ResNet18、ResNet50、ResNet152模型。
其中快速模式由于识别时间最快可以最快得到结果,适合网络速度慢时使用;准确模式识别精确度最高,适合网络速度快时使用;标准模式平衡了识别精确度和识别时间是默认识别模式。农户可根据实际使用过程中的网络情况选择相应的识别模式,减少网络对应用的影响。
3.3 基于Flask的园艺作物病害叶部识别网页应用开发
应用开发的软件是Visual Studio Code,分为前端和后端开发。前端使用HTML和JavaScript编写,由于PyTorch训练模型的代码和Flask开发网页后台的代码同样使用Python编写,因此后端使用Python编写,降低了开发难度,程序工作流程图如图4所示。
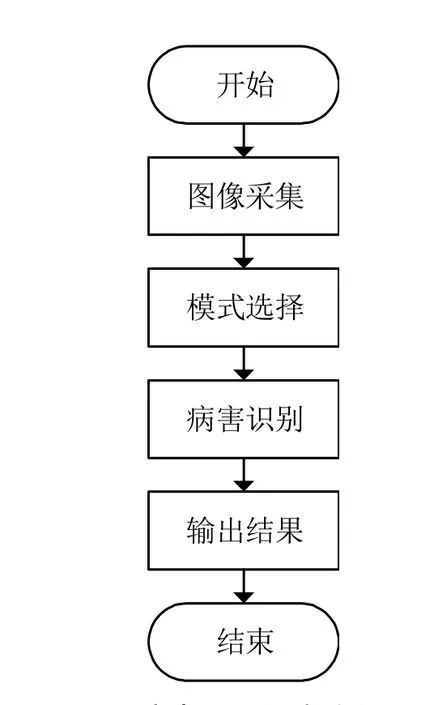
图4 病害识别程序流程图
园艺作物病害识别网页应用案例如图5所示,分别有选择图片按钮、模式选择3个复选框和识别按钮。用手机或者数码相机采集属于PlantVillage数据集中的14类园艺作物叶部病害图像,点击选择图片并且选择采集的图片;根据实际使用中网络速度和对准确率的需求选择相应的识别模式;然后点击识别按钮后,自动将图片压缩成WebP格式[23-24]再上传到服务器上,并对图片进行处理,包括将图像的大小尺寸调整为224×224像素、图像滤波等操作;然后在服务器端利用GPU加速[25]模型推理,最后输出识别结果并且显示在网页上。

图5 病害识别网页应用例子
4 结论
笔者对PlantVillage数据集进行预处理和扩充得到实验数据集,分别使用ResNet18、ResNet50和ResNet152 3种预训练模型在实验数据集上进行迁移学习训练,得到3种园艺作物叶部病害识别模型,设计快速、标准和准确3种识别模式,并开发园艺作物叶部病害识别网页应用,可识别14类园艺作物的26种叶部病害。
(1)不同深度模型大小、识别准确率、识别时间不同,将深度模型部署到实际生产中应综合考虑模型特点和用户期望。
(2)3种预训练模型对原始的PlantVillage数据集进行迁移学习训练,平均识别准确率分别是95.50%、96.06%、96.68%,经过预处理的数据集上训练的模型具有更高的精度,同时在PlantVillage数据集原有分类基础上增加了无叶片背景的分类,在实际使用过程具有更高的鲁棒性。
(3)园艺作物叶部病害识别在服务器端进行,基于Flask框架开发的Web应用具有很好的稳定性,可满足多个用户同时使用,对用户设备要求较低,无需安装额外应用,简单易用。
5 讨论
笔者结合农户实际使用情况,通过对原始的PlantVillage数据集进行数据增强,使用多个模型作为预训练模型进行迁移学习训练,得到不同的园艺作物病害识别模型,解决病害训练样本不足的问题[5]。综合比较模型大小、识别准确率和识别时间设计了快速、标准和准确3种病害识别模式,提供了病害识别Web服务。满足实际使用过程农户对病害识别时间和识别准确率的需求,降低了病害识别对农户设备要求[12],为农户提供更加方便、精确和廉价地园艺作物叶部病害识别服务。但是由于PlantVillage数据集提供的园艺作物种类以及病害种类有限,很多病害还无法识别,同时作物在不同生长阶段病害呈现的特征也不同,因此还需要进一步补充数据集,这也是笔者后期研究工作的重点。
