基于近红外光谱的大豆茎秆化学组分含量检测模型构建与应用
2021-03-25李佳佳洪慧龙万明月储丽赵敬会汪明华徐志鹏张阴黄志平张文明王晓波邱丽娟
李佳佳,洪慧龙,万明月,储丽,赵敬会,汪明华,徐志鹏,张阴,黄志平,张文明,王晓波,邱丽娟
基于近红外光谱的大豆茎秆化学组分含量检测模型构建与应用
李佳佳1,洪慧龙2,万明月1,储丽1,赵敬会1,汪明华1,徐志鹏1,张阴1,黄志平3,张文明1,王晓波1,邱丽娟2
1安徽农业大学农学院,合肥 230036;2中国农业科学院作物科学研究所/农业部作物基因资源与遗传改良重大科学工程/农业部作物基因资源与种质创制重点实验室,北京 100081;3农作物品质改良安徽省重点实验室,合肥 230001
【】大豆茎秆化学组分(纤维素、半纤维素、木质素和粗纤维等)与其茎秆抗倒伏能力密切相关,但由于目前大豆茎秆化学组分检测多采用传统的化学分析技术,测定过程操作复杂、耗时耗力、成本昂贵且易造成环境污染,不适合大规模育种应用,因此,通过构建一套低成本、快速、科学、无污染的大豆茎秆化学组分检测方法,为大豆种质资源茎秆组分分布规律及其与大豆生长习性和倒伏性关系的研究提供方法基础。通过建立一套基于近红外光谱检测技术的大豆茎秆化学组分检测模型,并利用该模型对大豆种质资源茎秆中的中性洗涤纤维(neutral detergent fiber,NDF)、酸性洗涤纤维(acid detergent fiber,ADF)和粗纤维(crude fiber,CF)等化学组分进行检测分析,通过方差分析、多重比较和小提琴图分析,明确大豆茎秆CF含量与其生长习性及抗倒伏性之间的内在关系。基于构建的大豆茎秆化学组分近红外光谱快速检测模型对茎秆NDF、ADF和CF组分检测数值的校正相关系数(RC)均在0.90以上。利用16份模型外大豆茎秆样本对模型的有效性进行验证发现,常规化学检测与该模型检测结果之间无显著性差异(>0.05)。利用该模型对2017年和2018年种植的393份大豆茎秆CF含量及其生长习性之间的关系进行分析,结果表明,大豆茎秆CF含量符合正态分布规律,在CF含量50.00%以上的材料中,2年数据均表现出直立型(91.67%和86.14%)显著高于蔓生型(8.33%和13.86%),表明大豆茎秆CF含量与其生长习性呈极显著正相关(<0.01)。构建的近红外光谱模型具有低成本、快速高效、无污染的特点。此外,茎秆中CF含量高的大豆品种植株具有更强的抗弯曲度,可作为大豆抗倒伏育种亲本筛选的重要指标。
大豆;茎秆化学组分;近红外光谱检测定标模型;生长习性;抗倒伏育种
0 引言
【研究意义】近年来,茎秆倒伏在中国大豆不同种植生态区内均有发生,不仅严重影响了大豆产量和品质的稳定优质发展,还对其机械化作业带来了不利影响,明显阻碍了中国大豆产业化进程[1]。因此,深入研究大豆茎秆理化特性与其生长习性之间的关系,不仅为了解大豆倒伏与茎秆机械强度及理化特性关系提供一定的理论信息,还对当前中国大豆抗倒伏育种和机械化产业发展具有重要的实际意义。【前人研究进展】大量研究结果表明,影响作物倒伏与茎秆机械强度的因素很多且复杂,其中,作物茎秆化学组分(粗纤维、纤维素、木质素、半纤维素等)与其茎秆抗倒伏能力密切相关。粗纤维是指不能被稀酸稀碱所溶解,亦很难被人体或动物所消化利用的有机物质,主要成分包括纤维素,残留的半纤维素和木质素[2]。纤维素、半纤维素及木质素共存于作物茎秆纤维原料中形成复杂的结构,可以增强作物茎秆的抗折力和抗倒伏力[3]。已有研究表明,作物茎秆粗纤维含量与其抗折力、茎秆充实度和抗倒伏性等均表现出显著性正相关[4-7]。水稻茎秆力学性能研究结果表明,水稻茎秆力学性能与其茎秆细胞壁中纤维素的相对含量成正比[8]。水稻单茎抗推力与粗纤维含量、硅含量以及其他相关因素呈显著正相关,说明茎秆中粗纤维含量越高,茎秆的充实度越好,其植株抗倒能力则越强[6]。陈晓光等[9]测定了抗倒性不同的6个小麦品种茎秆的木质素含量,结果表明,木质素含量高的品种茎秆折断力大。油菜中,粗纤维含量与茎秆抗折力、株高等呈显著正相关,木质素含量和粗纤维含量在抗倒伏材料和不抗倒材料间存在显著性差异,该指标可以为高产育种中选育抗倒伏性状新品种提供重要参考[4-5,10]。玉米的节间机械强度形成与其纤维素、木质素和半纤维素等结构性碳水化合物关系密切,其茎秆纤维素含量与茎秆强度呈正相关[7,11-12]。套作大豆茎秆木质素含量与实际倒伏率呈显著负相关(=-0.969);与抗折力和抗倒伏指数显著正相关(=0.958,=0.959),说明较高的茎秆木质素含量可能是提高套作大豆抗倒伏能力的生理基础[13]。此外,程颖颖[14]在大豆秸秆饲用品质性状的研究中发现,株高、茎粗与粗纤维含量均呈显著性正相关,基础高粗纤维素含量数据可以快速选择出茎秆粗壮、直立型大豆品种,达到抗倒伏和抵御恶劣环境条件的目的。由于时间和成本等原因,目前,国内外以茎秆为原料的生物质能产业中几乎不会在茎秆转换前进行茎秆化学组分的测定。当前,常使用传统的化学方法对农作物茎秆化学组分进行测定,例如Van Soset(范式法),其测定过程复杂,耗时费力(一般历时38 h),可能还会导致半纤维素的测定含量偏大[15];此外还有王玉万法[16-17]和高效液相色谱法[18]等,该类化学方法具有应用范围广、灵敏度高、仪器成本适中的优点,但同时具有操作复杂、费时费力、破坏样品、污染环境等缺点。近年来,基于近红外光谱技术的农作物化学组分检测分析越来越普遍。近红外光谱技术可以实现快速、低成本、绿色无污染测量茎秆组分,该方法需要在前期工作中进行大量采集、标定、模型建立等基本工作,模型建立后,对未知样品测定只需通过所建模型解析搜集到的光谱,在1 min内就可得到所要测定样本化学组分的数值[19-20]。Liu等[21]使用傅里叶变换红外光谱仪,选取玉米秸秆和柳枝为样品,对不同种类聚糖、木质素和灰烬进行检测,并与传统化学方法进行对比分析,证明了利用近红外光谱技术结合化学计量学构造模型可以对生物质的化学成分进行分析,并具有很高的精度,是一种切实可行并且前景广泛的方法。Schwab等[22]利用近红外光谱技术分析了玉米杂交种秸秆青贮样本中能值和产奶率相关性。赵峰等[23]利用近红外光谱分析方法,构建了武夷岩茶的茶多酚、粗纤维、水分等品质测定模型并加以应用。基于近红外光谱技术,Xu等[24]利用281份玉米秸秆样品建立定标模型获得了玉米秸秆中干物质、淀粉、糖分含量及消化率情况,结果表明这种方法可以快速、大量、及时测定玉米秸秆品质性状。此外,根据近红外光谱分析技术还建立了玉米秸秆成分定量分析模型,并基于该模型实现了玉米秸秆粗蛋白和半纤维素含量的快速测定[25]。王翠秀等[26]利用近红外光谱技术构建了大豆籽粒蛋白质、脂肪含量的快速、无损检测最佳模型,实现了大豆油脂和蛋白质含量快速无损检测,对大豆品质评估以及作物改良具有重要意义。相较于传统的检测技术,基于近红外光谱技术能够实现大豆茎秆化学组分的科学性、快速、低成本和绿色无污染检测分析[27-28],并有助于加速解析大豆茎秆理化特性与其抗倒伏性和生长习性之间的关系,为大豆抗倒伏育种和机械化产业发展提供理论基础。【本研究切入点】相较于传统的检测技术,基于近红外光谱技术的大豆茎秆化学组分检测分析具有独特的技术优势,然而,目前利用近红外光谱技术对大豆茎秆化学组分含量进行快速、高效、绿色检测分析的相关研究鲜见报道。【拟解决的关键问题】为了更快速、科学地评价大豆茎秆化学组分与其生长习性(直立型、半直立型、蔓生型和半蔓生型)[29]之间的关系,本研究基于近红外光谱检测技术利用135份大豆重组自交系(RIL)构建了一套低成本、快速、绿色的大豆茎秆化学组分检测模型,并根据该模型对2017年和2018年大豆茎秆资源粗纤维组分含量进行了快速检测分析,明确大豆茎秆粗纤维含量与其生长习性及抗倒伏性之间的内在关系,旨在为更好地利用大豆茎秆组分及理想株型育种、抗倒伏育种以及大豆机械化产业发展提供理论基础。
1 材料与方法
1.1 供试材料
135份(中黄35×十胜长叶)RILs群体后代2015年夏种植于中国农业科学院顺义基地(北京)用于模型构建。共有的393份精准鉴定大豆种质资源分别于2017年和2018年夏种植于安徽农业大学高新技术产业园试验站(合肥)(随机区组设计,3 m行长,行距0.4 m),用于模型验证和应用。上述所有材料均于成熟后正常收获,考种后保留大豆整株茎秆,备用。
1.2 样品处理
利用茎秆切片机(KQS-400型,北京锟捷玉诚设备有限公司)对晾晒干后的大豆整株茎秆进行切片处理。利用植物茎秆粉碎机(FSD-100A型,杭州绿博仪器有限公司)将切成片状的茎秆组织打磨成粉末状并通过18目筛,标记后装袋备用。近红外光谱技术检测时,取茎秆粉末(约35 g)平铺于器皿中,表面压平,覆盖完整,每个样品都采用重复装样2次,重复测定2次,取平均值。
空间调制系统的ML检测算法中,hlx需要4Nr次实数乘法,计算矢量的范数需要2Nr次实数乘法,由于ML检测要搜索所有的天线和符号,因此ML检测的计算复杂度为CML= 6MNtNr[13].
1.3 模型构建
1.3.1 大豆茎秆中性洗涤纤维、酸性洗涤纤维和粗纤维含量的化学测定 利用国家标准体系GB/T20806- 2006[30]和GB/T20805-2006[31]分别测定中性洗涤纤维(neutral detergent fiber,NDF)和酸性洗涤纤维(acid detergent fiber,ADF)的化学值含量。每个试样测定2次,取平均值。具体方法如下:
实践教育基地建设是不仅将学校资源与企业资源相融合,充分发挥各自的优势,每一个需要,合作是双赢的,也是符合我们学校建立“三位一体”人才培养模式,即:“学校,企业,研究机构”三位一体的教育主题?“,“常识科,专业课程,职业课程”Trinity课程体系,“学习,使用和创造”三位一体的培训方法。这种方法在促进学校,教师,学生和企业方面发挥了积极作用。“教学与学习紧密结合,理论与实践紧密结合,学校与企业紧密结合”教育模式积极适应并大力发展人才就业市场,创造本土应用型创新型人才模范。
(1)中性、酸性洗涤及水解:称取1.00 g样品放入长筒烧杯中,同时融入150 mL中性洗涤剂和10滴十氢化萘及0.50 g无水Na2SO4,并将烧杯置于熔炉上,持续进行加热,保持沸状态15 min,并持续保持微沸40 min。
(4)中秋节,将近正午的光景,在北平曾家旧宅的小花厅里,一切都还是静幽幽的,屋内悄无一人,只听见靠右墙长条案上一架方棱棱的古老苏钟迟缓低郁地迈着他“嘀塔嘀嗒”的衰弱的步子,屋外,主人蓄养的白鸽成群地在云霄里盘旋,时而随着秋风吹下一片冷冷的鸽哨响,异常嘹亮悦耳,这银笛一般的天上音乐使久羁在暗屋里的病人也不禁抬起头来望望:从后面大花厅一排明净的敞窗望过去,正有三两朵白云悠然浮过蔚蓝的天空。
(2)过滤:溶液沸腾40 min后将烧杯中溶液导入玻璃坩埚,采用绝缘锡纸进行过滤,同时移入所有残渣,并用沸水冲洗坩埚与固体残留物,不断进行滴定直至参与滤液pH接近0。酸性过滤方法:用少量丙酮冲洗残渣至抽下的丙酮液呈无色为止,并抽净丙酮。
实际上,甘肃道地中藏医药产业的发展基础较好,部分产地企业已经具有医药基础研究和医药专利,但专利自用率不高,专利闲置较多,专利发展规划缺乏[13],这更加证明,以高投入、高风险、高回报、研发周期长为特征的生物医药产业,必须向经济相对发达和专业智力密集的地区聚集,而兰州生物医药产业基地的发展确实有条件担当这一使命。因此,一方面要充分利用甘肃道地中、藏医药资源优势,以好药材保证好药品;另一方面要进一步增强与国内外知名医药企业和研究机构的联合协作,在区域性大尺度空间逐步形成从道地中、藏医药资源产地到医药产品市场的覆盖全产业链的广泛联动发展网络。
根据公式(1)和(2)分别求出NDF和ADF含量:
NDF(%)=(M1-M2)/M×100% (1)
式中,M1为玻璃坩埚和NDF的质量(g);M2为玻璃坩埚的质量(g);M为样品的质量(g)。
ADF(%)=(m1-m2)/m×100% (2)
1.3.4 光谱预处理 为避免样品装样量不一致对待测样品近红外光谱预测准确度的影响,采用卷积平滑求导法(savitzky-golay,SG)和一阶导数(first derivative,FD)[34]对近红外光谱进行预处理以提高近红外分析的预测准确度。
对仿真后获得的光照度数据进行处理,可得到三角形LED阵列的照度均匀度分别为74.7%、83.3%和77.3%,这一结果表明粒子群算法对三角形LED阵列优化后的均匀度较高,可提高6.0%~8.6%。
(4)将150 mL硫酸倾注在样品上,使其沸腾,并保持沸腾状态30 min。转动烧杯使其受热均匀,加入数滴防泡剂。
(1)试料:称取1.00 g大豆茎秆粉末,移至烧杯(W1)。
(2)除去碳酸盐:将100 mL盐酸倾注在试料上,连续振摇5 min,小心地将混合物倾入滤埚,滤埚底部覆盖一层滤器辅料。用100 mL水洗涤2次,洗涤干净。将滤埚内容物转移至原来的烧杯中。
(3)酸消煮。
基于国家标准体系GB/T6434-2006[32]测定粗纤维(crude fiber,CF)的化学值含量,其中部分步骤稍作改进。每个试样测定2次,取平均值。具体方法如下:
(5)第一次过滤:在滤埚中铺一层滤器辅料,当消煮结束时将液体通过一个搅拌棒过滤至滤埚中,用真空抽滤,使150 mL几乎全部通过。用搅拌棒移去覆盖在滤器辅料上的粗纤维。残渣用10 mL热水洗涤5次,要注意使滤埚的过滤板始终有滤器辅料覆盖,使得粗纤维不接触滤板。停止抽真空,加一定体积的丙酮,刚好能覆盖残渣,静置数分钟后,慢慢抽滤排出丙酮,继续抽真空,使空气通过残渣,使之干燥。
(6)脱脂:在冷提取装置中,在真空条件下,试样用石油醚脱脂3次,每次用石油醚30 mL,每次洗涤后抽吸干燥。
(7)碱消煮:将残渣定量转移至酸消煮用的同一烧杯中。加入150 mL氢氧化钾溶液,使其沸腾,保持沸腾状态30 min,在沸腾期间用一适当的冷却装置使溶液体积保持恒定。
(8)第二次过滤:在滤埚中铺一层滤器辅料,残渣用热水洗至中性。在真空条件下用30 mL丙酮洗涤3次,每次洗涤后抽吸干燥残渣。
1.3.2 光谱的采集 采用DA7200近红外光谱分析仪(DA7200,波通仪器,瑞典)对所有大豆茎秆样品进行近红外光谱扫描。茎秆样品为固体粉末,测样方式选择为漫反射,光谱扫描范围为950—1 650 nm,光斑直径为3.5 cm,分辨率为5 nm,环境温度控制在室温25℃左右,检测器采用铟镓砷二极管阵列检测器,光栅为镀金全息固定光栅,扫描次数为100次/s。将每个大豆茎秆样品平铺于器皿中,表面压平,覆盖完整。每个样品都采用重复装样2次和扫描2次的光谱收集方式,取平均值作为大豆反射率,得到最终的大豆反射光谱数据。
2.1.2 样品采集制备及标定 样品的采集是否具有代表性直接影响所建立校正模型的精度和稳定性。采集的样品是否具有正态分布是一个非常重要的指标,因此,首先对样品进行正态分析,结果显示,布尔变量H=0,表示不拒绝零假设,说明提出的假设“ADF含量均值为40.59%,NDF含量均值为63.12%,CF含量均值为47.08%”是合理的(表1)。ADF指标95%置信区间为[39.96,41.23],NDF指标95%置信区间为[62.46,63.77],CF指标95%置信区间[46.42,47.74],完全包括均值且精度很高,各组分含量符合正态分布。
实验组行4C延续性护理管理法。①创建专业化的护理小组:由护士长与护理工作人员组成专业化的护理小组,对患者进行健康知识的教育。②4C延续性护理:应遵循全面性的工作原则,在出院之前综合评估生理特点与健康情况,为其编制个性化的护理方案,指导患者及其家属掌握自我护理技巧[2]。还需保证护理工作的合作性,创建微信平台与患者之间相互联系,建立电子档案,使得家属密切配合,在协助监督的情况下改进问题。应遵循协调性的原则,相互协调密切的配合。另外还需进行延续性的护理,在出院之后的第二周到第四周进行家庭随访。第二个月到第六个月进行电话随访,每三周到家庭随访一次,掌握患者情况针对性护理[3]。
根据公式(3)求出CF含量:
CF(g·kg-1)=(W2-W3)/W1 (3)
式中,CF含量以每千克(g·kg-1)表示;W1:样品的质量(g);W2:灰化盘、滤埚以及在130℃干燥后获得的残渣的质量(mg);W3:灰化盘、滤埚以及在500℃灰化后获得的残渣的质量(mg)。
美方语料使用位移动词和指向动词臆造历史事实,描述中方“窃取美方知识产权,强制转移美方技术成果”的行为(如例[4]),目的是为其发动贸易战的无理行为寻求借口,并用标记影响的行为动词在话语中构建这些臆造事实产生的危害(如例[5]),企图给民众造成恐慌:
(9)干燥:将滤埚置于灰化皿中,灰化皿及其内容物在130℃干燥箱中干燥2 h。在灰化过程中,将坩埚置于灰化皿中。滤埚和灰化皿在干燥器中冷却,从干燥器中取出后,立即对滤埚和灰化皿进行称量W2,精确至0.10 mg。
新时代统一战线的战略定位与发展图景——从“爱国统一战线”到“中华民族伟大复兴统一战线” …………………… 林华山(1·19)
1.3.3 异常样品剔除 在近红外光谱分析建模过程中通常会出现2种异常样品:第一类是含有极端组成的样品,通常称为高杠杆值样品,这些样品对回归结果有强烈的影响。第二类是指参考数据与预测值在统计意义上有差异的校正样品。预测过程异常样品的识别主要是用来检验待测样品是否在所建立校正模型的覆盖范围内,以确保其预测结果的准确性。本研究使用X-Y残差剔除的方法[33]。
式中,m1为玻璃坩埚和ADF的质量(g);m2为玻璃坩埚的质量(g);m为样品的质量(g)。
1.3.5 定标模型构建 采用偏最小二乘法(partial least square,PLS)[34]对经过预处理的光谱数据进行回归分析,并利用SimplicityTM软件和The Unscramber X 10.3软件建模[35]。以RC(校正相关系数)、RCV(交互验证相关系数)、RMSECV(交互验证预测标准偏差)、RMSEC(校正相关系数标准偏差)作为衡量模型预测效果的主要参数[35]。其中,RC取值范围为0—1,越接近于1表明模型准确度越高;RCV越高且RMSECV和RMSEC越低,预测能力越强,表明模型精确度越高。
1.4 建模效果验证与评价
随机选取16份未知ADF、NDF和CF含量的待测样品,分别用国家标准体系GB/T20805-2006[31]、GB/T20806-2006[30]和GB/T6434-2006[32]等常规化学检测方法测定其化学值含量,与利用所建立模型检测结果进行比较分析,比较二者之间相关系数(R值)和预测标准偏差(RMSEP)的差异,判断模型的外部验证和准确度。
1.5 模型应用
将所构建的大豆茎秆化学组分快速检测模型导入DA7200型近红外成分测定仪,对2017年和2018年共有的393份大豆种质资源茎秆化学组分进行检测分析。测定步骤为:取大豆茎秆样品粉末,放入近红外仪器样品盘中,使样品自然填满样品盘,自然摊平,每一种大豆茎秆粉末样品为避免人工操作的不稳定性和多次重复扫描的方式以减少样品的不均匀性带来的影响,为了收集到更多的样品信息,都采用扫描2次和重复装样2次取平均值的光谱收集方式。测定结果包括6个数值,分别为ADF、NDF、木质素、纤维素、半纤维素和CF含量。大豆生长习性调查参考邱丽娟等[29]方法。本研究重点解析了大豆茎秆组分CF含量与其生长习性之间的相关性。
斯沃琪集团一走,巴塞尔还要靠这些大品牌撑场面。Benjamin Clymer认为,很多大品牌还将继续参加巴塞尔表展,媒体、零售商和收藏家也还是会来。
1.6 数据统计及分析
利用Microsoft Excel 2007对试验数据进行整理、统计与分析,利用SimplicityTM软件和The Unscramber X 10.3软件建模,利用SPSS 19.0软件对预处理光谱进行回归分析、对测试数据方差分析、LSD法多重比较以及利用R进行小提琴图分析,检验CF含量与大豆生长习性之间的差异显著性(=0.01,=0.05)。
2 结果
2.1 模型构建
2.1.1 大豆茎秆组分测试样品的化学值分析 135份大豆RILs群体茎秆化学组分化学值分析结果显示,其各组分含量分布均匀(电子附表1)。其中,ADF含量主要分布于36.00%—44.00%,均值为40.59%;NDF含量主要分布在59.00%—65.00%,均值为63.12%;CF含量主要分布于44.00%—50.00%,均值为47.08%(表1和图1)。上述结果表明,群体内不同株系大豆茎秆化学组分含量存在明显差异,这对于定量分析作物茎秆成分,实现生物燃料产量及配置都具有重要意义。
(10)灰化:将滤埚和灰化皿置于马福炉中,其内容物在500℃左右下灰化,直至冷却后称量。每次灰化后,让滤埚和灰化皿初步冷却,置于干燥器,使其完全冷却,然后称量(W3)。
2.1.3 原始光谱与光谱数据预处理方法的结果比较 大豆茎秆ADF、NDF和CF有C-H、O-H等含氢基团,因此,近红外光谱区域对此会有强烈的吸收。图2-A显示,光谱扫描范围为950—1 650 nm时大豆秸秆的近红外光谱具有基本相同的变化趋势,又具有明显的吸收峰,主要是由于不同测试样品的吸收强度不同,即大豆茎秆ADF、NDF和CF含量不同,结果说明,大豆茎秆ADF、NDF和CF的近红外光谱可以作为其含量的定量分析依据。同时,利用FD+SG预处理,能够减弱或消除背景噪音、消除基线漂移、克服谱带重叠、增强差别,突出光谱特征,对原始光谱进行平滑和求导,可以有效提高所建模型的光谱分辨率和灵敏度(图2-B)。本研究中,通过异常样品剔除方法得到剩余的131份大豆茎秆样品,选择交互验证(cross validation)来进行验证。结果显示,大豆茎秆ADF、NDF和CF的RC较高,分别为0.9408、0.9093和0.9185,均在0.9000以上;RCV分别为0.8010、0.8614和0.8257;预测标准偏差(RMSEP)分别为1.337、1.454和1.381(图3),说明所建立的大豆茎秆化学组分近红外光谱检测模型预测值与常规化学方法获得的真值之间的误差较小,结果表明,通过FD+SG预处理后大豆茎秆化学组分近红外光谱检测模型预测结果准确度高。

表1 大豆茎秆酸性洗涤纤维、中性洗涤纤维和粗纤维含量的方差分析和正态分布结果
ADF:酸性洗涤纤维;NDF:中性洗涤纤维;CF:粗纤维。下同
ADF: Acid detergent fiber; NDF: Neutral detergent fiber; CF: Crude fiber. The same as below
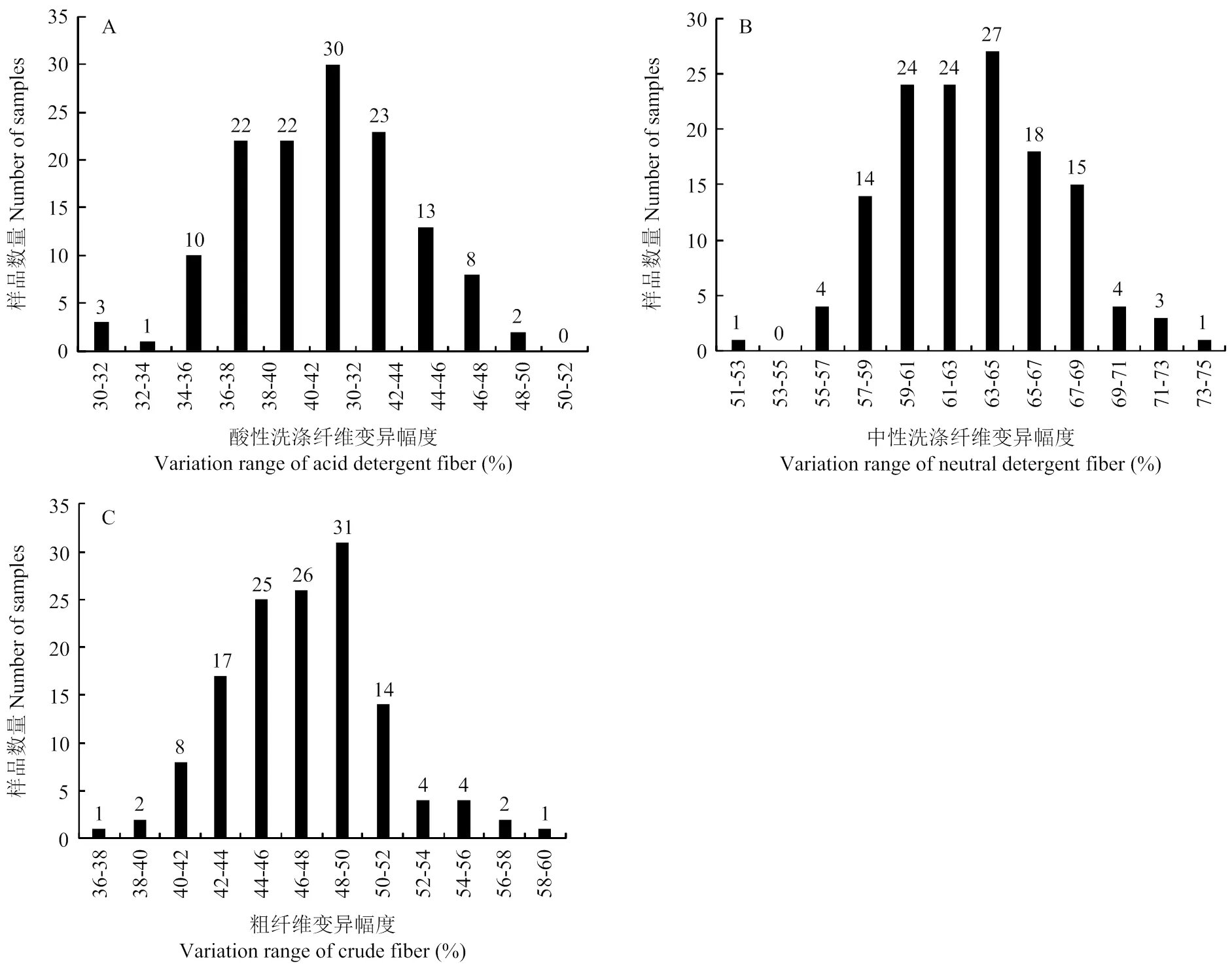
图1 大豆茎秆酸性洗涤纤维(ADF)、中性洗涤纤维(NDF)和粗纤维(CF)的变异频数图
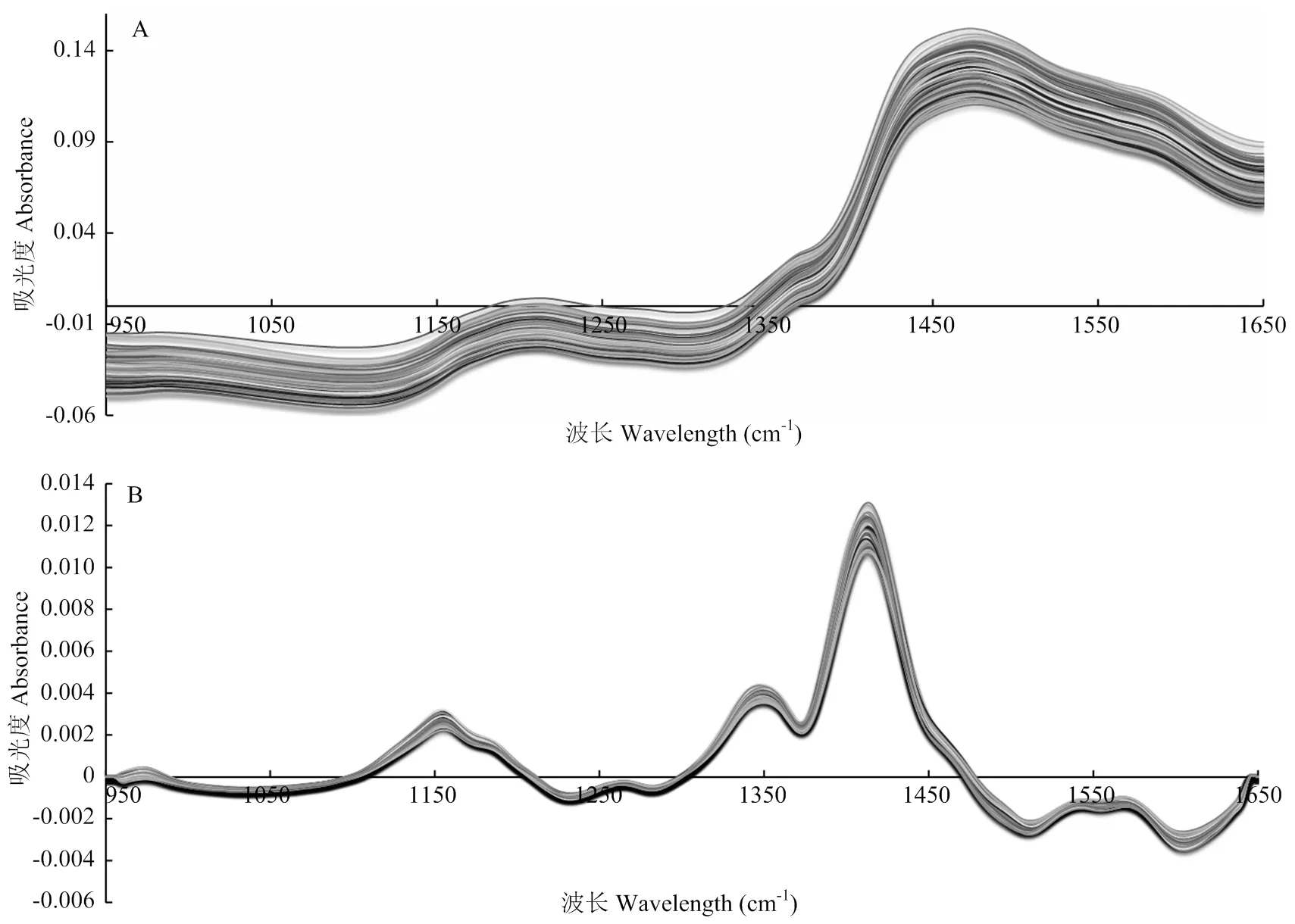
A:测试样品原始近红外光谱;B:FD+SG法处理的光谱图 A: Original near infrared spectrum of test sample; B: Processing spectrogram FD+SG method
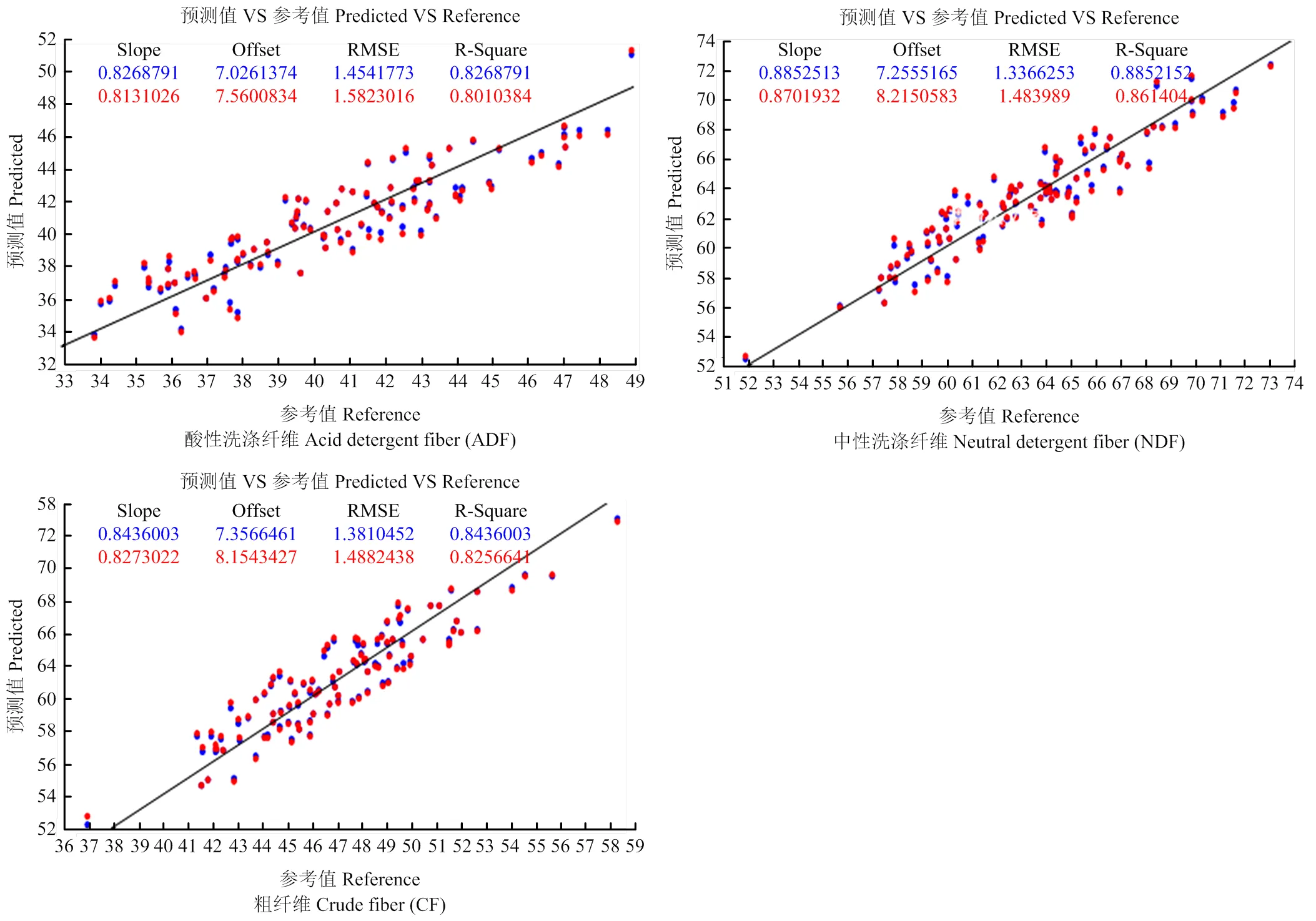
图3 大豆茎秆酸性洗涤纤维(ADF)、中性洗涤纤维(NDF)和粗纤维(CF)含量近红外校正模型参数
2.1.4 大豆茎秆组分含量近红外定标模型的建立 根据预处理后的光谱,采用偏最小二乘法(PLS)建立定标模型,获得了相关系数高和预测误差小的定标模型。131份大豆茎秆ADF、NDF和CF含量的化学测定值范围分别为30.27%—51.15%、51.91%—73.08%和36.98%—58.31%,构建的定标预测模型基本涵盖了大豆秸秆ADF、NDF和CF含量的范围,分布十分均匀(表1和图3)。因此,本定标模型针对ADF、NDF和CF含量适用的线性范围分别为30.00%—49.00%、51.00%—74.00%和36.00%—59.00%。
2.2 大豆茎秆化学组分含量近红外光谱定标模型的验证
随机选取16份未知样品进行平行试验,分别用常规化学测定方法和本研究建立的模型检测大豆茎秆ADF、NDF和CF含量值,以检验模型的精度。结果显示,大豆茎秆ADF、NDF和CF常规化学值和模型预测值统计分析之间的残差不超过2.87(表2),具有良好的相关性,相关系数分别为0.969、0.967和0.976(表3)。结果表明,利用近红外光谱技术测定大豆茎秆组分ADF、NDF和CF含量的方法是可行的。同时,对于给定的显著性水平0.05,将外部验证及样品所对应的大豆茎秆ADF、NDF和粗纤维含量与模型的预测值进行配对检验(表3),结果表明,二者之间差异不显著(=0.098>0.05;=0.374>0.05;=0.124>0.05),说明该模型的预测准确度较高,可用于大豆茎秆ADF、NDF和CF含量未知样品的实际预测。结果表明,基于近红外光谱技术构建的大豆茎秆化学组分定标检测模型是可靠的,基本可代替常规化学方法对大豆茎秆化学组分进行快速、高效、科学检测分析。
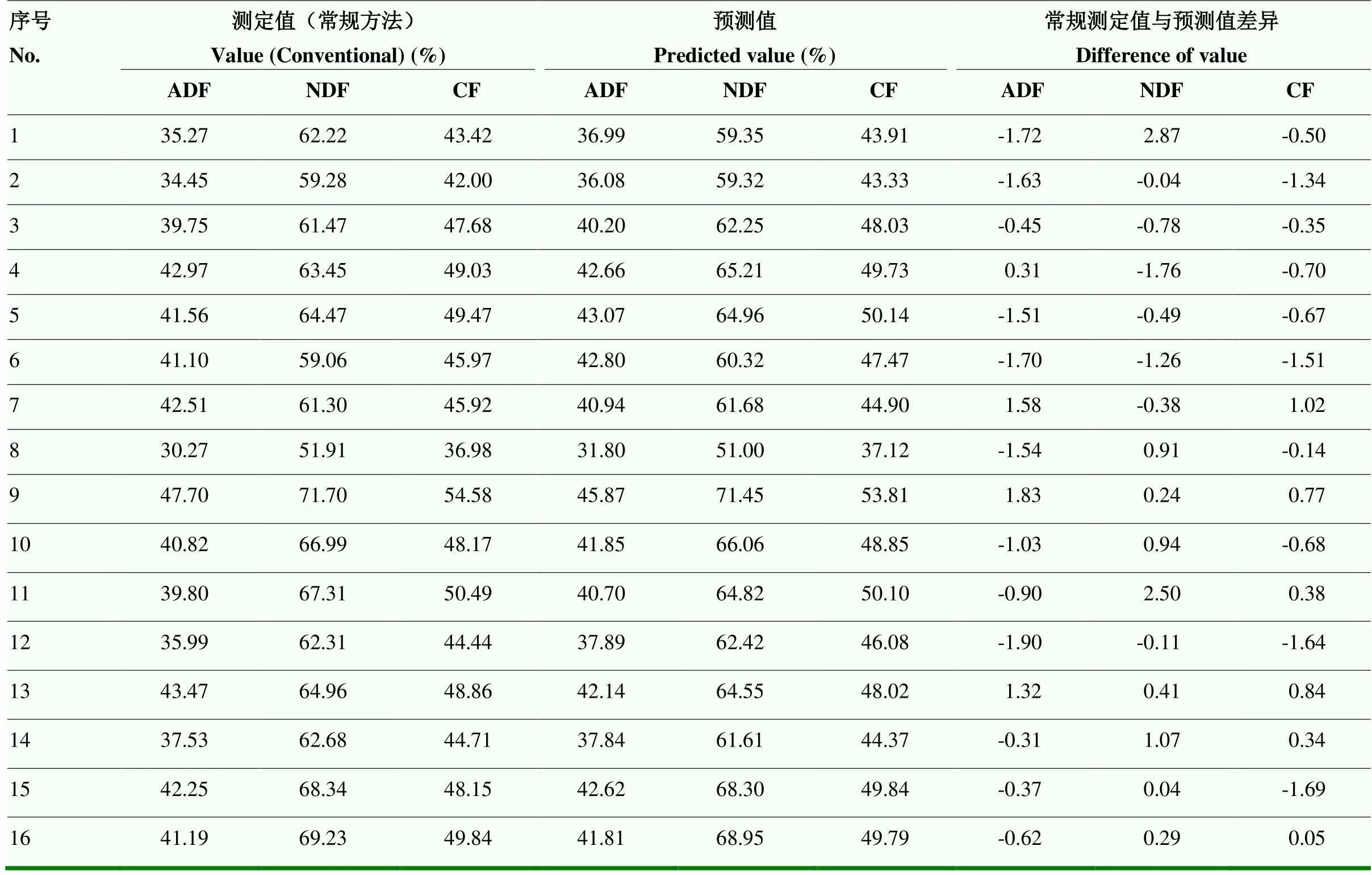
表2 常规法测定值和近红外模型预测值结果比较
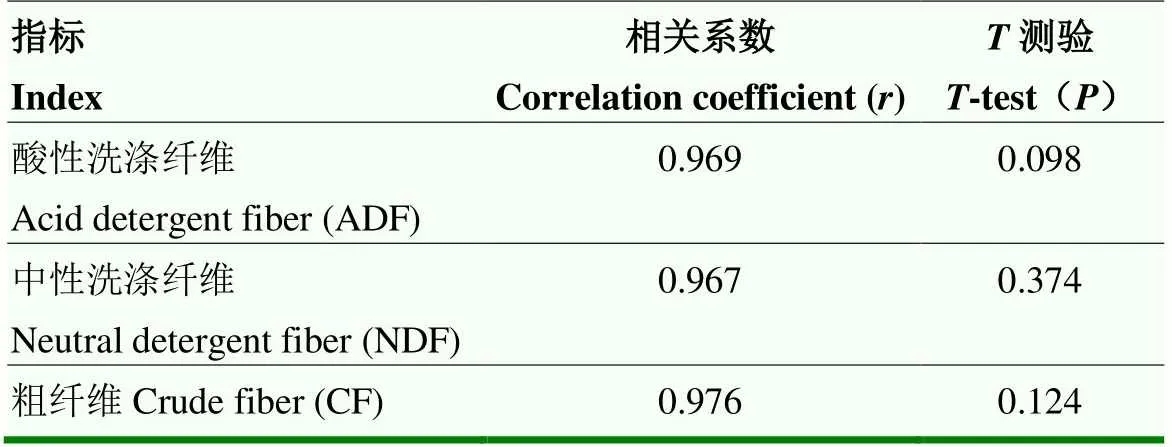
表3 常规法测定值与近红外模型预测值的相关系数
2.3 模型的验证和应用
2.3.1 供试材料表型数据整理、统计与分析 2017年和2018年共有的有效秸秆数量为393份,包括2017年收获直立型秸秆材料335份,蔓生型58份;2018年收获直立型秸秆材料312份,蔓生型81份(电子附表2)。其中,共有56个材料在2年均呈蔓生型生长,2个材料在2017年蔓生型而在2018年表现为直立型;25份材料在2017年直立生长而在2018年出现蔓生情况,这可能与两季的生长环境和管理措施有一定关系。
2.3.2 大豆茎秆粗纤维含量分布分析 对共有的393份大豆茎秆CF含量检测分析发现,2年的大豆茎秆CF含量基本呈一致性分布趋势,其含量主要分布于45.00%—55.00%(图4,2年比例分别高达77.86%和84.22%),2017年大豆秸秆CF含量主要分布在45.00%—50.00%(占55.47%),2018年主要分布在45.00%—50.00%(占42.49%),CF含量总体上仍呈现出正态分布规律(图4)。
对共有的393份大豆茎秆CF含量统计分析结果显示,2017年和2018年CF含量检测变异系数基本相同(表4),表明本研究获取的2年共有的粗纤维含量数据基本一致,数据检测结果是可信的,并能够用于进一步的分析。
在花期低温冻害发生前后,各地采用了各种预防应对措施,效果不尽相同。调查发现,整体而言,冻前采取措施优于冻后补救的效果。冻害后采取喷生长调节剂、施肥、灌水措施的,效果不明显。
2.3.3 大豆茎秆粗纤维含量与生长习性相关分析 对2年共有的393份茎秆生长习性与CF含量进行了方差分析,以了解茎秆中CF含量与生长习性之间的关系。结果显示,2017年85.24%的大豆秸秆表现出直立型生长习性,14.76%的为蔓生型生长习性,二者CF含量均值表现出极显著性差异(<0.01,表5);2018年79.39%的大豆秸秆表现出直立型生长习性,20.61%的表现为蔓生型,二者CF含量均值亦为极显著性差异(<0.01,表5)。上述结果表明,大豆品种茎秆生长习性与茎秆CF含量极显著相关。
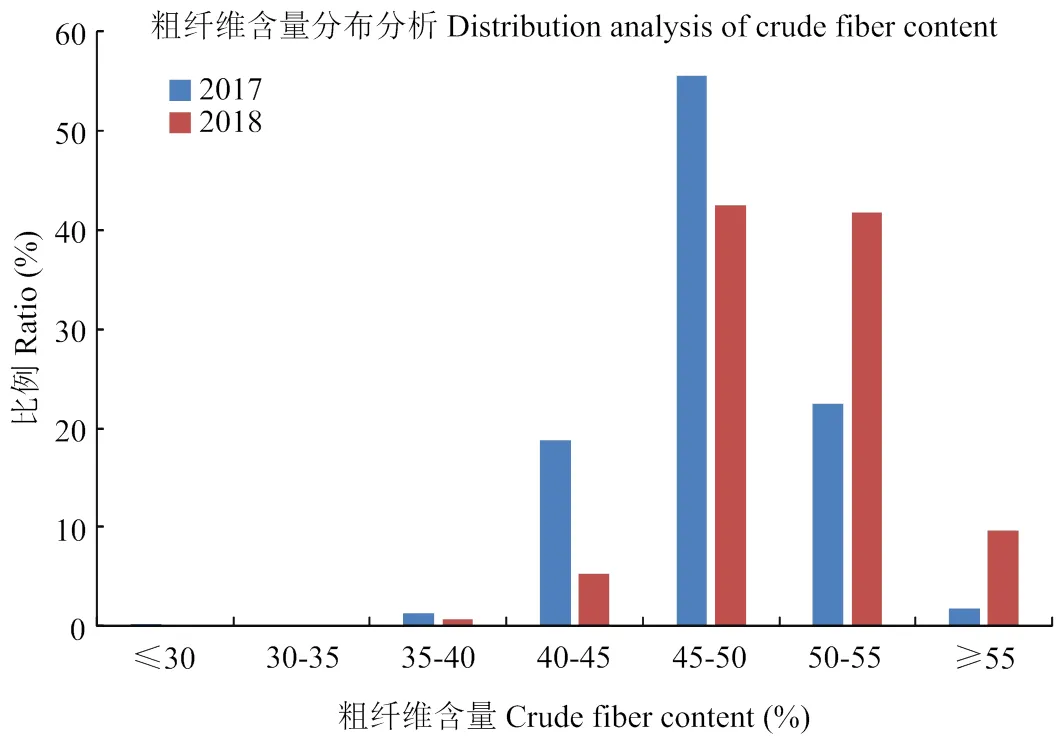
图4 大豆茎秆粗纤维含量分布分析
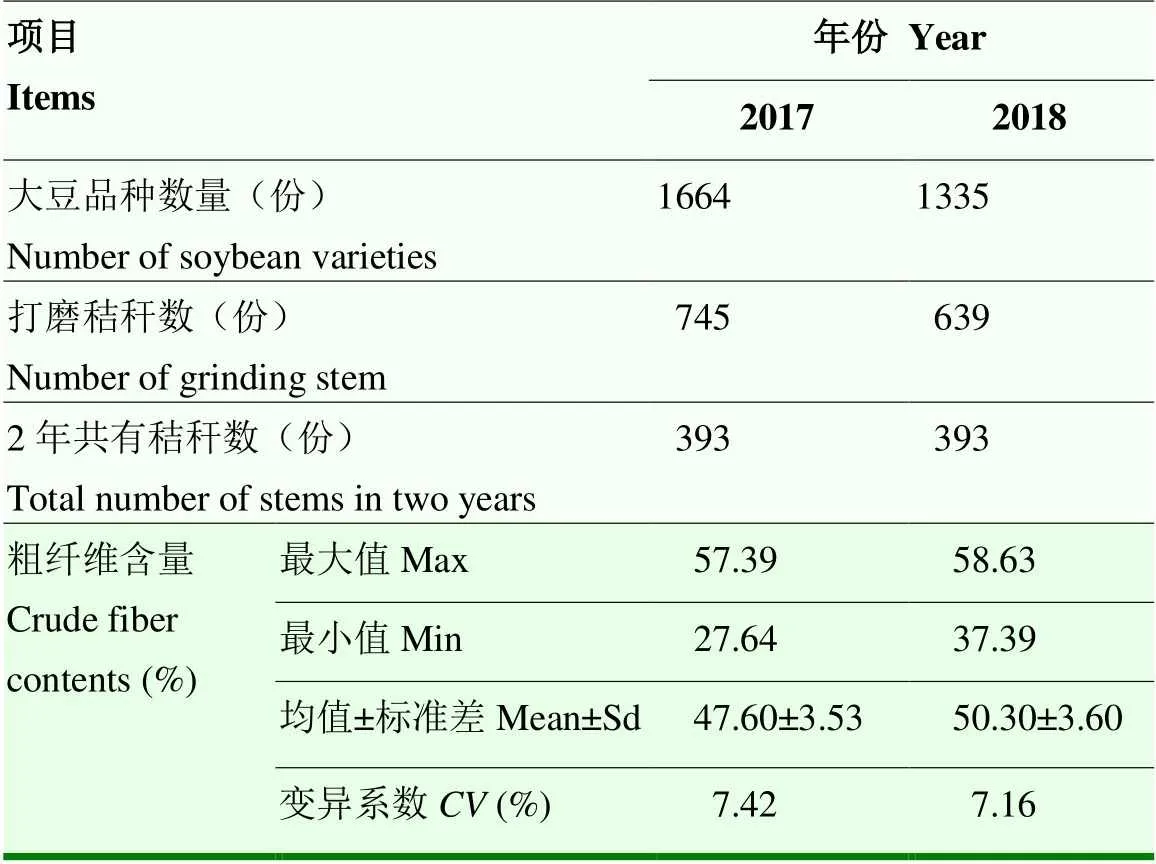
表4 393份大豆茎秆粗纤维含量检测分析
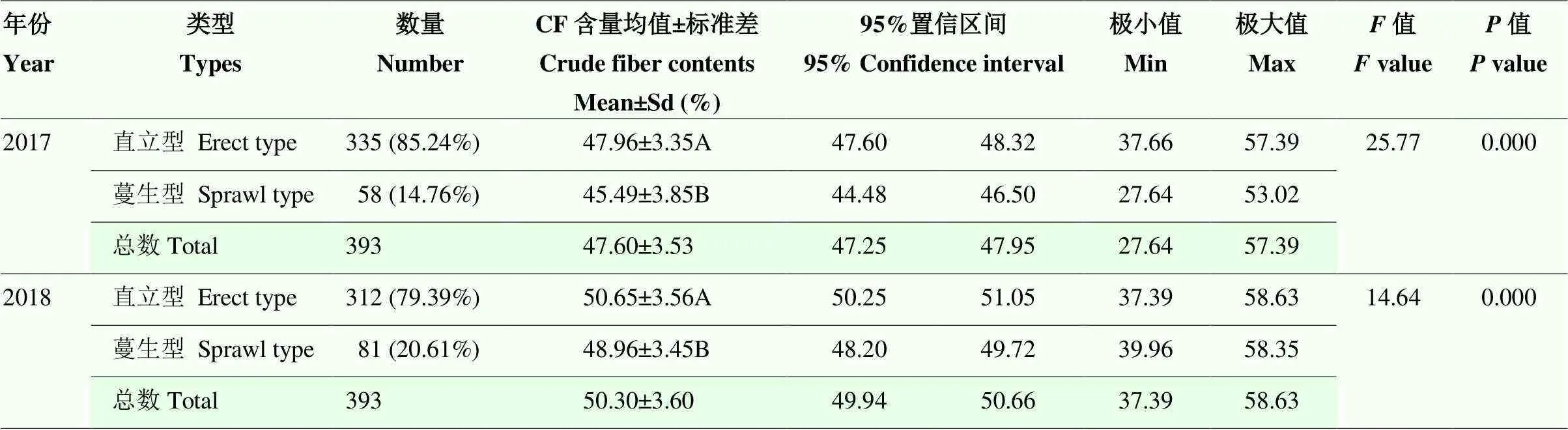
表5 大豆茎秆粗纤维含量与生长习性分相关性析
A、B代表多重比较结果差异显著 A, B represents the significance result of multiple comparisons, respectively
将2种类型CF含量按其分布比例划分为7个等级(图5)。结果显示,2017年和2018年所测直立型与蔓生型茎秆CF含量均呈现出正态分布规律,其主要分布在45.00%—55.00%。2017年,CF含量极低(小于30.00%)的区间内只存在蔓生材料(0.25%);CF含量极高(大于55.00%)的区间内只存在直立型材料(1.78%);2018年,在CF含量极低区间内的未鉴定到任何生长型(直立型和蔓生型)材料,而在CF极高区间内,100%材料分布比例中直立型占89.47%,蔓生型为10.53%(图5,电子附表2)。在CF含量大于50.00%的材料分布中,2年的数据均表现出直立型(91.67%和86.14%)显著高于蔓生型(8.33%和13.86%)(电子附表2),结果表明,CF含量较高的材料有助于茎秆抗弯曲度的增强和直立型生长。
为了更好地研究2017和2018年粗纤维含量(CF)与大豆生长习性之间的相关性,利用程辑包sm和vioplot(R 4.0.2)构建了小提琴图(图6)。结果显示,2017年,直立型的多数个体分布在(47.00±3.00)%范围内,而蔓生型的多数个体分布在(45.00±3.00)%范围内。2018年,直立型的多数个体分布在(50.00± 4.00)%范围内,而蔓生型的多数个体分布在(47.00± 3.00)%范围内。其中,2年数据中有部分个体CF含量超过了上须的延伸极限,说明可能存在CF含量极端高的单株;同时,部分个体含量低于下须的延伸极限,说明可能存在CF含量极端低的单株。对比2年的数据分布,直立型材料中CF含量的中位数、上四分位数和下四分位数均高于对应的蔓生型材料。核密度估测显示,相较于蔓生型材料,直立型材料CF含量概率密度函数分布峰值较高,说明二者可能存在显著差异(图6)。
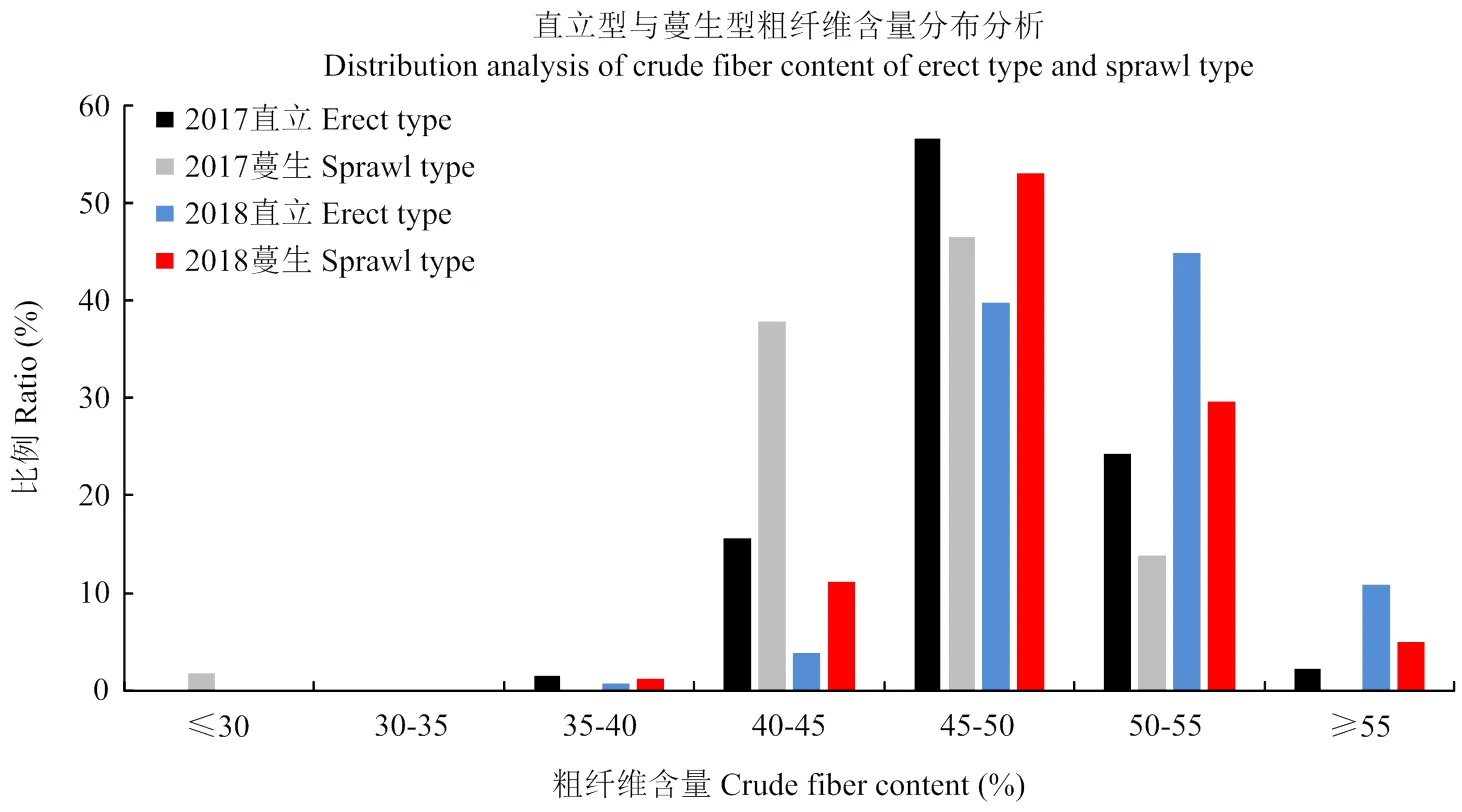
图5 大豆茎秆直立型与蔓生型粗纤维含量分布分析图
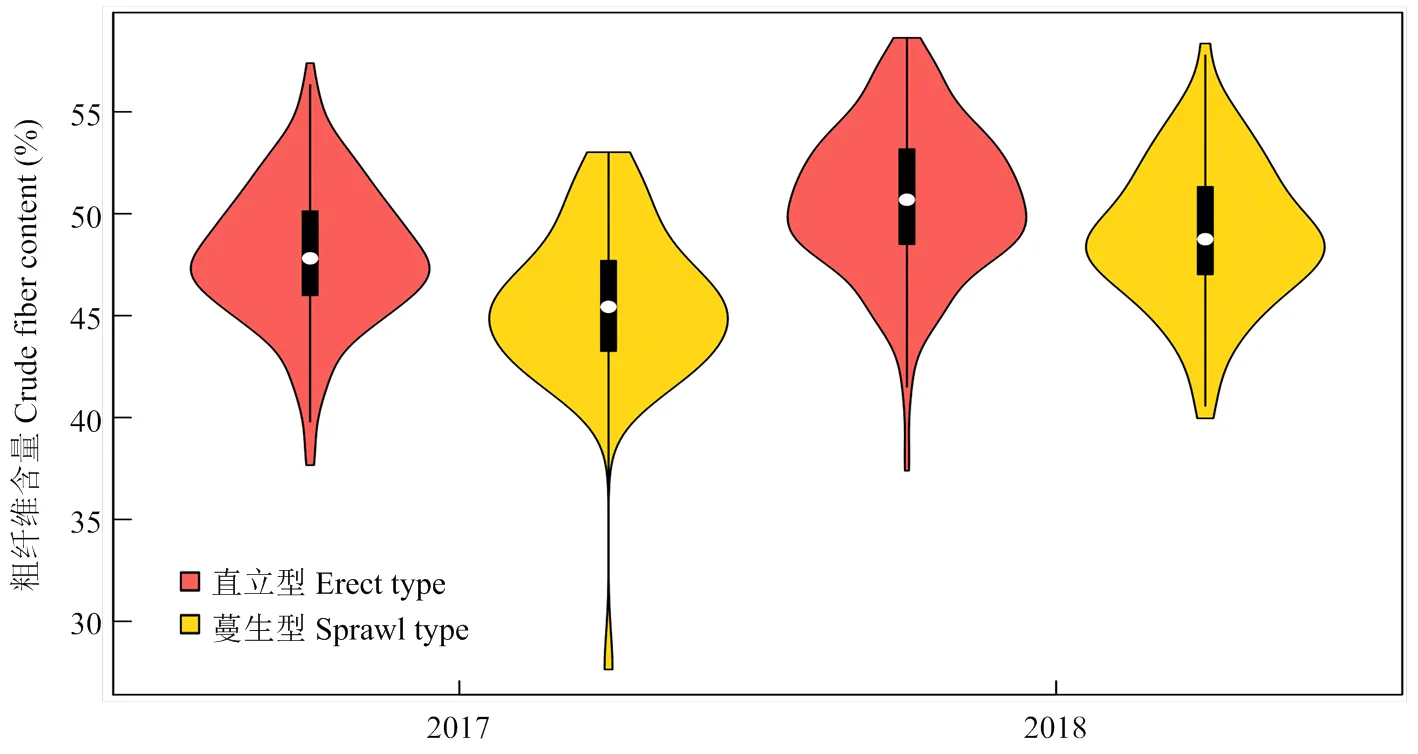
图6 大豆茎秆粗纤维含量与茎秆生长习性之间的关联分析
3 讨论
茎秆蔓生、倒伏现象在中国大豆不同生态区内均有发生,不仅严重影响了大豆产量和品质的稳定优质输出,还对其机械化作业带来了不利影响,明显阻碍了中国大豆产业化有序发展[1]。前人研究表明,作物抗倒伏性可能与其茎秆中的化学成分,尤其是粗纤维含量等密切相关。当前,农作物茎秆化学组分检测分析常使用传统的化学测定方法,此类方法优点是应用范围广、灵敏度高、仪器成本和费用相对较低,但其同时具有工作繁琐、复杂,费时费力、样品破坏性大,且在测定过程中产生的酸和碱废弃液会对环境造成污染等不利之处。相较于传统化学检测手段的缺陷,近红外光谱分析技术已经在多个领域作为产业产品品质和质量的评定标准,几乎替代了广泛使用的化学标准分析方法,在生产效率和产品质量方面取得了很好的效果[36-37]。近年来,基于近红外光谱仪的组织检测分析技术已被证明可以对不同农作物组织成分进行有效的检测分析[19-21,23,25-26]。
本研究基于新型固定光栅连续近红外光谱分析仪(DA7200,波通仪器,瑞典)构建了一套低成本、快速、高效、绿色、科学的大豆茎秆化学组分检测定标模型,并利用该模型对大豆茎秆化学组分进行光谱数据采集,以检测分析其ADF、NDF和CF组分含量。DA7200近红外光谱分析仪操作简单,使用高强度、宽波带的白光照射样品,将对样品相关组分测量的光谱信号转化为数字信号,获得测量值。然后,采用一阶导数处理(FD)+卷积平滑求导法(SG)对原始光谱进行预处理,同时利用软件SimplicityTM和The Unscramber X 10.3对预处理后的光谱进行计算建模,以减少样品散射对光谱的影响,提高光谱数据的精确度(图2)。处理之后的光谱采用偏最小二乘法(PLS)建立定标模型。近红外定量分析中统计分析方法主要有多元线性回归(multivarate linear regression,MLR)、主成分分析法(principal component analysis,PCA)和偏最小二乘法(PLS)。其中PLS和PCA均采用了全谱信息,将光谱变量压缩为为数不多的独立变量建立回归方程,通过交叉验证来防止过拟合现象。但是,PCA没有保证主成分一定与感兴趣组分浓度有关,而PLS则很好地保证了这一点[38]。因此,PLS分析精确度较高,是目前近红外光谱分析上应用做多的回归方法。本研究所用计量统计分析方法采用PLS建立定标模型,获得了相关系数高和预测误差小的检测定标模型。
颅脑损伤患者常合并高热等并发症,当受压组织温度升高时,更易发生压疮。临床上头部给冰枕冰帽降温,从而使患者头部皮肤处于相对潮湿状态,冰袋长时间使用,会影响组织代谢或使局部组织血管收缩而缺血缺氧,从而造成头部压疮的发生[3]。对使用冰枕冰帽降温者必须用毛巾将起包裹才可接触皮肤。
为了验证所建模型对大豆化学组分含量检测分析的准确度和可靠性,本研究随机选取了模型外的16份未知大豆茎秆组分分别采用常规化学检测和模型预测方法进行分析比较。结果显示,常规化学检测分析结果与利用本研究中构建的大豆茎秆化学组分近红外光谱检测定标模型预测分析结果无显著性差异,且二者之间的相关性较好(表2和表3)。结果表明,本研究构建的大豆茎秆化学组分近红外光谱检测定标模型测定结果是可靠的,基本上可代替常规化学方法的检测分析。同时,与传统化学检测技术相比,该定标模型操作过程简单、快速、环保,且数据可靠性高。此外,相较于ASEKOVA等[39]构建的NIRS(near-infrared reflectance spectroscopy)模型获得的R6期大豆茎秆中ADF(22.60%—38.10%,平均值为29.40%)和NDF(37.40%—66.60%,平均值为50.70%)检测结果,本研究利用构建的近红外光谱定标模型获得的大豆茎秆ADF(30.27%—51.15%,平均值为40.59%)和NDF(51.91%—73.08%,平均值为63.12%)含量与其存在一定的差异性,具体原因可能是:(1)所测样本时期不同,本研究为收获后晾晒干的大豆整体茎秆部分,而ASEKOVA等[39]所用样本为大豆R6时期植株茎秆烘干(60℃烘箱)后样品;(2)样品处理、光谱采集以及测量方法等方面不同。值得注意的一点是,本研究中,近红外光谱定标模型建立需要的样本量越大,建立的模型越稳定,结果越准确,得到的预测值与常规法实际值误差越小。本研究通过近红外光谱定标模型测定大豆茎秆化学组分ADF、NDF和CF含量,克服了以往常规化学方法测定过程中的繁琐复杂、耗时耗力、污染环境等缺点,为农作物茎秆化学组分含量的检测分析提供了一种新的测定方法参考。
北京科技大学图书馆推行的辅助大学生创新社会实践案例获得了2016年全国高校信息素养教育研讨会案例大赛一等奖,案例是为满足学生创新社会实践进行
