基于用户特征和评分的精准推荐策略研究
2021-03-24傅金京李玲娟
傅金京,李玲娟
(南京邮电大学计算机学院,江苏 南京 210023)
个性化推荐系统可以收集并分析用户在使用互联网过程中所产生的用户个人信息、浏览历史、购买记录以及评价等信息,然后基于这些信息从海量数据中挖掘出用户独特的需求和兴趣倾向,再将用户感兴趣的信息或商品推荐给用户[1-2]。近年来,科研人员提出了许多适用于不同场景的推荐算法,例如基于内容的推荐[3]、基于内存的协同过滤推荐[4]、基于关联规则的推荐[5]等。 其中应用最广的是基于内存的协同过滤推荐算法,此类算法又有基于用户的协同过滤推荐算法UserCF和基于物品的协同过滤推荐算法ItemCF。前者适用于用户数少的场合,后者适用于物品数明显小于用户数的场合。因此一个推荐系统只采用固定的一种推荐算法是不合适的,需要根据具体情况灵活选用合适的推荐算法来产生更有针对性的推荐结果。
推荐系统通过评估目标物品被用户喜欢的程度来决定是否将其列入推荐列表,而要完成用户偏好的评估,需要一定数据量的支持。但是,在实际应用中,推荐系统会有大量的新用户或者新物品,导致了数据的稀疏性很大,此时推荐系统没有足够的信息进行偏好的评估与分析,这种现象称为冷启动[6-7]。
为了解决以上问题,本文设计了一种基于用户特征和评分的精准推荐策略(Accurate Recommendation Strategy based on UserCharacteristics and Ratings,UCRAR)。 该策略一方面采用 K-means聚类算法对全体用户特征进行聚类,将新用户所属类中其他用户喜好物品的Top N个推荐给新用户,另一方面根据物品数和用户数的大小关系,或者不同推荐算法所得F1值的大小关系,来决定选择用哪种推荐算法产生的结果推荐给老用户。这种策略引入用户特征解决了用户冷启动问题,并且能够根据具体情况灵活选用合适的推荐算法来产生更有针对性的推荐结果。
1 相关知识
1.1 UserCF 与 ItemCF
协同过滤(Collaborative Filtering,CF)是个性化推荐系统中应用最为广泛的技术之一。该算法表明具有相似兴趣的用户可能喜欢相似的物品,或者用户可能对相似的物品表现出相似的偏好,这是一种具有集体智慧的决策方法[8]。
(1)基于用户的协同过滤推荐算法UserCF
UserCF算法的基本思想是:使用用户相似度计算方法,为目标用户找到最近邻居用户集;然后,提取最近邻居用户集中用户所喜欢的物品,并除去目标用户历史记录中感兴趣的物品;最后根据目标用户对这些物品感兴趣的程度排序获得最终结果,选择并推荐给用户。
在基于用户的协同过滤算法中,最重要的部分是计算用户的相似度,常用的用户相似度计算方法有皮尔逊相关系数[9]、欧几里得距离[10]、余弦相似度等[11]。
皮尔逊相关系数计算方法如式(1)所示。

其中,i表示物品,I表示用户u和用户v共同评分过的物品集合,rui为用户u对物品i的评分为用户u对他评过分的所有物品的平均评分。
余弦相似度的计算方法如式(2)所示。

在UserCF算法中,另一个重要的部分是预测用户对未评分物品的评分。计算方法如式(3)所示。

其中,S(u,K)为和用户u兴趣最相似的K个用户的集合,N(i)为对物品i评过分的用户集合。
(2)基于物品的协同过滤推荐算法ItemCF
ItemCF算法的基本思想是:通过使用物品相似度计算方法,结合目标用户的历史行为,为目标用户找到与其曾经喜好过的物品最相似的其他物品;然后,根据目标用户对这些物品感兴趣的程度排序,选择合适的物品推荐给用户。
在ItemCF算法中,物品相似度计算公式可以采用式(1)或式(2)进行调整运算,也可以运用关联规则方法计算,如式(4)所示。

其中,|N(i)|为喜欢物品i的用户数,|N(i)∩N(j)|为同时喜欢物品i和物品j的用户数。
用户偏好计算方法如式(5)所示。

其中,N(u)为用户喜欢物品的集合,S(j,K)为和物品j最相似的K个物品的集合,wji为物品j和物品i的相似度。
1.2 K-means聚类
聚类算法是机器学习中非监督学习的重要研究领域。聚类算法的基本目标是将相似的数据样本分组为一个类。传统的聚类算法可分为:划分聚类、层次聚类、基于密度的聚类、基于模型的聚类和基于网格的聚类[12-13]。划分聚类中最常用的是 K-means聚类算法[14]。
K-means聚类算法的基本思想是,首先任意选取K个数据作为初始聚类中心;然后进入迭代过程,每次迭代包含两个步骤:(1)分配步骤,即将其余各个数据划归到距离它最近的那个聚类中心所处的簇类中;(2)更新步骤,即重新计算每个簇类中所有数据的平均值,找到新的聚类中心。当聚类中心不再变化时,聚类完成。该算法具体步骤[15]如下:
(1)给定大小为n的数据集,令I=1,随机选择K个初始聚类中心Zj(I),j=1,2,…,K。
(2)计算每个数据对象与聚类中心的距离D[xi,Zj(I)],i= 1,2,…,n;j= 1,2,…,K,若满足D[xi,Zj(I)]=min{D[xi,Zj(I)],i= 1,2,…,n},那么xi∈wk。
(3)计算K个新聚类中心

以及误差平方和准则函数Jc的值

(4) 判断。 如果|Jc(I+1)-Jc(I) |<ξ,算法结束;反之,I=I+1,则重新返回第(2)步执行。
1.3 Top N推荐评价指标
Top N推荐常用的评价指标有准确率(Precision)、召回率(Recall)和 F1值。 其中,F1值是综合了前两者指标的评估指标。
(1) 准确率(Precision)
准确率(Precision)计算方法如式(8)所示。

其中,R(u)为根据用户在训练集上的行为给用户做出的推荐列表,T(u)为用户在测试集上的行为列表。
(2) 召回率(Recall)
召回率(Recall)计算方法如式(9)所示。
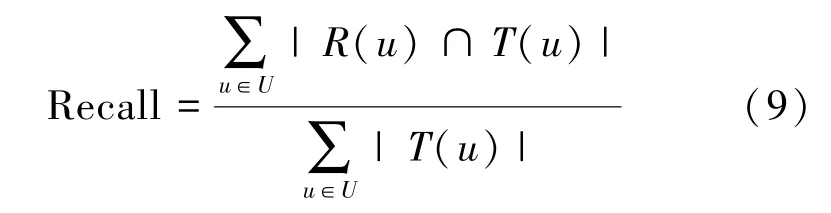
(3) F1值
F1值计算方法如式(10)所示。

2 基于用户特征和评分的精准推荐策略的设计与分析
与其他推荐算法相比,协同过滤推荐算法的优势在于它只依赖用户的行为数据,不依赖于具体用户及标的物相关的数据就可以做推荐。但是,如何在有新用户、新物品等情况下保证推荐精度,以及如何根据具体情况选择合适的算法来提高推荐精度,都是需要解决的问题。本文设计的基于用户特征和评分的精准推荐策略UCRAR总体上包括:新用户冷启动问题的解决方法、推荐算法及结果的选择策略。
2.1 新用户冷启动问题的解决办法
本文主要引入用户特征、K-means聚类算法来解决用户冷启动问题。研究发现要利用K-means聚类算法来寻找与新用户特征最为相似的老用户,需先对所有用户特征数据进行特征归一化处理,然后再对新老用户特征进行聚类,接着依次计算新用户所属类中其他用户与新用户的相似度,把它作为用户可能喜好物品的权重,最后从中选取Top N个推荐给新用户。
对用户特征数据进行归一化处理的过程如下:首先提取用户特征信息 Ftr=[age,gender,occupation],构建用户特征矩阵U×Ftr;然后使用LabelEncoder方法对分类型特征值进行编码,即将离散型的数据转换成0到n-1之间的数,这里n是一个列表的不同取值的个数,可以认为是某个特征的所有不同取值的个数;接着,对离散型特征进行one-hot编码,其方法是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,保证每个样本中的每个特征只有一位处于状态1,其他都是0;最后,将用户的所有特征拼接成一个用户特征向量,例如对于“年龄为 18岁,性别为男,职业是学生”的用户Ftr1= [18,M,student],经过如上处理后得到该用户特征向量为[0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1]。
2.2 推荐算法及结果的选择策略
鉴于UserCF算法和ItemCF算法的使用特性,即前者适用于用户数少的场合而后者适用于物品数明显小于用户数的场合,本文把用户特征作为算法的输入,生成针对用户灵活选用合适推荐算法的多个判断条件,最终来产生更有针对性的推荐结果。
在UCRAR策略中,首先比较用户数和物品数的大小关系,若用户数远大于物品数,则直接选用ItemCF算法;若物品数远大于用户数,则直接选用UserCF算法;若用户数和物品数较为接近,则系统把这两个推荐算法都作用于该用户并生成推荐列表集,每个列表和用户真实评价列表比较,并依据评价指标F1值决定当前用户所适用的推荐算法,若两者的推荐评价指标F1值结果不分上下,则将两者的推荐列表集结合在一起并根据权重与评分相乘结果排序,选择值最高的N个物品推荐给用户。
2.3 基于用户特征和评分的精准推荐策略总体流程
UCRAR策略的总体流程如图1所示。

图1 UCRAR策略的总体流程
总输入是用户信息,总输出是推荐物品列表。
在对任意一个用户进行推荐之前,首先判断该用户是否为新用户,然后采取不同的推荐策略,直到获得最终推荐结果。
针对新用户做推荐的具体步骤如下:
Step1:提取新用户的用户特征信息 Ftrnew=[age,gender,occupation]。
Step2:使用LabelEncoder方法和one-hot编码对新老用户特征进行特征归一化处理,利用式(6)和式(7)得到最终的K个聚类中心Zj(I),j=1,2,…,K。此步骤还可以得到一个关于每个数据样本所属最终聚类中心的列表label_pred。
Step3:从列表label_pred中找到与新用户属于同一个聚类中心的其他用户。计算这些用户与新用户的相似度,选择相似度最高的前K个用户。此步骤可生成由与新用户相似度最高的K个用户及对应相似度组成的字典nerb。
Step4:收集这K个用户所有喜好的物品,然后把字典nerb中对应用户的相似度作为该用户喜好物品的权重,据此计算新用户对所有推荐物品的喜好程度,从中选择喜好程度最高的N个物品,产生推荐物品列表,推荐给用户。
该部分伪代码如下。

针对老用户做推荐的具体步骤如下。
Step1:比较用户数M和物品数N的大小关系。
Step2:若用户数远大于物品数,则直接选用ItemCF算法做出推荐,获得推荐物品列表,推荐结束。
Step3:若物品数远大于用户数,则直接选用UserCF算法做出推荐,获得推荐物品列表,推荐结束。
Step4:若用户数和物品数较为接近,则系统把UserCF算法和ItemCF算法都作用于目标用户并生成推荐物品列表。
Step5:将这两个列表与用户真实评价物品列表进行比对,并以推荐评价指标F1值的高低抉择当前用户所适用的推荐算法。选用F1值较大的推荐结果,产生推荐物品列表;若两者的推荐评价指标F1值结果相近,则将两者的推荐物品列表集结合在一起,并根据权重与评分相乘结果排序,选择值最高的N个物品推荐给用户,推荐结束。
该部分伪代码如下。

2.4 UCRAR策略复杂度分析
UCRAR策略在针对新用户做推荐时,引入K-means聚类算法对全体用户特征进行聚类,该阶段的时间复杂度为O(nki),其中n为用户数,k为簇集数,i为K-means聚类算法迭代次数。然后,将新用户所属类中其他用户喜好的物品中的Top N个推荐给新用户,该阶段的时间复杂度为O(mN),其中m为新用户所属类中的用户数,N为推荐物品数,并且新用户所属类中的用户数远小于整个用户集数量,即m≪n。UCRAR策略在针对老用户做推荐时,主要是根据物品数和用户数的大小关系,或者不同推荐算法所得F1值的大小关系,来决定选择将哪种推荐算法产生的结果推荐给老用户,其时间复杂度近似为O(n2),n为用户数。综上所述,UCRAR策略具有较低的时间复杂度,在一定程度上提高了推荐系统的实时响应能力。
3 实验及结果分析
为了验证UCRAR策略的性能,本文分别基于Movielens数据集、FilmTrust数据集进行了实验。为保证算法的准确性,对上述两个数据集分别做了50次测试,求取相应测试结果的准确率(Precision)、召回率(Recall)和F1值的平均值,并同经典的UserCF算法和ItemCF算法的推荐结果进行对比。
3.1 实验数据集
Movielens数据集[16]是由明尼苏达大学 GroupLens研究组提供的。它是一个关于电影评分的数据集,里面包含用户对电影的评分信息、用户信息、电影信息和标签信息。Movielens数据集有多个版本,本文采用的是Movielens-100K数据集,它包含943个用户对1 652部电影的100 000个评分,稀疏度为93.7%。
FilmTrust数据集[17]是在2011年6月从FilmTrust网站上抓取下来的一个关于电影评分和用户间信任度评级的数据集。该数据集由ratings.txt和trust.txt两部分组成,包含了1 508个用户对2 071部电影的35 497个评分,以及关于1 642个用户间信任度评级的1 853条数据,稀疏度为98.86%。
3.2 实验结果及分析
(1)冷启动状态下的推荐
冷启动状态下的推荐结果如表1所示,其中的用户特征是指[年龄,性别,职业]。

表1 Movielens数据集上冷启动推荐结果
(2)用户数和物品数较为接近时的推荐结果
本文将基于用户的协同过滤推荐算法和基于物品的协同过滤推荐算法所获得的推荐物品列表与用户真实评价物品列表进行比对,并以F1值的高低抉择当前用户所适用的推荐算法。
实验中首先选择了两个用户,对每个用户分别用UserCF算法和ItemCF算法实施推荐,对比结果如图2所示,其中N为推荐物品数量。

图2 两个用户在两种推荐方法上的F1值对比
可以看出:用两种推荐算法对这两个用户推荐时所取得的F1值并不一致。对于用户1,UserCF算法的F1值总体上优于ItemCF算法;而对于用户 2,ItemCF算法的 F1值总体上优于UserCF算法。
进一步从全体用户出发,对比全体用户分别使用UserCF算法、ItemCF算法和本文的UCRAR策略的推荐效果,Movielens数据集上的实验结果如图3所示。FilmTrust数据集上的实验结果见表2至表4。其中N为推荐物品数量。

图3 Movielens数据集上的对比

表2 FilmTrust数据集上的准确率对比

表3 FilmTrust数据集上的召回率对比

表4 FilmTrust数据集上的F1值对比
综合图2和图3以及表2至表4中的结果可以看出,对于不同特征的用户使用UCRAR策略所取得的准确率、召回率和F1值均好于只用UserCF算法或ItemCF算法对用户进行推荐的方式。
4 结束语
本文基于K-means聚类算法和协同过滤推荐算法设计了一种基于用户特征和评分的精准推荐策略。该策略通过引入用户特征,使用K-means聚类算法对全体用户特征进行聚类,将新用户所属类中其他用户喜好的物品中的Top N个推荐给新用户,
解决了新用户冷启动问题;又根据物品数和用户数的大小关系,或者不同推荐算法所得F1值的大小关系,来决定选择将哪种推荐算法产生的结果推荐给老用户,弥补了单一协同过滤推荐算法在实际应用上的诸多不足。最后,将针对新老用户做出不同推荐的方法结合在一起,扩展了算法的使用范围,增强了算法的稳定性。在真实数据集上的实验结果表明,本文提出的基于用户特征和评分的精准推荐策略有着较高的准确度。
