基于Hue 的自动化数据分析系统设计与实现
2021-03-24王帅万小霞
王帅,万小霞
(盐城师范学院信息工程学院,盐城224002)
0 引言
淘宝、京东以及世界各地的大型商场和连锁门店,每日都有大量的交易清单产生,一个购物狂欢节就有过亿交易金额要处理。快递、物流每天也有各种数据产生如国内外物流清单、发货退货记录等,医院、诊所也有药物清单、病人资料、就诊记录等,就连日常聊天一段时间下来也是篇幅巨大。腾讯的数据中心内有大量的会话信息,基于这些数据进行新型应用开发。总之,这些数据不可避免地成为了一个新平台,大数据时代要求我们在以数据为中心的平台上进行分析并去开发新型数据管理系统和相应的应用系统[1]。
1 系统分析
大数据分析平台由商城系统和数据可视化系统组成。具体来说,商城系统有离线日志发送、实时数据转发两大功能;数据可视化系统具有用户总人数及活跃度统计、热销商品分析、广告实时点击量以及地域分布统计等功能。
1.1 商城系统
(1)离线日志发送
将商城的离线数据发送给Flume 日志系统并在本地备份
(2)实时数据发送
将商城的实时数据发送给Kafka 消息管理中心。
1.2 数据可视化系统
(1)用户统计
表格展示商城用户总人数、新增用户人数、昨日活跃度、昨日活跃率。
(2)标签点击量TOP5
环状图展示点击数量最多的前5 个分类。
(3)商品点击量TOP5
半环状图展示点击数量最多的前5 个商品。
(4)热销商品TOP5
环状图展示购买数量最多的前5 个商品。
(5)收藏商品TOP5
柱状图展示加入购物车数量最多的前5 个商品。
(6)广告实时点击量
折线图展示当天各时段的广告点击量
(7)销售区域分布
中国地图展示各区域销售情况
1.3 Hadoop服务器
(1)离线日志分析
Flume 日志系统接收离线日志,使用Hive 数据仓库存储数据,Spark SQL 处理离线数据
(2)实时数据转发
2 系统设计
2.1 商城系统设计
商城系统重点是整合获取离线和实时数据两部分功能,具体实施应与对应上线系统对接,本次使用的商城系统为简易设计的模拟系统,目的是保证大数据分析平台的数据来源真实可靠。
本系统主要配置两大模块,离线日志发送,实时数据发送。
(1)离线日志发送模块
首先商城中的离线数据发送至Linux 服务器中的Flume 日志系统,及那根离线数据日志存在服务器上,而后将日志上传至HDFS 分布式文件管理系统并按格式导入Hive 数据仓库,再运行编写好的Spark SQL 和Spark ALS 的JAR 包,将Hive 数据仓库中的数据提取分析并将结果写入MySQL 数据库中。
离线日志发送模块的流程如图1 所示。
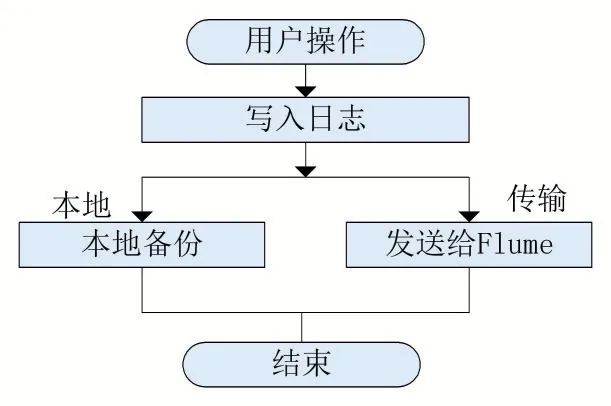
图1 离线日志发送模块流程图
(2)实时数据发送模块:
实时数据则由商城系统直接发送给Kafka 消息中心,将Kafka 消息中心作为中转站,把实时数据转发给已经启动好的Spark Streaming 服务,Spark Streaming 就会按照时间滑窗将数据按小时分组存入MySQL 数据库中。
2.2 数据库设计
本系统将设计1 个MySQL 数据库。数据库名为shop,数据库中包含的数据库表有:
addCar 表:存储加入购物车汇总信息;
buyGoods 表:存储购买商品汇总信息;
clickAd 表:记存储广告实时点击汇总信息;
clickGood 表:存储浏览商品汇总信息;
clickTab 表:存储浏览分类汇总信息;
hotGoods 表:存储销售区域分布汇总信息;
userStatistics 表:存储各用户统计信息;
recommend 表:存储所有用户的推荐商品信息。
其中最主要的是推荐表,是推荐算法的直观展示,表1 给出商品推荐表的详细设计。
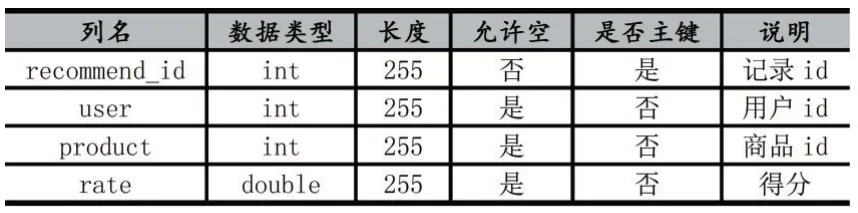
表1 商品推荐表
3 系统实现
3.1 离线数据处理模块
离线数据处理分为3 步:商城发送日志,过滤日志,导入数据仓并分析。
(1)商城发送日志
商城整合日志组件,配置Logback 配置文件。


以上代码为Logback 详细配置,一共两块日志采集的功能。fileAppender 的功能为本地备份,日志信息记录为log 格式的文件,每5MB 生成以一个记录文件,以时间格式命名。Flume 的功能为发送日志的功能,与Flume 建立连接后,追条发送日志给Flume。每当使用INFO 级别的日志功能就会触发这两个功能,将日志本地备份并且发送给Flume 日志系统,如图2 所示。
图2 后端日志图
(2)过滤日志
配置Flume 启动配置文件,编写Shell 脚本。


以上代码为Flume 详细配置,通过此配置启动Flume 日志系统,每当接收到日志数据时,按照拦截格式保留需求数据,存于本地shop 目录下的logs 文件夹内。

以上代码为Shell 脚本中的部分功能,目的是将logs 文件夹中的昨日数据,剪切到临时文件夹logsmv,通过HDFS 命令将历史文件夹中的日志上传到HDFS文件管理系统,最后清空临时文件夹。使用临时文件夹logsmv 的目的是因为在命令执行期间可能会有新的日志进来,清空数据的时候会产生误删的情况。
(3)导入数据仓并分析
启动Hive 和Spark 服务,执行Spark SQL 的JAR 包。
以上代码为Spark SQL 详细功能,使用Scala 语言开发。先将HDFS 文件系统中的日志导入Hive 数据仓库中内,再将日志数据分类分析,最后将结果存入MySQL 数据库,便于查询。
3.2 实时数据处理模块
实时数据处理分为3 步:商城发送消息、消息中转、实时分析数据。
(1)商城发送消息
为商城整合消息组件,与Kafka 建立会话。

以上代码为商城将广告点击的消息发送给Kafka的实现代码,通过配置的参数将消息发送到指定IP 和端口的Kafka。
(2)消息中转
将Kafka 作为消息中转站。

以上代码为启动Kafka 服务并开启shop 会话。
(3)实时分析数据
数据可视化模块获取消息,分析实时数据。

以上代码为Spark Streaming 获取Kafka 的消息,而后将计算每个小时的各个广告点击量并存入MySQL。
3.3 数据可视化模块
本功能模块为前后端分离项目,前台使用VUE 框架,后台使用Spring Boot 搭建的SSM 框架,界面效果如图3 所示。

图3 数据可视化界面
3.4 商品推荐模块
本功能模块为离线分析拓展模块,通过算法实现数据分析进阶功能,即针对每一位用户,为其推荐满足其喜好的商品,让平台具有智能化。
(1)ALS 推荐算法
本模块使用的技术是Spark MLlib,基于Spark ML⁃lib 实现的ALS 推荐算法。


以上代码为商品推荐的具体实现。ALS 是交替最小二乘(Alternating Least Squares)的简称。在机器学习中,ALS 特指使用交替最小二乘求解的一个协同过滤推荐算法。它通过将用户的浏览、收藏和购买行为进行打分,将用户与商品之间缺失的评分补齐,以评分为依据来推断每个用户的爱好并向用户推荐适合的产品。
(2)RMSE 算法调优
ALS 推荐算法训练过程中存在拟合问题,拟合问题有两种,欠拟合和过拟合,都会影响结果的精准度。欠拟合就是拟合精度不够,举个例子,数据集是个第一象限的幂函数,而我们得到的结果却是个一次函数直线,虽然也接近目标,但是误差还是比较大。过拟合是指精度要求过高,过分考虑到每一个数据点,使得原本很完美的结果曲线变形。在科学研究过程中,对于异常数据的排除和忽略是至关重要的环节。在算法调优时,可以通过RMSE 均方根误差判断拟合参数是否合理。


以上代码为算法调优的具体实现,代码对评分矩阵进行分解,隐特征数量设置为10,迭代10 次,正则化参数设为了0.01。将真实评分数据集与预测评分数据集合并,可以得到用户对每一个商品的实际评分和预测评分,然后计算评分的根均方差,以误差值为依据,调整参数进行调优。
4 结语
本次大数据分析平台的重要核心功能就是数据的分析模块,分析中针对不同需求场景,对应着不同的算法。在对算法的研究过程中,了解到聚类、分类、推荐、决策树等高阶算法,更加加深了对普通算法的理解,即使使用寻常算法,许多难题也都迎刃而解。继大数据学习之后,学习算法接触人工智能也是主流方向,用大规模数据训练模型,可以给后续学习打下基础。
