基于迁移学习的小规模医学领域文本摘要生成模型
2021-03-24刘佳芮
刘佳芮
(同济大学电子与信息工程学院,上海201804)
0 引言
随着社会分工的日益明确,几乎每个人都带有专业性的行业标签。然而快速迭代的经济发展模式需要人们不断学习才能更好地适应工作中的各种挑战,因此人们总会通过不断地补充大量的跨领域知识让自身在职场中一直保持竞争性。但是当人们需要去检索有关文献时,太过专业性的文本总会削弱对跨领域知识学习的求知欲。因此,本文旨在通过机器学习模型解决跨领域标题可读性和可理解的问题,并基于文本自身文意[1]得到更常语化的标题表达。传统的机器学习方法经常依赖于大量数据以支撑参数调整优化[3],然而特定专业领域的数据往往由于上述假设过于严格而难以成立。事实上,这些领域的可用数据量较小,特别是有标签的数据样本更加难得,这使得训练样本不足以供复杂的机器学习算法进行训练并得到一个可靠的生成预测模型。
如何分析并挖掘小规模样本数据是现代机器学习最具有挑战性的前沿方向之一。在该环境背景下,迁移学习应运而生。该学习算法的主要优点在于避免了必须有足够可用的训练样本才能够学习到一个好的生成模型的束缚,因此迁移学习能够在彼此不同但又相互关联的两个领域间挖掘数据的本质特征和内在结构,这使得有监督参数信息得以在领域间实现迁移和复用。
摘要文本生成模型研究是当前自然语言处理中的难点和热点,其主要分为抽取式和生成式方法,前者通过直接获取原文中的相应句子并根据一定的排列方式构成摘要标题,后者与其的区别在于会自动生成一些在源文本中不存在的新单词或词组。本文的主要目的是为特定专业领域的文本构造清晰易懂的标题,因此我们将使用生成摘要的方法构造标题。当前生成式文本摘要的方法主要依靠深度神经网络结构实现,如2014 年Google 团队[5]提出的Seq2Seq 模型开启了自然语言处理中端到端的研究,其中编码器负责将原文编码为一个向量,解码器负责从该向量中提取语义并生成相应的生成式文本摘要。该模型在机器翻译、文本理解等领域具有卓越的效果。Rush[6]团队受机器翻译原理的启发,首次将Seq2Seq 模型应用到生成式摘要的任务中,其主要使用带有注意力机制的卷积神经网络模型对文档进行编码来提取文本的特征,然后由基于前馈网络的神经网络模型作为解码器生成摘要,并在Giga word 数据集中得到了良好的实验结果。
基于上述研究,本文旨在解决以医学为代表的特定专业领域小规模文本的摘要生成问题,提出了基于迁移学习的文本摘要生成模型,其有效解决了专业领域标题简易化以及小规模样本不足以支撑现有机器学习模型的问题。
1 基于迁移学习的文本摘要生成模型
1.1 预训练文本模型
本文在文本词向量生成阶段主要使用了针对特定领域数据集的BERT 改进模型。BERT 模型在摘要任务中并不直观,大多数BERT 模型任务主要解决的是某一个字段的生成,而摘要自动生成任务是一个Seq2Seq 生成模型问题,因此我们需要解决整个摘要生成句子的向量表示。由于本文以小规模的医学领域数据集为研究对象,考虑到文本的特殊性,下面将采用三层嵌入层来实现上述目标。如图1 所示,①为了使模型对文本中不同的句子关系进行区分,在生成过程中嵌入A、B 符号表示区分多个句子在整篇文章中的奇偶性。②在针对每个句子的处理中,原本的BERT 模型仅在每个样本前端插入[CLS]标识,而本文针对特定领域的文本摘要生成。为了更细粒度地提取样本内容的语义特征,我们在样本中为每个句子的起始位置均插入[CLS],而非传统上只在每条文本前插入[CLS]符号。同时,在每句话的最后加入[SEP]标识来表明每个句子的结束边界。③为了识别文本中单词的前后依赖关系,我们在最后一层嵌入了位置向量层去传递模型相应单词的位置信息。

图1 预训练文本模型结构
通过上述分析,文本向量由三层嵌入层作为数据输入到初始化Transformer 模型中,并且运用上层的Transformer 层训练得到句子间的区分边界;通过关注句子的末尾特征,下层运用自注意力机制训练得到各文本之间的权重。在该模型中,我们同时考虑了BERT在对长文本的处理中带有最大长度为512 个单词的限制,因此在输入每个样本超过512 个长度情况下,加入了更多的位置向量并随机初始化。
1.2 基于迁移学习的文本摘要生成模型
基于数据预训练模型和改进的BERT 算法,本文提出的基于迁移学习的文本摘要生成模型如图2所示。

图2 基于迁移学习的文本摘要生成模型结构图
在自动抽取摘要的任务中,我们通常会将其看作一个Seq2Seq 的建模问题。假设每个输入数据文件以一串序列x={x1,x2,x3,x4,…,xn}输入至编码器中并生成一个连续的特征表示z={z1,z2,z3,…,zk},然后再输入至解码器中以单词为单位,通过自回归方式生成目标摘要y={y1,y2,y3,y4,…,ym},最后得到条件概率分布:p(y1,…,ym|x1,…,xn)。
本部分的编码器为上一节提到的预训练文本模型,首先使用源域数据对编码器进行预先训练,提取相似特征的全连接层进行模型迁移;其次,进行细粒度调整隐层权重矩阵;最后,加入医学领域的数据进行参数微调使其更适合目标域数据。
本部分的解码器为六层随机初始化的Transformer模型,由于编码器是已训练的参数值,而解码器参数是未设置的初始默认值,则在进行模型训练时,参数调整幅度的不匹配会导致微调效果不稳定,故在本文中我们使用了两个不同的Adam 优化器去解决这个问题,使前者编码器训练的步长较小而后者解码器训练的步长较大。

图3 随机初始化的Transformer模型结构图
如图3 所示为一层的Transformer 结构图。在得到了输入的特征向量后,叠加标识位置的嵌入层,并将其输入至编码器中;训练集中的标签文本即标题转为词向量后加入位置嵌入层后进入解码器,其中解码器一共由三个部分组成,即由两层多头注意力机制和一层前馈网络构成。当经过第一层多头注意力机制[4]后,我们即可通过不同序列位置的不同子空间的特征信息进行序列处理,并将其结果与编码器生成的特征向量共同进入第二层多头注意力机制中。最后通过前馈神经网络的线性映射得到词库的概率分布。
在如图2 所示的词库概率分布模块中,以y2举例进行说明。首先选取词汇中概率分布最高的单词;其次,根据前序单词y1影响参数与词库生成单词的概率p2的参数加权求和得到y3,以此类推;最后,输出结果即为生成式文本摘要。同时在图3 的模型结构中,每层注意力机制与前馈网络后均有归一化层以减小过拟合对训练效果的影响。
2 实验结果
2.1 实验数据
本文采用普华永道RegRanger 项目中医疗引擎后台数据库中的新闻文章作为目标领域数据集,该数据集共包含四千条数据,数据集内容为医学领域法律条款、文献指导和新闻类英文文本。同时,RegRanger 本身包括了500 条相关法律信函。我们在对该数据集的预处理中,考虑到警告信函、医学法规等具有特定文本格式的数据文本的标题位置相对固定唯一的特点,其均位于文章第一段的内容中。由于本文的目的为基于文本自身文意得到更常语化的标题表达,我们剔除了该部分具有特定文本格式的数据文本并保留了有效的文本数据即内容非空或内容可追溯的文本。本文首先使用斯坦福核心NLP 工具包OpenNMT 对实验数据进行预处理,这样每个输入文本被分块并被截断为长度是512 的输入数据。具体数据集分布信息见表1。

表1 实验文本数据集分布
根据表中数据集标题的特点,本文将模型的生成摘要标题的长度设置为10。本文的测试环境为Linux,NVIDIA GTX 1080Ti GPU。模型的实现基于Pytorch 深度学习框架,版本为1.3.1,开发环境为Ubuntu18.04,Python 版本为3.7.4,模型支持多GPU 多线程进行。
2.2 评估指标
本文将使用一种广泛被认可的评估工具ROUGE[2,7]对所提出模型的性能进行评价。在自动评估机器生成的标题与人工标题的相似度的任务中,ROUGE 包含了五种评估方法,分别是ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-S 和ROUGE-SU。本文仅使用ROUGE-N 和ROUGE-L 评测。
(1)ROUGE-N 通过N 元模型计算生成摘要和人工摘的召回率去评判匹配度,其表达式如下:

其中N 表示N 元模型的长度,Countmatch(gramn)表示在一个生成摘要元素和一系列人工摘要元素共现的最大数目,Count(gramn)表示人工摘要元素中n 元模型的数目。
相对应的ROUGE-1 即仅考虑单个单词,生成式摘要和人工摘要都出现的个数与人工摘要的单个单词之比,同理ROUGE-2 为两个单词作为两元标识进行两者比较计算。
(2)ROUGE-L 通过计算生成摘要和人工摘要的最长相同子序列的比率去评测,其表达式如下所示:


其中 |R|和 |S|分别表示人工摘要与生成摘要的长度,LCS(R,S)表示二者的最长共同子序列的长度。PLCS(R,S)表示LCS(R,S)的精准率,RLCS(R,S)表示LCS(R,S)的召回率,β为精准率与召回率的比值。本文主要使用ROUGE-1、ROUGE-2、ROUGE-3 以及ROUGE-L 评估模型生成摘要的效果。
2.3 实验结果
本文中,我们在给定的样本数据集上进行实验,并使用标准的Seq2Seq 模型、基于迁移学习的模型以及基于迁移学习的预训练模型与Seq2Seq 融合的模型进行了摘要生成任务,并通过Rouge-F 和Rouge-R 对上述三种模型进行了对比,结果如表2 所示,其中迁移学习思想所达到的跨领域同参使相似度得到了明显的提升,同时预训练模型的结果在此任务中也达到了一定的提升。
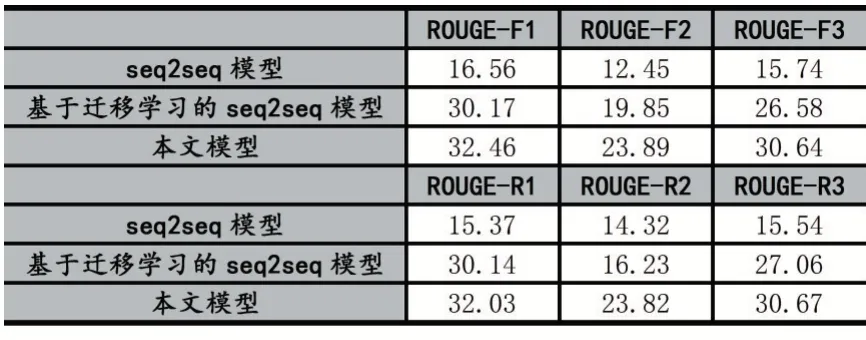
表2 原始模型、基于迁移学习的Seq2Seq 模型以及本文的实验模型对比结果
如 表2 所 示,我 们 使 用ROUGE-F1、2、3 和ROUGE-R1、2、3 分别表示F 分数和召回率在一元语法、二元语法与三元语法上的表现。基于迁移学习的Seq2Seq 的表现最优时相较原始Seq2Seq 模型在一元召回率上提升了14.77;同时,基于迁移学习的文本摘要生成模型相较基于迁移学习的Seq2Seq 模型在一元F 分数上提升了2.29。
本文提出的基于迁移学习的预训练与Seq2Seq 的融合模型的实验结果如表3 所示。
为了评估小规模样本集下所提模型中不同参数对实验结果的影响程度,我们对本文提出的模型做了多种参数的调试,同时应用在文本生成任务中。最终我们所选取的部分主要超参数如表4 所示。图5 为不同Batch size 设置下的实验结果。

表3 模型生成摘要文本与人工标注摘要的对比

表4 实验参数设置

图4 不同Batch size下在Rouge中的实验结果
如图4 所示,本文模型在Batch size 为200 时的表现最为优异。图5 为在输入文本中每个样本超过512个至1000 个长度并以随机初始化位置向量加入词嵌入层的模型与仅考虑前512 个单词作截断的模型进行对比得到的实验结果。

图5 对输入文本长度进行约束的模型在相似Rouge-F上的实验结果
图5 中Rouge-F’表示在考虑了前512 个单词的同时对输入文本第512 个至2000 个词以随机向量嵌入至位置嵌入层时模型在Rouge-F 中的评测结果。实验结果表明,基于迁移学习的文本摘要生成模型在加入输入文本的限制后在摘要生成任务的表现更为优异。从以上分析可知,在解决基于小规模样本的深度学习训练时,基于迁移学习对模型进行异域调参相较于仅单纯改善模型结构有更明显的优势,并且本文所提模型在医学文本摘要生成任务中的表现优于标准的基于迁移学习的Seq2Seq 模型,同时所提模型的实验结果与人工处理结果具有较高的匹配度。
3 结语
本文针对以医学为代表的特定专业领域小规模文本标题摘要难以阅读理解的问题,提出了基于迁移学习预训练与注意力机制的融合模型对原始文本进行自动生成标题摘要,主要贡献是在原有的Seq2Seq 模型中引入迁移学习思想,其可以使模型在彼此不同但又相互关联的两个领域间有效挖掘文本的本质特征和结构,实现了有监督参数信息在领域间进行迁移和复用;同时,文本采用了预训练模型作为编码器,在句子前端加入[CLS]以便更精准地得到每个句子的特征,这可以使专业领域知识进行细粒度的特征化表示。综上所述,本文所提模型有效地解决了专业领域标题简易化以及小规模样本不足以支撑现有机器学习模型训练的难题,这对于基于自身文本得到更常语化的标题摘要具有重要的指导意义。
