跨模态检索在食物计算里的研究进展
2021-03-24蒋国芝左劼孙频捷
蒋国芝,左劼,孙频捷
(1.四川大学计算机学院,成都610065;2.上海政法学院,上海200000)
0 引言
随着人们生活水平的不断提高,人们对健康以及饮食的关注度也日益增长。由于美食网站的涌现,如下厨房,美食杰等,食物相关的研究也受到了越来越多人的重视。由于这类美食网站是对任何注册用户开放的,对于食谱描述以及食物图像都没有要求与限制,所以这类网站的食谱描述不一定准确详尽,食物图像也不一定和食谱描述最后生成的一致。因此食物计算(Food Computing)[1]中的一个重要子领域就是跨模态检索(Cross-Modal retrieval)。跨模态检索是以一种模态的数据检索得到另外一种模态的数据,这两种模态的数据是异质,在跨模态检索在食物计算里面,是以食物图像检索烹饪食谱或者以烹饪食谱检索食物图像。
1 相关工作
食物计算对生活、日常行为、健康、文化、农业都有深远影响。食物计算从不同的数据源(如社交网络、食谱网站、相机等)以不同的方式获取并分析异质食物数据,以进行食物的感知、识别、检索、推荐、监控等任务。食物相关的数据类型可以分为美食照片、食谱标题、食物成份、烹饪指示、食物类别、食物风味,食物日志、餐馆相关的食物信息等[1]。食物计算的总体框架如图1 所示。
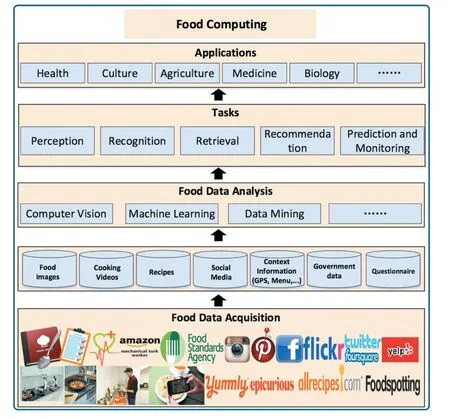
图1 食物计算总体框架[1]
随着多媒体数据的快速增长,食物相关的搜索引擎对于获得所需的食物信息是必要的。跨模态检索是食物计算里面的一个重要子领域。该领域任务用到食物数据类型有食物图像以及食谱(食谱包含了标题、成份、烹饪指示、类别),该任务的目的是用食物图像检索得到菜谱信息或者使用菜谱检索得到食物图像,目前跨模态菜谱的方法有JE[2]、ACME[3]、DUCP[4]、AdaMine[5]、SAN[6]等。
2 跨模态检索
跨模态检索问题是以一种类型的数据作为查询来检索另一种类型的相关数据,例如使用图像和视频之间进行相互检索,图像和文字之间进行相互检索等。跨模态检索中大多使用成对的数据,跨模态检索由于检索的数据是异质,特征难以对齐,因此该领域需要解决数据对齐和相似性度量问题。数据对齐分为全局对齐和局部对齐,全局对齐的典型代表的方法有CCA[7],DCCA[8]、KCCA[9],局部对齐的现有方法有:C2MLR[10]、DFE[11]、HM-LSTM[12],相似性度量是通过学习得到可以使得异质的数据模态分布一致的公共子空间,计算相似性判断他们之间的距离,最后通过排序得到检索结果。在度量相似性时,常用的损失函数有排序损失(Ranking Loss)、对比损失(Contrastive Loss)、三元组损失(Triplet Loss)等。
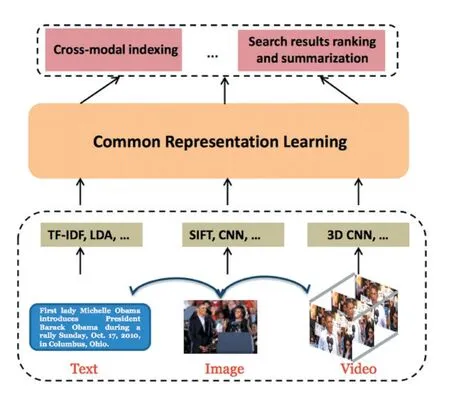
图2 跨模态检索通用框架[13]
2 研究进展
2.1 基于Attention机制的跨模态检索
2014 年Google Mind 在团队在使用Attention 机制进行图像分类[14],Attention 机制基于一个假设,人类只关注整个感知空间的特定部分,即观察一个事物或者图像的时候,会对不同的区域投入不一样的关注度。在食物计算领域使用Attention 机制的进行跨模态菜谱检索的方法有DUCP[4]、SCAN[6]、MCEN[15]、PROTEIN[16]、SAM[17]等。DUCP 认为食品准备过程涉及到原料成份、器皿、切割和烹饪操作,烹饪过程的描述是隐式的,因此提出使用层次化的注意力机制对食谱中的标题、成份以及烹饪指示进行建模。SCAN 和SAM 均使用自注意力机制对菜谱文本部分进行建模。不同的是SCAN使用LSTM 对菜谱文本进行特征提取,在特征提取之后使用自注意力机制学习文本中的显著特征,并且用KL 损失函数改善图像食谱的匹配度并使不同分类器预测的概率保持一致;SAM 使用基于Transformer 网络的食谱文本编码器,改进了传统方法注意力机制的环境向量选取方式。MCEN 结合随机潜在变量显式地捕获文本和视觉特征之间的相关性来得到模态一致性的embedding,使用层次化的注意力机制对食谱进行特征提取,利用潜在变量在训练过程中将跨模式注意机制纳入检索任务。PROTEIN 中首先利用并行注意力网络来独立学习图像和食谱中的注意力权重,再使用跨注意力网络学习图像和食谱之间的相互作用。
PROTEIN 是基于parallel-and cross-attention 的一种方法,该方法认为食物成份对跨模态食谱检索任务的贡献均不相同,且图像和文本是作为独立通道em⁃bedding 到公共子空间的,不足以捕获图像图像和食谱之间细微的相互作响,图像和食谱的embedding 由于独立的建模在,因此如何有效地发现不同embdding 的重要性成为了要解决的问题。为了解决以上问题,使用parallel-attention 网络分别调整图像和食谱中各组分的注意权重。使用cross-attention 网络发现图像区域和单词之间的对齐方式,并进一步推断图像和食谱之间的相互作用。使用pair-ranking loss 连接并优化来自parallel-attention 和cross-attention 网络的图像和食谱的embdding。
(1)Parallel-attention 网络
图像区域隐藏状态和背景信息作为输入数据计算image-channel 的注意力权重αj,n为:
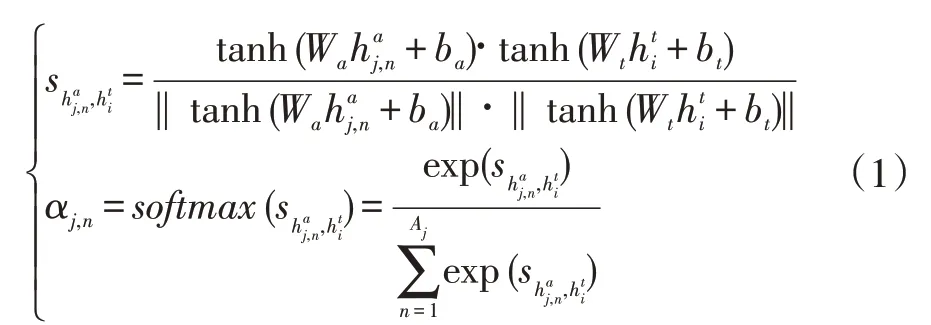
食物图像的表示由图像区域所有已转换为隐藏状态的加权总和来构造:
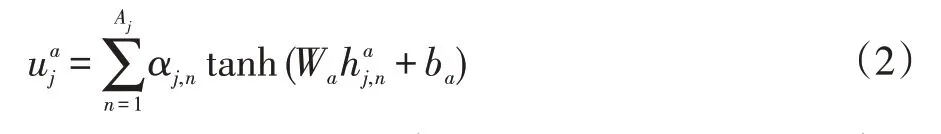
Recipe-channel 的注意力和image-channel 相似,表示为:

Recipe 的特征表示由所有转换后的单词隐藏状态的加权总和来构造:
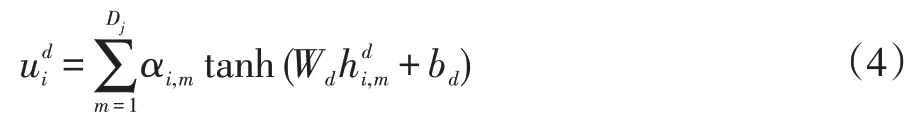
(2)cross-attention 网络
cross-attention 网络能够对图像区域和单词之间的相互作用进行建模。
①单词指导图像
第i 个食谱说明的第m 个单词的第j 个图像的第n 个图像区域的相似度表示为:
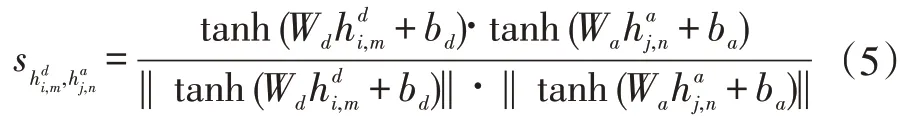
关于第i 个食谱说明的第m 个单词的第j 个图像的第n 个图像区域的注意力分数表示为:
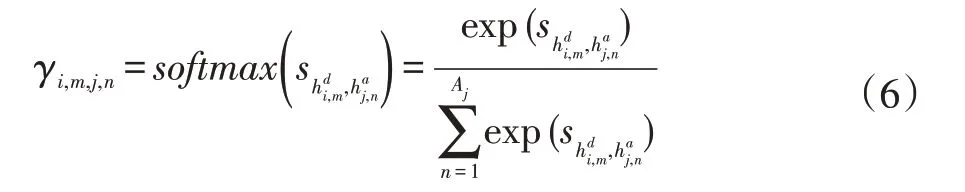
第i 个食谱说明中第m 个单词的第j 个图像表示形式是图像区域所有已转换隐藏状态的基于注意的组合表示为:
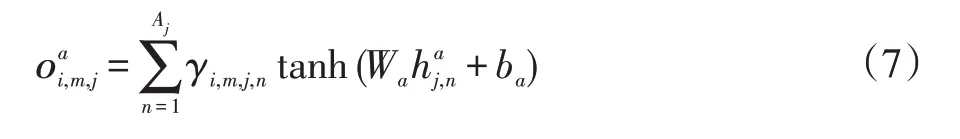
整个图像的矢量表示:

②图像指导单词
第i 个食谱说明中第m 个单词相对于第j 个图像的第n 个图像区域的注意力分数表示为:
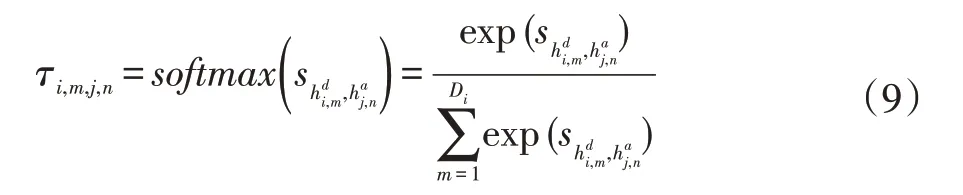
关于第j 个图像的第n 个图像区域的第i 个食谱描述的表示形式是单词的所有已转换隐藏状态的基于注意的聚合,表示为:

多模式融合模块首先用超参数λ平衡两个注意力网络的重要性,输入是来自并行注意网络(即和)和交叉注意网络(即和)的学习结果的嵌入。融合策略表示为:

其中xi表示食谱,yj表示图像,cos(∙ ,∙)表示余弦相似度。
2.2 基于GAN的跨模态检索
Ian J.Goodfellow 等人于2014 年10 月提出了一个通过对抗过程估计生成模型的新框架[18]。GAN(Gener⁃ative Adversarial Networks)由生成器G 和判别器D 组成,训练生成器G 捕获真实数据分布pdata并生成伪造的图像,以欺骗识别器D。另一方面,识别器D 被训练以区分真实和伪造图像。G 和D 玩一个minmax 游戏来优化以下目标函数:
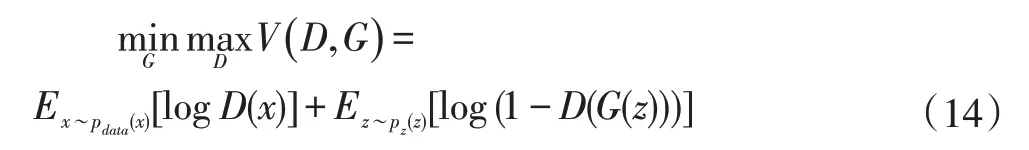
其中x为pdata数据分布的真实图像,Z 是具有先验分布pz的噪声。在食物计算领域的跨模态检索任务中,使用对抗网络的有ACME[3]以及R2GAN[19]。在AC⁃ME 中使用hard-example mining 采样策略,来决解trip⁃let loss 难以迅速收敛的问题,使用GAN 网络来对齐不同模态的特征,使以使烹饪食谱和食物图像的特征分布无法区分。在R2GAN 中,认为烹饪指示暗示着某种烹饪的因果关系并且跨模态检索本质是无法解释的,该文章使用GAN 网络实现了从文本生成图像证明了包含某种因果关系并也使食谱生成的图像来解释搜索结果。
在R2GAN 中,使用一个生成器,和两个判别器来学习兼容的跨模态特征,并且可以显示的从食谱生成图像来解释搜索结果。总的损失函数表示为:

其中γ和λ为权衡的超参数,Lrank两级的triplet loss,函数表示为:
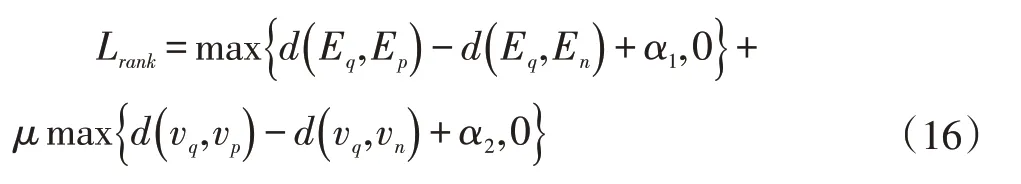
其中d(.,.) 表示测量给定查询与候选对象相似度的距离函数,其中(Eq,Ep)表示正的embedding 对,(vq,vp)表示相应的图像对,一对数据分别属于不同的模态,α1和α2表示正负样本之间的边界,μ表示权衡的超参数。
Lrecon是考虑了特征和图像级别的两级损失,可以使重构图像保留尽可能多的原始图像信息。该函数表示为:
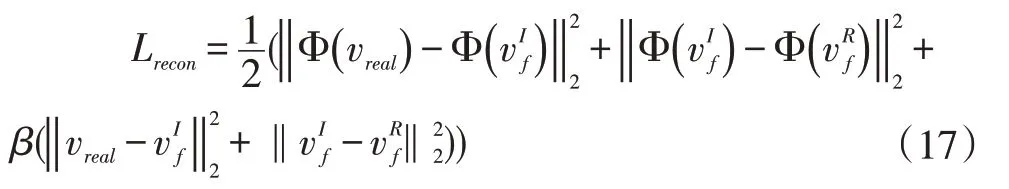
Φ(.) 表示输入图像的特征提取器,vreal表示真实的食物图像表示从图像和菜谱embedding 重建的图像,Φ(v1)-Φ(v2)表示特征级别的损失,v1-v2图像级别的损失。
Lsem表示语义损失,表示为:

Ec表示图像或者食谱的embbding 种类。
生成器的参数是由对抗损失和重建损失来进行更新,损失函数表示为:

其中Lrecon同上面公式一样,其中LG的公式计算如下:
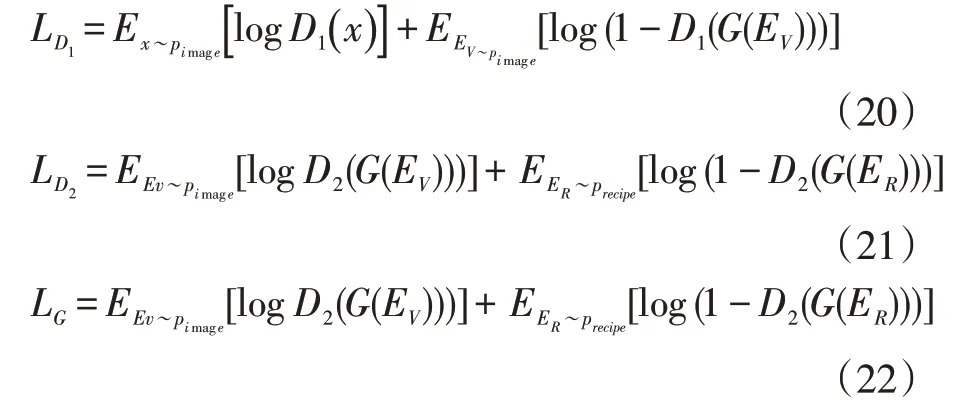
其中LD1和LD2分别表示辨别器1 和辨别器2 的损失函数,EV和ER分别表示图像和食谱的embedding特征。
3 结语
本文介绍了在食物计算领域,基于Attention 机制的跨模态检索和基于GAN 的跨模态检索,这两种的方法的相同点在于:他们都是实值特征学习方法,关注的点都在于提高模型的准确度。在提取图像和食谱特征时,都使用不用的网络分别对图像和食谱进行特征抽取。使用Attention 机制和GAN 都是为了使特征更好的对齐。不同的点在于:基于Attention 机制的跨模态检索使用了更细腻度的监督信息来使图像和食谱的特征得到对齐,损失函数仅使用Pairwise ranking,而基于GAN 的跨模态检索使用GAN 网络,利用文本的特征来生成食物图像,来证实了食谱包含因果关系,能够使图像和文本的特征更好得到对齐,也增加了网络的可解释性,也使用了多种损失函数来进行学习。从以上内容可以看出,跨模态检索在食物计算领域受到了广泛的关注,且在已发表的文献中呈现的实验效果也充分证明了跨模态检索在食物计算领域的有效性和进一步的研究价值。
