基于推理网络的人体动作识别
2021-03-23葛鹏花
葛鹏花,智 敏
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
0 引 言
人体动作识别是计算机视觉领域一个重要的研究方向,但由于人体动作比较复杂利用深度学习方法对人体动作进行识别仍然具有一定的挑战[1]。目前基于深度学习的人体动作识别方法主要是以CNN[2,3]、RNN[4,5]为基本框架或者两者相结合[6,7],并且取得了显著的成绩,文献[6]提出将视频建模为一个有序的帧序列,在CNN的输出端与LSTM相连以提取动作时序特征;文献[7]通过对输入信息和未来预测的信息相结合学习高级特征;文献[8]中提出双流CNN,对于视频图像和密集光流分别训练CNN两个分支,然后对两个分支的成绩进行融合得到分类结果;为了更好地利用时空信息,文献[9]提出了多个用于视频片段的时空融合方法;文献[10]通过构建长时间卷积网络进行评估实验,提高了动作识别的准确性。
大多数方法由于缺少来自交互对象的信息,在识别一些动作序列比较相似的任务中,识别结果还有待提高。为了改善视频中人体动作识别精确度,提出了基于推理网络的人体动作识别算法,主要创新点如下:①结合物体信息辅助视频动作识别;②改进Faster RCNN框架,通过加入LSTM指导下一时刻的边框回归以及提取人与物体的上下文信息从而对动作更精确的分类。
1 相关工作
在静态图像中目前有两种类型的上下文信息模型用于检测[11]。第一种类型是捕捉对象-对象间关系[11],第二种类型包含围绕对象或场景上下文的信息[11-14]。Liu Y等[15]将这两种上下文信息进行结合共同帮助检测,取得了很好的结果。而对于构建人与交互物体之间上下文关系的工作相对较少,Gkioxari G等[12]根据人体姿势以及周围物体和环境信息在静态图像中对人体行为进行分类。
人体动作识别相比于静态图像的识别较为复杂,在视频动作分析方面有部分研究者通过对人和物体之间的交互信息进行上下文建模,然后对人类行为进行预测[16-18],Koppula HS等[16]提出使用图形模型来表示状态空间,通过低层次的运动学和高层次的意图来对人类行为和物体之间的交互活动进行建模,使得训练的模型能够预测人类下一步的行为。随后Koppula HS等[17]通过建模获取人与物体以及周围环境的上下文信息来预测人类下一步要进行的活动。为了结合深度RNN的序列学习能力和时空图的上下文信息,Jain等[18]提出用于人-物交互问题的结构化深层RNN,将人与物体表示为图结点,边表示为人与物体的交互关系,其中结点和边都采用RNN结构来学习它们之间的关系,在人体运动建模、人与人之间的互动、预测驾驶员下一步动作等任务都表现出很好的结果。
以上上下文建模的方法中,用于静态图像动作分类方法较少,用于视频分析的大多数方法都是对人与交互物体进行建模从而对人未来的行为进行预测,本研究与上述方法有所不同,通过将目标定位方法和LSTM相结合获取以人为主要区域以场景信息为附加区域改善识别效果。
2 算法结构
本研究的整体算法在Faster RCNN的基础上加入LSTM。LSTM通过获取RPN提取的候选框和人与物体的相关关系从而对下一时刻的输入数据进行边框回归以及动作分类。算法主要分为两大步骤(2.1节和2.2节),下面将对这两大步骤进行详细阐述。整体算法结构如图1所示。

图1 算法结构
2.1 Faster RCNN算法提取特征
本研究采用了经典的检测算法-Faster RCNN对视频的每帧中人体区域和与人体动作相关的附加区域提取特征,主要分为以下步骤:
步骤1 特征提取:首先利用在ImageNet上的预训练模型VGG-16得到输入图片的特征;
步骤2 选择候选框:在VGG-16的conv5之后添加RPN网络,RPN网络主要目的是在原始图像上产生候选框,这也是目标检测中最关键的一步。RPN网络通过学习相对参考boxes偏移量的方法来预测目标的边界框。假设以 (x0,y0,h0,w0) 为参考区域,则需要学习的偏移量为(Δx0,Δy0,Δh0,Δw0),其中x,y,w,h分别表示边框中心点坐标和边框的宽高。那么如何在原始图像中产生候选框呢?首先采用3*3的卷积核对特征图进行卷积操作,当滑动窗口滑动到某一位置时,以此时的窗口中心为中心映射到原图的图像像素空间的某一点(称为anchor),每一个anchor考虑k种可能的候选框,一般选择k=9:3种尺寸*3种比例 {1∶1,1∶2,2∶1},每个anchor通过softmax获得正样本(1)和负样本(0)的类标签,所以会分类层输出2k个得分,而每个候选框都有 (x,y,h,w) 4个参数化的坐标向量所以回归层会输出4k个得分,通过非极大抑制算法(NMS)从所有的候选框中选取固定数量的候选框参与训练。
步骤3 ①人体区域:对得到的候选框进行感兴趣池化(ROI),将其调整为固定大小的特征图,通过一个全连接层将其映射为特征向量,得到图片I中包含人区域r的特征向量;②附加区域:计算人体区域r与场景中其它感兴趣区域s(I) 的重合率,得到附加区域的一系列候选区R(r;I),通过参数设置可以将其设置为r的相邻区域的集合,也可设置为从整个图片随机搜索的区域(当l=0,u=1),然后将其送入全连接层,得到附加区域的特征向量。附加区域的定义用式(1)来表示
R(r;I)={s∈S(I)∶overlap(s,r)∈[l,u]}
(1)
步骤4 根据人体姿势以及附加区域(从附加区域候选框中选择得分最高的边界框)对人体行为α进行加权求和,得到最终的行为得分score,得分用式(2)来表示
(2)
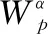
(3)
2.2 LSTM获取视频动作信息
由于视频中的人体动作是一系列连续的帧组成的,增加动作的时间信息就需要设计1种记忆机制对视频中每帧的上下文信息进行编码。LSTM是RNN的变体,为了解决长序列依赖的问题,LSTM中引入了单独的记忆单元,记忆可从上个时刻传递到下个时刻,而且记忆单元中加入了门控机制。门的主要结构是使用sigmoid神经网络,sigmoid通过输出一个大于0小于1之间的数值,来控制当前输入有多少信息量。
一个典型的LSTM单元包含输入门it,遗忘门ft,输出门ot,隐藏状态ht,以及内部内存单元状态ct。
LSTM的循环结构如图2所示。

图2 LSTM结构
将LSTM设置在候选框提取之后分类和回归层之前,是为了获得前一时刻的候选框信息以及感兴趣区域特征信息从而指导下一时刻边界框回归以及分类。LSTM更新过程与原始的LSTM类似如式(4)
it=σ(Wxixt+Whiht-1+bi)ft=σ(Wxfxt+Whfht-1+bf)ot=σ(Wxoxt+Whoht-1+bo)gt=σ(Wxgxt+Whght-1+bg)ct=ft⊙ct-1+it⊙gtht=ot⊙tanh(ct)
(4)
具体的LSTM的推理算法如下:
输入:两个区域的边框偏移量 (Δx0,Δy0,Δh0,Δw0) 以及区域特征向量Φ共同作为输入xt
输出:回归后边框偏移量以及多帧特征信息ot
信息更新及推理过程:
首先将状态h0初始化为0,t时刻的输入即为当前时刻候选框和特征信息xt,隐含状态ht-1为前一时刻的边框偏移量以及特征。遗忘门ft和输入调制门gt根据当前输入信息的重要程度和前一时刻的隐含状态对记忆细胞ct进行更新。然后再根据记忆细胞中的候选框和特征信息对此时的隐含状态进行更新,根据输出(ot)公式隐含状态能够指导下一时刻边框偏移以及新的特征信息更新,以此对下一时刻的候选框以及动作分类进行合理的推理。如图3所示,从左到右对视频中的边界框位置及动作进行推理。

图3 Faster RCNN+LSTM结构
其中ot指t时刻的一个N(B*5+S)+Φ张量,N是指经过非极大抑制算法筛选后得到的候选框数量。候选框B用一个五元组来表示 (Δx0,Δy0,Δh0,Δw0,c),其中Δx0,Δy0,Δh0,Δw0,c分别表示框的中心点坐标、宽、高的偏移量与真实标签的重合率,S=(Sac,Sbg) 表示正负样本的概率,Φ表示人和物体的特征向量。
在式(3)中得到归一化后的动作概率P(α|I,r) 用p*表示,网络中分类和回归函数的损失函数可以定义为式(5)

(5)


(6)
在上一步中得到视频中每帧的一系列边界框,并选择其中置信度最高的边框作为目标提取框B={i∈[1…T]},其中,T表示视频帧的长度,对于每个边框都有置信度Sc、动作概率Sac,然后LSTM将视频中所有与动作相关的区域整合起来进行并分类。
在实验中将连接起来的多帧信息被本文定义为式(7)
(7)
平衡参数λ0的引入是为了在训练过程中能够均衡考虑每帧置信度和帧与帧之间重叠率两种损失。由于LSTM最后一个隐藏状态融合了多帧视频中的所有特征信息,能够对时间级别动作进行分类并且Faster RCNN在空间级别每帧中都得到了一个动作分类的成绩(式(3)),通过对这两种结果进行加权求和得到分类结果,最终的分类结果被本文定义为式(8)来表示

(8)
式中:w1和w2分别表示动作类别的时间和空间权重,X1作为LSTM在时间上捕获的动作类别概率,X2作为Faster RCNN在空间上捕获的动作概率,X2取多帧概率相加的平均值。
3 实验与分析
实验中使用的配置为:CPU Inlel i7 8700K,内存 16 G,GPU NVIDIA-GTX1080Ti,Linux Ubuntu 16.04操作系统,使用TensorFlow深度学习框架,Python 3.6。
3.1 实验设置
实验中使用了两个公认的数据集。UCF-101数据集包含101类动作类别,13 000多个视频。在实验过程中首先使用一个子集,包含24个类别用于训练提取人与物体相关关系的任务。然后在测试集上进行样验证任务。HMDB-51数据集中包含51类动作,6000多个视频序列,主要来源于电影片段以及YouTube等网络视频库。这两个数据集像素较低,受光照、遮挡等因素影响具有一定的挑战性。UCF-101 数据集样本帧如图4所示。

图4 UCF-101数据集样本帧示例
首先用预训练模型VGG16参数对整个Faster RCNN+LSTM网络进行初始化,然后在UCF-101和HMDB-51数据集上进行微调。对整个网络联合训练,训练和测试过程中NMS选择2个图像和128个候选框,LSTM的神经元个数设为512。
3.2 实验结果与分析
本研究的动作识别方法从每帧图片获取人和物体作为主要区域并提取深度特征,然后经过LSTM,它的隐含层记忆了每帧中人运动特征信息和与人相关的物体的上下文信息,可以计算出动作类别识别准确率,以及动作的混淆矩阵。通过比较以上两个指标验证方法的有效性。
图5为网络对测试图片框选的人体区域和附加区域,其中实线框表示人体区域,虚线框表示附加区域。其中前两行为检测正确的示例图,后两行为检测错误的示例图,分别为蛙泳-仰泳,投篮-扣篮,倒立行走-倒立俯卧撑,拉锡塔琴-弹吉他。

图5 人体区域和附加区域检测
采取了其它方法与本研究方法进行了对比,由于本研究中采用的是加权平均的方式得到最终的结果,所以在对比过程中选取了较类似的融合方式。如表1中,文献[6]、文献[7]中都结合了LSTM。文献[8]中平均值融合方式与本研究方法对比。本研究采用VGG-16训练模型,故选取文献[9]中VGG-16中的late fusion方式进行对比。通过实验对比可以看出,本研究中加入人与场景信息的特征,实验结果相比于其它方法准确率有了一定的提升。
此外在实验中,我们对比较相似的16类动作,比如骑车和骑马、滑雪和滑板等进行了混淆度分析(如图6所示)。
从混淆矩阵(图6(a)、图6(b))中能够看出,加入人与物体的关系特征后,不同物体特征(马和自行车)对于比较相似的动作识别(骑马和骑车等)起到了一定的改善作用,但是具有同样物体特征(水)的相似动作(蛙泳和仰泳等)识别结果还有待提高。

表1 准确率对比

图6 混淆矩阵
4 结束语
针对比较相似的动作序列容易识别错误的问题,提出了一种基于推理网络的人体动作识别算法,算法结合目标定位技术学习人与物上下文信息。通过加入人体区域与附加区域的线索提高了一些比较相似动作的识别精确度。通过对比实验验证了算法的有效性,但是与直接对人体序列进行识别的算法相比仍然存在耗时的问题。接下来将进一步针对算法进行优化,以便实现算法的实时性。
