基于卷积神经网络的海洋地震勘探拖缆混采数据分离❋
2021-03-23童思友尹文笋
童思友,王 凯,尹文笋,胡 伟
(1.中国海洋大学海底科学与探测技术教育部重点实验室,山东 青岛 266100;2.青岛海洋科学与技术试点国家实验室 海洋矿产资源评价与探测技术功能实验室,山东 青岛 266237;3.中海石油(中国)有限公司上海分公司,上海 200335)
近年来,混合震源采集技术在海洋勘探中发展迅速,由于其高效的采集方式和高质量的地震数据,受到了广泛的青睐,其不仅极大地提高地震勘探采集的效率,增加空间采样率,还可以丰富方位角信息。混合采集的概念由Berkhout[1]于2008年提出,将同时源激发概念拓展到了非相干混合源激发,两个或多个震源采用同时或随机时间延迟后激发的方式。
混合震源采集在海洋勘探中有着天然的优势,Berkhout[2-3]于2010和2012年详细论证了混合震源采集技术在海洋勘探中提高采样率,获取宽方位的地震数据的优势。自2007年起,Chevron能源公司[4]、PGS公司[5]、BP公司[6-7]等相继进行了二维、三维海洋拖缆以及海底电缆和海底节点混合震源采集,证明了混合采集的优越性。2014年CGG[8]在印度尼西亚海域进行了宽频变深度缆混合震源采集试验,包括同时源和随机延迟源,并采用宽频处理流程,证明了混合震源采集和宽频采集的很好的兼容性,已经逐渐成为海洋拖缆采集新的趋势。
如何对混采数据进行有效的分离,是混合震源采集技术成败的关键。目前混采数据分离的方法主要分为两种:采用去噪的方法和稀疏约束反演的方法。
去噪的方法最早于2002年Vaage[9]在其专利中提出,将混采数据中的邻炮干扰作为噪声进行压制。大多应用中值滤波及改进后的算法,以及结合其他方法进行处理。如2012年Huo等[10]应用矢量中值滤波器、2013年韩立国等[11]结合多级中值滤波和Curvelet阈值去噪、2015年Chen[12]提出的基于空变的中值滤波技术等。
反演方法是将混采分离问题转化为通过迭代反演混合方程,加入一定的约束项,求解矩阵来估计未混合数据。在Radon域[13]、Curvelet域[14]、Wavelet域[15]和Seislet域[16]均有学者进行了求解。此外,2019年Li等[17]还借助了压缩感知理论,结合地表一致性混采分离以及利用非单调交替方向法实现多级迭代反演。
上述两种常规混采数据分离的方法均由多个步骤组成,为了确保混采数据分离的效果,需要经过多个流程、反复的进行参数测试,过程繁琐复杂,且需耗费较多的人力和时间。
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈式的神经网络,具有很强的表征学习能力,在图像、视频、语音和音频处理等方面都取得了重大突破。在地震勘探领域,已经在地震初至拾取、波形分类、随机噪声衰减、面波衰减、多次波衰减、速度建模、地震数据插值重构等诸多领域都取得了较好的进展。
应用CNN进行混采分离,已有一些学者进行了一些探索。如2018年Baardman[18]在合成记录上进行了分类和分离试验,2019年Slang[19]在共检波点域进行分离试验,Sun[20]设计了神经网络模型,对海洋拖缆资料进行分离,Zu[21]构建了卷积和反卷积神经网络进行混采分离。
本文进一步对CNN混采分离进行研究,构建了一种适用于地震数据处理的神经网络模型,并用于拖缆数据混采分离。构建的神经网络模型由输入层、卷积层、批标准化层、激活层和输出层构成。通过制作混采数据样本集,将共检波点域的混合震源采集数据作为输入,将未混合的数据作为网络模型的输出,进行神经网络的训练,用于更新神经网络的参数,获取混采分离模型。在测试集中进行了混采分离试验,并与常规混采分离方法进行了对比,验证了本文方法的有效性和优势。
1 CNN基本原理
卷积神经网络属于包含卷积运算,且具有一定深度的前馈神经网络,最主要的几个特点,卷积、池化、稀疏连接、权值共享和多层网络层,具有很强的表征学习能力。
典型的卷积神经网络结构由一系列阶段构成,前面阶段主要由两种类型的层:卷积层和池化层所构成。卷积层单元被组织在特征图中,每个单元通过滤波器的一组权重,连接到上层特征图的一个局部块。局部加权会传向给非线性函数,同一个特征图中的所有单元共享相同的滤波器。所包含的层可概括为输入层、隐含层以及输出层,其中卷积层、池化层和全连接层为隐含层部分,其典型拓扑结构如图1所示。
图1 卷积神经网络典型拓扑结构Fig.1 Typical topology of convolutional neural network
2 CNN混采分离架构
混合震源采集数据在共炮域中,主震源和相邻震源在振幅和倾角上都具有相似的特征;而在共检波点域中,混叠噪声呈离散分布,有效信号依旧是连续的,混叠噪声的特征更为明显,因此选择在共检波点域进行神经网络的训练和学习,效果更加理想。通过制作混采数据样本集,将混合震源采集数据作为输入,将未混合的数据作为网络模型的输出,用于更新神经网络的参数,进行卷积神经网络的训练,获取混采分离模型。
将混合震源数据的地震信号表示为:
y=x+n。
(1)
式中:x为纯净信号;y为混合震源采集地震信号;n为混叠噪声。通过神经网络可构建出x和y之间的关系,Θ表示神经网络的参数。
x=Net(y;Θ) 或y-x=Res(y;Θ)。
(2)
地震信号的处理与计算机图像处理有很高的相似性,可借鉴其处理方式,但同时也需特别注意地震信号的独特性。
(1)图像处理中通常是彩色(RGB),在CNN中的输入为三通道,而地震信号图像仅有灰度这一单通道。
(2)地震信号中每一列的信息代表时间采样点,需遵循采样定理,若按常规图像处理的方式进行池化,容易造成信号的损失以及产生空间假频。
(3)地震信号的动态范围通常较大,特别是叠前数据,一个道集内振幅差距至少达到三个数量级。
结合这些特性,构建神经网络模型,确定处理流程,具体流程如图2所示。
构建的卷积神经网络模型中,包括输入层,隐含层和输出层,隐含层主要由三种网络层构成:卷积层、批标准层以及激活层。
卷积层中,卷积核大小选用了3×3的尺寸。较大的卷积核,也就意味着较大的感受野,获取到的信息也就越多,因此能够获得更好的特征,但大的卷积核,导致参数量巨大,计算量倍增,影响计算性能且不利于模型深度的增加,因此选用3×3的卷积核进行组合,是更优的选择。
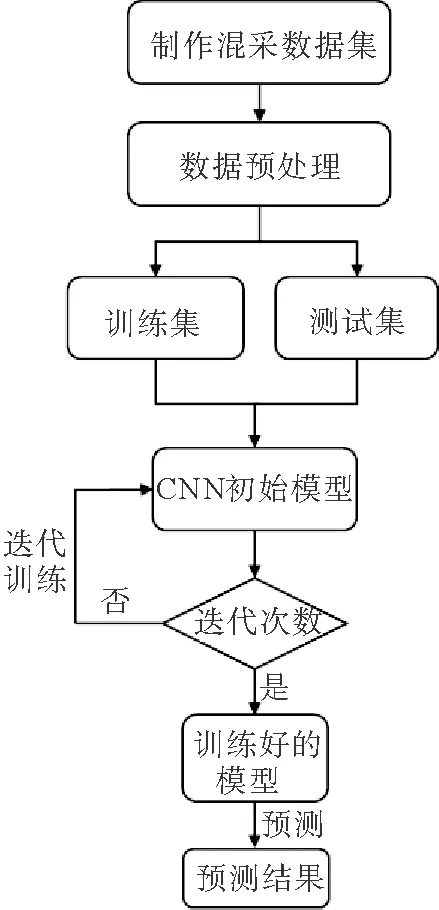
图2 处理流程图Fig.2 The processing flow diagram
批标准化层(Batch Normalization)即BN层,通过将标准化作为模型体系结构的一部分,并对每个用于训练的小批次执行标准化。能够解决随着前一层参数的变化,各层输入分布发生变化的问题,且减少了Dropout层的需求,大大降低了调整参数的难度。
激活函数采用ReLU函数,在正区间上解决了梯度消失的问题,能够明显加速神经网络模型的收敛。
池化层可以降低优化难度和参数量,但不可避免的会带来误差,导致信息和学习表征能力的模糊化。根据地震图像与静态图像的差异,本文在神经网络模型构建中,为了减少地质数据模糊和丢失的风险,未按照常规CNN的方式添加池化层。
构建的混采分离网络模型示意如图3所示。
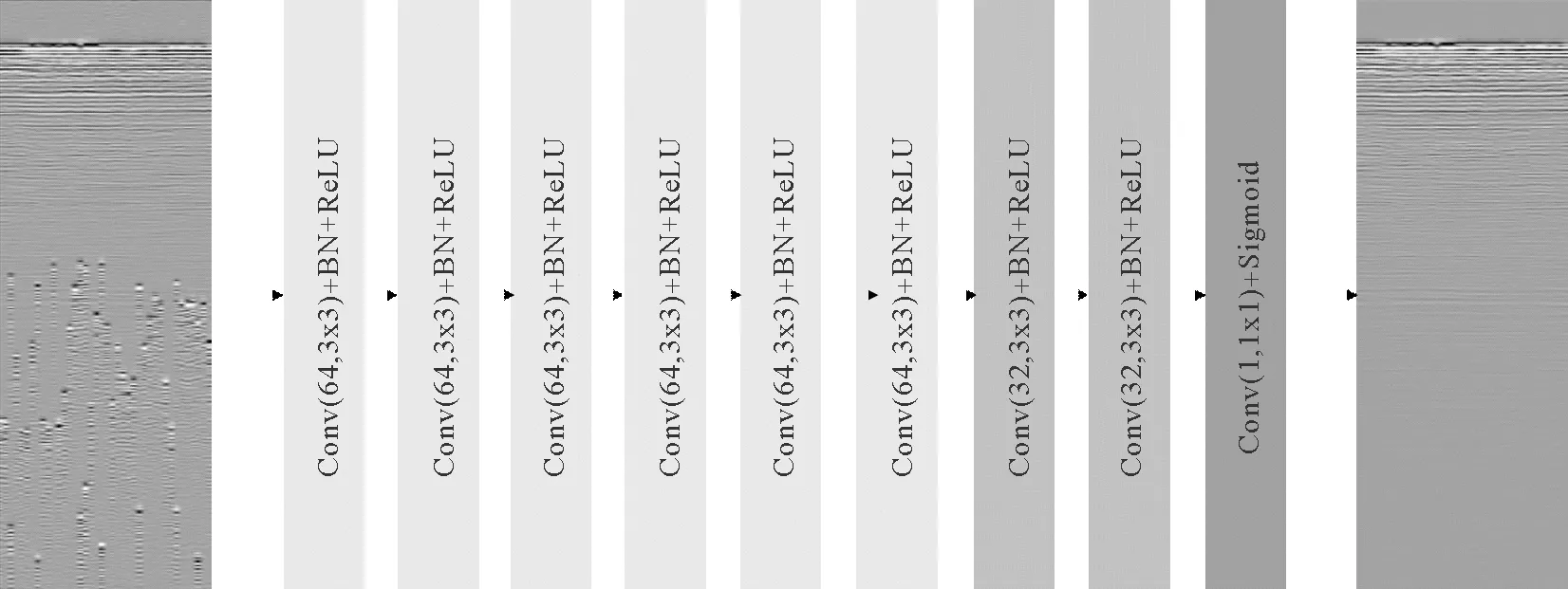
图3 混采分离网络模型示意图Fig.3 Schematic diagram of deblending network model
3 应用实例
深度学习是基于数据驱动的,数据集的质量一定程度上决定着训练的成败,因此数据集的制作尤为关键。
本文应用了东海某区域的拖缆数据,选用原始未混合的数据3 600炮,截取了4 s的记录长度,模拟双源交替激发的方式对拖缆数据进行数值混叠。对第N+1炮的激发延迟时间设置为1 s,并添加±0.2 s范围内的随机抖动。将混叠后的数据分选到共检波点域后,切割为2 000×40的大小(即2 000个样点、40炮,通过切割到较小的大小以获取到更多的样本),总计21 600个样本。将未混合单震源数据,同样也转到共检波点域,做相同的处理,切割到2 000×40的大小,与混叠处理后的混采数据共同组成数据集,并按照8∶1∶1的比例分为三部分:训练集、验证集和测试集。应用训练集训练神经网络模型,根据预测输出与真实值的差异,调整网络参数权值和偏置;通过验证集的最佳拟合情况,确定最终的模型参数;最终将独立测试集,应用到训练好的模型中,来检测网络的性能。
由于地震信号的振幅分布范围很大,直接输入进行训练,某些较大的值会对模型产生不利影响。因此在训练之前,需要先对数据集做归一化预处理,将数据值的范围限定到一定区间内,避免因奇异样本数据带来梯度方向偏离等不良影响,使某些激活函数的梯度不至于过小,从而加快收敛,缩短训练时间。
本文选择应用下式将数据归一化到[0,1]区间内。其中:max和min分别代表混采数据和真实数据之间的最大值及最小值。
(3)
(4)
归一化的过程是可逆的,根据卷积神经网络训练得到的模型,获得预测结果后,再进行归一化的逆过程,即可得到最终混采分离结果。
predictdenorm=predictnorm×(max-min)+min。
(5)
超参数是在模型训练初始便需要人工设定好的,根据经验设定,且需要通过训练进行优化,选出一组最优超参数。本文经前期的试验探索,最终将主要的超参数设定如下:
代价函数采用了L2范数。由于其处处可导,求解效率高,更容易收敛,解的稳定性也更好。
(6)
通过最小化标签数据与预测数据之间的L2损失,来拟合预测数据,选用Adam优化器来进行优化。学习率是需要预先设置的一个最主要的超参数。顾名思义,学习率代表学习的速率,决定着能否收敛以及何时能够收敛。较小的学习率收敛过程会十分缓慢,而较大的学习率会导致梯度在最小值附近震荡,难以收敛。因此,及时的调整学习率是对于保证训练的效率的极为关键。
本文经前期的大量试验后,设定学习率初始值为0.001,每经2次迭代缩小到原来的0.9倍。Batch size设定为40。Batch size指单个批次训练所需的样本量,每次从总体样本中随机选取。通常情况下,较大的Batch size能够增加梯度的准确性,减少震荡,因此在显卡显存允许的情况下,Batch size应设定的尽量大。
经前期的试验,进行了50个epoch的训练,共用时4.3 h即达到了较好的收敛,loss值随epoch的变化趋势如图4所示。
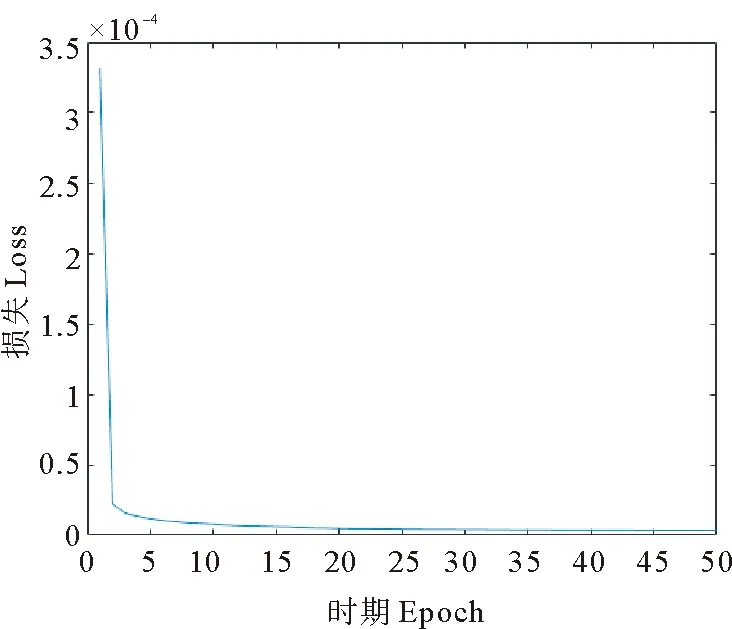
图4 Loss变化曲线Fig.4 Loss curve
上述测试所采用的硬件设备如下:CPU采用E5-2603,1.70 GHz;GPU采用Nvidia GeForce GTX 1080 Ti显卡、11G显存; 64G内存。
将训练好的模型,在测试集中进行预测,获得共检波点域混采分离效果如图5所示。
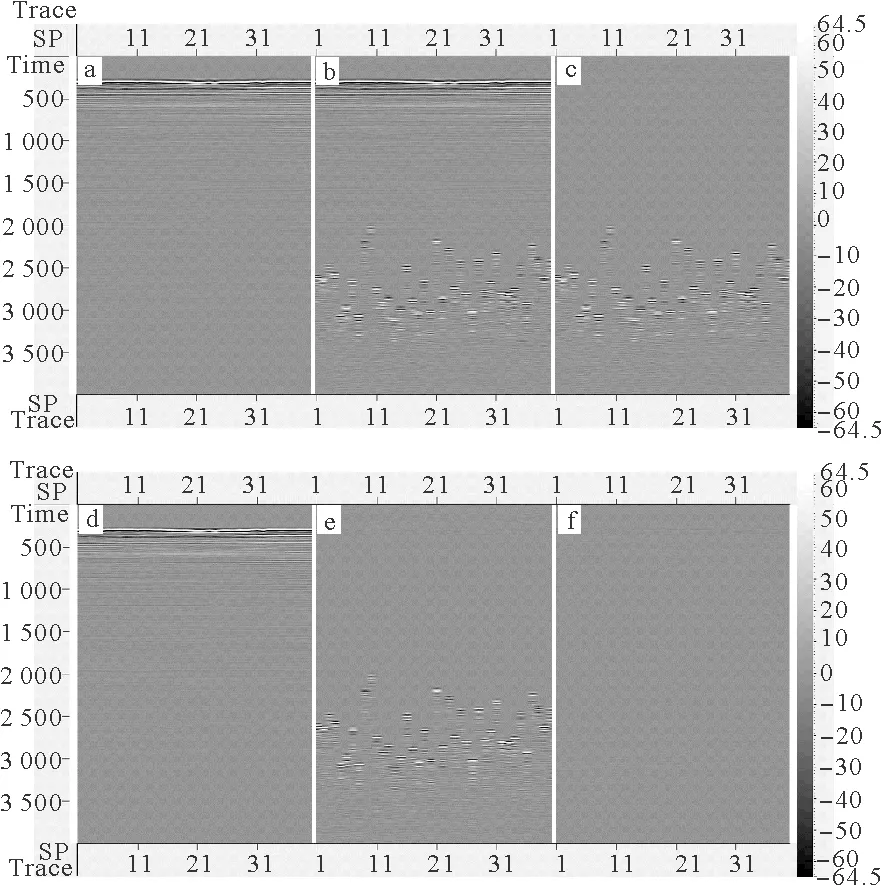
(a:未混合数据;b:混合震源数据;c:混叠噪声;d:CNN混采分离结果;e:CNN分离掉的混叠噪声部分;f:CNN混采分离结果d与未混合数据a的残差。 a: Reference unblended data, b: Blended data, c: Blending noise, d~f: Deblended data, removed blending noise and the difference between unblended data and deblended data using the CNN.)
从图中可以看出,混叠噪声得到了很好的分离,原始未混合数据和CNN预测结果的差异中,可以看到残差值很小,证明了CNN混采分离的有效性。进一步将共检波点域的混采分离结果再分选回到共炮域显示,如图6所示。

(a:未混合数据;b:混合震源数据;c:混叠噪声;d:CNN混采分离结果;e:CNN分离掉的混叠噪声部分;f:CNN混采分离结果d与未混合数据a的残差。 a: Reference unblended data, b: Blended data, c: Blending noise, d~f: Deblended data, removed blending noise and the difference between unblended data and deblended data using the CNN.)
在共炮域同样可以看到混合震源数据得到了高精度的混采分离。进一步对图6中局部区域进行放大显示的结果(见图7)表明,混叠区域部分邻炮记录得到了很好的分离,混叠部分的有效信号得到了很好的恢复。CNN混采分离结果图7d与未混合数据图7a的残差很小,只剩余微弱的残差(见图7f),CNN混采分离获得了高精度的结果。
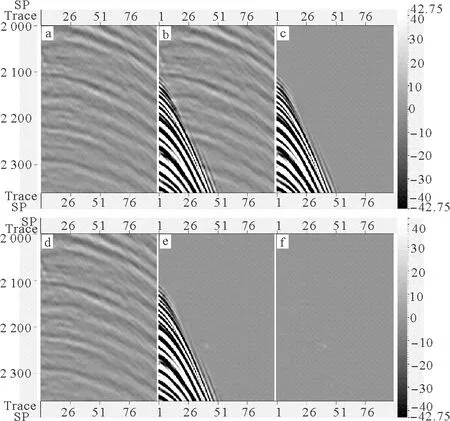
(a:未混合数据;b:混合震源数据;c:混叠噪声;d:CNN混采分离结果;e:CNN分离掉的混叠噪声部分;f:CNN混采分离结果d与未混合数据a的残差。a: Reference unblended data, b: Blended data, c: Blending noise, d~f: Deblended data, removed blending noise and the difference between unblended data and deblended data using the CNN.)
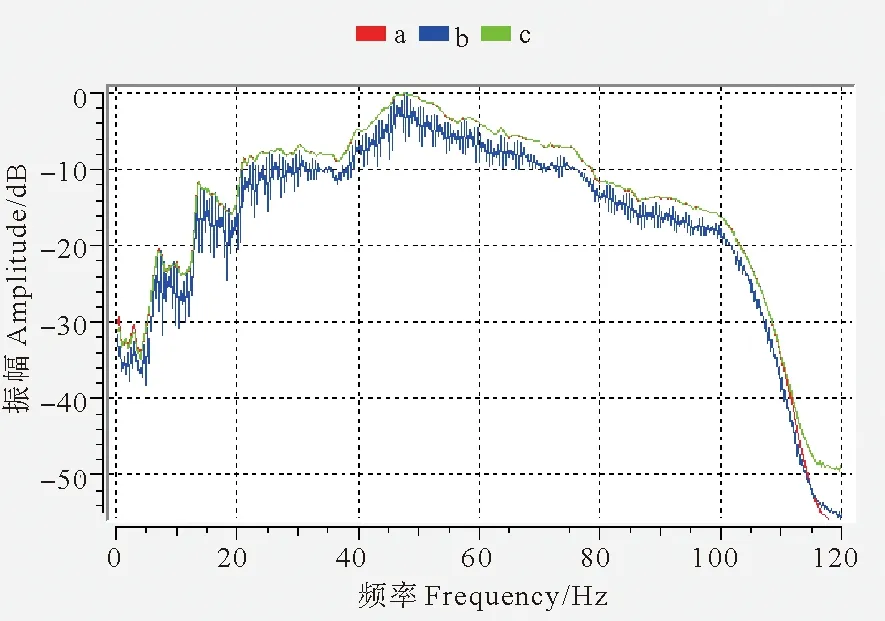
对混采分离结果和原始未混合数据做频谱分析,二者的频率曲线高度重合,进一步证明了CNN混采分离的效果,没有伤及有效信号。
将CNN混采分离的结果与常规中值滤波的方法比较,相较常规方法的结果,优势更加明显,混采分离的精度更高。如图9中箭头所示,CNN方法比常规方法对有效信号的保护能力更为优秀。在混采分离结果与未混合数据的残差中,通过CNN的方法获得的分离结果残差更小。在图10局部放大显示中,可以更加清晰的看出这一点,表明CNN的方法对有效信号的保护更好。
(a:未混合数据,b:混合震源数据,c:CNN混采分离结果。a: Reference unblended data, b: Blended data, c: Deblended data using the CNN.)
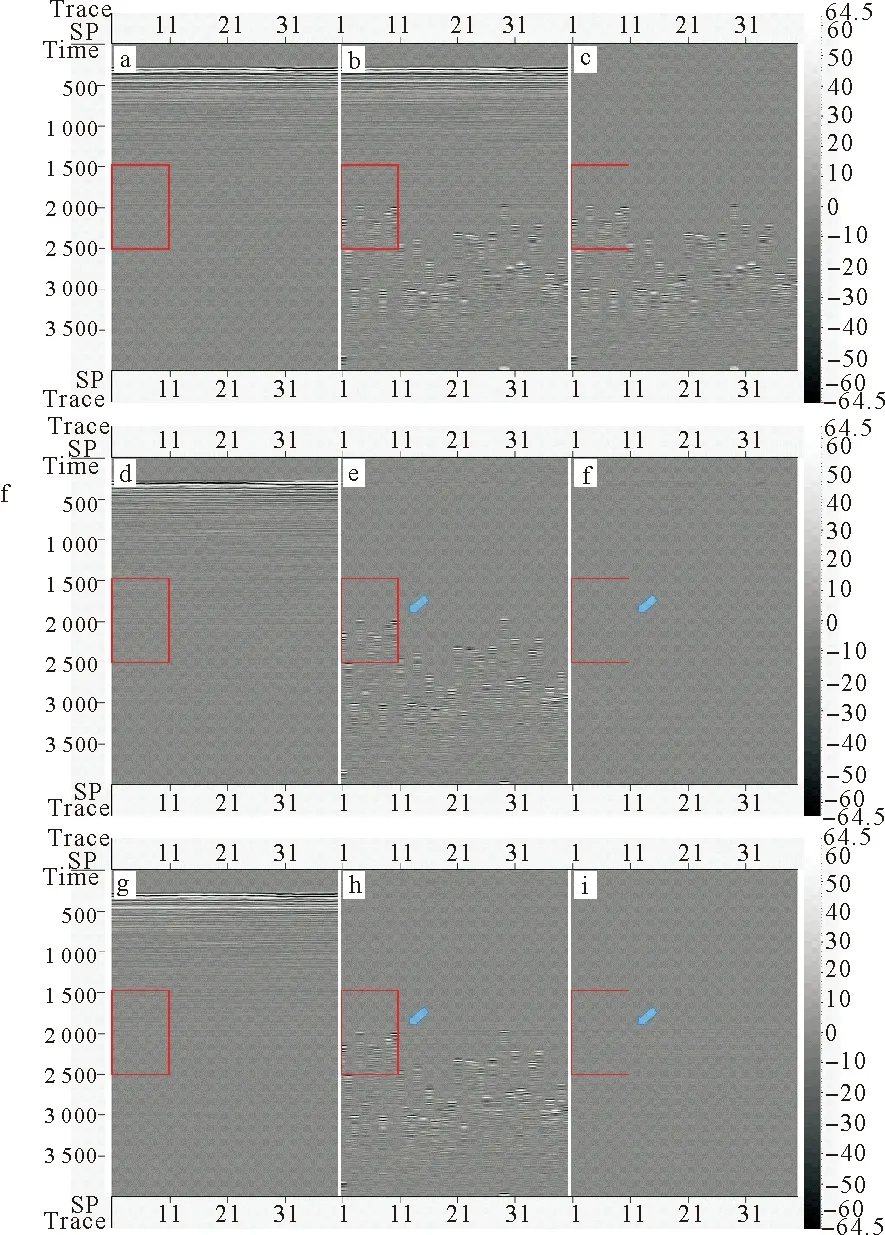
(a:未混合数据;b:混合震源数据;c:混叠噪声;d:CNN混采分离结果;e:CNN分离掉的噪声;f:CNN混采分离结果d与未混合数据a的残差;g:常规方法混采分离结果;h:常规方法分离掉的噪声;i:常规分离结果g与未混合数据a的残差。a: Reference unblended data, b: Blended data, c: Blending noise, d~f: Deblended data, removed blending noise and the difference between unblended data and deblended data using the CNN, g~i: Deblended data, removed blending noise and the difference between unblended data and deblended data using the conventional method.)
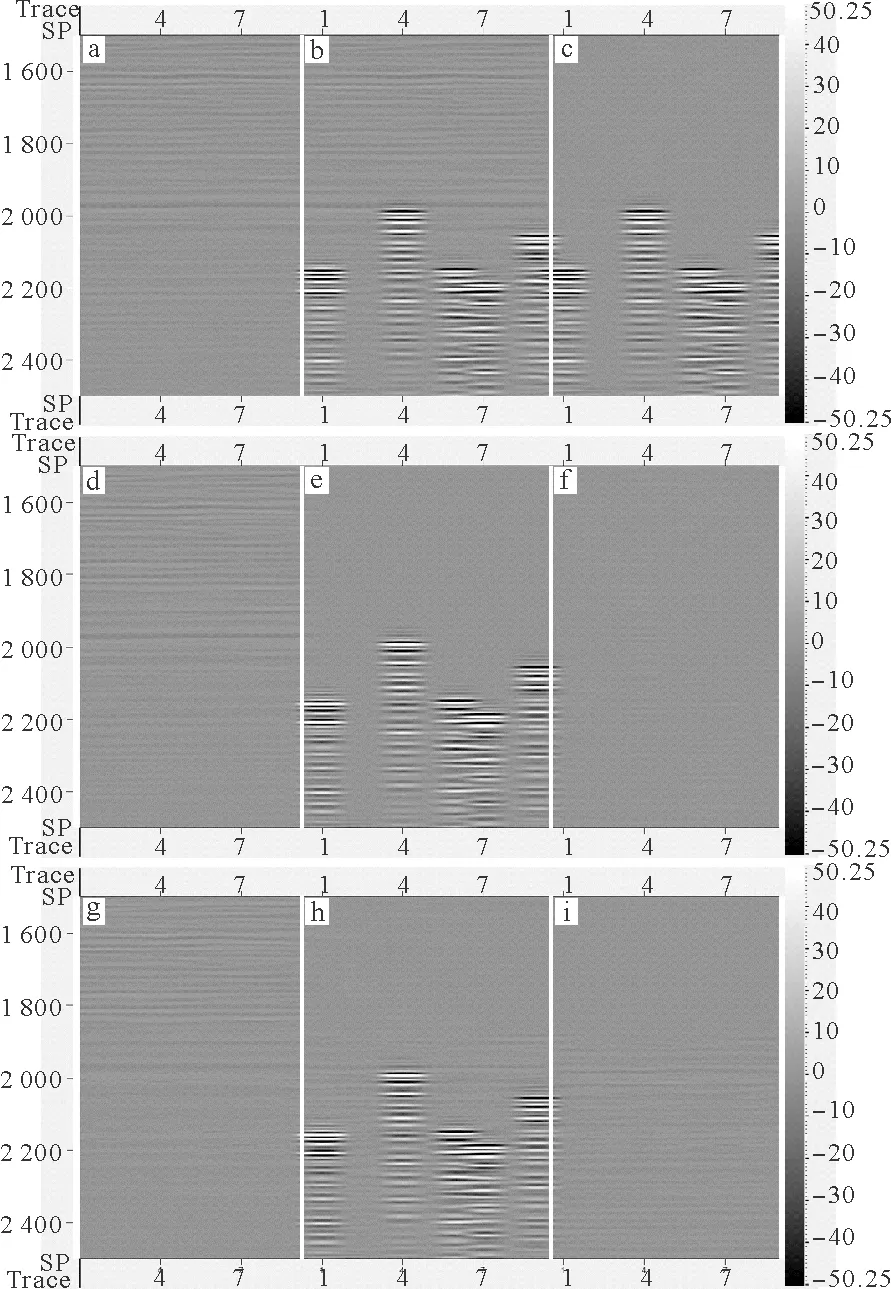
(a:未混合数据;b:混合震源数据;c:混叠噪声;d:CNN混采分离结果;e:CNN分离掉的噪声;f:CNN混采分离结果d与未混合数据a的残差;g:常规方法混采分离结果;h:常规方法分离掉的噪声;i:常规分离结果g与未混合数据a的残差。a: Reference unblended data, b: Blended data, c: Blending noise, d~f: Deblended data, removed blending noise and the difference between unblended data and deblended data using the CNN, g~i: Deblended data, removed blending noise and the difference between unblended data and deblended data using the conventional method.)
应用CNN进行混采分离,无需人工指定特征,仅需调试确定少量超参数,即可训练获得神经网络模型。只要训练所用的数据集有一定丰富度,训练好的神经网络模型可用于其他区域的地震数据中进行混采分离。而常规混采分离处理时,需要进行繁多的参数试验,每更换一套地震数据,便需要重新进行试验,耗费时间人力。此外,CNN方法处理用时极短,6.5 G的数据仅用时289 s,不到5 min,平均每个样本仅耗时约0.013 s;而使用常规方法处理,同样大小的单个样本需耗时1.7 s。
4 结论
混合震源采集技术是地震勘探中一种十分高效的采集方式,兼顾了采集效率与成本。并且具有增加照明范围,提高信噪比等优势。
本文开展了卷积神经网络在海洋地震勘探拖缆混采数据分离中的应用研究,构建了适用于地震数据处理的卷积神经网络模型。通过对实际拖缆数据进行数值混合,制作数据集,对神经网络模型进行训练,将训练好的模型应用测试集进行测试,试验结果表明:
(1)采用CNN进行混采分离的方法具有较高的分离精度,且所用参数较少,相较于常规方法繁多的参数和反复的试验,更加简便。
(2)采用CNN进行混采分离的方法具有很高的效率,在训练模型阶段需要花费一定时间,一旦训练完成,处理用时极短,效率很高,能够大大减少地震数据处理的时间。
