语音潜信道通信方法及其防护措施*
2021-03-21吴思慧王佩瑶费灵芝
郭 娟,文 红,2,3,张 鹏,吴思慧,王佩瑶,费灵芝
(1.电子科技大学 航空航天学院,四川 成都 611731;2.电子科技大学 飞行器集群智能感知与协同控制四川省重点实验室,四川 成都 611731;3.电子科技大学 四川省智慧物联通信技术工程研究中心,四川 成都 611731)
0 引言
信道是通信系统的一部分,是传输各种信息的通道。潜信道是一种隐蔽存在的信道,可以在不为人知的情况下实现重要机密的传输,该概念最早由Simmons在1978年提出[1]。传统扬声器的声音传播是发散式的,由此产生的噪声给人们的日常带来了各种困扰,一种高指向的扬声器应运而生。高指向的扬声器对于不在该方向的人而言,感受不到声音的存在,这就是一种隐蔽的信息传输方式,因此,可以将这种声音传播方式称为语音潜信道通信,产生的高指向性的声音为“声音波束”,正如图1所示,只有波束所指的方向上的人物能够正常接收到声音信号。
不容置否,科技是一把双刃剑。潜信道信息在安全通信方面发挥着重要作用,由此带来的安全隐患问题同样值得思考并解决。近年来,智能语音助手带来了良好的用户体验,但因为缺乏严格的机制来保证操作系统的声源的可信性,智能语音系统容易受到非法语音命令的攻击[2-3]。使用潜信道语音通信技术可以对电子产品注入旁人难以察觉的“声音波束”控制命令,可能导致致命性的灾难。
本文从“声音波束”的产生及其安全隐患着手,提出解决基于机器学习的软件相关的防御办法。由于该隐患不再是传统的简单的声音的复现,因此,提出基于HHT对MFCC的改进算法提取信号特征,使用不同的分类算法验证所提出的防御措施的可行性,同时对比发现MFCC改进后防御系统的识别的准确性普遍提高了。
1 “声音波束”生成原理
“声音波束”的产生主要包括3部分:一是将声音调制到超声波上,二是对信号进行波束成形处理,三是将信号利用扬声器阵列发射。
将普通声音调制成超声波的方法已经非常成熟,该过程涉及AM调制,是将需要隐蔽传输的信号控制高频载波信号,对该过程进行一般性建模,其表达式为:
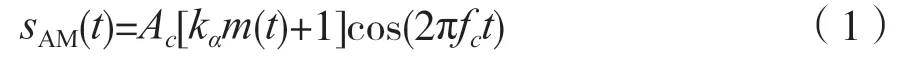
式中中,m(t)为调幅波模型的输入信号,sAM(t)为调制好的高频输出信号,频率为fc,kα是调制幅度,满足|ka|≤1。从频域角度分析,可得到调制后的语音含有fc、fc±fm这3种频率分量。
波束成形这一技术的使用主要是为了得到特定方向的声音波束,该理论最早使用于MIMO系统的智能天线[4],对该过程进行一般性建模,得到:
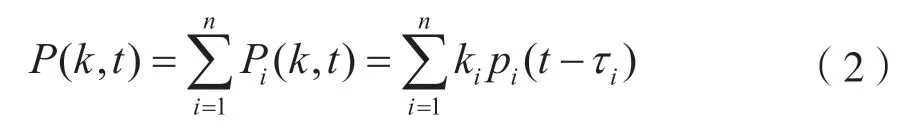
式中,pi(t)为经AM调制后的高频信号,Pi(k,t)为经过幅度加权并延时的信号,加权因子为ki,延时为τi。在已知目标方向后,可以控制pi(t)的权值ki以及延时τi,使得声音在该方向得到一个最大值,而在其他方向上信号尽可能小,实现声音定向传输,实现语音潜信道通信。
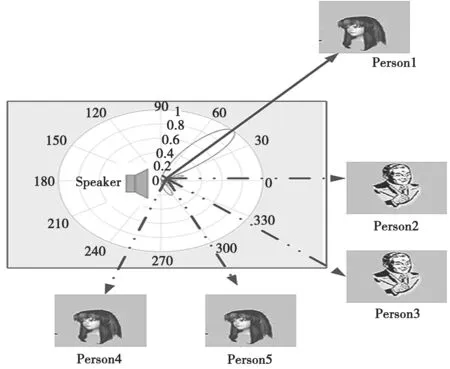
图1 语音潜信道隐蔽安全通信示意图
自适应滤波通过各种准则来自适应调整加权值,使得波束成形处理方法得到更多的普适性,尤其是存在干扰的情况下。图2是假设目标方向在30°,窃听者方向在40°,经过自适应波束成形仿真,可以将信号最大化地传输到目标方向,同时使得窃听方向存在陷波,抑制信号在该方向的传输。
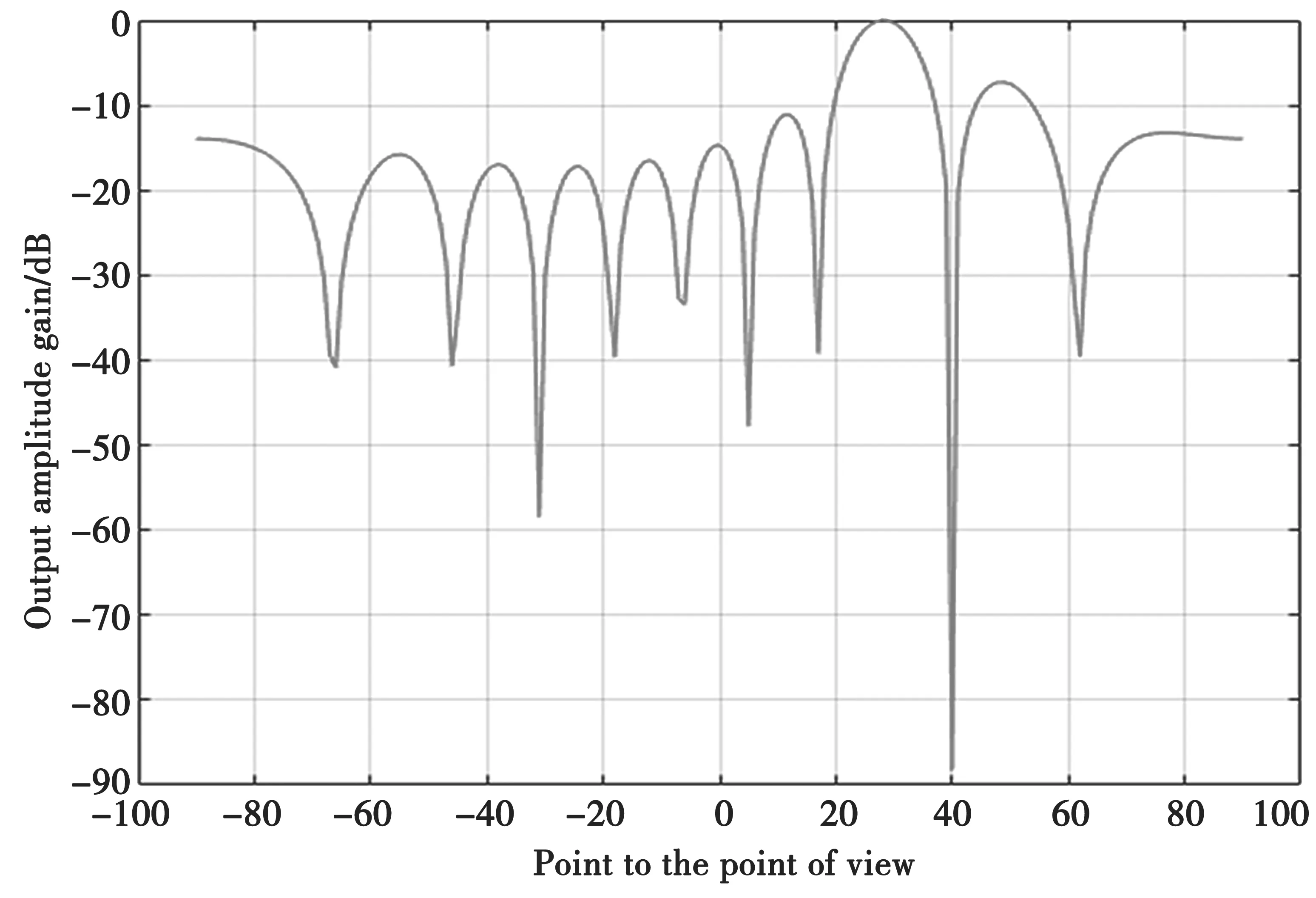
图2 自适应波束成形指向图
超声波是一种人耳甚至麦克风(麦克风电路中含有低通滤波器)无法理解的一种高频声音信号。而传统的AM解调方法代价都很高。扬声器阵列能利用空气这一非线性介质从高频信号中解调出原始信号,使语音潜信道通信方法如虎添翼。
扬声器阵列也具有增强声音指向性的作用,主要是以Westervelt方程[5]及“Berktay远场解”[6]为理论支持的。Westervelt方程可表示为:
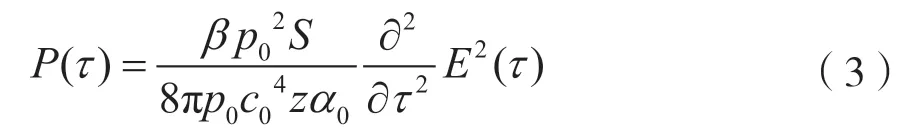
式中,β是非线性因子,p0是声压幅值,S是声源面积,z是传播距离,E(τ) 是调制信号,表示声音到达目标方向的时间。波束成形处理的目的之一是补偿各阵元的延时,使得各阵元到达目标方向的值最大。从上式中可以推出,调制高频信号经过二次求导后,含有fc±fm、fc、fm、2(fc±fm)、2fc、2fc±fm多种频域分量,其中fm频率分量是常人可以理解的声信号,也是原始语音信号的频率,其余高频成分的语音具有衰减快和人耳不易察觉的特点,在传播过程中被忽略了。“Berktay远场解”则是对Westervelt方程的补充,使得任何宽带信号可以做傅立叶级数展开,宽带信号可以看成具有多个频率分量的信号。
原始低频声信号经过上述3个过程实现了语音潜信道隐蔽安全传输。
2 基于HHT改进的MFCC模型
梅尔倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)是根据人耳听觉特性提出的一种语音特征提取方法,常用于语音识别系统,与频率的关系可以表示为:
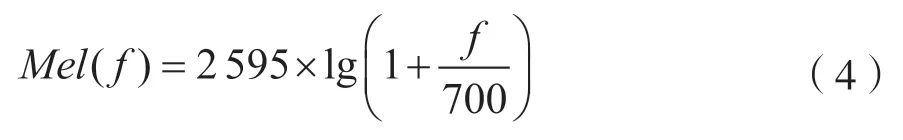
MFCC特征提取是假设语音信号是平稳的这一理想前提下,但是实际中,语音信号是连续非平稳的。本文提出基于黄-希尔伯特变换(Hilbert-Huang Transformation,HHT)改进的MFCC特征提取方法,该方法可适用于非平稳信号中。基于HHT的MFCC改进的流程如图3所示,与MFCC的特征提取过程相比主要是增加了HHT经验模式分解以及分解后IMF(Intrinsic Mode Function,IMF)分量的重组,并且用HHT边际谱代替FFT谱。HHT变换根据经验模态分解方法将信号分成若干IMF和一个残余分量,每一个MIF代表一定频率段的震荡情况,并且每个MIF的频率逐渐降低。
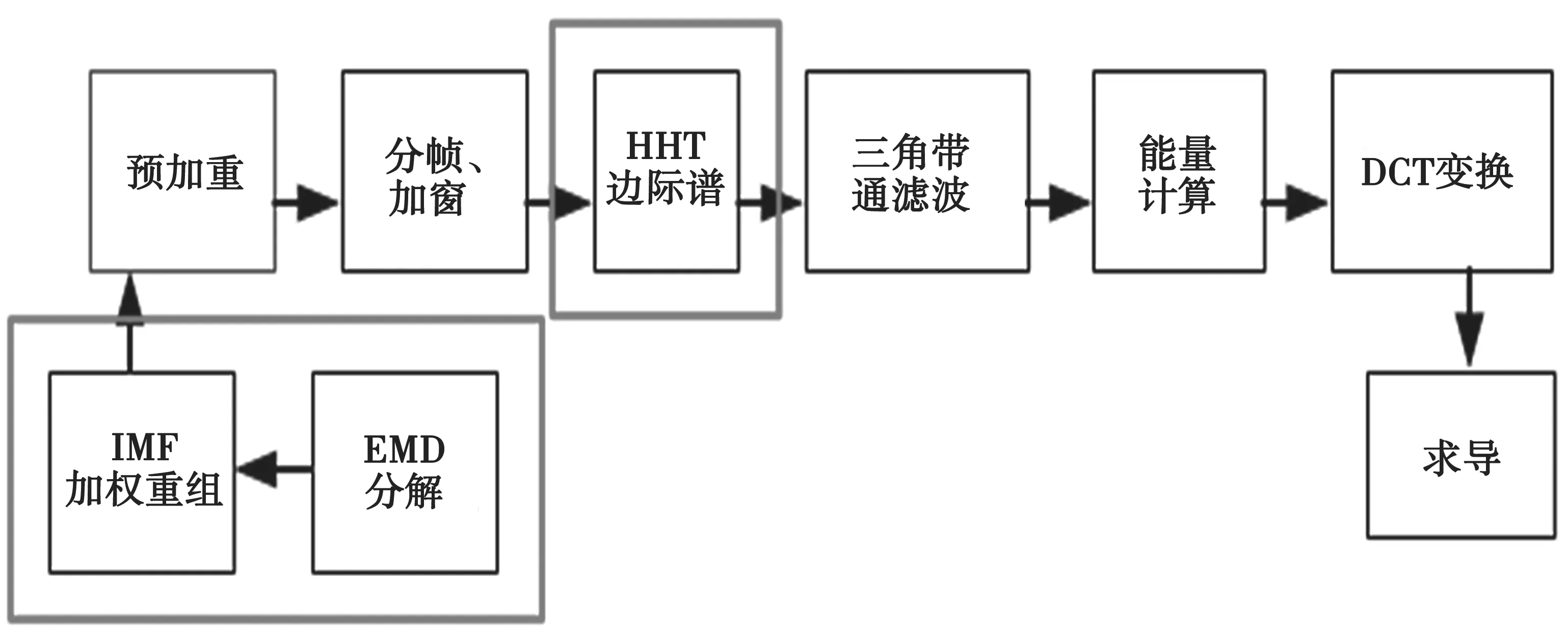
图3 基于HHT的MFCC特征提取流程
由于高频分量主要分布在前几个IMF,后几个MIF函数的幅值几乎为零,为了凸显高频信号对原始信号的贡献,重新对前五个MIF函数进行加权重组形成新的信号,权值分别是1,0.7,0.5,0.3,0.3。随后,在进行与MFCC特征提取相同的操作,不同的是,不使用快速傅立叶变换,而是通过求HHT的边际谱代替该过程。HHT的边际谱是将信号与基函数做卷积得到的,是全局意义下的频率谱。图4中,分别对FFT傅立叶变换的幅频特性和HHT的边际进行对比,发现两者形状相似。
使用改进后的MFCC分别对高频和低频两种语音进行特征提取,该特征是由36维的向量,对于任何一段语音取中间260帧信号进行分析,高低频两种信号的改进后的MFCC第一维MFCC特征如图5所示。
3 “声音波束”攻击防御方法
智能语音设备存在被有心人利用的风险,例如将听不到的海豚音注入非线性器件麦克风[2]。然而,本文提到的语音潜信道通信方式具有能量更大,方向性强,低通滤波器无法滤除的特点,产生的危害更为致命。
本文已经指出该语音潜信道通信方式仍存在高频成分以及改进后的MFCC对高低频两种声音的提取的特征存在差异性,提出对含有智能语音助手设备的麦克风接收的语音进行分类,根据声音来源判断语音命令的合理性的防御措施。
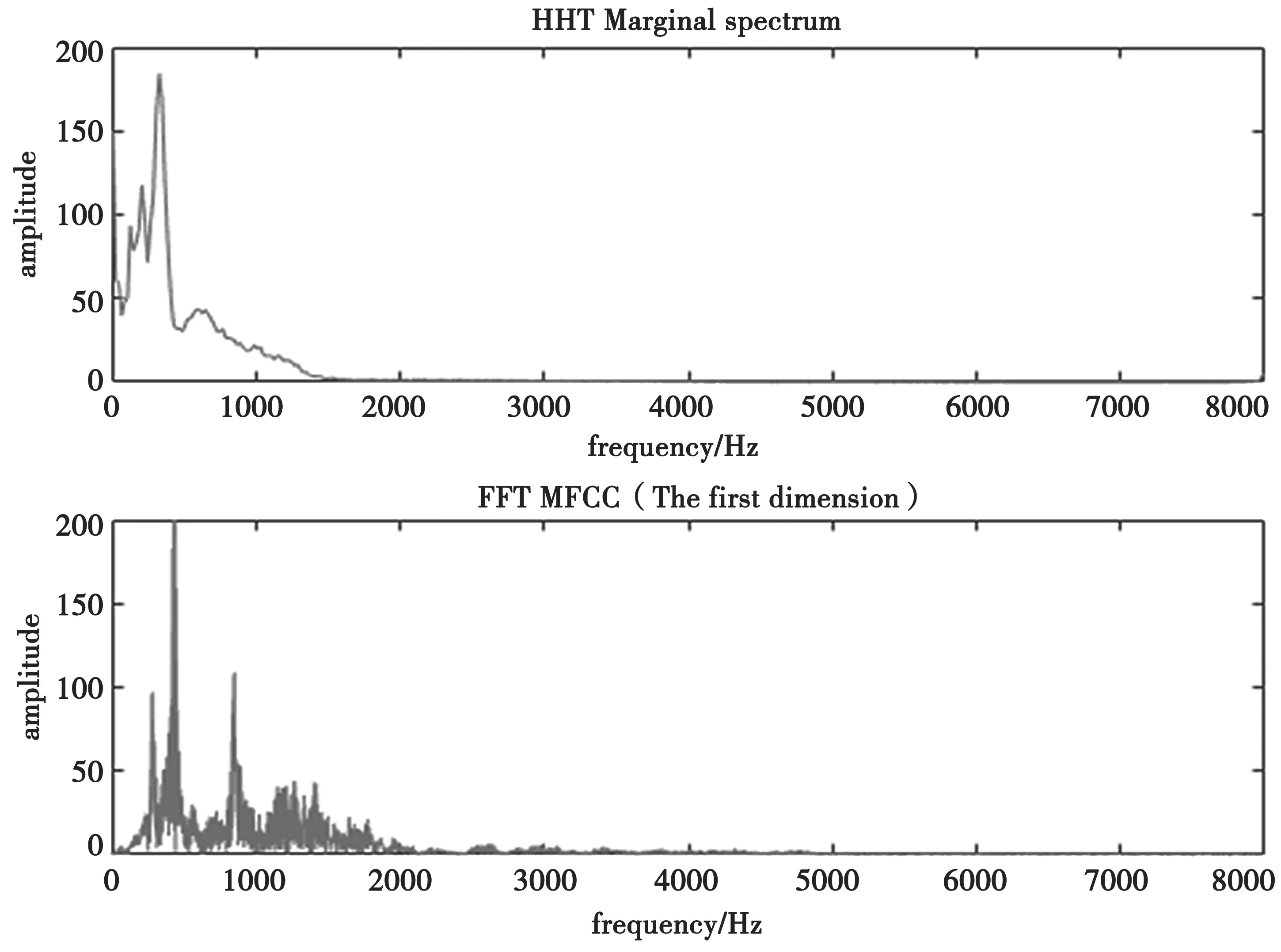
图4 HHT边际谱和FFT幅频对比
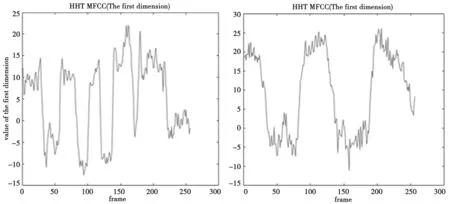
图5 基于改进的MFCC对高低频两种语音特征提取
通过机器学习算法可以对数据进行高效的处理,本节采用4种常见的机器学习分类算法:支持向量机(Support Vector Machines,SVM)、随机森林(Random Forest)、K-近邻算法(K-Nearest Neighbor,K-NN)、误差反向传播(error Back Propagation,BP)算法验证该防御措施是否可行。此外,还验证了改进的MFCC比改进前的特征更具有代表性,通过分别对所改进的MFCC和原来的MFCC所提取的特征数据进行分析,建立相应的机器学习识别模型,再使用实际采集的音频信号对模型进行验证分析,比较改进前后的MFCC提取特征的识别率。
4 实验验证
在空旷且安静的环境中,对高频和低频语音信号各采集了20组,各包括10组男性和10组女性声音。根据上述语音特征提取,每一组声音可以用260帧36维数据表示,对于每一组语音,再随机抽取其中25帧作为数据集,25帧作为测试集,每一帧高频语音数据记为标签“0”,为非法语音,低频语音数据记为标签“1”,为合法语音,这样得到1 000×37的训练集和1 000×37的测试集样本。
此外,为了验证基于HHT改进的MFCC特征提取的性能比改进前的好,在语音中分别加入信噪比为5 dB、10 dB的高斯白噪声,在相同的分类模型下比较它们的性能。得到的结果如图6所示。
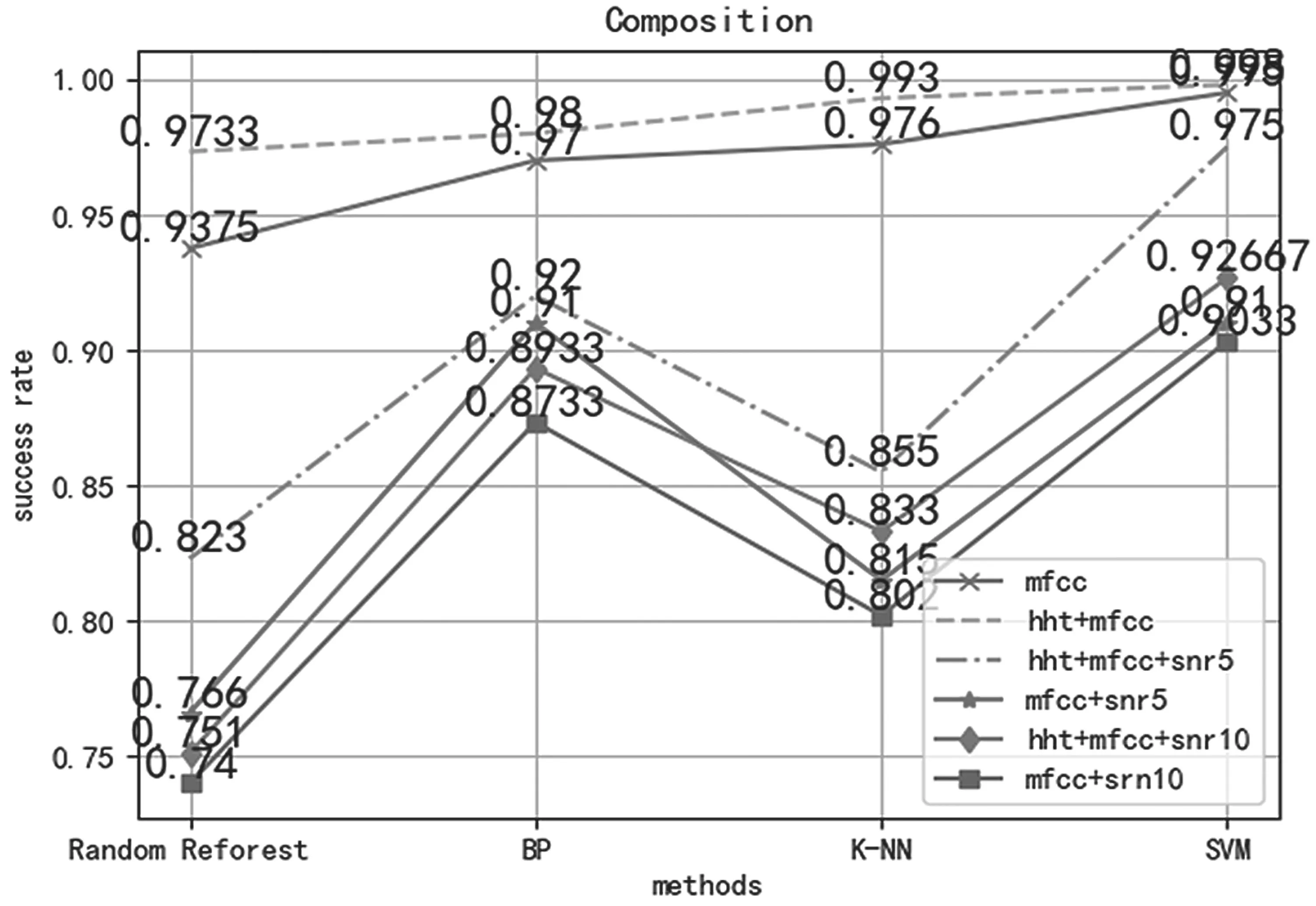
图6 实验结果
HHT改进后的MFCC对高频声音的识别率普遍高于改进前大约5%,这也体现了相同维度的改进后的MFCC较改进前含有更多的信息分量,由此判定的改进是有效的。此外,SVM分类模型和BP算法分类模型即使在加入信噪比为10 dB的噪声后,识别率仍能在87%以上,这两种分类算法模型具有更强的鲁棒性,能更好地应用到防御系统中。
5 结语
语音通信围绕着人们生活的方方面面,本文提出了一种新的语音潜信道通信方式,不同于以往的是,该方法借助自然现象——空气的非线性生成定向语音信号实现语音潜信道通信。考虑到这种通信方式的高隐蔽性带来的危害,本文提出了基于HHT的MFCC改进方法提取语音信号特征,使用机器学习的不同分类模型对两种通信方式的语音信号进行判别。在加入不同信噪比的高斯白噪声情况下经分类模型测试发现,改进后的MFCC特征识别率更高,同时,对比发现BP算法和SVM算法两种算法用于防御系统中更具鲁棒性,证实了所提出的防御措施是有效的。
