基于特征选择和XGBoost的风电机组故障诊断
2021-03-20靳志杰霍志红郭宏宇周华建
靳志杰,霍志红,许 昌,郭宏宇,周华建
(河海大学 能源与电气学院,江苏 南京 211100)
0 引言
近年来,风电产业高速发展,随着风电装机容量的增加,风电装备运行安全保障和运维成本增加愈发成为风电行业的重要问题。部分风电场进入运营中后期后,运维成本不断上涨,做好风电机组运行状态预测和故障诊断能有效减小风电机组故 障 率,提 升 风 电 场 效 益[1],[2]。
目前,风电机组的故障诊断主要分为基于解析模型和基于数据的故障诊断方法[3]。随着机器学习和神经网络技术的发展,大量学者开展了基于机组运行数据的故障诊断研究。文献[4]提出了一种基于风电机组SCADA数据的轴承故障预警方法,通过相关性分析提取SCADA所记录的轴承运行相关特征数据,使用BP神经网络实现轴承故障预警。文献[5]利用FDA故障贡献图分析变桨系统故障强相关特征变量,进而实现故障定位。文献[6]对现有的各种支持向量机模型的特点进行了系统分析,提出了包括标准型支持向量机、最小二乘支持向量机以及和其相关的混合模型对电机故障进行诊断。文献[7]采用极端梯度提升算法提取隐含特征信息,应用支持向量机算法实现基于数据的故障诊断。以上研究中,故障诊断过程中的特征选取方式均影响模型性能,对风电机组数据进行初始特征选择时多依赖人的先验知识,在数据特征较多时无法完全排除人的主观性影响。依靠相关性分析和主成分分析进行特征变换只能处理具有线性关系的特征,存在新构造特征向量可解释性弱,降维后反而不利于模型训练的问题[8]。所采用的浅层机器学习算法对复杂函数的表述能力不足,不同机器学习算法对不同型号风电机组、不同部件的故障诊断性能差异较大。
针对基于数据的故障诊断方式中特征选择过程存在主观性及所采用传统机器学习算法性能不佳的问题,本文提出了一种基于特征选择和XGBoost的风电机组故障诊断方法。在该方法中,首先利用随机森林的袋外估计功能对故障相关特征进行重要性排序,并做特征选择;然后采用网格搜索和交叉验证优化的XGBoost算法进行故障诊断。使用荷兰某风电场机组SCADA数据对模型进行训练和验证后发现,该方法的运算结果在精度上高于传统机器学习方法的计算结果。
1 基于随机森林的特征选择
1.1 SCADA数据预处理
SCADA为风电场运营商提供风电机组各系统运行状态监测信息,是风电场运行维护的主要支撑。其监测内容为风资源和机组运行状态,包括离散数据和连续数据两类,具体监测数据有风速、风向、有功功率、转子转速、各部件温度等。以湖南某风电场为例,其在2014年6月1日-2015年5月31日采集的部分监测数据如表1所示。

表1 SCADA数据示例Table 1 Examples of SCADA data
对SCADA原始数据进行初步筛选,剔除因传感器故障、通讯故障等引起的不合理数据和明显异常工况数据[9],减小异常数据对故障诊断模型训练和测试精度的影响。SCADA数据筛选之后,结合机组运行状态记录对数据进行状态标记。
1.2 特征选择
风电机组SCADA系统所采集数据种类众多,其中包含与故障有关特征数据、无关特征数据和有关但冗余特征数据,在面临复杂故障时,依靠专家的经验和简单相关性分析进行特征选择工作已不能完全且准确获取与故障相关的重要特征,因此本文采用随机森林(RF)的袋外估计对故障相关特征进行重要性排序[10]。
RF是基于决策树的组合分类器,可用来进行特征选择。RF使用Bagging方法从原样本集中随机且可重复抽取样本进行分类器训练,其中约37%的样本数据不会被选中,这些数据称为袋外数 据(Out of Bag,OOB)。计 算 某 特 征 重 要 性 时,用OOB数据作为测试集测试训练后的基学习器,测试错误率记为袋外误差(errOOB);对OOB样本中待计算重要性特征加入噪声,再次计算errOOB;计算所有基学习器的测试平均误差,以平均精度下降率(MDA)作为指标进行特征重要性计算[11]。
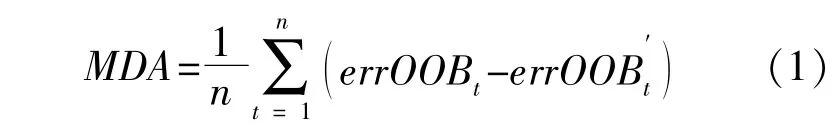
式中:n为基学习器的个数;errOOB′为加入噪声后的袋外误差。
MDA指标下降越多,说明所对应特征对预测结果影响较大,进而说明其重要性越高。这种特征重要性计算方法称为随机森林的袋外估计,依此方法对故障相关特征进行重要性排序,进行特征选择。
2 故障诊断模型
2.1 极端梯度提升
极端梯度提升(XGBoost)是T Chen在2016年提出的一个分布式通用Gradient Boosting库[12],该算法是以决策树作为基学习器的集成学习模型,可在训练时利用所有CPU内核并行建树。XGBoost在梯度提升的基础上改善了目标函数计算方式,可提高模型精确度,并将目标函数的优化问题转化为求二次函数的最小值问题,利用损失函数的二阶导数信息训练树模型,同时将树复杂度作为正则项加入到目标函数中,提升了模型的泛化性能。XGBoost的目标函数为
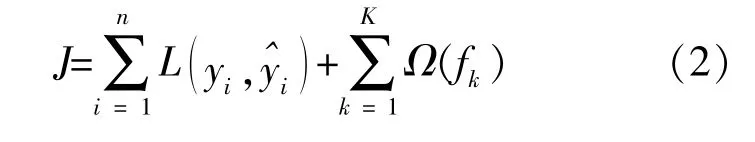

目标函数在时间t内的迭代结果为

式 中:ft(xi)为 第t次 迭 代 计 算 变 量xi所 在 决 策 树复杂度;C为常数。
将损失函数进行二阶泰勒展开,设损失函数为均方误差,则目标函数为

式中:gi,hi分别为均方损失函数的一阶和二阶导数。
为避免传统经验法确定参数值导致参数组合为局部最优的结果,本文采用网格搜索算法对XGBoost模型进行参数优化,并采用交叉验证减小模型训练过程中随机抽取样本所致偏差影响[13],该种参数寻优方式可获得网格参数内全局最优参数组合,进而获得参数最优下故障诊断模型。
2.2 建模流程
本文基于随机森林和XGBoost算法实现风电机组故障诊断,其具体步骤如下:
①数据预处理阶段对风电机组SCADA数据进行筛选,剔除异常数据,减小其对模型的影响;
②数据进行预处理后,利用随机森林的袋外估计功能获得特征的重要性排序来进行特征选择,并综合考虑模型的准确性和计算时间选择特征集;
③将经特征选择后的数据划分为训练样本和测试样本,为模型的训练及测试备好数据集;
④利用训练样本对模型进行训练,通过网格搜索和交叉验证对XGBoost算法模型进行参数优化,得到该训练样本对应全局最优参数组合下的故障诊断模型;
⑤利用测试样本对步骤④所获取模型进行检验,通过常用机器学习模型性能衡量指标准确率、精准率、召回率和平衡分数F1值检验所提模型准确性。将决策树(DT)、支持向量机(SVM)和RF传统机器学习算法与应用XGBoost算法的模型计算结果进行横向对比,检验所提模型优异性。
建模流程如图1所示。
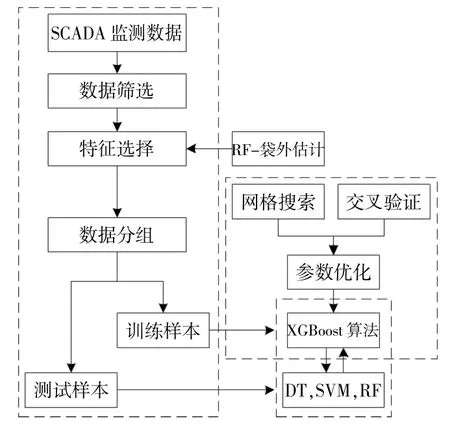
图1 故障诊断模型构建流程Fig.1 Fault diagnosis model flow diagram
3 实例分析
3.1 特征选择
本文依据荷兰某风电场2014年4月6日-2015年4月1日连续360 d故障记录台账和SCADA记录数据,以52 560条、61个特征数据作为原始数据,经数据筛选后留存有效数据49 028条,留取状态数据27 398条,关键状态数据1 850条,该数据集覆盖机组正常运行状态和故障状态。对常见发电机和变流器位置处A,B两类故障进行预测,分别为发电机过热(故障A)和变流器馈电(故障B)故障。
通过随机森林的袋外估计功能,针对两个类型故障,对表2所示29个初选特征变量进行重要性计算,每一类故障重复进行20次计算,每项特征重要性取20次计算平均值。然后再进一步选取特征重要性排名前9和前6的特征变量集进行精确度测试。

表2 特征描述及重要性Table 2 Feature variable description and importance
通过所提故障诊断模型对不同特征数量方案进行对比(表3)。
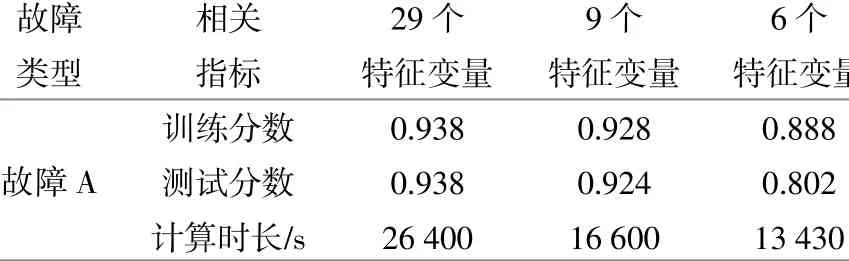
表3 特征变量方案选取对比Table 3 Comparison of feature variable scheme selection

续表3
由表3可知:模型在输入29个特征变量和9个特征变量时计算结果精确度相近,与输入29个特征变量进行训练相比,输入9个特征变量的训练耗时能够降低30%;输入6个特征变量和输入9个特征变量进行训练相比,训练耗时有所减少,但模型精确度出现明显下降。综合考虑模型精确度和训练耗时,选择输入9个特征变量训练各个故障诊断模型。
3.2 模型参数优化
本文采用网格搜索算法和10折交叉验证对XGBoost算法进行参数优化,具体步骤如下:
①确定调节参数及取值范围,预设最小均方误差值0.4作为优化标准;
②依据参数调节范围构造粗网格,设定步长,计算网格内每一点经10次迭代计算后的平均均方误差;
③以经步骤②计算后低于误差设定值的点为中心,附近点作为边界构造细网格,设置新步长,重复步骤②,计算低于设定值所有点并记录结果;
④比较步骤③得出的所有平均均方误差,平均均方误差值最小的点所对应参数作为模型全局最优参数组合。
通过上述步骤,为每一类故障诊断模型进行参数优化,调节参数如表4所示。

表4 XGBoost参数设定范围及含义Table 4 Range and meaning of XGBoost hyperparameter
3.3 故障诊断结果
应用最优参数下的故障诊断模型对故障A和故障B进行诊断,并与DT,SVM和RF传统机器学习算法的计算结果进行对比。采用准确率、精准率、召回率和F1值作为评判指标对模型计算结果进行评判。为保证测量结果的准确性,重复测试10次,取10次平均值作为最终结果,结果如表5所示。

表5 故障诊断结果Table 5 Diagnosis results of fault
对于故障A:DT和SVM算法模型各项指标均低于0.9,表现不佳;XGBoost和RF算法模型性能类似,XGBoost算法模型的各项指标均高于0.9,其中召回率明显高于其它算法模型,说明该算法模型对A类故障关键信息的提取能力较强。
对于故障B,XGBoost算法模型的诊断结果在准确率、精准率、召回率和F1值上明显高于传统机器学习算法,各项指标均高于0.93,与传统机器学习算法相比,诊断效果有很大提升。
以计算过程所得假阳率和真阳率作为横、纵坐标绘制受试者工作特征曲线(ROC),对比不同算法模型性能。AUC(Area Under Curve)即ROC曲线下面积,是衡量模型优劣的一种性能指标,其值越大,代表模型的性能越好,准确率更高。
故障A各算法模型的ROC曲线对比如图2所示。

图2 故障A各算法模型的ROC曲线对比图Fig.2 Comparison diagram of ROC curve-fault A
由图2可知:相较于DT和SVM算法模型,RF和XGBoost算法模型对应的ROC曲线位置相近;DT与SVM算法模型的ROC曲线更靠近左上角。验证了所提XGBoost算法模型的有效性。
故障B各算法模型的ROC曲线对比如图3所示。

图3 故障B各算法模型的ROC曲线对比图Fig.3 Comparison diagram of ROC curve-fault B
由图3可知:XGBoost算法模型的AUC值为0.96,说明该算法模型具有较高的准确性;XGBoost算法模型对应的ROC曲线整体更靠近左上角,即AUC值更大。验证了XGBoost算法模型的优异性。
4 结论
本文提出了一种基于特征选择的XGBoost风电机组故障诊断算法,该方法将随机森林的袋外估计应用到特征选择中,运用经网格搜索算法和交叉验证优化的XGBoost算法模型作故障分类预测。
①XGBoost故障诊断方法利用风电场SCADA实测数据,通过挖掘数据中隐含的机组状态特征信息,实现故障诊断,能够提高风电机组运行数据利用率,有效降低故障诊断模型部署成本。
②采用随机森林的袋外估计功能获取特征重要性排序,得到故障强相关特征,有效提升了复杂故障的特征选择客观性和准确性,拓宽了故障诊断模型的适用范围。该故障诊断方法利用网格搜索算法对XGBoost算法模型进行参数优化以提高模型准确性,参数调优过程简单且可获得全局最优参数组合,同时采用交叉验证方法避免随机抽取样本训练导致的测试偶然性误差。这两项举措提高了模型的预测准确率,增强了模型在不同型号风电机组的部署能力。
③采用荷兰某风电场实测数据对所提故障诊断模型的有效性进行验证。两种风电机组故障诊断结果表明,模型的预测准确率均达到0.91以上。XGBoost算法较传统的机器学习算法模型在预测准确率上有较大的提升,验证了所提故障诊断方法的有效性和优异性。
